

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Dans l’épisode précédent [1], nous avons posé les premières briques d’une infrastructure d’auto-hébergement : vm-bhyve comme solution de virtualisation, sous FreeBSD donc, Wireguard comme gestionnaire de tunnel, une petite instance t4g.nano, 2 cœurs ARM64 et 512M de RAM chez AWS et un premier succès de déplacement de machine virtuelle hébergeant un simple serveur web d’un serveur dédié vers notre infrastructure personnelle. Nous allons voir maintenant comment migrer en douceur une machine virtuelle concentrant les services de base d’une architecture à l’autre.
1. Précédemment, dans « La grande migration »
Depuis l’article précédent, le (nouveau et très spartiate) site du groupe GCU-Squad est hébergé sur une machine virtuelle bhyve, dans une machine physique située à quelques mètres de moi. Cette première expérience a permis de poser les bases de notre infrastructure auto-hébergée, dont voici un petit schéma.
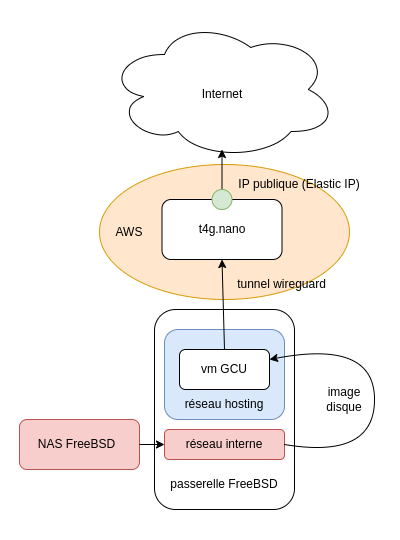
Le trafic de cette VM est transporté vers et depuis l’instance EC2 qui nous sert de routeur public à travers un tunnel Wireguard via une interface wg0 sur laquelle écoute un fier serveur web NGINX.
Cette configuration est relativement simple, en effet les clients HTTP/S se connectent en réalité à un serveur NGINX installé et configuré pour agir comme reverse proxy sur l’instance EC2 qui porte l’IP publique de notre plateforme. De cette façon, nous cachons les réponses sur l’instance et évitons d’inutiles allers-retours vers notre machine virtuelle. Une telle configuration a la forme suivante :
Les articles expliquant la configuration de NGINX étant plus nombreux que les recettes de vinaigrette, nous ne rentrerons pas dans le détail de cette dernière, commentons simplement que :
- nous déclarons une zone de cache avec un contenu maximal de 10 mégaoctets ;
- lorsqu’une requête à destination de l’un des server_name arrive, on la transmet à l’hôte gcu, dont l’adresse est renseignée dans le fichier /etc/hosts ;
- le cache est valide 5 minutes sur les réponses HTTP valides ;
- on ajoute les en-têtes X-Real_IP et X-Forwarded-For afin de transporter l’IP réelle du visiteur et non uniquement cette du reverse proxy jusqu’au serveur web de destination.
Nous aborderons le thème des certificats plus loin dans cet article, mais notons pour le moment que c’est le reverse-proxy qui jouera le rôle de « terminaison SSL », on complétera par conséquent la configuration ci-dessus avec un autre bloc server qui écoutera sur le port 443 et muni des certificats adéquats.
2. La nouvelle victime
Pour rappel, l’objectif de cet exercice est de migrer et rassembler mes machines clairsemées au gré des années dans différentes infrastructures. GCU était hébergé chez mon ancien employeur, et notre nouvelle victime, chez Online / Scaleway : la machine virtuelle qui gère mes services fondamentaux, senate.De quoi parle-t-on, oh, trois fois rien :
- DNS primaire et master ;
- MX primaire ;
- serveur IMAPS ;
- site web ;
- MUA ;
- client IRC.
Oui, oui, tout ça sur une seule machine virtuelle NetBSD. Mes plans, à terme, pour ces services sont plus ambitieux que de simplement migrer la machine virtuelle qui les héberge, mais chaque chose en son temps, mon premier objectif consiste à déplacer cette VM de chez son hébergeur actuel vers ma dataétagère.
Avant d’aller plus loin, il est nécessaire d’autoriser ces flux côté AWS, pour cela, nous allons éditer les inbound rules du security group associé à notre instance pour obtenir les autorisations présentées en Figure 2.
