

Depuis une dizaine d’années, le mouvement NoSQL s’est largement répandu et de nouveaux types de bases de données sont apparus. Parmi celles-ci, les bases de données dites « orientées-séries-chronologiques » (TSDB pour Time Series Database) ont montré leur intérêt pour stocker et analyser des données horodatées. On les retrouve dans différents domaines : de l’Internet des objets (IoT) à la collecte de métriques serveurs et réseau, en passant par la surveillance d’applications, la mesure de performances… Dans ce marché de niche, InfluxDB apparaît comme une solution leader [1].
InfluxDB a été développé depuis octobre 2013 en langage Go par la société InfluxData [2]. Tout d'abord basé sur le SGBD « clé-valeur » LevelDB de Google, il utilise dorénavant le moteur BoltDB, écrit lui aussi en Go. InfluxDB existe en 2 versions : la v1 et la v2. La roadmap indiquant que la v1 ne serait plus maintenue, dans sa version open source, à partir de 2022, cet article portera sur la jeune version 2 (2.0.9 pour être précis), disponible depuis novembre 2020.
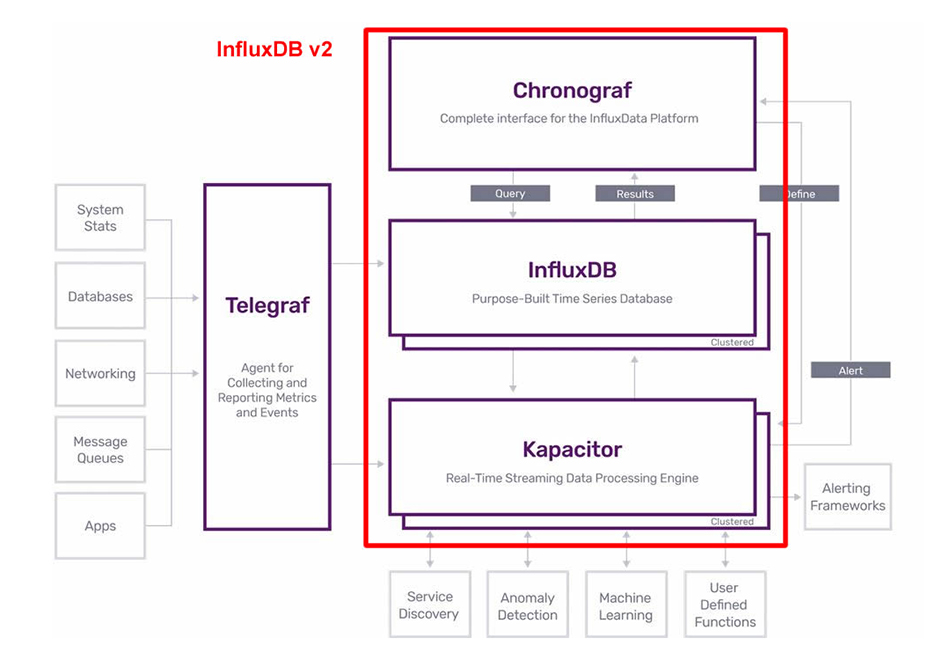
Pour ceux qui connaîtraient déjà la version 1 de InfluxDB, ils doivent savoir que deux modifications importantes ont été apportées à la v2 : le langage InfluxQL a été remplacé par Flux et les anciens produits Chronograf (pour la visualisation) et Kapacitor (pour la gestion des alertes) sont dorénavant intégrés à InfluxDB. Seul Telegraf reste un produit indépendant.
L’architecture de l’ancienne pile dite « TICK » devient donc celle de la figure 1.
1. Installation et configuration de base
Les méthodes d’installation sont diverses : du téléchargement d’un fichier au format tar.gz, à l’installation d’un package (rpm ou deb), en passant par une image docker ou un fichier manifeste au format YAML pour Kubernetes !
Dans tous les cas, il faudra :
- démarrer le serveur influxd en lui communiquant sa configuration (qui indiquera au minimum l’emplacement prévu pour stocker ses bases) ;
- disposer du client influx pour gérer le serveur, sachant qu’une majorité des opérations peut être réalisée à travers l’interface web standard du serveur !
