

Découvrez le langage de référence de la programmation impérative.
1. Introduction
Le langage C fut un langage révolutionnaire à sa sortie, au début des années 1970. Les programmeurs purent coder dans un langage compréhensible, tout en ayant à disposition des fonctions pour les opérations courantes et la gestion de la mémoire, lequel fut popularisé avec le système Unix, premier système à intégrer le langage C. De nos jours, il reste encore le langage le plus utilisé au monde à la fois pour sa simplicité, sa rapidité et sa robustesse, et cela malgré la pléthore de langages concurrents (on en dénombre pas moins de 600, sans compter les langages spécifiques à un produit). [1, 2]
Cependant, malgré son apparente simplicité, le langage C est également subtil et contient quelques pièges à éviter. En effet, l'accès aux zones mémoires physiques de la machine demande une certaine rigueur durant les manipulations pour éviter d'empiéter sur la mémoire du processus voisin. De plus, les pointeurs – ces couteaux suisses du langage C – doivent être utilisés à bon escient : derrière un pointeur se trouve l'adresse d'une zone mémoire, que l'on ait ou non initialisé le pointeur. En appliquant ces quelques précautions, on appréciera de plus en plus, avec l'expérience, ce langage concis, précis et renommé.
Dans la suite de cet article, après s'être intéressé à l'histoire du C, on abordera ce langage par la pratique, avec quelques exemples illustrant les principaux éléments du langage C.
2. Brève d'histoire
Le langage C remonte au début des années 70. À cette époque, l'informatique était déjà un secteur industriel productif, bien que réservé aux grandes entreprises. Les ordinateurs commercialisés étaient d'imposantes machines de plusieurs tonnes, des mainframes, le plus souvent des IBM de la série 360, à lecteur de cartes perforées, stockage sur bandes magnétiques, et systèmes d'exploitation propriétaires OS/MFT, OS/MVT (l'ancêtre du système MVS), ou DOS/360 (à ne pas confondre avec le x86-DOS des années 80). Au niveau des gestionnaires de fichiers, le progiciel Mark IV de la société Informatics se vendait à 30 000$ la licence.
Cependant, une nouvelle génération d'ordinateurs, plus petits et moins coûteux, les mini-ordinateurs, commençait à prendre essor, surtout dans le milieu universitaire et scientifique, en particulier les mini-ordinateurs System/3 (IBM, série 5400), PDP-7 et PDP-8 (DEC). Les langages de programmation les plus utilisés furent le Fortran (Formula Translating System, de 1957), le Cobol (Common Business Oriented Langage, de 1960) et les langages assembleurs, qui sont à la limite des langages machine. Il n'y avait pas encore d'ordinateurs personnels à l'époque ; il faudra attendre pour cela la sortie de l'Apple II en 1977.
Le début des années 70, c'est aussi un période de crise économique (Crise américaine du crédit de 1966) et de guerre (Viêt Nam, 1954-1975). L'industrie dans son ensemble est impactée, y compris dans le secteur informatique. Le temps n'est plus aux commandes pharamineuses, mais aux restrictions budgétaires.
_and_Dennis_Ritchie_at_PDP-11.jpg)
Ken Thompson (assis) et Dennis Ritchie autour d'un PDP-11. Source : WIKIMEDIA (Creative Commons CC-BY-SA-2.0 licence), http://cm.bell-labs.com/who/dmr/picture.html
Dans les laboratoires Bell, un nouveau système d'exploitation voit le jour : le système UNIX. Ce projet – nommé à l'origine UNICS et débuté en 1969 par deux chercheurs, Ken Thompson et Dennis Ritchie – avait pour but de mettre au point un système d'exploitation plus simple et plus fiable que son prédécesseur issu du consortium Bell labs, General Electric et MIT : le système MULTICS. [3, 4, 5]
Écrit en assembleur PDP sur un DEC PDP-7, le système Unix fut également porté sur un PDP-11 disposant de 24 Ko de mémoire vive (16 Ko pour le système et les 8 Ko restant pour les utilisateurs). Multi-tâche, multi-utilisateur et gratuit, le système Unix remporta un grand succès, en particulier dans le milieu universitaire.
Néanmoins, l'assembleur PDP n'était pas le langage le plus adéquat pour maintenir Unix. Ken Thompson tente, en 1969, d'écrire un compilateur Fortran en TMG sur un PDP-7, puis préfère écrire un nouveau langage à partir du BCPL : le langage B. [15]
Ce langage disposant de quelques lacunes pour maintenir Unix, Dennis Ritchie entreprend en 1971 d'améliorer le langage B dans une nouvelle version, le NB (New B), qui fut renommé plus tard en C. Langage procédural et structuré, le langage C possède des structures de contrôle (if, switch, while, do, for), des types (int, short, …), des tableaux, des pointeurs, des structures de données (struct) et des fonctions avec des arguments pouvant être passés par valeur ou par adresse. Le succès est au rendez-vous : en trois décennies, il devient le langage de haut-niveau (le bas-niveau étant alors le langage machine) le plus utilisé au monde. Le système Unix commença à migrer vers le C dès la version V2 (1972). [6, 7]
En 1989, le langage C fut une première fois normalisé par l'Institut national américain de normalisation (ANSI), appelé « norme ANSI C », ou C89. Il fut de nouveau normalisé en 1995, cette fois par l'Organisation internationale de normalisation (ISO), suite à des correctifs et amendements (norme C94, aussi appelée C95).
C'est surtout en 1999 qu'une évolution importante du langage C eut lieu avec la norme C99, encore en vigueur aujourd'hui (les premières lignes d'un fichier de la bibliothèque standard du C, comme /usr/include/stdlib.h, devraient vous indiquer « ISO C99 Standard »), qui supporte, entre autres, les tableaux dynamiques. Encore récemment, en 2011, l'ISO normalisa une nouvelle version, la C11 (ou C1X), qui améliore le support du multi-threading et doit, en principe, remplacer la version C99. [8]
Aujourd'hui le langage C est toujours majoritairement utilisé, en particulier au niveau des systèmes embarqués, des systèmes d'exploitation et des pilotes matériels – pour lesquels on trouve des compilateurs C pour la plupart des micro-contrôleurs et micro-processeurs connus – ainsi que dans le milieu universitaire, où en général il reste le premier langage étudié. C'est également le langage de haut-niveau le plus rapide existant du fait de sa légèreté et de ses compilateurs longuement peaufinés.
