

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
LXD (LinuX container Daemon) est un environnement complet comprenant une API, des outils et un service (daemon) permettant de gérer des conteneurs LXC (LinuX Containers) et des machines virtuelles QEMU / KVM sur un cluster de machines Linux. L’atout principal de LXD est sa légèreté en termes d’installation, administration et empreinte sur le système. Dans cet article, nous allons explorer l’installation et l’utilisation d’un cluster LXD.
La virtualisation et la conteneurisation sont deux mécanismes radicalement différents dans leur fonctionnement, mais partageant le même objectif : isoler un ou plusieurs processus. Ces processus isolés, qu’il soient virtualisés ou conteneurisés, peuvent être créés individuellement sur chaque machine les hébergeant ou alors orchestrés sur un cluster de nœuds dédiés à cet usage. L’orchestration consiste à distribuer les machines virtuelles et les conteneurs sur un ensemble de machines en passant uniquement une contrainte de ressources et une image à déployer. Un composant nommé orchestrateur (orchestrator) examine votre contrainte de ressource et essaye de placer vos conteneurs et machines virtuelles en fonction. Dans certaines ressources sur la conteneurisation et la virtualisation, vous pourrez trouver le terme ordonnanceur (scheduler) à la place d’orchestrateur. Le terme ordonnanceur est usuellement réservé au noyau Linux, plus précisément le CFS (Completely Fair Scheduler) chargé de répartir le temps processeur entre les différents cœurs du processeur. On retrouve également ce terme pour parler du service chargé de placer les travaux des utilisateurs sur les clusters HPC (High Performance Computing). Dans cet article, nous parlerons d’orchestrateur pour évoquer LXD et consorts.
1. Introduction
Il existe de nombreuses solutions pour orchestrer des processus isolés sur une infrastructure. Côté logiciels propriétaires, on trouve l’incontournable VMWare. Pour le libre, on trouve Proxmox [1] ou OpenNebula [2,3]. La question qui vient immédiatement à l’esprit concerne le positionnement de LXD dans cet écosystème. Son originalité est de proposer une solution beaucoup plus simple en termes d’architecture, d’installation et d’utilisation que les solutions susnommées. En effet, ces solutions lourdes intègrent, en plus de l’orchestration, le provisionnement des machines hébergeant les conteneurs et les machines virtuelles. Le provisionnement consiste à créer et mettre en place une infrastructure informatique physique ou virtuelle de façon automatique ou manuelle. Ce terme regroupe les différentes étapes nécessaires à la gestion de la mise en place d’un système fonctionnel. Nous noterons que lorsque le provisionnement est mentionné, il sous-entend généralement un déploiement automatique par lot. Les solutions susmentionnées intègrent également le provisionnement des images de machines virtuelles et conteneurs. En plus d’assurer le provisionnement des différents acteurs, les solutions lourdes assurent leur supervision via des agents déployés sur les machines hôtes pour la machine elle-même et ses conteneurs et dans les machines virtuelles. Cette supervision sert notamment à piloter le passage à l’échelle du service sous-tendu par les machines virtuelles et/ou les conteneurs. Enfin, les solutions lourdes intègrent également la virtualisation du réseau d’interconnexion des machines virtuelles et des conteneurs pour réglementer les interactions entre eux ainsi que vers l’extérieur. Pour notre étude de LXD, nous allons déployer un laboratoire très simple en machine virtuelle. Nous allons avoir trois nœuds :
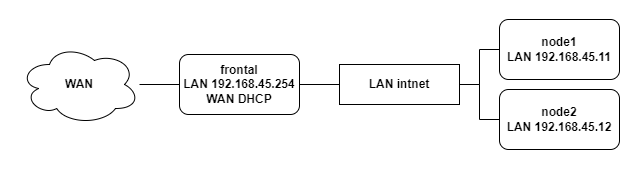
- Un frontal portant le DNS de notre laboratoire ainsi qu’un serveur DHCP. Cette machine fait également office de routeur vers l’extérieur ;
- Deux nœuds (node1 et node2) chargés d’accueillir les machines virtuelles et les conteneurs. Ces nœuds embarquent donc LXC pour l’instanciation des conteneurs et KVM pour les machines virtuelles. J’ai activé le « nesting » pour pouvoir imbriquer les machines virtuelles.