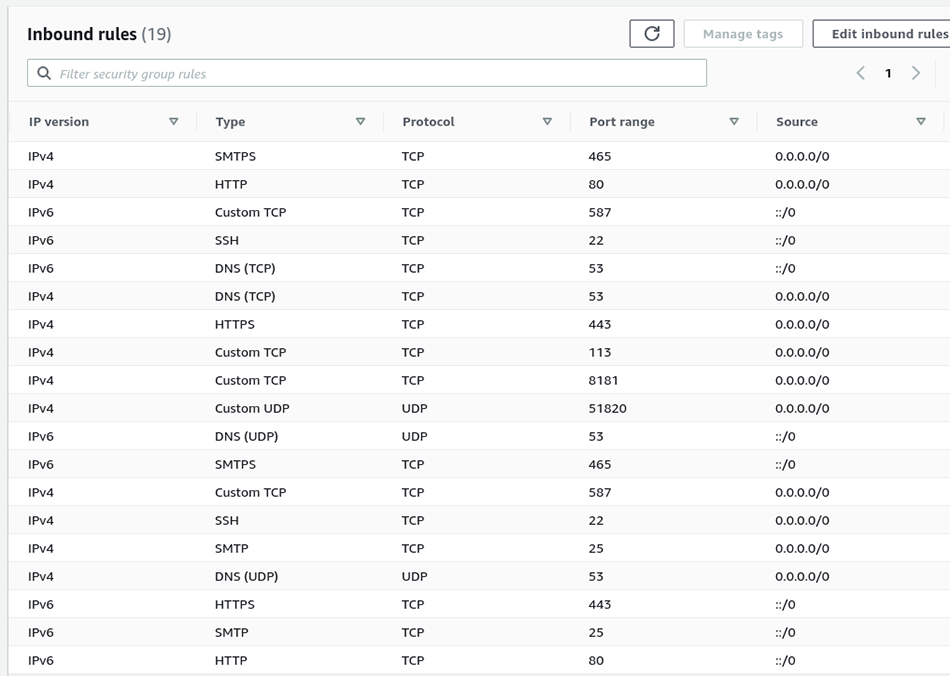
Notez que tous les services publics sont configurés pour autoriser le trafic IPv4 et IPv6. Nous y reviendrons.
Comme nous l’avons vu dans l’épisode précédent, le raccordement d’une machine NetBSD à un serveur Wireguard s’effectue à travers l’interface wg(4), seulement voilà, senate date un peu, sa version est 9.0 dans laquelle le pilote wg n’est pas disponible. Qu’à cela ne tienne ! La mise à jour d’un système d’exploitation NetBSD s’effectue de façon très simple avec l’outil sysupgrade téléchargeable avec, par exemple, le gestionnaire de paquets binaires pkgin.
Si on mettait à jour notre système sur une version mineure supérieure, par exemple une migration de 9.0 à 9.3, on pourrait utiliser la commande suivante :
Mais comme nous passons à une nouvelle version majeure, un peu plus de soin est nécessaire. Tout d’abord, une précision, lorsque j’ai effectué cette migration, et à l’heure où j’écris ces lignes, la version finale de NetBSD 10 n’est pas encore disponible, il s’agit d’une version bêta. Il est néanmoins possible de télécharger les binaires de mises à jour sur http://nycdn.netbsd.org/pub/NetBSD-daily/netbsd-10/.Ainsi, on peut utiliser sysupgrade de la sorte, tout d’abord pour récupérer les archives (sets) nécessaires :
Puis on met à jour le noyau ainsi que ses modules :
On redémarre sur ce nouveau noyau afin de pouvoir exécuter les binaires NetBSD 10 que nous allons installer :
Nous pouvons dès lors mettre à jour les sets binaires qui contiennent les outils, bibliothèques et configurations du système de base :
Il faut mettre à jour /etc avec les nouveaux paramètres, scripts d’init et potentiels nouveaux fichiers de configuration :
On réalise les tâches de post-installation, par exemple l’effacement des fichiers inutiles ou la mise à jour de certains paramètres :
Reste à nettoyer les archives téléchargées :
Et rebooter sur notre nouveau système :
3. La technique à tonton
Je sais pas pour vous, moi, les migrations, ça me stresse. Il y a toujours quelque chose qui se passe mal. Et mon plan initial était périlleux, je prévoyais en effet de copier la machine virtuelle sur ma passerelle en ayant préalablement préparé le réceptacle, d’activer le tunnel Wireguard en n’oubliant pas de modifier l’adresse de la passerelle, de la machine, la route par défaut, les DNS, les certificats… beaucoup trop d’opérations à effectuer en un coup.
