

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Il arrive parfois un jour où, ça y est, vous avez pris votre décision, le courage et l’envie sont là, c’est le moment : on va migrer. D’une ancienne technologie à une plus récente, par impératif professionnel, personnel, parce que c’est plus cohérent dans vos nouvelles coutumes, vous voyez exactement de quoi je parle, on frappe dans ses mains, on regarde le chantier, et on dit à voix haute : c’est parti.
1. L’état des lieux
Nous sommes nombreux à posséder des machines, virtuelles ou non, éparpillées aux quatre vents, un dédié par-ci, une machine historiquement hébergée chez votre ancien employeur, des machines virtuelles dans différents clouds… et jusqu’à récemment en tout cas. Pour ma part, cela se traduisait ainsi :
- une machine « perso » chez Scaleway, un Intel(R) Xeon(R) CPU E3-1220 V2 @ 3.10GHz muni de 16G de RAM DDR3 sous Debian GNU/Linux 10. Cette machine physique accueille 3 machines virtuelles fonctionnant sous NetBSD 9.2 :
- un serveur web (nginx), mail (postfix), DNS (bind) et client IRC (irssi) ;
- un serveur OpenVPN ;
- un client de backup (rsync).
- Coût : 50€ / mois.
- la machine du groupe GCU-Squad, jusqu’à il y a peu hébergée chez mon ancien employeur, un fier Intel(R) Xeon(R) X5450 @ 3.00GHz, muni de 8G de RAM DDR2 FB-DIMM qui faisait tourner les machines virtuelles suivantes :
- un serveur web (nginx) sous NetBSD ;
- une machine de services (mail (exim) et DNS (nsd)) sous OpenBSD ;
- une machine shell dans laquelle chaque membre avait un accès SSH, sous OpenBSD ;
- un serveur pour le site web NetBSDfr, bien évidemment sous NetBSD.
- Coût : 0€ / mois.
- une instance AWS t4g.nano (2 cores ARM aarch64 / 512M RAM) sous Debian 11 initialement utilisée comme bastion de secours.
- Coût : 3€ / mois.
Les plus assidus se souviennent peut-être de zone0 qui avait bénéficié d’un article dans GNU/Linux Magazine France n.100 (❤), dans lequel nous décrivions, en 2007, le setup complet d’un hyperviseur Xen (dom0) muni de 4 domUs, ce sont ceux-là même qui ont ensuite migré de Xen vers KVM dans la zonex sus-citée. Oui, vieux comme ça.
Mais la vie n’est pas un long fleuve tranquille, et on ne reste pas indéfiniment dans la même structure, surtout dans nos métiers, et bien que mes fantastiques collègues de l’époque se sont démenés pour garantir la survie de zonex dans les baies de ce qui furent « mes » cages, il était temps de reprendre possession de l’infrastructure et la migrer dans un endroit dans lequel je serais plus à même d’intervenir. Proche. Nous y reviendrons.
Deuxième cas de figure, deuxième nécessité, le dédié.
Peu ou pas d’inquiétude particulière quant à la survie de l’offre d’hébergement sur laquelle mon serveur personnel s’inscrit, mais vous le savez, ces derniers mois, les prix, tous les prix se sont envolés, et en particulier celui de l’électricité. Conséquence directe de cette envolée, le prix de l’hébergement informatique s’est aussi vu affubler quelques pour cent en plus.
50€ par mois, ce n’est pas rien. 600€ par an, ça fait s’interroger sur le nécessité, finalement, de faire héberger cette machine ailleurs.
Son utilité n’est pas discutable, elle héberge finalement mes services que je ne souhaite pas envoyer à un service clé en main. Premièrement parce que ce sont mes données, et bien que peu intéressantes pour des agences de renseignement, elles m’appartiennent et je ne souhaite pas qu’elles soient scrutées par d’autres. Ensuite, et c’est pour moi une raison au moins aussi importante : je veux continuer à maintenir ces services de base, je veux garder la main. Mes MX, mes démons, mon serveur HTTP/S.
