

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
L’objet de cet article est de vous donner les clés pour installer (et tester) votre propre système d’orchestration de conteneurs basé sur Kubernetes, classique, et CRI-O, beaucoup moins classique.
Sur beaucoup de documentations, y compris l’officielle de Kubernetes (abrégé en K8s dans la suite de l’article), le moteur de conteneurs par défaut est Docker. Or il existe une alternative à Docker nommée CRI-O. Cette alternative est maintenant le moteur de conteneurs par défaut sur la solution OpenShift qui est un K8s packagé par Red Hat [1]. Il existe beaucoup de documentations pour intégrer CRI-O avec K8s, mais beaucoup sont fausses, obsolètes et surtout assez morcelées. Cet article va vous donner toutes les étapes ainsi que quelques éléments théoriques pour installer votre propre infrastructure K8s + CRI-O en local.
1. Préambule
Cette section introduit les termes avec une définition de chacun succincte, mais suffisante pour la compréhension générale de l’article. Cette introduction est suivie de la présentation du laboratoire utilisé pour les manipulations et des manipulations à effectuer sur les nœuds pour les préparer à l’installation de K8s.
1.1 Terminologie
Un premier travail est de se mettre d’accord sur la terminologie. Nous allons partir de la définition d’un orchestrateur et expliciter chaque notion l’une après l’autre. Un orchestrateur est un système d’ordonnancement de conteneurs sur une infrastructure. Je ne vais pas prendre les termes dans l’ordre volontairement. Commençons par définir la notion de conteneur.
Un conteneur est une boite dans laquelle on enferme un programme. Cette boite est étanche et contient toutes les dépendances nécessaires à son fonctionnement. L’étanchéité (par rapport au système hôte et vis-à-vis des autres conteneurs) est garantie par des mécanismes d’isolation dans le noyau [2]. Une fois remplie, cette boite se présente sous la forme d’une image. En pratique, elle contient un /etc, /lib, /bin, etc. Une fois créée, elle est mise à disposition dans un registre qui est un dépôt accessible par votre infrastructure K8s. Le dépôt public le plus classique est celui de Docker, docker.io, qui fournit des images prêtes à l’emploi.
Une infrastructure est un ensemble de machines physiques ou virtuelles. Pour l’orchestrateur, il s’agit des ressources disponibles pour y placer ses conteneurs. Dans des environnements type Cloud, il est classique d’exécuter les conteneurs dans des machines virtuelles, car elles sont plus faciles à provisionner. Le provisionnement est l’action de mettre automatiquement à disposition des machines virtuelles configurées à l’orchestrateur sur lesquelles exécuter ses conteneurs. Ce principe est complémentaire à la fonction de mise à l’échelle automatique orchestrateurs (autoscale) qui instancie automatiquement des conteneurs en cas de surcharge du service. Attention, provisionnement ne rime pas forcément avec virtualisation, une provision des machines physiques est tout à fait réalisable. Chaque machine physique ou virtuelle est appelée un nœud.
L’ordonnancement est l’utilisation d’un algorithme PAR l’orchestrateur POUR placer les conteneurs sur l’infrastructure physique. L’orchestrateur dispose donc d’une vision globale des ressources disponibles sur l’infrastructure. Il va y placer les conteneurs en confrontant l’état des ressources avec les contraintes attachées au conteneur formulées par l’utilisateur. L’algorithme consiste à évaluer différents critères pour calculer un score pour chaque nœud et élire le plus propice à accueillir le conteneur. Une fois placé et lancé, le conteneur exécute le programme contenu dans la boite.
1.2 Préparation de l’environnement de test
Notre infrastructure de test est composée de trois nœuds virtualisés. Le premier nommé api-server va être dédié à héberger le cerveau de notre orchestrateur. C’est-à-dire le composant qui va ordonnancer les conteneurs. Nous allons suivre une des premières bonnes pratiques à observer lors de la mise en place d’un orchestrateur qui est d’interdire l’ordonnancement de conteneurs sur ce nœud. Les deux autres nœuds nommés node1 et node2 seront utilisés par api-server pour y exécuter les conteneurs. Ces trois nœuds tournent sur une Debian Buster (10). L’installation de K8s nécessite une préparation sur chaque nœud de notre laboratoire de test. Ces actions sont à effectuer en root évidemment.
