

On trouve des compilateurs partout : quand on construit des programmes, bien sûr, mais aussi quand on visite la page web des Éditions Diamond — elle embarque du JavaScript, qui est probablement compilé à la volée par un composant de votre navigateur. Quand on utilise un Notebook Jupyter pour du calcul scientifique — ne serait-ce que pour la compilation en bytecode du source Python. Quand on installe un APK pour ART, celui-ci est transformé en code natif depuis son bytecode Dalvik… encore de la compilation. Et nous allons voir que le domaine de la compilation peut aussi très largement intéresser celui de la sécurité informatique et du reverse engineering.
1. Qu'est-ce qu'un compilateur ?
C'est un programme qui prend en entrée un code source et le transforme en une représentation d'un niveau d'abstraction généralement inférieur (ou égal). Ainsi, un programme qui transforme un fichier texte écrit en langage C en un fichier texte écrit en langage assembleur est un compilateur (voir figure 1). Le programme LaTeX est également un compilateur, puisqu'il transforme une description de haut niveau d'un document en une version bas niveau, au format DVI par exemple. Le vénérable cat est un cas limite de compilateur :-)
2. Une famille éclectique
La famille des compilateurs est grande : il existe des compilateurs source à source dont la sortie est un format textuel et non binaire, comme les minifier JavaScript ; des compilateurs à la volée qui génèrent du code pendant l'exécution d'un programme hôte qui utilise directement le code généré pour continuer son exécution. Le moteur V8 de Chrome, dédié à l'exécution et la compilation à la volée de… JavaScript en est un bon exemple. Il existe aussi des compilateurs faisant de la compilation croisée, c'est-à-dire qui génèrent du code machine pour une architecture matérielle différente de celle sur laquelle ils s'exécutent, ce qui est très pratique quand on compile pour des architectures ayant de faibles capacités de calcul.
Il n'est pas rare d'avoir plusieurs compilateurs différents — et donc plusieurs formats — dans le même écosystème. Beaucoup de langages dits de haut niveau exposent une API C qui leur permet de fournir une surcouche autour de bibliothèques natives existantes. C'est notamment le cas du langage Python, dont plusieurs modules standards sont le résultat de la compilation d'un code C en code natif présent dans une bibliothèque partagée, bibliothèque dont l'importation est supportée par le mécanisme d'import de Python. Une exécution de code Python navigue constamment entre interprétation de bytecode et exécution de code natif.
Une branche de la famille des compilateurs chère au cœur des lecteurs de MISC est celle des décompilateurs, ces compilateurs qui partent d'une représentation bas niveau pour générer une représentation de plus haut niveau. Par exemple, le décompilateur RetDec est capable de décompiler un code assembleur en bitcode LLVM, puis de décompiler un bitcode LLVM vers un code C. Par nature, le processus de décompilation est imparfait, puisque certaines informations sont perdues lors de la compilation (un exemple trivial : le nom des variables locales et de certains types), mais on y reviendra.
3. La compilation, un domaine pour le reverser ?
Comprendre les différents mécanismes de compilation offre au reverser une meilleure compréhension de son objet d'étude : savoir qu'on est arrêté sur un code compilé à la volée, c'est avoir la possibilité de remonter à son entrée, probablement plus simple à comprendre. C'est aussi pouvoir séparer un binaire en sections différentes suivant leur langage d'origine, et pour chaque langage remonter aux idiomes spécifiques à ce langage, voire reconnaître les marqueurs de certains algorithmes.
Mais avoir des bases en compilation, c'est aussi s'offrir de nouvelles cordes à son arc pour mieux reverser ; on ne compte plus les outils mettant en œuvre des techniques de compilation et diffusés dans le monde de la sécurité informatique : RetDec [RetDec] (décompilation), Triton [Triton] (exécution concolique), Miasm [Miasm] (désobfuscation).
Les dernières sections de cet article illustrent plus en détails quelques-uns de ces liens entre compilation d'une part et sécurité informatique ou reverse engineering d'autre part, en se concentrant sur les plus classiques des compilateurs : les compilateurs statiques (on dit aussi ahead of time par opposition aux compilateurs à la volée just in time) de source vers binaire, et les outils de reverse correspondants.
4. Compiler pour mieux sécuriser
Les compilateurs peuvent optimiser un code pour la sécurité, en incluant des protections contre des erreurs de programmation communes ou des contre-mesures pour des failles matérielles connues, compliquant ainsi le travail du reverser malveillant.