Et puis l’idée.
Pourquoi ne pas monter le tunnel Wireguard avant de migrer, ainsi avant même de déplacer la machine virtuelle, on pourra configurer les enregistrements DNS pour qu’ils pointent vers sa destination finale, l’IP de l’instance AWS tout en gardant ses routes et IP actuelles, le temps de tout configurer in-situ et simplement déplacer le block device une fois tout préparé ?
Je vous vois tiquer d’ici : mais si la VM a déjà une route par défaut, quel mécanisme tortueux vais-je mettre en place pour qu’elle réponde aux requêtes en provenance de l’Internet passant par l’instance EC2 puis le tunnel Wireguard ? En un mot comme en cent : pf(4).
Voyez-vous, pf(4) dispose de deux mécanismes que j’affectionne particulièrement, route-to et reply-to. Ces deux paramètres d’une règle pass permettent respectivement :
- de router le trafic vers un couple interface / passerelle spécifique fonction d’un match de règles, par exemple « router le trafic en provenance de l’IP 192.168.1.10 vers l’interface wg0 vers la passerelle 172.16.1.1 » ;
- de répondre à une requête qui match une règle sur un couple interface / passerelle donné.
Dans notre cas, la règle est la suivante :
De toute beauté n’est-ce pas ?
Afin de valider notre théorie, nous allons charger les règles de pre-routing suivantes sur notre « routeur », l’instance EC2, afin de rediriger le trafic en direction des ports 25 (SMTP), 53 (DNS), 465 (SMTPS) et 587 (Submission) :
Sur senate, nous configurons l’interface Wireguard wg0 comme nous l’avions fait pour la machine GCU :
Et on enregistre cette configuration dans le fichier /etc/ifconfig.wg0 :
Enfin, nous lançons la commande pfctl -f /etc/pf.conf afin de charger la règle reply-to et les réponses en provenance de l’Internet passant par wg0 reçoivent bien une réponse.
On prendra soin de graver dans le marbre les règles de pre-routing de l’instance t4g :
Et pour faire les choses proprement, on crée un lien de ce script vers /etc/network/if-post-down.d pour que ces règles soient effacées lorsque l’interface wg0 est descendue.
4. J’vous jure que c’est moi m’sieur l’agent !
Ce n’était pas une nécessité absolue, mais comme j’ajoute un FQDN à la liste des hôtes que je veux pouvoir identifier par un certificat TLS, j’ai régénéré un certificat Let’s Encrypt. Là encore, étant donné le nombre gigantesque de tutoriels disponibles sur la Toile, j’irai droit au but.
J’utilise, pour la gestion de mes certificats, le très convivial lego, son utilisation initiale s’écrit ainsi :
Le mode HTTP de lego est simple et rapide à mettre en place, ici ce dernier démarre un serveur web qui répondra aux requêtes Let’s Encrypt sur le port 8181 et les certificats seront sauvegardés dans le répertoire /home/imil/etc/le.
Pour que ceci fonctionne, il faut ajouter la location suivante dans la configuration de notre reverse proxy nginx :
/.well-known/acme-challenge est le chemin interrogé par Let’s Encrypt, nous créons donc une règle proxy_pass qui transférera les requêtes vers ce chemin au serveur lego sur le port 8181.
Il conviendra d’automatiser le renouvellement par exemple à l’aide d’un cronjob :
Cette tâche s’exécutera tous les jours à 1h du matin en mode renew.
Les certificats sont générés et présentés par le reverse proxy fonctionnant sur l’instance t4g, mais ces derniers doivent également être utilisés par d’autres services comme le mail, et eux tournent sur la machine virtuelle FreeBSD auto-hébergée. Dans la précédente mouture de mon petit setup, l’hôte faisant tourner le reverse proxy exportait en NFS le répertoire des certificats vers la machine de services, senate, mais il s’agissait d’une machine virtuelle gérée par l’hôte lui-même, pas de soucis de latence à prévoir, dans notre cas, la VM bhyve et le routeur public sont distants de 2000km et reliés via un tunnel, pas la configuration idéale pour mon montage réseau.
