

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Ces dernières années ont été le témoin d'une recrudescence d'attaques informatiques avec des victimes de plus en plus nombreuses, et des impacts financiers tout aussi conséquents. Une chose est sûre, nos données valent de l'argent et il faut les protéger. Il est donc indispensable d’opter pour une stratégie de détection à la hauteur de leur valeur.
Le gouvernement français en a d’ailleurs pris conscience et a lancé en 2020 un vaste dispositif nommé « France Relance », comprenant un volet cybersécurité, dédié à aider les acteurs publics à renforcer le niveau de sécurité de leurs infrastructures, mais également à la création de CSIRT régionaux (pour porter assistance aux TPE/PME et aux particuliers) [1].
De nombreuses méthodes apportent un cadre de réflexion aux entreprises afin d’établir la stratégie de réflexion la mieux adaptée. Il s’agit de prendre en compte toutes les aspérités de nos systèmes d’information, qu’elles soient bonnes ou mauvaises, et les mettre sous surveillance. Parmi ces méthodes, nous pouvons citer :
- la cyber kill chain est une méthode de modélisation des procédés d'intrusion sur un réseau informatique proposée en 2011 par la société Lockheed Martin [2]. Elle permet de définir une stratégie de détection comprenant les moyens mis par une organisation pour répondre aux problématiques de chacune des 7 phases de cette méthodologie, dépendamment des vecteurs d'attaques identifiés. Chacune de ces phases correspond à l’objectif que l’attaquant doit réussir pour compléter son attaque ;
- l’unified kill chain datant de 2017, proposée par Paul Pols, apporte des améliorations significatives en prenant en compte un périmètre bien plus large (cf. image ci-dessous) ;
- le framework MITRE ATT&CK [3] sera détaillé dans la suite de l’article ;
- les analyses de risques (EBIOS RM…).
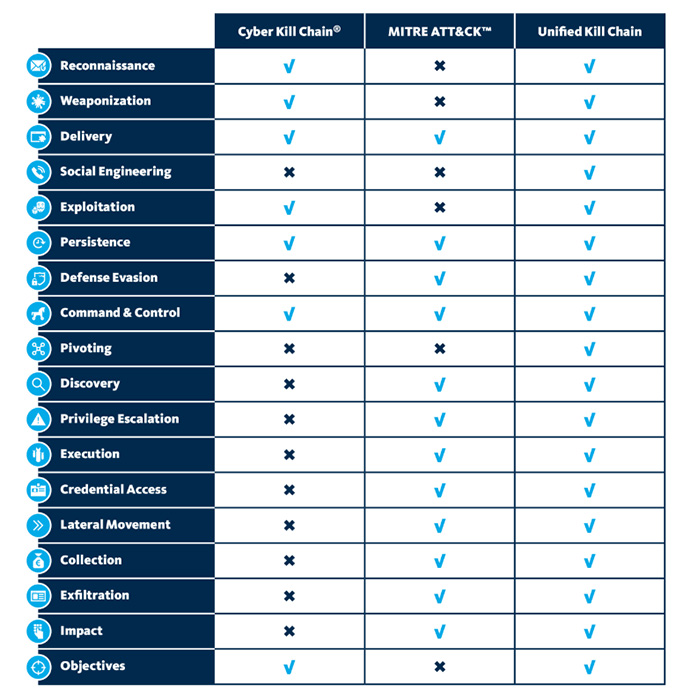
Ces réflexions vont conduire à la mise en place d’un ensemble de solutions techniques afin d’empêcher la réussite de ces étapes par l’attaquant et vont être à l’origine d’une quantité importante d’événements de sécurité et de fichiers de logs. C'est dans ce contexte de gestion, caractérisation et exploitation des logs que le SOC trouve son intérêt.
Il est à noter qu’il n’y a pas de stratégie de détection universelle. Il s’agit bien d’avoir une réponse pragmatique en identifiant les vecteurs d’attaques, les vecteurs ou tactiques techniques, IOC et IOA pouvant impacter l’organisation et comment ces derniers peuvent être détectés. Nous avons pour cela un ensemble d’outils dédiés à ces nombreuses étapes.
