

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
OpenNebula est un orchestrateur libre de machines virtuelles (KVM, VMWare) et conteneurs lourds (LXC). Son rôle est d’organiser et placer les machines virtuelles sur une infrastructure physique. C’est un peu le chaînon manquant entre le serveur physique et les orchestrateurs de conteneurs applicatifs types Kubernetes.
L’instanciation d’applications sur un système d’exploitation a considérablement évolué au cours de ces dernières années. Jadis, nous compilions les applications directement sur le système d’exploitation. Une distribution Linux était d’ailleurs basée sur ce principe : LFS (Linux From Scratch). Dans cette distribution, nous trouvions les sources du noyau Linux, la libc et les outils GNU essentiels à l’utilisation du système. L’informatique était alors bien plus confidentielle que maintenant. En conséquence, l’administrateur du système était souvent également l’utilisateur de l’application. Il était responsable de la compilation et de l’installation de l’application. Ensuite, les gestionnaires de paquets sont arrivés. Allant de pair avec les distributions précompilées, les gestionnaires de paquets fournissent les applications sous une forme déjà compilée et préconfigurée pour le système cible. La compilation et l’installation sont alors échues à deux personnes distinctes : le mainteneur du paquet qui le compile et le préconfigure pour la distribution et l’administrateur du système qui l’installe. Avec le gestionnaire de paquets, l’application est donc fortement adhérente au système d’exploitation sous-jacent. C’est pour cette raison que la distribution d’application s’est orientée vers la conteneurisation. L’application est cette fois-ci livrée avec ses librairies pour être indépendante du système sous-jacent. En conséquence, ce système doit seulement intégrer des mécanismes noyaux permettant d’exécuter les applications distribuées sous cette forme de façon confinée (namespaces et cgroups).
Cette évolution tendant vers l’indépendance de l’application par rapport au système d’exploitation a considérablement changé la façon d’envisager la gestion des applicatifs. Dorénavant, on parle de « déployer un WordPress » alors qu’auparavant il était question d’installer un LAMP avec les bons modules PHP pour ensuite installer un WordPress dessus. On envisage maintenant le déploiement d’applications comme une icône à cliquer suivie d’une barre de progression et d’informations pour l’utilisation (par exemple, identifiant et mot de passe du compte par défaut), le tout évidemment via un navigateur web. C’est ce que l’on appelle le mode SaaS (Software as a Service) chez les fournisseurs de services Cloud. Pour arriver à une telle simplicité d’instanciation (on ne parle même plus d’installation) d’applications, les couches inférieures nécessaires sont bien plus nombreuses. Premièrement, ces applications ne sont plus exécutées sur le système d’exploitation installé sur le matériel, mais dans des machines virtuelles pour offrir de la souplesse au fournisseur de service (migration des VM pour maintenance, partitionnement des ressources, etc.). Deuxièmement, ces machines virtuelles sont liées à un orchestrateur de conteneurs chargé de placer les applications instanciées par les utilisateurs. Cet article va se concentrer sur le premier point, à savoir comment gérer des machines virtuelles déployées sur une infrastructure physique de façon centralisée avec OpenNebula.
1. Architecture d’OpenNebula
L’architecture d’OpenNebula est assez classique. Les nœuds physiques qui la composent peuvent avoir deux rôles : frontal (frontend) ou dorsal (backend). Le frontal embarque les services nécessaires au fonctionnement de l’infrastructure OpenNebula. Les nœuds ayant le rôle dorsal sont aussi appelés nœuds d’hypervision. Comme leur nom l’indique, c’est sur eux que tourne l’hyperviseur qui va exécuter les VM. Dans notre article, nous allons utiliser KVM. La complexité d’installation se trouve sur le frontal, car on y retrouve toute la pile de services OpenNebula. Pour y voir plus clair, je vais avancer dans le temps et lister les processus en exécution sur un frontal OpenNebula fonctionnel :
On constate qu’il y a deux gros morceaux : les processus fils de oned et les processus invoqués par Systemd.
1.1 Le processus oned et ses fils
Le service chargé d’orchestrer tous les services d’OpenNebula se nomme oned. Il présente l’interface XML-RPC permettant aux différents composants d’interagir entre eux. Dans ce sens, on peut envisager oned comme un bus de communication entre les services de l’infrastructure OpenNebula. Il va aussi gérer les pilotes des différentes ressources (type d’hyperviseur, stockage, réseau, etc.). Le processus oned a plusieurs fils. Le premier est onemonitord. Ce processus va démarrer des sondes (ou probes) sur les nœuds d’hypervision. Ces nœuds vont ensuite pousser des métriques vers le processus onemonitord. On notera également que onemonitord appelle plusieurs instances du script one_im_exec.rb. Ces scripts permettent de traiter les données remontées par les sondes en fonction de l’hyperviseur passé en paramètre (Firecracker, KVM, LXC, LXD, QEMU et VCenter).
Juste après onemonitord, oned invoque un processus one_hm.rb. Dans le nom de ce processus, « HM » se réfère à « Hook Manager ». Le gestionnaire de crochets permet au processus oned de s’accrocher a un autre processus plus bas dans la liste onehem-server.rb. Dans le nom de ce processus, « HEM » se réfère à « Hook Execution Manager ». Le principe du crochet est de placer des déclencheurs sur différentes fonctions d’un programme pour exécuter des choses lorsqu’elles sont invoquées. Ainsi, oned informe onehem-server.rb via son processus fils one_hm.rb de ses actions. Si un crochet a été placé sur la fonction invoquée par oned alors onehem-server.rb va exécuter l’action définie dans le crochet en mode fork/exec.
Ensuite, nous avons une suite de processus one_vmm_exec.rb. Ces processus gèrent les VM pour les différents hyperviseurs supportés. On constate qu’il n'y a pas que des hyperviseurs pour de la virtualisation complète, mais aussi des conteneurs, donc le terme VM n’est pas forcément idéal, mais c’est celui qu’on retrouve dans la documentation OpenNebula. Historiquement, OpenNebula ne supportait que KVM.
