

Dans cet avant-dernier article de la série, nous passons en revue les namespaces network et PID pour lesquels la documentation de Linux est plutôt succincte, au regard des fonctionnalités disponibles.
Les namespaces network (net_ns) et PID (pid_ns) ont déjà occupé beaucoup de lignes dans les articles précédents de cette série. Mais ils recèlent encore quelques secrets que nous allons découvrir dans cet article.
Le code de cet article est disponible sur https://github.com/Rachid-Koucha/linux_ns.git.
1. Le namespace network
Le namespace network isole la pile réseau et les structures de données afférentes (les interfaces, la table de routage, les filtres firewall, etc.). Il isole aussi les sockets abstraites du domaine UNIX (cf. man 7 unix). Ces dernières ont la particularité d’utiliser un chemin de fichier (c.-à-d. le champ sun_path dans la structure sockaddr_un) qui n’est pas visible dans le système de fichiers. Pour cela, il faut positionner le premier octet à 0 (c.-à-d. sun_path[0] = ‘\0’). Nous prenons la peine de citer ce point de détail, car LXC est un grand utilisateur des sockets abstraites : la communication entre les outils utilisateur comme lxc-attach ou lxc-console (pour ne citer qu’eux) et le moniteur du conteneur (le processus [lxc monitor] déjà évoqué dans le premier opus de cette série d’articles [1]) se fait par le truchement d’une telle socket. Elle est nommée : /var/lib/lxc/<nom_conteneur>/command.
Une entrée est dédiée à ce namespace dans le manuel en ligne de Linux : man 7 network_namespaces. Il faut cependant reconnaître qu’il est assez succinct.
1.1 L’interface loopback
À la création, un net_ns ne possède qu’une interface réseau : loopback. D’ailleurs, un champ dans la structure du contexte du net_ns pointe dessus. Il s’agit du champ loopback_dev [2].
Notre programme client-serveur simple basé sur UDP utilise l’interface loopback pour communiquer. Le serveur udpsrv reçoit en argument le numéro de port sur lequel il réceptionne un message du client pour l’afficher à l’écran avant de se terminer :
Le client udpcli reçoit en paramètres le numéro de port du serveur suivi du message à envoyer :
Si on lance le serveur en arrière-plan sur hôte avec le numéro de port 12345 par exemple et que nous lançons le client, la communication s’opère avec succès :
Si nous lançons deux serveurs en arrière-plan sur le même numéro de port, le second se termine en erreur EADDRINUSE, car le port 12345 est déjà utilisé par le premier sur l’interface loopback :
Par contre, le lancement d’un second serveur dans un nouveau net_ns à l’aide de la commande unshare démarre sans problème :
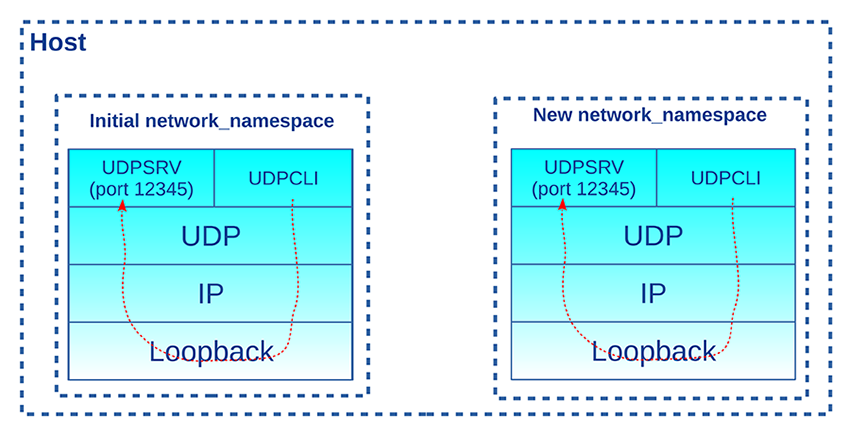
Les deux serveurs ne sont pas en concurrence sur le même port UDP, car chacun est sur sa propre pile réseau et son interface loopback. Ils sont respectivement dans le namespace initial et celui créé par la commande unshare. On note l’identifiant du processus du second serveur (c.-à-d. 11506), car cela va nous servir pour exécuter des commandes dans son net_ns.
En lançant les clients dans chaque namespace, ces derniers atteindront les serveurs respectifs. Mais au préalable, il faut activer l’interface loopback dans le nouveau net_ns. En effet, à la création du namespace, l’interface est dans l’état « down ». Pour le vérifier, on utilise la commande ip via nsenter auquel on passe le PID du second udpsrv avec l’option -t et l’option -n pour entrer dans le net_ns associé :
On procède de même pour activer l’interface et vérifier le changement :
Maintenant, il est possible de lancer udpcli dans chaque namespace pour avoir les réponses de la part des serveurs :
Le schéma de la figure 1 résume le mécanisme.