Nous nous servirons de ce laboratoire pour présenter la configuration de LXD ainsi que le déroulement de plusieurs scénarios d’instanciation. Nous verrons ce qui se passe concrètement sur les nœuds lorsque les machines virtuelles et les conteneurs sont en exécution. Dans la figure 1 représentant le laboratoire, nous voyons que la machine frontale est bidomiciliée. Elle est à la fois connectée au réseau externe en NAT pour accéder à internet et à un réseau interne nommé intnet. Les machines node1 et node2 sont également connectées à intnet. Le réseau intnet porte le réseau 192.168.45.0/24. Le frontal est en 192.168.45.254 et node1 et node2 sont respectivement en 192.168.45.11 et 192.168.45.12. Le frontal embarque également un serveur DHCP qui sert l’étendue 192.168.45.100 à 192.168.45.200. En conséquence, le frontal fait office de passerelle pour que node1 et node2 puissent sortir sur l’extérieur.
2. Les briques de base
Pour préparer l’installation de LXD sur notre cluster de test, il faut présenter deux briques : LXC et KVM / QEMU. LXC est utilisé pour gérer les conteneurs, alors que KVM / QEMU s’occupera de l’instanciation des machines virtuelles. Ces deux briques vont s’appuyer sur un réseau très simple. Sur chaque nœud, nous créerons un pont sur l’interface portant le réseau 192.168.45.0/24 afin d’y attacher nos machines virtuelles et conteneurs. Nous commencerons donc par créer les ponts sur node1 et node2. Ensuite, nous présenterons LXC et enfin nous présenterons KVM / QEMU.
2.1 Création des ponts
Un pont est une extension de domaine de diffusion (broadcast) Ethernet (niveau 2 du modèle OSI). Un pont peut être physique. Par exemple, lorsque vous tirez un câble entre deux commutateurs, vous agrégez les deux domaines de diffusion Ethernet de chacun des commutateurs en un seul. En conséquence, comme ces deux commutateurs sont sur le même domaine de diffusion Ethernet grâce au câble d’interconnexion, le trafic ARP passe de l’un à l’autre. Ainsi, les paquets transportés peuvent circuler entre les machines du même réseau IP. Sur un système Linux, nous pouvons créer des ponts virtuels locaux à la machine. En conséquence, les machines virtuelles et les conteneurs attachés au pont pourront communiquer sur le réseau de la machine hôte. Nous verrons la configuration du pont pour node1, il faudra faire la même chose sur node2. Commençons par installer les paquets gérant les ponts sous Linux :
Ensuite, nous allons configurer le pont dans /etc/network/interfaces :
L’interface réelle de la machine est enp0s3, elle est connectée physiquement au réseau intnet. Nous voyons dans la configuration du pont br0 que enp0s3 est membre du pont (bridge_ports enp0s3). En conséquence, les interfaces virtuelles liées au pont verront le trafic de niveau 2 tel que ARP et pourront elles-mêmes y faire transiter des trames. Du fait que ce pont est virtuel, on peut désactiver le Spanning-Tree (bridge_stp off) considérer que toutes les interfaces du pont sont immédiatement disponibles (bridge_waitport 0) et qu’elles peuvent communiquer tout de suite (bridge_fd 0). Enfin, on spécifie l’adresse IP du pont (address 192.168.45.11/24) et sa passerelle par défaut (gateway 192.168.45.254). La configuration est à répéter sur node2.