Les derniers processus fils de oned sont les pilotes lui permettant d’interagir avec son écosystème. On retrouve one_auth_mad.rb qui gère la partie authentification avec différentes méthodes : certificats X509 [1], SSH, LDAP [2], etc. Le processus one_tm.rb gère le transfert d’images entre le frontal et les nœuds d’hypervision en vue de leur instanciation sous forme de VM. On retrouve en arguments tout un tas de technologies gravitant autour des systèmes de fichiers. On note qu’on retrouve les mêmes technologies invoquées par le pilote one_datastore.rb qui gère les Datastores OpenNebula. Un Datastore est un entrepôt dans lequel OpenNebula stocke les fichiers permanents (images) ou temporaires (changement d’état par rapport à l’image de référence) relatifs à la gestion des VM. Le pilote one_market.rb met à disposition la Market Place d’OpenNebula aux utilisateurs. Enfin, one_ipam.rb donne la possibilité à l’administrateur de laisser un système tiers gérer l’adressage réseau des VM.
1.2 Les processus invoqués par Systemd
Le premier composant est l’ordonnanceur de VM (scheduler). Dans l’arbre des processus ci-dessus, c’est le processus mm_sched. Son rôle est de placer les VM sur les nœuds d’hypervision. L’ordonnanceur de VM peut être installé sur une autre machine que oned, il communiquera avec ce dernier par le réseau via des appels de procédure XML-RPC. L’autre gros client est le processus sunstone-server.rb, il s’agit de l’interface graphique que nous allons présenter dans la suite de l’article. Un pendant de Sunstone est le processus websockify qui offre un accès VNC aux VM depuis l’interface Sunstone. Les deux derniers processus onegate-server et oneflow-server sont des composants optionnels.
Le composant onegate-server peut s’exécuter sur une autre machine, car à l’instar de l’ordonnanceur de VM, il dialogue avec oned par des appels de procédures XML-RPC. Le but de onegate-server est de collecter des métriques à l’intérieur de la VM. Plus généralement, cela permet à oned de savoir ce qui se passe dans les VM et aux VM d’avoir des informations sur l’infrastructure OpenNebula. Pour que cela fonctionne, il faut prévoir d’intégrer à votre image de VM les paquets de contextualisation. Ces paquets ne concernent que l’espace utilisateur. Dans le cas de l’utilisation de KVM, votre système en VM n’a aucune idée qu’il est virtualisé même avec ce paquet de contextualisation. Ce n’est pas de la para-virtualisation, c’est « juste » un agent qui tourne dans la VM et interagit avec le processus onegate-server.
Le composant oneflow-server peut également s’exécuter sur une autre machine, car il communique avec oned via des appels de procédure XML-RPC. L’objectif de ce service est double. Le premier est d’offrir la possibilité de créer des automates de création lors de l’instanciation de services multi-VM. Par exemple, si on instancie un CMS, on voudrait pouvoir lancer en premier la VM avec la base de données, ensuite le serveur web hébergeant le code du CMS. Ces deux machines peuvent être sur des adresses privées. Enfin, une fois le CMS déployé, on déploiera le reverse proxy sur une adresse publique pour accéder au CMS. Le second objectif de oneflow-server est d’offrir de l’élasticité en créant des VM automatiquement lors de la montée en charge d’un service. Pour avoir des métriques précises sur l’applicatif et pas que sur le couple CPU/mémoire, oneflow-server pourra collaborer avec onegate-server par l’intermédiaire de oned.
Le dernier composant optionnel est invisible, car je ne l’ai pas installé. Il s’agit de Fireedge qui est une interface distincte de Sunstone et qui permet à l’administrateur de la plateforme OpenNebula de provisionner des fournisseurs de Cloud externes tels qu’Amazon. Grâce à Fireedge, vous pouvez ajouter des ressources prises dans un Cloud extérieur et lancer vos VM dessus via Sunstone.
Vous avez maintenant la vue d’ensemble des composants OpenNebula. La documentation est assez décriée sur Internet, mais personnellement je la trouve très bien. Ce qu’on peut en dire, c’est que les mainteneurs ne documentent que les aspects OpenNebula. Par exemple, si vous cherchez des informations sur comment placer vos VM sur un bridge Ethernet alors vous aurez juste la manipulation. Vous n’aurez pas une seule ligne sur ce qu’est un bridge. Nous allons donc voir comment intégrer notre infrastructure cible OpenNebula dans le système d’information existant en renforçant les explications sur les technologies clés de l’intégration.
2. Intégration de la solution OpenNebula
Une solution de gestion de VM comme OpenNebula n’arrive pas en mode hors-sol. L’idée est de l’intégrer dans un réseau existant. Je mets en place OpenNebula pour donner la possibilité à des enseignants chercheurs d’instancier eux-mêmes des VM en mode libre-service. Ces VM devront être accessibles soit uniquement de l’intérieur de l’université (plage d’adresses IP privées), soit de partout (plage d’adresses IP publiques). L’intégration va donc dépendre de la topologie réseau du site. OpenNebula propose toute une quantité de pilotes réseaux pour s’intégrer dans l’existant. Chez nous, le réseau est segmenté en VLAN (Virtual Local Area Network). Nous avons un pare-feu de site qui porte les passerelles par défaut des différents VLAN et qui effectue les NAT. Cette topologie va avoir des incidences à la fois sur la configuration d’OpenNebula lui-même, mais aussi sur les nœuds. Pour bien comprendre les réglages que nous allons faire, il faut faire un point sur deux notions : les ponts (bridges) et les VLAN. Dans la suite de l’article, nous allons construire un petit laboratoire avec un frontal et un nœud d’hypervision. Le frontal sera contenu dans un LXC. Notre frontal physique se nommera on-master1, son LXC accueillant le service OpenNebula on-buster (à l’heure actuelle les paquets OpenNebula ne sont pas disponibles sur Bullseye) et le nœud d’hypervision on-node1.