3. Principes du langage C
Le langage C est un langage qui permet avant tout de s'abstraire des langages plus proches de la machine, comme le langage assembleur ou le langage binaire du niveau électronique. Cependant, in fine, un micro-contrôleur ou un micro-processeur ne peut exécuter qu'une suite d'instructions binaires, comme tout circuit électronique. Aussi, pour qu'un programme en C parvienne à s'exécuter sur un micro-processeur, quelques opérations seront nécessaires.
On parlera souvent de taille et de type dans cet article, aussi voici les principaux types du C99 et leurs tailles, tels que définis dans le fichier stdint.h (les types unsigned sont non-signés, c'est-à-dire positifs ou nuls ; ils récupèrent le bit signé (signe '+' ou '-') pour une plus grande plage de valeurs positives) :
|
Type |
Taille en bits |
|
char, unsigned char |
8 |
|
short int, unsigned short int |
16 |
|
int, unsigned int |
32 |
|
long int, unsigned long int |
64 (32 sur systèmes 32 bits) |
|
long long int, unsigned long long int |
64 |
|
float |
32 |
|
double |
64 |
|
long double |
128 |
|
int8_t, uint8_t |
8 |
|
int16_t, uint16_t |
16 |
|
int32_t, uint32_t |
32 |
|
int64_t, uint64_t (sur systèmes 64 bits) |
64 |
3.1 Édition d'un premier programme
Partons d'un cas simple. On écrit le programme C suivant, avec n'importe quel éditeur de texte (comme Vim par exemple), puis on l'enregistre dans un fichier prog1.c.
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
char *p = NULL;
if(argc > 1){
p = argv[1];
}else{
p = "C is the best";
}
printf("%s\n", p);
return EXIT_SUCCESS;
}
La fonction main() est le point d'entrée du programme, fonction unique qui sera exécutée en premier et qui contient deux arguments : int argc et char *argv[]. Le premier argument argc est un entier indiquant le nombre de paramètres passés en ligne de commandes lorsqu'on exécute le programme (nom du programme inclus) ; tandis que l'argument argv est un pointeur (notation *) de tableaux (notation []) de caractères (char) qui contient les paramètres de la ligne de commandes. De plus, la fonction main() attend un code retour de type int, que l'on passe à l'instruction return.
La première instruction (char *p = NULL) déclare un pointeur p de caractères (char *p), que l'on initialise à adresse nulle. Ensuite, si le nombre de paramètres, incluant le programme, est supérieur à 1 (argc > 1), on affecte le premier paramètre – qui ne soit pas le nom du programme – à p (p = argv[1], les tableaux commencent par l'indice 0), sinon on affecte au pointeur p la chaîne de caractères « C is the best ».
Ensuite, un appel à la fonction printf – définie dans le fichier d'en-tête (ou header) stdio.h que l'on a inclus par la macro #include – affiche la chaîne de caractères pointée par p. EXIT_SUCCESS est également une macro qui retourne l'entier 0 (EXIT_FAILURE retourne 1). Dans le fichier stdio.h (en principe se trouvant dans le dossier /usr/include/) nous trouvons le prototype de la fonction printf qui indique que celle-ci attend un pointeur constant de caractères en argument (const char *), suivi d'un nombre quelconque d'arguments (…). Cette fonction renvoie également un entier (voir aussi le manuel, commande man 3 printf, troisième section des pages du manuel, section développement, après avoir installé le paquet gcc-X.X-doc) :
int printf (const char *__restrict __fmt, ...) ;
Les choses commencent à se compliquer : on a déjà des pointeurs, des constantes, des pointeurs de tableaux, des pointeurs de caractères, des pointeurs de tableaux de caractères... Faisons un rapide point sur les pointeurs avant d'aller plus loin.
3.2 Un point sur les pointeurs
Un pointeur, que l'on déclare avec un astérisque (*), est un type de donnée, une variable, de la taille d'une adresse mémoire (32 bits sur un système 32 bits, 64 bits sur un 64 bits, c'est-à-dire la taille d'un mot (__WORDSIZE), et non la taille d'un int qui peut être de 32 bits sur un système 64 bits), et qui contient une adresse mémoire. Comme son nom l'indique, il sert à indiquer, à pointer, la première adresse d'une zone mémoire. Cela peut sembler abstrait lorsque l'on est habitué à des langages plus récents dénués de pointeurs (du moins en surface), mais c'est très concret. L'avantage c'est qu'au lieu de recopier toute une zone de mémoire lorsqu'on fait appel à une fonction qui nécessite sa lecture ou son écriture, on utilise juste son adresse de départ que l'on récupère avec un pointeur.
Un pointeur de caractères (char*) c'est donc un pointeur de la taille d'un mot, qui contient l'adresse mémoire du début d'une chaîne de caractères. Par commodité, on dit que c'est un pointeur de type char (et int* un pointeur de type int), mais il faut plutôt le voir comme un pointeur qui pointe vers des données de type char. Par contre, un pointeur n'indique pas, de lui-même,la fin de la zone mémoire qui contient les données. C'est le point crucial, le point de difficulté du langage C, the big one. Comment savoir où s'arrête une zone mémoire lorsqu'on ne connaît que son adresse de départ ?
En principe – bien que l'on pourrait retrouver cette information par des chemins détournés mais non-conventionnels – on ne peut pas connaître directement cette taille, mais il existe des conventions. Par convention, une chaîne de caractères se termine par un zéro (un octet 0), que l'on note '\0'. Par conséquent, le pointeur de caractères (char*) pointe sur l'adresse mémoire du début d'une chaîne de caractères et la fonction printf devra parcourir toutes les adresses contiguës jusqu'à trouver un octet à 0. Dans notre exemple, pour revenir au pointeur p, celui-ci pointe sur l'adresse mémoire qui contient le premier caractère de la chaîne. Chaque mot de mémoire est composé de cellules d'un octet, et chaque cellule possède une adresse différente. Sur un système 64 bits les adresses ont une taille de 64 bits. Il s'agit d'adresses virtuelles, la mémoire physique étant gérée par des systèmes de segmentation et de pagination.