2.2 Installation de snap
Pour disposer d’une version récente de LXD, nous allons passer par l’installeur snap. La différence avec apt est que snap dispose d’un magasin (snap store) alimenté en direct par les développeurs des applications. Par rapport à apt, le cycle de livraison des applications est plus court. Les paquets apt sont gérés par des mainteneurs, sont testés sur la distribution et surtout liés avec les autres paquets (sous forme de dépendances). Ainsi, les mises à jour via apt (ou avec tout autre gestionnaire de paquets natif de distribution Linux) sont beaucoup plus solides qu’avec des systèmes « cutting edge » comme snap. Ici, nous utilisons snap pour installer une seule et unique application donc la maintenance n’est pas très compliquée. D’autant plus que le système de base est assez simple, car il n’embarque que les utilitaires de base du système, KVM et LXC. En revanche, en cas d’assemblages complexes, le recours massif à snap sur une base conséquente installée avec apt peut mener à des incohérences de configuration. Commençons donc par installer snap sur node1. Le gestionnaire d’applications snap s’incarne sous la forme d’un service snapd s’exécutant en arrière-plan sur la machine. La première chose à installer est le paquet snapd sur notre Debian via apt. Contrairement à ce que le nom laisse supposer, le paquet snapd ne contient pas le daemon snapd. Il contient les script permettant à systemd de démarrer snapd lorsqu’il est présent. L’installation se fait donc en deux temps, d’abord l’installation du paquet snapd et l’enregistrement du chemin des exécutables snap dans le PATH :
Effectivement, aucun processus snapd n’est en exécution :
Une fois cette installation effectuée, il faut ajouter /snap/bin dans le PATH de votre session. Vous pouvez ajouter un export dans votre .bashrc :
Ensuite, on installe le paquet core via snap. Ce paquet contient les composants essentiels pour le fonctionnement du système de gestion des paquets Snap sur votre système Linux, y compris le démon snapd et les bibliothèques de base nécessaires à l'exécution des applications snap. Installons le paquet core :
Cette fois-ci, nous retrouvons bien un processus snapd en exécution sur le système :
Vérifions quand même que nous n’avons pas fait tout ça pour rien. Regardons la version de LXD dans les dépôts apt :
Nous sommes en version 5.0.2. Regardons la version proposée par snap :
C’est la 5.18, l’écart est donc assez considérable. Nous allons maintenant évoquer LXC qui sera présent sur les nœuds participant au cluster LXD.
2.3 La couche LXC
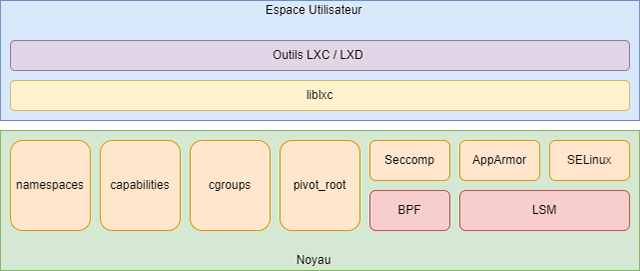
LXC (LinuX Containers) est un moteur de conteneur lancé en 2008 qui s'appuie directement sur les mécanismes disponibles dans le noyau pour isoler des processus. Son architecture est présentée dans la figure 2. LXC fournit à la fois une librairie servant d'interface d'utilisation de ces mécanismes avec le noyau nommée liblxc, mais également des outils de haut niveau pour les utilisateurs / administrateurs qui sont un ensemble de commandes préfixé par lxc-*.La librairie liblxc s'appuie sur des mécanismes de contrôle d'accès mandataires notamment SELinux [4] et AppArmor [5], pour créer des politiques d'isolation des conteneurs. Elle peut également tirer parti de Seccomp pour limiter les appels système. Seccomp s'appuie sur le framework BPF [6], idéal pour l’instrumentation des appels système. Si le conteneur a besoin de privilèges particuliers, liblxc peut s'interfacer avec les capacités. Évidemment, liblxc interagit également avec le couple cgroups [7] / espaces de noms [8,9,10]. Enfin, le système de fichiers du conteneur LXC est isolé grâce à pivot_root() qui est un appel système comparable à chroot() au niveau fonctionnel. La différence majeure est que pivot_root() requiert que la nouvelle racine de notre processus soit sur un système de fichiers différent, ce qui mitige les risques inhérents à chroot() qui se contente de modifier un attribut du descripteur de processus avec un nouveau chemin.Au niveau de l'usage, LXC est assez semblable à une machine virtuelle (attention, nous parlons bien de l'usage, pas des mécanismes sous-jacents). Il n'est pas vraiment utilisé par des développeurs, mais plus par des administrateurs pour créer des conteneurs de systèmes Linux complets beaucoup moins volatiles que les conteneurs type Docker. Vous pourrez retrouver dans [11] un exemple d’instanciation d’un conteneur LXC via LXD en mode standalone (c’est-à-dire sans notion de cluster comme le présent article).
