

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
IP Virtual Server (IPVS) est un équilibreur de charge agissant au niveau 4 du modèle OSI. Il est implémenté sous forme d’un module noyau s’appuyant sur le framework Netfilter, ce qui le rend efficace sur l’équilibrage des services par rapport à leurs ports TCP/UDP, mais totalement agnostique aux protocoles applicatifs transportés (LDAP, HTTP, etc.).
Un service réseau est un processus à l’écoute sur une interface attendant des requêtes depuis des clients distants. Un exemple typique est le serveur web. Il se lie aux ports TCP/80 pour accepter le trafic en clair (HTTP) et TCP/443 pour le trafic chiffré (HTTPS). Ces services réseaux étaient historiquement localisés sur une machine serveur physique. Ces serveurs physiques ont peu à peu laissé la place aux machines virtuelles. Cette évolution a grandement rationalisé l’attribution des ressources de machines de plus en plus puissantes, donc disproportionnées par rapport à l’utilisation que pourrait en faire un service réseau isolé. Enfin, la tendance actuelle est la conteneurisation pour encore redécouper les machines virtuelles si besoin (on peut évidemment également faire tourner des conteneurs sur des machines physiques directement). Pour ce qui nous intéresse, cette flexibilité dans l’attribution des ressources favorise grandement le placement de plusieurs instances du même service réseau pour en accroître la disponibilité. Pour répartir les requêtes entre ces différentes instances du service et vérifier leur disponibilité, il faut mettre en place un équilibreur de charge en frontal de ceux-ci. On parle alors d’instances de services équilibrés.
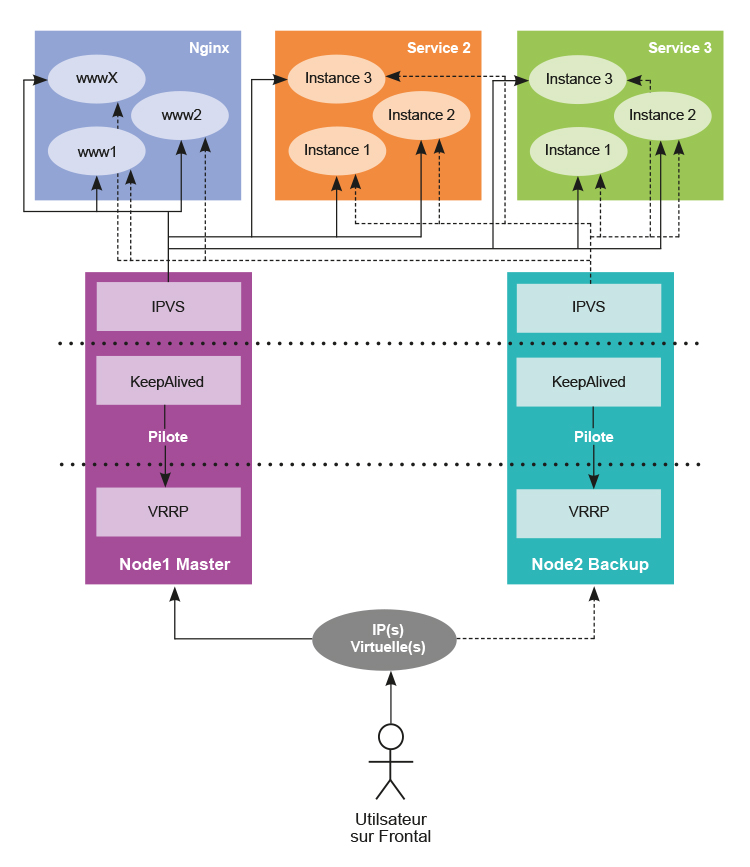
IPVS (IP Virtual Server) est un équilibreur de charge niveau 4, ce qui correspond à la couche transport du modèle OSI. La couche 3, réseau, s’occupe d’acheminer le paquet sur la bonne interface réseau avec, évidemment, le concours des couches inférieures : liaison (2) et physique (1). La couche transport démultiplexe le trafic reçu et livre le paquet au bon processus en écoute sur le réseau en l’adressant par le port avec lequel il s’est lié à l’interface. Le rôle d’IPVS est d’organiser les instances de services réseaux en groupes et de rediriger le trafic du client vers une des instances du service demandé. La disponibilité de l’équilibreur de charge lui-même est donc critique, car la disponibilité d’un ou plusieurs services dépendent de lui. En général, ces systèmes d’équilibrage sont redondés.