Mais alors si je n’hébergerai plus « ailleurs », cela signifie que je compte héberger chez moi ! L’auto-hébergement, la quintessence de l’autonomie numérique certes, mais pas sans quelques difficultés tant techniques que pratiques.
2. Factorisation
Je me souviens, il y a bien des années, plus j’empilais les machines dans mon datace^Wma buanderie, plus j’aimais ça. Une machine un service on disait. Un firewall, un NAS, un serveur web, aucune idée de leur consommation respective, aucune idée de ma consommation globale d’ailleurs, les factures électriques de l’époque ne pesaient pas si lourd qu’aujourd’hui.
La situation est très différente aujourd’hui, et l’explosion du prix de l’énergie m’a amené à m’équiper de prises murales « intelligentes » flashées avec le firmware libre Tasmota pour constater qu’en situation normale l’ensemble de mes machines « infrastructure » consommaient autour de 1kWh. C’est beaucoup. Cette « dataétagère » était composée de :
- un NAS sous FreeBSD muni d’un Intel i3-4130, TDP, ou thermal design power de 54W ;
- une passerelle sous FreeBSD munie d’un Intel i7-920, TDP de 130W (!!) ;
- une vm-box, machine accueillant mes machines virtuelles de test ou d’hébergement, munie d’un AMD Phenom II X6 1055T, TDP 95W.
Il y avait clairement matière à optimisation. Par chance, éparpillée façon puzzle dans mon bureau, je disposais d’une carte mère pouvant accueillir un i3-2120 au TDP de 65W qui remplacera avantageusement le vieux et gourmand i7-920.
Quant au Phenom, il allait simplement disparaître, et ses machines virtuelles ventilées… ailleurs.
3. Enchanté, Bhyve
Ailleurs ailleurs, c’est vite dit ! 10 ans de KVM / QEMU ça marque, j’avais tous mes repères moi. Les candidats à la réception des machines virtuelles anciennement hébergées sur le Phenom étaient :
- ma workstation Linux ;
- mon firewall FreeBSD ;
- mon NAS FreeBSD.
Il était clairement hors de question d’héberger quoi que ce soit sur ma station de travail, la mémoire du NAS est déjà bien occupée par ZFS, reste la passerelle / firewall qui, munie de son nouveau i3 2120 se tourne les pouces allègrement. Quelques barrettes de mémoire supplémentaires en feraient un hôte parfaitement convenable pour des machines virtuelles faiblement sollicitées.
L’hyperviseur de FreeBSD s’appelle Bhyve, ce dernier avait été présenté dans ces colonnes dans le numéro 74 de GNU/Linux Magazine… en 2014. Comme vous pouvez vous en douter, les choses ont évolué en pratiquement 10 ans, et si à l’époque la création d’une machine virtuelle requérait l’empilage d’un certain nombre de paramètres à la commande bhyve, il existe aujourd’hui des interfaces bien plus commodes et fort bien ficelées pour administrer vos VM sous FreeBSD. N’étant pas très téméraire, j’ai jeté mon dévolu sur celle qui m’a semblé la plus mature et la plus utilisée : vm-bhyve. Cet outil en ligne de commandes est en réalité un script shell de toute beauté dont l’utilisation est très intuitive. La documentation est claire, le projet est vivant (j’ai demandé un pull request sur la documentation, il a été effectué en 2 jours), et après un rapide sondage sur Twitter, c’est la solution qui s’est nettement détachée.
Le firewall en question ne disposant que d’un disque SSD unique, les disques des machines virtuelles seront stockés sur le NAS, les deux machines étant reliées en gigabit, la bande passante suffira amplement à travailler avec des données exportées en NFS depuis le NAS.
Sur le NAS, nous avons :
Et côté firewall, nous avons :
Un mount plus loin, nous vérifions que nous avons bien accès en lecture et écriture dans le répertoire /mnt/newcoruscant.
