

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Le renseignement sur les menaces, ou Cyber Threat Intel, est un domaine où il est facile de se perdre tant les sources, méthodes et outils sont nombreux. Dans ce dossier, nous nous efforçons de vous donner les clés pour démarrer avec des outils libres sans perdre pied.
Dans ce premier article du dossier, nous proposons une vision d’ensemble du processus de Cyber Threat Intelligence (CTI) puis dans le second nous démontrons comment la Plateforme de Threat Intelligence (TIP) MISP [MISP] peut y prendre un rôle central. Enfin dans un troisième temps, nous verrons un exemple de service d’expansion avec hashlookup [HL] qui permet d’ajouter du contexte à des indicateurs et lever le doute sur leur statut de faux positifs.
L’analyse de la menace a pour but de produire des informations utiles pour la défense d’une organisation. Dès lors, la première étape lors de la création d’un processus de CTI, souvent dénommée pipeline, est la définition d’un plan pour parvenir à ce but. Ce plan est étroitement lié aux activités de l’organisation et à sa défense contre les menaces connues ou estimées.
L’article introduit les concepts de base relatifs à la collection du renseignement dans l’objectif de limiter les risques contre une organisation. Nous verrons comment planifier et structurer son pipeline de Threat Intelligence ainsi que comment l’intégrer avec des outils libres pour automatiser ce mécanisme. Plusieurs éléments de ce processus combinent des composantes venant d’analyses de risques ou d’informations relatives à des incidents antérieurs. La chaîne complète pourra facilement s’intégrer dans des équipes existantes ayant des responsabilités en sécurité informatique.
1. La place du CTI
Avant de rentrer dans le vif du sujet, il convient de réaliser qu’un pipeline de CTI est l’affaire de toutes les équipes qui traitent de sécurité au sein d’une organisation :
- Le SOC va consommer des renseignements pour identifier des menaces, mais va aussi nourrir le pipeline des informations contenues dans les alertes qui donneront lieu à une réponse à incident.
- Le CSIRT va consommer des renseignements pour contextualiser la réponse à incident, mais va aussi nourrir le pipeline de ses résultats d’analyse.
- L’équipe CTI va enrichir les renseignements via l’adjonction de renseignements extérieurs et produire des briefings et autres rapports de sécurité qui seront utiles pour faire la chasse aux menaces identifiées (aussi appelé le Cyber Threat Hunting).
2. Pourquoi choisir l’open source ?
La mise en place d’un pipeline de CTI est une tâche ardue qui demande beaucoup de ressources de la part des équipes de sécurité et qui met du temps à porter ses fruits, aussi nous proposons dans ce dossier de se concentrer sur des outils libres et open source :
- cela permet de mettre en place le pipeline progressivement et de pouvoir expérimenter sans engager d’autres ressources que du temps humain et machine ;
- l’open source permet plus facilement de s’approprier les outils et les processus pour les adapter à l’organisation, aux menaces auxquelles elle fait face, ainsi qu’à ses capacités de traitement d’incidents ;
- utiliser de telles solutions permet aux équipes impliquées de monter en compétences sur des problèmes techniques concrets plutôt qu’aux idiosyncrasies de telle ou telle solution propriétaire ;
- une solution libre et open source permet de garantir la pérennité de la solution adoptée : si quelques autres « big players » ont investi des ressources dans cette solution et que la licence a été pensée intelligemment, il est très peu probable que l’outil disparaisse ou devienne payant. Par ailleurs, baser son pipeline CTI sur une solution commerciale place l’organisation dans une situation vulnérable qu’il est difficile de justifier quand l’offre libre est le principal vecteur d’innovation dans le domaine.
Enfin, l’interopérabilité de ces solutions est cruciale pour la pérennité de l’effort de CTI, c’est pourquoi nous recommandons fortement de choisir des standards libres comme misp-standard [MS] pour supporter ces aspects.
Les aspects intégration de ce dossier sont calqués sur le pipeline CTI du CIRCL [CIRCL], le CERT responsable du secteur privé au Luxembourg. Ce pipeline est supporté exclusivement par du logiciel libre, depuis la planification jusqu’à la dissémination des renseignements produits, mais il est tout à fait compatible avec des solutions propriétaires qui proposent des connecteurs via des standards libres.