Comme exemple, nous allons utiliser docker et lancer le serveur influxd dans un conteneur : tout d’abord, nous créons un répertoire pour stocker le fichier de configuration et un répertoire pour stocker les données :
puis, nous créons un fichier de configuration par défaut, au format YAML (les formats TOML et JSON sont aussi supportés) :
Nous pouvons maintenant créer le conteneur définitif :
L’option --reporting-disabled supprime l’envoi de données statistiques sur l’usage de InfluxDB à la société InfluxData.
Vous pouvez vérifier avec docker ps et docker logs influxd que influxdb ait bien démarré.
Mais pour se connecter au serveur, il faudra disposer du client influx. Rien de plus simple : il fait partie de l’image utilisée pour lancer le conteneur. On peut accéder au client ainsi :
À partir de maintenant, nous considérerons que nous pouvons utiliser le client influx à partir de notre compte, que nous soyons dans un conteneur ou non. Ainsi, le prompt sera uniquement symbolisé par un $.
Pour que notre serveur soit réellement opérationnel, il y a une configuration de base à compléter. Cette configuration doit indiquer :
- le nom d’un utilisateur initial, qui sera l’administrateur ;
- son mot de passe initial ;
- le nom de votre « Organization » ;
- le nom du « Bucket » initial (assimilable à votre base de données initiale) (voir §2) et sa période de rétention (oui, comme nous le verrons, InfluxDB supprime automatiquement les données considérées comme périmées).
Cette configuration peut être réalisée en mode CLI avec le client influx ou bien en mode web, en naviguant sur le port 8086 du serveur. Le mode CLI s’utilise ainsi :
Vérifions que nous pouvons dialoguer avec le serveur :
ou plus simplement :
En effet, vous pouvez définir plusieurs configurations et choisir celle qui deviendra votre configuration par défaut.
Avec une installation standard (et non pas en utilisant la commande influx du conteneur), vous pouvez activer la complétion du shell bash (ou zsh) en ajoutant la commande suivante à votre fichier .bashrc (ou .zshrc) :
Le serveur influxdb propose aussi une interface web, à l’écoute du port 8086 par défaut. Pour s’y connecter, utilisez le nom d’utilisateur et le mot de passe que vous avez renseigné lors de la création de la configuration (figure 2).

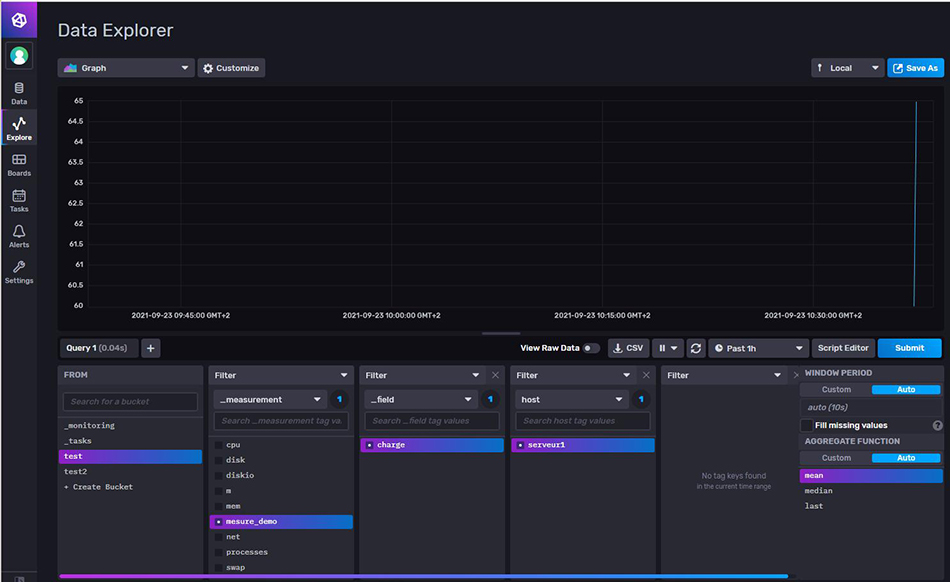
Cette interface web permet de gérer les utilisateurs, les Buckets, les alertes, les tâches... Elle permet d’explorer les données en vous guidant dans l’utilisation du langage de requêtage, nommé Flux. Elle vous permet aussi de visualiser les données via des graphes, des jauges, des histogrammes, des heatmaps, etc.(voir figure 3).