La redondance d’un équilibreur de charge fonctionne sur le principe de l’IP virtuelle. Les équilibreurs de charge vont se « partager » une adresse IP virtuelle. Un équilibreur de charge sera maître du lien tandis que les autres seront positionnés en secours. Lorsque le maître tombe, un des secours prend le relai (par ordre de priorité). Le protocole le plus répandu de gestion d’IP virtuelle est VRRP (Virtual Router Redudancy Protocol). Il s’appuie sur ARP pour annoncer l’IP virtuelle sur le lien maître ou un des liens de secours. Je vais rentrer dans le détail du fonctionnement de ces dispositifs en les prenant un par un.
1. Redondance de l’équilibreur de charge
Dans cette section, nous allons voir comment mettre en place une redondance au niveau de l’équilibreur de charge. Nous allons traverser les couches de la plus basse à la plus haute en commençant par le protocole ARP qui va être manipulé par VRRP pour associer l’IP virtuelle à l’équilibreur de charge maître ou en secours. Nous manipulerons une IP virtuelle avec le service vrrpd qui implémente VRRP en espace utilisateur et nous verrons le comportement avec ARP. Enfin, nous préparerons le terrain pour la seconde partie de l’article dédiée à IPVS en installant un service keepalived qui gère l’IP virtuelle, mais propose aussi de surveiller les instances de services redondées pour renseigner IPVS en temps réel.
Notre laboratoire se compose de trois machines. Une machine nommée frontal en 172.16.0.1 avec l’adresse MAC 08:00:27:f4:11:cd, une machine nommée node1 en 172.16.0.11 avec l’adresse MAC 08:00:27:22:36:5a qui sera maître sur le lien VRRP et une machine nommée node2 en 172.16.0.12 avec l’adresse MAC 08:00:27:42:c9:c0 qui sera secours sur le lien VRRP. L’IP virtuelle sera en 172.16.0.13. J’ai choisi de mettre toutes les machines sur le même réseau IP pour éviter de surcharger l’article avec les notions de routage.
1.1 ARP
ARP (Address Resolution Protocol) est le protocole qui fait le lien entre la couche 2 (liaison) et la couche 3. Les machines qui sont sur un même segment LAN (Local Area Network), aussi appelé domaine de broadcast Ethernet, commutent les trames encapsulant les paquets IP grâce aux adresses MAC. Un segment LAN peut être défini : 1) physiquement par un commutateur voire des commutateurs cascadés les uns avec les autres ou 2) logiquement par des VLAN (Virtual LAN) [1]. MAC signifie Media Access Control, c’est-à-dire que c’est une adresse d’accès au media (sous-entendu physique). Ici, le media est l’interface physique connectée au commutateur avec un câble. Une fois l’interface physique localisée, le paquet IP est extrait de la trame Ethernet par le noyau (précisément la pile réseau) du système destinataire et livré à la bonne interface. Voyons avec un exemple, où la machine 172.16.0.1 (frontal) envoie une requête ICMP echo request à la machine 172.16.0.11 (node1). Nous lançons d’abord une capture sur 172.16.0.1 avec tcpdump qui ne récupère que le trafic ARP :
Dans une autre fenêtre, lançons les requêtes ICMP avec l’utilitaire ping :
On constate que le paquet IP est bien livré, car notre « echo request » est bien acquitté par un « echo reply ». Or si cela fonctionne, c’est que les trames contenant les paquets ont bien été commutées et donc que les machines se sont trouvées au niveau des adresses MAC. Or, nous n’avons pas précisé d’adresses MAC. C’est ici qu’ARP intervient. Revenons sur la fenêtre du tcpdump :