2.1 Introduction aux ponts et aux VLAN
Pour comprendre la notion de pont, il convient d’introduire la notion de domaine de diffusion (broadcast) Ethernet. Un domaine de diffusion Ethernet correspond à la portée potentielle de votre machine pour communiquer avec d’autres machines. Si on connecte une machine M1 à un commutateur C1, alors elle peut potentiellement contacter toutes les machines connectées à C1. Si une machine M2 est connectée à un autre commutateur C2 non connecté avec C1 alors M1 et M2 ne se voient pas. Par contre, si on tire un câble entre C1 et C2 alors M1 et M2 pourront communiquer. Les ports sur C1 et C2 sur lesquels le câble d’interconnexion est branché constituent un pont. L’idée du pont est de grouper des interfaces pour les mettre sur le domaine de diffusion Ethernet. Un pont peut aussi grouper des interfaces au sein du même équipement physique. Par exemple, peut-être avez-vous remarqué que votre box Internet vous attribue des adresses IP situées dans le même réseau que vous soyez en filaire ou en Wifi. Cela s’explique par le fait que les ports du commutateur embarqué et l’interface correspondant à l’antenne Wifi sont dans un pont. Or le serveur DHCP de votre box arrose ce pont donc les mêmes paramètres vous sont servis que vous soyez en filaire ou en Wifi. Le niveau 2 du modèle OSI est différent (filaire et ondes), la constitution d’un pont présente une vision unifiée au niveau 3 pour y superposer un unique réseau IP.
J’ai déjà eu l’occasion de détailler les VLAN dans un article [3]. Je vais donc faire une explication sommaire. Le fil conducteur de l’explication est qu’un VLAN permet de limiter un domaine de diffusion Ethernet. Les VLAN vont donc donner la possibilité de domicilier plusieurs domaines de diffusion Ethernet sur le même équipement de commutation via l’ajout d’un marqueur (tag) sur les trames Ethernet. La responsabilité du positionnement du marqueur peut incomber soit au commutateur (dans ce cas on parle de mode « access »), soit à la machine elle-même (dans ce cas, on parle de mode « 802.1Q » ou « trunk » chez Cisco). En mode accès, on configure le commutateur pour dire (par exemple) les ports 3, 5 et 7 sont dans le VLAN numéro 10 et les ports 4, 10 et 20 sont dans le VLAN numéro 11. Le marqueur est le numéro associé au VLAN. À partir de ce moment, les machines connectées aux ports domiciliés dans les différents VLAN du même commutateur ne se voient plus. En mode 802.1Q, le commutateur s’attend à voir arriver les trames déjà marquées. C’est de la responsabilité de la machine de marquer ou retirer la marque les trames. C’est utile dans le cas où une machine doit être domiciliée sur plusieurs domaines de diffusion Ethernet. Par exemple, dans cet article, les VM s’exécutant sur une même machine physique doivent pouvoir être domiciliées sur différents VLAN (donc sur différents domaines de diffusion Ethernet).
2.2 Configuration des prérequis sur on-master1
La configuration réseau est homogène sur tous les nœuds de l’infrastructure OpenNebula. La première étape est de donner la possibilité au noyau de traiter les marqueurs 802.1Q. Pour ce faire, il faut charger le module noyau 8021q. Il suffit d’ajouter le nom du module dans le fichier /etc/modules :
Ensuite, il faut installer le paquet permettant de configurer les ponts :
La configuration visée est d’avoir une seule interface physique pour faire passer le réseau d’administration, soit le VLAN 43 avec la plage 192.168.43.0/24 et le réseau dédié aux VM, soit le VLAN 46 avec la plage 10.1.16.0/20. Les passerelles par défaut sont des interfaces de VLAN placées sur le pare-feu et répondant aux adresses 192.168.43.254 pour le VLAN 43 et 10.1.31.254 pour le VLAN 46.

Examinons la configuration réseau de on-master1. La configuration réside dans le fichier /etc/network/interfaces :
Ce fichier débute avec la configuration de l’interface de rebouclage. C’est la configuration par défaut au moment de l’installation de la distribution, nous ne la toucherons pas. Ensuite, on trouve une interface eno1.43. Le préfixe eno1 de cette interface est bien connu. Le .43 en suffixe correspond au numéro du VLAN. Nous la configurerons en mode manuel, c’est-à-dire que la configuration ne se fait pas au démarrage via ce fichier. Cette interface va donc être capable de remonter les trames Ethernet transitant dans le VLAN 43 au noyau. Cette interface va servir de base pour le pont configuré juste après br43. Le nom br43 est totalement arbitraire, mais on trouve souvent dans la littérature la construction br pour « bridge » suivie d’un numéro. Comme le pont va servir à distribuer le VLAN 43 au conteneur LXC on-buster, j’ai décidé d’utiliser l’identifiant de VLAN comme numéro. Ce qui donne pour ce pont le nom d’interface br43. La directive bridge_ports lie l’interface eno1.43 à l’interface br43. La trame taguée transite par le câble connectant la machine on-master1 au commutateur. Côté commutateur, le port est configuré en mode 802.1Q. Lorsque la trame arrive sur l’interface physique eno1, elle est prise en charge par l’interface de VLAN eno1.43, donc potentiellement toutes les interfaces liées à br43. Une fois l’interface de VLAN et le pont configurés, on peut déployer le conteneur LXC dessus.
2.3 Configuration du conteneur LXC on-buster
Un précédent article détaille déjà la configuration d’un conteneur LXC [4] donc je ne donnerais que les grandes lignes. Commençons par installer les paquets et descendre le système de fichiers racine de la Debian Buster pour créer on-buster :
Nous allons personnaliser la configuration du conteneur dans le fichier de configuration /var/lib/lxc/on-buster/config pour le lier au pont br43 :
Dans cette configuration, on déclare une interface type Ethernet dans le conteneur (lxc.net.0.type = veth), on la lie au pont br43 (lxc.net.0.link = br43) et elle est montée par défaut (lxc.net.0.flags = up). À l’intérieur du LXC on-buster, on retrouve bien une interface eth0 classique :
Passons maintenant à la préparation du nœud d’hypervision on-node1.
