

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Recueillir et utiliser des informations liées aux menaces informatiques n'est pas chose aisée ; les standardiser et les partager est encore plus difficile. L'outil libre de renseignements sur les menaces MISP a été conçu afin de faciliter ces aspects complexes et pourtant si essentiels de nos jours. Dans cet article, nous explorons les principaux concepts et fonctionnalités qui ont fait la popularité de la plateforme auprès des analystes en cybersécurité.
La communauté informatique est confrontée à des incidents de toutes sortes et natures, de nouvelles menaces apparaissant quotidiennement. Combattre ces incidents de sécurité individuellement est presque devenu une tâche impossible. Le partage d’informations sur les menaces au sein de la communauté est devenu un élément clé dans la réponse aux incidents pour rester au niveau des attaquants. Des ressources d’information fiables, fournissant des informations crédibles, sont donc essentielles pour assurer une réponse sur incident adéquate au sein des entreprises et organisations.
Cet article présente la plateforme libre de partage d’informations et de renseignements sur les menaces en cybersécurité dénommée MISP. Le projet MISP a démarré il y a plus de dix ans. Son objectif initial était le partage d’indicateurs de compromission (IoC) pour aider à la détection et surtout éviter le travail redondant entre plusieurs équipes de CERT en Europe.
Ce petit projet open source est devenu au fil du temps un projet significatif avec plus de cinq cents contributeurs à travers le monde et plusieurs milliers d’utilisateurs. MISP est devenu un standard incontournable pour l’échange et la fusion d’informations des domaines de cybersécurité, de renseignements et de fraudes financières. La Commission européenne a plusieurs fois financé des développements dans MISP et continue à le faire pour Cerebrate [CEREBRATE], que nous présentons plus bas. Son schéma de licensing [1] et sa gouvernance [2] en font un projet pérenne pour lequel le risque de mauvaise surprise est minimal.
Cette pluralité d’usages favorise les contributions et MISP est aujourd’hui plus qu’une simple plateforme. MISP intègre désormais des librairies communes sur les menaces et adversaires [3], plus de deux cents taxonomies [4] pour aider à la classification de l’information et une pile de logiciels libres pour la structuration du renseignement et le partage d’informations.
Le présent article est une introduction à l’utilisation de MISP, son modèle de données et les possibilités d’intégration dans un SOC, CERT ou toute équipe de sécurité. Nous montrons comment le projet est utile pour le partage d’informations et comment il aide à la mise en place d’actions préventives, de détections et de mesures contre les attaques ciblées, mais aussi à mieux comprendre les attaques auxquelles fait face une organisation.
1. MISP - Les concepts de base
Dans cette section, les concepts de base de MISP sont présentés. Nous avons fait le choix de garder la dénomination anglo-saxonne de la terminologie utilisée dans MISP pour faciliter les éventuelles recherches que le lecteur pourrait faire en ligne à leur propos.
Tout d’abord, il est important de comprendre la manière dont MISP est organisé. Comme dans toute application, des structures de données prédéfinies existent et sont utilisées pour représenter et sauvegarder des données. De telles structures dans MISP sont par exemple les attributes et les events.
Les attributes sont des blocs individuels qui contiennent l’essence même de l’information à utiliser ou à partager. Grâce à leur caractéristique appelée type, les attributes peuvent représenter des concepts tels qu’une adresse IP, un nom de domaine ou un hash cryptographique. En plus de contenir un type et une valeur, ils peuvent exprimer s’ils sont des indicateurs de compromission (IoC) comme par exemple le hash d’un logiciel malveillant ou bien des données de support telles que des analyses ou références vers de la documentation.
Dans la plupart des situations, ces blocs d’informations sont souvent intrinsèquement liés entre eux et peuvent être combinés pour former un objet plus élaboré appelé MISP Object. Grâce aux Objects, les attributes peuvent être combinés en une structure qui a du sens. Un exemple très parlant est celui de la représentation d’un fichier. Tous fichiers possèdent plusieurs propriétés comme un nom, une taille et un contenu. Il devient donc évident que plusieurs attributes représentant ces propriétés peuvent être combinés afin de former un object du type fichier.
