

Dans le hors-série 24 de MISC [0], nous avions montré que les outils et techniques de la compilation sont aujourd'hui des éléments incontournables dans le domaine de la sécurité des applications, que ce soit pour les protéger, les obfusquer, et même de manière plus surprenante les reverser.Nous plongeons ici plus en détail dans les entrailles d'un compilateur, Clang/LLVM [LLVM] : ses différentes étapes, son architecture, sa représentation interne, ses optimisations. Nous illustrerons les transformations les plus communes par un exemple concret, et nous verrons que si certaines structures de code observées dans les binaires sont facilement reconnaissables, d'autres peuvent surprendre...
1. La compilation : un processus par étapes
Dans cette section, nous allons nous intéresser au processus de compilation dans son ensemble, et faire quelques rappels basiques.
Tout d'abord, comment définir un compilateur ? On peut dire que c'est un programme qui prend en entrée un code source et le transforme en une représentation d'un niveau d'abstraction généralement inférieur (ou égal). Il y a bien évidemment des multitudes de compilateurs différents, mais pour notre exemple, nous allons nous intéresser à un type bien particulier de compilateur, qui transforme un fichier texte écrit en langage C en un programme en langage assembleur pour une architecture cible particulière.
Pour ce type de compilateurs, le processus de compilation peut généralement être découpé en trois étapes principales : la traduction du code source dans une représentation intermédiaire (RI), l'application d'un ensemble d'optimisations sur cette RI, et une étape finale d'émission du code machine spécifique à la cible.
Néanmoins, ce processus ne permet pas — seul — de générer un programme exécutable, et un certain nombre d'étapes supplémentaires sont nécessaires. Le processus de compilation complet est transparent pour l'utilisateur du compilateur : la commande appelée pour la compilation (par exemple, en lançant clang fichier.c) est en fait un appel au driver qui va contrôler la compilation en lançant les différentes étapes les unes après les autres, jusqu'à obtenir le fichier approprié en sortie.
Pour illustrer ces différentes étapes, le code ci-dessous va nous servir d'exemple tout au long de l'article. Il comporte une fonction intToString qui transforme un entier en chaîne de caractères, étant donnée une base de numération.
La première étape du processus est du ressort du préprocesseur : son but est de résoudre les différents fichiers inclus, d'étendre les macros, et de supprimer les commentaires, afin d'obtenir en sortie un fichier C autonome. Ce fichier n'est jamais présenté tel quel à l'utilisateur, mais il est tout à fait possible d'indiquer au compilateur de n'effectuer que cette étape : pour Clang et GCC, cela se fait en passant l'option -E, pour MSVC en passant l'option /P.
Notre exemple ne contient aucune inclusion, le préprocesseur émet donc un code très proche de l'original, où seule la macro BASE est étendue, ce qui donne ce corps de boucle :
Vient ensuite l'étape de compilation à proprement parler, où le fichier préprocessé est analysé, optimisé, et finalement traduit dans un langage assembleur. Là encore, la sortie obtenue n'est généralement pas présentée à l'utilisateur, mais il est possible d'indiquer au compilateur que l'on souhaite s'arrêter à cette étape. Pour Clang et GCC, cela se fait en passant l'option -S, pour MSVC en passant l'option /FA.
L'étape suivante est l'assemblage : l'assembleur est traduit en langage machine, et l'on obtient en sortie un fichier objet. Pour Clang et GCC, cela se fait en passant l'option -c, pour MSVC en passant l'option /c.
Pour ces trois étapes, si plusieurs fichiers sont fournis en entrée sur la ligne de commande, ils sont traités indépendamment et un fichier de sortie est créé pour chacun d'eux.
La dernière étape est l'édition de liens, et vise à combiner un certain nombre de fichiers objets et de bibliothèques externes en un fichier exécutable. Lors de cette étape, les symboles utilisés dans le code (fonctions ou variables globales) sont résolus : chacun d'eux doit exister de manière unique (dans le fichier objet fourni, dans une bibliothèque statique ou partagée fournie).
Pour chacune de ces étapes, un compilateur peut utiliser une ou plusieurs représentations intermédiaires afin de faciliter son travail. Ceci est complètement dépendant de l'implémentation et pour rentrer dans les détails, nous avons choisi comme cas d'étude l'infrastructure de compilation LLVM, et son compilateur pour le langage C/C++, Clang.
2. L'infrastructure de compilation Clang/LLVM
L'infrastructure de compilation LLVM est bien plus qu'un simple compilateur : en pratique, c'est un ensemble d'outils autour du processus de compilation, dont la majorité a pour point commun la représentation intermédiaire LLVM (voir figure 1).