Un des exemples les plus répandus est la protection contre les conséquences de certains types de dépassement de tampon. Prenons l'exemple du fameux stack canary. Pour chaque fonction compilée avec cette protection, le compilateur évalue si cette fonction est exposée à des attaques de type dépassement de tampon. Les critères varient suivant les options passées par l'utilisateur, mais elles permettent de prendre en compte la taille de la pile, ou la présence d'allocation dynamique de la pile, ces deux informations étant connues par le compilateur lors de l'émission du code assembleur. Le cas échéant, le compilateur insèrera une écriture dans la pile d'une valeur aléatoire fournie par le système lors du prologue de la fonction, et une vérification de cette valeur avant chaque saut hors de la fonction. Cette protection est activée par -fstack-protector sous GCC et Clang.
Dans certains cas, le compilateur pallie également les limitations du système : afin de détecter une collision entre la pile et le tas, le noyau Linux alloue systématiquement une page mémoire protégée en lecture et écriture entre ces deux espaces. Ainsi, un programme qui allouerait trop de pile (p.e. à travers des appels récursifs) finirait par allouer de la mémoire utilisant cette page, et l'accès à cette mémoire déclencherait une erreur. Cependant, si une allocation de pile venait à dépasser la taille d'une page, et que les accès à la pile sautent aussi cette page, un attaquant contrôlant la pile gagne un accès au tas. Pour contrer cette attaque, le compilateur découpe chaque allocation de la pile par pages, et force un accès mémoire entre chaque allocation de page, déclenchant ainsi la page de garde. Cette protection est activée par -fstack-clash-protection sous GCC et Clang.
Il y a quelques années, une attaque reposant sur la prédiction de branchement des processeurs modernes a défrayé la chronique. L’attaque « Spectre » [Spectre2019] permet de charger une adresse mémoire gardée par un prédicat faux si la prédiction de branchement considérait ce prédicat comme vrai, amenant ainsi la donnée en cache. La contre-mesure implémentée dans Clang/LLVM masque chaque adresse mémoire accédée à travers un prédicat avec une valeur dépendante du prédicat, ce qui rend l'adresse invalide si le prédicat est faux. Cette transformation se fait au niveau de la représentation interne (RI) de LLVM et est activée par -mspeculative-load-hardening.
De nombreuses autres protections ont vu le jour dernièrement : vérification de l'intégrité du flot de contrôle (CFI), parfois avec support matériel (XFG), authentification de pointeurs… C'est un sujet foisonnant !
5. Un obfuscateur dans un compilateur ou comment ramer à contre-courant
Obfusquer un programme, c'est le transformer en un programme fonctionnellement équivalent, mais dans lequel les éléments à protéger sont plus complexes à retrouver, quitte à en payer le prix en termes de performances.
Cette complexité peut prendre diverses formes, comme le remplacement d'une opération ou d'une constante par une série d'opérations plus complexes, le chiffrement des chaînes de caractères, l'ajout de branchements conditionnels, l'aplatissement du flot de contrôle des fonctions, la découpe en petits fragments ou la fusion de code, etc. L'éventail des possibilités est large [Hosseinzadeh2018] !
Et le tout doit se faire de la façon la plus diversifiée possible pour désorienter l'attaquant.
Transformer un programme, c'est le rôle des compilateurs, et l'idée est donc tentante de les réutiliser pour bénéficier de leurs infrastructures de modification de code. Cependant, il ne faut pas oublier que ces outils sont d'abord conçus pour être au service de la performance, en temps d'exécution, ou en empreinte mémoire, statique ou dynamique. Et ces objectifs vont à l'encontre de la complexification et de la variabilité recherchées pour l'obfuscation : le développeur d'obfuscations doit donc s'assurer qu'elles ne sont pas cassées par les optimisations du compilateur.
De ce point de vue, le choix de la partie du compilateur (voir figure 2) dans laquelle insérer les obfuscations n'est pas anodin [Guelton2018].
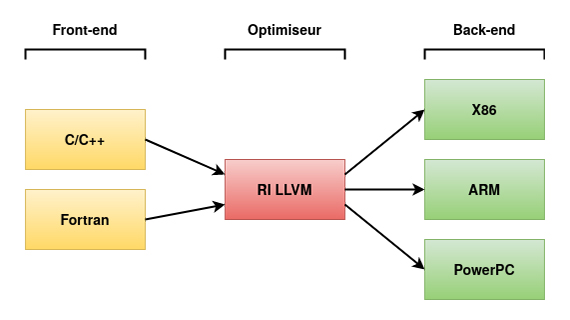
S'insérer dans le front-end, qui traduit le code source en une représentation intermédiaire (RI), permet de tenir compte des caractéristiques de haut niveau du langage, mais nécessite d'écrire un obfuscateur pour chaque langage source. De plus, le code obfusqué risque de ne pas bénéficier des optimisations du compilateur, car il devra être en mesure de résister à celles-ci pour rester obfusqué.