La figure suivante montre quelles sections du pipeline sont couvertes par les différents outils. MISP est omniprésent de par ses multiples fonctionnalités et sa capacité à interagir avec les différents outils de collection et d’expansion de données que nous détaillons dans le second article de ce dossier.
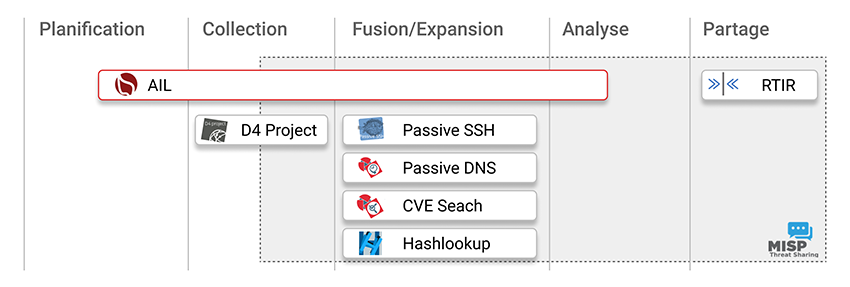
3. Le pipeline
3.1 Planification et priorisation
Un programme de CTI est pensé du stratégique vers l’opérationnel et a pour but de produire du renseignement pour la direction comme pour les opérations dans le but d’assurer la résilience d’une organisation. Il aide à identifier, contrôler et surveiller les menaces en produisant du renseignement fiable et utile pour contrôler le risque portant sur les opérations de l’organisation. Dès lors, la première étape de la création d’un processus (souvent dénommée pipeline) de CTI est la définition d’un plan adapté à l’organisation pour parvenir à ce but.
Ce plan est étroitement lié aux activités de l’organisation et à la création de valeur. Le recueil d’informations pour l’établir est assez commun à une analyse de risques et nous permet d’établir une liste de priorités. Ainsi il nous faut identifier les produits et services produits par l’organisation ainsi que leur valeur monétaire et stratégique : quel serait le coût de leur perte pour l’organisation ? Pourrait-elle encore fonctionner normalement si tel ou tel composant venait à faillir ?
Une fois les joyaux de la couronne identifiés, il nous faut construire le réseau de dépendance qui garantit leur exploitation et leurs éventuelles vulnérabilités. Il est ainsi nécessaire de connaître l’environnement de l’organisation : quels sont les secteurs affiliés, l’empreinte géographique, le support sociopolitique, mais surtout l’organisation elle-même.
En effet, la meilleure source d’information est l’environnement de l’organisation et les organisations qui lui ressemblent (y compris ses concurrents). Il faudra établir un inventaire technique aussi complet que possible (chose qui de toute manière est utile pour la réponse à incidents) et identifier :
- les services exposés depuis l’extérieur :
- les versions de toutes les strates logicielles (OS, serveurs HTTP, etc.) ;
- les applications particulières au secteur d’activité, et les éditeurs associés ;
- les options de travail à distance et les technologies utilisées ;
- les solutions de maintenance à distance et qui y a accès.
- les services déployés en interne :
- les postes de travail et smartphones ;
- les serveurs de messagerie, les types d’attachements permis ;
- les services git, intranet, serveurs de fichiers, d’impression, etc. ;
- diagramme réseau complet, et OS des matériels utilisés, etc.
- les capacités d’introspection :
- quels sont les logs conservés pour les e-mails, les proxys, le réseau, etc. ;
- quels sont les IDS / EDR et les capacités de requêtes ;
- quelles sont les capacités de collection passive (passive DNS, etc.).
Il faudra aussi établir un historique de l’organisation pour déterminer quels sont les incidents passés contre l’organisation et ses concurrents. Ces informations sont les plus importantes, car elles renseignent à la fois sur la menace, les assets visés, mais aussi les TTP (Tactiques, Techniques et Procédures) et les acteurs à surveiller.
Il faut noter que la maturité de l’organisation joue un rôle primordial dans cette phase de planification. Une organisation peut n’avoir aucun incident connu et aucune capacité à traiter ou inventorier correctement des incidents. Pour ces organisations, il peut être intéressant d’avoir une approche pragmatique du pipeline CTI en commençant par le bas, sans plan particulier, en lançant la chasse sur quelques indicateurs récents pour faire ses premières armes.