1. Qu’est-ce qu’un SOC ?
Le SOC (Security Operations Center) doit être appréhendé comme le cœur de la cybersurveillance. Il s’agit de l’entité qui se doit de connaître au maximum les systèmes d’information, leur fonctionnement et leurs particularités. Pour l’aider dans sa mission, l’analyste SOC travaillera en étroite collaboration avec les opérationnels pour obtenir des schémas réseau et des indications sur la vie des systèmes. Il a ainsi une vision holistique de la sécurité de l’entreprise, ce qui lui permettra de corréler plusieurs événements suspects provenant de systèmes différents et en découler un incident de sécurité. Ce positionnement au sein de l’entreprise et cette vision globale permettent également de coordonner efficacement les investigations en étroite collaboration avec les équipes de réponse sur incident CERT/CSIRT, les opérationnels et la DSI.
L’ANSSI a dans ce sens publié un référentiel « PDIS » ayant pour but d’encadrer les différents SOC présents en France. Ce référentiel spécifie notamment un certain nombre d’exigences attendues pour que l’intégrité d’une preuve fournie ne puisse pas être remise en question par les CERT/CSIRT lors de l’analyse, et/ou par le juge chargé de l’affaire. Car oui, en fonction du niveau de criticité de l’incident, l’affaire peut être judiciarisée suite au dépôt d’une plainte.
Pour comprendre comment s’intègre le SOC dans l’écosystème de la cyberdéfense, le diagramme ci-dessous décrit ses missions et comment il communique avec les autres acteurs (CSIRT/CERT). Note : CERT est une marque déposée aux États-Unis, raison pour laquelle il est souvent mal employé :

Le SOC a pour rôle de veiller à la centralisation des informations liées à l’activité de nos systèmes et à les superviser. Pour cela, il est nécessaire de mettre en œuvre un ensemble de solutions techniques parfaitement compatibles les unes avec les autres afin d’obtenir un écosystème homogène. Cet écosystème n’est pas facile à appréhender, car il doit répondre à un certain nombre d’attentes, dont celles de collecter des informations de capteurs hétérogènes (systèmes, réseaux...) et d’y appliquer des règles de détection adaptées. Vous l’aurez compris, toutes ces briques vont permettre de collecter, de normaliser, d’enrichir les données provenant des actifs de votre SI, pour permettre une détection optimale et faciliter la qualification des événements de sécurité de la part des analystes. Cette qualification se fera au sein d’une solution appelée SIEM qui a pour rôle d’unifier l’ensemble des informations collectées, normalisées, traitées et enrichies. L’objectif premier est de pouvoir détecter toute intrusion ou tout comportement malveillant sur notre système d’information avant que la situation ne devienne catastrophique pour l’entreprise. Le second se situe, malheureusement, après que le mal ait été fait. Il s’agit d’être en capacité de fournir aux équipes de réponse à incident des informations cruciales permettant le bon déroulement de leur investigation. Sans ces informations, les équipes seraient dans l’incapacité d’identifier avec certitude le vecteur initial d’intrusion, les souches utilisées, le périmètre, et ainsi espérer un retour à la normale rapide.
1.1 Quel SOC pour quel besoin ?
Les solutions SOC ont très rapidement évolué et de nombreuses notions les caractérisent.
Nous pouvons distinguer les SOC :
- externes ;
- internes ;
- hybrides.
Dans le cas d’un SOC externe, le prestataire fournit un service managé de sécurité ou MSSP en apportant rapidement des ressources, processus et technologies aux équipes de sécurité des entreprises. Dans le cas d’un SOC interne au contraire, il s’agit de rendre la DSI autonome sur les choix des solutions utilisées, hébergées au sein de leur propre infrastructure.