Par leurs natures, les objects organisent et facilitent la lecture des données dans l’application. Mais l’efficacité de ces structures est décuplée lorsque l’on y ajoute la capacité de les lier entre eux. Les objects references ont été introduites dans cette optique. Ce sont des relations entre objects et attributes permettant d’exprimer leurs interactions. Avec leur aide, il devient possible de représenter des comportements ou des similarités et de décrire des actions entre les différentes entités sous la forme d’un graphe (cf. event graph plus loin). On peut par exemple représenter qu’un logiciel malveillant a téléchargé un virus en se connectant sur une adresse réseau spécifique, ou qu’un site internet se fait passer pour un autre.
Une lacune des concepts présentés jusqu’ici réside dans le fait qu’il n’est pas possible de grouper les attributes et objects contextuellement liés entre eux. Les MISP Events comblent ce vide en agissant comme une enveloppe et permettent de rassembler ces données ensemble. Typiquement, les events sont utilisés pour encoder des incidents, des événements ou encore des rapports.
Il est important de noter qu’à la fois les attributes, objects et events peuvent tous être contextualisés à titre individuel, mais que cette contextualisation peut aussi être propagée de l’entité parente jusqu’à l’enfant. En d’autres termes, tout attributes faisant partie d’un event marqué comme pratiquant de l’hameçonnage ciblé (spear-phishing) héritera systématiquement de ce contexte.
Et en ce qui concerne le cas du partage d’informations, toutes les unités d’information (event, object, attributes, etc.) peuvent posséder leur propre niveau de distribution indépendamment les unes des autres. Ceci offre aux utilisateurs une granularité très fine de la dissémination de l’information.
Un des aspects les plus puissants de MISP est probablement sa capacité à pouvoir accueillir n’importe quel type de structure de données même si elles sont inconnues de l’outil. Cette fonctionnalité souvent négligée par d’autres logiciels similaires offre une solution élégante pour symboliser n’importe quel concept. On peut citer par exemple certains cas connus d’utilisation comme la représentation de voitures, des rapports sismologiques ou encore l’interception d’ondes radar.
Il en va bien évidemment de même pour la contextualisation. Tous les moyens disponibles pour ajouter du contexte proviennent d’un système astucieux composé de projets autonomes hébergés sur GitHub. Cette organisation favorise la contribution provenant de la communauté tout en garantissant une segmentation claire et précise des différents projets. Néanmoins, les utilisateurs ne sont pas tributaires de ces projets et peuvent toujours créer leurs propres contextes sans avoir besoin de les partager avec la communauté.
Afin de faciliter encore plus l’implication de la communauté dans le maintien et la mise à jour de ces projets, ceux-ci sont composés de fichiers JSON offrant le bénéfice d’être aisés à éditer pour un humain et faciles à lire pour une machine. Heureusement, même dans le cas où des éléments voulant être exprimés ne seraient pas disponibles dans ces listes, MISP est capable de reconnaître et d’utiliser des listes modifiées et personnalisées ayant été créées par des personnes tierces.
Cette solution est donc un excellent compromis entre flexibilité et structuration tout en garantissant que quiconque soit libre d’étendre MISP à sa guise.
Le dernier point à aborder afin d’avoir une vue d’ensemble du logiciel est incontestablement celui du partage d’informations et de la collaboration. MISP comprend plusieurs moyens de synchronisation automatique permettant de recevoir des données et d’en envoyer tant que celles-ci adhèrent aux règles définies sur les liens de synchronisation.
Une collaboration ne serait pas efficace si deux individus ne peuvent pas échanger leurs opinions sur les données. C’est pourquoi MISP donne la possibilité aux analystes de proposer des modifications aux données reçues et de les propager jusqu’à leur créateur afin que celui-ci les accepte ou les rejette. Cet aspect porte le nom de proposals et est crucial pour éviter les faux positifs et erreurs.
2. MISP dans le pipeline CTI
MISP peut être utile dans toutes les phases du pipeline CTI. Les sections présentées ci-dessous proposent des suggestions et astuces afin d’améliorer l’expérience et l’utilisation de l’outil.
2.1 Collection
MISP est principalement un outil de partage d’informations (n’importe quel type d’information) et permet de récupérer des events provenant d’instances connectées. Comme nous l’avons vu dans le premier article, il est préférable de rejoindre des communautés d’organisations soumises aux mêmes risques pour obtenir du renseignement pertinent (Information Sharing and Analysis Centers - ISAC). Par ailleurs, il est possible d’ingérer des feeds de Threat Intelligence (une trentaine sont disponibles gratuitement par défaut) et d’évaluer leurs intersections. Cela rend très facile l’évaluation de solutions payantes par rapport à des flux libres issus de la communauté.