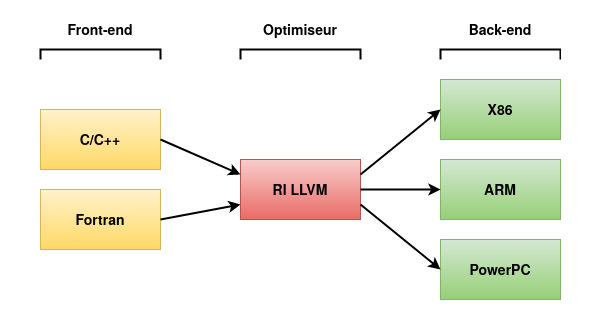
Elle dispose d'un certain nombre de front-ends qui traduisent un code source en RI LLVM, comme Clang pour C/C++/ObjectiveC, Flang pour Fortran, ou encore Rust.
Viennent ensuite un certain nombre d'outils autour du middle-end et qui eux agissent directement sur la RI ; on peut notamment citer opt, qui permet d'appliquer des passes de transformations arbitraires.
De nombreux back-ends viennent s'ajouter à cela, et permettent de cibler les principales architectures utilisées : X86, ARM, PowerPC, et bien d'autres...
Finalement, cet ensemble est complété par différents utilitaires : un éditeur de lien lld, un débogueur lldb, et d'autres outils « standard » comme llvm-objdump, llvm-nm, etc.
Dans les sections suivantes, nous détaillerons sur notre exemple comment chaque partie joue un rôle bien spécifique dans les optimisations appliquées sur le code fourni en entrée.
2.1 L'optimiseur et la représentation intermédiaire
L'optimiseur est responsable de la transformation du code issu du front-end, c'est à dire le code écrit par l'utilisateur converti en RI, en un code équivalent, mais s'exécutant plus rapidement, ou ayant une empreinte mémoire plus faible. Dans le cas de LLVM, cette RI est appelée LLVM-IR. On peut récupérer la LLVM-IR pour un fichier source après optimisation en le compilant avec la ligne suivante :
Pour chaque fichier C, la RI générée par le front-end contient la liste des variables globales et des fonctions disponibles dans le code source. Mais aussi, des métadonnées et des informations liées à l'architecture cible, nécessaires pour que certaines optimisations puissent décider si une transformation va être efficace.
En compilant notre code C avec -O3, des optimisations relatives à la vitesse d’exécution sont effectuées sur le code issu du front-end, et on obtient l'extrait de code suivant :
Dans la RI, chaque fonction est composée d'un ou plusieurs basic blocks (ici, seuls les deux premiers sont affichés), et chaque basic block est lui-même composé d'une séquence d'instructions qui sont exécutées les unes après les autres. Les branchements ne peuvent se faire que depuis la dernière instruction d’un bloc (appelée terminator) vers la première instruction du bloc visé.
Les instructions ressemblent à celles des langages assembleur classiques : instructions arithmétiques et logiques, add, or, xor, and, icmp, fadd, fmul, fcmp… ; appels de fonction call, invoke… ; sauts, br, switch, ret… ; et des instructions phi (on reviendra sur celles-ci plus tard).
Mais au contraire des instructions assembleur, celles de la LLVM-IR sont typées, et les types sont explicites : i32 (entier 32 bits), i1 (entier 1 bit), i32* (pointeur vers un entier 32 bits), etc.
Ceci a l'avantage de permettre de conserver une information précise tout en limitant la taille du jeu d'instructions de la RI, dont le but est de proposer un bon compromis entre l'abstraction de l'architecture cible, du langage d'entrée, et la facilité de développement des transformations et des analyses.
L'identifiant à gauche d'une instruction, %7 par exemple, est un registre virtuel dans lequel un résultat d’opération sera sauvegardé, ici le retour de l'appel à atoi. À la différence des CPU physiques, il n'y a pas de limite au nombre de registres virtuels.
2.2 Notre première optimisation
Dans notre exemple, nous retrouvons bien la division par 10 stockée dans le registre %18, mais — surprise ! — dans la fonction main au lieu de la fonction intToString : l'optimiseur a remplacé l'appel à intToString par son code. Cette transformation s'appelle l'inlining et présente un double intérêt : d'une part, éviter le coût d'un appel de fonction, et d'autre part permettre d'optimiser le code inliné pour les valeurs des paramètres du site d'appel. La contrepartie est une plus grosse taille de code lorsqu'une même fonction est inlinée plusieurs fois.