2. Représentation des données
Lors de l’installation, nous avons précisé un nom de Bucket et un nom d’organisation : à quoi servent ces informations ? Comment sont structurées les données stockées dans InfluxDB ? InfluxDB définit un certain nombre d’éléments reliés entre eux selon la figure 4.
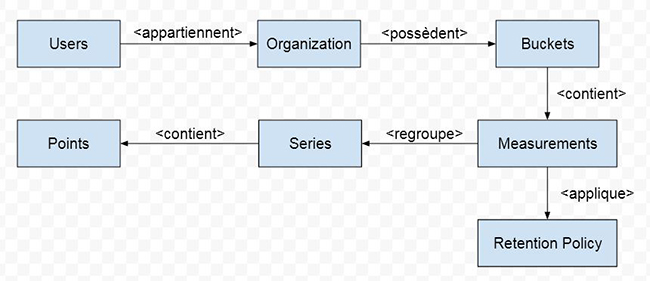
Nous déduisons de cette figure que :
- les utilisateurs appartiennent à des organisations qui sont donc les entités de plus haut niveau ;
- les Buckets appartiennent à des organisations, ainsi les utilisateurs ne peuvent accéder qu’aux Buckets de leur organisation. Les Buckets peuvent être assimilés aux « bases » des SGBDR ;
- les Buckets contiennent des mesures (measurement) qui peuvent être vues comme des tables (au sens SGBDR). Les mesures contiennent des points. La syntaxe formelle de définition d’un point est :
(il y a un espace entre la liste des tags et la liste des fields) ;
- un point est donc constitué d’un ensemble estampillé de tags optionnels et de champs valués (au moins un champ est requis). Si l’estampille est manquante lors de l’insertion du point, la date courante du serveur est utilisée ;
- pour une mesure donnée, les points qui partagent les mêmes valeurs de tags constituent une série ;
- les Buckets sont associés à une politique de rétention des données, ce qui permet de supprimer automatiquement les données obsolètes.
Exemple : nous imitons des données météorologiques qui seraient fournies par des capteurs géographiquement répartis sur le territoire français. Nous pouvons créer des points de mesure ainsi :
La mesure se nomme ici meteo. Il y a 2 séries, car le tag station a 2 valeurs différentes : Toulouse et Lyon. Chaque point contient 2 champs : la température t et pression au niveau de la mer pmer. Les points sont estampillés (au format Unix timestamp et exprimés en nanosecondes par défaut).
Un lecteur attentif aura remarqué la présence de la lettre i après la valeur de la pression atmosphérique (champ pmer). En effet, les données sont typées et le type est déterminé automatiquement par InfluxDB et ici nous voulons imposer le type « entier ».
Quelle est la différence fondamentale entre tags et fields (champs) ?
Pour le dire simplement : les valeurs des tags sont indexées, les valeurs des fields ne le sont pas. Donc les requêtes sur les valeurs de tags seront efficaces, les autres non !
On pourrait alors naïvement décider de « tagger » à outrance ? Seulement, imaginez que la température et la pression atmosphérique deviennent des tags : leurs valeurs ayant une très forte cardinalité, le nombre de séries va littéralement exploser. La gestion des index va consommer de plus en plus de mémoire, les performances peuvent alors se dégrader. La documentation officielle [4] donne des conseils pour éviter et corriger ce problème.
3. Insertion de données
Il est temps maintenant d’insérer nos premières données dans InfluxDB et ce ne sont pas les solutions qui manquent ! Nous pouvons utiliser la commande influx, l’interface web du serveur influxd, l’outil de collecte Telegraf, des Scrapers et finalement nos propres programmes, car bien sûr il existe une librairie cliente pour votre langage préféré.
Pour invoquer l’API de InfluxDB vous devez présenter le nom de votre organisation ainsi qu’un Token valide. On peut pour cela ajouter les options --org et --token à la ligne de commandes ou bien nous pouvons définir une fois pour toutes les variables d’environnement INFLUX_ORG et INFLUX_TOKEN. C’est la solution que nous allons utiliser systématiquement dans la suite de cet article :
Oui, mais quelle est la valeur de mon Token ? À partir de l’interface web, il suffit de cliquer sur le bouton Data du menu vertical à gauche, puis il faut choisir l’onglet Tokens. Le nom de mon Token apparaît et j’obtiens sa valeur en cliquant dessus ! On pourrait aussi créer de nouveaux Tokens avec des privilèges sur des Buckets précis.