Deux lignes sont apparues. La première est une requête « who-has » (qui possède ?) envoyée par 08:00:27:f4:11:cd qui est l’adresse MAC de 172.16.0.1 à destination de toutes les machines du segment LAN (en gros, toutes les machines connectées au commutateur). En effet, une trame envoyée à l’adresse MAC de broadcast ff:ff:ff:ff:ff:ff touche toutes les machines connectées au segment LAN. Cette requête demande quelle adresse MAC est derrière 172.16.0.11 et d’envoyer la réponse à 172.16.0.1. La deuxième ligne est la réponse en question. Elle vient de 08:00:27:22:36:5a qui est l’adresse MAC de 172.16.0.11 et elle est adressée à 08:00:27:f4:11:cd qui est bien l’adresse MAC de 172.16.0.1. La réponse est un « is-at » (localisée à) 08:00:27:22:36:5a (adresse MAC de 172.16.0.11). On notera que peu importe le nombre de requêtes ICMP qu’on peut envoyer, une fois l’échange who-has / is-at effectué, tcpdump ne bouge plus. La raison est que les systèmes intègrent un cache ARP que l’ont peut simplement consulter avec la commande nommée arp. Par exemple sur 172.16.0.1 :
On y retrouve bien la machine 172.16.0.11 avec son adresse MAC 08:00:27:22:36:5a. En conséquence, une adresse IP virtuelle est une adresse qui se balade entre plusieurs adresses MAC. Nous allons simuler une permutation d’adresse MAC pour une IP en forgeant manuellement une trame « gratuitous ARP ».
Une trame « gratuitous ARP » est une réponse ARP sans qu’aucune requête n’ait été formulée. Nous allons utiliser Scapy [2] pour forger une telle requête. Disons que nous voulions que la machine node2 en 172.16.0.12 porte l’IP 172.16.0.11. Il s’agit juste ici de mettre à jour le cache ARP des machines pour que les trames destinées à 172.16.0.11 n’arrivent plus sur node1 possédant l’adresse MAC 08:00:27:22:36:5a, mais sur node2 possédant l’adresse MAC suivante :
Affichons le cache ARP de la machine frontal :
Il possède l’IP 172.16.0.11 qui pointe sur l’adresse MAC 08:00:27:22:36:5a qui est bien node1. Depuis une machine quelconque du segment LAN (par exemple node2), utilisons Scapy :
Les caractéristiques d’une telle trame sont qu’au niveau Ethernet son adresse MAC de destination est ff:ff:ff:ff:ff:ff (Ether(dst=ETHER_BROADCAST)) et au niveau ARP on envoie une réponse (op=2) en demandant de mettre à jour l’IP 172.16.0.11 (psrc="172.16.0.11") dans tous les caches ARP (pdst="0.0.0.0") pour toutes les machines (hwdst=ETHER_BROADCAST). Vérifions à nouveau le cache ARP de frontal :
Voici le truchement par lequel l’IP virtuelle se promène d’une machine à une autre. Évidemment, il y a d’autres choses à configurer. Nous n’avons vu que la permutation d’adresse MAC permettant à la trame d’arriver sur la machine ayant récupéré l’IP virtuelle. Encore faut-il qu’elle accepte la trame et la traite. Allons plus en avant en manipulant VRRP.
1.2 VRRP
VRRP (Virtual Router Redundancy Protocol) est un protocole de redondance de lien. Son rôle est de réglementer les échanges entre plusieurs machines se partageant une IP virtuelle en mode maître/secours. Le maître porte l’adresse IP virtuelle, c’est-à-dire que c’est lui qui répond aux sollicitations ARP des clients souhaitant établir un lien avec cette adresse. L’élection et les réélections maître/secours se font sur une adresse multicast définie dans le protocole VRRP, la 224.0.0.18. Cette section se compose donc de deux parties : la configuration du multicast et la configuration du lien VRRP sur node1 et node2.