Votre choix doit se porter sur vos attentes et le budget mis à votre disposition par la direction de l’entreprise. Externaliser la supervision de sécurité peut être une très bonne solution. Cela permet de bénéficier des compétences et de l’expertise d’une équipe déjà formée, mais également de process internes rodés. La partie RH (salaires, vacances, arrêts maladie) est de ce fait déléguée au prestataire de services, vous permettant de vous focaliser uniquement sur votre métier. De plus, toute l’infrastructure recueillant les informations de vos SI est installée, maintenue et sauvegardée par le prestataire, vous garantissant un taux de disponibilité élevé (grâce au PCA/PRA mis en place). Vous l’aurez compris, tout ceci a un coût de fonctionnement important, et faire le choix d’un SOC managé vous permet de vous en abstenir. Certes, la prestation sera plus coûteuse sur le long terme, mais vous permettra dans un premier temps de vous consacrer à votre expansion. A contrario, le choix de faire appel à un SOC externe implique une certaine dépendance et un coût non négligeable dans la configuration associée à l’envoi des données dans son infrastructure, qui pourrait être à renouveler si vous décidez de changer de prestataire dans quelques années. De plus, certains prestataires basent leur tarification sur la quantité de données envoyées, il est donc très important de prendre en compte ces éléments dans sa réflexion.
Petit point d’attention, même si l’externalisation du SOC reste attractive au premier abord, il est nécessaire de prendre en compte le niveau de confidentialité associé aux données qui devront être transmises sur des clouds plus ou moins maîtrisés. Certaines précautions et garanties devront être prises auprès du prestataire afin de garantir ces critères. Cette sensibilité des données peut amener une entreprise à faire le choix d’un SOC hybride en favorisant la supervision de sécurité des SI sensibles par un SOC interne et les autres SI de moindre importance à un SOC externe.
Les SOC hybrides peuvent également prendre sens dans un découpage du processus de traitement des événements de sécurité. Le SOC externe assure ainsi la prise en compte et qualification des événements de sécurité et le SOC interne a la charge de toute investigation poussée et remédiation. Cette approche démontre une certaine logique étant donné que le SOC interne possède sans aucun doute une meilleure connaissance de l'infrastructure.
Les SOC managés représentent une réelle plus-value pour les entreprises, car en plus de permettre le lissage du budget alloué à la supervision de sécurité sur plusieurs années, il s’agit d’une réelle opportunité de consacrer une part du budget en communication et/ou en R&D. Cela permet de réduire ainsi les coûts liés à une infrastructure, aux personnels et aux formations nécessaires pour constituer un SOC mature, cela même si, au final, le SOC managé représentera un coût plus élevé sur le long terme.
Il est à noter qu’il est néanmoins recommandé de garder en local l’analyse du réseau « NDR » (Network Detection & Response), car les SOC managés n’ont pas la connaissance des infrastructures, des flux réseau, légitimes ou non, et il leur est ainsi très difficile d’apprécier un événement de sécurité.
1.2 Les différents acteurs actuellement sur le marché
Nous avons pu voir qu’un SIEM est indispensable au SOC pour mener à bien sa mission. Il existe actuellement un ensemble de solutions sur le marché et il peut paraître difficile de faire le bon choix. Chaque année, GARTNER publie son « MAGIC QUADRANT For SIEM » [4], résumant ainsi les données recueillies tout au long de l’année [5], afin de conseiller les entreprises dans leur réflexion. Nous avons effectivement constaté une corrélation entre ce classement et la répartition des solutions étudiées sur le marché français, avec une présence quasi exclusive de Splunk et IBM QRadar.
1.3 Alors que faire ?
Pour choisir le SIEM pour notre entreprise, il est important que ce dernier réponde à chacun des besoins identifiés.
Même si l’objectif est de superviser l’intégralité de son système d’information, les lignes budgétaires ne sont pas du même avis. Il va donc falloir procéder à un arbitrage et prioriser le(s) système(s) d’information le(s) plus important(s). Le curseur peut être placé au niveau de la criticité/disponibilité/intégrité des données du SI, et/ou au niveau d’exposition d’un SI à Internet, et/ou sur la vétusté d’un SI qui ne peut plus bénéficier de mises à jour de sécurité. Autant de critères tout aussi importants les uns que les autres.
