

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Après la présentation des structures de données supportant les namespaces, ce nouvel opus se consacre à la partie immergée dans le noyau des appels système.
Nous continuons notre balade hors des sentiers battus dans le code source de Linux 5.3.0 afin de nous pencher sur le fonctionnement des appels système dans le noyau.
Le code de cet article est disponible sur http://www.rkoucha.fr/tech_corner/linux_namespaces/linux_namespaces.tgz.
1. NSFS
Le Virtual File system Switch (VFS) [1] de Linux est une couche d’abstraction qui présente à l’utilisateur un ensemble d’opérations génériques (par exemple open(), close(), ioctl(), etc.) en masquant les spécificités des différents types de systèmes de fichiers [2]. Le NameSpace File System (NSFS) est l’un d’eux et il est dédié aux namespaces [3].
1.1 Interactions avec PROCFS
NSFS gère plus précisément les cibles des liens symboliques du répertoire /proc/<pid>/ns. Son code source se trouve dans fs/nsfs.c. Il n’est pas monté explicitement par l’utilisateur, mais de manière interne lors de l’initialisation du noyau (fonction nsfs_init() étiquetée avec __init) :
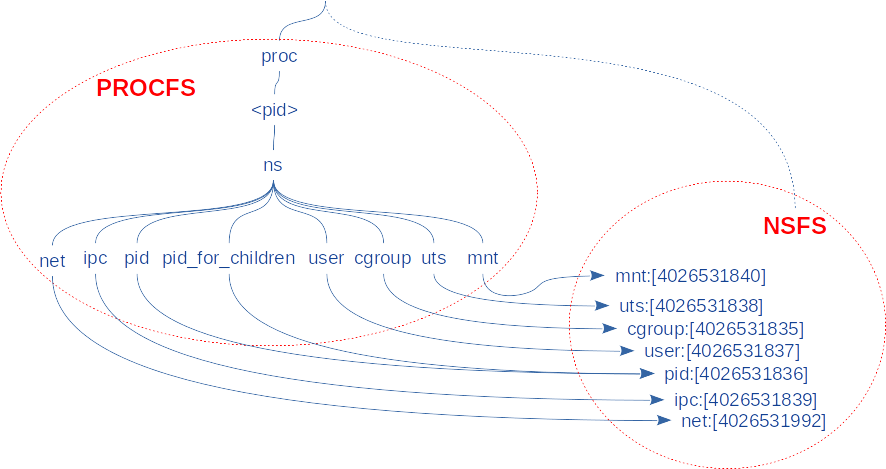
La figure 1 schématise la gestion des fichiers relatifs aux namespaces à travers PROCFS d’une part (les liens symboliques) et NSFS d’autre part (cibles des liens symboliques).
Notre programme linfo prend en paramètre le chemin d’un lien symbolique et affiche des informations sur le lien et sa cible, en s’appuyant respectivement sur les appels système lstat() et stat() :
Lancé avec le lien sur le net_ns associé au shell courant, linfo affiche d’abord les informations retournées par procfs (le lien symbolique) et les informations retournées par NSFS (la cible du lien) :
Pour la cible, on retrouve bien le numéro d’inode affiché dans le nom du fichier par la commande ls dans le répertoire :
Notre programme fsinfo reçoit en paramètre le nom d’un fichier et s’appuie sur l’appel système statfs() pour afficher des informations à propos de son système de fichiers :
Pour la cible d’un lien symbolique sur un namespace, il retourne bien le type NSFS :
Pour le répertoire où se trouve ce même lien, c’est le type PROCFS :
Sur l’appel système readlink() (utilisé dans le programme linfo pour récupérer la cible du lien symbolique) dans /proc/<pid>/ns, le système de fichiers PROCFS appelle le service interne ns_get_name() de NSFS pour retourner le nom des cibles (cf. fonction proc_ns_readlink() dans fs/proc/namespaces.c) :
Définie dans le fichier fs/nsfs.c, la fonction ns_get_name() construit le nom de la cible avec les informations du descripteur de namespace (c’est-à-dire les champs name, real_name et inum de la structure ns_common vue dans l’article précédent dans GNU/Linux Magazine no243) :
1.2 Les inodes
Lorsque la cible d’un lien symbolique dans /proc/<pid>/ns est demandée, l’opération proc_ns_get_link() dans fs/proc/namespace.c est déclenchée. Cette dernière appelle la fonction ns_get_path() dans fs/nsfs.c qui finit par appeler __ns_get_path() pour allouer l’inode et le dentry associé :
L’inode ainsi alloué est présenté en figure 2.