À l’heure où j’écris ces lignes, je ne suis pas encore vraiment satisfait de la solution que j’ai mise en place, je vous livre néanmoins son fonctionnement.
Tout d’abord, sur le routeur, nous ajoutons une location nginx interrogeable uniquement par senate :
Et nous assurons de placer les certificats téléchargés par lego dans la location en question avec les permissions correctes à l’aide du script suivant :
Puis on exécute ce script toutes les nuits :
Sur senate, le script suivant va vérifier si les fichiers présents sur le routeur sont différents de ceux disponibles dans la machine virtuelle et les écraser le cas échéant :
J’ai créé pour l’occasion le groupe mail qui permet à mon utilisateur, mais également à postfix et dovecot d’utiliser ces certificats :
Le script est lui aussi lancé par un cronjob :
Et finalement, si le certificat a changé, le logiciel direvent(8) exécutera à son tour un autre script. direvent est un utilitaire disponible dans pkgsrc similaire à inotifywait, il s’agit d’un petit utilitaire qui monitore l’activité dans un répertoire donné, dans notre situation nous le démarrons via la commande suivante :
avec le fichier de configuration suivant :
On regarde l’activité du répertoire /home/imil/etc/le, et lorsqu’un événement d’écriture a lieu, on invoque le script /home/imil/bin/mailrestart.sh qui pour sa part a cette forme :
Reste à s’assurer que nos démons vont bien lire les certificats dans leur nouvelle localisation :
Et voilà, la mise à jour automatique des certificats est fonctionnelle, la technique est cependant très perfectible.
5. Voile à bâbord !
Nos services sont désormais capables de répondre sur les deux pattes publiques, l’originale, IP publique de notre bientôt-ex-dédié, et via le routeur chez AWS. Le vrai test commence maintenant : il faut croiser les effluWW^Wbasculer les entrées DNS !
Notre serveur répond sur l’Internet avec les hôtes suivants sur le domaine imil.net :
- ns1 et ns6, respectivement DNS maître IPv4 et IPv6 ;
- senate, le nom générique associé à l’IP publique ;
- mail, le MX (Mail eXchanger) de mon domaine ;
- www, le point d’entrée HTTP/S ;
- ingress, le nom associé à l’instance.
Afin de réduire le temps de propagation des informations DNS que nous allons changer, il sera de bon aloi de passer le TTL (Time To Live) à, par exemple, 5 minutes. J’utilise le bon vieux serveur DNS Bind, aussi cette configuration s’effectue dans le fichier de zone, en ajoutant cette directive après l’origine :
Une fois le serial augmenté et la zone rechargée, les changements seront propagés aux DNS slaves, Gandi dans mon cas. Idéalement, cette modification est à effectuer bien avant la modification des adresses de façon que ces dernières se propagent plus rapidement.Voici l’extrait de la zone imil.net qui va être mise à jour :
Un rndc reload imil.net plus tard, la zone est rechargée sur senate et les transferts vers les slaves sont effectués. Nous reviendrons sur la configuration IPv6 un peu plus loin.Ça y est ! L’IP d’« entrée » de mes services publics a basculé, la machine virtuelle qui les fait fonctionner, encore hébergée chez Scaleway à ce stade, est certes toujours capable de répondre sur l’une ou l’autre des adresses, mais c’est désormais sur l’IP AWS qu’elle est interrogée.
Mais alors… c’est le moment tant attendu ? ON MIGRE !
L’opération a eu lieu vers 5h30 du matin, oui que voulez-vous mon grand âge semble avoir un impact sur mes horaires de sommeil. Après avoir soigneusement shutdown senate (je sais que vous comprenez le sentiment), j’ai opéré son transfert de la même façon que la machine virtuelle GCU dont je vous entretenais dans le précédent article :
« Bourrin » « bourrin », comme vous y allez, je récupère à travers une liaison SSH l’entièreté des octets du block device contenant les données de la machine virtuelle, pas de fastidieux rsync ou de hasardeux ansible, c’est la machine complète, configurée, prête à servir qui va se retrouver dans environ 2h sur l’hôte Bhyve.