Prenons par exemple l'état d'une mémoire 64 bits suivant, lorsque le programme, lancé sans arguments, est arrivé à l'instruction printf :
|
Adresses virtuelles 64 bits |
Valeurs hexadécimales des cellules en mémoire |
|||||
|
... |
... |
|||||
|
0x7fffffffe958 (&p) |
B4 |
06 |
40 |
00 |
00 |
00 |
|
... |
... |
|||||
|
0x0000004006c0 |
74 ('t') |
00 |
... |
|||
|
0x0000004006ba |
68 ('h') |
65 ('e') |
20 (' ') |
62 ('b') |
65 ('e') |
73 ('s') |
|
0x0000004006b4 |
43 ('C') |
20 (' ') |
69 ('i') |
73 ('s') |
20 (' ') |
74 ('t') |
|
... |
... |
|||||
Dans cet exemple, le pointeur p est déclaré à l'adresse 0x7fffffffe958 (l'adresse d'une variable peut être obtenue avec l'opérateur adresse, noté & comme &p (à ne pas confondre avec la référence & du C++, il n'y a pas de déclaration de référence en C). La valeur binaire de cette adresse est B4 (première cellule du tableau). Cependant, comme un pointeur indique une adresse, et que les adresses tiennent ici sur 64 bits, soit 6 cellules de 8 bits, on trouve comme adresse pointée par p la valeur 0x0000004006b4 (les 6 cellules dans l'ordre inverse en format little-endian sur processeurs x86). On regarde ce qui se trouve à cette adresse, et effectivement, on retrouve le début de notre chaîne de caractères, le caractère 'C' (0x43 en hexadécimal). En suivant cellule par cellule la mémoire jusqu'à celle qui contient la valeur 00, on retrouve bien notre message « C is the best ».
Autrement dit, le pointeur p contient l'adresse du premier caractère de la chaîne. L'adresse de la cellule suivante – du deuxième caractère (' ') – c'est l'adresse du premier caractère + 1 octet : 0x0000004006b5 ; le troisième ('i') c'est donc 0x0000004006b6. On peut le vérifier en indiquant à p l'index concerné, comme pour un tableau de caractères (p[0] = 'C', p[1] = ' ', p[2] = 'i', ...). De plus, on peut incrémenter le pointeur directement en utilisant l'opérateur ++, ce qui a pour effet d'incrémenter – selon le type de donnée – l'adresse de la mémoire contenue par p (et donc de modifier p). Par exemple, si l'on ajoute l'instruction p++ avant la fonction printf, celle-ci n'affichera plus que « is the best ».
En résumé, la fonction printf va parcourir de la première adresse pointée par p de valeur 'C' jusqu'à la première cellule de valeur 00, puis afficher le message suivi d'un retour-chariot ('\n',newline). Vous pourrez vérifier tout cela en utilisant un débogueur comme gdb et en scrutant le contenu de la mémoire. [9,10]
On trouve fréquemment des doubles pointeurs, comme char **pp. Un double pointeur char** peut être soit la déclaration d'un pointeur qui pointe vers une suite de pointeurs de caractères (comme un tableau à deux dimensions, on a pp[0] un premier pointeur de caractères, pp[1] un second, etc.), ou soit, en argument de fonctions, un type adresse de pointeur (que l'on utilisera avec un appel à &pp, comme par exemple dans la fonction getline (cf. man 3 getline)). Par ailleurs, dès lors que l'on réutilise la notation * sur un pointeur déjà déclaré, comme *p, on n'obtient non pas l'adresse du pointeur (&p), ni l'adresse pointée (juste p), mais la valeur du premier élément pointé (comme p[0]). Par exemple :
const char *p = "Test";
printf("%c\n", *p); //affiche le caractère 'T'
3.3 Précompilation, compilation, édition des liens et exécution
Pour passer du code C à un programme exécutable, il suffit de faire appel au compilateur gcc (GNU CC, version GNU – développée par Richard Stallman – du compilateur CC d'Unix). Par exemple, la commande suivante compile le fichier prog1.c en un exécutable a.out :
$ gcc prog1.c
$ ./a.out
C is the best
On peut bien sûr lui passer le nom du programme avec l'option -o.
Mais ce qui va nous intéresser, ça ne va pas être de décortiquer la pléthore des options du compilateur, mais de voir ce qui se passe d'un peu plus près.
3.3.1 Un programme pour un micro-processeur et un système d'exploitation
Un programme, c'est une suite d'instructions binaires que le micro-processeur devra exécuter au niveau électronique. Aussi, l’exécutable a.out généré précédemment ne contient qu'une suite de bits, c'est du langage machine. Ces bits ne peuvent être lus que par un micro-processeur spécifique pour lequel le programme aura été compilé, et le résultat ne pourra être exploité que par un système d'exploitation donné. Pour savoir pour quel micro-processeur sera compilé par défaut un programme, vous pouvez appeler la commande gcc -v, qui affiche en particulier le processeur et le système cible (Target, ici un processeur de type x86-64 et un système GNU/Linux) :
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/4.8/lto-wrapper
Target: x86_64-linux-gnu
...
Maintenant, pour passer d'un fichier C à un exécutable binaire, le compilateur devra effectuer plusieurs tâches successives.
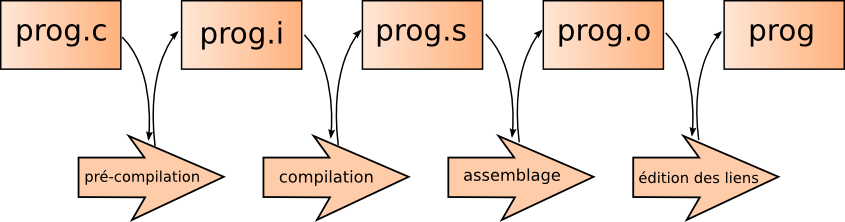
3.3.2 Du langage machine au langage assembleur
Il y a fort longtemps, à l'époque des dinosaures ou presque, alors que les ordinateurs ne possédaient pas de transistors mais des tubes à vides et des câbles, comme le Whirlwind I, le Manchester Mark I, le SSEC (1948-1950), les programmeurs, ou plutôt les chercheurs, codaient directement en langage machine, avec des bits (sur certains modèles, comme le Whirlwind I, on trouvait tout de même un clavier et un écran cathodique).