1.2 Migration des interfaces
On a vu que l’interface loopback est répliquée dans tous les net_ns. Mais il s’agit d’interfaces différentes pour chaque namespace, car toute interface réseau ne peut appartenir qu’à un net_ns à un moment donné. Par défaut, les interfaces autres que loopback sont assignées au namespace initial. On a vu lors de la description de la commande ip [3] qu’il est possible de les faire migrer d’un net_ns à l’autre : l’interface Ethernet eno1 a été transférée dans un conteneur. Cependant, ce n’est pas vrai pour toutes les interfaces. Par exemple, une interface Wi-Fi ne peut pas migrer dans un namespace autre que le namespace initial. De même, il n’est pas possible de migrer les interfaces loopback assignées par défaut à chaque net_ns.
Une astuce [4] permet de savoir si une interface peut changer de namespace ou non. Dans le driver, c’est contrôlé par le drapeau NETIF_F_NETNS_LOCAL. Par exemple dans le source de l’interface loopback (drivers/net/loopback.c) de Linux 5.3.0 :
Comme il n’est pas facile de lire le code source de Linux et de savoir quel driver gère les interfaces sur nos systèmes, il y a heureusement l’outil ethtool. Il affiche différents paramètres des interfaces et notamment « netns-local » qui reflète la valeur du drapeau dans le code source. Pour un exemple d’interface Ethernet, la valeur « off » (drapeau non positionné) signifie que l’interface peut migrer d’un namespace à l’autre :
Il en est de même pour l’interface Ethernet virtuelle utilisée par les conteneurs LXC vu que le principe consiste à créer les interfaces des deux extrémités du tunnel, puis à en migrer une dans le net_ns du conteneur :
Pour un exemple d’interface Wi-Fi et d’interface loopback, la valeur « on » (drapeau positionné) indique au contraire qu’elles ne peuvent pas migrer :
1.3 PROCFS
Le manuel mentionne que l’arborescence /proc/net est virtualisée dans le sens où son contenu reflète le net_ns du processus qui le consulte. Par exemple, le fichier /proc/net/dev contient des statistiques de trafic sur les interfaces actives :
Si on lance un shell dans un nouveau net_ns avec notre outil shns, le même fichier ne montre par conséquent que l’interface loopback, car c’est la seule attachée par défaut à un net_ns non initial :
1.4 SYSFS
Le système de fichiers virtuel SYSFS [5], généralement monté sur /sys, fournit la visibilité sur des structures de données du noyau (cf. man 5 sysfs). On y trouve notamment les interfaces réseau dans /sys/class/net :
Le manuel des net_ns (c.-à-d. man 7 network_namespaces) précise que ce répertoire est virtualisé de sorte à ne montrer que les interfaces réseau liées au net_ns du processus appelant. À l’aide de notre outil shns, effectuons l’essai en créant un shell dans un nouveau net_ns. Affichons le contenu de ce répertoire à partir de ce nouveau shell :
Le résultat ne correspond pas à ce qu’on attendait, car un nouveau net_ns n’a que l’interface loopback par défaut. Ici, on continue à voir les interfaces du net_ns initial. La documentation du noyau Documentation/filesystems/sysfs-tagging.txt explique qu’un système d’étiquettes a été mis en place dans SYSFS pour le rendre « namespace aware ». Sans entrer dans les détails, une même étiquette est attribuée à tout objet de SYSFS qui concerne un namespace donné. Un parcours dans l’arborescence n’affiche que les nœuds ayant la même étiquette que le point de montage courant. Il faut donc avoir un point de montage associé au net_ns courant pour voir les nœuds associés. Dans notre cas de figure, /sys est donc un point de montage associé au mount_ns initial. Un remontage de /sys est nécessaire pour avoir le reflet des objets réseau du noyau associé à notre nouveau net_ns. Il est aussi conseillé de positionner le type de propagation MS_SLAVE afin de ne pas polluer le mount_ns initial (sur les distributions Ubuntu, les points de montage sont en MS_SHARED par défaut). Relançons donc notre shell avec les paramètres net et mnt pour créer les nouveaux namespaces et effectuons les actions adéquates. Nous ne voyons plus que l’interface loopback par défaut de notre net_ns :
1.5 Terminaison
Un net_ns disparaît lorsqu’il n’y a plus de processus qui lui est associé. Si une interface est locale à son namespace (par exemple loopback), elle disparaît avec le namespace. Si l’interface a été migrée dans le namespace alors elle est réaffectée au namespace initial. Nous avons vu cela lors de l’étude [3] de la commande ip : la terminaison du conteneur LXC dans lequel nous avions migré l’interface eno1 (Ethernet) a provoqué une réapparition de cette dernière dans le net_ns initial.
1.6 SR-IOV
Nous avons vu que les interfaces réseau ne sont pas virtualisées dans la mesure où une même interface n’est pas partagée par plusieurs net_ns. Elles sont généralement dédiées au namespace initial et certaines peuvent migrer d’un net_ns à l’autre. Mais de nouveaux équipements ont fait leur apparition sur le marché pour notamment répondre à la spécification SR-IOV ou « Single-Root Input/Output Virtualization » [6]. Les fonctionnalités des interfaces PCI Express sont étendues en plusieurs interfaces virtuelles appelées « Physical Functions » (PF), elles-mêmes divisées en « Virtual Functions » (VF) pouvant être distribuées à différents net_ns et donc par extension à plusieurs machines virtuelles ou conteneurs comme on peut le voir dans l’illustration de la figure 2.