Une fois cet inventaire terminé, il nous faut identifier comment les renseignements vont être collectés, stockés et traités et qui vont être les destinataires des renseignements ainsi produits. On a vu que toutes les équipes sécurité d’une organisation peuvent être consommatrices et productrices de renseignements, mais il convient aussi d’identifier les communautés de partage d’informations, les autres sources et destinations extérieures pertinentes.
Toutes les informations collectées vont nous permettre de construire une liste de mots-clés, sujets et TTP à surveiller, car ils sont pertinents pour assurer la sécurité de l’organisation. Les TTP sont souvent décrits en utilisant des modèles comme MITRE ATT&CK [ATT&CK] qui permettent de contextualiser les informations tout au long du pipeline de CTI en ajoutant les techniques. Cela aide à caractériser les défenses en place et à identifier les insuffisances dans la défense d’une organisation.
Nous terminons ici nos réflexions sur la planification pour développer dans la suite de l’article ce qu’il est pertinent d’implémenter. Mais gardez en tête que tout ce que nous allons voir maintenant devrait être réfléchi en amont de l’implémentation.
3.2 Collection d’informations et sources externes / OSINT
Avant de plonger dans la liste des sources d’informations et des outils à notre disposition pour trouver les informations pertinentes, il convient de rappeler ce que sont les notions d’informations quantitatives et qualitatives : un article de blog expliquant comment un APT cible un secteur d’activité en particulier constitue par exemple une somme d’informations qualitatives, issue de la réflexion d’un analyste, alors que les IoC (Indicators of Compromise) qui l’accompagnent seront des données quantitatives.
Ainsi, les informations traditionnelles fournissent des informations qualitatives intéressantes, en particulier sur les fusions-acquisitions des différents éditeurs qui peuvent ouvrir des accès à des acteurs inconnus. Les blogs et les comptes de microblogging concentrés sur la sécurité apportent des informations qualitatives et parfois quantitatives sur les menaces. Ces entités sont même parfois plus à même de donner une réponse quant à la réalité d’une menace ou l’effectivité d’un patch que les éditeurs eux-mêmes (j’en veux pour exemple la mascarade de Microsoft autour des vulnérabilités d’Exchange en 2021 [GGMS]).
On peut ensuite approfondir nos recherches pour obtenir des informations plus spécifiques :
- Les bases de vulnérabilités comme CVE search [CVES] et les sites de distribution d’exploits comme exploitdb [ED] doivent être monitorés pour réagir aux nouvelles vulnérabilités découvertes qui concernent notre organisation, connaître la maturité de la menace, et pouvoir faire du Threat Hunting et des scans préventifs si besoin.
- Les security et technical reports (édités par exemple par l’ANSSI, CERT-EU, etc.) peuvent être d’une grande aide pour identifier et contrôler la menace ou parfois même convaincre un éditeur de la réalité de la menace et l’inciter à faire son travail (voir par exemple TR-64 [TR64]).
- Les Threat Intelligence feeds sont des sources intéressantes de renseignement quantitatif qu’il convient d’évaluer pour éviter d’avoir trop de duplicatas d’indicateurs ou de faux positifs.
- Les sources de Threat Sharing peuvent fournir des renseignements quantitatifs et qualitatifs de qualité si les communautés de partage sont pertinentes pour l’organisation. Nous verrons plus en détail en deuxième partie de ce dossier comment utiliser MISP pour les exploiter.
- Les forums blackhat et autres canaux Telegram peuvent fournir des renseignements intéressants sur les TTP, les fuites d’informations ou les attaques ciblées sur des infrastructures qui ressemblent à notre organisation.
- De même, monitorer l’Internet et le darknet pour la mention de l’organisation à défendre est une bonne idée. Cela permet par exemple souvent de gagner quelques heures sur l’identification d’une fuite de données et cela s’avère crucial pour contrôler les dommages d’images.
- Un réseau de honeypots, de sensors et autres canaries [CANARIES] peut aussi être intéressant pour avertir des nouveaux TTP, et du niveau de menace portant sur certains aspects de l’organisation.
- Monitorer les app-stores contre les applications tierces utilisant le nom ou l’image de l’organisation permet de répondre rapidement aux tentatives d’imitation.
- Les réseaux de Fraud Intelligence peuvent être d’une grande aide pour connaître les TTP des réseaux criminels plus traditionnels qui pourraient cibler notre organisation (pour une fraude au président par exemple).
