

Après les premiers pas dans le monde des namespaces à travers l’étude des appels système et des utilitaires qui les mettent en œuvre en espace utilisateur, ce nouvel opus se consacre à leur implémentation dans le noyau.
Lire le code du noyau [1] et l’exposer sous forme d’article est un exercice délicat, car c’est susceptible d’ennuyer le lecteur. Ce n’est pas une étape nécessaire à la compréhension et à l’utilisation des namespaces. Mais c’est indéniablement un plus de connaître les rouages de la partie immergée dans le noyau. Cet opus se concentre sur les structures de données associées aux namespaces dans le code source du noyau Linux 5.3.0.
Le code de cet article est disponible sur http://www.rkoucha.fr/tech_corner/linux_namespaces/linux_namespaces.tgz.
1. Le descripteur de processus
En espace utilisateur, on parle communément de processus et de threads pour désigner les unités d’exécution. Un processus est même plus précisément vu comme un ensemble de threads : le thread principal et les threads secondaires. Dans le noyau, ce sont simplement des tâches. La tâche « thread group leader » représente le thread principal et les autres tâches représentent les threads secondaires.
À toute tâche est associé un descripteur (structure task_struct) au sein duquel se trouvent toutes les informations nécessaires à son suivi et fonctionnement. Il est déclaré dans le fichier include/linux/sched.h :
À l’image du pointeur this du langage C++ qui pointe sur l’objet courant, le pointeur current référence toujours le descripteur de la tâche en cours d’exécution. Il est largement utilisé dans le noyau pour accéder aux informations de la tâche courante.
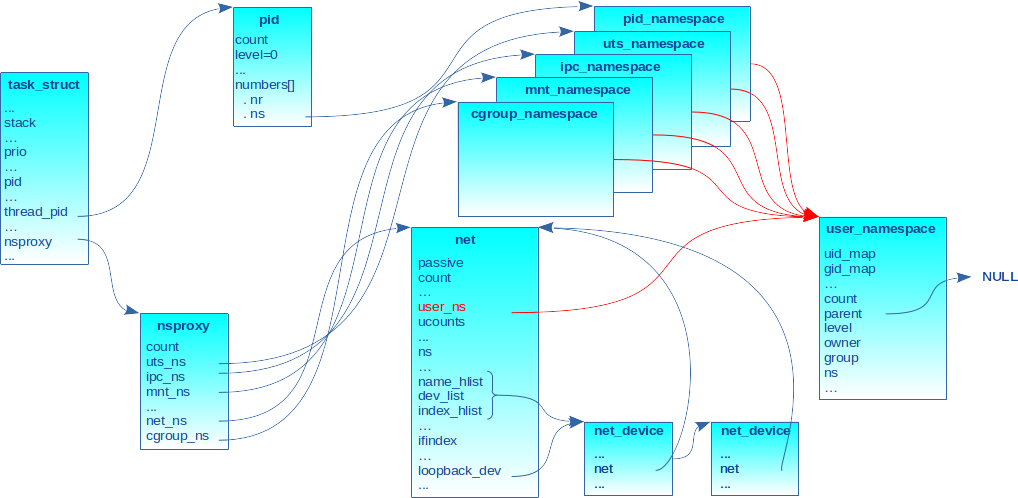
Parmi les nombreux champs comme la pile, les identifiants, la priorité, le nom du programme ou l’affinité CPU, pour n’en citer que quelques-uns, se trouve un pointeur sur la structure nsproxy.
2. Les namespaces d’un processus
2.1 Le nsproxy
La structure nsproxy contient un ensemble de pointeurs référençant les namespaces auxquels la tâche est associée. Elle est déclarée dans le fichier include/linux/nsproxy.h :
On notera tout d’abord l’utilisation du principe des compteurs de références (champ nommé count ou kref) dans les structures de données afin de provoquer la libération implicite de ces structures à partir du moment où elles ne sont plus utiles (c.-à-d. quand le compteur atteint la valeur 0). C’est l’un des modèles de conception de Linux [2]. L’allocation dynamique (sauf pour certains namespaces initiaux qui ne sont jamais désalloués) utilise l’allocateur SLAB [3] dédié aux objets de taille fixe.
Les champs uts_ns, ipc_ns, mnt_ns, net_ns et cgroup_ns pointent respectivement sur les descripteurs des namespaces UTS, IPC, mount, network et cgroup comme schématisés en figure 1.
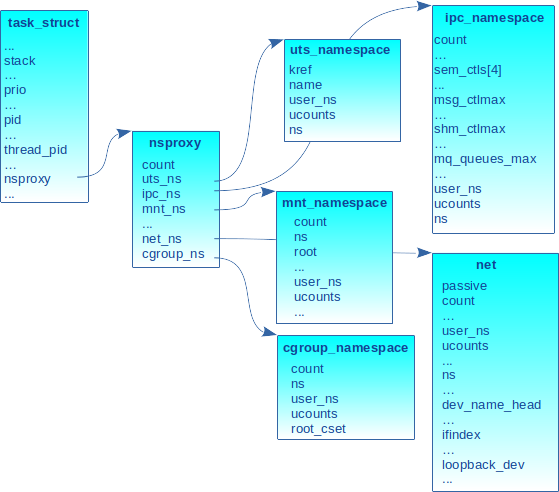
2.2 Les namespaces hiérarchiques
Le user_ns et le pid_ns ne sont pas référencés directement par la structure nsproxy. Ils sont gérés différemment notamment à cause :
- de leur aspect hiérarchique (un user_ns ou un pid_ns est le fils du user_ns ou du pid_ns associé à la tâche qui l’a créé) ;
- du fait que tout namespace est la propriété du user_ns associé à la tâche qui l’a créé ;
- du fait qu’une tâche à un identifiant (c.-à-d. PID) différent dans chaque pid_ns et par conséquent la structure task_struct doit permettre d’accéder à tous ces identifiants et aux pid_ns associés ;
- du fait qu’une tâche pouvant changer de user_ns peut acquérir de nouveaux droits.