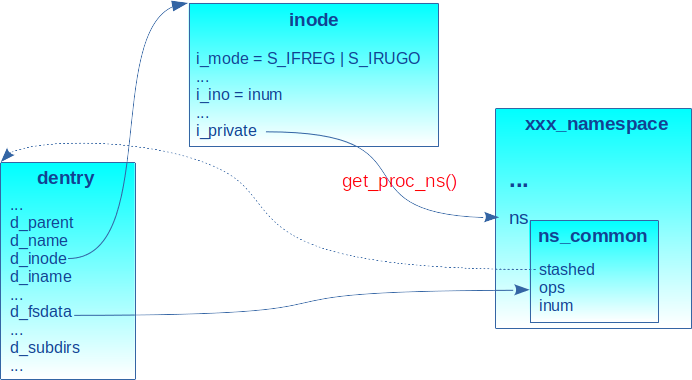
Le champ ns de type ns_common dans le descripteur de namespace est pointé par le champ i_private de la structure inode. Le numéro d’inode stocké dans le champ inum du namespace lors de son allocation est assigné au champ i_ino. Le champ stashed de ns_common pointe sur la structure dentry liée à l’inode. Ce champ permet de savoir si l’inode est associé à un dentry ou pas, car dans certaines situations où les ressources mémoire se raréfient, le VFS peut faire de « l’élagage » (c.-à-d. « prune » en anglais) dans le cache dentry, de sorte à libérer des ressources. Dans ce cas, cela aboutit à l’appel à la fonction ns_prune_dentry() dans fs/nsfs.c qui marque le champ à 0 :
1.3 Du descripteur de fichier au namespace
L’appel système open() sur un lien symbolique de namespace aboutit via les fonctions précédentes à l’allocation d’une structure dentry, de l’inode et la structure file. Un descripteur de fichier est retourné côté espace utilisateur.
Ensuite, avec les différentes fonctions de translation du VFS, le descripteur de fichier passé aux appels système, tels que ioctl() ou setns(), permet de retrouver la structure file avec le service proc_ns_fget() défini dans fs/nsfs.c :
Le service file_inode() du fichier include/linux/fs.h retrouve l’inode à partir de la structure file :
Le service get_proc_ns() du fichier include/linux/proc_ns.h retrouve un namespace à partir d’un pointeur sur une structure inode :
Le champ i_private de l’inode pointe sur la structure du namespace et les opérations associées comme indiqué en figure 2.
1.4 Les montages
Un namespace est désalloué par le noyau à partir du moment où il n’est plus référencé (valeur 0 pour le compteur kref ou count vu dans l’article précédent). En général, il n’est plus référencé lorsqu’il n’y a plus aucune tâche associée. Cependant, comme on l’a vu avec la commande ip par exemple, il peut s’avérer nécessaire de garder un namespace actif, même s’il n’a plus de tâche associée. Garder une tâche active liée au namespace est une solution, mais ce n’est pas très économique en termes de ressources de mémoire et CPU. L’astuce consiste à monter le fichier du namespace sur un autre fichier dans l’arborescence. Ainsi, tant qu’il est monté, le namespace reste référencé [4]. Reprenons l’exemple de création d’un net_ns avec la commande ip :
La commande a appelé unshare(CLONE_NEWNET) pour créer un nouveau net_ns. Une fois créée, la seule tâche associée au net_ns est la commande ip elle-même. Pour que ce net_ns ne disparaisse pas à la fin de la commande (c.-à-d. lorsqu’elle rend la main à l’opérateur), l’astuce consiste à monter /proc/self/ns/net (c.-à-d. la cible de ce lien symbolique !) sur /run/netns/newnet (c.-à-d. le nom passé en paramètre) afin de laisser une référence sur le net_ns. Le fichier mountinfo montre le type de système de fichiers NSFS et le nom du fichier cible.
