

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Analyser des binaires est une tâche souvent répétitive, voyons comment capitaliser sur les analyses passées et automatiser les analyses futures.
Lors de l'analyse de malware, il est utile de disposer d'une chaîne d'analyse automatique de binaires. En premier lieu, cela permet d’éviter les étapes répétitives et de rapidement séparer les binaires qui méritent une analyse approfondie de ceux qui sont seulement des mises à jour ou des variants de malwares connus.
Capitaliser sur ses analyses passées et celles des autres passe par l’indexation, le partage d'informations ainsi que par la mise à jour des informations déjà partagées. Heureusement, il existe des outils de partage d'information généralistes comme MISP [MISP] qui permettent de partager automatiquement IoC, règles de détections ou rapports d'analyse. Reste qu'il faut tout de mème produire les analyses des binaires correspondants à des malwares connus qui ne méritent plus le temps d'un analyste.
Pour répondre à ce problème, on peut imaginer un traitement automatique de binaire qui, depuis l'analyse jusqu'au partage d'information, prendrait la forme illustrée en figure 1.
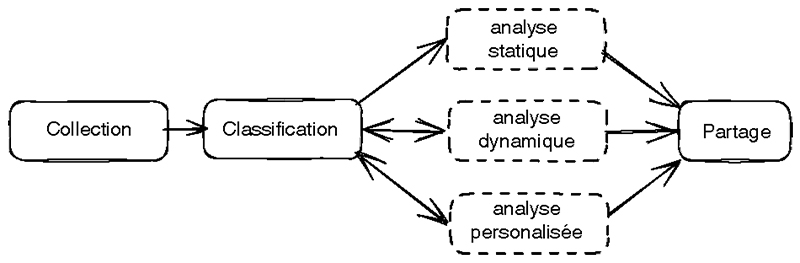
Dans les prochaines sections, nous montrons comment mettre en œuvre une telle chaîne d'analyse et comment extraire des informations spécifiques d'un malware sans intervention humaine.
Présentation des protagonistes et installation
Nous allons articuler ensemble plusieurs projets open source, principalement issus de CERT.PL :
- MWDB [mwdb] : est une application qui sert à stocker, indexer et rechercher des malwares et leurs configurations ;
- malduck [malduck] : est une collection de helpers supportant l'analyse de malwares ;
- karton [karton] : est un outil d'orchestration de tâches ;
- drakvuf [drakvuf] : est une sandbox d'analyse dynamique compatible Windows et Linux, sans agent ;
- MISP : est un outil de partage d’information.
Nous verrons ensuite comment faire une analyse particulière d'un malware. Nous laisserons l'analyse dynamique avec drakvuf de côté, car celle-ci mériterait un article à elle seule.
1. Installation
Une installation complète (avec drakvuf) requiert un processeur Intel doté de VT-X et EPT et de préférence un système Debian ou Ubuntu. CERT.PL met à disposition un conteneur docker [docker], que vous pouvez utiliser pour vous familiariser avec karton et MWDB, mais qui trouvera rapidement ses limites.
1.1 MWDB
MWDB utilise une base PostgreSQL qu'il va nous falloir configurer, ainsi que ssdeep qu'il va nous falloir installer. On utilise ici une distribution Ubuntu 20.04, et on a préalablement créé un utilisateur mwdb :
On peut maintenant démarrer MWDB avec la commande mwdb-core run. MWDB sera alors disponible à l'adresse http://127.0.0.1:5000.
1.2 drakvuf et karton
Drakvuf utilise karton pour gérer ses services. Pour installer le tout, nous allons installer drakuf-sandbox [ds] qui propose en plus de drakvuf une interface web et une API pour piloter l'outil (mais ne supporte pas les guests linux pour le moment).
On télécharge les fichiers drakvuf-bundle, drakcore et drakrun à l’adresse https://github.com/CERT-Polska/drakvuf-sandbox/releases puis on installe le tout :
Ensuite, pour que drakvuf soit fonctionnel, on doit télécharger une image du guest à utiliser, ici Windows 10 : https://www.microsoft.com/fr-fr/software-download/windows10ISO puis on l'installe dans drakvuf (un seul guest est utilisable à la fois) :
L'interface web de drakvuf-sanbox est accessible sur le port http://127.0.0.1:6300.