Les instructions étaient alors moins complexes et en nombre plus restreint. Une instruction, en binaire, est une suite de bits dont les premiers indiquent l'opération à effectuer (bits op, operation), et chaque processeur possède son propre jeu d'instructions. On peut observer le code machine hexadécimal du programme a.out, avec la commande hexdump par exemple :
$ hexdump -C a.out
...
000005d0 8b 7c 24 30 48 83 c4 38 c3 0f 1f 80 00 00 00 00 |.|$0H..8........|
000005e0 f3 c3 00 00 48 83 ec 08 48 83 c4 08 c3 00 00 00 |....H...H.......|
000005f0 01 00 02 00 43 20 69 73 20 74 68 65 20 62 65 73 |....C is the bes|
00000600 74 00 00 00 01 1b 03 3b 30 00 00 00 05 00 00 00 |t......;0.......|
00000610 cc fd ff ff 7c 00 00 00 0c fe ff ff 4c 00 00 00 |....|.......L...|
...
Difficile de lire le début et la fin d'une instruction et de savoir ce que fait ce programme, même si l'on voit apparaître la chaîne de caractères. Dès lors, l'utilisation de mnémoniques pour repérer les suites d'instructions à la place de leurs valeurs binaires facilita grandement la programmation : ce fut le langage assembleur, apparu dans les années 50. Par exemple, l'instruction machine 1110 1011 0000 1000 (ou EB08 en hexadécimal), est équivalente en assembleur à l'instruction jmp label.
Aussi pour passer d'un fichier C à un programme binaire, la principale phase de la compilation consiste à traduire le fichier texte C en un fichier texte assembleur. Une fois ce fichier généré, le compilateur gcc fait ensuite appel au programme assembleur (le programme as, ou GNU assembler), qui va le lire et produire un fichier binaire, appelé aussi fichier objet(extension .o). Bien que cette étape soit cachée par gcc, on peut néanmoins lui passer des commandes pour l'assembleur. Ainsi, on peut voir le fichier assembleur produit par gcc avec l'option -S (ce qui génère un fichier .s), et le fichier objet généré par l'assembleur avec l'option -c :
$ gcc -S prog1.c
$ less prog1.s
.file "prog1.c"
.section .rodata
.LC0:
.string "C is the best"
.text
.globl main
.type main, @function
main:
.LFB2:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
...
C'est déjà plus compréhensible que le code machine. Au lieu de lire une suite de bits, on lit à présent une suite d'instructions, de même que des sections de données : .rodata, pour les données en lecture seule (la chaîne de caractères s'y trouve) et .text pour le code exécutable. Le langage assembleur est encore utilisé de nos jours pour effectuer certains traitements spécifiques à un processeur ou coder des routines optimisées. De plus, on peut également utiliser directement le programme assembleur as, lequel est fourni avec gcc. [12,13]
3.3.3 Précompilation
Avant de passer à l'étape de compilation, le fichier C est purgé de toutes ses macros – directives pour le préprocesseur cpp (C preprocessor) dont les définitions sont reconnaissables par le caractère # – et cela durant une phase de précompilation (ou preprocessing). Le code résultant est un fichier C contenant les valeurs des macros à la place de leurs noms. Dans notre exemple de départ, la macro EXIT_SUCCESS, qui provient d'une directive #define, est remplacée par sa valeur 0 et les macros #include par le contenu des fichiers à inclure. Pour afficher le fichier obtenu, on peut utiliser gcc avec l'option -E, et avec -o pour indiquer le fichier de sortie (de préférence avec l'extension .i pour les fichiers pré-compilés) :
$ gcc -E -o prog1.i prog1.c
$ less prog1.i
[...]
int main(int argc, char *argv[])
{
char *p = ((void *)0);
[...]
return 0;
}
Le programme ne peut inclure deux fois le même fichier, cela multiplierait les prototypes des fonctions et les déclarations. Pour pallier ce problème, on ajoute des macros #ifndef _LE_FICHIER_H et #define _LE_FICHIER_H en début de fichier d'en-tête, et une macro #endif à la fin de fichier, ce qui a pour effet d'inclure une seule fois le contenu du fichier durant la précompilation, à l'instar d'un #pragma once, mais standardisé.
3.3.4 Édition des liens
Enfin, dernière étape effectuée par le compilateur gcc : l'édition des liens. Après avoir généré des fichiers objets .o avec l'assembleur as, gcc va utiliser le programme ld (the GNU Linker), pour lier les symboles des fonctions dont le code se situe dans d'autres fichiers objets, ou dans des bibliothèques externes (statiques ou dynamiques). Dans notre exemple, le code, la définition, l'implémentation de la fonction printf se situe dans la bibliothèque dynamique libc.so (so comme shared object). Le linker ld relie le tout et génère un exécutable final au format ELF (Executable and Linkable Format, format des exécutables sous Linux).
Comme l'assembleur as, on peut utiliser ld à part entière ou lui passer des options via gcc, comme -o (nom de l’exécutable), -lm (utilisation de la bibliothèque mathématique), le nom d'une bibliothèque à linker, etc. On peut également lui indiquer de générer une bibliothèque de fonctions au lieu d'un programme exécutable, avec l'option -shared pour une bibliothèque dynamique (dynamiquement chargée à l’exécution du programme), ou -static pour une bibliothèque statique (intégrée au programme durant l'édition des liens).
On peut lister les bibliothèques dynamiques utilisées par un programme avec la commande ldd, par exemple :
$ ldd a.out
linux-vdso.so.1 (0x00007fffff4bf000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f04bf050000)
/lib64/ld-linux-x86-64.so.2 (0x00007f04bf42c000)
Cette commande est également utile pour afficher les liens qui font défaut.
Pour lister les fonctions exportées par une bibliothèque dynamique, on peut utiliser les commandes nm ou readelf :
$ nm -D --defined-only /lib/x86_64-linux-gnu/libc.so.6
[...]
0000000000050ec0 T printf
[…]
$ readelf -s /lib/x86_64-linux-gnu/libc.so.6
[...]