L’installation de vm-bhyve s’effectue avec le gestionnaire de paquets binaires pkg :
Et pour démarrer des machines virtuelles contenant d’autres systèmes d’exploitation que FreeBSD :
Comme n’importe quel service dans FreeBSD, on déclare son exécution au lancement du système de cette façon :
vm_enable="YES"
vm_dir="/mnt/newcoruscant/vm" # on déclare où se trouvent les machines virtuelles
EOF
Et puisque nous ne redémarrons pas la machine, nous lançons la commande vm init qui va initialiser les répertoires nécessaires au fonctionnement de vm-bhyve et charger les modules noyau adéquats.
La dernière étape de préparation de vm-bhyve consiste à copier les templates de configuration relatifs aux systèmes d’exploitation que nous allons virtualiser, ceci s’effectue avec un banal cp :
C’est prêt.
4. Mon petit réseau
Je vous entends grommeler depuis tout à l’heure « mais comment ça il va monter des VM qui seront accédées publiquement sur son firewall ?! HÉRÉTIQUE », oui, oui, je sais. Hérétique peut-être, mais pas inconscient.
Le firewall en question est muni de 4 interfaces :
- interne, privée ;
- interne, invités et domotique diverse ;
- interne, hébergement des machines virtuelles ;
- externe, connexion à la box internet.
Les VLAN sont parfaitement supportés sous FreeBSD, mais j’ai souhaité une isolation physique entre ces réseaux sur cette machine, et de surcroît, le réseau qui connectera les machines virtuelles sera bloqué par défaut d’accéder aux autres réseaux, voici la règle pf(4) associée :
hosting_net="192.168.14.0/24"table <rfc1918> const { 192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }# [...]block drop log from $hosting_net to <rfc1918>
vm-bhyve utilise le concept de switch pour fournir de la connectivité à une machine virtuelle, et en particulier, on peut attacher ces switches à une interface physique. Il ne s’agit en réalité que de bridges et on peut les visualiser avec un simple ifconfig.
Considérant que l’interface qui accueillera les machines publiques est re2, on configure le switch de la façon suivante :
# vm switch add public re2
# vm switch address public 192.168.14.254/24
Une fois cette configuration effectuée, on peut visualiser son résultat à l’aide de la commande suivante :
NAME TYPE IFACE ADDRESS PRIVATE MTU VLAN PORTS
public standard vm-public 192.168.14.254/24 no - - re2
Et constater son effet plus bas niveau à l’aide de la commande ifconfig :
NAME TYPE IFACE ADDRESS PRIVATE MTU VLAN PORTS
public standard vm-public 192.168.14.254/24 no - - re2
Et constater son effet plus bas niveau à l’aide de la commande ifconfig :
$ ifconfig vm-public
vm-public: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 36:44:1d:e9:c3:2e
inet 192.168.14.254 netmask 0xffffff00 broadcast 192.168.14.255
id 00:00:00:00:00:00 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 2000 timeout 1200
root id 00:00:00:00:00:00 priority 32768 ifcost 0 port 0
member: tap1 flags=143<LEARNING,DISCOVER,AUTOEDGE,AUTOPTP>
ifmaxaddr 0 port 11 priority 128 path cost 2000000
member: tap0 flags=143<LEARNING,DISCOVER,AUTOEDGE,AUTOPTP>
ifmaxaddr 0 port 10 priority 128 path cost 2000000
member: re2 flags=143<LEARNING,DISCOVER,AUTOEDGE,AUTOPTP>
ifmaxaddr 0 port 4 priority 128 path cost 55
groups: bridge vm-switch viid-4c918@
nd6 options=9<PERFORMNUD,IFDISABLED>
Dans cet exemple, en plus de l’interface re2, deux machines virtuelles sont déjà attachées à ce bridge.
5. Dédé, ton ami pour la vie
La première machine à migrer vers notre nouvel hébergement sera la VM du groupe GCU. Il s’agit d’une simple machine virtuelle démarrant sur un volume logique LVM, que nous devrons transporter dans une image disque. Nous effectuons cela de la façon suivante, après avoir éteint la machine virtuelle :
Oui, c’est un peu violent, mais ça marche ! Avec cette commande, nous faisons transiter à travers la connexion SSH les octets qui peuplent le volume logique « gcu » dans le volume group « vmsvg » de la machine zonex, et les inscrivons dans une image disque brute que nous utiliserons pour la future VM « gcu » auto-hébergée.