1.3 mwdb-plugin-drakvuf
Pour pouvoir lancer des analyses dynamiques dans drakvuf depuis mwdb, il est nécessaire d'ajouter un plugin mwdb.
En tant qu'utilisateur mwdb, avec le virutalenv précédemment créé, activé, on lance :
Puis on modifie le fichier /home/mwdb/mwdb/mwdb.ini :
Enfin, on reconfigure mwdb pour utiliser le plugin :
Dorénavant, tout fichier PE téléchargé dans mwdb sera lancé dans drakvuf pour subir une analyse dynamique.
1.4 mwdb-plugin-karton
Karton est partie intégrante de drakvuf et par conséquent karton ainsi que ses dépendances, sont déjà installés. Pour pouvoir interagir avec cette installation (et par la suite créer nos propres modules), nous allons devoir configurer chaque plugin pour intégrer cette chaîne d’analyse.
Cette configuration nous ne l’écrirons qu’une fois, en faisant interagir mwdb et karton via l’installation du plugin mwdb-plugin-karton. Nous téléchargeons le code du plugin qui se trouve ici à cette adresse : https://github.com/CERT-Polska/karton-playground/tree/master/mwdb-plugin-karton et nous l’installons avec pip :
Nous créons ensuite le fichier de configuration /home/mwdb/mwdb/karton.ini comme ci-dessous, en utilisant les identifiants minio qu’on trouve dans le fichier /etc/drakcore/minio.env, dans votre profil mwdb :
Nous resterons toujours dans ce répertoire par la suite pour réutiliser cette configuration.
Il nous faut ensuite mettre un peu les mains dans le cambouis pour faire fonctionner le plugin en recompilant sa partie web (CERT.PL est en plein effort de partage/documentation de karton et cette étape ne devrait plus être nécessaire dans les prochaines versions).
Il faut installer nodejs et npm puis modifier le fichier mwdb.ini comme suit :
Ensuite, il nous suffit de recompiler sa partie web :
En vous rendant dans l'onglet `about` de mwdb, vous devriez maintenant voir la liste des plugins activés sur votre instance (voir Fig. 2).
1.5 MISP
Pour installer MISP, on a trois solutions : utiliser l’installeur https://github.com/MISP/MISP/tree/2.4/INSTALL, utiliser la machine virtuelle https://vm.misp-project.org/ ou utiliser une instance existante.
2. Modules Kartons
2.1 Cycle de vie et headers
Notre installation sert de support aux modules karton qui vont exécuter la logique de la chaîne d'analyse. Chaque karton peut être consommateur, producteur, ou les deux. Chaque tâche va être constituée principalement de ressources et de headers qui décrivent l’état de ces ressources dans leur cycle de vie. Cette dernière partie est très importante, car c'est par ces headers que se fait le routage des tâches dans karton. Ainsi, quand on va pousser un nouveau sample dans mwdb, le plugin karton va créer une tâche avec le header suivant :
Par défaut, un des modules qui va réagir aux tâches possédant ce header est le classifier. Celui-ci va identifier le fichier et ajouter de nouvelles informations dans le header pour définir le type de la ressource, par exemple :
Ce nouveau header fait avancer le sample dans son cycle de vie en déclenchant d'autres modules, par exemple, une analyse dynamique dans drakvuf.
2.2 module karton
Un module karton est un script python qui doit respecter certaines conventions, il lui faut un nom, un filtre et une fonction process :
Un module karton n'a qu'une seule dépendance : karton-core. Par ailleurs, celle-ci donne accès à la CLI karton qui permet de :
- lister les binds ou les modules qui ont enregistré un filtre, et donc une queue dans le système karton avec la commande list ;
- détacher les binds et supprimer les queues avec la commande delete.
3. Use Case : suivre un miner XMRig linux
Tâchons maintenant de réaliser quelque chose d'utile : nous avons eu à analyser récemment un miner XMRig linux dont le service de contrôle se trouve distribué entre de nombreux hidden services TOR [xmrigminer] [samples]. Après analyse, il s’avère que ces binaires sont compressés avec UPX, puis les headers UPX sont cassés volontairement pour empêcher la détection antivirus. Nous allons utiliser notre pipeline comme suit pour automatiser l'analyse et le partage des nouveaux samples de ce malware :
- mwdb ingère un nouveau sample, ce qui déclenche le pipeline karton ;
- karton-classifier identifie le sample comme étant un ELF ;
- karton-yaramatcher détecte les headers modifiés ;
- karton-upx-fixer corrige les headers ;
- karton-unpacker décompresse le sample corrigé ;
- karton-mwdb-reporter renseigne les nouveaux samples et nouvelles config dans mwdb ;
- karton-config-extractor extrait la configuration XMRig ;
- karton-misp-pusher pousse le résultat dans MISP.