Intervenir au niveau du back-end, qui traduit la RI en code assembleur, permet d'introduire de la diversité au niveau des instructions ou séquences d'instructions assembleurs générées (par exemple, en remplaçant certains lea par des sub), d'introduire des instructions assembleur inutiles, etc. En revanche, cela nécessite de développer un obfuscateur par architecture cible.
La dernière option est d'implémenter les obfuscations dans l'optimiseur, qui travaille exclusivement sur la représentation intermédiaire : les transformations sont alors (quasiment) indépendantes du langage source et des architectures cibles. C'est le cas d'OLLVM [OLLVM] ou YANSOllvm [YANSOllvm] parmi les outils open source, ou de Quarks App Protect [QAP] (anciennement Epona). Dans tous ces outils, les transformations sont réalisées sur la RI LLVM, et bénéficient donc de ces caractéristiques et des outils et analyses mis à disposition (forme SSA, graphe de flot de contrôle, graphe d'appels, analyses de dépendances…).
Pour profiter des gains de performance apportés par les optimisations du processus de compilation normal, il est possible d'implémenter les obfuscations après les passes d'optimisation. Refaire tourner les optimisations après les obfuscations (voir figure 3) permet aussi de nettoyer le code généré et de s'assurer que ce dernier est en mesure de leur résister, que ce soit par des contrôles visuels, ou automatisés dans un processus d'intégration continue (CI).
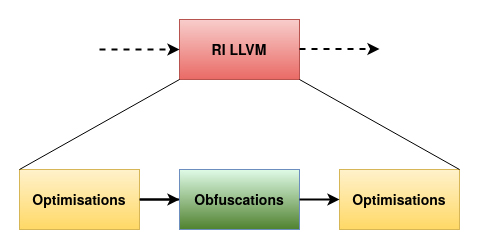
Nous allons d'ailleurs voir dans les sections suivantes que cette capacité à résister aux optimisations est loin d'être un détail !
6. Compiler pour reverser ?
Paradoxal, non ?
En fait pas tant que ça. Des désassembleurs/décompilateurs comme Binary ninja, Ghidra, IDA Pro, angr, radare2, Hoppe ou Miasm par exemple [Wagner2019] utilisent des techniques similaires à celles rencontrées dans les compilateurs : analyses de flot de données ou d'ensembles de valeurs, forme SSA, élimination de code mort… Et ce, aussi bien pour construire que pour raffiner leurs différents niveaux de représentations intermédiaires, qui sont généralement des représentations internes « maison ». Chacun de ces désassembleurs/décompilateurs réimplémente donc ses propres analyses et transformations…
Utiliser une représentation interne commune comme la RI LLVM leur permettrait de bénéficier directement des analyses et optimisations de LLVM, qui ont l'avantage d'être nombreuses et éprouvées, mais aussi des nombreux outils qui reposent sur cette représentation. Plusieurs initiatives ont vu le jour à cet effet, les plus actives et matures semblant être McSema/ReMill et RetDec :
- RetDec [RetDec] s'appuie sur Capstone [Capstone] lors de son processus de traduction du binaire en RI LLVM. Il utilise certaines optimisations de LLVM et ajoute des transformations qui lui sont propres. Le code généré est donc déjà bien nettoyé.
- McSema [McSema] utilise un désassembleur tiers (IDA ou Binary Ninja) pour récupérer le flot de contrôle de l'application étudiée. Il traduit alors les portions de binaire correspondant à du code en RI LLVM en utilisant ReMill [Remill] [McSemaLifting]. Le code généré est assez compliqué, car il fournit pour chaque instruction une émulation de son comportement.
Une fois le code assembleur transformé en RI LLVM, il s'agit d'en extraire des informations pertinentes, notamment en le débarrassant des différentes couches d'obfuscation qui peuvent le protéger. Parmi les nombreux outils reposant sur la RI LLVM, certains aident à l'analyse et/ou l'optimisation/simplification de programme. Citons par exemple le moteur d'exécution symbolique dynamique KLEE [Klee] qui permet d'explorer des chemins d'exécution et de raisonner au sujet de leur faisabilité à l'aide d'un solveur SMT. Ou encore le super-optimiseur Souper [Souper], qui permet de simplifier une portion de programme en validant la transformation à l'aide d'un solveur SMT.