Les feeds sont aussi un moyen rapide et peu coûteux de sauvegarder localement son contenu afin d’être utilisé par le système de corrélation ou pour vérifier si une valeur en fait partie. Par exemple, MISP inclut par défaut la liste des nœuds de sortie TOR via un feed. Ces données peuvent être placées dans une base de données annexe par le processus de mise en cache et pourront servir sans pour éviter de polluer la base de données.
2.2 Contextualisation
Un des aspects les plus importants et pourtant couramment mis de côté est la contextualisation. Si faite correctement, cette étape permet aux utilisateurs d’en apprendre plus sur l’origine des données, ce qu’elles concernent, si elles sont pertinentes pour une organisation donnée et comment les exploiter au mieux.
L’une des fonctionnalités facilitant la contextualisation dans MISP est l’annotation. On peut annoter de l’information dans MISP en utilisant de simples tags (de simples étiquettes attachées à une donnée) pour rapidement marquer une donnée, ou des galaxy clusters (morceaux d’une encyclopédie consacrée à un sujet en particulier) pour annexer des informations documentées et vérifiées par la communauté.
L’avantage principal des galaxy clusters est qu’ils peuvent être agencés de manière à représenter une matrice rendant la lecture d’actions chaînées plus facile. Un grand succès de ce genre de matrice est incontestablement la base de données de MITRE ATT&CK décrivant les tactiques, techniques et procédures des attaquants. Le framework MITRE ATT&CK est très populaire et son utilisation est fortement recommandée, car il offre des possibilités de descriptions très détaillées. Il permet de bien comprendre comment les attaquants agissent et quels sont leurs objectifs, ce qui aide à prendre les contre-mesures adaptées pour se défendre plus efficacement.

Indépendamment de ces deux extrêmes de classification, MISP supporte un système intermédiaire appelé taxonomies proposant un large choix de listes de vocabulaire complètes permettant une classification précise et efficace. Dès lors que les informations sont encodées correctement, il devient trivial de naviguer à travers une grande quantité d’informations et d’en extraire le contenu recherché.
En plus des différentes techniques de contextualisation existantes, MISP crée automatiquement des relations entre attributes grâce à un système appelé correlation engine. Ce système offre la possibilité de voir si des events présentent une intersection comme un malware similaire, une adresse IP réutilisée ou de manière plus générale, n’importe quelle donnée.
En supplément de ces liens créés automatiquement, MISP permet au dicton « un bon dessin vaut mieux qu’un long discours » d’être mis en pratique grâce à la fonctionnalité Event Graph. Elle permet aux analystes de visualiser ou de créer des relations entre les différentes entités afin de pouvoir décrire de manière concise des scénarios complexes tels que des événements exécutés en parallèle ou des attaques en plusieurs étapes. La représentation de l’Event Graph en figure 2 permet de comprendre en quelques secondes toutes les étapes de l’attaque réalisée par le pirate.
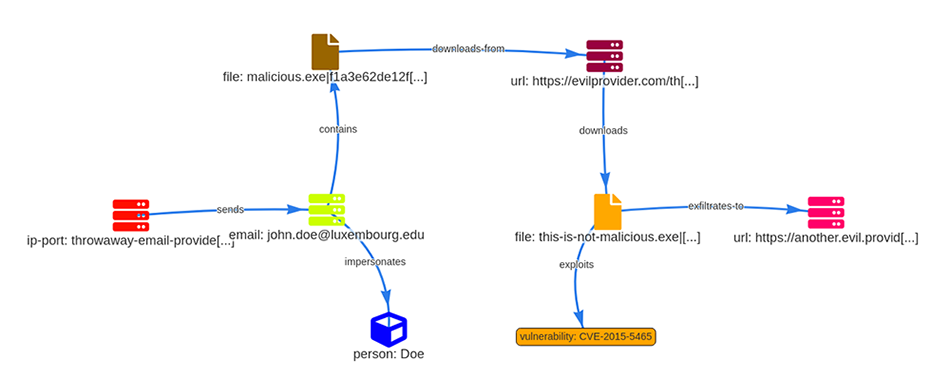
Les différentes techniques de contextualisation citées ci-dessus sont utiles pour modéliser un contexte peu variable, mais omettent de prendre en compte de manière efficace la temporalité des données. Pour combler ce manque, le système de sighting a été développé et sert à exprimer qu’une certaine donnée a été observée un certain nombre de fois, lui donnant ainsi un caractère temporaire et donc, plus de crédibilité. Si exploité correctement, ceci peut être extrêmement utile lorsqu’il s’agit de filtrer les faux positifs.