- Les sites de partage de presse-papiers ainsi que les trackers de torrents peuvent aussi fournir des informations pertinentes sur des attaques en cours ou des informations perdues.
Pour accomplir ces tâches au sein du CIRCL, nous utilisons massivement AIL [AIL], un outil de collection, de web scraping et d’analyse pour collecter les informations sur Tor, certains sites de partage de presse-papier, Twitter et autres canaux Telegram à la recherche de mentions d’entreprises du secteur financier enregistrées au Luxembourg. La Figure 2 montre le leak hunter correspondant, une règle yara de 6000 lignes, responsable de cette collection dans AIL.
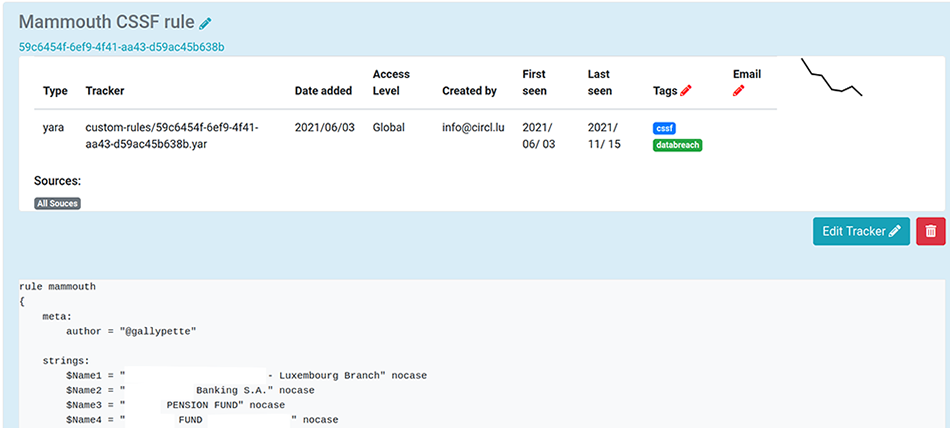
Parmi les autres outils open source qui peuvent vous assister, entre autres lors de la phase de collection, nous recommandons chaudement Yeti [YETI] et le tout nouveau taranis-ng [TARANIS].
3.3 Fusion et expansion
Les informations collectées peuvent prendre différentes formes, ce qui complique leur ingestion. On va retrouver quelques informations structurées, par exemple les informations provenant d’une plateforme de partage d’informations comme MISP. Ces dernières seront directement exploitables pour contextualiser des événements analysés en interne, car les données sont accompagnées d’un schéma pour les exploiter.
Mais on va aussi consommer des informations non structurées qui ne sont pas directement compréhensibles par une machine. Le machine learning peut aider à classer ces informations, et l’usage d’expressions régulières et de règles Yara à fouiller le flux de données à la recherche d’informations pertinentes. AIL peut par exemple annoter automatiquement les items reçus pour indiquer quelle langue a été reconnue, si des numéros de cartes de crédit ont été détectés, s’il est fait mention de certains mots-clés, etc.
Les résultats d’analyse sont souvent partagés sous forme d’articles de blogs. C’est en effet ce qui se prête le mieux au développement et à la présentation d’arguments. Cela crée malheureusement des problèmes au moment de traiter ces données si les IoC qui accompagnent l’analyse sont communiqués sous forme d’images ou autres excentricités. Deux bonnes nouvelles cependant : (1) MISP dispose d’une fonctionnalité de free-text import qui fonctionne plutôt bien et (2) les rapports de sécurité sont parfois accompagnés d’IoC au format MISP ou STIX (par exemple, le CERT-FR utilise le format MISP [CERT-FR]).
Mais tout cela est sans compter sur les différents formats de données de quelques outils qui vont aussi venir compliquer les choses. Des outils d’ETL (Extract Transform Load) existent pour transformer ces flux de données, nous avons de bons retours d’expérience avec Apache NiFi [NIFI] et Elixir Broadway [BROADWAY] que l’on utilise pour ingérer les données provenant de nos honeypots et autres sondes issues du projet d4 [D4].
L’exploitation des informations collectées va aussi passer par l’analyse de malwares récupérés par le pipeline CTI. Le sujet est bien trop vaste pour être traité ici, mais des outils comme FAME [FAME] ou KARTON [KARTON] peuvent tout à fait interagir avec MISP ou YETI et marier ainsi un pipeline CTI avec un pipeline d’analyse de malwares.