Comme nous l’avons vu dans l’article précédent, la configuration de la machine virtuelle lue par vm-bhyve est de cette forme :
Mais point d’empressement, car notre image disque fraîchement transférée est encore configurée avec le sous-réseau que j’utilisais dans son ancien hôte, et sa route par défaut pointe vers ce même hôte. Comme nous l’avons fait pour la précédente VM, nous devons modifier l’IP de la machine dans le fichier /etc/ifconfig.vioif0, désactiver la mise en place d’une route par défaut et renseigner les nouvelles valeurs dans le fichier /etc/ifconfig.wg0.
Pour effectuer ces modifications, nous allons démarrer la VM en mode single user ; pour cela, soit nous appuyons sur une touche lors du compte à rebours et choisissons l’option 2 « Boot single user », soit nous modifions la ligne grub_run0 du fichier de définition de notre machine virtuelle et ajoutons le flag -s, qu’il ne faudra pas oublier de changer au prochain redémarrage. Dans tous les cas, on utilisera la commande vm start -fi senate pour démarrer la VM en mode console sur le terminal.
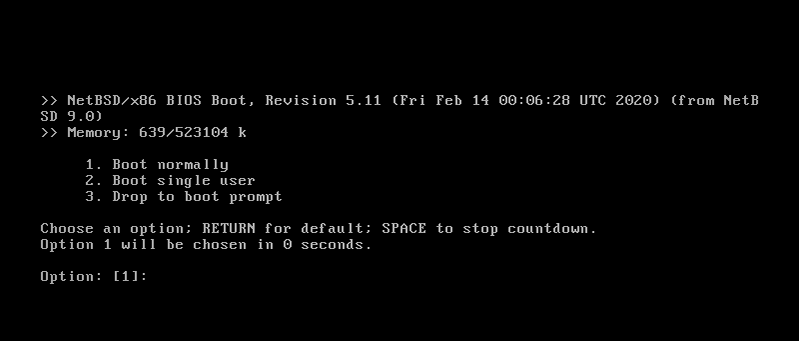
Voici le contenu du nouveau /etc/ifconfig.vioif0 :
Et surtout, le nouveau contenu du fichier de définition de l’interface wg0 :
On notera ici l’ajout d’une route explicite vers le routeur t4g qui passe par la passerelle du réseau d’hébergement pour avoir accès au serveur de tunneling. Une fois cette route ajoutée, on route tout le trafic vers l’interface Wireguard. Puisque la route par défaut de notre VM est désormais le tunnel, on commentera la ligne defaultroute du fichier /etc/rc.conf.
Finalement, puisque cette machine n’est plus connectée qu’à un seul point de sortie, notre règle pf(4) n’a plus lieu d’être, aussi on pourra simplement désactiver ce dernier :
Et lui préférer npf(7) pour implémenter du firewalling, celui-ci ayant été choisi comme solution de filtrage de paquets par NetBSD. Bien que légitime pour des raisons de performances, on regrettera que ce choix ait été précipité avant que npf n’implémente route-to et reply-to.
Une fois ces modifications effectuées, on reboote notre VM pour constater que les modifications sont bien prises en compte, et, oh joie, une fois le tunnel monté, le trafic arrive bien de l’Internet vers notre serveur auto-hébergé.
6. IPv6 c’est demain !
J’entends encore, en 2003, les commerciaux de la société 6wind nous dire « IPv6 c’est demain ! L’année prochaine tous les opérateurs vont commencer à migrer ! » ah-ah, le bon vieux temps.Nous sommes 20 ans plus tard (…) et IPv6 est encore vu comme un gadget par nombre de professionnels. Néanmoins, il était inenvisageable que https://imil.net ne réponde pas sur la pile IPv6. Le challenge ici, était de router l’IPv6 depuis l’instance AWS jusqu’à notre machine virtuelle, et je dois l’astuce à hobgoblinsmaster sur le canal #GCU@libera.chat qui m’a pointé cette documentation https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-prefix-eni.html, AWS prévoit en effet la possibilité de router des « petits » préfixes vers une interface. Pour ce faire, sélectionner, pour l’interface voulue (celle attachée à votre instance dans 90% des cas), le menu de gestion des préfixes puis choisir un préfixe IPv6 à router sur cette interface.
