

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Les temporisations sont essentielles au sein des systèmes d'exploitation et dans certaines applications, pour déclencher des actions à l'échéance d'un délai. Il existe différents algorithmes pour les gérer de manière efficace. Cet article présente la fusion de deux d'entre eux, pour en tirer le meilleur.
Les temporisations, essentielles dans les systèmes informatiques, doivent être gérées de manière efficace. Il existe des API standard dans Linux ou dans la GLIBC pour les mettre en œuvre. Cependant, pour des raisons d'optimisation ou de non-disponibilité de services adaptés à certains environnements logiciels ou matériels, des applications implémentent leur propre API. Cet article s'inscrit dans cette démarche en présentant deux algorithmes : la liste delta (delta list) et la roue des temporisations (timer wheel). Le premier est utilisé dans Minix [1], le célèbre système d'exploitation universitaire ancêtre de GNU/Linux. Le second est en service sous une certaine forme dans le noyau Linux [2]. Il sera ensuite proposé une fusion des deux solutions, afin de bénéficier d'une certaine complémentarité et obtenir de meilleures performances du point de vue de la latence et de la charge CPU induite.
1. Généralités sur les temporisations
1.1 Champs d'application
Les champs d'application des temporisations sont variés. En voici quelques exemples :
- robustesse : dans le domaine des réseaux, un serveur peut se protéger contre les déconnexions subites des clients en armant une temporisation qui représente un délai maximum autorisé pour recevoir une réponse. En cas d'échéance du délai, les ressources dédiées au client sont désallouées pour être réaffectées à une nouvelle connexion ;
- sécurité : lors de la connexion à un système, lorsque le mot de passe saisi est incorrect, le délai d'affichage des demandes suivantes est accru, de sorte à allonger le temps nécessaire à la connexion. Ainsi, on dissuade le pirate qui tente toutes les combinaisons possibles de caractères. C'est le principe des vitres dites à retard d'effraction. Elles ne sont pas indestructibles, mais le temps nécessaire à les briser est dissuasif. C'est aussi un des moyens utilisés pour parer les attaques par déni de service (Denial of Service ou DoS) [3]. Le serveur repère les adresses sources des systèmes qui le bombardent de requêtes et leur applique un délai de punition, pour étaler dans le temps l'acceptation des nouvelles demandes de connexion ;
- planification : des utilitaires « calendrier » sont basés sur des temporisations à l'échéance desquelles des opérations de maintenance sont réalisées ;
- fiabilité : certains garbage collectors, notamment dans les services de gestion mémoire (RAM ou disques), sont déclenchés cycliquement pour défragmenter les données, de sorte à garantir des temps de réponse moyens raisonnables. Les protocoles réseau tels que TCP garantissent le transfert des données de bout en bout en procédant à des retransmissions en interne lorsqu'à échéance de temporisations, certains acquittements sont perdus.
1.2 Types
Les champs d'application précédents permettent de distinguer deux types de temporisations :
- temporisations dites de garde (timeout) qui ne sont pas censées échoir dans un mode de fonctionnement normal : elles sont en général arrêtées avant terme. À échéance, elles entraînent un mécanisme de rectification pour organiser un retour à l'état normal (par exemple, déconnexion d'un interlocuteur réseau qui ne répond plus ou retransmission d'un paquet perdu sur le réseau) ;
- temporisations de planification qui vont à leur terme (run to completion) pour déclencher des activités dans le futur (par exemple, rappel d'un rendez-vous dans un utilitaire de calendrier ou délai avant affichage d'une nouvelle demande de saisie de mot de passe).
Ce dernier cas se décline en deux sous-catégories : les temporisations normales (one shot) qui une fois arrivées à leur terme ne sont pas forcément réarmées et les temporisations cycliques qui expirent périodiquement.