La commande influx write permet d’ajouter des points dans InfluxDB. Les points sont décrits sous forme de lignes séparées par des \n. Il est possible de spécifier un fichier en entrée, ce fichier peut être au format CSV et enfin, il est possible de préciser l’unité de l’estampille, ce sera la seconde dans notre cas.
Ajoutons maintenant deux points de la même série dans le Bucket test :
Les nouveaux points peuvent être visualisés dans l’interface web (figure 5).
4. Interrogation des données : introduction au langage Flux
À partir de la version 2 de InfluxDB, vous n’avez guère le choix, vous devez utiliser le langage Flux, même si le support de l’ancien langage InfluxQL est proposé avec quelques restrictions.
Il existe 4 méthodes pour effectuer les requêtes via Flux :
- à partir de l’interface web (en sélectionnant l’icône Explore du menu vertical à gauche) ;
- à l’aide de l’API de InfluxDB ;
- en mode ligne de commandes grâce à la commande flux, mais qu’il faut compiler à partir des sources [5] ;
- en passant le script Flux à la commande influx query.
Avant d’explorer les fonctionnalités du langage Flux, nous avons besoin d’un peu plus de données. Nous utiliserons les données météorologiques « SYNOP » disponibles sur le site https://public.opendatasoft.com. Nous avons téléchargé les observations effectuées entre le 1er janvier 2019 et la date du jour, ce qui représente 472434 enregistrements au 22 septembre 2021. Le fichier est au format CSV.
La 1ère ligne du fichier CSV donne le nom des colonnes, les autres lignes sont des mesures ressemblant à ceci :
Les colonnes que nous allons indexer sont :
- la date qui contient la date et l’heure de la mesure ;
- la pression au niveau de la mer ;
- la température relevée, la température minimale sur 24h et la température maximale sur 24h ;
- les précipitations sur 24h ;
- le nom de la commune et le numéro du département.
Les données seront ajoutées dans un nouveau Bucket nommé « meteo » que vous pouvez créer à partir de l’interface web. La politique de rétention sera « infinite ».
Chaque type de données (pression, température et précipitations) sera stocké dans une mesure spécifique. Les tags seront associés aux noms des communes. Voici un exemple de point pour chaque mesure :
4.1 Injection des données via Python
Notre programme d’injection sera écrit en Python. Il aura les exigences d’optimisation décrites dans la documentation [6] :
- il utilisera le « Bulk mode », la taille de bloc recommandée est de 5000 points ;
- les Tags seront listés par ordre alphabétique.
Le client Python est documenté sur GitHub [7]. Nous l’installons rapidement (il nécessite une version 3.6 de Python au minimum) :
Notre script d’insertion se nomme insert_synop.py, il fait environ 60 lignes !
Après importation de quelques librairies, dont le client InfluxDB, nous définissons des variables globales en particulier le Bucket destinataire :
Nous créons un client InfluxDB en indiquant les paramètres de connexion. Ces paramètres pourraient provenir d’un fichier INI ou bien de variables d’environnement. Pour des raisons de performances, nous prévoyons donc d’écrire par paquets de 5000 points. Le mode « debug » permet de tracer les échanges avec le serveur InfluxDB.
Comme souvent, les données fournies contiennent des valeurs manquantes ou mal formées. Nous devons nous prémunir ici contre les erreurs de conversion, car beaucoup de chaînes que nous considérons comme des nombres réels sont en fait vides... Pour éviter cela, nous écrivons une fonction de conversion :
Pour des raisons d’efficacité, chaque ligne du fichier CSV va être analysée et produire un point pour chaque mesure (pression, température et précipitation). La création d’un point suit la syntaxe abstraite suivante :
Après conversion de la date trouvée dans le fichier CSV, on n’oubliera pas de préciser que l’unité temporelle est la seconde (WritePrecision.S). L’analyse d’une ligne et la création des points est implémentée par la fonction suivante :
Il ne reste plus qu’à lancer la lecture du fichier CSV puis effectuer les requêtes d’écriture dans InfluxDB :
Au bout de quelques dizaines de secondes, les données sont insérées dans InfluxDB. Vérifions qu’elles sont disponibles dans l’interface web… et là, il y a un piège : les données datent pour partie de 2019 et 2020, il faut donc définir un intervalle de temps personnalisé (Custom Time Range).