2.3 L'assignation unique
Les registres virtuels de la RI de LLVM ont une particularité : on ne peut leur affecter une valeur qu'une seule fois dans le programme. Plusieurs RI (mais pas toutes) respectent cette propriété, connue sous le nom de Static Single Assignment (SSA), car elle permet de retrouver très facilement la provenance d'un opérande d'une instruction. De ce fait, elle décrit les contraintes minimales sur l'ordre dans lequel les instructions doivent effectivement être exécutées, contraintes que doivent évidemment garantir les optimisations éventuelles.
Dans la fonction intToString, la variable n prend en premier la valeur du résultat de l'appel à atoi, puis se voit affecter d’autres valeurs lors de l'exécution de la boucle. Comment cela se traduit-il dans la RI ? Reprenons cette partie spécifique de notre exemple :
Pour retrouver cette variable dans la RI optimisée, on peut suivre les instructions qui opèrent sur le résultat du atoi, stocké dans le registre %7. Nous retrouvons une comparaison avec 0 dont le résultat est sauvegardé dans le registre %8, et une instruction phi sauvegardée dans le registre %12.
L'instruction phi est une instruction spéciale, n'ayant pas d'équivalent dans les CPU réels. Elle est caractéristique des RI basées sur le SSA, et permet de résoudre le problème des affectations multiples. Le phi prend différentes valeurs selon le chemin pris pendant l'exécution : dans notre code, %12 prend la valeur de %7 si le chemin d'exécution vient du bloc 2, sinon il prend %18 si le chemin vient du bloc 11.
2.4 Où est passée ma boucle ?
Un autre point d'intérêt est de suivre les sauts entre les basic blocks de la fonction. Nous trouvons deux branchements, le premier dans le bloc 11, qui saute conditionnellement dans lui-même en fonction de la valeur du registre %12 (correspondant à la variable n). On reconnaît là une boucle ; peu importe si à l'origine il s'agissait d'une boucle while ou for. Quant au branchement dans le bloc 2, il saute dans la boucle si n n'est pas 0. Réécrit en C, cela donne quelque chose comme :
Ceci est le résultat d'une transformation connue sous le nom de loop-rotate. Petit à petit, au fil des transformations, il est de plus en plus difficile de retrouver le code d'origine dans la RI, ce qui rend le débogage (ou le reverse...) du code optimisé plus compliqué.
2.5 Les différents niveaux d'optimisation
Dans un compilateur, les transformations, comme l'inlining ou le loop-rotate, sont implémentées sous forme de passes indépendantes, appliquées les unes après les autres par l'optimiseur. Ce découpage permet de garder le code de l'optimiseur maintenable, tout en facilitant la configuration de la chaîne de passes selon différents objectifs comme la vitesse d'exécution, la taille du code généré, voire le temps d'exécution de l'optimiseur (critère important dans la compilation à la volée).
Dans GCC comme dans Clang, la chaîne de passes dépend des options spécifiées par l'utilisateur. Ainsi, les options -O0, -O3 ou -Os permettent d'initialiser cette chaîne pour que le code généré ait des caractéristiques différentes : un code facile à déboguer, un code performant, ou un code prenant peu de place en mémoire vive. En -O0, les transformations sont limitées à la génération d'un code qui corresponde à celui écrit par le développeur, peu de transformations sont donc effectuées. Pour générer un code performant (-O1 à -O3), les transformations peuvent réordonner les instructions, supprimer celles qui sont redondantes, mais aussi en dupliquer d'autres. Pour réduire la taille du code (en -Os), celui-ci est aussi optimisé pour la performance, mais les transformations qui risquent d'augmenter la taille du code sont évitées.
Notons au passage qu’en cas de code incorrect (les fameux Undefined Behavior [4]), le compilateur n’a aucune obligation de le transformer en respectant sa sémantique initiale, et peut par exemple supprimer des pans entiers de code.
Grâce à la RI, chaque passe peut être écrite par les développeurs du compilateur de façon indépendante de la cible, mais le comportement de la passe peut changer suivant ses propriétés.
En effet, la RI contient des informations relatives à l'architecture, comme le boutisme, l'alignement, la taille des pointeurs, les tailles d'entiers supportés de façon native par la cible, la taille des registres vectoriels, parmi d'autres. Ceci sert, par exemple lors de la vectorisation d'une boucle, à décider de combien d'itérations il faut la dérouler : typiquement, un multiple de la quantité d'éléments qui rentrent dans un registre vectoriel supporté par la cible.