Astuce
Une application basique, mais très pratique est de mettre en place une boucle entre un système d’intrusion de détection (IDS) et les sightings provenant de MISP.
En premier lieu, MISP met à disposition de l’IDS une liste d’indicateurs devant être bloqués. Lorsqu’une menace est détectée et bloquée, un sighting pour marquer l’activité est créé dans MISP et est partagé avec la communauté. Plus tard, lorsque l’IDS veut récupérer une liste mise à jour des derniers indicateurs à bloquer, MISP priorisera les indicateurs ayant eu une activité récente ; le cycle peut ensuite recommencer. Ainsi, MISP peut toujours fournir une liste dynamique de taille raisonnable qui sera mise à jour continuellement pour l’IDS.
2.3 Analyse
Grâce à ses structures de données riches et flexibles, MISP offre des moyens de description et de visualisation de scénarios d’attaques complexes. En plus de l’exploration de graphes de corrélations et des graphes d’événements (event graph), MISP propose un outil de navigation chronologique des données d’un events sous la forme d’une ligne du temps ou frise chronologique. Cette interface présente toutes les occurrences d’attributes ou objects basées sur leurs données de première et dernière observation. Cette fonctionnalité est très fréquemment utilisée pour représenter des changements d’adresses réseau ou des changements d’identités virtuelles telles que des adresses e-mail.
Par ailleurs, même si MISP met à disposition plusieurs interfaces de visualisation, il est toujours possible d’interfacer d’autres outils à son API. Un excellent exemple d’une telle intégration est l’outil MISP-maltego [MISP-MALTEGO]. Cette intégration contient un ensemble de transformations pour l’outil Maltego qui interagissent avec une instance MISP et permettent d’explorer son contenu sans quitter le logiciel. Il devient dès lors possible de combiner des données provenant à la fois de MISP et d’une autre base de données.
2.4 Enrichir les données partagées à l’aide de modules
Dans l’écosystème de dictionnaires et de logiciels gravitant autour de MISP, nous retrouvons les MISP-modules [MISP-MODULE], un système autonome de modules python qui permettent d’étendre les fonctionnalités de la plateforme sans toucher à son noyau. Nous pouvons distinguer deux types de modules :
- Les modules d’import/export ont pour but d’importer ou exporter des données non présentes dans MISP, exprimées sous un format différent et donc converties en format JSON MISP.
- Les modules d’enrichissement permettent d’améliorer des données qui se trouvent déjà partagées sur la plateforme, à l’aide de requêtes vers des services extérieurs.
L’enrichissement de données déjà sauvegardées et partagées au niveau de la plateforme s’avère être une fonctionnalité fort intéressante dans le travail d’un analyste. À partir d’un IoC, il est possible de collecter un bon nombre d’informations complémentaires qui vont soit donner plus de détails sur l’IoC en question, soit retourner d’autres données pouvant à leur tour être définies comme potentiellement malveillantes et catégorisées comme IoC.
Le principe de ce type de module est très simple :
- La valeur de l’attribut à propos duquel nous souhaitons obtenir des informations supplémentaires est utilisée pour interroger le service externe voulu, qui retourne en réponse les informations voulues.
- Les résultats peuvent dans certains cas simplement être affichés dans une fenêtre flottante. C’est notamment le cas lorsque l’on questionne un service au vu d’obtenir plus de détails sur notre attribut initial. En d’autres termes, c’est une simple requête de « lookup ».
- Dans d’autres cas de figure, les résultats à notre requête apportent de réelles données complémentaires, qui vont être converties en format standard MISP qu’il sera possible d’ajouter à l’event auquel appartient l’attribut initial. On parle donc dans ce cas d’enrichissement.