Ainsi, la commande ip pourra accéder de nouveau au net_ns pour y exécuter des commandes ou y migrer des interfaces réseau. Listons les net_ns créés :
Listons les interfaces réseau dans le net_ns à l’aide de la commande ip link list associée à ce net_ns. On y trouve uniquement l’interface loopback, car c’est la seule interface disponible dans tout nouveau net_ns. On remarquera qu’elle a l’indice 1 comme nous l’avions mentionné dans l’article précédent :
2. Les appels système
2.1 Les identifiants
Un certain nombre de fonctions et macros « helpers » ont été définies en interne :
- pid_nr() : identifiant de processus (global) vu du pid_ns initial ;
- pid_vnr() : identifiant de processus (virtuel) vu du pid_ns courant ;
- pid_nr_ns() : identifiant de processus (virtuel) vu du pid_ns passé en paramètre ;
- pid_<xid>_nr() : identifiant (global) vu du namespace initial ;
- pid_<xid>_vnr() : identifiant (virtuel) vu du namespace courant ;
- pid_<xid>_nr_ns() : identifiant (virtuel) vu du namespace passé en paramètre.
Ces dernières sont largement mises à contribution dans les appels système tels que getpid(), gettid(), getgid(), getuid() et autres afin de les virtualiser (c.-à-d. leur faire retourner un résultat correspondant aux namespaces auxquels le processus appelant est associé).
2.2 ioctl
Le point d’entrée ioctl du système de fichiers NSFS est la fonction ns_ioctl() dans le fichier fs/nsfs.c. Le début de la fonction retrouve l’inode à partir de la structure file passée en paramètre. Puis la structure ns_common du namespace cible est retrouvée (variable locale ns) depuis l’inode, comme on l’a vu précédemment (cf. figure 2) :
Dans l’article précédent, nous avons vu que le champ ops de la structure ns_common contient des informations et opérations communes à tous les namespaces. Elles vont être exploitées dans la suite.
Comme souvent avec les fonctions ioctl(), l’algorithme consiste en un « switch/case » pour chaque opération supportée :
L’opération NS_GET_USERNS déclenche le point d’entrée owner afin de retourner le descripteur de fichiers sur le user_ns propriétaire :
L’opération NS_GET_PARENT déclenche le point d’entrée get_parent afin de retourner le descripteur de fichier sur le namespace parent. Le retour erreur EINVAL est pour les namespaces non hiérarchiques (c.-à-d. autres que user_ns et pid_ns). Leur champ get_parent est NULL :
L’opération NS_GET_TYPE retourne la valeur du champ type (c.-à-d. un drapeau CLONE_NEWXXX) :
L’opération NS_GET_OWNER_UID ne s’applique qu’aux user_ns (sous peine de retour EINVAL) et retourne l’identifiant d’utilisateur d’un user_ns :
Un mauvais identifiant d’opération tombe sous le coup du cas « default » pour retourner ENOTTY. Ce code d’erreur peut prêter à confusion, car dans le cas où les paramètres n’ont pas les valeurs attendues, on utilise généralement EINVAL. Mais c’est devenu une règle dans les ioctls des drivers et systèmes de fichiers afin de signifier que la commande passée n’est pas connue [5] :
On comprend maintenant la signification du nom du fichier d’en-tête <linux/nsfs.h> nécessaire à l’utilisation de ioctl() côté espace utilisateur :
L’opération non documentée SIOCGSKNS [6] qui retourne un descripteur de fichier sur le net_ns auquel une socket est associée est gérée dans net/socket.c :
De la structure file est déduit le descripteur de socket duquel on récupère une référence sur le net_ns associé. Ensuite, la fonction vérifie que l’appelant a bien la capacité CAP_NET_ADMIN dans le user_ns propriétaire du net_ns avec le service interne ns_capable() [7]. Enfin, la fonction open_relelated_ns() de fs/nsfs.c est invoquée pour retourner un descripteur de fichier sur le net_ns.
2.3 clone
Le fichier kernel/fork.c contient l’implémentation de l’appel système clone().
La fonction clone() appelle copy_process() à partir de _do_fork() pour dupliquer la tâche appelante :
La fonction interdit la combinaison des drapeaux CLONE_NEWNS et CLONE_FS, car deux processus évoluant dans des mount_ns différents ne peuvent pas partager le répertoire racine ou le répertoire courant. Elle interdit aussi la combinaison des drapeaux CLONE_NEWUSER et CLONE_FS, car deux processus évoluant dans des user_ns différents ne peuvent pas partager les mêmes informations dans le système de fichiers pour raisons de sécurité :
À moins que le drapeau CLONE_NEWUSER ne soit passé, la fonction ne peut être exécutée qu’à la condition où l’utilisateur a la capacité CAP_SYS_ADMIN. Nous verrons la raison de cette exception dans l’article dédié au user_ns :
Pour des raisons de sécurité, tous les threads d’un processus doivent résider dans le même user_ns et pid_ns. Par conséquent, la fonction interdit la création d’un thread (drapeau CLONE_THREAD passé par pthread_create() de la librairie C) dans un nouveau user_ns ou pid_ns. Cela comprend aussi le cas où un processus fait un premier appel à clone(CLONE_NEWPID) pour créer un premier fils dans un nouveau pid_ns, puis appelle pthread_create() pour créer un thread (sans ce contrôle, le nouveau thread s’exécuterait aussi dans le nouveau pid_ns, bien que CLONE_NEWPID n’est pas passé).