Nous allons commencer par le réseau. Cette phase est intimement liée au plugin usité par la suite. Dans cet article, j’ai choisi Calico. Cependant, je donnerais les directives nécessaires aux principaux plugins (ça coûte pas cher). Pour Calico, il faut autoriser l’ip_forward. Cette directive est une variable du noyau autorisant (ou non) le transfert de paquets entre les interfaces réseau (physiques ou virtuelles). En conséquence, c’est souvent un préambule à la configuration de tables de routage. C’est le cas ici, car les paquets ont besoin d’être routés entre les interfaces virtuelles associées aux conteneurs. Tout cela se passe dans le fichier /etc/sysctl.d/k8s-net-forward.conf :
Pour d’autres plugins plus simples que Calico, iptables doit accéder au trafic des ponts (bridge). On commence par activer le module noyau br_filter dédié au filtrage des ponts :
Puis on rend la manipulation persistante en ajoutant le module dans le fichier /etc/modules :
Une fois ce module chargé, il faut initialiser ses variables pour autoriser iptables à filtrer le trafic des ponts. Vous pouvez les renseigner dans un fichier /etc/sysctl.d/k8s-br.conf :
On indique au noyau de relire les fichiers pour ajuster les variables en fonction de nos réglages :
On notera que l’on peut afficher toutes les variables disponibles avec leurs valeurs respectives :
Toujours pour la partie réseau, il faut repasser de nftables à iptables pour Calico [3] :
La dernière étape est de désactiver le swap. Cette étape est nécessaire à l’installation future de K8s :
On rend cette manipulation persistante en le désactivant dans le fstab :
Pour vérifier :
Je vous conseille à cette étape de redémarrer la machine et de vérifier que tous les changements sont bien persistants. Ces manipulations doivent être réalisées sur TOUS les nœuds de l’infrastructure.
2. Installation de CRI-O
CRI-O est un moteur de conteneurs. C’est lui qui est chargé de prendre une image et de l’exécuter sur la machine. Docker est autre moteur plus célèbre que CRI-O. Cet article n’a pas pour but de faire un comparatif entre les deux. Pour positionner simplement CRI-O, on peut dire qu’il a été développé spécifiquement pour uniquement exécuter des conteneurs. Docker s’envisage plus comme une trousse à outils autosuffisante de gestion des conteneurs. Par rapport à CRI-O, Docker intègre des outils de gestion des images (création, modification et gestion des dépôts). Attention cependant, Docker n’est plus monolithique. Les développeurs ont repensé le produit pour l’éclater en modules. Les deux produits sont donc tout à fait intégrables dans des infrastructures plus globales type K8s. CRI-O doit être installé sur TOUS les nœuds de l’infrastructure, car les services K8s sont eux-mêmes dans des conteneurs.
CRI-O s’appuie sur le module noyau overlay qui fournit le système de fichiers overlayfs. Ce système de fichiers est utilisé par les images en lecture seule (type live CD) pour garder une trace des altérations niveau fichiers (par exemple modification d’un fichier, ajout d’un paquet, etc.). Overlayfs gère une couche accessible en écriture au-dessus de l’image pour stocker les différences dues au cycle de vie du conteneur.
Puis on rend la manipulation persistante en ajoutant le module dans le fichier /etc/modules :
Passons aux dépendances :
Ensuite, on récupère la dernière version de CRI-O :
On installe directement, pas de compilation, car nous avons récupéré la version déjà compilée statique.
À partir de maintenant, nous avons un moteur de conteneurs capable d’exécuter des images. Pour qu’il soit complet, il doit aussi connaître un ou plusieurs dépôts pour aller les chercher. Cela se passe dans le fichier /etc/containers/registries.conf :
Il nous reste plus qu’a activer le service via systemd :
Vérifions après redémarrage de la machine que tout est bon :
Passons à la configuration de l’orchestrateur K8s qui va placer les conteneurs sur nos nœuds.
3. Architecture de K8s
L’architecture de K8s s’articule autour d’un service central nommé API-Server. La figure 1 présente un schéma (très) simplifié d’une instance de K8s. Nous allons expliciter chacune des interactions représentées sur le schéma.