1.3 Opérations
Une API de gestion des temporisations propose les opérations suivantes :
- allocation/démarrage d'une temporisation qui reçoit en entrée un type (normal ou cyclique), la durée avant expiration et l'action effectuée à échéance de la temporisation. Cela peut se faire en passant le pointeur sur une fonction à appeler (callback) ou un message à envoyer vers un destinataire. L'identifiant d'un descripteur de temporisation est en général retourné pour référence dans les opérations suivantes ;
- arrêt d'une temporisation qui reçoit en entrée l'identifiant afin de désarmer la temporisation associée avant son terme. Cette fonction se charge aussi, quand c'est possible, de la résolution des cas de croisement. En effet, lorsque des tâches s'exécutent en parallèle, il peut arriver que l'application demande à arrêter une temporisation déjà échue. Si les structures de données le permettent, il faudra annuler l'appel de la fonction d'échéance ou supprimer le message d'échéance déjà posté dans la queue de réception du destinataire ;
- désallocation d'une temporisation qui reçoit en entrée l'identifiant. Cette fonction est appelée quand il n'est plus envisagé d'utiliser la temporisation à plus ou moins long terme.
1.4 Granularité
Les temporisations sont cadencées par une pulsation périodique (tick) à l'échéance de laquelle on détermine quelles sont les temporisations expirées. La période du tick détermine la précision de la date d'échéance des temporisations. Quand on arme une temporisation pour une durée donnée, celle-ci est divisée par la période du tick et arrondie au tick supérieur, si nécessaire. Pour plus de précision, on a donc intérêt à avoir un tick de période la plus petite possible, mais la latence de traitement de l'échéance de la temporisation ainsi que les capacités matérielles sont des facteurs limitatifs. L'efficacité de l'algorithme utilisé pour gérer l'échéance est primordiale pour réduire la latence.
2. Algorithme de la liste delta
2.1 Principe et structures de données
Le code source de la librairie ainsi que l'API mettant en œuvre l'algorithme se trouvent respectivement dans les fichiers tdl.c et tdl.h.
La structure tdl_desc_t définit un descripteur de temporisation :
Le champ timeout est la durée en pulsations de la temporisation. Elle est fournie par la fonction de démarrage. On parlera de période d'échéance si la temporisation est de type cyclique (champ type égal à TDL_TIMER_CYCLIC).
Le champ link regroupe, dans la structure tdl_link_t, les liens avant et arrières dans la liste doublement chaînée de tous les descripteurs de temporisations armées. La tête de cette liste est mémorisée dans la variable globale tdl_timers du fichier tdl.c.
Le choix d'un double chaînage permet l'ajout et la suppression efficaces des éléments dans la liste, car il n'y a pas besoin de la parcourir. Trois macros réalisent les opérations courantes dans la liste (ajout d'un élément avant un autre, suppression d'un élément et test de liste vide) :
La macro TDL_LINK2DESC() s'appuie sur la macro standard offsetof() pour retrouver l'adresse de début du descripteur de temporisation à partir de l'adresse des liens :
Les champs user_cbk et user_ctx sont respectivement le pointeur sur la fonction à appeler et le pointeur sur un contexte utilisateur à passer à cette dernière, lorsque la temporisation est échue.
Le champ delta est le délai d'échéance associé à ce descripteur après l'expiration de la temporisation dont le descripteur est situé juste avant dans la liste. C'est le principe de base de l'algorithme où le délai d'échéance d'un descripteur correspond à la somme de son champ delta avec les champs delta des descripteurs qui le précèdent dans la liste. La figure 1 illustre le fonctionnement en cinq étapes :
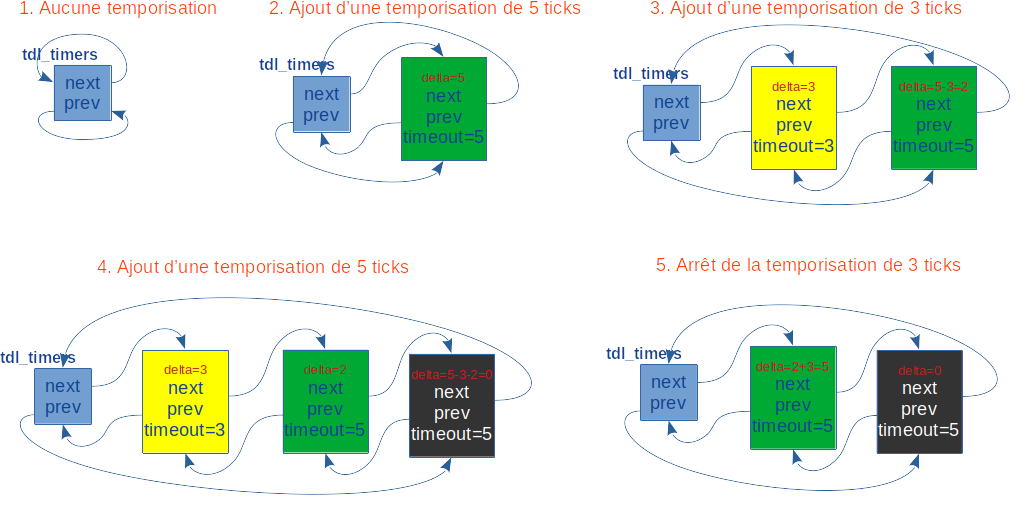
En étape 1, les pointeurs avant et arrières de la structure tdl_timers autoréférencent la structure pour signifier que la liste est vide.