Ensuite, parmi les nombreuses autres actions, il y a la copie (héritage) des informations de sécurité (« credentials ») via copy_creds() et des namespaces du processus appelant via copy_namespaces(). La copie des informations de sécurité donne toutes les capacités au nouveau processus si le drapeau CLONE_NEWUSER est passé (le nouvel user_ns associé est d’ailleurs créé à ce moment-là). De plus, cela nous permet de souligner que dès lors que le drapeau CLONE_NEWUSER est passé, il est traité en premier ! Nous verrons l’importance de ces points dans l’article dédié aux user_ns :
Enfin, la fonction alloc_pid() est appelée pour allouer une structure pid afin de créer et mémoriser l’identifiant de la nouvelle tâche dans tous les pid_ns en remontant jusqu’à la racine. On notera que c’est ici que le pointeur pid_ns_for_children du nsproxy est utilisé pour référencer le pid_ns. Ce dernier pointe sur le pid_ns de la tâche appelante (le père) sauf si le drapeau CLONE_NEWPID a été passé, auquel cas il pointe sur le pid_ns nouvellement alloué :
Détaillons la fonction copy_namespace() définie dans kernel/nsproxy.c. Si aucun des drapeaux CLONE_NEWXXX n’est passé, cela signifie que le processus créé hérite des namespaces de l’appelant (la variable locale old_ns pointe sur le nsproxy de la tâche appelante). Dans ce cas, on n’alloue pas un nouveau nsproxy, mais la nouvelle tâche va pointer sur le nsproxy de son père en incrémentant son compteur de références (on a vu cela dans l’article précédent) :
Si au moins un des drapeaux CLONE_NEWXXX est passé, alors on va obligatoirement allouer une nouvelle structure nsproxy. Les capacités du processus appelant sont de nouveau vérifiées (Rappel : si le drapeau CLONE_NEWUSER a été passé, toutes les capacités sont activées) :
La combinaison des drapeaux CLONE_NEWIPC et CLONE_SYSVSEM n’est pas autorisée, car dans un nouvel ipc_ns, les sémaphores de l’appelant ne sont plus accessibles et par conséquent, il n’est pas possible de partager la liste des semadj (mécanisme qui sera détaillé dans un prochain article dédié aux ipc_ns) :
Ensuite est appelée la fonction create_new_namespaces() située dans le même fichier. Cette fonction alloue une nouvelle structure nsproxy. Pour chaque drapeau CLONE_NEWXXX passé en argument à clone(), le namespace associé est alloué et le pointeur associé dans le nsproxy pointe dessus. Pour les autres namespaces dont les drapeaux ne sont pas spécifiés, il n’y a pas d’allocation de nouveaux namespaces, mais seulement une référence au namespace de l’appelant (avec incrémentation du compteur de références) et le pointeur correspondant du nsproxy pointe dessus :
Enfin, le nsproxy ainsi alloué est assigné au champ nsproxy de la nouvelle tâche :
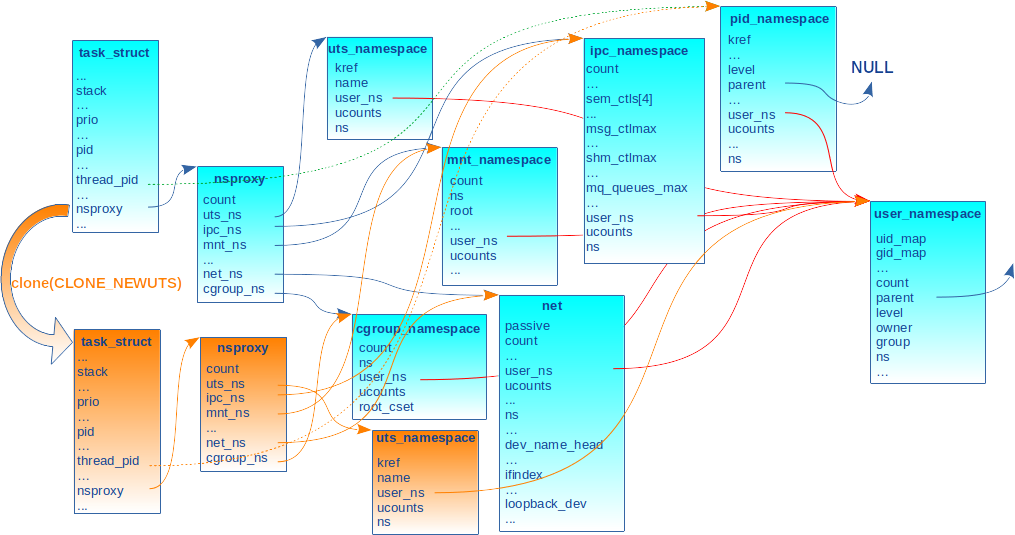
La figure 3 schématise l’opération clone(CLONE_NEWUTS). Les actions et structures mises en œuvre pour la nouvelle tâche sont en orange. Les pointeurs du nsproxy nouvellement alloués sont identiques à ceux du processus père, sauf pour l’uts_ns qui pointe sur le descripteur d’uts_ns nouvellement alloué. Pour des raisons de lisibilité, nous n’avons pas représenté la structure pid.