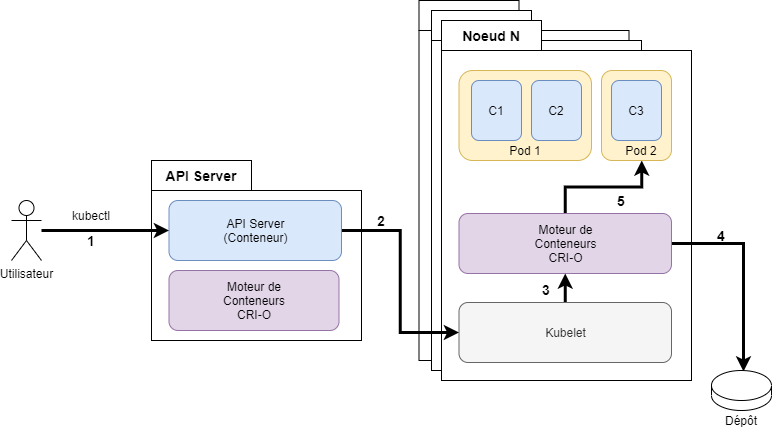
3.1 Interactions entre les composants
Rappelons que l’objectif de K8s est de placer les conteneurs créés par les utilisateurs sur une infrastructure. L’utilisateur interagit avec l’API-Server via une commande nommée kubectl. L’utilisateur décrit un état souhaité dans un fichier YAML et le passe à la commande kubectl. Cet état cible peut être le lancement d’un ou plusieurs conteneurs. L’interaction (1) est donc la soumission de la requête de l’utilisateur à l’API-Server via l’outil kubectl. On notera que l’API-Server est lui-même un conteneur. C’est pour cette raison que nous installons CRI-O partout. L’API-Server va évaluer les ressources disponibles, réfléchir (phase ordonnancement) et envoyer au nœud sélectionné la requête d’exécution de conteneur. Sur chaque nœud, un composant nommé Kubelet s’exécute pour interagir avec le moteur de conteneur (CRI-O). L’API-Server s’adresse à lui, c’est l’interaction (2). Par conséquent Kubelet n’est pas conteneurisé. Si la demande est de créer un conteneur, le Kubelet passe la requête au moteur de conteneur CRI-O. C’est l’interaction (3). L’interaction (4) est optionnelle, car elle consiste à récupérer l’image du conteneur auprès d’un dépôt si elle n’est pas localement disponible sur le nœud. La dernière interaction (5) est l’instanciation du ou des conteneurs. Jusqu’ici, pour simplifier la discussion, j’ai évité la notion de Pod. C’est le moment d’aborder le sujet.
3.2 Notion de Pod
Un Pod est une boite contenant un ou plusieurs conteneurs. En réalité, lorsqu’un utilisateur veut instancier quelque chose, il décrit son Pod avec le ou les conteneurs à l’intérieur. Une bonne pratique est de ne faire tourner qu’un seul programme dans un conteneur. Or dans la vraie vie, ce qu’on appelle une application peut impliquer plusieurs programmes, surtout dans des services types frontaux qui implémentent la séparation de privilèges dans une optique de sécurité. Prenons l’exemple de la figure 2, elle décrit une application type LAMP comprenant un serveur web et une base de données communiquant par un socket local.
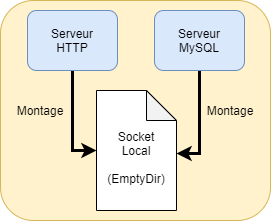
Nous avons donc une application incarnée par le Pod. Cette application est composée de deux programmes, donc deux conteneurs distincts si on suit la logique des bonnes pratiques. Ces deux conteneurs doivent communiquer par un socket local. L’atome ordonnancement de K8s est le Pod. C’est-à-dire que tous les conteneurs du Pod vont tourner sur le même nœud. La logique est donc de créer un Pod avec un volume partagé (de type EmptyDir [4]). À l’intérieur de ce Pod, il faut créer deux conteneurs qui vont monter ce volume partagé pour communiquer entre eux. Nous n’entrerons pas dans le détail de cette configuration, car il faut tenir le cap vers notre objectif. C’est juste un exemple pour hiérarchiser Pod et conteneurs.
4. Installation de K8s
Il existe énormément de façons d’installer une architecture K8s allant de l’instance locale de test type Minikube jusqu’à une mouture beaucoup plus enrichie type OpenShift. Les différentes méthodes sont une combinaison de choix faits pour vous et de modules optionnels préconfigurés. Pour l’article, j’ai retenu la méthode officielle supportée par K8s via Kubeadm. La première étape est donc d’installer l’installeur Kubeadm sur TOUS les nœuds de l’infrastructure.