C’est pour cela qu’il est très important d’inclure l’ensemble des équipes de production/exploitation dans la mise en œuvre de la stratégie de détection. Ces différents acteurs apporteront leur connaissance des SI de l’entreprise, mais également des contraintes techniques qu’il faudra prendre en compte (p. ex. : faible bande passante d’un site localisé à l’autre bout du monde).
De plus, un SIEM doit pouvoir interagir avec l’ensemble des technologies présentes au sein de nos écosystèmes, qu’elles soient OnPremise ou dans le cloud.
Pour que nous puissions bénéficier d’une bonne surveillance, certains capteurs sont incontournables et donc voici une liste non exhaustive dans laquelle vous pourrez identifier la solution la plus adaptée à votre besoin :
- journaux d’événements système, encore trop peu exploités à ce jour ;
- antivirus, eh oui, peu d’entreprises exploitent également leurs journaux ;
- capteurs système, type : EDR, SYSMON ;
- capteurs réseau, type : sonde NIDS, journalisation des requêtes DNS, honeypot. Il est également possible d’analyser les journaux d’événements de votre proxy, si et seulement si ce dernier réalise une interception SSL.
Indicateurs et maturité du SOC :
- Niveau de maturité via la méthodologie SOC CMM (Measuring Capability Maturity in Security Operations Centers). Il s’agit d’une méthodologie permettant de mesurer la maturité d’un SOC [6].
- Mise en place de KPI (Key Performance Indicators) tendant à définir les axes d’amélioration, quelques exemples :
- nombre d’équipements surveillés ;
- durée du processus d’investigation ;
- MTTD (Mean Time to Detect) : durée avant connaissance d’un potentiel incident de sécurité.
- Maturation des processus de Threat Hunting (Méthode [TaHitI] par exemple) afin de proposer des matrices de risques par SI pour l’analyste SOC.
2. Une règle, des règles, trop de règles
Les règles de détection permettent de confronter des patterns précis à des données collectées pour en déterminer un comportement malveillant. Elles se distinguent en fonction du type de données et du moteur de détection utilisés.
L’évolution des technologies et notre perpétuelle adaptation à la menace ont vu fleurir de nombreuses solutions techniques. Les moteurs de détection les plus connus sont les NIDS et HIDS. Chacun d’entre eux officie sur un périmètre bien spécifique, les NIDS pour « Network Intrusion Detection System » et HIDS pour « Host Intrusion Detection System ». Les dernières années ont apporté également les notions d’EDR « Endpoint Detection Response », ADS « Anomaly Detection System » et NDS « Network Detection System ».
3. Exemples de solution
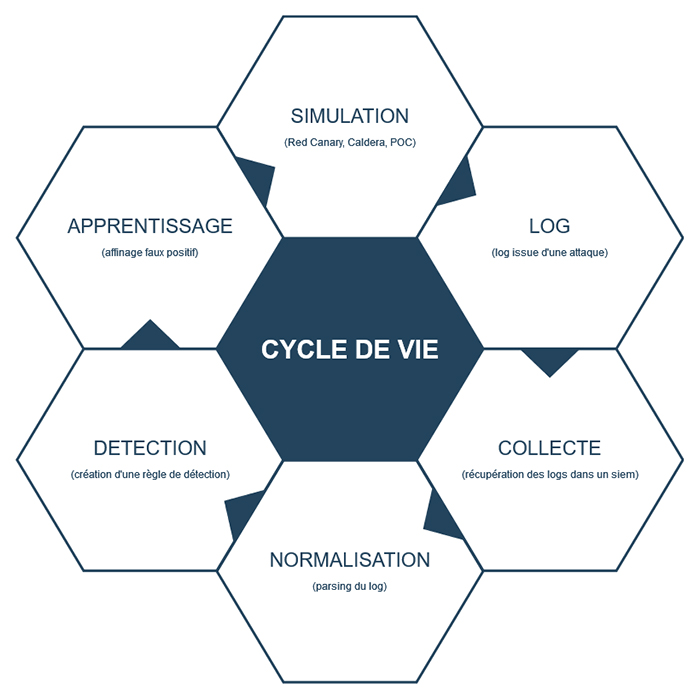
Le SOC tire sa puissance de sa capacité à détecter la menace avec, au cœur de ce mécanisme, des règles de détection. Nous allons détailler le mode de fonctionnement de deux entreprises sur leur gestion de règles. Il n'y a pas de bonne ou mauvaise façon de procéder et les cas présentés ne sont bien entendu pas exhaustifs. La figure ci-dessous présente le cycle de vie des règles de détection. Il présente les nombreux éléments nécessaires à l’établissement d’une détection cohérente et est, de facto, au cœur de nombreuses stratégies de détection.