Notre image étant désormais disponible, nous pouvons procéder à la création de la machine virtuelle au sein de vm-bhyve. Nous l’avons vu précédemment, des fichiers templates sont disponibles, ils contiennent des configurations types pour différents systèmes d’exploitation :
alpine.conf coreos.conf freepbx.conf resflash.conf
arch.conf debian.conf gentoo.conf ubuntu.conf
centos6.conf default.conf linux-zvol.conf windows.conf
centos7.conf dragonfly.conf netbsd.conf
config.sample freebsd-zvol.conf openbsd.conf
On fait référence à ces templates à l’aide du flag -t. Et puisque nous disposons déjà d’une image disque, nous spécifions une taille de « 0 », simplement pour s’économiser le temps de sa création :
La configuration générée est la suivante :
loader="grub"
cpu=1
memory=256M
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
grub_run0="knetbsd -h -r ld0a /netbsd"
uuid="c9a3afed-7d3c-113d-a2ee-6909ca24f3c4"
network0_mac="58:ac:ec:e3:f1:9a"
Bien que cela ne pose aucun problème à NetBSD de démarrer avec 256M de mémoire, puisque cette machine sera le futur serveur web, nous nous offrons le luxe de monter cette valeur à 512M. On prend soin de déplacer l’image gcu.img précédemment transférée vers /mnt/newcoruscant/vm/gcu/disk0.img. Le template NetBSD déclare une partition root sur un device dk0, or nous utilisons les drivers disque VirtIO, nous devrons donc modifier cette valeur à ld0a, soit la première partition du disque ld0, qui représente un disque de type VirtIO. Les autres paramètres du fichier de configuration de la machine virtuelle ne nécessitent pas de changement.
Notre VM est maintenant prête à démarrer ! Évidemment, vm-bhyve permet d’interagir avec la machine à travers une console via le port série virtuel ; par défaut, le logiciel qui permet cette interaction est cu, mais vm-bhyve intègre également le support de tmux, on peut configurer son utilisation dans le fichier .config/system.conf situé dans le répertoire de travail de vm-bhyve :
switch_list="public"
type_public="standard"
addr_public="192.168.14.254/24"
ports_public="re2"
console="tmux"
C’est également dans ce fichier que sont enregistrés les paramètres des switches précédemment configurés.
Pour démarrer notre VM fraîchement migrée, on utilise la commande vm start <nom de machine>, et si on souhaite voir se dérouler la séquence de démarrage, on y ajoute le flag -f :
On verra alors une invite grub qui présente une entrée vers un noyau NetBSD. Si tout se passe bien, une fois le timeout passé ou la touche [Entrée] pressée, le noyau devrait démarrer, suivi d’init.
Afin d’automatiser le démarrage de la VM lors de l’amorce de la machine physique, on ajoutera la ligne suivante au fichier /etc/rc.conf de l’hyperviseur FreeBSD :
La variable vm_list contient la liste des machines virtuelles à démarrer, et vm_delay le nombre de secondes à attendre entre chaque démarrage de VM.
6. La caverne
Notre machine démarrée, modulo un changement d’IP dans /etc/ifconfig.vioif0, elle est désormais joignable sur notre réseau. Pour répondre aux plus attentifs qui me diront que la règle de firewall mentionnée plus haut ne permettra pas au réseau « hosting » de répondre au SSH, je rétorque avec cette règle pf :
pass quick proto { tcp, udp } \ from <imilnet_allowed> to any port {22, 53}
Qui autorise les machines présentes dans la table <imilnet_allowed> de joindre n’importe quoi sur les ports SSH et DNS. Le comportement par défaut de pf est d’autoriser le trafic retour.
Très bien, mais reste la pierre angulaire de l’hébergement, en effet dans cette configuration, les machines du réseau « hosting » peuvent sortir sur Internet, mais l’Internet ne les voit pas.
Mon fournisseur d’accès à Internet ne fournit pas d’IP publique fixe, ce qui m’empêche de simplement exposer un port en utilisant par exemple les fonctionnalités de translation de la box de l’opérateur qui ne supporte pas le mode bridge.