L’aspect hiérarchique est caractérisé par deux champs dans la structure décrivant le namespace :
- parent : pointeur sur la structure du namespace père. Quand ce champ est NULL, cela indique le sommet de la hiérarchie donc un user_ns ou un pid_ns initial (c.-à-d. les namespaces créés au démarrage du système encore appelé « système hôte » quand on est dans un environnement de conteneurs) ;
- level : entier désignant le niveau dans la hiérarchie. Le premier niveau est 0 (la racine ou niveau initial). La valeur augmente séquentiellement pour chaque nouveau namespace fils.
La figure 2 donne un exemple d’une hiérarchie de trois niveaux de user_ns. Ils sont liés par le pointeur parent et chaque niveau est marqué par le champ level.
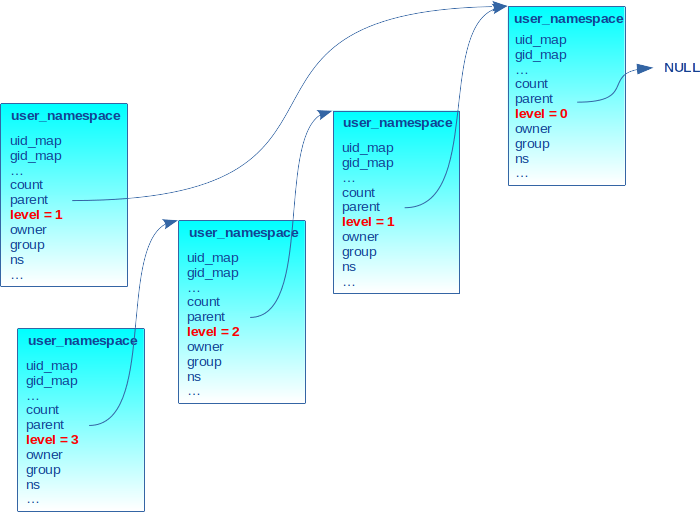
2.3 Le user_ns propriétaire
Toute structure décrivant un namespace possède un champ nommé user_ns qui pointe sur le descripteur du user_ns propriétaire, comme indiqué sur la figure 3 avec les flèches rouges. On aurait pu complexifier le dessin en mettant un user_ns différent pour certains namespaces, mais le cas le plus courant dans la pratique est qu’une tâche a le même user_ns pour tous ses namespaces.
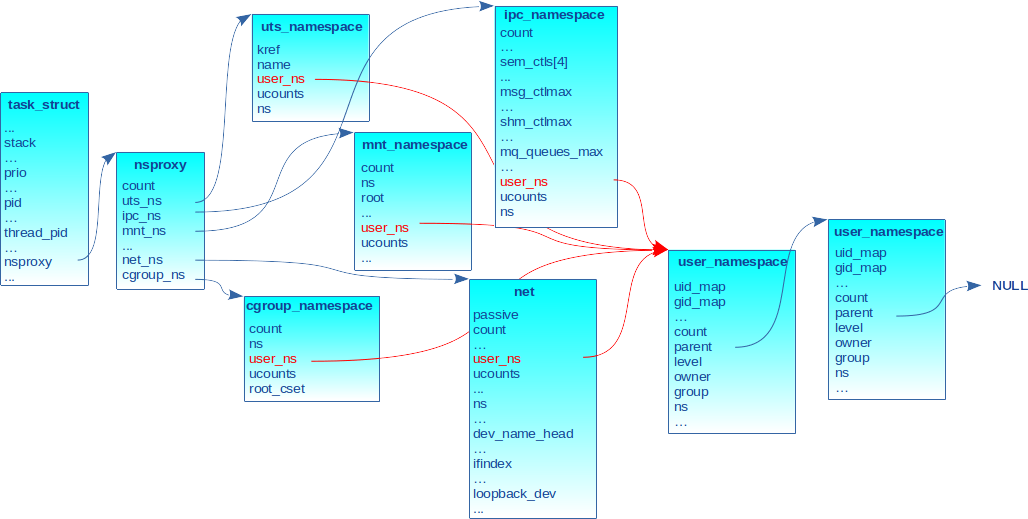
2.4 Gestion des identifiants de processus
Pour les pid_ns, une structure intermédiaire nommée pid a été mise en place pour refléter l’identifiant de processus dans tous les namespaces de la hiérarchie [4]. Elle est déclarée dans include/linux/pid.h :
Le champ level est le niveau du processus dans la hiérarchie des pid_ns. Il fonctionne de la même manière que le même champ dans les descripteurs des pid_ns et user_ns vus plus haut (figure 2). Ce champ est l’indice maximum dans la table numbers[] dont les entrées sont décrites par la structure upid. Chaque entrée de cette table associe un identifiant au processus (champ nr) dans le pid_ns de niveau level de la hiérarchie (référencé par le champ ns).