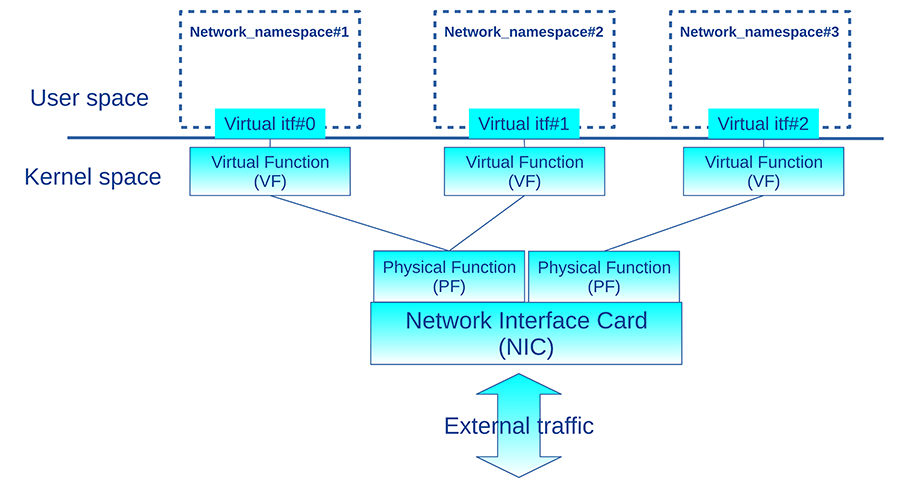
Le noyau Linux supporte SR-IOV [7]. Les fournisseurs de cartes réseau proposent de nombreuses solutions maintenant. Le document [8] présente une expérimentation réalisée par le CERN consistant à utiliser du matériel Intel conforme à la spécification SR-IOV dans des conteneurs LXC. L’étude se base non seulement sur des drivers dédiés pour le matériel, mais aussi sur la commande ip pour configurer les interfaces avec des options dédiées au SR-IOV :
2. Le namespace PID
Le pid_ns isole les identifiants de processus permettant ainsi d’avoir des processus avec le même identifiant sur le système. Une entrée est dédiée à ce namespace dans le manuel en ligne de Linux : man 7 pid_namespaces.
Tout processus créé a un identifiant dans son namespace courant, mais aussi dans le pid_ns à partir duquel son namespace a été créé et ainsi de suite jusqu’au namespace initial. Par conséquent, dans ce dernier, nous voyons tous les processus du système. Dans chacun des namespaces, le PID d’un même processus peut être différent (c’est en général le cas !), mais il est bien entendu toujours unique.
La figure 3, confuse au premier abord, montre un système hypothétique où tournent 10 processus.
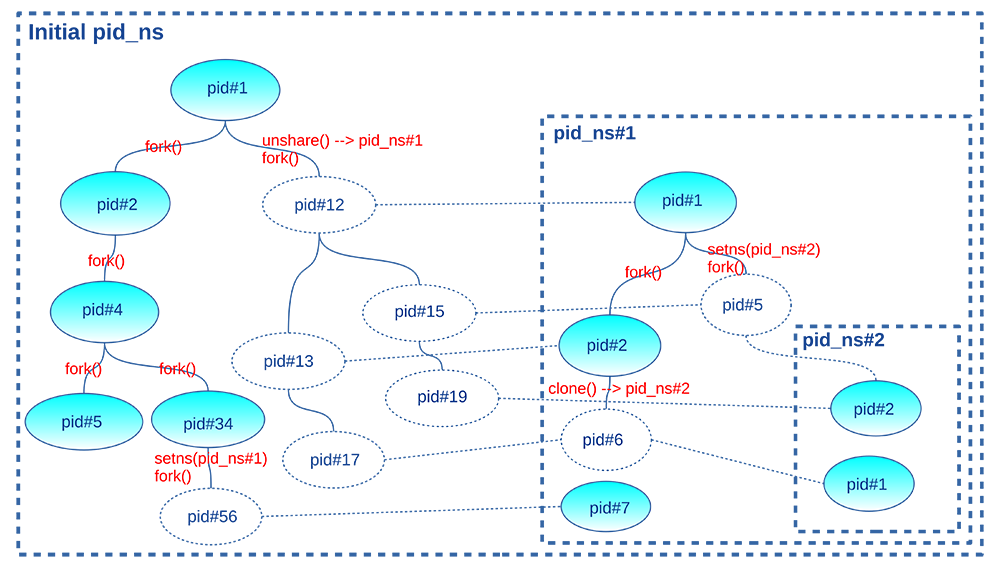
Tous visibles du pid_ns initial, seuls les processus d’identifiants 1, 2, 4, 5 et 34 sont associés à ce namespace. Les processus 12, 13 et 56 sont attachés au pid_ns#1 avec respectivement les identifiants 1, 2 et 7. Les processus de PID 17 et 19 sont attachés au pid_ns#2 avec les identifiants respectifs 1 et 2 visibles dans le pid_ns#1 avec les PID respectifs 6 et 5. Voici un scénario possible pour arriver à cet état :
- Le processus #1 du pid_ns initial a appelé unshare(CLONE_NEWPID) pour créer le pid_ns#1 et a ensuite appelé fork() pour créer le processus #12. Ce dernier a hérité du nouveau pid_ns#1 et est devenu le premier processus d’identifiant 1.