2.4 La couche KVM / QEMU
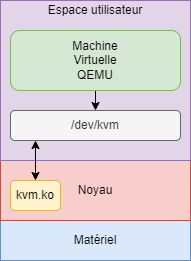
Pour la virtualisation, LXD va s’appuyer sur le couple KVM / QEMU. La figure 3 présente les imbrications entre ces deux composants. Commençons par installer QEMU sur notre machine (le noyau par défaut intègre déjà la couche KVM) :
QEMU s’appuie sur KVM pour exploiter le matériel. En effet, QEMU est un hyperviseur de type 2. C'est-à-dire qu’il s’exécute sous la forme d’un processus en espace utilisateur. En effet, si nous listons les programmes en exécution sur le nœud accueillant notre machine virtuelle, nous constaterons que nous avons un processus en cours d’exécution nommé qemu-system-x86_64 qui va la piloter. QEMU va s’appuyer sur la notion de « passthrough » pour optimiser les performances de la machine virtuelle via KVM. Pour bien comprendre ce principe, il faut savoir qu’en plus des hyperviseurs de type 2 déjà mentionnés, il existe des hyperviseurs de type 1 tels que KVM. Un tel hyperviseur dispose d’un accès direct au matériel, ce qui le rend plus performant qu’un type 2, mais nécessite des extensions de virtualisation au niveau processeur (ce qui est quand même majoritairement le cas de nos jours). La présence de KVM sous Linux se manifeste par l’exécution d’un module noyau nommé kvm (kvm.ko) :
Lorsque ce module est chargé, un périphérique bloc /dev/kvm est créé permettant à QEMU d’adresser directement le matériel réel (et pas celui émulé dans son espace), ce qui améliore les performances. C’est la mécanique par défaut de LXD lorsqu’il doit instancier une machine virtuelle. Il lance un processus qemu-system-x86_64 qui va s’appuyer sur KVM pour optimiser l’accès au matériel.
3. Configuration du cluster LXD
Deux cas de figure conditionnent l’installation de LXD. Le premier cas est l’initialisation du cluster. C’est la configuration à réaliser sur le premier nœud. Le second cas est le recrutement du nœud dans un cluster existant. On doit l’appliquer sur tous les nœuds souhaitant rejoindre le cluster. Ces deux installations nécessitent l’installation du paquet snap lxd. Nous allons commencer par créer le premier nœud du cluster.
3.1 Initialisation du cluster
Nous décidons arbitrairement que le premier nœud sera node1. La première chose à faire est d’installer le paquet snap lxd :
L’outil en ligne de commandes pour piloter le cluster se nomme lxd. Pour initialiser la configuration, il faut invoquer le paramètre init. Une fois la commande invoquée, lxd vous posera quelques questions pour configurer le cluster.
La première question est de savoir si vous voulez fonctionner en mode cluster ou standalone (un seul nœud isolé). Ici, contrairement à [11] nous créons un cluster :
En cas de machine domiciliée sur plusieurs réseaux, lxd propose de choisir l’adresse à laquelle contacter le nœud pour les tâches d’administration. Nous n’avons qu’une seule adresse sur la machine, nous laissons donc le paramètre par défaut.
La question suivante est de savoir si nous rejoignions un cluster existant. Ici, nous configurons le premier nœud donc non.
Il faut ensuite définir le nom de la machine au sein du cluster. Nous laissons le paramètre par défaut.
Cette question propose de configurer un stockage local pour accueillir les conteneurs et machines virtuelles. Ici nous allons répondre oui et les questions suivantes vont nous permettre de le caractériser.
Ici, nous devons choisir le mécanisme de stockage. Nous avons le choix entre plusieurs stockages à portée locale : dir, lvm et btrfs. Le pilote dir est le plus simple. Il s’agit de stocker les machines virtuelles et conteneurs à plat sur le système de fichiers existant. Nous allons l’utiliser dans l’article, car c’est le format le plus simple pour aller voir ce que LXD stocke sur le disque. Le pilote LVM [12] permet de passer un VG (Volume Group) à LXD. Chaque conteneur ou machine virtuelle sera stocké sur un LV (Logical Volume). Un système de fichiers à la discrétion de l’utilisateur sera instancié sur le LV. Enfin, btrfs propose de créer un fichier bloc sur le système de fichiers existant (il est impossible de lui passer un périphérique bloc natif). Ce n’est pas très efficient en termes de performances, mais cela permet de profiter des fonctionnalités de btrfs. Nous choisissons donc dir :
LXD peut s’interfacer avec un système de fichiers distribué Ceph [13,14]. C’est ce qui est sous-entendu par la possibilité de s’attacher un volume distant.