Une fois la RI optimisée, il est temps de générer le code spécifique à la cible, ceci est fait dans le back-end.
2.6 Le back-end
Afin de pouvoir générer du code assembleur, la RI utilisée par l'optimiseur est transformée en un autre type de représentation intermédiaire, connue sous le nom de SelectionDAG dans LLVM. À la différence de la LLVM-IR, le SelectionDAG permet de représenter un plus grand nombre d'instructions spécifiques de la cible, et d'effectuer des opérations de pattern-matching de manière efficace, afin de réaliser des optimisations de plus bas niveau dans le back-end.
Pour continuer avec notre exemple, nous pouvons récupérer le code assembleur généré par le compilateur avec la commande clang -S -masm=intel pour l'architecture x86_64.
Ce code assembleur est un extrait du code associé à la fonction main. Dans le bloc de label .LBB0_2, on retrouve le bloc associé au corps de la boucle while de la fonction intToString (le bloc 11 dans la RI optimisée). De manière surprenante, on ne retrouve ni division ni modulo ! Où sont-ils passés ?
La division et le modulo sont des opérations coûteuses en termes de nombre de cycles. Mais, si le dénominateur est une constante connue, il est possible de remplacer la division par des opérations moins coûteuses : une multiplication et un décalage à droite (plus de détails sur cette astuce dans le livre Hacker's Delight [1] et sur ce blog [2]).
Dans notre code, la division est remplacée par une multiplication par 3435973837 et un décalage de 35 bits à droite.
3. Quelques autres exemples d'optimisation
Le code que nous avons utilisé comme exemple reste assez simple, et ne laisse pas énormément d'opportunités pour illustrer la richesse des optimisations des compilateurs. Afin d'être un peu plus complets, nous allons vous donner quelques autres exemples de transformations ayant un impact important sur le code généré, en fonction des éléments sur lesquelles elles s'appliquent.
3.1 Propagation de constantes
L'une des transformations les plus simples à imaginer est la propagation des valeurs constantes. Si une série d'instructions ne dépend en entrée que d'opérandes constantes, alors l'optimiseur peut calculer le résultat de cette série d'instructions, et propager la ou les valeurs constantes le plus loin possible (parfois même à travers les paramètres de fonction).
Bien qu'à elle seule cette transformation ne suffise pas toujours à diminuer de manière drastique le temps d'exécution d'un code, elle peut ouvrir la porte à d'autres optimisations telles que le peephole ou le retrait de code mort.
3.2 Optimisation peephole
L'optimisation peephole consiste à analyser un certain nombre d'instructions successives (une fenêtre), et à essayer d'y retrouver des motifs connus qui peuvent être simplifiés. Voici par exemple quelques équivalences qui sont simplifiées lors de cette étape : x | 1 => 1, x & x => x, x * 1 => x, etc. La liste est longue, et l'on voit ici l'intérêt de propager préalablement les constantes dans tous les opérandes possibles.
3.3 Retrait de code mort
Le retrait de code (dead code elimination ou DCE) est une optimisation simple ayant pour objectif de diminuer la taille du binaire généré. La transformation retire les basic blocks dont le compilateur peut prouver qu'ils ne seront jamais exécutés, soit parce qu'aucune branche n'y mène, soit parce que la condition de branchement peut être évaluée (par exemple, à la suite d'une propagation de constante). Elle élimine aussi les instructions dont le résultat n’est jamais utilisé. Ainsi, si l’on n’y prend garde, elle peut enlever les memset destinés à effacer les données sensibles de la mémoire...
Cette transformation est en fait appelée plusieurs fois au cours du pipeline d'optimisation, car différentes optimisations peuvent laisser du code mort. Et plutôt que d'implémenter la même logique dans chaque passe, autant réutiliser une transformation existante.
Une transformation similaire, l'élimination de code mort globale, agit au niveau de l'unité de compilation en supprimant les fonctions inutiles. Elle est notamment invoquée après l'inlining.
3.4 Simplification du graphe de flot de contrôle
La passe SimplifyCFG enlève les blocs qui n'ont pas de prédécesseurs, et ne seront donc jamais exécutés, et fusionne les blocs consécutifs qui peuvent l'être. C'est principalement une passe de nettoyage, qui réduit la taille du code et favorise les optimisations inter- ou intra-blocs ultérieures.
3.5 Optimisations de boucles
Les optimisations de boucles sont un point critique pour les performances du code généré par les compilateurs. À ce titre, c'est aussi là que le nombre de transformations est le plus important, et l'une des catégories qui a énormément d'impact sur la différence de structure entre le code source original et le code assembleur généré.