Parmi les services externes supportés, nous pouvons citer notamment CVE-search, passive-ssl ou passive-ssh, des API libres d’utilisation permettant d’accéder à des librairies de données fournissant de précieuses informations complémentaires sur les vulnérabilités existantes, l’historique des certificats x509 par adresse IP ou encore celui des enregistrements DNS.
De nombreux autres services sont supportés et disponibles via les modules, et il est également facile de construire soi-même un module en seulement quelques lignes, comme le montre la simplicité du module DNS auquel nous pouvons soumettre un nom de domaine et recevoir en réponse toutes les adresses IP correspondant à la résolution DNS du domaine en question.
Ainsi, même si certains modules requièrent l’accès à certaines plateformes propriétaires, à l’aide de clés d’API par exemple, un bon nombre de services restent accessibles gratuitement.
2.5 Interopérabilité et intégration avec les autres standards
À l’image du support de divers services externes décrit ci-dessus, l’un des objectifs clés de MISP est de s’intégrer facilement au flux opérationnel (workflow) d’un maximum de ses utilisateurs. Pour cela, un réel effort a été porté sur le développement et le maintien des multiples intégrations disponibles dans MISP. Comme mentionné déjà brièvement dans notre article sur le pipeline CTI, le but est à la fois de permettre aux données recoupées par des analystes d’être importées dans MISP au vu d’être partagées, et d’utiliser ensuite le contenu partagé pour alimenter d’autres outils de sécurité.
Ainsi, MISP intègre de nombreux outils permettant d’ingérer des données, tels que :
- Quelques modules d’import déjà cités ci-dessus.
- Des fonctionnalités de synchronisation pour récupérer les informations partagées au niveau de toutes les instances connectées dans une communauté d’instances.
- Des feeds de données en libre accès qui peuvent être également synchronisées, et la possibilité d’ajouter tout autre feed.
Mais la plateforme dispose également d’un client REST intégré permettant d’accéder de façon programmatique à toutes les fonctionnalités disponibles de l’interface utilisateur. Outre les fonctionnalités d’administration de la plateforme et d’ajout/suppression de données, celle que nous souhaitons mettre en lumière ici est l’export de données.
Le point d’accès qui nous intéresse ici, intitulé restSearch, permet d’exporter des collections de données partagées sur la plateforme tout en sélectionnant ou filtrant les échantillons à exporter. Via celui-ci, il est possible d’exporter des données depuis MISP, en une multitude de formats, notamment CSV, STIX, Yara et d’autres.
L’accès au client REST via son API est par ailleurs facilité pour les adeptes des scripts d’automatisation en Python grâce à la librairie PyMISP, qui assure une équivalence à toutes les fonctionnalités disponibles de l’API REST de MISP en n’écrivant que quelques lignes de code Python.
Il est ainsi facilement possible d’importer et d’exporter des données dans une instance MISP de façon programmatique.
Il est à noter que la synchronisation entre plusieurs instances MISP utilise le format MISP Standard [MISP STANDARD], également disponible via le point d’accès restSearch, plutôt que des formats CSV ou STIX, afin de garantir un transfert sans perte de précision.
Le format CSV offre moins de possibilités que le format JSON de par sa nature. Le format STIX se retrouve limité à supporter uniquement des données étiquetées ‘Threat Intelligence’, dans un format souvent plus compliqué à analyser, là où MISP supporte des utilisations plus variées (Threat Intelligence, mais aussi renseignements, indicateurs financiers, etc.).
Plus qu’une simple plateforme, MISP se place d’ailleurs aujourd’hui comme un véritable format standard dans le partage d’informations, il n’est pas rare que certaines organisations, utilisatrices de la plateforme, aient leurs propres intégrations en interne, ingérant directement du format MISP, et alimentant leur écosystème d’outils directement.
L’efficacité du standard, couplée à une facilité d’intégration avec d’autres formats, assure l’interopérabilité de MISP.