2.4 Configuration du nœud d’hypervision on-node1
Comme sur on-master1, il ajouter le module noyau 8021q et installer le paquet bridge-utils :
Pour la configuration réseau, nous allons procéder de la même manière que pour on-master1, excepté que nous allons ajouter un second couple interface de VLAN/pont. Ce pont supplémentaire sera utilisé pour domicilier les VM sur le VLAN 46 et par conséquent se nommera br46. Voyons ce que ça donne dans le /etc/network/interfaces de on-node1 :
On notera que le pont br46 n’a pas d’adresse IP. En fait, la machine en elle-même n’a pas besoin d’être joignable sur ce réseau. En revanche, elle doit fournir une continuité physique (comprendre niveau 2 du modèle OSI) aux VM qu’elle va héberger.
3. Installation d’OpenNebula
L’installation se déroule en 3 temps. Le premier temps est un tronc commun de manipulation à effectuer à la fois sur on-buster et on-node1. Le second est l’installation du frontal Sunstone sur on-buster. Enfin, le troisième temps est l’installation des paquets clients.
3.1 Tronc commun
Nous allons installer OpenNebula sur une base de Debian Buster, car les paquets pour Bullseye ne sont pas encore disponibles. Nous installerons Sunstone et les services associés sur on-buster puis nous installerons les paquets client et l’hyperviseur sur on-node1. Installons quelques paquets pour ajouter les dépôts OpenNebula :
Ajoutons la clé :
Puis l’URL du dépôt :
Enfin, mettons à jour le cache des paquets disponibles pour la distribution :
3.2 Installation du frontal
Passons à la configuration du frontal. Commençons par installer les paquets :
Le paquet opennebula intègre l’ordonnanceur, opennebula-sunstone le portail Sunstone, les deux composants optionnels OneFlow (opennebula-flow) et OneGate (opennebula-gate). Le troisième composant optionnel FireEdge n’a pas été installé.
La partie Sunstone est livrée configurée et opérationnelle. Il faut juste désactiver FireEdge dans le fichier /etc/one/sunstone-server.conf en commentant les lignes relatives à sa configuration :
Ensuite, il faut configurer OneGate, cela se passe dans le fichier /etc/one/onegate-server.conf et consiste à faire écouter le service sur les interfaces avec la directive :host: 0.0.0.0 :
Et informer Sunstone de l’emplacement du service OneGate via la directive ONEGATE_ENDPOINT du fichier /etc/one/oned.conf :
Enfin, nous passons à la configuration de OneFlow. Comme pour OneGate, cela se limite à le faire écouter sur le réseau dans le fichier /etc/one/oneflow-server.conf avec la directive :host: 0.0.0.0 :
Nous pouvons ensuite activer les services au démarrage :
Et les démarrer :
Nous pouvons maintenant tester la validité de l’installation. OpenNebula a créé un utilisateur oneadmin. Nous allons transiter vers cette identité pour vérifier la bonne santé de notre installation avec la commande oneuser qui va afficher les informations de notre administrateur :
Notre installation est fonctionnelle. Nous pouvons nous connecter à l’interface graphique. L’identifiant est « oneadmin » et le mot de passe est disponible dans le fichier /var/lib/one/.one/one_auth :
Nous pouvons maintenant accéder à l’URL http://on-buster:9869 ou http://192.168.43.250:9869 en fonction de votre configuration DNS, vous devriez tomber sur la page présentée par Sunstone.
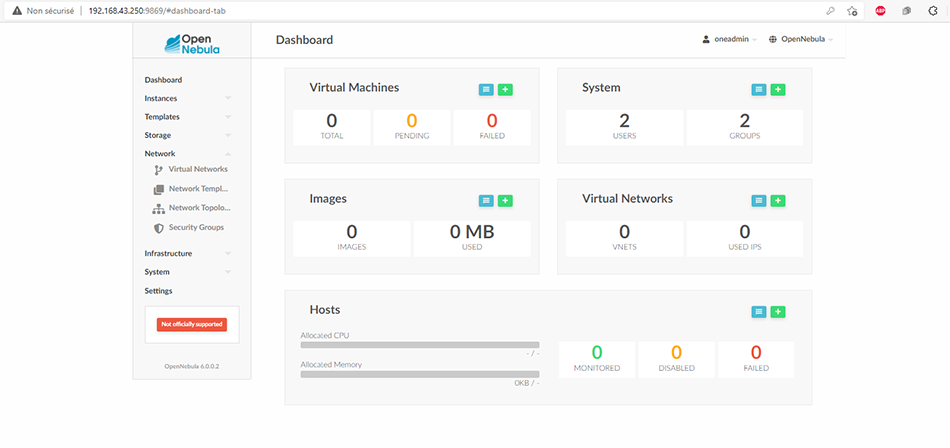
Une fois identifiés, nous atterrissons sur le tableau de bord (dashboard) présenté en figure 2 qui donne une vue globale des ressources OpenNebula. Évidemment, pour l’instant c’est vide. Mais l’univers en a horreur alors nous allons configurer le stockage et le réseau.