Dans l’outil d’exploration, cliquez sur le bouton Script Editor et copiez cette requête :
Un joli graphe inexploitable est affiché, mais au moins nous avons nos données (voir figure 6) !
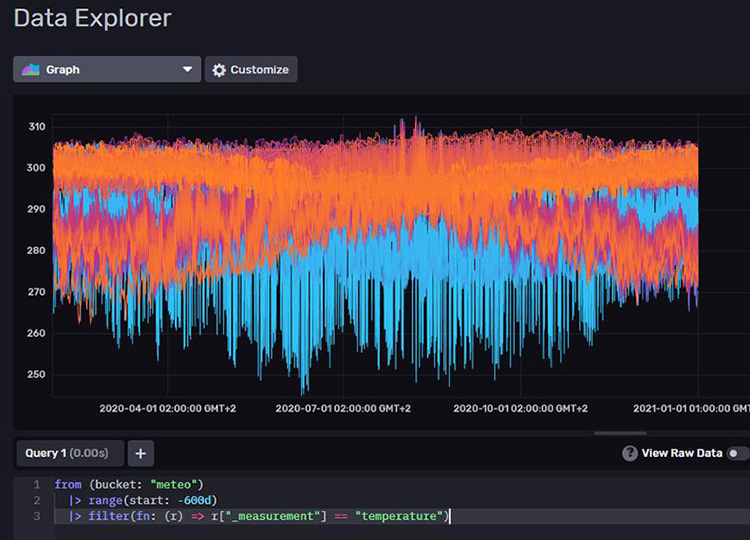
4.2 Extraction et analyse des données
Commençons par obtenir quelques dénombrements.
Pour obtenir la liste des communes, nous allons utiliser les clauses group() pour dégrouper les données (c’est l’effet de cette fonction si on l’invoque sans paramètre) puis unique() qui permet d’agréger les lignes pour obtenir les valeurs identiques d’une colonne. La requête est alors :
Si nous ne voulons que la colonne "commune", il faut utiliser la fonction keep(). Les clauses ORDER BY et LIMIT de SQL sont supportées par les fonctions sort() et limit(). Par exemple, si nous ne voulons que les 3 dernières communes, nous écrirons :
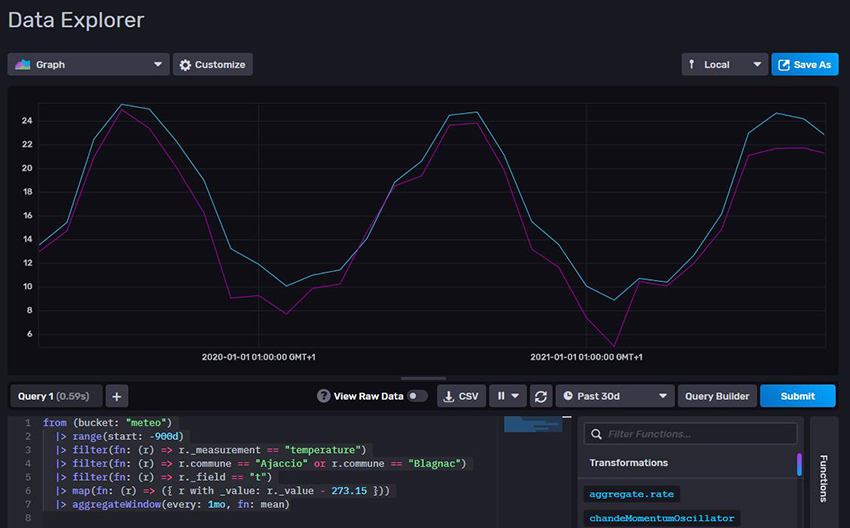
Essayons d’obtenir la moyenne des températures par mois pour les communes de Blagnac et Ajaccio. Nous avons certes besoin de la fonction mean(), mais aussi de aggregateWindow() pour effectuer un regroupement des données par mois. Notons aussi que la température est exprimée en Kelvin. Pour obtenir sa valeur en degrés Celsius, nous allons utiliser la fonction map() pour changer la valeur du champ _value :
Et nous obtenons le graphe présenté en figure 7.
Les fonctions que nous avons invoquées jusqu’à présent étaient des builtins. Mais il est possible de charger des packages supplémentaires pour accéder à de nouvelles fonctions. Par exemple, le package strings permet d’invoquer des fonctions de traitement de chaînes.