1.2.1 Configuration du multicast
En introduction rapide au multicast, on peut dire que c’est un système de diffusion de niveau 3. Les machines souscrivent à une adresse de multicast. Lorsqu’un paquet est envoyé à cette adresse de multicast, tous les clients ayant souscrit le reçoive. Le multicast est donc bien adapté pour tout ce qui est télévision IP, webradios et même diffusion d’images système sur un réseau. On notera que la duplication des paquets envoyés aux abonnés d’une adresse multicast est assurée par les équipements de commutation/routage. VRRP se repose donc sur le multicast pour l’élection du maître portant l’IP virtuelle. La première chose à faire sur node1 et node2 est d’activer IGMP (Internet Group Management Protocol) qui pilote la table de diffusion du trafic multicast sur chaque machine participante. Ça se passe dans le fichier /.etc/sysctl.conf :
Et reproduire la manipulation sur node2. Après le redémarrage des deux machines node1 et node2, nous allons tester l’adresse 224.0.0.1 sur laquelle toutes les machines configurées en multicast doivent répondre :
On retrouve bien nos deux machines node1 et node2. Nous pouvons maintenant les abonner au groupe multicast VRRP en 224.0.0.18. Commençons par installer le paquet smcroute sur les deux machines :
Ensuite, nous allons abonner les deux machines au groupe multicast en modifiant le fichier /.etc/smcroute.conf :
Ces deux manipulations sont évidemment à reproduire sur les deux machines. Après un redémarrage, testons l’adresse de multicast VRRP :
Nos deux machines répondent. Nous pouvons passer à la configuration de VRRP.
1.2.2 Configuration de VRRP
Pour illustrer le fonctionnement de VRRP, nous allons utiliser un démon en espace utilisateur qui implémente ce protocole. Il faut donc commencer par installer le paquet vrrpd sur node1 et node2 :
Nous allons maintenant exécuter vrrpd sur node1 qui est le maître du lien :
Cette commande lance le démon vrrpd en arrière-plan (-D), sans gérer l’adresse MAC virtuelle (-n). Étant donné que l’IP virtuelle est sur le même réseau, elle peut tout à fait répondre sur l’adresse MAC originale de la carte, la convergence en cas de perte du lien n’en est que plus rapide. L’interface à gérer via VRRP (-i) est enp0s3 (qui est la seule interface de node1 et node2). La priorité (-p) est fixée à 100. La machine ayant la plus haute priorité est le maître. On n’authentifie pas les machines participant au lien VRRP (-a none). Le groupe VRRP possède l’identifiant 1 (-v 1). En effet, vrrpd peut gérer une multitude de liens, donc il faut les identifier sans ambiguïtés. Enfin, on renseigne l’IP virtuelle, ici 172.16.0.13. Allons voir ce qui s’est passé dans les logs :
On voit qu’on passe du statut de backup router à celui de maître en 4 secondes. Effectivement :
L’adresse virtuelle est bien portée par l’interface enp0s3 avec l’adresse MAC originale. Essayons de toucher l’IP virtuelle en ICMP depuis la machine frontal :
Ça fonctionne. Regardons le cache ARP :
On voit que la machine node1 en 172.16.0.11 et l’IP virtuelle 172.16.0.13 sont derrière la même adresse MAC. Lançons maintenant vrrpd sur le node2 avec une priorité un peu inférieure :
Et allons voir dans les logs :
Ce second lien s’est bien positionné en secours. Supprimons l’association dans le cache ARP de la machine frontal :
Relançons quelques requêtes ICMP :
Et vérifions à nouveau le cache ARP :
C’est bien toujours node1 qui sert l’IP virtuelle. Regardons ce qui se passe en cas de rupture de lien. Lançons un ping en continu depuis le frontal sur l’IP virtuelle et cassons le lien en envoyant un SIGTERM au service vrrpd sur node1. On récupère le PID :
Et on tue le processus :
Examinons le ping que nous avons lancé en continu depuis le frontal :
On constate que deux paquets ICMP sont perdus entre les séquences 103 et 106 le temps qu’on permute de node1 à node2. Regardons le cache ARP de frontal :
L’IP virtuelle est maintenant portée par node2.