594: 0000000000050ec0 161 FUNC GLOBAL DEFAULT 12 printf@@GLIBC_2.2.5
[…]
En résumé, en passant la commande gcc prog.c, le compilateur aura pré-compilé le fichier prog.c en un fichier C dépourvu de macros, compilé celui-ci en un fichier texte assembleur, passé ce dernier à l'assembleur as pour générer un fichier objet binaire, puis relié ce fichier objet avec les bibliothèques partagées nécessaires grâce à l'éditeur de liens ld, pour produire au final (avec ld toujours) un exécutable a.out au format ELF. [12]
Les bibliothèques dynamiques doivent être présentes sur le système lorsque le programme s’exécute et leurs chemins connus par celui-ci (cf. LD_LIBRARY_PATH). De plus, les prototypes de leurs fonctions doivent correspondre à ceux utilisés par le programme lors de sa compilation. Il n'est pas rare qu'à la suite d'une mise à jour de bibliothèques, un programme anciennement compilé se mette à planter soit parce que la mise à jour supprime l'ancienne bibliothèque, soit parce que la fonction utilisée ne correspond plus à celle de la nouvelle. Dans ce cas, une solution est d'effectuer les modifications de code nécessaires (ou s'aider d'un patch) et de recompiler le programme avec la nouvelle bibliothèque.
4. Exemples
4.1 Appels de fonction
Dans cet exemple, nous allons faire quelques appels de fonction, avec quelques erreurs que l'on corrigera par la suite. On reprend l'exemple de départ, qu'on améliore en lui ajoutant une fonction afficher(). On passe à cette fonction un argument de type pointeur de caractères constant (const char*) qu'elle affichera avec un appel à la fonction printf.
include <stdlib.h>
#include <stdio.h>
void afficher(const char *message)
{
printf("%s\n", *message);
}
int main(int argc, char *argv[])
{
const char *p = NULL;
if(argc > 1){
p = argv[1];
}else{
p = "C is sexy";
}
afficher(p);
return EXIT_SUCCESS;
}
Le programme se compile bien, mais à l’exécution on obtient une erreur de segmentation :
$ gcc exemple1.c -o exemple1
$ ./exemple1
Erreur de segmentation
Une erreur de segmentation concerne des segments de mémoire, lorsque par exemple le programme tente de lire dans un segment de mémoire dont il n'a pas le droit d'accès, ou lorsqu'il essaye d'écrire dans un segment en lecture seule (dans une constante par exemple).
Dans cet exemple, on passe bien le pointeur p à la fonction afficher, mais la fonction printf attend une chaîne de caractères (%s), c'est-à-dire l'adresse du premier caractère pointé par le pointeur. Mais au lieu de lui fournir cette adresse, on lui passe la valeur du premier élément (*message), c'est-à-dire le caractère 'C', soit la valeur hexadécimale 0x43. Du coup, au lieu d'aller lire à l'adresse indiquée par le pointeur, le programme va tenter de lire à partir de l'adresse 0x43. Cette adresse ne concernant pas les données du programme, et même pouvant être utilisée par un autre programme, au lieu de poursuivre les dégâts, le système va interrompre le programme et envoyer une erreur de segmentation. Une correction du programme est donc d'indiquer le pointeur (message) – et non son premier élément (*message) – en paramètre de la fonction printf.
Une bonne pratique est d'utiliser des codes retoursde fonction : on gagne ainsi en temps de débogage et cela facilite également les tests unitaires. Ainsi la fonction printf renvoie le nombre de caractères affichés si succès, et un nombre négatif en cas d'erreur (cf. man 3 printf). Cependant, l'erreur de segmentation intervient avant que la fonction printf n'ait pu se terminer : c'est une interruption de programme, un arrêt d'urgence en quelque sorte. On ajoute néanmoins des codes retours par sécurité, et également une boucle for, laquelle boucle depuis i = 1 et tant que i < argc, en incrémentant i de 1 (i++).
#include <stdlib.h>
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int afficher(const char *message)
{
int erreur = 0;
erreur = printf("%s\n", message);
if (erreur < 0) {
return FALSE;
}
return TRUE;
}
int main(int argc, char *argv[])
{
const char *p = NULL;
int i = 0;
if(argc > 1){
for (i=1; i<argc; i++){
p = argv[i];
if (!afficher(p)) {
perror("erreur de la fonction afficher");
return EXIT_FAILURE;
}
}
}else{
p = "C is sexy";
if (!afficher(p)){
perror("erreur de la fonction afficher");
return EXIT_FAILURE;
}
}
return EXIT_SUCCESS;
}
$ gcc exemple1.c -o exemple1;
$ ./exemple1 "C is nice" "C is incredible"
C is nice
C is incredible
4.2 Prototype de fonction
Jusqu'à présent, nous n'avons utilisé qu'un seul fichier et une fonction, mais dans la pratique un programme se compose de nombreuses fonctions. Aussi, il convient de respecter une certaine structure : on place les prototypes des fonctions dans des fichiers d'en-têtes .h (headers), et leurs définitions dans des fichiers sources .c.