De toute façon, cette méthode est à éviter. En effet, les plages d’adresses dédiées à l’accès sont discréditées, voire ignorées par les moteurs de recherche, mais également de nombreuses plateformes de mail. Il faut que l’IP publique qui expose nos services soit légitime.
J’ai longtemps cherché une méthode élégante, comprendre : qui n’implique pas un tunnel vers un serveur privé virtuel (VPS), mais plutôt un service qui routerait une IP ou un sous-réseau public vers ma passerelle, et si de telles solutions existent en France, elles sont inexistantes en Espagne où je vis depuis 2016. Il existe de nombreuses offres de VPN qui permettent de sortir avec une IP publique d’un pays choisi, mais rien à ma connaissance qui ne permette de router des IP publiques vers un point défini.
Solution ? Un tunnel vers un serveur privé virtuel...
C’est à partir de ces lignes que je vais m’attirer les foudres d’une partie des lecteurs, mais je vais tâcher de justifier mon choix.
Des fournisseurs de VPS, il y en a autant que d’étoiles dans le ciel. Beaucoup, de qualité inégale, et pour des prix souvent abusifs. Mon besoin, c’est une machine virtuelle ridiculement petite, dont le travail sera de :
- servir de hub public pour mon réseau d’hébergement ;
- recevoir du trafic HTTP/S et le renvoyer vers mes machines virtuelles.
Pas besoin du dernier CPU en vogue pour cela. Et en l’occurrence, l’offre la plus pratique et peu chère pour laquelle j’ai opté est une instance t4g nano chez AWS.
*esquive les tomates pourries* “vendu !” “traître !” “tU eS sOuMis aUx gAfFAmMe !”
Laissez-moi vous expliquer !
Deux cœurs de processeur ARM de type AArch64, 512Mo de mémoire, une IP publique fixe (Elastic IP dans le jargon AWS) et toutes les fonctionnalités de leur Cloud (ouh le vilain mot) pour… autour de 5€ par mois. J’ai cherché, j’ai demandé, j’ai creusé, je n’ai pas trouvé mieux. Quoi qu’il en soit, l’avantage majeur de mon setup, c’est qu’il me sera très simple de basculer vers un autre fournisseur si je jugeais cela nécessaire.J’ajoute que j’avais une contrainte de temps non négligeable.
L’instance est une bête Debian GNU/Linux Bullseye sans particularité, mais pour en faire une passerelle dans AWS il y a quelques éléments à préciser.
Premièrement, le security group : toute instance AWS est associée à un groupe de sécurité, ce dernier est très restrictif par défaut, aussi il sera nécessaire d’ouvrir les ports dont nous aurons besoin, en particulier :
- SSH (TCP/22) ;
- HTTP (TCP/80) ;
- HTTPS (TCP/443) ;
- Wireguard (UDP/51820).
Ensuite, par défaut, et c’est une très bonne chose, même si on configure du NAT sur l’instance, l’interface réseau associée à l’instance est configurée avec l’option Source/dest. check à true, c’est-à-dire que du trafic en provenance d’une autre IP que celle de l’instance sera simplement ignoré. Il faudra donc s’assurer de passer cette valeur à false.