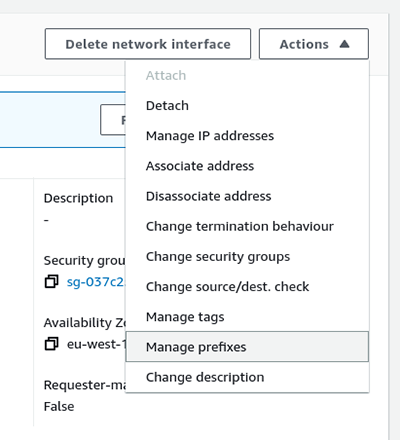
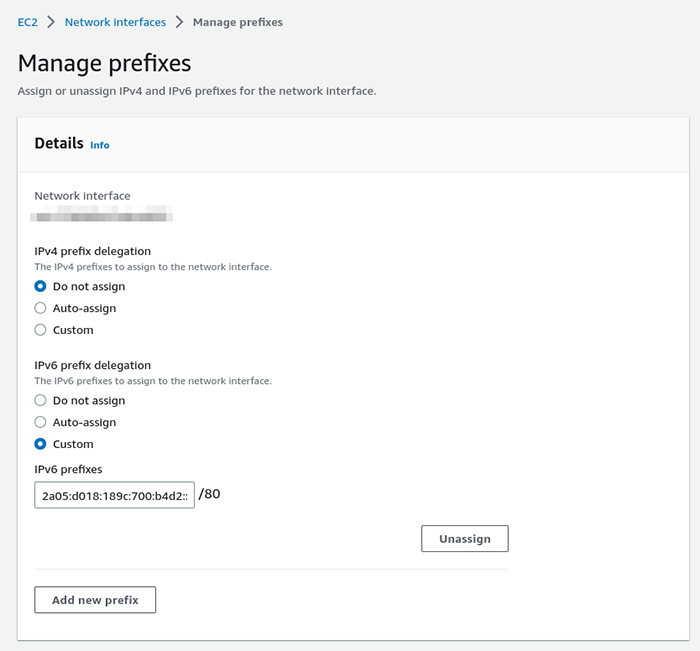
Modulo cette manipulation, le sous-réseau 2a05:d018:189c:700:b4d2::/80 est routé via l’interface de l’instance.
Attention : Pour que le routage fonctionne, comme nous l’avons fait la dernière fois, il faut impérativement passer l’option Source / Dest check à false, toujours dans le menu de gestion des l’interface.
Une fois cette opération réalisée sur la console AWS (probablement réalisable via la CLI awscli), le reste des manipulations est à mener sur nos machines de façon parfaitement standard. Tout d’abord, assurons-nous que l’IPv6 parvient bien jusqu’à notre instance :
Pour les vétérans de l’IPv6, le projet KAME était le projet d’implémentation d’IPv6 sur tous les systèmes BSD UNIX, il est achevé depuis 2006.
Ajoutons maintenant une IPv6 sur l’interface Wireguard ainsi qu’une route statique vers l’IPv6 que nous affecterons à senate :
On grave ces changements dans la définition de l’interface dans le fichier /etc/network/interfaces.d/wg0 :
Pour autoriser le trafic sur la patte IPv6 du tunnel, il convient d’autoriser ce dernier, d’abord dans le fichier /etc/wireguard/wg0.conf sur le routeur :
Ne pas oublier non plus d’autoriser ce routeur à… router !
Et sur notre VM auto-hébergée, ajouter les informations concernant la connexion IPv6 dans le fichier de définition de l’interface :
Nous avons ajouté une IPv6 sur l’interface, autorisé le trafic en provenance de n’importe quelle adresse IPv6 (::/0) et ajouté une route par défaut sur le réseau public IPv6. Afin d’éviter un reboot, nous réalisons ces opérations manuellement :
Et logiquement, nous devrons pouvoir pinger notre routeur :
Ainsi que l’Internet v6 :
Yatta !