3.1 Première solution
Pour la première entreprise, l'idée de départ a été de se baser sur un référentiel, le framework MITRE ATT&CK [3] ainsi que sur le format de signature Sigma [7].
La matrice MITRE ATT&CK référence un ensemble de tactiques et techniques d'attaques (exemple : https://attack.mitre.org/techniques/T1134/).
S’agissant d’un standard, les règles Sigma devront être converties afin de s’adapter aux solutions techniques. Dans le cas présent, c’est le couple Elastic [8] + Elastalert [9] qui est utilisé. Cette conversion peut se faire via l’outil mis à disposition par Sigma à savoir Sigmac ou bien via des sites dédiés tels qu’Uncoder [10]. Attention à la pertinence de la traduction dans ce cas précis.
La principale problématique est de pouvoir traduire un comportement écrit au format Sigma selon un vocabulaire plus ou moins avancé, car dans bien des cas, certaines règles ne pourront être traduites. Pour exemple, les premières règles relatives au malware Emotet ont été traduites de Sigma en SPL (langage de requête propre à Splunk), car Elastalert ne possédait pas le vocabulaire suffisant pour assurer cette détection.
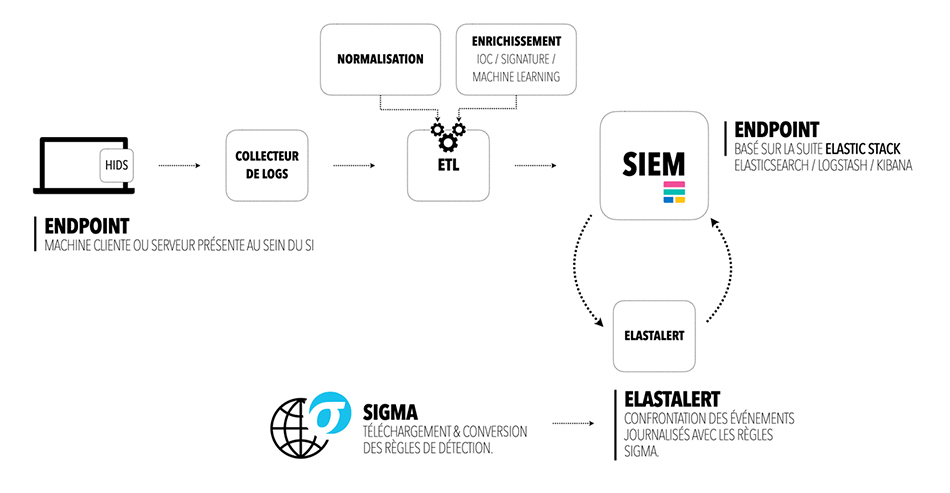
Le schéma ci-dessus montre que le choix s’est porté exclusivement sur l’HIDS comme source de logs. De nombreuses entreprises, au regard de la difficulté de gérer des règles Suricata (taux de faux positifs) ou autre NIDS, ont exclu cette source de logs.
Les agents de transfert installés sur les postes clients appartiennent à la suite Elastic. Connus sous le nom d’agents Beats, ils permettent aussi bien de transférer des indicateurs, données réseau, que des fichiers d’événements (p. ex. : winlogbeat pour les logs des événements Windows) et sont donc compatibles avec le standard ECS pour « Elastic Common Schema » [11] facilitant ainsi la normalisation des logs. Cette spécification normalise un ensemble de champs (nom, description, exemples). De manière plus globale, les « Common Information Model » ou CIM sont composés de modèles de données permettant de normaliser les données vers des standards communs.