- Le processus #1 du pid_ns#1 a créé le processus #2 (visible avec l’identifiant 13 dans le pid_ns initial) qui a appelé à son tour clone(CLONE_NEWPID) pour créer le pid_ns#2 et le processus #6 qui devient le processus #1 dans le pid_ns#2 et est visible avec le PID 17 dans le pid_ns initial.
- Le processus #1 dans le pid_ns#1 a appelé setns() pour entrer dans le pid_ns du processus #6 (c.-à-d. pid_ns#2) et a appelé fork() pour créer le processus #5 (d’identifiant 15 dans le namespace initial) qui a hérité du pid_ns#2 dans lequel il est visible avec l’identifiant 2. Ce dernier a l’identifiant 19 dans le namespace initial.
- Le processus #34 du pid_ns initial a appelé setns() pour entrer dans le pid_ns du processus #13 (c.-à-d. pid_ns#1) et a appelé fork() pour créer le processus #56 qui a hérité du pid_ns#1 avec l’identifiant 7.
- Quand le père d’un processus se situe en dehors du pid_ns auquel il est associé (c.-à-d. premier processus d’un pid_ns suite à l’appel clone() ou unshare() ou migration via l’appel setns()), getppid() retourne 0. C’est le cas pour les processus 12 et 17 (premiers processus de leur pid_ns suite à l’appel unshare() de leur père) et pour les processus 19 et 56 (arrivés dans leur pid_ns suite à l’appel setns() de leur père).
2.1 Création
À la création, le premier processus du pid_ns a l’identifiant numéro 1 et il a le rôle de faucheur (« reaper » en anglais) des processus orphelins dans le namespace. Fonction essentielle pour les conteneurs destinés à faire tourner des distributions Linux où le premier processus (init) a justement ce rôle [9].
Pour étayer le propos, notre programme pid affiche l’identifiant du processus courant ainsi que celui de son père :
Si nous lançons notre programme shns pour exécuter un sous-shell dans un nouveau pid_ns, nous constatons bien qu’il a l’identifiant 1 :
Le lancement de pid dans le sous-shell montre que son identifiant est 2 (deuxième processus créé et que le père est le sous-shell d’identifiant 1 à partir duquel il a été lancé) :
Pour le premier processus d’un pid_ns ainsi que tout processus entrant dans un pid_ns, le processus père est en dehors du namespace, l’identifiant vu du pid_ns est 0 (on l’a vu lors de la description de la figure 3). Pour s’en convaincre, exécutons une nouvelle fois pid, mais par l’intermédiaire de execns qui rappelons-le, appelle setns() pour entrer dans les namespaces d’un processus donné, puis exécute la commande passée en paramètre. D’abord, on repère le PID du sous-shell dans le namespace initial :
Puis toujours du namespace initial, on lance le programme pid dans le pid_ns du sous-shell :
On vérifie bien que pid s’exécute avec l’identifiant 3, car seulement deux processus ont été lancés avant lui dans le pid_ns (le sous-shell et la commande pid). Le père a l’identifiant 0, car execns tourne dans le pid_ns initial donc extérieur à celui du sous-shell.
Avec le drapeau CLONE_NEWPID, clone() permet de créer un processus dans un nouveau pid_ns. Les appels unshare() et setns() permettent respectivement de créer un nouveau namespace et d’entrer dans un namespace existant pour l’appelant. Cependant, il y a une spécificité quand il s’agit d’un pid_ns : seuls les processus fils du processus courant changent de pid_ns. Cette manière de faire, surprenante de prime abord, préserve le fonctionnement de nombreuses applications et librairies qui subitement se retrouveraient avec un retour différent de l’appel système getpid(). Par exemple, lorsque le résultat de ce dernier sert à identifier des contextes créés avant le changement de namespace, des incohérences et des plantages pourraient apparaître. L’implémentation choisie privilégie donc la compatibilité ascendante.