Tous les modules ont besoin d'un fichier karton.ini pour fonctionner. Nous nous plaçons dans le répertoire /home/mwdb/mwdb qui contient déjà toutes les sections nécessaires et nous créons un environnement virtuel python3 pour chaque module qu'on installera pour éviter les problèmes de dépendance. Le plus simple et de laisser tourner les modules dans un multiplexeur de terminaux comme screen ou tmux pour expérimenter puis d’écrire des unités systemd pour chaque module une fois le pipeline fonctionnel (exercice laissé au lecteur).
Pour l'ingestion, nous utilisons simplement l'interface de mwdb pour télécharger les samples. mwdb dispose d'une librairie python [mwdblib] pour ajouter/supprimer des samples en masse.
3.1 karton-classifier
Ce module ne nécessite pas de modification. Nous créons un environnement virtuel, installons le module karton-classifier avec pip et le lançons :
3.2 karton-yaramatcher
De mème, nous créons un venv avant d'installer le module karton-yaramatcher. Ensuite, nous devons créer une règle yara qui va permettre de détecter les samples ayant les magic bytes UPX écrasés par les valeurs 00 FF 99 41 ou DF DD 30 33. Le module annote les samples détectés avec un tag pour qu'ils puissent être identifiés et traités par d'autres modules par la suite.
On crée un répertoire yara_rules contenant la règle torxmrminer.yar :
Et on lance le module :
3.3 karton-upx-fixer
Maintenant que nos samples sont correctement annotés, il nous faut créer un module de toute pièce qui va :
- détecter ces samples dans le pipeline ;
- corriger les headers pour les rendre utilisables par l'utilitaire UPX.
Pour cela, on crée un nouvel environnement virtuel qu'on active, on y installe karton-core avec pip et on crée le fichier karton-upx-fixer.py suivant :
3.4 karton-unpacker
karton-unpacker est un méta module qui peut décompresser automatiquement des binaires. Son module le plus simple est UPX, que nous allons utiliser ici. On installe karton-unpacker puis on télécharge et installe ses modules :
Quelques modules utilisent Qiling [qiling] et permettent de décompresser certains binaires par émulation. Nous choisissons de ne pas terminer leur installation ici par soucis de concision.
3.5 karton-config-extractor
karton-config-extractor est le module chargé d'extraire les données intéressantes d'un sample en utilisant malduck. Le principe de l'extraction de configuration est simple :
- On crée une règle yara pour sélectionner une partie du binaire (qui peut aussi être un dump mémoire drakvuf) qui contient des données qui nous intéresse ;
- puis on crée un callback malduck qui sera chargé de les extraire sous forme intelligible pour la suite du pipeline.
Dans le cas de notre malware XMRig, la configuration est simplement ajoutée au binaire sous forme JSON. On crée une règle yara pour la trouver et le script malduck correspondant pour l'extraire. XMRig incorpore son fichier après une chaîne d'octets reconnaissable config.json..xmrig.json..xmring/config.json puis 5 fois 00. Vient ensuite la configuration dont la fin est délimitée de nouveau par 5 fois 00.
On installe karton-config-extractor, puis on crée un répertoire modules qui va contenir notre module d'extraction personnalisé. Dans modules, on crée un répertoire xmrminer qui va contenir un fichier __init__.py :
On ajoute à notre module la règle yara xmrminer.yar :
Yara va permettre de récupérer l'adresse du premier octet détecté. Comme $json mesure 48 octets, on récupère une chaîne de caractères à l’adresse retournée +48 octets dans le script d'extraction xmrminer.py :
On lance le module avec :
3.6 karton-misp-pusher
Ce module filtre les configurations extraites et les pousse dans MISP. Comme les autres, il faut d'abord l'installer, puis le lancer.