La structure pid est allouée par la fonction interne alloc_pid() définie dans kernel/pid.c. Appelée lors de la création d’un processus fils (p. ex., clone()), son résultat est assigné au champ thread_pid du descripteur de tâche. La figure 4 illustre le propos en représentant le cas d’un processus créé dans un pid_ns de troisième niveau (c.-à-d. level 2).
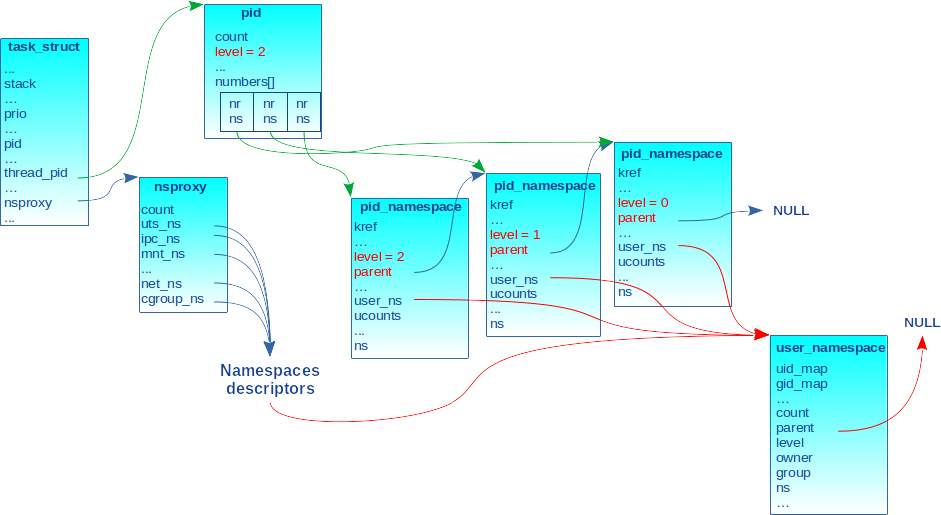
L’identifiant de processus (champ nr) dans chaque pid_ns est alloué via le mécanisme IDR du noyau [5] afin d’associer le pointeur sur le pid_ns avec l’identifiant de processus dans ce namespace. Cela permet à partir d’un identifiant de processus de retrouver le pointeur sur le descripteur de son pid_ns courant et inversement. Ainsi, la fonction alloc_pid() appelle idr_alloc_cyclic() avec le champ idr du pid_ns pour allouer un identifiant séquentiel unique à partir de la valeur 1 afin de renseigner le champ nr de chaque entrée dans la table number[]. Si le pid_ns est nouveau (c.-à-d. drapeau CLONE_NEWPID passé à clone()), la valeur de nr sera 1 (l’identifiant du processus init).
2.5 Allocation des namespaces
Lorsque les tâches sont associées aux mêmes namespaces, elles pointent toutes sur la même structure nsproxy comme indiqué en figure 5 (le pointeur est hérité de père en fils). Le champ count reflète bien entendu chaque référence.
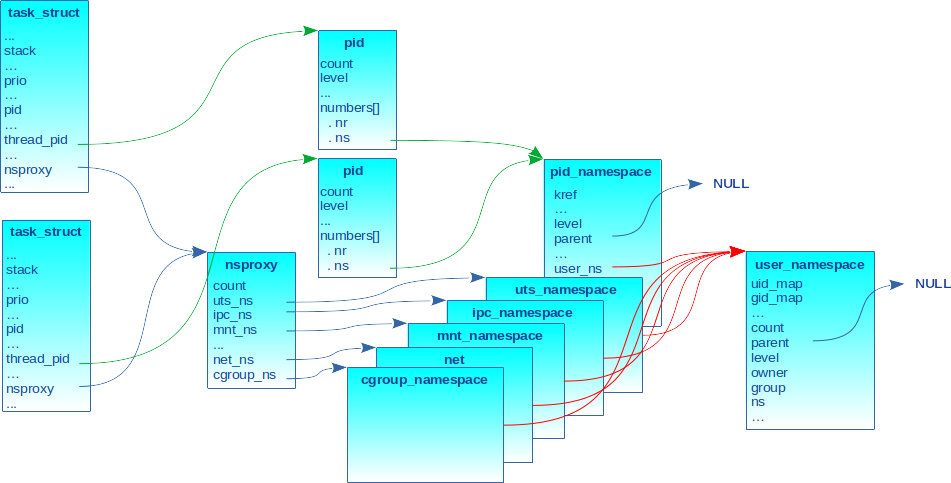
Si au moins un des namespaces diffère, une nouvelle structure nsproxy est allouée comme indiqué en figure 6, où l’uts_ns diffère entre les deux tâches.