Exécutons un shell dans un nouveau pid_ns à l’aide de l’option -p de l’utilitaire unshare. Rappelons que unshare, dans sa plus simple expression, appelle unshare(CLONE_NEWPID) et exécute (sans créer de processus fils !) la commande demandée. Ici, le shell exécuté est donc toujours dans le pid_ns initial (d’où l’identifiant différent de 1 affiché par la built-in echo du shell). Par contre, si l’on exécute un processus fils dans ce shell (le programme pid), on constate que ce dernier a l’identifiant 1 et celui de son père est 0, car le sous-shell fait d’abord un fork() qui a pour conséquence de mettre le processus fils dans le nouveau pid_ns avec l’identifiant 1, suivi d’un exec() pour exécuter la commande :
Nous pouvons faire la même chose avec l’option -f (c.-à-d. --fork !) de unshare qui provoque l’exécution du programme demandé dans un processus fils juste après l’appel système à unshare(). Le programme ainsi lancé est bien le premier dans un nouveau pid_ns (PID 1 et PPID 0 !) :
Si un processus peut entrer dans un pid_ns existant via setns(), le chemin inverse est impossible. On peut aller dans le sens descendant de la hiérarchie, mais jamais dans le sens montant. D’ailleurs, la hiérarchie des pid_ns fait qu’à un niveau donné, les processus ne voient que les identifiants des processus situés dans les pid_ns fils. Testons le programme enter_pidns_up suivant qui ouvre le lien symbolique du pid_ns courant, effectue un unshare(CLONE_NEWPID) avant de créer un processus fils qui va d’une part se retrouver dans un nouveau pid_ns et d’autre part hériter du descripteur de fichier sur la cible du lien symbolique ouvert par son père. Voyons ce que provoque un appel à setns() par le fils sur ce descripteur de fichier (en d’autres termes, une tentative de faire ensuite entrer ses propres fils dans le pid_ns de son père) :
L’exécution de ce programme aboutit à un retour erreur EINVAL de la part de setns() appelé dans le fils. Ce qui correspond bien à la description dans le manuel : « EINVAL The caller tried to join an ancestor (parent, grandparent, and so on) PID namespace » :
2.2 PROCFS
Alors que nous connaissons le fichier /proc/<pid>/ns/pid, lien symbolique sur le pid_ns du processus d’identifiant pid, il y a un autre fichier qui attire notre attention dans le même répertoire. Il s’agit de /proc/<pid>/ns/pid_for_children. C’est aussi un lien symbolique pointant sur le pid_ns du processus d’identifiant pid. Il intervient lorsque le processus crée un nouveau namespace ou entre dans le namespace d’un autre processus. Nous avons vu que cela ne concernera en réalité que les fils de ce processus. Dans le laps de temps qui sépare le setns()/unshare() et la création du processus fils, ce lien symbolique est vide, puis lorsque le premier processus est créé, le lien symbolique référence son pid_ns.
Lançons un shell via la commande unshare en demandant un nouveau pid_ns, mais sans fork() :
À ce moment-là, nous sommes dans l’état où un unshare(CLONE_NEWPID) a été appelé et un exec(/bin/sh) a été fait sans création de processus fils. Donc le shell ainsi créé est dans le pid_ns de son père. Listons le contenu de son répertoire à partir des namespace initiaux (c.-à-d. à partir d’un autre terminal) :
La commande ls affiche une erreur, car comme nous sommes dans le laps de temps où un processus a fait un unshare(CLONE_NEWPID), mais avant de créer un fils qui entrera dans le nouveau pid_ns, la cible de son lien symbolique pid_for_children est inexistante.
Du côté du sous-shell, lançons un autre shell. Cela va provoquer un fork() qui mettra le fils dans le nouveau pid_ns (son identifiant est 1) suivi d’un exec() pour le nouveau shell :
Du côté namespaces initiaux, la commande ls montre que pid_for_children pointe désormais sur le namespace du fils :
Terminons le processus fils :
Du côté namespaces initiaux, la commande ls montre que pid_for_children pointe toujours sur le nouveau namespace, alors que ce dernier n’existe plus suite à la terminaison du sous-shell fils :
Il n’est plus possible de lancer un nouveau processus dans le sous-shell :
Le résumé de tout ceci est qu’à partir du moment où un processus appelle unshare(CLONE_NEWPID), il pourra créer autant de processus fils qu’il le désire, tant que le premier processus fils n’est pas terminé. Tous les processus ainsi créés s’exécuteront bien sûr dans le même pid_ns que le premier processus. À partir du moment où ce dernier est fini, tous les processus en cours dans le pid_ns sont tués et il n’est plus possible pour le processus père de créer de nouveaux processus (le fork() retourne une erreur ENOMEM comme ci-dessus). Le manuel de fork() est d’ailleurs explicite sur le sujet :
« ENOMEM An attempt was made to create a child process in a PID namespace whose "init" process has terminated ».
Le fichier /proc/sys/kernel/ns_last_pid contient le dernier identifiant de processus alloué dans le pid_ns courant. Avec les droits suffisants (c.-à-d. CAP_SYS_ADMIN), il est même possible de le modifier afin de contrôler la valeur de l’identifiant du prochain processus créé.
Abordons maintenant l’arborescence /proc/<pid> qui peut prêter à confusion lorsqu’on manipule les namespaces. Dans un nouveau pid_ns, nous savons maintenant que la numérotation des processus recommence à 1. Dans l’exemple suivant, lançons un sous-shell dans un nouveau pid_ns. On utilise l’option -f (c.-à-d. --fork) pour s’assurer que le sous-shell s’exécute lui-même dans le nouveau pid_ns et pas seulement ses fils (son identifiant est donc 1 !) :
Pourtant lorsqu’on lance la commande ps, l’identifiant du shell est celui du pid_ns initial (c.-à-d. 445) :
Cette incohérence est due au fait que des commandes comme ps vont chercher leurs informations dans l’arborescence /proc/<pid> pour tous les processus affichés. Or, le manuel précise que ces arborescences sont l’image des processus dans le pid_ns qui a effectué le montage de /proc. Comme ce dernier a été monté dans le pid_ns initial, cela explique que ps affiche des identifiants correspondant au namespace initial. Dans ce cas de figure, un processus peut donc lire le lien symbolique /proc/self pour connaître son PID dans le pid_ns parent.