Et si on fait revenir le master :
Dans les logs de node1 :
Et dans ceux de node2 :
La perte et le retour de node1 se sont donc bien passés. On notera qu’il est sans doute préférable de remettre en ligne node1 manuellement, car la disponibilité du lien VRRP ne signifie pas forcément que tout va bien. Nous allons maintenant nettoyer nos configurations pour laisser la place à Keepalived :
Il faut bien redémarrer node1 et node2.
1.3 Keepalived
Le service keepalived est un démon qui réunit toutes les fonctionnalités que nous avons évoquées précédemment pour gérer des IP virtuelles partagées entre plusieurs nœuds. De plus, il va gérer la couche IPVS pour invalider des instances de services équilibrés qui seraient tombées. Dans cette section, nous allons juste mettre en place un service keepalived sur node1 et node2 pour assurer la disponibilité d’une adresse virtuelle pour recréer la configuration précédente. La section suivante fera le lien entre keepalived et IPVS. Commençons par node1 en installant le paquet keepalived :
Et configurons-le via le fichier /.etc/keepalived/keepalived.conf :
Avec le travail précédent, nous sommes en terrain connu. Nous configurons une instance VRRP en état MASTER (state MASTER) attachée à l’interface enp0s3 avec l’id 1 et une priorité de 100. Ici, contrairement à la section précédente, nous authentifions le lien. Enfin, on spécifie l’IP virtuelle. Démarrons keepalived :
Voyons le résultat :
Effectivement, l’IP virtuelle est portée par l’interface enp0s3. Configurons maintenant le keepalived de node2 qui est en secours :
Dans le fichier de configuration, seules deux choses changent, l’état qui sera BACKUP (state BACKUP) et la priorité qui passe à 90 :
Démarrons le service keepalived sur node2 :
Testons depuis le frontal :
Vérifions le cache ARP de frontal :
L’IP virtuelle est bien servie par node1, le maître. Laissons tourner un ping sur le frontal et coupons le lien vers la machine node1 :
On constate la perte d’un paquet entre la séquence 19 et 21. Examinons le cache ARP :
La permutation de node1 vers node2 a bien fonctionné. Nous pouvons maintenant passer à la configuration d’IPVS.
2. IPVS
IPVS va venir se reposer sur les deux keepalived que nous avons installés dans la phase précédente. Keepalived va instruire IPVS des règles à créer pour équilibrer le trafic vers les instances de services équilibrés. IPVS va ensuite s’appuyer sur le framework Netfilter pour rediriger le trafic. C’est la raison pour laquelle on dit qu’IPVS est un équilibreur de charge de niveau 4 (transport), car Netfilter ne travaille que sur des sujets de type couple IP/Port. Nous allons ajouter deux serveurs web Nginx à notre laboratoire et les mettre en ferme derrière l’IP virtuelle déjà configurée. Le FQDN www.lab.local pointera sur l’IP virtuelle 172.16.0.13. Derrière cette IP, nous retrouverons www1 en 172.16.0.14 avec la MAC 08:00:27:ca:3b:eb et www2 en 172.16.0.15 avec la MAC 08:00:27:03:a8:e2.
2.1 IPVS en manuel
Les deux points importants à clarifier sont : 1) les algorithmes d’ordonnancement pour l’équilibrage de charge et 2) le mode d’accès réseau aux instances de services équilibrés. Les algorithmes d’ordonnancement sont très nombreux. IPVS intègre dix algorithmes. Ces algorithmes vont conditionner la façon dont les clients accèdent aux instances de services équilibrés. Nous allons en discuter deux : RR et SH. Pour les accès réseau, nous parlerons du mode routage direct. Commençons par les algorithmes d’ordonnancement.