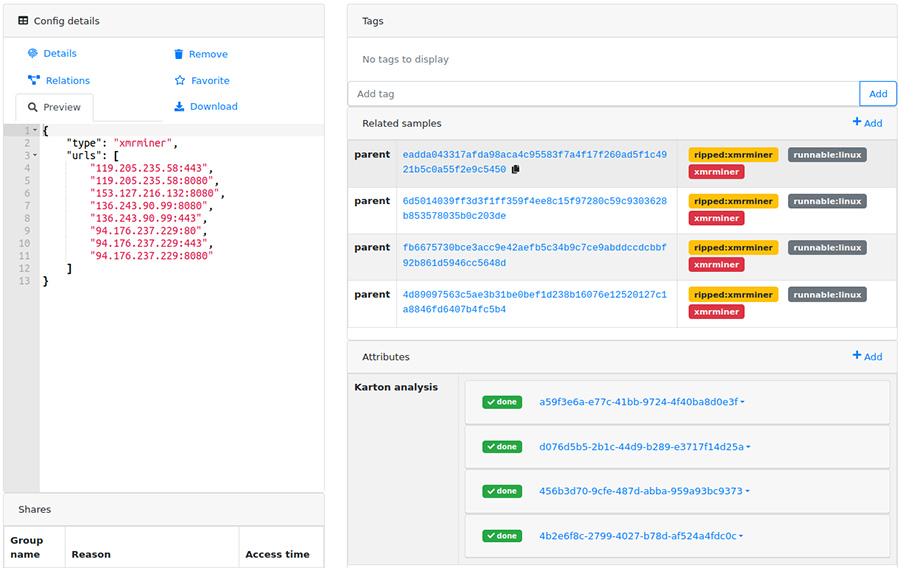
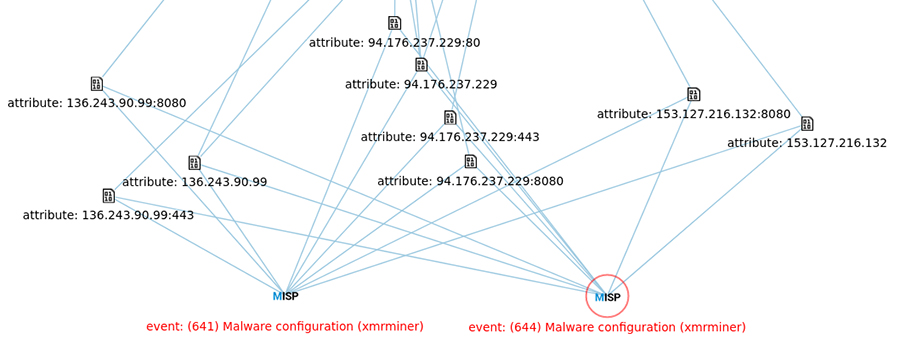
En téléchargeant un sample XMRig miner [samples] dans votre mwdb, vous obtenez maintenant l'extraction automatique de sa configuration dans mwdb (voir Fig.3) et les corrélations avec les autres configurations dans MISP prêtes à être partagées (voir Fig.4).
Épilogue
Voilà pour un exemple de la mise en œuvre d'un pipeline d'analyse de malware open source en 2021. Ce cas d'usage est très simple, mais a le mérite de montrer toute la chaîne de traitement, depuis l'analyse, jusqu'au partage d'informations. Que se soit via le traitement de binaires recueillis à travers des honeypots ou un EDR (on l’a fait par exemple avec WHIDS [WHIDS]), ses interactions avec drakvuf ou cuckoo, jusqu’à l’export MISP et l’ingestion des logs dans Splunk ; la nébuleuse des outils cert.pl possède de vrais atouts de par sa flexibilité et sa faculté à interagir facilement avec d’autres outils. J’espère vous avoir fourni les clés pour vous donner envie d’en apprendre plus à son sujet.
Références
[MISP] https://misp-project.org
[mwdb] https://www.cert.pl/en/posts/2019/01/mwdb-our-way-to-share-information-about-malicious-software/
[malduck] https://github.com/CERT-Polska/malduck
[karton] https://github.com/CERT-Polska/karton
[drakvuf] https://drakvuf.com/
[docker] https://github.com/CERT-Polska/karton-playground/
[ds] https://github.com/CERT-Polska/drakvuf-sandbox
[xmrigminer] https://www.d4-project.org/2021/04/20/torproxies.html
[mwdblib] https://github.com/CERT-Polska/mwdblib
[qiling] https://qiling.io/