5. Pour aller plus loin
5.1 Sauvegarde et restauration
Comme tout SGBD qui se respecte, InfluxDB propose des commandes de sauvegarde et restauration.
La sauvegarde invoque la commande backup et doit être effectuée en utilisant le Token qui a été créé lors de la phase de setup. Ici, c’est le Token dont nous avons donné la valeur à la variable d’environnement INFLUX_TOKEN. Pour sauvegarder l’ensemble des bases dans le répertoire /backup, la commande est :
L’option -b permet de sauvegarder un Bucket particulier.
La restauration utilise la commande restore. Cette commande possède quelques subtilités... En particulier, elle refusera de restaurer des Buckets si ceux-ci existent déjà :
Il faut préalablement supprimer les Buckets. Si on souhaite restaurer un seul Bucket et que celui-ci existe, il est possible de restaurer les données dans un nouveau Bucket en utilisant l’option --new-bucket. Notez aussi que la restauration ne restaure que les données des Buckets. Si vous souhaitez restaurer aussi les Tokens, les comptes utilisateurs, les Dashboards, etc., il faudra ajouter l’option --full à la commande de restauration.
5.2 Traitement en continu avec les tâches
La version 1 de InfluxDB proposait un mécanisme de requêtage « en continu » dont le principe consistait à déclencher automatiquement et périodiquement une requête d’agrégation sur les données d’une base pour insérer les résultats dans une autre base.
La version 2 supporte aussi cette fonctionnalité sous le nom de tâches (tasks). Les tâches ne sont ni plus ni moins que des requêtes Flux qui sont exécutées périodiquement par InfluxDB. Ces tâches peuvent être définies et gérées en mode CLI, avec la commande influx, ou bien via l’interface web.
5.3 Monitoring et alertes
Comme nous l’avons indiqué en introduction, la version 2 de InfluxDB inclut l’outil Kapacitor qui est en charge d’analyser les données en continu, apportant ainsi à l’outil une fonctionnalité d’alertes. Pour configurer une alerte, il faut créer un check puis définir des notification rules qui signaleront l’alerte à des notification endpoints. Toutes les définitions de ces objets peuvent être réalisées à partir de l’interface web.
Conclusion
Nous avons présenté succinctement la version 2 de InfluxDB qui marque une coupure nette avec la version précédente. Le langage d’interrogation a été repensé pour devenir Flux ; les anciens produits Chronograf et Kapacitor ont été intégrés au serveur influxd. De la pile « TICK », il ne reste donc plus que le « T » (Telegraf) et le « I » (InfluxDB).
C’est un point positif pour l’installation du produit ! Ajoutons aussi que Telegraf s’intègre très aisément pour permettre la collecte de métriques d’origines diverses. La prise en main du produit est rapide avec toutefois une régression induite par l’usage de Flux. En effet InfluxQL, l’ancien langage de requêtage, qui imitait le « bon vieux » SQL simplifiait encore l’utilisation du produit (mon avis est totalement subjectif !).
Si InfluxDB est le leader des bases de données de type « Time-Series », il est en sérieuse concurrence avec le couple Prometheus-Grafana sur les plateformes de conteneurisation. Depuis quelques années, il est aussi en concurrence avec ElasticSearch qui cherche à élargir ses parts de marché en intégrant aussi une possibilité de stockage de données horodatées.
Mais peut-être l’inconvénient majeur de InfluxDB concerne-t-il l’absence du support de la réplication et de la clusterisation dans sa version gratuite ? Si vous avez besoin d’un serveur hautement disponible et capable de supporter des dizaines de milliers d’insertions par seconde, vous devrez alors vous tourner vers la version « Enterprise ».
Références
[1] Classement des SGBD : https://db-engines.com/en/ranking
[2] Site de la société InfluxData : https://www.influxdata.com/
[3] Installation : https://docs.influxdata.com/influxdb/v2.0/install/
[4 ] Problème des cardinalités élevées : https://docs.influxdata.com/influxdb/v2.0/write-data/best-practices/resolve-high-cardinality/
[5] Sources de la commande flux : https://github.com/influxdata/flux
[6] Optimisation des écritures : https://docs.influxdata.com/influxdb/v2.0/write-data/best-practices/optimize-writes/
[7] Obtenir le client pour Python : https://github.com/influxdata/influxdb-client-python