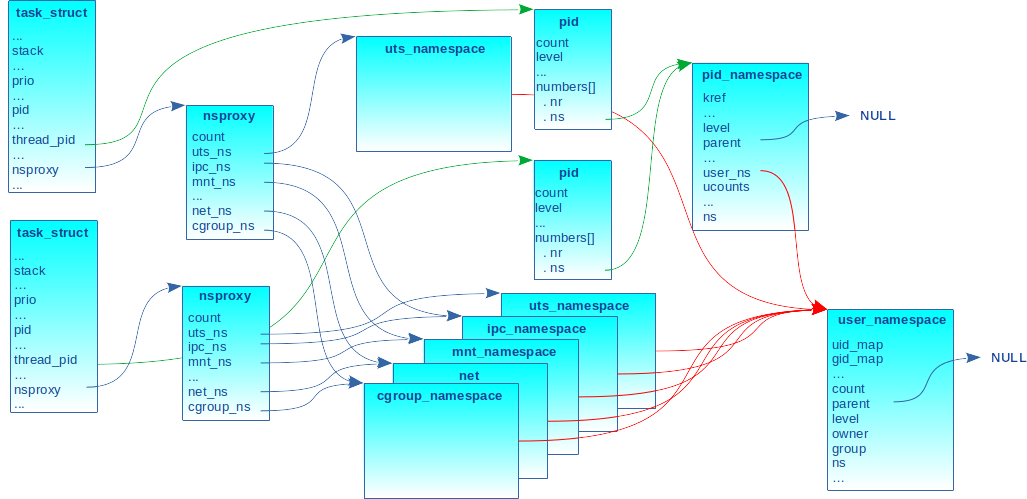
C’est la fonction copy_namespaces() dans kernel/nsproxy.c, appelée par clone() lorsqu’une tâche crée un fils, qui décide ou pas de l’allocation d’un nouveau nsproxy :
Si la condition indiquant qu’aucun drapeau CLONE_NEWXXX n’est passé, elle incrémente, via get_nsproxy(), le compteur de référence sur le nsproxy du processus père signifiant ainsi que le processus fils est associé aux mêmes namespaces que son père.
Par contre, si au moins un des drapeaux est passé pour créer au moins un nouveau namespace, une nouvelle structure nsproxy est allouée en appelant create_new_namespaces().
Les pointeurs sur les namespaces de la structure nsproxy nouvellement allouée sont soit une copie du même pointeur dans le nsproxy du père (c.-à-d. le drapeau CLONE_NEWXXX associé n’a pas été passé), soit mis à jour pour référencer le namespace nouvellement alloué (c.-à-d. le drapeau CLONE_NEWXXX associé a été passé). On verra par la suite que dans ce dernier cas, l’opération « copy » des namespaces est appelée pour faire hériter aux namespaces du processus fils les informations des namespaces du processus père.
Pour en revenir à la figure 6, elle illustre un processus père qui a créé un processus fils en l’associant à un nouvel uts_ns (c.-à-d. appel à clone() avec le drapeau CLONE_NEWUTS). Le processus engendré pointe sur une nouvelle structure pid. La structure pid pointe sur pid_ns du processus père, mais son champ nr reflète le nouveau PID du processus nouvellement créé. Ce dernier a aussi un nouveau nsproxy dont un pointeur référence le descripteur du nouvel uts_ns tandis que les autres sont des copies de ceux du processus père, car les autres namespaces sont partagés.
2.6 Accréditations des tâches
Les accréditations (c.-à-d. « credentials » en anglais) sont sous la forme d’une structure cred définie dans include/cred.h. Elle contient toutes les informations d’identification (identifiants réels et effectifs d’utilisateur, identifiants réels et effectifs de groupe, les capacités...) et notamment un pointeur sur le descripteur de user_ns auquel elle s’applique :
Cette structure est référencée par le champ cred du descripteur de tâche task_struct. La figure 7 illustre un processus associé à ses namespaces. Ils ont tous été créés dans le même user_ns. Le champ cred du descripteur de tâche pointe sur ce même user_ns.
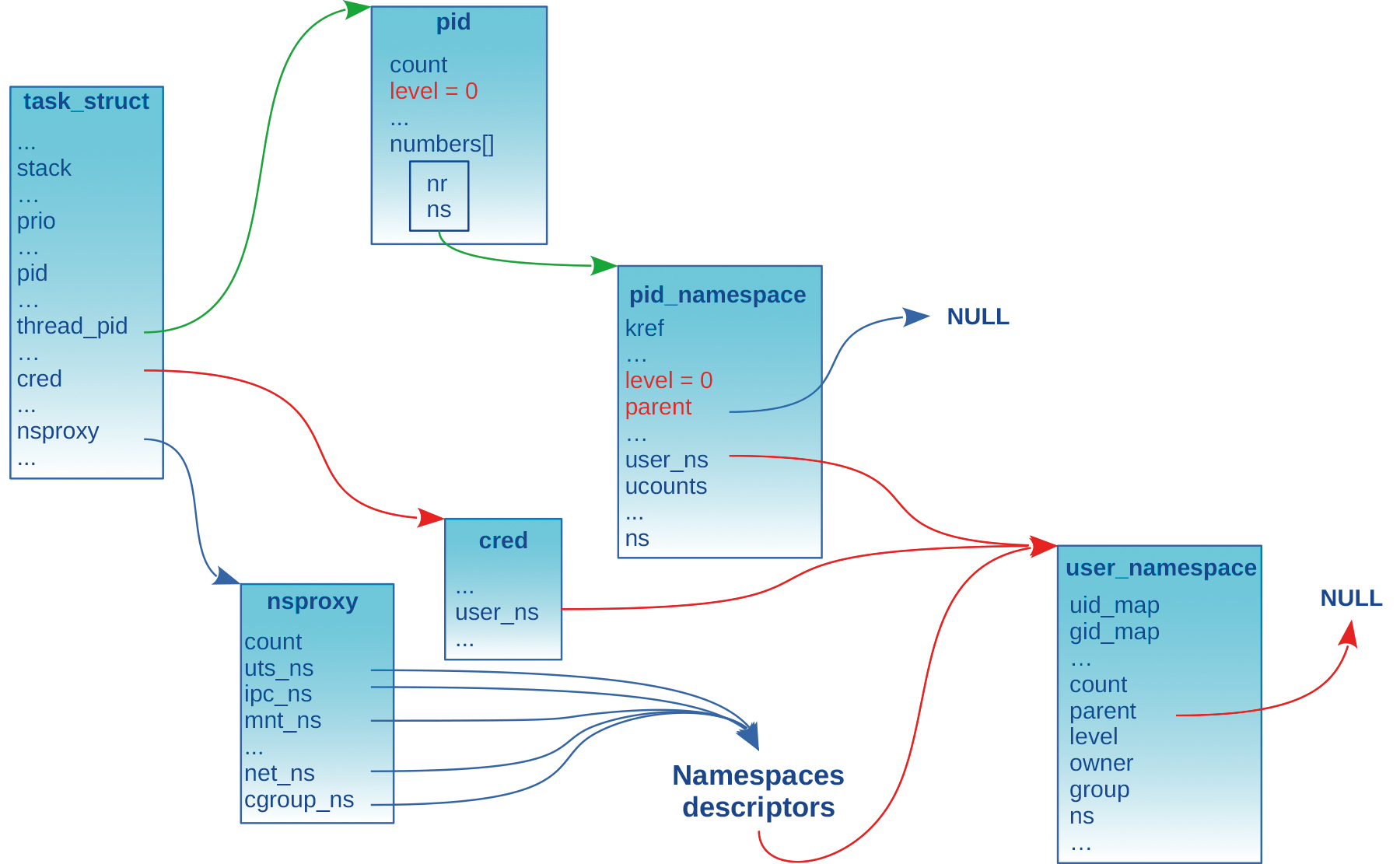
Nous reviendrons sur ces aspects dans un article dédié aux user_ns, mais on peut d’ores et déjà retenir qu’un processus peut changer de user_ns (via l’appel système setns()). Dans ces conditions, le pointeur cred du descripteur de tâche est mis à jour pour pointer sur une structure cred nouvellement allouée et renseignée avec les nouvelles accréditations et le pointeur sur le descripteur du user_ns cible.