3.3 Installation du client
On part du postulat que les manipulations de la section 3.1 ont été effectuées. Nous installerons le paquet opennebula-node-kvm qui installe les wrappers OpenNebula et l’hyperviseur associé (KVM) :
Ce paquet a créé un utilisateur « oneadmin » (avec le même UID que sur le frontal). Il faut initialiser le mot de passe de ce compte pour ensuite manipuler les clés SSH :
En effet, sur OpenNebula, les communications entre le frontal et les nœuds d’hypervision passent par des connexions SSH. Il va falloir créer un fichier contenant toutes les empreintes des clés, car les connexions se font évidemment en mode non interactif. Nous allons nous appuyer sur la commande ssh-keyscan pour les collecter depuis on-buster avec le compte « oneadmin » :
On recopie le fichier known_hosts sur tous les nœuds d’hypervision (ici on-node1) :
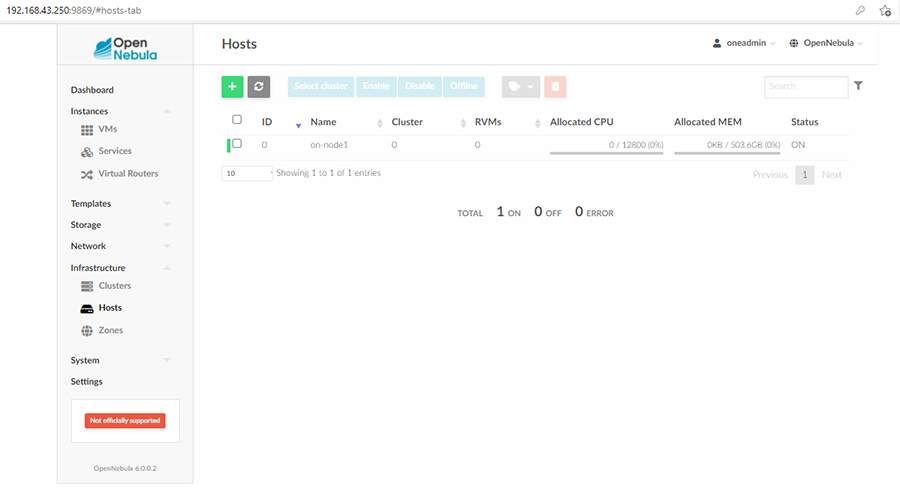
Normalement, vous devriez pouvoir vous connecter depuis on-buster avec le compte « oneadmin » vers on-node1 avec le même compte. Une fois que la connexion SSH est bonne, l’ajout du nœud d’hypervision via Sunstone est possible. Il faut aller dans le menu Infrastructure puis Hosts. La page est vide. Pour ajouter un nœud d'hypervision (en l’occurrence on-node1), il faut fournir trois informations, à savoir : l’hyperviseur concerné (KVM pour cet article), le nom court ou le nom pleinement qualifié ou l’adresse IP selon votre configuration (ou absence de configuration) DNS. Enfin, il faut lui donner le nom du cluster dans lequel ajouter ce nœud physique. Dans cet article, tout se fait dans le cluster par défaut, nous utilisons donc la valeur default. Une fois ces étapes complétées, le nœud devrait apparaître dans la liste avec un Status à ON comme dans la figure 3. Évidemment, vous devrez réitérer le processus sur tous les nœuds d’hypervision de votre plateforme OpenNebula.
4. Configuration du stockage
OpenNebula stocke les images et les états des VM en cours d’exécution (si on opte pour des VM persistantes) dans ce qu’on appelle des Datastores. On a 3 types de Datastores : Images, Files et System. Le Datastore « Images » contient les images qui sont une archive du système de fichiers de la VM à exécuter. Le Datastore « System » stocke les disques durs des machines virtuelles en cours d’exécution. Le Datastore « Files » contient les fichiers de configuration des VM à destination des hyperviseurs (configuration réseau, nombre de cœurs, etc.). Par défaut, les Datastores OpenNebula pointent sur le système de fichiers local, précisément /var/lib/one/datastores/<ID>. L’« ID » est un identifiant numérique accolé au Datastore. Par défaut, les fichiers sont recopiés via SSH d’un système de fichiers local à un autre en fonction des besoins. Nous allons modifier ce fonctionnement en passant sur un Datastore partagé (shared). Pour partager le système de fichiers sur le cluster OpenNebula, nous allons mettre en place un serveur NFS. La machine faisant office de serveur se nomme on-filer1. Cette section va s’organiser en trois parties : configuration du serveur NFS sur on-filer1, configuration du montage sur le frontal on-buster et configuration des montages sur on-node1.
4.1 Configuration du serveur NFS
NFS (Network File System) est un système de fichiers distribué destiné à partager des répertoires entre les machines. Pour l’utiliser, il faut commencer par installer le service réseau :
Ensuite, nous créons trois répertoires physiques correspondants aux trois types de Datastores mentionnés en introduction de cette section :
Nous créons l’utilisateur oneadmin pour une meilleure lecture des ACL :
On met les droits à l’utilisateur oneadmin sur les répertoires partagés :
La configuration des répertoires à exporter se trouve dans le fichier /etc/exports :
La première ligne positionne la racine des partages avec la liste des adresses IP autorisées à accéder au partage. L’article ne porte pas sur NFS donc je laisse au lecteur le soin de parcourir la documentation. Le jeu d’option donné est standard. On redémarre NFS :
Et on vérifie que les répertoires sont bien exportés :
4.2 Configuration du stockage du frontal
Nous allons commencer par nous connecter à Sunstone pour supprimer les Datastores existants. Il faut aller dans la section Storage puis Datastores. Il faut ensuite les sélectionner et les supprimer en cliquant sur la petite poubelle et confirmer. Une fois ce travail effectué, nous allons pouvoir recréer les trois Datastores en mode distribué. Toujours dans la même section, cliquez sur le + en haut à gauche et choisissez Create.