Concernant le provisionnement, LXD propose de s’attacher à un serveur MaaS (Metal as a Service). MaaS est un système de déploiement automatique de serveurs physiques (le Metal de MaaS) s’appuyant, entre autres, sur DHCP / PXE / Bootp. Ici nous ne le souhaitons pas.
Nous passons à la configuration réseau. La première question est de savoir si nous nous attachons à un pont existant pour raccorder les machines virtuelles et conteneurs au réseau. Ici, nous répondons oui, car nous allons utiliser le pont configuré dans la partie 2.1.
Nous nommons explicitement le pont à utiliser, ici br0 :
Le dernier paramètre à configurer est de savoir si vous voulez que les images utilisées par un conteneur soient mises à jour entre deux instanciations.
Enfin, lxd init propose de faire un dump en YAML de la configuration réalisée :
On y retrouve bien tous les paramètres de configuration renseignés précédemment. Ce fichier vous permet de refaire l’installation en mode non interactif au cas où. Pour préparer le recrutement du second nœud node2, nous allons générer un jeton qu’il va falloir passer lors de son initialisation :
Passons au second nœud node2.
3.2 Recrutement d’un nœud
Nous allons ajouter un nœud dans notre cluster. À l’instar de la création du nœud initial, nous allons commencer par invoquer un init :
Et configurer le nœud en cluster :
Nous validons l’IP par défaut détectée par le configurateur de LXD :
C’est à cette étape que l’installation diffère par rapport à la section précédente. Cette fois-ci, nous indiquons rejoindre un cluster existant :
Et nous renseignons le jeton généré à la fin de la section précédente :
On valide nos choix :
On indique que nous utilisons le stockage local :
Et on fait un dump de la configuration en YAML :
Nous allons maintenant vérifier l’état du cluster. Peu importe le nœud sur lequel on lance les commandes, la configuration est distribuée. Commençons par vérifier l’état du cluster :
+-------+----------------------------+------------------+--------------+----------------+-------------+--------+-------------------+
| NAME | URL | ROLES | ARCHITECTURE | FAILURE DOMAIN | DESCRIPTION | STATE | MESSAGE |
+-------+----------------------------+------------------+--------------+----------------+-------------+--------+-------------------+
| node1 | https://192.168.45.11:8443 | database-leader | x86_64 | default | | ONLINE | Fully operational |
| | | database | | | | | |
+-------+----------------------------+------------------+--------------+----------------+-------------+--------+-------------------+
| node2 | https://192.168.45.12:8443 | database-standby | x86_64 | default | | ONLINE | Fully operational |
+-------+----------------------------+------------------+--------------+----------------+-------------+--------+-------------------+
Le stockage :
Le réseau :
Le cluster est opérationnel, nous pouvons créer nos premiers conteneurs et machines virtuelles.
4. Gestion des conteneurs et machines virtuelles
LXD vient avec un magasin d’images utilisables directement. Pour les lister, il faut utiliser la commande lxc image avec l’argument list. Nous mettons en forme l’affichage avec -c lat pour sélectionner l’alias (nom) de l’image, l’architecture et le type (machine virtuelle ou conteneur).
Les deux points après images sont importants, car si on ne les spécifie pas, lxc va lister les images locales et non celles du magasin. Lançons notre premier conteneur.
4.1 Lancement de conteneurs
Nous allons exécuter notre premier conteneur de la façon la plus simple possible. Nous commençons avec un conteneur Debian 12 récupéré depuis le magasin répondant au nom de container1.