Une fois les règles converties au format Elastalert, elles sont vérifiées d’un point de vue structure, avec génération automatique d’un log validant la lecture de la règle. Cette méthode comportant de nombreux biais, un processus de validation de règles via simulateur a été mis en place.
Pour ce faire, une équipe est chargée de la simulation. Cela consiste donc à générer des attaques afin de créer des règles précises et adaptées. Ces solutions sont diverses, mais dans le cas présent, il s’agit d’une solution IaaS basée sur « Terraform + Packer + Ansible » pour le déploiement.
Le processus est le suivant :
- création de scénario avec SI à superviser ;
- action de la purpleteam (redteam + blueteam) :
- sous forme de scénario ;
- via des frameworks adaptés (Red Canary, Caldera, APT Simulator…).
- création des règles (test / validation).
Ce premier cas est intéressant, car il prend l’existant comme base de référence et adapte ce dernier pour les besoins propres à l’entreprise en question. Cette démarche, bien qu’empirique, est partie d’une base de connaissances de la menace, sans se focaliser sur la menace pouvant cibler ses SI.
Note : bien que les choix techniques ne soient pas au centre de cet article, il est à noter que c’est la seule société s’appuyant sur la suite Elastic que nous ayons rencontrée. Le choix d’Elastalert avec l’arrivée dans les prochaines versions d’EQL et les possibilités offertes par Opendistro [12] influeront sûrement sur ce processus.
Note bis : une étude est en cours pour intégrer les événements ETW afin d’être plus précis sur la détection de certains patterns.
3.2 Seconde solution
La seconde société que nous allons présenter procède à une génération des règles via une approche proactive alliant la Threat Intelligence associée à une analyse comportementale du réseau et du système suite à l’exécution d’un binaire suspect en environnement maîtrisé.
Durant son fonctionnement, le processus associé au binaire va réaliser un certain nombre d’actions telles que la création de fichiers sur le disque, création de tâches planifiées, mais également des tentatives de connexions vers son serveur de rattachement C2.
Autant d’informations/d’observables que nos capteurs vont intercepter et que les analystes qualifieront. Ces derniers, illustrés sur le schéma, vont permettre de comprendre le mode opératoire des attaquants (IOC+IOA) et en découler des règles de détection.
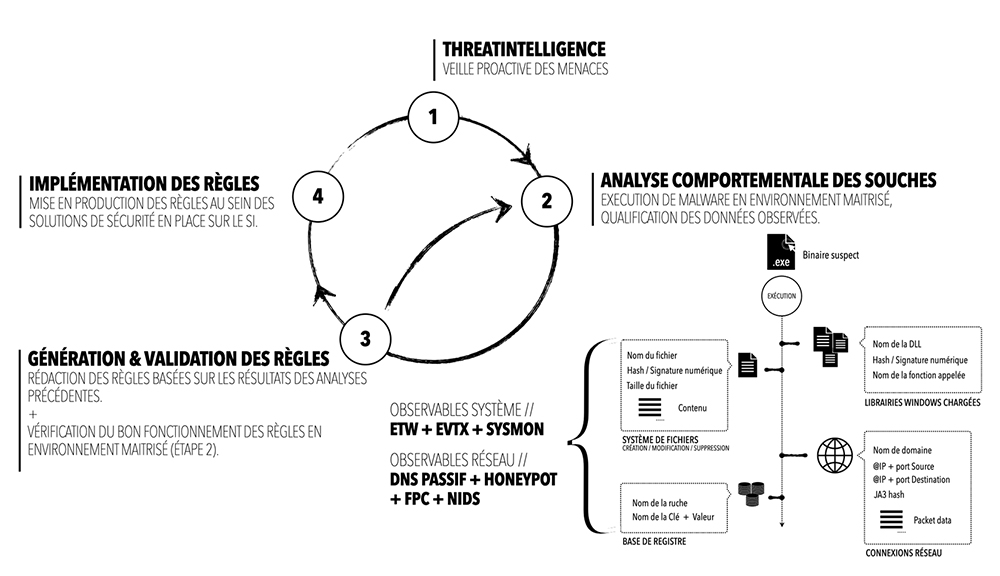
Le schéma ci-dessus représente succinctement les différentes étapes constituant cette approche proactive. Cette dernière, souvent utilisée par les équipes de Threat Intelligence, permet d’enrichir leur connaissance des menaces dans le domaine du renseignement d’intérêt cyber. Les souches inconnues identifiées suite à une veille des analystes sont récupérées, puis analysées. Tout d'abord de manière statique (via des outils tels que Capa, PeStudio, Radare2...), puis dynamiquement via détonation au sein d’une sandbox. Les données recueillies durant les étapes 1 et 2 permettront d’établir des règles de détection qui pourront être testées et validées en rejouant la détonation. Même si les malwares ont su s’adapter et détecter les environnements virtualisés afin de contourner les analyses, cette technique reste toujours valable, car il ne faut pas oublier que nos infrastructures sont de plus déployées en environnement virtualisé et cela ne nous empêche malheureusement pas de subir des campagnes de ransomwares.