Le premier paramètre est le nom du Datastore, ici Images (NFS). Le second est le mode d’accès, ici Filesystem – shared mode. Le dernier est le type de Datastore, ici « Images ». Nous allons créer les deux autres System et Files sur le même modèle. Notez bien les associations d’ID : 100 pour Images, 101 pour System et 102 pour Files. Ces identifiants sont les noms des répertoires correspondants au Datastore sur le système de fichiers dans /var/lib/one/datastores. Ils sont créés sur le frontal, mais il faudra les créer sur les nœuds d’hypervision. Commençons par installer le paquet nfs-client :
Le frontal n’est utilisé que pour charger les images des VM. Donc le seul répertoire à monter en NFS est l’export correspondant aux images. Nous allons monter l’export NFS « Images » dans le répertoire /var/lib/one/datastores/100. Nous allons configurer ce montage via Systemd. Tout d’abord, il faut identifier le nom de fichier à donner au script Systemd réalisant notre montage. En effet, ce nom est normé et dépendant du répertoire dans lequel nous effectuons le montage. Pour le déterminer, je m’appuie sur l’outil systemd-escape :
Nous pouvons maintenant créer le script de montage var-lib-one-datastores-100.mount dans le répertoire /etc/systemd/system :
Comme nous avons créé un nouveau fichier dans l’arborescence Systemd, il faut recharger le démon :
Ensuite, on lance et active au démarrage le service :
Regardons si le montage NFS est bien réalisé :
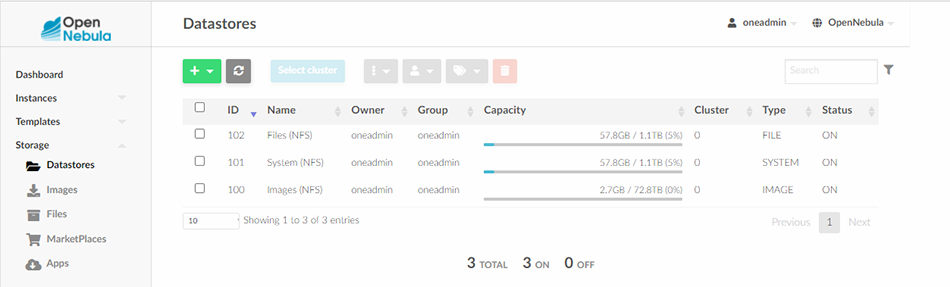
De retour sur l’interface de Sunstone, tous les nouveaux Datastores devraient apparaître. Le lecteur attentif verra sur la figure 4 que le Datastore « Images » avec l’ID 100 a beaucoup plus d’espace disponible que les deux autres. C’est normal, les deux autres résident sur le disque local tandis que le Datastore « Images » est monté depuis le serveur de fichiers on-filer1.
4.3 Configuration du stockage des nœuds d’hypervision
La différence principale d’avec le frontal c’est que nous allons également monter les Datastores « Files » et « System » depuis le serveur NFS. Commençons par installer le paquet nfs-client :
Créons les répertoires correspondants à nos Datastores partagés :
Créons les fichiers de configuration des montages pour Systemd. Commençons par « Images » :
Puis « System » :
Et enfin, « Files » :
Il nous reste à redémarrer le démon, lancer les trois montages et les activer au démarrage :
La dernière étape de configuration est le réseau.
5. Configuration du réseau
Dans cette courte section, nous allons configurer le réseau des machines virtuelles. Pour mémoire, il s’agit du VLAN 46 avec la plage 10.1.16.0/20. La passerelle par défaut est le 10.1.31.254 sur le pare-feu. La configuration réseau va se cantonner à indiquer à l’hyperviseur installé sur les nœuds d’hypervision le pont sur lequel positionner les interfaces réseaux virtuelles des VM. Dans Sunstone, il faut aller dans la section Network et ensuite Virtual Networks. On clique sur le + en haut à gauche puis sur Create. On arrive sur l’onglet General. Ici on va positionner un nom « NetPrivVMs ».
Passons à l’onglet Conf. C’est ici que nous allons faire la glue entre la VM et le VLAN 46 en définissant le pont br46 dans le champ Bridge et Bridged dans Network Mode.
L’onglet suivant Addresses sert à spécifier l’étendue des adresses IP à utiliser pour les VM. Nous allons mettre l’adresse 10.1.16.10 dans First IPv4 Address et une taille (Size) de 50.
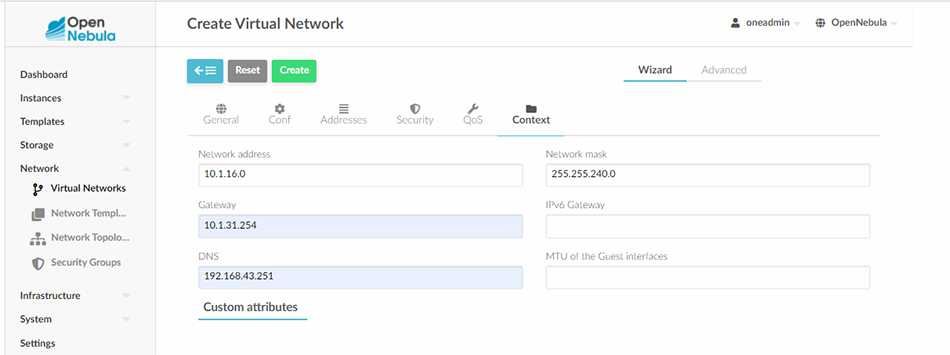
Pour la dernière étape de configuration, rendons-nous dans l’onglet Context. Il faudra définir l’adresse du réseau 10.1.16.0 dans le champ Network address, le masque 255.255.240.0 dans Network mask, la passerelle par défaut 10.1.31.254 dans le champ Gateway et enfin le serveur DNS 192.168.43.251 dans DNS conformément à la figure 5.
Une fois ces renseignements fournis, on peut cliquer sur Create. Créons maintenant notre première VM.
6. Création d’une VM
Pour créer une VM, il faut commencer par se procurer une image. Nous allons récupérer une image Debian 11 standard sur la Market Place OpenNebula [5]. Nous allons la charger dans le Datastore « Images ». On doit aller dans la section Storage puis Images. On clique sur + et Create. Dans le formulaire qui arrive conformément à la figure 6, il faut renseigner le nom Name, positionner le Type sur Operating System et placer l’image dans le « Datastore » ayant l’ID 100, « Images (NFS) ». Nous chargeons l’image depuis notre poste de travail, donc pour Image location il faut sélectionner l’option Upload.