Une étude [Saturn2019] s'est ainsi récemment penchée sur le couplage de la sortie de ReMill avec Souper afin de simplifier les prédicats opaques. Le code résultant est ensuite simplifié par l'optimiseur de LLVM, et ceci dans un processus itératif jusqu'à atteindre un état stable. Même si le processus reste coûteux et ne cible pas tous les types d'obfuscation, il démontre toutefois la faisabilité d'utiliser une représentation interne de compilateur comme support pour une chaîne d'outils automatiques d'aide au reverse engineering.
On notera cependant que les outils de décompilations ne font que retrouver une structure présente, implicitement ou explicitement, dans le binaire final. Certaines informations comme les noms de variables locales, absentes du binaire, sont à jamais perdues. Certaines abstractions, comme les classes ou les structures, peuvent être partiellement reconstruites en s’appuyant sur le mangling de certains symboles et sur les conventions d'appel pour les méthodes. Parfois, un idiome est reconnaissable et facilite la reconstruction de l'abstraction, p.e. pour la gestion des exceptions. Le processus reste donc intrinsèquement imparfait.
Alors, Tom ou Jerry ?
En résumé, les outils de la compilation sont devenus des éléments incontournables dans le domaine de la sécurité des applications, que ce soit pour les protéger, les obfusquer ou même les reverser. Ce qui nécessite de connaître un minimum leur fonctionnement interne, mais ce sera l'objet d'un article à venir !
Dans l'immédiat, une question se pose : si les reversers jouent à armes égales avec les compilateurs, est-ce vraiment une bonne idée d'utiliser ces derniers à des fins de protection ? Dans la pratique, les outils de reverse disponibles présentent souvent des inconvénients : ils sont efficaces contre un nombre limité de protections, et sont parfois coûteux à appliquer à grande échelle, ce qui nécessite de déterminer préalablement les zones d'intérêt dans le binaire à analyser. Empiler des couches de protections variées et protéger l'ensemble de l'application (et pas seulement les éléments sensibles) demeure donc un moyen efficace de complexifier la tâche des attaquants. Mais cela reste toujours un jeu du chat et de la souris !
Références
[RetDec] RetDec, https://github.com/avast/retdec
[Triton] Triton, https://triton.quarkslab.com/
[Miasm] Miasm, https://miasm.re
[Spectre2019] P. Kocher, J. Horn, A. Fogh, D. Genkin, D. Gruss, W. Haas, M. Hamburg, M. Lipp, S. Mangard, T. Prescher, M. Schwarz, et Y. Yarom, « Spectre Attacks: Exploiting Speculative Execution », 40th IEEE Symposium on Security and Privacy (S&P'19), IEEE, 2019
[Hosseinzadeh2018] S. Hosseinzadeh et al., « Diversification and Obfuscation Techniques for Software Security: A Systematic Literature Review », Information and Software Technology, 2018
[Guelton2018] S. Guelton, A. Guinet, P. Brunet, J. M. Martinez Caamaño, F. Dagnat et N. Szlifierski, « Combining Obfuscation and Optimizations in the Real World », 18th IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM), 2018
[OLLVM] OLLVM, https://github.com/obfuscator-llvm/obfuscator
[YANSOllvm] YANSOllvm, https://github.com/emc2314/YANSOllvm
[QAP] Quarks App Protect, https://quarkslab.com/quarks-appshield-app-protect/
[Wagner2019] R. Wagner, « Modern Static Analysis of Obfuscated Code », 3rd ACM Workshop on Software Protection (SPRO'19), ACM, 2019
[Capstone] Capstone, https://www.capstone-engine.org/
[McSema] McSema, https://github.com/lifting-bits/mcsema
[ReMill] ReMill, https://github.com/lifting-bits/remill
[McSemaLifting] Heavy lifting with McSema 2.0, https://blog.trailofbits.com/2018/01/23/heavy-lifting-with-mcsema-2-0/, 2018
[Klee] KLEE, https://klee.github.io/
[Souper] Souper, https://github.com/google/souper
[Saturn2019] P. Garba et M. Favaro, « SATURN Software Deobfuscation Framework Based on LLVM », 3rd ACM Workshop on Software Protection (SPRO'19), ACM, 2019