Les applications comme les conteneurs LXC remontent /proc à partir du nouveau pid_ns. Mais il faut aussi utiliser un nouveau mount_ns pour ne pas perturber l’environnement initial (à partir duquel le conteneur est créé). Avec la commande unshare, c’est exactement ce que font les options de -m (nouveau mount_ns) et --mount-proc (remontage de /proc dans le nouveau mount_ns). En d’autres termes, en relançant le shell précédent comme suit, la commande ps est cohérente :
En interne, unshare a effectué les actions suivantes :
- Création de nouveaux mount_ns et pid_ns (options -m et -p) : unshare(CLONE_NEWNS|CLONE_NEWPID).
- Création d’un processus fils qui sera effectivement dans le nouveau pid_ns avec l’identifiant numéro 1 (option -f) : fork().
- Le processus fils remonte toute l’arborescence / de manière récursive avec le type de propagation privé afin de ne pas répercuter les futurs montages/démontages dans le mount_ns initial : mount("none", "/", NULL, MS_REC|MS_PRIVATE, NULL).
- Le processus fils remonte /proc : mount("proc", "/proc", "proc", MS_NOSUID|MS_NODEV|MS_NOEXEC, NULL).
- Le processus fils exécute le shell : execve("/bin/sh", ...).
2.3 Conversion d’identifiant
Les pid_ns sont hiérarchiques. Un processus a un identifiant différent du pid_ns courant jusqu’au pid_ns initial. À un niveau donné de la hiérarchie, on connaît l’identifiant d’un processus dans le pid_ns courant, mais on ne voit pas l’identifiant dans les pid_ns descendants ou montants. Rien d’anormal à tout cela, c’est inhérent à l’isolation. Cependant, une fonctionnalité de Linux laconiquement présentée dans la rubrique « Miscellaneous » du manuel des pid_ns indique :
« When a process ID is passed over a UNIX domain socket to a process in a different PID namespace (see the description of SCM_CREDENTIALS in unix(7)), it is translated into the corresponding PID value in the receiving process's PID namespace ».
La même fonctionnalité pour les identifiants d’utilisateur et groupe est évoquée tout aussi discrètement dans le manuel des user_ns, comme on l’a déjà souligné dans l’article dédié [10].
En clair, les appels système sendmsg() et recvmsg() donnent la possibilité d’accompagner les messages de données auxiliaires (c.-à-d. « ancillary data » en anglais). Ces données sont typées. SCM_CREDENTIALS est le type qui nous intéresse ici. Le format du message associé est la structure ucred :
Les informations d’identification (PID, UID et GID), stockées dans les champs de cette structure par le processus émetteur du message, sont vérifiées par le noyau. Seul un processus privilégié peut mettre des informations qui ne lui correspondent pas. L’envoi de ce message d’un processus à un autre provoque au sein du noyau une conversion du champ pid, de sa valeur dans le pid_ns du processus émetteur à sa valeur dans le pid_ns du processus récepteur. Il en est de même pour les champs uid et gid, lors du transfert d’un user_ns à un autre.
Le programme getnsids ci-dessous met en application cette fonctionnalité en traduisant les identifiants de processus, de groupe ou d’utilisateur vu du pid_ns et du user_ns courants dans les namespaces auxquels est associé un processus. Le programme reçoit en paramètre l’identifiant du processus cible vu du pid_ns courant (option -t pour « target ») et les identifiants (PID, UID et GID respectivement avec les options -p, -u et -g) vus des namespaces courants à convertir en identifiants vus des namespaces cibles. Le synopsis est le suivant :
Il crée une socket UNIX, entre dans le pid_ns (si l’option -p est passée) et le user_ns (si l’option -u ou -g est passée) du processus cible (option -t) via l’appel à setns(). Puis il crée un processus fils avec le service fork(), qui s’exécute dans le pid_ns et/ou le user_ns cible (par héritage).
La fonction main() analyse les options sur la ligne de commande avec la fonction getopt() et appelle la fonction interne getnsids() qui effectue la conversion des identifiants pour enfin afficher le résultat à l’écran :
La fonction getnsids() crée la socket UNIX dans /tmp :
Le processus s’associe au pid_ns et/user_ns du processus cible en fonction de ce qui a été demandé :
Ensuite, il crée un processus fils :
Le fils exécute la fonction child_getids() qui se met en attente de connexion sur la socket ouverte par son père (select()), accepte la demande de connexion du père (accept()), positionne l’option SO_PASSCRED avec setsockopt() sur la socket allouée (étape préalable pour recevoir des données auxiliaires de type SCM_CREDENTIALS conformément aux indications de man 7 unix), attend le message avec le PID, UID et GID reçus dans les données auxiliaires et convertis par le noyau aux valeurs dans le pid_ns et/ou user_ns cible, pour ensuite envoyer le résultat de cette conversion au processus père dans les données normales d’un message :
Après le fork(), le père se connecte au fils via la socket sur laquelle le fils est en attente (connect()), envoie un message avec le PID, l’UID et le GID cible dans les données auxiliaires (SCM_CREDENTIALS), attend la réponse du fils avec le PID, l’UID et le GID convertis dans les données normales du message et attend la fin du processus fils (waitpid()) :
La figure 4 résume le fonctionnement du programme lorsqu’on l’appelle avec l’option -p pour convertir un PID.