4.1 Installation de Kubeadm
Kubeadm est une commande qui va installer la couche K8s sur l’infrastructure. Une fois cet outil installé, le rôle du nœud sera déterminé par les paramètres invoqués avec la commande kubeadm. Commençons par installer les dépendances de Kubeadm :
On ajoute la clé du dépôt apt de chez Google hébergeant le paquet Kubeadm :
On ajoute les coordonnées du dépôt dans le fichier /etc/apt/sources.list.d/kubernetes.list :
On installe les composants Kubelet (couche entre CRI-O et K8s), Kubeadm (outil d’installation / administration de la couche K8s) et Kubectl (la CLI de K8s) :
On fixe la version des paquets, ce qui empêchera qu'ils soient installés, mis à jour ou supprimés automatiquement :
Enfin, il faut créer un fichier contenant les paramètres par défaut utilisés au lancement du service Kubelet pour qu’il s’adresse correctement au service CRI-O. Il s’agit du paradigme de gestion des cgroups (systemd) et du socket local de communication (unix:///var/run/crio/crio.sock) mis à disposition par CRI-O pour recevoir des instructions.
La configuration commune est terminée. Passons à celle de l’API Server.
4.2 Configuration de l’API Server
L’API Server est le composant central de K8s. Nous nous connectons sur la machine api-server. La commande kubeadm prend un paramètre init qui installe tout ce qu’il faut pour que la machine prenne le rôle de « control plane » (cerveau) dans l’infrastructure. Dans la commande, il faut fixer la plage réseau utilisée par les Pods et l’emplacement du socket local de communication avec le moteur de conteneur. Examinons la sortie de la commande :
D’après les sorties, nous sommes en mesure de retracer le déroulement de l’installation. Kubeadm commence par récupérer les images des conteneurs qui composent le control-plane à savoir l’api-server, le controller-manager et le scheduler (ordonnanceur) ainsi le service DNS (CoreDNS) et Proxy (kube-proxy). La ligne mark-control-plane est intéressante, elle indique qu’aucun Pod ne sera ordonnancé sur le control-plane. Enfin, nous avons la commande à entrer sur les nœuds pour les lier au control-plane.
Regardons les Pods en exécution sur le nœud api-server avec la commande crictl qui interroge directement le moteur de conteneurs :
Configurons l’utilitaire kubectl pour l’utilisateur nico :
Nous allons passer sur le compte nico pour les manipulations. Commençons par afficher les nœuds disponibles :
Installons le module réseau Calico pour gérer les communications entre les Pods, mais aussi des Pods vers l’extérieur. Pour étendre les fonctionnalités d’un cluster K8s, il suffit d’appliquer un fichier manifest via la commande kubectl :
Si on liste les Pods en exécution sur la machine api-server, on voit que deux nouveaux protagonistes sont arrivés :
Ce sont les Pods nécessaires au bon fonctionnement de Calico. Ils vont gérer la couche de virtualisation du réseau en utilisant la plage que nous avons passée au moment du kubeadm init.
4.3 Configuration des nœuds
Sur les nœuds, nous devons donc utiliser Kubeadm avec l’argument join. Je prends la commande indiquée à la fin de l’instanciation du control-plane et je la lance sur le node1 :
L’association entre le nœud et le control-plane est réussie. On devine d’après les sorties qu’une PKI assez complexe est à l’œuvre pour authentifier les nœuds par rapport au control-plane et chiffrer les échanges. On réitère le même processus pour la machine node2. Enfin, on peut visionner notre cluster K8s de test :
5. Lancement du premier Pod
Notre infrastructure est maintenant fonctionnelle, nous pouvons lancer notre premier Pod dessus. L’idée est de créer un fichier décrivant le Pod à lancer. Nous allons créer un Pod très simple contenant un seul conteneur basé sur Debian 10. Ce fichier, que nous nommerons debian.yml, est au format YAML :
La première ligne fixe la version de l’API utilisée pour parler au controler-plane. En effet, le composant api-server est, comme son nom l’indique, un serveur d’API permettant de requêter le service K8s. Il convient donc de préciser la version des échanges. La deuxième ligne est le kind de l’objet à créer, ici il s’agit d’un Pod. Ensuite, nous avons les metadata avec comme attribut le nom du Pod (Metadata / Name) et enfin la spécification du conteneur.