En étape 2, une temporisation de 5 ticks est insérée (bloc vert).
En étape 3, une temporisation de 3 ticks est insérée (bloc jaune). Pour trouver sa place, la liste est parcourue du début vers la fin et le champ delta de son descripteur est décrémenté de la valeur de chaque champ delta rencontré, tant que ce dernier est inférieur ou égal à sa valeur courante. Comme la première valeur rencontrée est 5 (donc supérieure), le nouveau descripteur est inséré devant le premier descripteur (bloc vert), dans lequel on prend soin de soustraire à son champ delta la valeur du même champ du descripteur nouvellement inséré (c.-à-d. 3). D'où la nouvelle valeur égale à 2 du champ delta du bloc vert. La première temporisation (bloc vert) tombera bien à échéance dans 5 ticks, ou plutôt 2 ticks après la temporisation de 3 ticks (bloc jaune) nouvellement insérée devant elle.
En étape 4, une nouvelle temporisation de 5 ticks (bloc noir) est insérée. Pour trouver sa place, on procède de même qu'à l'étape précédente, en parcourant la liste du début vers la fin. La position du nouveau descripteur sera donc juste avant le premier descripteur rencontré avec un champ delta supérieur ou lorsqu'on a atteint la fin de liste, comme dans cette étape. D'où la décrémentation de 3, puis 2 de son champ delta. Le champ est donc 0, car la temporisation associée doit tomber à échéance au même moment que la temporisation (bloc vert) située avant lui (c.-à-d. dans 3 + 2 + 0 = 5 ticks).
En étape 5, un arrêt avant terme est demandé pour la seconde temporisation (bloc jaune). Le descripteur est enlevé de la liste, mais on prend soin au préalable d'incrémenter le champ delta du descripteur situé juste après (bloc vert) avec la valeur du même champ du descripteur enlevé (c.-à-d. 2 + 3 = 5). Ainsi, le délai d'expiration de la temporisation associée sera bien dans 5 ticks.
À chaque pulsation de l'horloge, il suffit de décrémenter le champ delta du premier descripteur de la liste. Lorsque ce dernier atteint la valeur 0, toutes les temporisations associées aux descripteurs ayant leur champ delta à 0 en tête de liste sont échues. Leur descripteur est enlevé de la liste et la fonction utilisateur correspondante est appelée.
À l'image du système Minix, l'organisation des temporisations en liste delta est donc plutôt simple, car il est destiné avant tout à l'enseignement. Mais il n'en reste pas moins efficace et astucieux !
2.2 Allocation/désallocation
La fonction tdl_alloc() crée une temporisation. Elle reçoit en paramètre le type (cyclique ou non) de la temporisation. Le service alloue dynamiquement, via malloc(), une structure tdl_desc_t et retourne son adresse. Inutile de présenter le code source, car la fonction est triviale. De sorte à garder une opacité sur les structures de données internes au service, l'adresse retournée à l'utilisateur est un pointeur anonyme de type tdl_t défini dans le fichier d'en-tête tdl.h :
Ce pointeur servira de référence pour la temporisation dans les autres routines de l'API.
tdl_free() désalloue un descripteur de temporisation précédemment alloué par tdl_alloc(). Ce service, tout aussi trivial, reçoit en paramètre le descripteur et appelle la fonction free() pour libérer l'espace mémoire.