RR signifie Round Robin. Avec cet algorithme, les accès aux instances de services équilibrés se font en mode tournant. Si on a trois serveurs, la première requête va sur le premier serveur, la seconde sur le second serveur, la troisième sur le troisième serveur et la quatrième sur le premier, etc. Cet algorithme est le plus simple en termes d’équilibrage de charge donc le plus performant. On notera qu’il existe une version pondérée (weighted) où il est possible d’ajouter un poids à chaque instance de services équilibrés pour moduler la répartition des requêtes clientes en fonction de la puissance des serveurs portant les instances de services équilibrés.
SH signifie Source Hashing. Dans cet algorithme, les accès aux instances de services équilibrés se font en fonction de la source de la requête. L’objectif est qu’un client accède toujours à la même instance de service équilibré à chacune de ses requêtes. Une empreinte (hash) de la source est mémorisée par IPVS pour lui servir toujours la même instance. Cet algorithme est utilisé lorsqu’il faut maintenir une session côté instance de service équilibré. Cependant, dans notre exemple nous n’allons considérer que le Round Robin.
Pour la partie mode d’accès réseau aux instances de services équilibrés, nous verrons le mode routage direct (aussi appelé DR pour Direct Routing), l’équilibreur de charge reçoit le paquet du client sur l’IP virtuelle. L’équilibreur de charge ne touche pas le paquet, il change juste l’adresse MAC de destination de la trame de transport pour que le paquet arrive sur l’une des instances du service équilibré. Par ce truchement, l’instance de services équilibrés répond directement au client. L’IP virtuelle doit donc être à la fois portée par l’équilibreur de charge et par chaque instance des services équilibrés. Le lecteur attentif relèvera qu’une telle configuration engendre des conflits d’IP. L’astuce est que l’IP virtuelle configurée sur les instances de services équilibrés est « neutralisée », c’est-à-dire qu’elle ne répondra pas aux sollicitations ARP. Nous allons commencer par configurer IPVS à la main et regarder ce qui se passe. L’outil ipvsadm interagit avec le noyau Linux pour configurer les règles d’équilibrage de charge. Commençons par examiner la configuration en place :
Elle est vide. Déclarons l’IP virtuelle avec une organisation en Round Robin (rr) :
Examinons à nouveau la configuration :
Ajoutons les deux instances de services équilibrés :
Cette commande ajoute un serveur (--add-server), sur un service TCP (--tcp-service) sur une IP virtuelle et son port (172.16.0.13:80). On spécifie ensuite le couple IP / port du serveur réel (--real-server) en mode routage direct (--gatewaying). Examinons la configuration :
Testons les deux serveurs en direct. Nous avons modifié la page d’accueil du Nginx installé pour juste afficher le nom de la machine. Accédons à www1 :
Et www2 :
Nos deux serveurs sont fonctionnels. Fixons maintenant l’alias de l’IP virtuelle sur les instances de services équilibrés. Il faut ajouter cette section dans les fichiers /.etc/network/interfaces de www1 et www2 :
Pour ce qui est du blocage de l’ARP, il y a plusieurs écoles. Sur Internet, vous trouverez beaucoup de documentation qui propose de modifier les variables du noyau via sysctl et ignorer les requêtes ARP sur une interface donnée. Ici on ne peut pas faire ça, car l’interface porte également l’IP standard du serveur qui accueille le serveur Nginx. Nous allons donc créer une règle avec arptables pour bloquer les requêtes ARP concernant l’IP virtuelle :
Rendons ça persistant au redémarrage :
Et mettons les droits d’exécution dessus :
Redémarrons et vérifions la présence de l’alias :
L’IP virtuelle est bien portée par l’interface réseau de l’instance de service à équilibrer www1. Vérifions la règle arptables :
On est bons. Il faut répéter la même manipulation sur www2. Une fois www2 configuré et redémarré, on peut tester :
On voit bien que notre requête touche à tour de rôle www1 puis www2 puis www1, etc. Si on capture les réponses HTTP 200 OK (code renvoyé par le serveur web lorsque la page est disponible) reçues par le client on voit les informations suivantes :
On constate que les paquets arrivent de l’IP virtuelle 172.16.0.13, mais avec une adresse MAC qui change. En premier, on trouve 08:00:27:ca:3b:eb (www1), puis 08:00:27:03:a8:e2 (www2). C’est conforme à ce qui a été avancé lors de l’explication du mode routé. Éteignons maintenant la machine www2, c’est là que le bât blesse :
Une fois sur deux, on tombe sur la machine défaillante. C’est pour cela que nous avons besoin de Keepalived. En plus de maintenir l’IP virtuelle via VRRP, keepalived surveille la disponibilité des instances de services équilibrés pour ajuster la configuration d’IPVS en temps réel.