Nous attirons votre attention sur le fait que cette approche peut vite trouver ses limites dans la durée de vie associée aux IOC identifiés. Ils peuvent très bien être pertinents durant l’analyse, mais obsolètes dans les 24 prochaines heures.
Nous souhaitons partager, pour finir cet article, une vision personnelle de ce que nous aurions aimé rencontrer au travers de nos activités. Même si les solutions tendent à évoluer dans le bon sens, nous rencontrons encore trop souvent des interfaces utilisateurs laissant les analystes face à des millions d’événements de sécurité produits par nos solutions de sécurité, souvent sans être enrichis de contexte ni être regroupés. Ainsi, charge à eux de mettre en place des filtres pour éliminer le bruit des faux positifs ou données déjà traitées.
Le schéma ci-dessous illustre une vision unifiée claire et concise que toute solution de type SIEM se doit, selon nous, de proposer aux SOC. Nous pouvons y découvrir un workflow d’analyse débutant par les indicateurs de sécurité jusqu’aux données relatives au contexte, en offrant la faculté aux personnels du SOC de rebondir d'un IOC vers une liste d'actifs permettant ainsi d’obtenir des indicateurs de performances (KPI) tels qu’un MTTD « Mean Time To Detect » et un MTTR « Mean Time To Respond » très faibles.
N’oublions pas que le rôle premier d’un SOC est d’analyser les alertes de sécurité, mais surtout le cas échéant d'identifier un périmètre des actifs impactés par une attaque en ayant une vision holistique de son SI, et non des milliers d’occurrences d’événements.
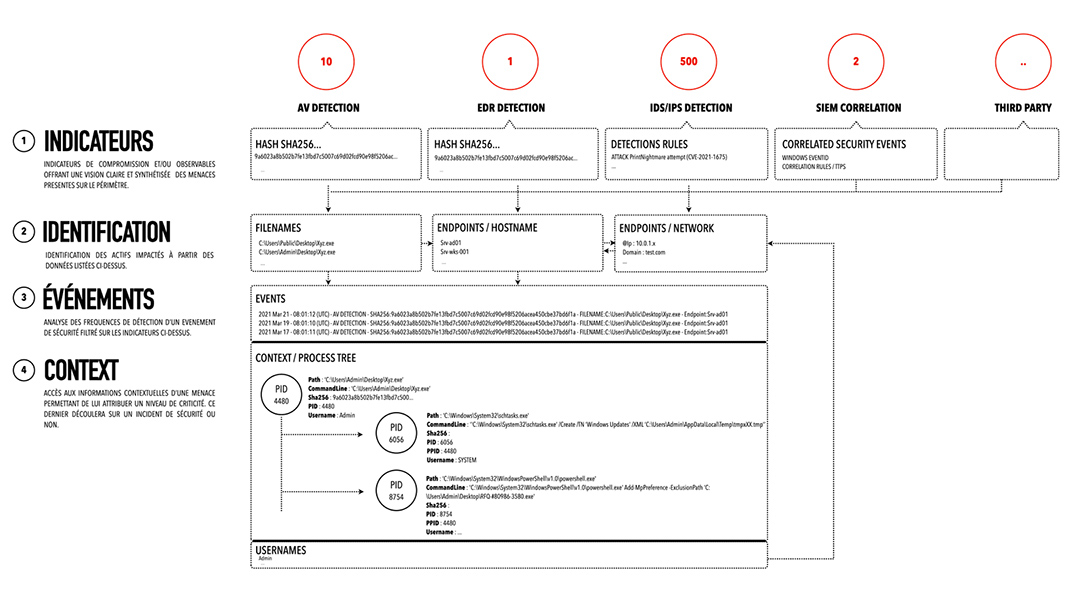
L’objectif de ces approches est d’aborder des moyens constituant une défense en profondeur.