3. Les descripteurs de namespaces
3.1 Les informations communes
Dans tous les descripteurs de namespaces, il y a un champ nommé ns de type struct ns_common. C’est un ensemble de données et d’opérations communes à tous les namespaces. Cette structure est définie dans include/linux/ns_common.h :
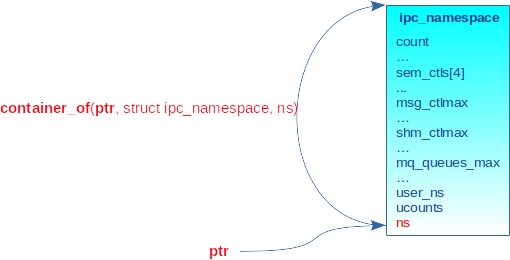
À partir d’un pointeur sur ce champ, il est possible de retrouver l’adresse de départ du descripteur de namespace englobant avec la macro container_of(ptr, type, member) définie dans include/linux/kernel.h et basée sur la macro offsetof(type, member) de la librairie C. Pour chaque type de namespace, il existe un service nommé to_<namespace_type>() utilisant container_of() afin de retrouver l’adresse de début du descripteur. Par exemple, un descripteur d’ipc_ns est retrouvé comme suit :
La figure 8 schématise l’opération.
Le champ inum est le numéro d’inode unique global au système attribué à la création du namespace. C’est la valeur affichée dans les liens symboliques lorsqu’on liste le répertoire /proc/<pid>/ns :
Hormis certains namespaces initiaux pour lesquels la valeur est fixée (on le verra par la suite), inum est positionné avec le résultat de la fonction proc_alloc_inum() définie dans fs/proc/generic.c qui retourne une valeur entre PROC_DYNAMIC_FIRST (0xf0000000) et 0xffffffff (mécanisme IDA du noyau [5]). Avec le champ stashed, il permet de manipuler les namespaces à travers le système de fichiers NSFS que nous reverrons dans le prochain article.
Le type du champ ops est défini dans include/linux/proc_ns.h :
Les champs ont la signification suivante :
- name est le nom du namespace (utilisé pour le nommage dans le répertoire /proc/<pid>/ns) ;
- real_ns_name est le nom du namespace pour le namespace transitoire « pid_for_children » utilisé lors de la création des pid_ns ;
- type est le drapeau CLONE_NEWXXX associé au namespace (p. ex. CLONE_NEWUTS). Il est utilisé par l’ioctl NS_GET_NSTYPE ;
- get() incrémente le compteur de références sur le namespace. Opération préalable pour utiliser le namespace ;
- put() décrémente le compteur de références. Opération exécutée après utilisation du namespace. Si le compteur atteint la valeur 0, le namespace est désalloué ;
- install() est déclenché lors de l’appel système setns() ;
- owner() retourne le user_ns propriétaire de ce namespace. Il est utilisé par l’ioctl NS_GET_USERNS ;
- get_parent() retourne le namespace parent. Il ne concerne que les namespaces hiérarchiques user_ns et pid_ns. Il est utilisé par l’ioctl NS_GET_PARENT.