2.2 Keepalived + IPVS
Nous allons modifier le fichier de configuration de keepalived pour y intégrer les déclarations d’instances de services à équilibrer. Vous retrouverez des directives très proches de la configuration manuelle. Voyons la section à insérer à la suite du fichier de configuration /.etc/keepalived/keepalived.conf :
Cette configuration concerne l’IP virtuelle 172.16.0.13 et pointe sur deux instances de services équilibrés (real_server) avec leur IP (172.16.0.14 et 172.16.0.15) et le port TCP (protocole TCP) concerné (80). Le service keepalived va contrôler les instances de services équilibrés toutes les 8 secondes (delay_loop) avec un test de connexion TCP (TCP_CHECK) avec un délai de garde fixé à 3 secondes (connect_timeout). L’algorithme d’ordonnancement est un Round Robin (lb_algo rr) et on est sur un mode d’accès aux instances de services équilibrés en mode routé (lb_kind DR). Regardons avec la commande ipvsadm la configuration générée par keepalived :
La configuration est identique à la configuration manuelle que nous avions réalisée. Testons-la :
Ça fonctionne ! Éteignons maintenant www1 et regardons le résultat :
Et node2 :
Nos deux équilibreurs de charge ont bien détecté la panne, www1 a été retiré des instances de services équilibrés. Testons :
Le load balancer ne nous sert plus que pour www2. Regardons la table ARP du frontal :
Coupons maintenant node1 qui est l’équilibreur de charge maître et testons :
Le service web répond toujours. Regardons le cache ARP :
Nous avons donc monté notre infrastructure web en haute disponibilité avec Keepalived et IPVS.
Conclusion
Dans cet article, nous avons balayé à la fois les aspects théoriques et pratiques autour du couple Keepalived/IPVS. J’ai volontairement limité les configurations au couple routage direct et round robin avec beaucoup de détails pour que vous puissiez rapidement adapter cette configuration à vos besoins. De plus, dans les environnements actuels types cloud avec des SDN (Software Defined Network), il existe une multitude de couches d’abstraction au-dessus du réseau traditionnel pour servir les conteneurs. Or l’équilibrage de charge fait partie de l’ADN de ces environnements hautement élastiques et dynamiques. Il faut donc une solide compréhension des mécanismes sous-jacents à l’équilibrage de charge pour arriver à déboguer celui-ci en cas de problèmes.
Références
[1] N. GRENECHE, Y. ABDECHCHAFIQ, « Les réseaux logiques (VLANs) », GLMF n°198, novembre 2016 : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-198/les-reseaux-logiques-vlans
[2] P. BIONDI, « Scapy, TCP et les automates », MISC n°52, novembre/décembre 2010 :
https://connect.ed-diamond.com/MISC/misc-052/scapy-tcp-et-les-automates