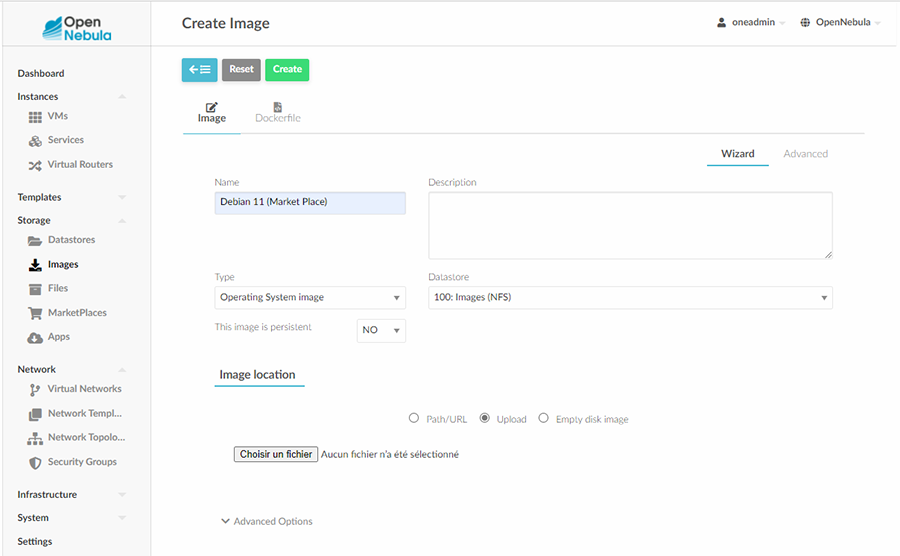
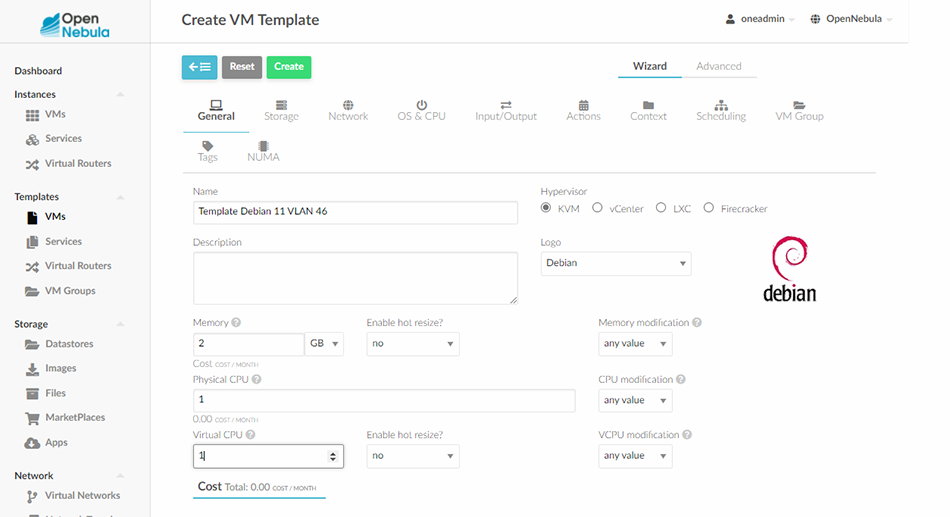
Une fois l’image chargée et le réseau configuré (section précédente), il faut aller dans la section Templates puis VMs. On clique sur + et Create. Il faut lui donner un nom, ici « Template Debian 11 VLAN 46 ». On sélectionne l’hyperviseur KVM, un petit logo, 2GB de mémoire, 1 CPU physique et 1 CPU virtuel comme indiqué dans la figure 7.
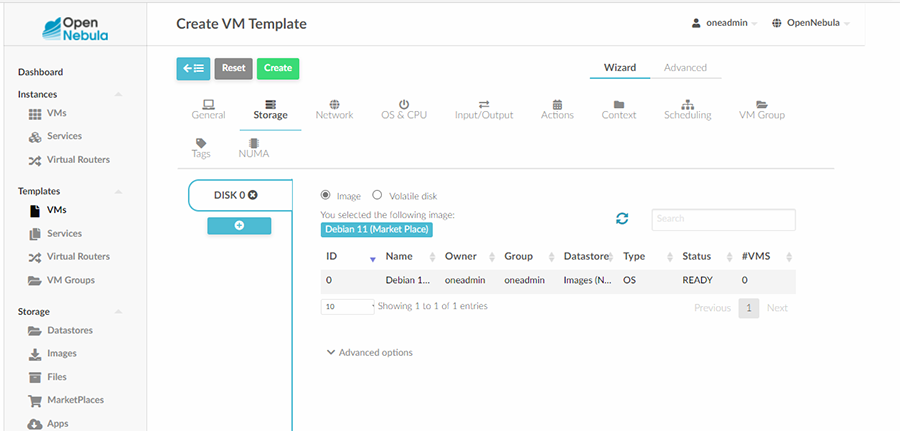
Nous passons ensuite à l’onglet Storage où nous pouvons sélectionner l’image « Debian 11 (Market Place) » précédemment chargée en cliquant dessus comme dans la figure 8.
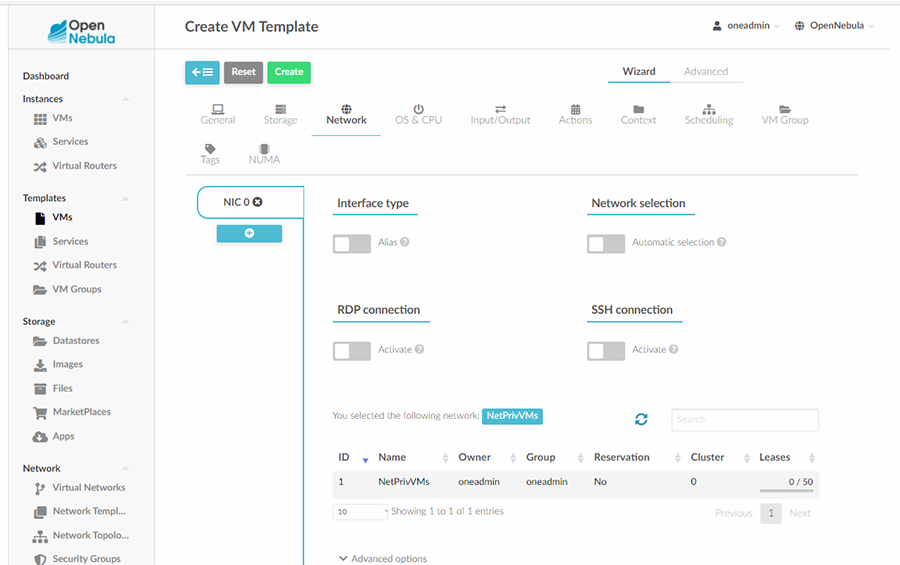
Puis nous passons à l’onglet Network où nous pouvons affecter le réseau « NetPrivVMs » au Template comme dans la figure 9.