2.3 Armement/arrêt
La fonction tdl_start() démarre une temporisation. Elle reçoit en paramètres l'identifiant retourné par tdl_alloc(), la durée de la temporisation (en ticks), un pointeur sur une fonction à appeler au moment de l'échéance, ainsi qu'un pointeur sur un contexte à passer à cette dernière :
La boucle while du service met en œuvre l'algorithme de la liste delta vu plus haut pour insérer le descripteur au bon endroit dans la liste. L'API étant destinée à un environnement multithread, une exclusion mutuelle (sous la forme des macros TDL_LOCK/UNLOCK()) est nécessaire pour protéger l'accès à la liste des temporisations. Ici, le service d'exclusion mutuelle est basé sur les futex [4] (dans les fichiers mtx.c et mtx.h), mais on aurait aussi pu utiliser les services POSIX standard de la GLIBC, basés eux aussi, sur les futex. Les sémaphores System V sont par contre déconseillés pour leur lenteur !
Bien que le code source correspondant n'est pas exposé, la fonction gère aussi le redémarrage d'une temporisation avec une échéance éventuellement différente. Cela consiste à enlever le descripteur correspondant de la liste (comme le fait tdl_stop()), avant de le réinsérer à son nouvel emplacement.
La fonction tdl_stop() arrête une temporisation. Cette dernière reçoit en paramètre l'identifiant retourné par le service tdl_alloc() et déchaîne le descripteur de la liste des temporisations armées. Conformément à l'algorithme détaillé plus haut, s'il y a un successeur dans la liste, le champ delta de ce dernier est incrémenté avec la valeur du même champ dans le descripteur en cours de suppression :
2.4 La pulsation
L'API est dans une librairie partagée libtdl.so dont le point d'entrée démarre implicitement un thread. Ce dernier est en charge de gérer la pulsation qui décrémente le champ delta du premier descripteur de la liste. La période TDL_TICK_PERIOD du tick est de 1 milliseconde :
En espace utilisateur, différentes options s'offrent à nous pour générer le tick. Nous choisissons la fonction select() temporisée au sein d'une boucle infinie dans le point d'entrée tdl_engine() du thread. On gère aussi un pipe dont le côté en lecture tdl_fifo[0] est passé à select(). Cela permet à la fonction de sortie de la librairie (en cas de déchargement dynamique) d'envoyer un message pour signifier au thread de s'arrêter (sortie de la boucle infinie). Nous ne présentons ici que la section de code chargée de décrémenter le champ delta de la tête de la liste des temporisations. Quand ce champ atteint la valeur 0, la temporisation associée est échue. Il en est de même pour les descripteurs suivants.
2.5 Complexité
L'armement d'une temporisation (fonction tdl_start()) peut amener, dans le pire des cas, à parcourir toute la liste des temporisations armées afin d'insérer le descripteur en dernière position. Sa complexité est par conséquent O(N). L'arrêt d'une temporisation (fonction tdl_stop()) est par contre O(1), car le double chaînage permet d'extraire le descripteur de la liste sans la parcourir. La gestion de la pulsation dans la boucle du thread est aussi O(1), car seul le champ delta du premier descripteur de temporisation de la liste est décrémenté. La gestion de l'échéance des temporisations dans la boucle du thread est O(N), car dans le pire des cas, toutes les temporisations expirent en même temps. On ne peut pas faire mieux pour ce cas précis. Mais cela tient plus du cas d'école que d'une situation courante.
3. Algorithme de la roue des temporisations
3.1 Principe et structures de données
Le code source de la librairie ainsi que l'API mettant en œuvre l'algorithme se trouvent respectivement dans les fichiers ttw.c et ttw.h. Il se schématise comme une roue de bicyclette dont les rayons sont représentés par les listes de temporisations armées. L'écart entre les rayons correspond à la période de la pulsation. À chaque tick, la roue tourne sur une distance correspondant à l'espace entre deux rayons. Traduit en langage informatique, il s'agit d'un tableau de listes chaînées indexé de manière circulaire avec une opération modulo. À chaque pulsation, l'index circulaire s'incrémente d'une unité pour référencer l'entrée suivante dans la table où se trouvent éventuellement des temporisations qui doivent échoir à ce moment, ou après un ou plusieurs tours supplémentaires de la roue. La figure 2 illustre le propos.