Gardons à l’esprit que les cas présentés sont bien entendu non exhaustifs, mais représentent selon nous une vision plus ou moins répandue des solutions actuelles. Une parenthèse sur l’analyse de risques. Nous avons rencontré quelques entreprises ayant inclus dans leur processus l’exploitation des analyses de risques de type EBIOS RM qui couplées avec d’autres indicateurs (CVE, menace et mode opératoire rattachés à chaque SI…) proposent une vision intéressante. Nous n’avons pas, au regard des contraintes de place, abordé plus en profondeur cette approche.
Conclusion
L’importance du SOC et des différents éléments qui le composent dans la politique de cybersurveillance est indéniable. Il faut garder à l’esprit que son utilité est étroitement liée à sa capacité à détecter des événements de sécurité. Il n’y a pas de normes et les sociétés ont souvent dû s’adapter et trouver des solutions. L’hétérogénéité des solutions présentées en est le témoin.
Il faut cependant accorder une attention toute particulière et cohérente aux règles de détection. Se baser sur un état de l’art, se protéger après avoir subi une attaque ou encore prendre les recommandations d’une analyse de risques sont autant de méthodes qui, bien que subjectives, sont le reflet d’un effort d’adaptation de l’entreprise face à la menace, et c’est bien là le plus intéressant.
Remerciements
Nous espérons que vous avez pris autant de plaisir à lire cet article que nous en avons pris à l’écrire. Cet article est le résultat de réflexions, d’expériences passées, réunissant deux amis que la vie a éloignés, mais qui profitent de ces projets pour se retrouver.
Références
[1] Publication de l’ANSSI relative au plan France Relance : https://www.ssi.gouv.fr/agence/cybersecurite/france-relance/
[2] Modélisation des procédés d'intrusion :
https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html
[3] Site officiel dédié au framework MITRE ATT&CK : https://attack.mitre.org
[4] Article listant les solutions SIEM du marché en 2021 :
https://www.silicon.fr/siem-distingue-marche-densification-412136.html
[5] Site du cabinet Gartner :
https://www.gartner.com/reviews/market/security-information-event-management
[6] Site dédié à l’évaluation de la maturité de SOC :
https://www.soc-cmm.com/downloads/soc-cmm%20whitepaper.pdf
[7] Dépôt GitHub contenant les règles Sigma : https://github.com/SigmaHQ/sigma
[8] Site officiel des solutions Elastic : https://www.elastic.co/fr/
[9] Site dédié à la solution Elastalert : https://github.com/Yelp/elastalert
[10] Site Uncoder dédié à la conversion des règles de détection : https://uncoder.io/
[11] Documentation relative au schéma utilisé par les solutions Elastic : https://www.elastic.co/guide/en/ecs/current/ecs-field-reference.html
[12] Site dédié au projet Open Distro : https://opendistro.github.io/for-elasticsearch/
[TaHitI] Présentation de la méthodologie de Threat Hunting TaHiTI : https://www.betaalvereniging.nl/wp-content/uploads/TaHiTI-Threat-Hunting-Methodology-whitepaper.pdf