Enfin, il faut créer une clé SSH afin de pouvoir se loguer à la VM par la suite. Depuis mon poste de travail :
Ce qui donne la clé publique :
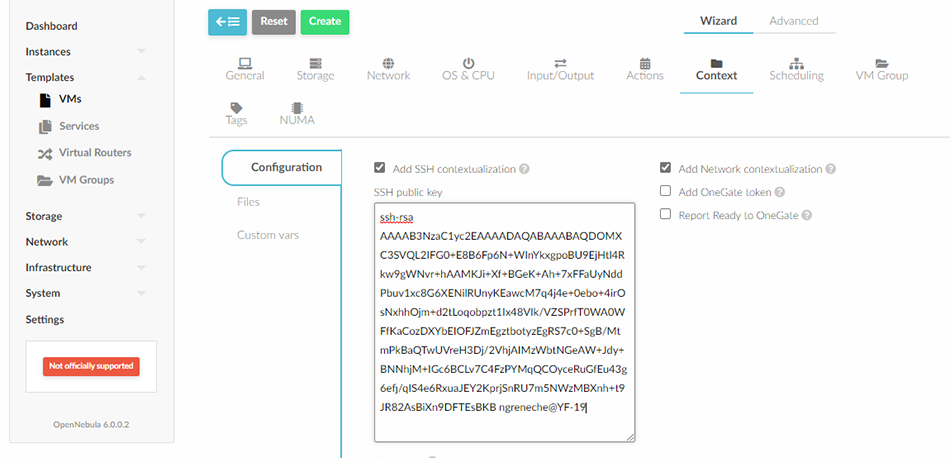
Nous pouvons passer au dernier onglet Context où il y a une zone de texte où saisir cette clé publique (Figure 10). Une fois que c’est terminé, vous pouvez cliquer sur Create. Le Template devrait apparaître dans la liste.
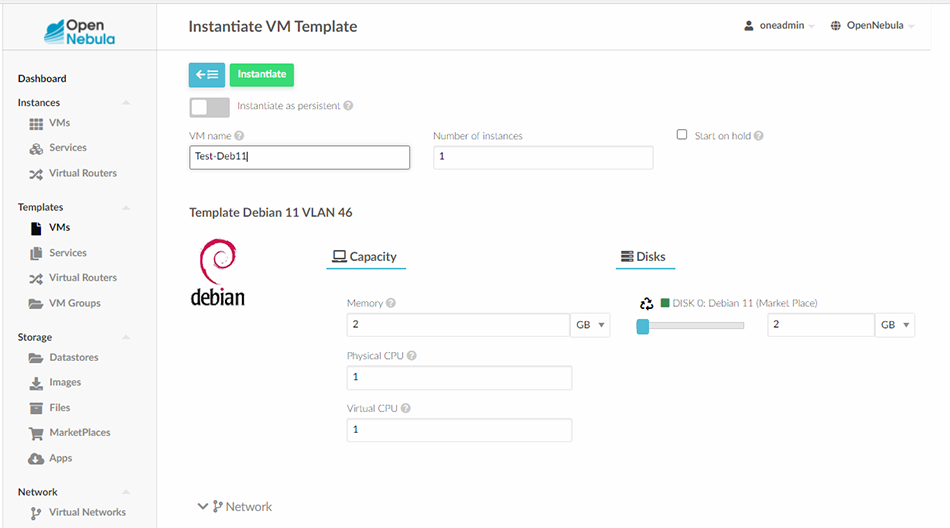
Vous pouvez ensuite cliquer sur le Template et sur le bouton Instantiate pour arriver sur le nouveau formulaire (Figure 11). La seule information à donner est un nom pour l’instance du Template, ici « Test-Deb11 ». On notera que c’est à ce niveau que l’on choisit si l’instance doit être persistante ou pas (paramètre Instantiate as persistent).
Enfin, nous pouvons aller dans la rubrique Instances puis VMs pour y retrouver notre machine virtuelle comme dans la figure 12. On note également qu’on y trouve l’adresse IP associée à la VM en exécution ainsi qu’une icône écran qui renvoie vers une session VNC directement sur votre VM.

Il ne nous reste plus qu’a nous connecter à la VM fraîchement instanciée :
On notera que le -i permet de spécifier la clé privée associée avec la clé publique chargée dans le contexte du Template de la VM.
Conclusion
Cet article vous a donné les clés pour intégrer une solution OpenNebula dans votre infrastructure. J’ai sciemment passé beaucoup de temps sur les technologies (surtout réseau) autour de notre déploiement d’OpenNebula pour deux raisons. Premièrement, il est nécessaire de comprendre ces concepts pour configurer correctement OpenNebula. Deuxièmement, ces concepts sont utiles pour toutes les applications de gestion de VM ou conteneurs. Si vous avez l’occasion de faire du LXC, KVM, VMWare, Proxmox, etc., vous retrouverez toujours ces éléments de configuration.
Références
[1] https://connect.ed-diamond.com/Linux-Pratique/lp-123/les-certificats-de-l-emission-a-la-revocation
[3] https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-198/les-reseaux-logiques-vlans