Enfin, d’autres sources et services vont ajouter du contexte à l’information. Pour faire la fusion de ces données, se rendre compte de la chronologie des évènements et produire des renseignements activables, nous utilisons MISP. Comme on peut le voir sur la première figure, MISP est le point commun entre tous les projets open source que nous utilisons dans notre pipeline CTI. Chaque projet dispose d’un export vers MISP pour exploiter et partager les résultats. Par exemple, la Figure 3 montre un graphe issu de AIL où l’on peut observer deux services onion que AIL a crawlé sur lesquels figure une même clé PGP. Un bouton permet d’exporter ces données sous un format JSON directement assimilable par MISP.
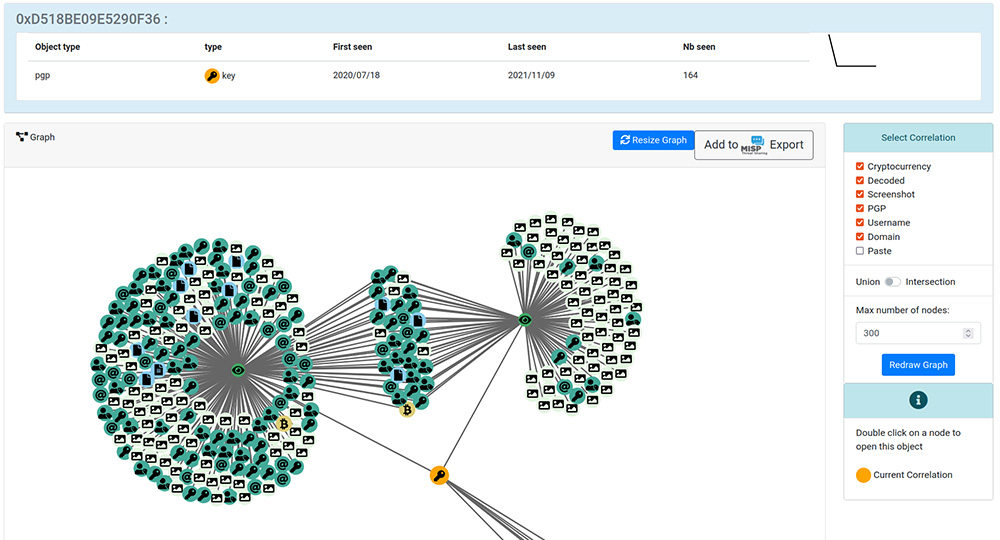
Cette interopérabilité des outils nous permet de continuer à pivoter sur les données à portée de l’instance MISP, qu’elles se trouvent dans les événements de l’instance ou dans le cache des feeds auxquels l’instance a accès. Une fois un événement (event) créé, il est possible d’enrichir certains attributes en lançant des requêtes sur des services externes comme les passive DNS, et SSH qui gardent l’historique des associations entre une adresse IP et des noms de domaines, ou des clés SSH respectivement. En troisième partie de ce dossier, nous présentons hashlookup qui est intégré à MISP de la même manière.
Un autre aspect de cette phase de fusion de données est la consommation de renseignement issu du threat sharing. En effet, un event MISP va arriver sur une instance MISP avec l’analyse et donc la contextualisation déjà réalisée par d’autres analystes. Ainsi un event sera porteur de tags, et pourra être lié à un threat actor et autres TTP.
3.4 Analyse et production de renseignements
C’est à cette étape que l’analyste entre vraiment en jeu. Il lui faut produire du renseignement, et comme on peut le voir dans la colonne analyse de la première figure, nous n’utilisons pas d’outil libre dédié à cette tache à part MISP. Dans le cas de production qualitative, cela signifie passer d’informations factuelles et des hypothèses qu’il peut formuler, à des findings et forecasts qui seront le résultat d’une argumentation claire autour des faits sans jamais tomber dans le fortune-telling [INTEL].
Il convient par exemple d’être particulièrement prudent dans les résultats que l’on avance et il peut être utile de recourir à des techniques directement issues du renseignement pour certaines analyses, par exemple pour l’attribution. Les Structured Analysis Techniques [SAT], par exemple l’Analyse des Hypothèses Concurrentes [ACH] utilisée pour l’attribution, proposent des procédures à suivre pas à pas pour éviter les biais cognitifs de l’analyste et se rapprocher le plus possible de la vérité, eu égard aux faits.