7. Comment ça « j’ai rien reçu » ??
Fier comme Artaban, je regarde mes logs défiler avec une certaine satisfaction, et alors que j’ai envoyé un correctif sur l’article précédent à Diamond quelques jours plus tôt, je m’étonne de ne pas avoir de réponse… pris d’un doute, je lance la commande mailq sur senate afin de voir combien de mails sont en file d’attente et la, horreur, plus de 500 mails non envoyés (dont de nombreux MAILER-DAEMON évidemment) ! Mais pourquoi ?
Un simple telnet vers le port 25 d’un serveur SMTP quelconque depuis l’instance AWS répond à la question, en effet, comme expliqué dans cette documentation https://aws.amazon.com/premiumsupport/knowledge-center/ec2-port-25-throttle/ qui m’avait totalement échappé, par défaut, l’accès au port 25 d’hôtes distants est bloqué, ceci pour éviter d’héberger sans vergogne des plateformes de spam. Fort heureusement, comme l’indique la documentation, le remplissage d’un simple formulaire justifiant de l’utilité de l’accès au port 25, et les preuves de la bonne configuration de votre serveur mail (en particulier l’utilisation de SPF et DKIM) suffisent à obtenir cette autorisation.
8. On n’est pas bien là, la carte mère à l’air ?
Et voilà, le « gros morceau » a migré, je vais bientôt pouvoir annuler mon dédié, il reste quelques services à déplacer, mais rien d’aussi minutieux ni alambiqué. Alors que j’écris ces lignes, la zone imil.net et ses services sont hébergés derrière moi depuis plus d’un mois, je garde un œil attentif sur les logs, mais tout semble ronronner, nous verrons bientôt comment cette « infrastructure » réagit à un déménagement physique, mais tout étant articulé autour d’un tunnel, cela ne devrait pas poser de problèmes… (famous last words)
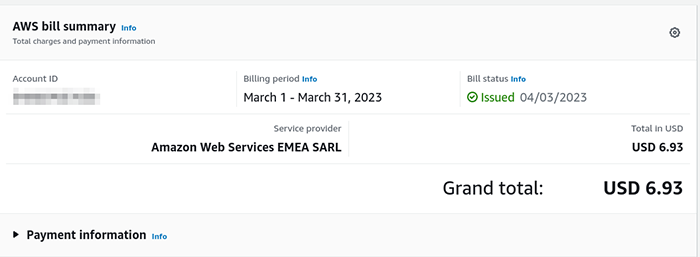
Pour finir, le nerf de la guerre, le prix total de mon « infrastructure » de routage chez AWS est resté stable, entre $5 et $7 par mois, il convient de bien suivre son utilisation, et en particulier sa consommation réseau, pour éviter les surprises. La consommation électrique de la dataétagère elle est stable à environ 3kWh/jour, pour le mois de mars 2023, cela correspond à une somme de 14€. Soit une somme mensuelle totale d’environ 20€, à comparer aux 50€ mensuels, je divise la facture par plus de 2. notbad.jpg.

9. Deux semaines plus tard...
Un timing parfait. Nous voici deux semaines après l’écriture de l’article et j’ai littéralement déménagé d’appartement, avec la dataétagère. Verdict : 30 minutes de downtime.
Le mouvement des machines a été la priorité, car désormais elles hébergent tous mes services, y compris le mail, il y a donc eu un premier voyage qui comprenait globalement uniquement cette infrastructure, pour ne pas perdre de temps. J’avais préalablement pris des photos du câblage pour le reproduire verbatim et ne pas réfléchir aux positions. Branchement du NAS en premier, c’est lui qui contient les disques des machines virtuelles, puis la passerelle, qui fait tourner les VM en question. vm console senate, elle a démarré. tail -F /var/log/maillog, je reçois mon premier SPAM, nous sommes up.
Pas le même endroit, pas le même fournisseur d’accès, mais toujours le même routeur, notre instance AWS. Pour Internet, rien n’a changé.

L’aventure est-elle finie pour autant ?… j’ai des plans diaboliques. Savez-vous qu’on peut faire booter une machine virtuelle NetBSD en 100ms ? Quelle classe ce serait de diviser tous ces services en micro-services, chacun sur sa micro-vm NetBSD dédiée, non ?
On en reparle.
Référence
[1] https://connect.ed-diamond.com/linux-pratique/lp-137/la-grande-migration-episode-i