Créons un second conteneur nommé container2 (quelle imagination !) :
Regardons comment se sont répartis nos conteneurs :
Ils ont bien été orchestrés sur node1 et node2. On retrouve leur système de fichiers en mode dir dans le répertoire suivant (pour node1) :
Cependant, un détail est frappant : les conteneurs ont chacun récupéré une adresse IP. En effet, un serveur DHCP est installé sur frontal et sert des adresses IP sur le domaine de diffusion Ethernet correspondant à intnet1. En effet, dans la section 2.1, nous avons vu que chacun des nœuds node1 et node2 embarque un pont intégrant leur interface réseau. À partir de ce moment-là, toutes les interfaces raccordées au pont sont également sur le domaine de diffusion Ethernet de intnet. Nous rappelons que le frontal embarque également un serveur DHCP qui sert l’étendue 192.168.45.100 à 192.168.45.200, ce qui correspond aux adresses récupérées par node1 et node2. Si nous examinons la composition du pont sur node1, nous avons la sortie suivante :
Nous voyons que le pont est composé de l’interface réseau « réelle » du nœud enp0s3 et d’une autre interface veth5204af45 correspondant à l’interface eth0 de container1. Connectons-nous au container1 pour voir si le réseau fonctionne :
Nous avons réalisé une première instanciation simple de deux conteneurs.
4.2 Gestion des ressources des conteneurs
Pour évaluer la gestion des ressources par nos conteneurs et machines virtuelles, nous allons installer l’utilitaire stress dans chacun d’eux. Installons-le dans container1, il faudra répéter cette installation pour chaque conteneur ou machine virtuelle instrumenté :
Reprenons notre conteneur container1. Lançons un stress qui met quatre CPU à 100% :
Regardons l’empreinte sur node1 avec un top :
Nous avons quatre processus qui prennent chacun 100% d’un CPU. Par défaut, LXD n’impose aucune limite aux ressources consommées par les conteneurs. Changeons la configuration du conteneur container1 pour le restreindre à deux CPU :
Et examinons la sortie du top :
Cette fois, les quatre processus utilisent chacun la moitié d’un CPU, soit 2 CPU au total. La limitation des ressources s’opère via les cgroups [15]. On notera qu’on peut limiter la mémoire de la même manière.
4.3 Lancement de machines virtuelles
Comme nous l’avons évoqué précédemment, il est également possible d’instancier des machines virtuelles. Pour créer des machines virtuelles, il faut d’abord installer les paquets suivants sur les nœuds du cluster LXD afin de disposer du couple KVM / QEMU :
Une fois ces paquets installés, nous stoppons et détruisons nos conteneurs :
Puis nous recréons deux machines virtuelles basées sur la même image que les conteneurs précédents :
Listons le résultat :
Cette fois, nous voyons que dans la colonne TYPE il s’agit bien de machines virtuelles et non plus de conteneurs. Listons les processus en exécution sur node1 :
J’attire l’attention du lecteur sur l’argument suivant : -cpu host,hv_passthrough qui illustre l’explication donnée dans la section 2.4. C’est ici qu’intervient KVM. QEMU indique à la machine virtuelle d’accéder directement au CPU via KVM et non à une émulation qu’il lui présenterait.
4.4 Gestion des ressources des machines virtuelles
À l’instar des conteneurs, il faut être attentif à l’utilisation des ressources par la machine virtuelle. Lançons deux processus à l'intérieur de notre machine virtuelle qui mettent un cœur à 100% :
Regardons le résultat dans la machine virtuelle avec top :
Nous avons deux processus utilisant chacun environ 50% du processeur. Et effectivement, LXD n’a alloué qu’un seul CPU à notre machine virtuelle :
Sur la machine hôte, nous voyons que le processus utilise environ 100% du CPU, soit un cœur complet :
Relançons notre machine virtuelle en indiquant l’utilisation de deux CPU :
Lançons le même stress :
Nous avons bien deux processus utilisant environ 100% du CPU, c'est-à-dire deux cœurs. En effet, cette fois-ci LXD a dédié deux cœurs à la machine virtuelle :
Regardons à nouveau l’utilisation du CPU sur l’hôte :
Le processus qemu-system-x86 utilise bien 200% du CPU c'est-à-dire deux cœurs. Ici c’est donc le problème inverse des conteneurs, par défaut LXD ne met qu’un seul cœur aux machines virtuelles et limits.cpu va nous servir à monter cette limite.