Parmi les informations communes, nous verrons aussi que les descripteurs de namespaces ont tous un champ nommé ucounts. Il permet de compter les nombres de namespaces actifs afin d’en limiter le nombre aux valeurs maximales [6] exportées dans les fichiers sous /proc/sys/user (cf. man 7 namespaces) :
3.2 Virtualisation de procfs
Le système de fichiers procfs (monté sur /proc) permet de consulter, voire de modifier des informations dans le noyau. Certaines de ces informations sont globales et par conséquent restent inchangées, peu importe les namespaces à partir desquels nous les consultons. Par contre, d’autres informations sont stockées ou liées aux descripteurs de namespaces. Dans ce cas, les valeurs exportées dépendent des namespaces à partir desquels nous les consultons. On parle alors de fichiers ou répertoires virtualisés.
3.3 Sécurisation des structures
La plupart des structures de données présentées sont étiquetées avec la macro __randomize_layout. C’est une extension sous forme de greffon ajoutée au compilateur GCC dans la chaîne de compilation du noyau Linux pour réordonner les champs des structures de manière aléatoire pendant la compilation. Cela aide à contrer les attaques pirates qui se basent sur la connaissance de l'ordre des champs dans les structures [11]. Cela permet de définir un nouvel attribut nommé randomize_layout que le noyau encapsule avec cette macro dans le fichier include/linux/compiler-gcc.h :
3.4 Le user_ns
Introduit dans Linux 2.6.23 et complété dans Linux 3.8 [7], ce namespace est décrit par la structure user_namespace définie dans le fichier d’en-tête include/linux/user_namespace.h :
Les champs uid_map et gid_map définissent les mappings utilisateur. Ils sont respectivement exposés en espace utilisateur via les fichiers /proc/<pid>/uid_map et /proc/<pid>/gid_map. De même, le champ flags permet de gérer l’autorisation d’appel à setgroups() via le fichier /proc/<pid>/setgroups utilisé lors du mapping des identifiants d’utilisateurs et groupes. Ce sera détaillé dans un article consacré au user_ns.
Ce namespace étant hiérarchique, il y a les champs parent et level comme indiqué précédemment.
Les champs owner et group sont respectivement les identifiants effectifs d’utilisateur et de groupe de la tâche à l’origine de la création de ce user_ns.
Les champs ucount_max[] gèrent le comptage du nombre de namespaces par types (une entrée pour chacun) pour ce user_ns [6].
3.5 Le pid_ns
Introduit dans Linux 2.6.24 [7], ce namespace est décrit par la structure pid_namespace définie dans le fichier d’en-tête include/linux/pid_namespace.h :
Comme le user_ns, c’est un namespace hiérarchique (d’où les champs parent et level). On notera cependant que le nombre maximum de niveaux est limité pour les pid_ns. Il est défini avec la constante interne MAX_PID_NS_LEVEL (égale à 32 dans kernel/pid_namespace.c). Cette valeur permet de limiter la taille du tableau numbers[] dans la structure pid vue plus haut.
Le champ pid_cachep est le cache dans lequel sont allouées les structures pid des tâches associées à ce namespace. L’initialisation du cache définit une taille de structure par rapport au niveau du pid_ns (champ level). Ceci afin de dimensionner au plus juste le nombre d’entrées upid dans son champ numbers[]. La formule utilisée est :
Le champ idr permet d’allouer les identifiants de processus de manière séquentielle dans le pid_ns à l’aide du mécanisme IDR vu plus haut.
Le champ pid_allocated est le nombre courant de tâches dans le namespace.
Le champ child_reaper pointe sur le descripteur de processus (c.-à-d. processus init) qui joue le rôle de faucheur des processus orphelins. C’est le premier processus créé dans le namespace.
Le champ user_ns pointe sur le descripteur du user_ns propriétaire, c’est-à-dire le user_ns associé au processus qui a créé ce namespace.
Le champ hide_pid correspond à l’option hidepid de montage du système de fichiers /proc et peut prendre les valeurs suivantes : HIDEPID_OFF (0), HIDEPID_NO_ACCESS (1) et HIDEPID_INVISIBLE (2). La documentation du noyau [8] décrit la fonction de chacune de ces valeurs.
Le champ reboot est positionné avec l’identifiant du signal SIGHUP ou SIGINT en fonction des paramètres passés à l’appel système reboot(). Des détails supplémentaires seront donnés dans l’article relatif aux pid_ns.
3.6 Le net_ns
Introduit dans Linux 2.6.24 et complété dans Linux 2.6.29 [7], ce namespace est décrit par la structure net définie dans include/net/net_namespace.h :
Le champ list est un lien dans une liste globale de net_ns. Cela sert à l’algorithmique interne pendant les phases de désallocation des namespaces.
Les champs proc_net ainsi que proc_net_stat concernent les fichiers dans les répertoires /proc/net ainsi que les fichiers de statistiques dans /proc/net/stat (cf. man 5 proc).
Les interfaces assignées au namespace sont chaînées dans différentes listes référencées par les champs dev_base_head, dev_name_head et dev_index_head. Elles permettent de retrouver une interface par son nom ou son index.
Le champ ifindex est le dernier index attribué aux interfaces installées dans ce net_ns. Sa valeur commence à 1 et est réservée à l’interface loopback. Les index ne sont pas forcément séquentiels, car lorsqu’une interface migre dans un namespace, elle ne change son index que s’il est déjà attribué dans le net_ns cible. De même, si une interface quitte le namespace, les interfaces restantes ne sont pas renumérotées.