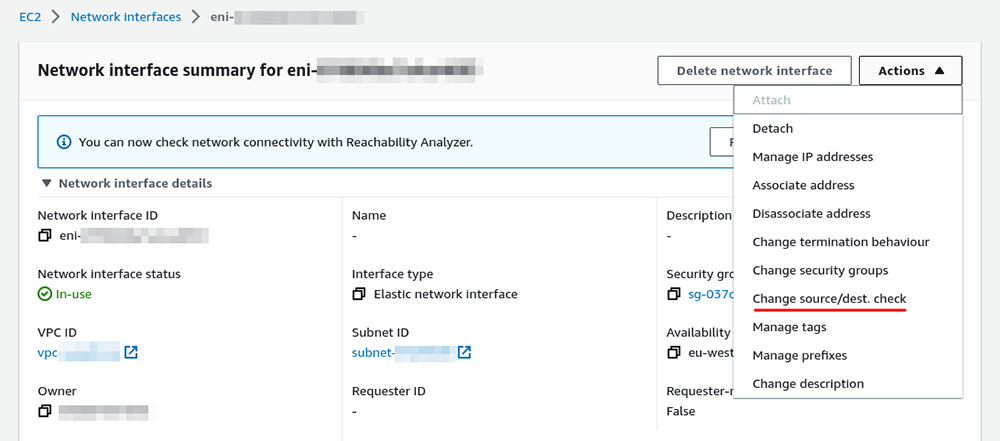
Finalement, il est nécessaire d’affecter une Elastic IP à notre VPS, en effet, l’IP publique affectée automatiquement à l’instance n’est pas fixe et il n’y a aucune garantie qu’elle sera identique lors d’une extinction / rallumage.
À savoir
Lorsqu’on reboote simplement une instance AWS, elle reste sur le même hôte, cela signifie que par exemple si on utilise du stockage éphémère (plus rapide), normalement, après un reboot simple, les données seront toujours là, et accessibles. Il en va de même avec les IP publiques assignées au démarrage. Par contre, si on éteint la machine puis qu’on la rallume, il n’y a aucune garantie qu’elle démarre sur le même hôte.
7. Pose des tuyaux
Il est maintenant temps de raccorder notre machine virtuelle à l’Internet, il est temps de faire arriver jusqu’à elle les paquets magiques.
Il existe de multiples solutions pour monter un VPN entre deux machines, le choix par défaut pour moi, jusqu’à il y a peu, ayant toujours été OpenVPN. Mais depuis quelque temps, une technologie m’attire tant par sa simplicité que sa massive adoption : Wireguard.
Par chance, la dernière version de NetBSD inclut le pilote wg(4) qui permet de se raccorder à un serveur Wireguard, et comme à son habitude, le projet a intégré cette technologie de façon très élégante.
Pour l’installation du serveur Debian, la procédure décrite par le site https://wireguard.how/server/debian/ fut une excellente source d’inspiration.
Évidemment, on installe le logiciel et ses dépendances à l’aide d’apt :
Puis on génère une paire de clés qui seront utilisées pour la connexion des clients :
Munis de la clé privée, nous pouvons créer un fichier /etc/wireguard/wg0.conf qui contiendra pour le moment uniquement ces informations :
PrivateKey = <clé privée précédemment générée>
ListenPort = 51820
J’aime la méthode proposée par ce tutoriel qui consiste à configurer l’interface wireguard wg0 à l’aide d’un fichier /etc/network/interfaces.d/wg0 :
iface wg0 inet static
address 172.16.1.1/24
pre-up ip link add $IFACE type wireguard
pre-up wg setconf $IFACE /etc/wireguard/$IFACE.conf
post-down ip link del $IFACE
Dans cette configuration, on déclare l’interface wg0 qui sera montée automatiquement au démarrage de l’instance, avec une IP statique qui sera le nœud local du serveur. On utilise iproute2 pour monter un nouveau lien de type wireguard, c’est cette commande qui chargera également les modules noyau nécessaires. On configure les informations nécessaires à Wireguard avec wg setconf en passant en paramètre l’interface et le fichier de configuration précédemment créé. Notez que cette dernière étape peut aussi s’effectuer manuellement, sans fichier de configuration avec la commande wg set, il faudra dans ce cas spécifier dans la ligne de commandes toutes les informations listées dans le fichier wg0.conf.
Cette interface va servir de routeur pour certains services de notre machine virtuelle, aussi, il est nécessaire de mettre en place du NAT, pour cela on ajoute à /etc/network/interfaces.d/wg0 les commandes suivantes :
post-down /sbin/iptables -t nat -D POSTROUTING -o ens5 -j MASQUERADE
En remplaçant évidemment l’interface ens5 par l’interface de sortie de l’instance.