La première chose à fixer est l’image. Ici, il s’agit d’une Debian 10. Une fois la demande de création du Pod partie, il est de la responsabilité du moteur de conteneur (CRI-O) d’aller chercher l’image (cf. section 2, configuration du dépôt docker.io). Ensuite, cette image doit avoir un nom qui fait sens à l’intérieur du Pod. La combinaison des attributs command et args indique la commande exécutée dans le conteneur. Si la commande s’avère être un service type Nginx, la bonne pratique est de l’exécuter en avant plan et surtout de n’exécuter qu’un seul service par conteneur. Si on veut monter un LAMP, il est tout à fait possible de créer un Pod avec deux conteneurs, un pour Apache / PHP et l’autre pour MySQL comme discuté dans la section relative aux Pods (section 3). Dans notre exemple, le conteneur lance un shell qui exécute une boucle infinie. Nous nous y connecterons pour illustrer l’utilisation des Pods. La dernière section active la capacité NET_RAW. L’activation de cette capacité est nécessaire pour créer un objet raw socket afin de permettre à la commande ping d’envoyer des paquets ICMP. Créons notre Pod :
Si on liste directement les Pods disponibles, on voit que le nôtre n’est pas instancié de suite. En effet, il faut laisser au moteur de conteneurs le temps de récupérer l’image :
Revenons quelques secondes plus tard :
Nous allons lancer un shell bash à l’intérieur du conteneur :
La commande exec de kubectl va lancer la commande /bin/bash. La combinaison des arguments -t et -i lie l’entrée standard (notre clavier) à la commande. Le résultat est bien un shell bash s’exécutant dans le conteneur. Testons une commande dedans :
Notre conteneur fonctionne ! Nous pouvons l’arrêter :
Toutes les données générées par le Pod sont perdues à moins d’avoir attaché un volume. La gestion des volumes est hors du scope de cet article.
6. Communication avec les Pods
Lançons un Pod Nginx. À l’instar de notre Pod Debian, il faut créer un fichier manifest nginx.yml :
Affichons les IP de nos différents Pods à l’intérieur de notre infrastructure K8s :
L’IP de notre serveur Nginx est la 192.168.104.3. Nous allons tenter un curl depuis le Pod debian vers le pod pod-nginx :
Installons curl dans le Pod debian :
Nos Pods communiquent donc bien l’un avec l’autre. Cependant, le service est inaccessible depuis l’extérieur. Nous pouvons exposer des ports de conteneurs vers l’extérieur avec la commande port-forward. Cette commande est souvent utilisée pour déboguer l’accès à un service :
Cette commande reste en avant-plan. Elle effectue une redirection du port 8080 de l’interface de rebouclage 127.0.0.1 vers le port 80 de notre Pod Nginx. Essayons :
Si on revient sur la première console où on a lancé la redirection, une nouvelle ligne s’est affichée :
Tant qu’on parle de déboguer, une autre possibilité intéressante est d’afficher les logs du programme localisé dans le conteneur. Ouvrons un troisième terminal pour afficher les logs du conteneur Nginx. Il s’agit de la commande logs de kubectl (le -f pour s’attacher à la sortie et afficher les logs quand ils arrivent). Si on relance un curl, on voit bien qu’une ligne est produite :
Conclusion
Nous avons mis en place un cluster K8s reposant sur le moteur de conteneurs CRI-O. Nous avons également lancé des Pods basiques pour valider le fonctionnement système et réseau et donné quelques commandes pour aider au débogage. C’est une base solide pour vous lancer dans l’expérimentation d’une infrastructure K8s. Je conseille au lecteur souhaitant approfondir le sujet de se référer au dossier très complet présenté dans le hors-série n°98 de GNU/Linux Magazine consacré à l’orchestration de conteneurs [2].
Références
[2] Comprenez enfin tout sur … Les conteneurs ! GNU/Linux Magazine Hors-série n°98 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMFHS-098
[3] https://github.com/projectcalico/calico/issues/2322
[4] https://kubernetes.io/fr/docs/concepts/storage/volumes/#emptydir