2.4 unshare
Le fichier kernel/fork.c contient l’implémentation de l’appel système unshare() :
Tout le travail est fait dans la fonction ksys_unshare() située dans le même fichier. unshare() accepte bon nombre de drapeaux en paramètres. Nous nous concentrerons uniquement sur ceux concernant les namespaces. La fonction commence par positionner implicitement les drapeaux CLONE_THREAD et CLONE_FS si CLONE_NEWUSER est passé :
Le drapeau CLONE_FS est aussi implicitement positionné s’il y a création d’un nouveau mount_ns :
Comme pour clone() vu précédemment, si CLONE_NEWUSER n’est pas passé, alors la fonction retourne en erreur (EPERM) si l’appelant n’a pas la capacité CAP_SYS_ADMIN. Lors de l’étude détaillée des user_ns, nous verrons pourquoi il est important d’autoriser la fonction lorsque la création d’un user_ns est demandée :
Un certain nombre de contrôles de cohérence et de validité sur les drapeaux est effectué :
Si le drapeau CLONE_NEWUSER est passé, comme précédemment souligné pour clone(), il est traité en premier en allouant un nouvel user_ns (appel à unshare_userns()), puis les autres namespaces sont créés conformément aux autres drapeaux passés en paramètres (appel à unshare_nsproxy_namespaces() qui appelle create_new_namespaces() vue avec clone()). On notera que si CLONE_NEWIPC est passé, un nouveau système de fichiers mqueue (généralement monté sur /dev/mqueue côté espace utilisateur) est monté en interne pour le nouvel ipc_ns. L’ancien est « oublié ». En d’autres termes, les noms des queues de message POSIX créés par la tâche courante ne seront plus accessibles pour une destruction dans le système de fichiers, car la tâche ne les verra plus à partir de son nouvel ipc_ns. Par contre, les descripteurs de fichiers actuellement ouverts sur les queues de message permettent toujours d’y accéder pour émettre et recevoir des messages ! On reverra cela dans un exemple lors de l’étude détaillée des ipc_ns.
Si le drapeau CLONE_NEWIPC a été passé (la variable locale do_sysvsem vaut 1), la fonction exit_sem() est appelée pour mettre en œuvre le mécanisme semadj afin d’éviter les interblocages en annulant les opérations en cours sur les sémaphores. Nous reviendrons sur ce sujet dans le paragraphe dédié à l’ipc_ns.
Toujours pour le drapeau CLONE_NEWIPC, exit_shm() est appelée pour les identifiants de segments de mémoire partagée. Les segments créés par la tâche courante sont marqués orphelins (c.-à-d. l’identifiant de tâche créatrice est effacé afin de pouvoir les détruire plus tard dans l’ipc_ns que l’on quitte). Puis la liste des segments créés est mise à 0 pour la tâche courante. De plus, si le fichier /proc/sys/kernel/shm_rmid_forced est différent de 0, alors les segments créés par la tâche et non encore attachés (c.-à-d. non mappés par au moins une tâche) sont détruits.