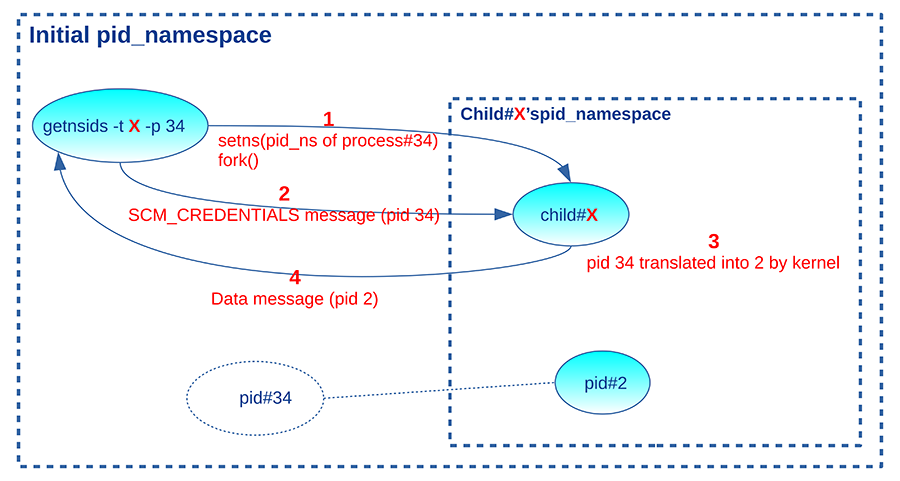
En guise d’exemple, lançons un conteneur LXC et affichons le PID de son processus init dans le pid_ns initial (c.-à-d. côté hôte) avec notre outil lxc-pid :
Cet identifiant est bien entendu l’identifiant du premier processus (identifiant numéro 1) dans le pid_ns du conteneur. Vérifions cela avec notre nouvel outil :
Un conteneur LXC de type busybox fait aussi tourner d’autres daemons [11] comme udhcpc. Récupérons son identifiant côté hôte et utilisons l’outil pour voir sa valeur dans le conteneur :
Nous pouvons vérifier le résultat des conversions avec la commande ps côté conteneur :
Données auxiliaires dans LXC
LXC a recours aux données auxiliaires suivantes :
- le type SCM_CREDENTIALS est utilisé par toute commande utilisateur interagissant avec les conteneurs pour vérifier l’identité de l’appelant ;
- le type SCM_RIGHTS est utilisé lors du démarrage des conteneurs (dans lxc-start et lxc-execute) et par certaines commandes comme lxc-console pour le partage de descripteurs de fichiers (p. ex. terminaux) entre le conteneur et le système hôte.
2.4 Terminaison
2.4.1 Le reaper
Le processus init (c.-à-d. premier processus) d’un pid_ns est le reaper [9] dans le sens où tous les processus orphelins du namespace lui sont reparentés. Pour information, dans le noyau, le champ child_reaper de la structure pid_namespace pointe sur le descripteur task_struct de ce processus [2].
Notre programme reaper crée un processus fils qui exécute un shell, tandis que le programme principal (le processus père) capture les signaux passés en paramètre et se met en attente infinie dans une boucle qui appelle pause(). Le handler de signal sig_chld() gère le signal SIGCHLD en appelant waitpid() pour récupérer le PID et le statut de terminaison du processus terminé. Si c’est le processus shell, alors le programme se termine aussi. Pour les autres signaux, le handler affiche le type de signal et le PID du processus émetteur :
Si on lance ce programme dans un nouveau pid_ns, il devient le processus init du namespace tandis que son fils qui exécute le shell est le processus numéro 2 :
Notre programme orphan lance autant de processus fils que le nombre passé en paramètre, puis se termine. Comme il disparaît avant ses fils, ces derniers deviennent orphelins et sont donc rattachés au processus init. Chaque fils s’endort pendant un nombre aléatoire de secondes avant de se terminer.
Si on lance ce programme dans le shell du reaper ci-dessus, les orphelins sont reparentés au processus reaper dans lequel le handler se déclenche à chaque terminaison de processus :
Si l’on termine le shell du reaper, ce dernier se termine aussi, car c’est prévu dans le handler. Comme tout namespace, le pid_ns associé disparaît lorsqu’il n’y a plus aucun processus qui lui est associé.