En reprenant le programme précédent, nous allons ajouter le prototype de la fonction afficher() dans un fichier fonctions.h, et coder sa définition dans un fichier fonctions.c. La fonction main() est placée dans un fichier exemple2.c. Une bonne pratique est de commenter les prototypes, en indiquant au moins les codes retours. Dans cet exemple, nous utilisons le format de commentaires du logiciel Doxygen. On obtient les fichiers suivants (notez bien les #include : par convention on place les en-têtes locaux entre guillemets et les en-têtes système entre chevrons) :
fonctions.h :
#ifndef _FONCTIONS_H
#define _FONCTIONS_H
#define TRUE 1
#define FALSE 0
/**
* affiche un message
* @param[in] message le message à afficher
* @return TRUE si succès, sinon FALSE
**/
int afficher(const char *message);
#endif /*_FONCTIONS_H*/
fonctions.c :
#include "fonctions.h"
#include <stdio.h>
int afficher(const char *message)
{
int erreur = 0;
erreur = printf("%s\n", message);
if (erreur < 0) {
return FALSE;
}
return TRUE;
}
exemple2.c :
#include "fonctions.h"
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
const char *p = NULL;
if(argc > 1){
p = argv[1];
}else{
p = "C is sexy";
}
if (!afficher(p))
{
perror("afficher");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
Gcc va ensuite générer un fichier exemple2.o et un fichier fonctions.o, puis relier ces deux fichiers objets en un programme exécutable. La compilation du programme s'effectue par la commande suivante :
$ gcc exemple2.c fonctions.c -o exemple2
$ ./exemple2 "test ok"
test ok
4.3 Structures de données
Pour éviter d'avoir à gérer des variables éparpillées, on peut les regrouper dans des structures de données. Les structures se déclarent avec le mot-clé struct, suivi du bloc de type de données à inclure, sans oublier le point-virgule final. On peut ensuite initialiser la structure en utilisant des accolades, et accéder aux données membres avec un caractère '.'. Par exemple (notez également la fonction strlen, qui renvoie la taille d'une chaîne de caractères) :
#include "fonctions.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
struct message
{
char *message;
int longueur;
};
int main(int argc, char *argv[])
{
struct message mess = { NULL, 0 };
if(argc > 1){
mess.message = argv[1];
}else{
mess.message = "C is sexy";
}
mess.longueur = strlen(mess.message);
printf("longueur du message = %i\n", mess.longueur);
if (!afficher(mess.message))
{
perror("afficher");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
Une autre façon, plus couramment utilisée, de déclarer une structure est de l'inclure dans un typedef, qui sert à redéfinir le nom d'un type. Ainsi, dans l'exemple suivant, l'instruction typedef a pour effet de définir le type struct message comme un type s_message et un pointeur s_message* comme un type p_message. Par contre, pour accéder aux données membres d'un pointeur de structure, on utilise les caractères '->'. Par exemple :
#include "fonctions.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
typedef struct message
{
char *message;
int longueur;
} s_message, *p_message;
int main(int argc, char *argv[])
{
s_message mess = {NULL, 0};
p_message pmess = &mess;
if(argc > 1){
pmess->message = argv[1];
}else{
pmess->message = "C is sexy";
}
pmess->longueur = strlen(pmess->message);
printf("longueur du message = %i\n", pmess->longueur);
if (!afficher(pmess->message))
{
perror("afficher");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
$ gcc exemple3.c fonctions.c -o exemple3
$ ./exemple3 "ceci est un test"
longueur du message = 16
ceci est un test
4.4 Mémoire dynamique
Jusqu'à présent, nous n'avons pas rencontré beaucoup de problèmes de mémoire, car on se contentait d'utiliser des chaînes de caractères déjà placées en mémoire avant que la fonction main() ne commence. Cependant, dès lors que l'on ajoute des données de taille importante durant l’exécution du programme, il devient nécessaire de gérer dynamiquement le stockage en mémoire avec des fonctions comme malloc, calloc, realloc et free.
Prenons l'exemple suivant, qui utilise une fonction memset pour initialiser le tableau de caractères à zéro, une fonction strcpy pour copier une chaîne de caractères vers une autre, et une énumération enum qui énumère et incrémente une suite d'entiers à partir du premier, séparés par des virgules (DEFAUT vaut 0, COMMANDE vaut 1, on aurait pu mettre aussi DEFAUT=0). Le programme compile, mais provoque une erreur à l’exécution :
#include "fonctions.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MAX_CHAR 10000000
typedef enum MESSAGE_TYPE
{
DEFAUT,
COMMANDE
} E_TYPE;
typedef struct message
{
char message[MAX_CHAR];
int longueur;
E_TYPE type;
} s_message, *p_message;
int main(int argc, char *argv[])
{
s_message smess;
p_message pmess = &smess;
memset(pmess->message, 0, MAX_CHAR); //initialise la chaîne message à zéro
pmess->longueur = 0;
if(argc > 1){
strcpy(pmess->message, argv[1]); //copie de argv[1] à pmess->message
pmess->type = COMMANDE;
}else{
strcpy(pmess->message, "C is amazing");
pmess->type = DEFAUT;
}
if (!afficher(&pmess->message[0]))
{
perror("afficher");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
$ gcc exemple4.c fonctions.c -o exemple4
$ ./exemple4
Erreur de segmentation
Effectivement, on déclare un tableau de caractères de 10 Mo dans la structure message, puis le programme tente d'allouer la mémoire nécessaire à cette structure de façon statique. Cependant, la mémoire statique est d'une taille limitée : elle est allouée avant l’exécution du programme et permet de déclarer des variables de petite taille, comme des int, char, etc. Il en va de même pour la mémoire réservée aux fonctions, appelée mémoire de pile, ou mémoire stack, dont le dépassement engendre un débordement de pile(ou stack overflow).
D'une taille trop importante pour la mémoire statique, le programme bogue à la première ligne de la fonction main() : 's_message smess;'.
Pour allouer de la mémoire de grande taille (>100 Ko), il faut utiliser la mémoire sur le tas (ou mémoire heap). Pour ce faire, on utilise la fonction malloc(), qui alloue de l'espace en mémoire heap, et la fonction free() pour libérer celle-ci après utilisation. La libération de mémoire dynamique est très importante, car si on ne le fait pas, et si le programme alloue mémoire sur mémoire, les anciennes allocations n'étant pas libérées, le programme augmentera alors constamment la taille de la mémoire allouée, réduisant d'autant la mémoire libre du système (fuite de mémoire), jusqu'à provoquer à la longue un ralentissement ou une panne du système.
La fonction malloc() renvoie un pointeur indéfini (void*), que l'on peut caster en pointeur p_message – c'est le dynamic cast parenthésé (p_message) – et qui pointe vers l'adresse du début de la mémoire allouée (ou NULL si erreur). Cette fonction prend en paramètre la taille à allouer en octets (cf. man 3 malloc). Comme la structure message possède une taille fixe, on peut utiliser l'instruction sizeof() pour indiquer la taille à allouer. Cependant, si la chaîne de caractères dépasse la taille allouée, il y a débordement de tampon (buffer overflow), faille fréquemment utilisée par des programmes pirates pour accéder au système et dont le résultat est incertain (cf. man 3 strcpy). C'est pourquoi l'on indique spécifiquement la taille d'une zone mémoire en plus de son pointeur, lorsqu'on utilise des données allouées, c'est le cas par exemple de la fonction main (taille du tableau, argc, suivie du pointeur de données, *argv[]).
Si la fonction free n'a pas besoin de la taille de la zone mémoire en paramètre, cela est dû à l’implémentation de la fonction malloc, qui ajoute également des informations de taille en zone mémoire. Cependant, il n'est pas recommandé d'utiliser ces informations au sein d'un programme, celles-ci étant dépendantes de l'implémentation de la fonction malloc, et servant surtout à éviter les nombreux problèmes mémoire qu'il y aurait s'il fallait également renseigner la taille à la fonction free.