Le champ loopback_dev pointe sur l’interface loopback. Comme on l’a dit précédemment, tout net_ns a une interface loopback dédiée.
Les structures suivantes nommées netns_XXX sont toutes les fonctions réseau virtualisées (table de routage, filtres pare-feu...).
La structure net_device, décrivant un périphérique réseau et définie dans include/linux/netdevice.h, contient un champ nommé nd_net de type possible_net_t pour référencer le net_ns auquel appartient le périphérique :
À l’initialisation, le driver d’interface réseau alloue (via le service alloc_netdev_mqs() ou équivalent) et initialise une structure net_device [9]. Cette dernière est chaînée dans les listes du namespace associé avec les champs name_hlist, dev_list et index_hlist.
La structure possible_net_t définie dans include/net/net_namespace.h est une coquille au-dessus d’un pointeur sur la structure net décrivant le namespace :
La figure 9 représente une tâche associée à ses namespaces avec une vue simplifiée de deux interfaces réseau attachées à son net_ns. Le premier descripteur net_device de la liste correspond bien entendu à l’interface loopback.
Précisons, comme nous l’avons mentionné dans un précédent article, que ce qui détermine la possibilité pour une interface réseau de migrer ou pas dans un autre namespace est la présence du drapeau NETIF_F_NETNS_LOCAL positionné dans le champ features de la structure net_device dans la fonction d’initialisation du driver. Par exemple, l’interface loopback s’initialise comme suit dans drivers/net/loopback.c, car elle ne peut pas migrer :
Sur demande de migration d’une interface réseau, la fonction suivante est appelée dans net/core/dev.c. Elle sort en erreur si le drapeau est positionné :
Le livre [10] donne plus de détails sur le sujet.
3.7 L’uts_ns
Introduit dans Linux 2.6.19 [7], ce namespace est décrit par la structure uts_namespace définie dans include/linux/utsname.h :
Le champ name est une structure new_utsname définie dans include/uapi/linux/utsname.h :
Ce namespace est le plus simple de tous. Le nom de nœud et le nom de domaine sont respectivement les champs nodename et domainname de la structure utsname renseignée par l’appel système uname(). Ces informations peuvent être modifiées par les services sethostname() et setdomainname().
3.8 L’ipc_ns
Introduit dans Linux 2.6.19 [7] pour les IPC système V, il a été complété avec les queues de messages POSIX dans la version 2.6.30. Ce namespace est décrit par la structure ipc_namespace définie dans include/linux/ipc_namespace.h :
Le champ ids[] a trois entrées pour mémoriser les identifiants d’IPC système V des trois types possibles :
Comme les identifiants de tâches vus plus haut, ils sont alloués par le mécanisme IDR.
Les noms des champs qui suivent mettent en exergue quatre parties : la première dédiée aux sémaphores (sem_ctls[] et used_sems), la seconde dédiée aux queues de messages (msg_ctlmax à msg_hdrs), la troisième dédiée aux segments de mémoire partagée (shm_ctlmax à shm_ctlmni) et la dernière dédiée aux queues de messages POSIX (mq_mnt à mq_msgsize_default). Ces valeurs sont pour la plupart exportées dans les répertoires /proc/sys/kernel, /proc/sysvipc et /proc/sys/fs/mqueue (cf. man 7 namespaces).
Le champ mq_mnt est une référence sur le système de fichiers mqueuefs normalement monté sur /dev/mqueue en espace utilisateur. C’est l’endroit où sont créés les fichiers associés aux queues de messages POSIX.
Dans l’article dédié à l’ipc_ns, nous expliquerons la raison pour laquelle ce namespace ne concerne pas les sémaphores et segments de mémoire partagée POSIX.
3.9 Le mount_ns
Introduit dans la version 2.4.19 [7], c’est le premier namespace de Linux. Il est décrit par la structure mnt_namespace définie dans fs/mount.h :
3.10 Le cgroup_ns
Introduit dans Linux 4.6 [7], c’est le dernier né des namespaces dans Linux, même si nous verrons par la suite que de nouveaux namespaces sont en préparation ou en cours de discussion. Il est décrit par la structure cgroup_namespace définie dans include/linux/cgroup.h :
Le champ root_cset référence les états des sous-systèmes (Cgroup Subsystem State) et donne aux tâches associées au namespace une vue spécifique de la hiérarchie. Dans un contexte de conteneurs, cela sert à limiter la vue sur une partie de l’arborescence globale des cgroups (cf. Documentation/cgroups/namespace.txt).
4. Les namespaces initiaux
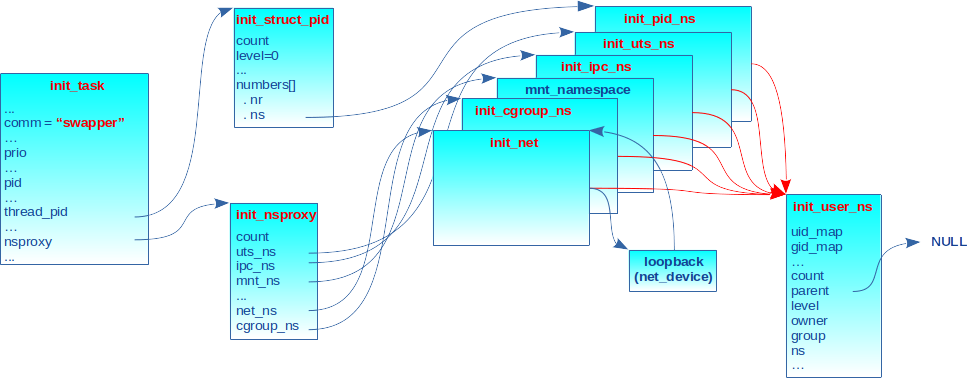
Au démarrage, les processus sont associés aux namespaces initiaux. Ils constituent le système hôte dans un environnement de conteneurs. Certains sont définis et initialisés de manière statique tandis que les autres le sont de manière dynamique.