Conclusion
Pour conclure sur LXD, nous pouvons dire que cet orchestrateur est une alternative très intéressante aux produits un peu plus lourds cités au début de l’article. LXD implémente un orchestrateur dont les fonctionnalités sont directement liées aux briques présentes sur la machine exécutant nos conteneurs et nos machines virtuelles. Par exemple, si un système de fichiers ne supporte pas les snapshots, alors LXD ne proposera pas l’option. De même, si KVM n’est pas installé sur les nœuds hôtes, nous ne pourrons pas exécuter de machines virtuelles. Cette forte adhérence au système sous-jacent fait de LXD un orchestrateur extrêmement léger en termes d’administration et d’utilisation, pourvu que notre besoin rentre dans son périmètre fonctionnel.
Références
[1] D. Gourmel, « Proxmox : vis ma vie d’éleveur de machines virtuelles », Linux Pratique n°134, novembre 2022 : https://connect.ed-diamond.com/linux-pratique/lp-134/proxmox-vis-ma-vie-d-eleveur-de-machines-virtuelles
[2] N. Greneche, « Monter sa plateforme Cloud avec OpenNebula », Linux Pratique n°128, novembre 2021 : https://connect.ed-diamond.com/linux-pratique/lp-128/monter-sa-plateforme-cloud-avec-opennebula
[3] N. Greneche, « Libre-service de machines virtuelles avec OpenNebula », Linux Pratique n°130, mars 2022 : https://connect.ed-diamond.com/linux-pratique/lp-130/libre-service-de-machines-virtuelles-avec-opennebula
[4] https://access.redhat.com/documentation/fr-fr/red_hat_enterprise_linux/9/html/using_selinux/index
[5] E. Gaspar, « Isolez vos processus grâce à AppArmor », Linux Pratique n°113, mai 2019 :
https://connect.ed-diamond.com/Linux-Pratique/lp-113/isolez-vos-processus-grace-a-apparmor
[6] F. Maury, « Namespaces et seccomp BPF : un zoom sur la conteneurisation Linux », MISC n°102, mars 2019 : https://connect.ed-diamond.com/MISC/misc-102/namespaces-et-seccomp-bpf-un-zoom-sur-la-conteneurisation-linux
[7] R. Koucha, « Contrôle des processus avec les cgroups », GNU/Linux Magazine n°141, septembre 2011 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-141/controle-des-processus-avec-les-cgroups
[8] R. Koucha, « Les namespaces ou l’art de se démultiplier », GNU/Linux Magazine n°239, juillet 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-239/les-namespaces-ou-l-art-de-se-demultiplier
[9] R. Koucha, « Les structures de données des namespaces dans le noyau », GNU/Linux Magazine n°243, décembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-243/les-structures-de-donnees-des-namespaces-dans-le-noyau
[10] R. Koucha, « Le fonctionnement des namespaces dans le noyau », GNU/Linux Magazine n°245, février 2021 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-245/le-fonctionnement-des-namespaces-dans-le-noyau
[11] N. Greneche, « La mise en conteneur d’une application ou d’un service avec LXD », Linux Pratique Hors-Série n°45, juin 2019 : https://connect.ed-diamond.com/Linux-Pratique/lphs-045/la-mise-en-conteneur-d-une-application-ou-d-un-service-avec-lxd
[12] S. Maccagnoni-Munch, « Un stockage plus souple avec Logical Volume Manager », GNU/Linux Magazine Hors-Série n°72, mai 2014 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmfhs-072/un-stockage-plus-souple-avec-logical-volume-manager
[13] O. Delhomme, « Présentation et installation du système de stockage réparti Ceph », GNU/Linux Magazine n°179, février 2015 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-179/presentation-et-installation-du-systeme-de-stockage-reparti-ceph
[14] O. Delhomme, « Mise en œuvre de Ceph », GNU/Linux Magazine n°180, mars 2015 :
https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-180/Mise-en-aeuvre-de-Ceph
[15] J. Delamarche, « Contrôle des processus avec les cgroups », GNU/Linux Magazine n°141, septembre 2011 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-141/controle-des-processus-avec-les-cgroups