Parmi celles-ci, on peut citer le déplacement de code invariant (invariant code motion). Le compilateur détermine par une analyse que certaines valeurs calculées à chaque itération ne dépendent pas du compteur de boucle, et sont donc identiques à chaque tour de boucle. Il peut donc déplacer le code de calcul avant la boucle et économiser un bon nombre d'instructions.
Certaines optimisations dépendent de l'architecture cible. Par exemple, si elle possède des registres vectoriels et dans le cas où des instructions d'itérations successives peuvent être effectuées simultanément, le compilateur peut tirer parti des registres vectoriels pour rassembler ces instructions en une seule. Cette transformation s'appelle la vectorisation et l'intérêt semble assez évident : le nombre d'instructions à exécuter est divisé proportionnellement à la largeur des registres et, à moins de passer son temps dans des transferts mémoires, le temps d'exécution est également diminué.
Dans le cas où la boucle contient une condition, le compilateur peut décider d'extraire la condition de la boucle, et générer une version spécifique de celle-ci pour chacune des branches de la condition. Cette opération permet de diminuer le nombre d'instructions exécutées à chaque tour de boucle, et de donner plus d'opportunités pour la vectorisation de la boucle, le tout au prix d'une augmentation de la taille du code.
La dernière transformation que nous souhaitons mentionner est assez connue : le déroulage de boucle (loop unroll). Elle consiste à générer le code de plusieurs itérations successives d'une boucle, afin notamment d'éviter le saut en fin d'itération, et d'offrir de nouvelles opportunités pour d'autres optimisations. En fonction des paramètres d'itération, la structure de boucle peut éventuellement complètement disparaître. Ici encore, il s'agit d'un compromis entre la taille du code généré et la vitesse d'exécution.
Le lecteur curieux trouvera dans [3] une description des transformations de boucles et de leur enchaînement.
3.6 Un mot sur l'interaction entre les optimisations
En effet, comme vous pouvez le supposer, l'ordre des optimisations est primordial, et la force du pipeline d'optimisation dans son ensemble vient de sa capacité à les combiner dans le « bon » ordre. Par conséquent, les différents niveaux d'optimisation (-O1, -O3, etc.) sont très compliqués à décrire, sont ajustés empiriquement, peuvent évoluer entre des versions successives d'un même compilateur, et ne sont pas identiques d'un compilateur à un autre. La commande suivante permet d'afficher les passes exécutées pour la compilation d'un programme avec Clang :
Il est possible d'utiliser l'outil opt mentionné précédemment pour personnaliser ce pipeline, mais cela n'est pas possible au niveau du driver Clang.
Conclusion
Un compilateur, comme nous avons pu le voir, ce sont plusieurs étapes consécutives, des représentations intermédiaires, des transformations sur ces représentations visant à optimiser le code selon des critères parfois antinomiques (performance vs taille de code), des analyses pour assurer la validité de ces transformations et pour finir, une orchestration de tous ces outils pour aboutir à un code binaire final.
En tant que développeur, connaître ce processus est un atout indéniable pour pouvoir tirer parti des capacités des outils ou être conscient de leurs effets et limitations, notamment en termes de sécurité. En tant que reverser, cela permet de comprendre la structure des codes générés, et de réutiliser ou d’adapter leurs techniques pour développer des outils d'aide au reverse.
Dans les deux cas, il ne faut pas oublier que les compilateurs évoluent en permanence et à tous les niveaux, que ce soit pour améliorer les optimisations ou pour prendre en considération les évolutions des architectures cibles.
Références
[0] https://connect.ed-diamond.com/misc/mischs-024
[1] Henry S. Warren. 2012. Hacker's Delight (2nd. ed.). Addison-Wesley Professional.
[2] Integer division by constants. Microsoft documentation,
https://docs.microsoft.com/en-us/archive/blogs/devdev/integer-division-by-constants
[3] M. Kruse et H. Finkel, Loop Optimizations in LLVM: The Good, The Bad, and The Ugly. 2018 LLVM developers' meeting, https://llvm.org/devmtg/2018-10/slides/Kruse-LoopTransforms.pdf
[4] F. Riss, R. Govostes, A. Zaks, Understanding Undefined Behavior. WWDC 2017, https://devstreaming-cdn.apple.com/videos/wwdc/2017/407kc2s6vvx95/407/407_understanding_undefined_behavior.pdf
[LLVM] LLVM, https://llvm.org/