Les namespaces initiaux ne devant jamais être désalloués, leur champ « compteur de références » (count ou kref) est initialisé à une valeur supérieure ou égale à 1.
Citons le user_ns initial en premier, car il est référencé en tant que propriétaire de tous les autres namespaces initiaux via leur champ user_ns. Il est défini de manière statique dans kernel/user.c :
Tout champ n’apparaissant pas dans l’initialisation statique est par défaut initialisé à 0. Le champ parent n’apparaissant pas, il est donc initialisé à 0 (c.-à-d. NULL) pour indiquer qu’on est au sommet (racine) de la hiérarchie des user_ns.
Le mount_ns initial est créé dynamiquement à l’initialisation du système (étiquette __init) via l’appel à la fonction init_mount_tree() dans le fichier fs/namespace.c :
L’appel à la fonction get_mnt_ns() permet d’incrémenter le compteur de références du namespace de sorte à le rendre persistant (c.-à-d. non désallouable).
Les autres namespaces initiaux sont créés de manière statique.
Le cgroup_ns initial est défini dans kernel/cgroup/cgroup.c :
L’ipc_ns initial est défini dans ipc/msgutil.c :
Le net_ns initial est défini dans net/core/net_namespace.c :
L’initialisation est complétée par des fonctions étiquetées __init et appelées lors du démarrage du système (cf. include/linux/init.h) pour, par exemple, enregistrer l’interface loopback de sorte qu’elle soit la première dans le net_ns initial.
L’uts_ns initial est défini dans init/version.c :
Le pid_ns initial est défini dans kernel/pid.c :
Comme pour le user_ns, le champ parent (n’apparaissant pas) est à 0 pour indiquer qu’on est au sommet de la hiérarchie.
Le lecteur perspicace notera que le champ nr de init_struct_pid est initialisé à 0 alors que nous avons dit plus haut que l’allocation des valeurs pour ce champ utilise le mécanisme IDR avec une plage qui commence à 1. Cela reste tout de même cohérent, car le second processus créé provoquera l’appel de la fonction alloc_pid() qui obtiendra le premier identifiant non utilisé dans la plage, autrement dit la valeur 1. La particularité ici est que seul le pid_ns initial a une première tâche d’identifiant 0 et la seconde d’identifiant 1. Les pid_ns descendants ont l’identifiant 1 pour la première tâche.
Les numéros d’inode des namespaces initiaux sont prédéfinis dans include/linux/proc_ns.h :
Cette énumération ne contient pas de numéros pour le net_ns et le mount_ns. Leurs inodes sont alloués dynamiquement au démarrage du système. La connaissance de ces valeurs permet de savoir si un processus est associé aux namespaces initiaux lorsqu’on liste le répertoire /proc/<pid>/ns. C’est une astuce qui n’a rien d’officiel ! Nous listons ci-dessous les numéros d’inodes des namespaces du processus init (PID 1) et vérifions que les valeurs affichées sont égales au contenu de l’énumération, vu que ce processus est associé aux namespaces initiaux :
La structure nsproxy référençant les namespaces initiaux est définie dans kernel/nsproxy.c :
Le champ mnt_ns est initialisé à NULL, mais nous avons vu plus haut que la fonction d’initialisation du mount_ns initial positionne ce champ avec l’adresse de la structure du namespace allouée dynamiquement :
Le descripteur de la première tâche du système est init_task. Elle est appelée swapper. Elle est définie dans init/init_task.c. Son champ nsproxy pointe évidemment sur init_nsproxy :
La figure 10 illustre les namespaces initiaux au démarrage du système.
Conclusion
Cet article est indéniablement sorti des sentiers battus en prenant le risque d’une plongée dans les sources du noyau de Linux. Nous avons tenté de ne pas être trop rébarbatifs dans cette présentation des structures de données. C’est une étape préalable qui nous est apparue nécessaire afin d’expliquer le fonctionnement interne des appels système dans le prochain article.
Références
[1] Premier post de L. TORVALDS sur Usenet : http://opendotdotdot.blogspot.com/2006/03/linus-torvalds-first-usenet-posting.html
[2] Linux kernel design patterns : https://lwn.net/Articles/336224/
[3] Slab allocation : https://en.wikipedia.org/wiki/Slab_allocation
[4] PID namespaces in the 2.6.24 kernel : https://lwn.net/Articles/259217/
[5] ID allocation : https://www.kernel.org/doc/html/latest/core-api/idr.html
[6] sysctl limits for namespaces : https://lwn.net/Articles/694968/
[7] Namespaces overview : https://lwn.net/Articles/531114/
[8] Options de montage de /proc : https://www.kernel.org/doc/Documentation/filesystems/proc.txt
[9] Network Devices : https://www.kernel.org/doc/Documentation/networking/netdevices.txt
[10] R. ROSEN, « Linux Kernel Networking: Implementation and Theory », Apress, 2014
[11] Randomizing structure layout : https://lwn.net/Articles/722293/