2.6 Dissémination
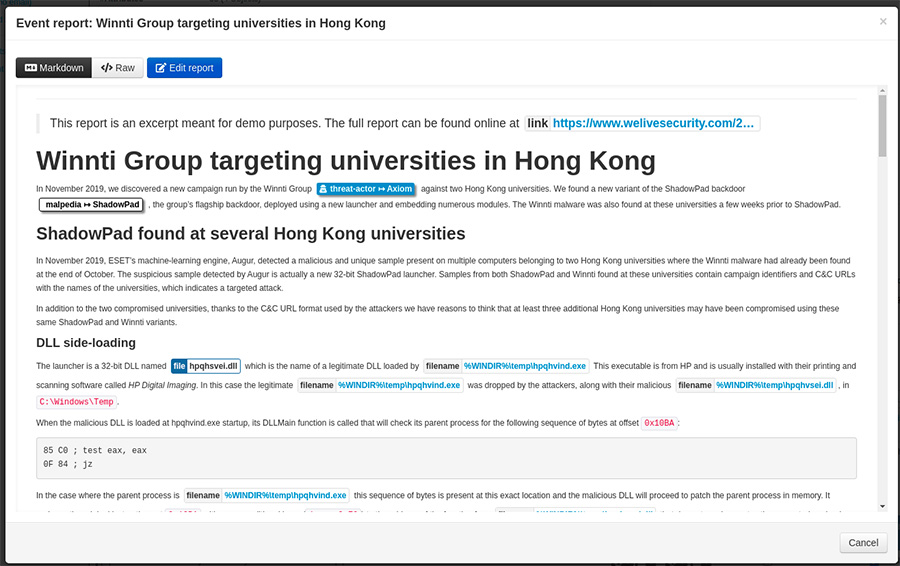
Et plus de partager de l’information structurée compréhensible par des machines, MISP propose un outil de rédaction de rapport utilisant les données d’un event. Cette fonctionnalité a vu le jour pour éviter que les utilisateurs ne publient les rapports sous forme de texte pur, de PDF, ou d'autres formats difficilement exploitables.
L’event report utilise la syntaxe markdown pour éditer le texte du rapport et ajoute des directives propres à MISP au langage de base. On peut ajouter un élément contenu dans l’event sous forme textuelle dans le rapport en utilisant :
Cette syntaxe supporte les attributes, les objects, les tags, les galaxy clusters, et enfin les galaxy matrices.
Le rapport ainsi construit est lié à l’event et sera synchronisé sur les autres instances MISP selon les règles standards de synchronisation.
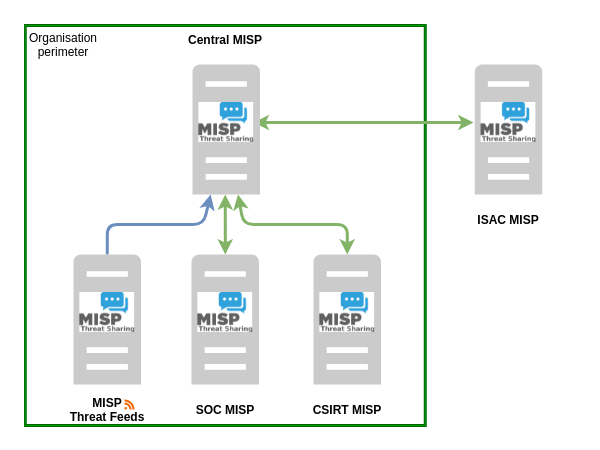
2.7 Déployer des instances MISP
Comme nous l’avons vu dans le premier article, plusieurs équipes peuvent prendre part au pipeline CTI et donc posséder une instance MISP. La figure ci-après représente un exemple d’un tel déploiement avec :
- Une instance responsable de recevoir les flux extérieurs qui pousse certains events dans une instance centrale sous certaines conditions.
- Des instances dédiées au SOC et au CSIRT qui reçoivent et envoient des events à l’instance centrale.
- Une instance centrale responsable de centraliser les renseignements internes, et synchroniser les events pertinents avec une instance extérieure d’une ISAC.
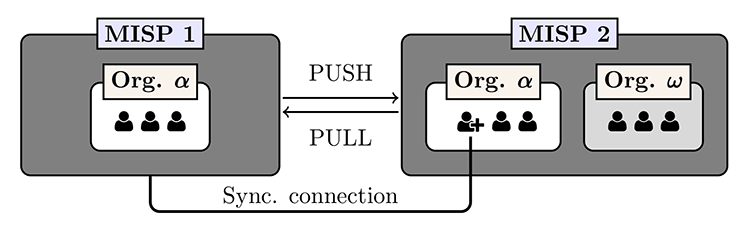
Comme déjà évoqué à plusieurs reprises, le partage de données dans MISP s’effectue par un processus appelé synchronisation. Lors d’une synchronisation, une instance MISP peut être à la fois le fournisseur ou le consommateur de données. Si l’instance envoie des données, le mécanisme de synchronisation est appelé PUSH. Si l’instance télécharge les données depuis une autre, on appelle cela PULL.