Dans la figure, la roue présente 19 entrées (ticks). Dans certaines d'entre elles se trouvent des listes de temporisations armées. L'index circulaire courant dans la table est en position 2. À chaque pulsation, il est incrémenté par l'opération :
Cette opération retourne l'indice suivant entre 0 et la taille de la roue moins 1 (c.-à-d. entre 0 et 18 pour l'exemple de la figure). Il est actuellement à la position 2.
L'index de l'entrée de la liste du descripteur d'une temporisation est calculé avec l'opération suivante :
Mais son échéance n’arrivera qu'après un nombre de rotations correspondant à la division entière de la durée d'échéance par le nombre d'entrées dans la roue :
Ainsi sur la figure, la temporisation de 54 ticks est mise dans la liste à l'indice 18, mais elle ne sera échue qu'après 2 tours de roue. La temporisation de 6 ticks est, quant à elle, chaînée dans la liste à l'indice 8 et sera échue dès que l'index de la pulsation aura atteint cette valeur, car le nombre de rotations associé est à 0.
Le champ « nombre de rotations » des descripteurs est décrémenté à chaque fois que l'index courant de la pulsation référence leur entrée dans la roue. Cela signifie qu'à chaque tick, un parcours de bout en bout de la liste est effectué pour décrémenter les champs « nombre de rotations » différents de 0 (temporisations qui expireront dans les tours suivants) et enlever les descripteurs dont ce même champ est à 0 (temporisations échues dans le tour courant).
3.2 Allocation/désallocation
Les fonctions ttw_alloc() et ttw_free() sont triviales. Comme leurs homologues dans l'API de l'algorithme de la liste delta, elles consistent à allouer/désallouer un descripteur ttw_desc_t de temporisation :
La structure est calquée sur le descripteur de l'algorithme de la liste delta, à ceci près que le champ delta est remplacé par le champ rotations. Même si nous ne le détaillerons pas, il y a aussi en plus le lien cbk_link qui sert à lier le descripteur dans une liste provisoire lors de l'appel de la fonction utilisateur, à échéance de la temporisation.
La roue des temporisations est la table globale ttw_wheel[] allouée dynamiquement au démarrage avec TTW_SIZE entrées. Ce sont les têtes des listes de descripteurs de temporisation qui tomberont à échéance lorsque l'indice courant global ttw_index référencera leur entrée. Cet indice est incrémenté d'une unité à chaque pulsation de période TTW_TICK_PERIOD microsecondes.
3.3 Démarrage/arrêt
La fonction ttw_start() démarre une temporisation. Ses paramètres sont identiques à ceux de la même fonction pour l'algorithme précédent :
En fait, l'algorithme est une table de hachage qui ne dit pas son nom. La fonction de répartition étant l'opération modulo de la durée de la temporisation par TTW_SIZE afin de déterminer l'indice de la liste dans laquelle sera inséré le descripteur.
La fonction ttw_stop() arrête une temporisation. Elle reçoit en paramètre l'identifiant retourné par le service ttw_alloc(). Son code est trivial, car il s'agit tout simplement d'enlever le descripteur de la liste doublement chaînée des temporisations.
3.4 La pulsation
Comme pour l'algorithme précédent, le service démarre implicitement un thread dans le point d'entrée de la librairie partagée libttw.so. La pulsation est générée via l'appel système select() temporisé avec la période TTW_TICK_PERIOD. À chaque pulsation, le thread incrémente de manière circulaire (opération modulo avec TTW_SIZE) l'indice courant ttw_index dans la roue. Si la liste de l'entrée correspondante dans la table n'est pas vide, elle est parcourue d'un bout à l'autre pour déchaîner les descripteurs dont le champ rotations est à 0 (temporisations échues) et décrémenter ce même champ pour les autres (temporisations qui échoiront dans les tours suivants). Les fonctions utilisateur sont bien entendu appelées pour les temporisations expirées. Pour celles qui sont de type cyclique, le nouvel emplacement du descripteur dans la roue est calculé afin de le chaîner dans la liste correspondante.