On corrige et restructure le programme en plaçant les définitions dans le fichier d'en-tête et en modifiant la fonction afficher en lui ajoutant une instruction switch. Cette instruction switch va exécuter un bloc case jusqu'au premier break ou return rencontré selon la valeur de l'étiquette (label) du case, de type int (ici une énumérationE_TYPE), un peu comme une suite de conditions if else mais en plus rapide. Le programme devient le suivant :
fonctions.h :
#ifndef _FONCTIONS_H
#define _FONCTIONS_H
#define TRUE 1
#define FALSE 0
#define MAX_CHAR (int)10e6
/**
* Type de message
*/
typedef enum MESSAGE_TYPE
{
DEFAUT,
COMMANDE
} E_TYPE;
/**
* structure d'un message
*/
typedef struct message
{
char message[MAX_CHAR];
int longueur;
E_TYPE type;
} s_message, *p_message;
/**
* affiche un message
* @param[in] pmessage le p_message à afficher
* @return TRUE si succès, sinon FALSE
*/
int afficher(const p_message pmessage);
#endif /* _FONCTIONS_H */
fonctions.c :
#include "fonctions.h"
#include <stdio.h>
int afficher(const p_message pmessage)
{
int erreur = 0;
if (pmessage == NULL) {
return FALSE;
}
switch (pmessage->type) {
case DEFAUT:
erreur = printf("Message par défaut : %s\n", pmessage->message);
break;
case COMMANDE:
erreur = printf("Message commande : %s\n", pmessage->message);
break;
default:
printf("Type de message non reconnu\n");
erreur = -1;
break;
}
if (erreur < 0) {
return FALSE;
}
return TRUE;
}
code
exemple4.c :
#include "fonctions.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
p_message pmess = (p_message) malloc(sizeof(s_message));
if (pmess == NULL)
{
fprintf(stderr, "erreur d'allocation\n");
return EXIT_FAILURE;
}
memset(pmess->message, 0, MAX_CHAR);
pmess->longueur = 0;
if(argc > 1 && strlen(argv[1]) < MAX_CHAR){
strcpy(pmess->message, argv[1]);
pmess->type = COMMANDE;
}else{
strcpy(pmess->message, "C is amazing");
pmess->type = DEFAUT;
}
if (!afficher(pmess))
{
perror("afficher");
free(pmess);
return EXIT_FAILURE;
}
free(pmess);
return EXIT_SUCCESS;
}
$ gcc exemple4.c fonctions.c -o exemple4 ; ./exemple4
Message par défaut : C is amazing
Remarquez également l'utilisation de la fonction fprintf, qui écrit dans un descripteur de fichier, ici la sortie d'erreur standard stderr,que l'on peut par la suite rediriger en console avec les redirections du shell, technique souvent employée pour les journaux (logs).
On peut détecter les fuites de mémoire avec le logiciel Valgrind, l'un des plus connus sous Linux.
4.5 Lecture et écriture d'un fichier
Enfin, dernier exemple concernant le traitement de fichiers. La fonction fopen() ouvre un pointeur de flux(FILE*), lequel pointe vers l'emplacement de lecture du fichier et avance à chaque caractère lu. De plus, pour lire une ligne, on peut utiliser la fonction getline(), qui nécessite un buffer pour écrire les données lues (cf. man 3 fopen, man 3 getline).
Cette fois, on prend un tout autre exemple qui consiste à lire les données d'un fichier – des coordonnées de points en 3D – pour en calculer la distance euclidienne D (pour deux points a et b) :
![]()
Le fichier de données data, construit à partir du nombre pi, est le suivant :
data :
#Xa:Ya:Za;Xb:Yb:Zb
14.15:92.65:35.89;79.32:38.46:26.43
38.32:79.50:28.84;19.71:69.39:93.75
10.58:20.97:49.44;59.23:07.81:64.06
28.62:08.99:86.28;03.48:25.34:21.17
06.79:82.14:80.86;51.32:82.30:66.47
09.38:44.60:95.50;58.22:31.72:53.59
40.81:28.48:11.17;45.02:84.10:27.01
93.85:21.10:55.59:64.46:22.94:89.54
Chaque coordonnée cartésienne X, Y, Z est séparée par deux points ':', chaque point de l'espace A, B par un point virgule ';'. On écrit le programme suivant :
exemple5.c :
#include <stdlib.h>
#include <stdio.h>
#include <strings.h>
#include <errno.h>
#include <math.h>
#define FICHIER_DATA "data"
#define FICHIER_RESULTATS "resultats"
typedef struct point
{
float X;
float Y;
float Z;
} s_point, *p_point;
int main(int argc, char *argv[])
{
FILE *data = NULL;
FILE *resultats = NULL;
char *ligne = NULL;
size_t longueur = 0;
ssize_t luts = 0;
char *fin = NULL;
float distance = 0;
errno = 0;
p_point a = NULL;
p_point b = NULL;
//allocations
a = malloc(sizeof(s_point));
if (a == NULL)
{
perror("malloc");
exit(EXIT_FAILURE);
}
b = malloc(sizeof(s_point));
if (b == NULL)
{
perror("malloc");
free(a);
exit(EXIT_FAILURE);
}
//ouverture des fichiers
data = fopen(FICHIER_DATA, "r");
if (data == NULL){
perror("fopen data");
free(a);
free(b);
exit(EXIT_FAILURE);
}
resultats = fopen(FICHIER_RESULTATS, "w");
if (resultats == NULL){
perror("fopen resultat");
fclose(data);
free(a);
free(b);
exit(EXIT_FAILURE);
}
//lecture des données
while ((luts = getline(&ligne, &longueur, data)) != -1) {
if(ligne[0] == '#'){
continue;
}
//analyse la ligne
a->X = (float)strtod(ligne, &fin);
a->Y = (float)strtod(++fin, &fin);
a->Z = (float)strtod(++fin, &fin);
b->X = (float)strtod(++fin, &fin);
b->Y = (float)strtod(++fin, &fin);
b->Z = (float)strtod(++fin, &fin);
if (errno != 0) {
perror("strtol");
break;
}
//calcul
distance = sqrt(pow(b->X – a->X, 2) + pow(b->Y – a->Y, 2) + pow(b->Z – a->Z, 2));
//écriture du résultat
fprintf(resultats,
"A(%.2f;%.2f;%.2f) B(%.2f;%.2f;%.2f) d(A,B)=%.2f\n",
a->X, a->Y, a->Z, b->X, b->Y, b->Z, distance);
}
fclose(data);
fclose(resultats);
free(a);
free(b);
exit(EXIT_SUCCESS);
}
Dans ce programme, on utilise la fonction fopen pour ouvrir le fichier data en lecture seule (read "r") et créer ou écraser le fichier resultats en écriture (write "w"). Ensuite, le programme lit ligne par ligne le fichier data avec la fonction getline tant que (boucle while) la fin du fichier n'est pas atteinte, auquel cas la fonction getline renvoie -1 (cf. man 3 getline). Si la ligne commence par un caractère '#', le programme passe à la ligne suivante (instruction continue).