La distribution est le terme utilisé dans MISP pour déterminer qui peut consulter les données partagées et comment elles doivent être synchronisées.
Ce paramètre possède plusieurs niveaux et peut être appliqué sur tous les blocs d’information comme les events ou attributes. Les niveaux vont du plus restrictif Your Organisation Only (seulement le créateur peut consulter les données) au plus libre All Communities (l’information peut se propager librement dans un réseau d’instances connectées et est visible par tous). Deux niveaux intermédiaires sont aussi disponibles ainsi que la possibilité de lister exactement quelles organisations peuvent consulter les données. Ce dernier niveau porte le nom de sharing group.
2.8 Cerebrate ou l’orchestration de votre cyber toolbox
Cerebrate est un nouvel outil résultant des diverses questions qu’on est amené à se poser quand on crée un pipeline de CTI, par exemple :
- Comment trouver des communautés relatives à mon secteur d’activité ?
- Comment s’interfacer avec ces communautés ?
- Comment trouver un contact dans telle organisation ? Quelle est sa clé PGP ?
- Comment créer des liens de synchronisation entre plusieurs MISP ? Ou d’autres outils ?
- Comment gérer mes outils de manière centralisée ?
Cerebrate répond à ces besoins selon deux axes. Tout d’abord, pour la gestion de communauté, Cerebrate propose un répertoire d’individus et d’organisations ainsi qu’un répertoire de liste de distributions appelé sharing groups. Gérer des organisations, leurs individus, les sharing groups et tout autres types d’informations de ce genre est commode et le tout peut être synchronisé par un système de synchronisation similaire à celui de MISP avec d’autres instances Cerebrate.
Ces répertoires sont d’une grande valeur, car ils peuvent être utilisés comme source garantissant l’authenticité des informations. Si l’on combine ces répertoires avec des clés de chiffrement telles que PGP, on obtient dès lors un mécanisme pouvant garantir l’authenticité et la non-falsification de l’information reçue par des tiers. Cette méthode de vérification cryptographique est actuellement en développement et fera partie intégrante de MISP pour toutes instances liées à Cerebrate.
Ensuite, pour la gestion d’outils, Cerebrate permet d’interconnecter des instances MISP ou d’autres outils utiles à la collaboration d’équipes de sécurité. Grâce à son mécanisme d’interconnexion en trois phases, deux équipes ayant leur Cerebrate connecté peuvent aussi établir un lien de synchronisation entre leurs instances MISP et prochainement leurs applications AIL-Framework ainsi que tout autre outil proposant des modules d’interconnexion via Cerebrate.
Conclusion
La conception de MISP a été réalisée par des analystes afin de les soutenir dans leurs tâches quotidiennes de recueil, d’analyse et de partage d’informations. Son modèle de représentation des données et ses éléments de contextualisation ont été pensés de manière à ce qu’ils puissent évoluer pour toujours mieux décrire les données, acteurs et menaces auxquels nous faisons face au jour le jour.
L'impartialité de la plateforme et ses multitudes possibilités d'intégrations font d'elle une pierre angulaire dans tout pipeline CTI sérieux. Les données peuvent être structurées de manière efficace, enrichies, analysées et finalement filtrées avant d’être utilisées par les outils de protections.
MISP n'est pas seulement un outil libre, mais tout un projet conçu pour promouvoir, améliorer et faciliter le partage d'informations à grande échelle.
Références
[CEREBRATE] Annuaire de confiance et interconnecteur d’outils de sécurité :
https://github.com/cerebrate-project/cerebrate
[MISP-MALTEGO] Collection de transformations Maltego pour MISP : https://github.com/MISP/MISP-maltego
[MISP-MODULE] Modules pour l’enrichissement et l’import/export de données : https://github.com/MISP/misp-modules
[MISP STANDARD] Standard de modélisation pour le partage de données : https://www.misp-standard.org/
[1] https://www.misp-project.org/license/
[2] https://www.misp-project.org/governance/