L’autre aspect de la production de renseignement est la production de renseignements quantitatifs. Tous les IoC, résultat d’analyses de malwares et autres C2 entrent dans cette catégorie, tout comme la création de règles de détection destinées aux IDS et autres EDR.
3.5 Dissémination
Comme suggéré en première partie, la dissémination du produit de notre pipeline peut se faire à plusieurs destinations :
- les équipes de sécurité de notre organisation ;
- les équipes de sécurité d’organisations similaires à la nôtre qui font partie des mêmes communautés d’échange d’informations ;
- aux organismes de protection de la vie privée qui peuvent éventuellement être concernés ;
- la communication interne de l’organisation à des vues de sensibilisation des usagers ;
- la direction à des vues de planification stratégique.
Les communautés de partage d’informations et les équipes de sécurité utiliseront le plus souvent MISP pour convoyer les données. Pour les autres parties, nous utilisons le plus souvent l’e-mail avec RTIR [RTIR] dont la sécurité des échanges est assurée par le bon vieux PGP.
Une question subsiste sur le partage d’informations : comment appliquer des restrictions d’usage sur les informations partagées ? Comme nous allons le voir dans la partie suivante, il est trivial de communiquer cette information à une machine à travers MISP ; le problème devient un petit peu plus épineux quand il est question de personnes. Au sein des CERT, c’est souvent le Traffic Light Protocol [TLP] qui est adopté pour apporter une réponse à la question « À qui puis-je communiquer cette information? » et le Permissible Action Protocol [PAP] pour répondre à la question « Comment puis-je exploiter cette information? ». Ainsi une communauté peut partager des informations entre ses constituants sans perdre l’avantage ainsi acquis sur l’adversaire.
Conclusion
Dans cet article, nous avons présenté comment CIRCL opère son pipeline CTI. Nous témoignons que ce pipeline fonctionne pour une équipe déterminée à opérer une veille constante de la sécurité de ses constituants et espérons qu’il vous sera utile pour construire le vôtre. Dans l’article suivant, nous présentons les fonctionnalités de MISP et comment cet outil peut constituer le point central d’un pipeline CTI.
Remerciements
Je tiens à remercier le reste de l’équipe CIRCL et Cédric Le Roux pour leurs relectures attentives et remarques pertinentes.
Références
[MISP] https://www.misp-project.org/
[HL] https://hashlookup.circl.lu/
[MS] https://www.misp-standard.org/
[CIRCL] https://circl.lu/
[ATT&CK] https://attack.mitre.org/
[CVES] https://www.circl.lu/services/cve-search/
[ED] https://www.exploit-db.com/
[GGMS] https://www.microsoft.com/security/blog/2021/03/02/hafnium-targeting-exchange-servers/
[TR64] TR-64 - Exploited Exchange Servers : https://www.circl.lu/pub/tr-64/
[CANARIES] What are Canarytokens : https://docs.canarytokens.org/guide/
[AIL] https://ail-project.org/
[YETI] https://github.com/yeti-platform/yeti
[CERT-FR] CERT-FR Indicateurs de compromission : https://www.cert.ssi.gouv.fr/ioc/
[NIFI] https://nifi.apache.org/
[BROADWAY] https://elixir-broadway.org/
[FAME] https://certsocietegenerale.github.io/fame/
[KARTON] https://github.com/CERT-Polska/karton
[TARANIS] https://github.com/SK-CERT/Taranis-NG
[INTEL] Facts, Findings, Forecasts, and Fortune-telling :
https://davebucklin.com/icfiles/facts-findings-forecasts-and-fortune-telling-davis-1995.pdf
[SAT] A tradecraft primer :
https://www.stat.berkeley.edu/~aldous/157/Papers/Tradecraft%20Primer-apr09.pdf
[ACH] Digital shadows, Applying the Analysis of Competing Hypotheses to the Cyber Domain
[RTIR] https://bestpractical.com/rtir
[TLP] TLP sur misp-project : https://www.misp-project.org/taxonomies.html#_tlp_2
[PAP] PAP sur misp-project : https://www.misp-project.org/taxonomies.html#_pap