2.4.2 Signaux de terminaison
Le pid_ns disparaît à partir du moment où son premier processus disparaît et cela entraîne aussi la terminaison de tout autre processus s’exécutant dans le même pid_ns (le noyau leur envoie le signal SIGKILL). Illustrons cela par un autre exemple ludique. Nous savons que le lancement de la commande unshare sans l’option -f exécute la commande demandée dans le processus courant. Un appel à unshare() est fait, mais comme aucun processus fils n’est créé, la commande reste dans le pid_ns initial. Quand la commande ainsi exécutée est un shell, toute commande lancée par ce dernier entraîne un fork()/exec() d’un fils dans le nouveau pid_ns. Mais comme on l’a déjà vu, après la première commande (d’identifiant 1), il n’est plus possible d’exécuter une nouvelle commande, car la fin du premier processus d’un pid_ns entraîne sa terminaison. Par contre, tant que le premier processus tourne, il est possible d’exécuter d’autres processus. Donc si nous utilisons la commande sleep en arrière-plan comme première commande, il sera possible d’exécuter des commandes jusqu’à échéance de la temporisation :
Le processus d’identifiant 1 dans un pid_ns ne reçoit que les signaux pour lesquels il a installé un gestionnaire. Cela s’applique à tout processus émetteur, privilégié ou non, qu’il soit dans le pid_ns courant ou les pid_ns parents. Cela protège de la destruction accidentelle des pid_ns. Toutefois, pour ne pas rendre impossible la destruction des pid_ns, un processus situé dans un pid_ns parent pourra quand même envoyer le signal SIGKILL ou SIGSTOP au processus init afin de provoquer respectivement une terminaison ou un arrêt du processus cible. Dans la structure siginfo_t passée au gestionnaire de signal, le champ si_pid est renseigné avec l’identifiant du processus émetteur du signal. Si ce dernier réside dans un autre pid_ns, la valeur est mise à 0. Illustrons le propos avec notre programme reaper. Lançons-le comme premier processus dans un pid_ns. Son gestionnaire de signal est déclenché uniquement par les signaux qu’il a capturés, les autres sont ignorés (même SIGKILL !) :
Quand on envoie un signal de la part d’un processus extérieur au pid_ns fils, le comportement est le même, sauf pour l’identifiant du processus émetteur positionné à 0 dans le champ si_pid et le traitement de SIGKILL qui entraîne la terminaison du processus reaper et par conséquent du pid_ns fils. Dans un autre terminal, repérons le PID du reaper dans le pid_ns père. Et envoyons-lui le signal SIGTERM, puis le signal SIGKILL :
De retour dans le terminal du reaper, on constate que l'identifiant du processus émetteur du signal SIGTERM est mis à 0 dans le champ si_pid et que le signal SIGKILL provoque bien la terminaison du reaper et de tous les processus du pid_ns fils entraînant ainsi sa disparition.
Pour être complet, précisons aussi que le signal SIGSTOP envoyé par un processus extérieur au pid_ns provoque l’arrêt du processus init et le champ si_pid est aussi positionné à 0.
2.4.3 Reboot
L’appel système reboot() a été adapté aux namespaces (cf. man 2 reboot). Lorsqu’il est invoqué à partir d’un pid_ns autre que l’initial, son comportement est le suivant en fonction du paramètre passé en argument :
- RB_AUTOBOOT termine le premier processus du pid_ns avec un statut de terminaison contenant l’identifiant du signal SIGHUP ;
- RB_POWER_OFF ou RB_HALT_SYSTEM termine le premier processus du pid_ns avec un statut de terminaison contenant l’identifiant du signal SIGINT ;
- toute autre valeur aboutit au code erreur EINVAL.
Notre programme rebootns reçoit en paramètre le type à passer à l’appel système reboot() :
Lançons de nouveau le reaper en tant que premier processus dans un nouveau pid_ns et utilisons notre programme rebootns pour le terminer. Le premier essai avec le paramètre SW_SUSPEND aboutit à l’erreur EINVAL conformément au manuel. Le second essai avec AUTOBOOT envoie bien le signal SIGHUP au processus init :
Conclusion
Les net_ns et pid_ns nous ont encore montré de nombreuses fonctionnalités. Et malgré cela, nous avons pu voir, notamment en évoquant l’état de l’art en matière de virtualisation des interfaces réseau, que le terrain est encore propice à des évolutions futures. D’ailleurs, les besoins sont tels que de nouveaux namespaces vont bientôt arriver et certains sont à l’étude, comme nous le verrons dans le prochain et dernier opus de cette série consacrée aux namespaces de Linux.
Références
[1] R. KOUCHA, « Les namespaces ou l’art de se démultiplier », GNU/Linux Magazine n°239, juillet/août 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-239/Les-namespaces-ou-l-art-de-se-demultiplier
[2] R. KOUCHA, « Les structures de données des namespaces dans le noyau », GNU/Linux Magazine n°243, décembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-243/les-structures-de-donnees-des-namespaces-dans-le-noyau
[3] R. KOUCHA, « Les utilitaires relatifs aux namespaces », GNU/Linux Magazine n°240, septembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-240/Les-utilitaires-relatifs-aux-namespaces
[4] R. ROSEN, « Linux Kernel Networking: Implementation and Theory », Apress, 2014.
[5] Le système de fichiers sysfs : https://fr.wikipedia.org/wiki/Sysfs
[6] Single-root input/output virtualization :
https://en.wikipedia.org/wiki/Single-root_input/output_virtualization
[7] PCI Express I/O Virtualization Howto : https://www.kernel.org/doc/html/latest/PCI/pci-iov-howto.html
[8] SR-IOV with Linux Containers : https://software.intel.com/en-us/articles/single-root-inputoutput-virtualization-sr-iov-with-linux-containers
[9] Zombie process : https://en.wikipedia.org/wiki/Zombie_process
[10] R. KOUCHA, « Identité multiple avec le namespace user », GNU/Linux Magazine n°246, mars 2021 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-246/Identite-multiple-avec-le-namespace-user
[11] Daemons : https://en.wikipedia.org/wiki/Daemon_(computing)