Ensuite, on met à jour le champ nsproxy de la tâche appelante avec le nouveau nsproxy alloué, si au moins un des drapeaux CLONE_NEWXXX autre que CLONE_NEWUSER est passé en paramètre à l’aide de switch_task_namespaces(). Cette dernière décrémente le compteur de référence sur le nsproxy courant et sa désallocation si le compteur atteint 0 :
Enfin, si CLONE_NEWUSER a été passé, le nouveau user_ns est « attaché » à la tâche courante :
La figure 4 schématise l’opération unshare(CLONE_NEWUTS). Les actions et structures mises en œuvre sont en orange.

On notera pour conclure que dans le cas de la création d’un nouveau pid_ns (drapeau CLONE_NEWPID), l’appelant n’est pas associé au nouveau pid_ns. Le champ pid_ns_for_children de son nsproxy est modifié pour le référencer afin qu’un prochain appel à clone() (sans le drapeau CLONE_NEWPID) s’appuie dessus pour y associer la nouvelle tâche. Dans un prochain article, nous expliquerons la raison de ce fonctionnement particulier pour le drapeau CLONE_NEWPID.
2.5 setns
L’appel système setns() est défini dans le fichier kernel/nsproxy.c. Le descripteur de fichier fd passé en paramètre permet de retrouver la référence sur le descripteur du namespace cible, comme on l’a déjà vu (variable locale ns). Si le paramètre nstype est différent de 0, on vérifie qu’il correspond bien au type du namespace lié au descripteur de fichier (sinon, l’erreur EINVAL est retournée) :
La fonction create_new_namespaces() déjà vue lors de l’étude de clone() est alors appelée pour allouer une nouvelle structure nsproxy. Le premier paramètre « flags » étant à 0, ses pointeurs vont référencer les mêmes structures que le nsproxy de la tâche appelante, mais leur compteur de références est incrémenté.
Puis la fonction install() du namespace cible (c.-à-d. correspondant au descripteur de fichier passé en paramètre) est appelée. Cette fonction vérifie la présence de la capacité CAP_SYS_ADMIN sous peine de retourner l’erreur EPERM, décrémente le compteur de références sur le namespace source (celui dans lequel l’appelant se trouve), effectue quelques actions d’intégrité dans le namespace source, incrémente le compteur de références sur le namespace cible et fait pointer le nouveau nsproxy dessus :
Parmi les opérations d’intégrité, on peut citer l’exemple où le namespace cible serait un ipc_ns : le mécanisme semadj est déclenché pour l’ipc_ns source avec un appel à exit_sem(). Dans le cas où le namespace cible est un user_ns, on retourne en erreur (EINVAL) si l’appelant est une tâche d’un processus multithreadé (car tous les threads d’un processus doivent être dans le même user_ns).
Enfin, le champ nsproxy de la tâche courante est remplacé pour laisser place à celui que l’on vient de créer avec l’un de ses pointeurs référençant le namespace cible. L’ancien nsproxy est libéré si la décrémentation de son compteur de références aboutit à la valeur 0 :
En conclusion, la tâche appelante se retrouve avec un nouveau nsproxy identique au précédent, sauf pour le pointeur associé au namespace cible. Cette opération est identique à l’opération unshare(), car elle alloue un nouveau nsproxy. Mais unshare() crée un nouveau namespace, alors que setns() fait pointer son nsproxy sur un namespace existant.
Conclusion
Ainsi s’achève notre plongée dans le noyau, pour observer de près l’implémentation des namespaces. Le but n’était pas de comprendre tous les détails, mais plutôt de donner des clés à qui voudrait approfondir le sujet ou comprendre certaines limitations que nous évoquerons par la suite.
À partir du prochain article, nous repasserons en espace utilisateur pour commencer notre passage en revue de chaque namespace de manière pratique, à l’aide de programmes d’exemples.
Références
[1] Overview of the Linux Virtual File System : https://www.kernel.org/doc/Documentation/filesystems/vfs.txt
[2] Anatomy of the Linux Virtual File System switch : https://developer.ibm.com/technologies/linux/tutorials/l-virtual-filesystem-switch/
[3] The namespace file system (NSFS) : https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=e149ed2b805fefdccf7ccdfc19eca22fdd4514ac
[4] Namespace file descriptors : https://lwn.net/Articles/407495/
[5] J. CORBET, A. RUBINI, G. KROAH-HARTMAN, « Linux Device Drivers (3rd Edition) », O'Reilly, February 2005.
[6] Add an ioctl to get a socket network namespace : https://lore.kernel.org/patchwork/patch/728774/
[7] Linux capabilities support for user namespaces : https://lwn.net/Articles/420624/