Pour indiquer à la pile IP du noyau qu’elle doit transmettre les paquets qui n’ont pas pour destination les adresses locales, on active l’IP forwarding :
# echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf
La configuration du serveur est prête, et on peut faire monter l’interface à l’aide de la commande ifup, on liste l’état de la configuration des interfaces Wireguard avec la commande wg.
# wg
interface: wg0
public key: <notre clé publique>
private key: (hidden)
listening port: 51820
Notez que pour le moment aucun client, ou peer dans la terminologie Wireguard, n’est visible puisque nous n’en avons pour le moment ajouté aucun.
La configuration du client NetBSD, notre machine virtuelle cliente du serveur Wireguard est sensiblement différente, mais les mêmes pas sont nécessaires.
En premier lieu, la création des clés, cette fois avec la commande wg-keygen :
# wg-keygen --pub < /etc/wg/wg0 > /etc/wg/wg0.pub
Le support de Wireguard n’étant pas compilé dans le noyau de base, il faudra commander le chargement de son module au démarrage de la machine :
Et pour le charger immédiatement :
La configuration des interfaces, dans NetBSD, s’effectue dans un fichier /etc/ifconfig.<nom de l'interface>, aussi nous créons le fichier /etc/ifconfig.wg0 avec les informations suivantes :
!wgconfig wg0 set private-key /etc/wg/wg0
!wgconfig wg0 add peer aws <clé publique du serveur> --allowed-ips=0.0.0.0/0 --endpoint=<Elastic IP du serveur>:51820
up
!route add -host <Elastic IP du serveur> 192.168.14.254 # IP de la passerelle locale
!route add default 172.16.1.1
Remarquez bien cette configuration, on ajoute une route vers l’IP publique de notre serveur Wireguard en spécifiant comme passerelle la passerelle locale du réseau « hosting », celle que nous avons affectée au switch de ce réseau.
Ensuite, on spécifie comme passerelle par défaut le endpoint du tunnel Wireguard, car à l’issue de la connexion, ce dernier sera bien à 1 hop de l’interface wg0.
Attention de vérifier qu’il n’y a pas de fichier /etc/mygate ou de valeur defaultroute dans /etc/rc.conf.
Le fichier /etc/ifconfig.wg0 est lu et interprété par un shell script au démarrage de la machine. La première ligne est passée en paramètre à la commande ifconfig, les lignes suivantes préfixées par un point d’exclamation sont exécutées. Néanmoins, avant de taper ces instructions, il va falloir ajouter ce peer à la configuration du serveur. On ajoute les lignes suivantes au fichier /etc/wireguard/wg0.conf de l’instance AWS :
Ici nous déclarons simplement que la machine qui s'identifie avec la clé publique `PublicKey` est autorisée à faire transiter du trafic depuis l'IP `172.16.1.2/32` (son IP, de son côté du tunnel) et `192.168.14.1/32` (son IP sur le réseau « hosting ») qui seront dès lors routées par Wireguard.
On recharge les modifications de la configuration avec la commande :
Et si tout se passe bien… ça ping ! On vérifie que le client NetBSD joint bien l’autre bout du tunnel :
$ ping -c 1 172.16.1.1
PING 172.16.1.1 (172.16.1.1): 56 data bytes
64 bytes from 172.16.1.1: icmp_seq=0 ttl=64 time=53.827017 ms
----172.16.1.1 PING Statistics----
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 53.827017/53.827017/53.827017/0.000000 ms
Et encore plus fort, que la VM est bien NATée par l’instance AWS :
{
"origin": "54.200.71.42"
}
C’est gagné. La tuyauterie est branchée, il ne reste plus qu’à lancer les services !
8. Dataétagère

Je ne sais plus exactement qui a trouvé ce terme, mais je l’affectionne particulièrement : plus de datacenter, mais une dataétagère qui est désormais prête à envoyer et recevoir du trafic public, au chaud à quelques mètres de moi.
Il reste plusieurs éléments à expliquer, parmi eux rentrer dans le détail de la configuration de pf, la mise en place du reverse DNS, la configuration d’un reverse proxy cache sur l’instance AWS… des sujets qui seront abordés dans un prochain article dédié aux services cette fois. D’ici là : Happy Hosting !