Les valeurs en nombres flottants sont converties avec la fonction strtod, qui prend en premier paramètre le début de la chaîne de caractères à convertir et qui indique dans le pointeur fin l'adresse du premier caractère non numérique atteint (cf. man 3 strtod).
Ainsi, pour la première valeur a->X, la fonction strtod part du premier caractère de la ligne (ligne) et va jusqu'au premier caractère non numérique ':', dont l'adresse est placée dans le pointeur fin. Pour la seconde valeur a->Y, on incrémente le pointeur fin (++fin pour incrémenter avant l'appel de fonction, et non fin++ qui incrémente après celle-ci) pour qu'il pointe vers le début du deuxième nombre, et ainsi de suite. Si une erreur de conversion survient, la fonction strtod renseigne la variable d'erreur errno, définie dans le fichier errno.h (cf. man 3 strtol) et le programme sort de la boucle while (break).
Le calcul de la distance s'effectue avec les fonctions racine carrée (sqrt) et puissance (pow) de la bibliothèque mathématique, et le résultat est écrit dans un fichier resultats avec la fonction fprintf. Avant de quitter, les fichiers sont fermés avec la fonction fclose et les allocations dynamiques libérées avec free. Pour la compilation, comme on utilise la bibliothèque mathématique, on ajoute l'option -lm :
$ gcc exemple5.c -lm -o exemple5
$ ./exemple5
$ cat resultats
A(14.15;92.65;35.89) B(79.32;38.46;26.43) d(A,B)=85.28
A(38.32;79.50;28.84) B(19.71;69.39;93.75) d(A,B)=68.28
A(10.58;20.97;49.44) B(59.23;7.81;64.06) d(A,B)=52.48
A(28.62;8.99;86.28) B(3.48;25.34;21.17) d(A,B)=71.68
A(6.79;82.14;80.86) B(51.32;82.30;66.47) d(A,B)=46.80
A(9.38;44.60;95.50) B(58.22;31.72;53.59) d(A,B)=65.63
A(40.81;28.48;11.17) B(45.02;84.10;27.01) d(A,B)=57.98
A(93.85;21.10;55.59) B(64.46;22.94;89.54) d(A,B)=44.94
Conclusion
Cette introduction sur le langage C se termine. Après s'être intéressé à l'origine du langage C, on aura vu une bonne partie des fonctions de base et on se sera exercé avec la compilation, les pointeurs et les adresses, notions essentielless pour bien aborder ce langage. Cependant, il ne s'agit ici que d'un aperçu, de nombreux livres, revues et sites Internet, ainsi que la suite de cet ouvrage, approfondissent ces concepts et apportent des compléments de langage.
On aura également apprécié l'importance que prennent les pointeurs, très précis et très délicats à manier, comme vous aurez pu le constater à travers les exemples précédents. On pourra s'aider des pages du manuel Linux (man) pour la description des fonctions de l'API (Application Programming Interface) et utiliser des outils d'analyse de code et de débogage pour ne pas rester coincer sur un bug.
Il y aurait encore beaucoup à dire, notamment sur les tableaux dynamiques, les fonctions récursives, le débogage, mais cela dépasserait le cadre de cette introduction. Retenez qu'il faut initialiser les variables (un pointeur s'initialise en NULL) et qu'il faut libérer les allocations dynamiques (avec la fonction free). N'hésitez pas à ajouter des fonctions, à utiliser des fichiers d'en-têtes .h et des fichiers sources .c, et à factoriser les fonctions : cela rendra le code plus lisible et plus maintenable (en principe, une fonction ne doit pas dépasser 50 lignes de code), sans oublier les commentaires. Bon codage !
Références
[1] TIOBE, The TIOBE Programming Community index, http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html, 2013.
[2] WIKIPEDIA, List of programming languages, http://en.wikipedia.org/wiki/List_of_programming_languages, 2013.
[3] J-Y BIRRIEN, Histoire de l'informatique, Que sais-je, 1990
[4] M. CAMPBELL-KELLY, Une histoire de l'industrie du logiciel, Vuibert Informatique, 2003
[5] H. HENDERSON, Encyclopedia of Computer Science and Technology, Facts on file science library, 2003
[6] The Unix Heritage Society, The Unix Tree, http://minnie.tuhs.org/cgi-bin/utree.pl, 2013
[7] D. M. RITCHIE, K. THOMPSON, The UNIX Time-Sharing System, http://cm.bell-labs.com/who/dmr/cacm.html, 2013
[8] WIKIPEDIA, C11 (C standard revision), http://en.wikipedia.org/wiki/C11_(C_standard_revision), 2013
[9] Telecom-Paris Tech BCI Informatique, Gestion de la mémoire, http://www.infres.enst.fr/~dupouy/pdf/BCI/6-MemBCI-07.pdf, 2013
[10] WIKIPEDIA, Endianness, http://fr.wikipedia.org/wiki/Endianness, 2013
[11] ISO / IEC, Programming languages – C, http://www.open-std.org/JTC1/SC22/WG14/www/docs/n1256.pdf, 2007
[12] P. PRINTZ, T. CRAWFORD, C in a Nutshell, O'Reilly, 2006
[13] WIKIPEDIA, Machine code, http://en.wikipedia.org/wiki/Machine_code, 2013
[14] Y. METTIER, C en action, O'Reilly, 2005
[15] WIKIPEDIA, TMG (language), http://en.wikipedia.org/wiki/TMG_(language), 2013