3.5 Complexité
L'armement d'une temporisation (fonction ttw_start()) est O(1), car il s'agit d'insérer le descripteur en fin de liste à l'indice dans la roue correspondant à la durée de la temporisation. L'arrêt d'une temporisation (fonction ttw_stop()) est aussi O(1), car le double chaînage permet d'extraire le descripteur de sa liste sans la parcourir. La gestion de la pulsation dans la boucle du thread est O(N), car il faut parcourir tous les éléments de la liste située à l'indice courant dans la roue pour repérer les temporisations échues (champ rotations à 0) et décrémenter le champ rotations des temporisations qui échoiront dans les tours suivants. Dans le pire des cas, toutes les temporisations armées peuvent s'y trouver (cas d'école). De même, la gestion de l'échéance des temporisations dans la boucle du thread est O(N), car dans le pire des cas, toutes les temporisations expirent en même temps (cas d'école).
4. Fusion des algorithmes
Les rayons de la roue souffrent d'un parcours complet des listes de temporisations afin de repérer celles qui sont échues et de décrémenter le champ rotations pour les autres. C'est un parcours systématique sur toute la liste à l'échéance de la pulsation (complexité O(N) !). Pour éviter ou accélérer ce parcours complet [6], propose un ordonnancement de la liste. C'est justement l'idée de notre amélioration. Elle consiste à appliquer le principe de la liste delta sur chaque rayon de la roue. En clair, les deux algorithmes sont fusionnés. Le champ rotations, renommé delta_rotations, est géré comme le champ delta du premier algorithme présenté. Ainsi, à chaque pulsation de l'horloge, si le champ delta_rotations du premier descripteur de la liste courante est à 0, la temporisation correspondante ainsi que celles qui suivent avec le même champ à 0 sont échues. Sinon, on ne décrémente que le champ delta_rotations du premier descripteur de la liste. Il n'y a plus de parcours systématique de toute la liste ! L'algorithme résultant est donc une synthèse du meilleur des deux solutions précédentes. On l'appelle temporisations sur roue delta (ou TDW pour Timers on Delta Wheel).
Le code source de l'API est dans les fichiers tdw.c et tdw.h. La librairie partagée correspondante se nomme libtdw.so. Pour rester concis, nous ne détaillons pas les sources, car la description des deux premières API permet de comprendre la troisième. Nous sommes simplement partis du code source de la seconde dans laquelle la manipulation des listes chaînées de la roue utilise l'algorithme de la liste delta.
La figure 3 énumère la complexité des opérations dans chaque algorithme.

Nous avons amélioré le traitement de l'échéance de la pulsation qui passe de O(N) à O(1). C'est de bon augure pour la charge CPU moyenne induite par le service à chaque tick. Du côté de l'échéance des temporisations, même si la complexité théorique O(N) ne change pas, d'un point de vue purement pratique, nous nous trouvons très rarement dans le pire cas (c.-à-d. le cas où toutes les temporisations expirent en même temps). Ce sont donc les deux points essentiels d'amélioration apportés par la fusion.
Le démarrage de la temporisation passe de O(1) à O(N), car c'est le principe de la liste delta qui s'applique. C'est le prix, plus souvent théorique que pratique, à payer pour être O(1) au moment du traitement de la pulsation. Cependant, on peut noter qu'en positionnant la taille de la roue TDW_SIZE à 1, on n'a plus qu'un rayon. En d'autres termes, on a une seule liste correspondant tout simplement à l'algorithme de base de la liste delta. Augmenter le nombre d'entrées dans la roue revient à découper la liste delta en plusieurs listes plus courtes, de sorte à diminuer le temps moyen de parcours de la liste lors de l'insertion d'un nouveau descripteur de temporisation. Le temps de démarrage d'une temporisation est donc en pratique meilleur quand le nombre d'entrées dans la roue augmente.
Conclusion
Améliorer un algorithme s'apparente souvent à réinventer la roue, tant l'effort peut être vain. L'algorithme universel qui répond à tous les besoins n'existe pas en général. Le choix est guidé par les capacités matérielles (CPU, mémoire), le profil d'exécution (quantité de ressources simultanées) ou encore la latence du service (temps de réponse moyen stable ou tolérance de certains pics de charge). La gestion des temporisations présentée dans cet écrit synthétise le meilleur de deux algorithmes. Sans vouloir s'imposer comme une nouvelle référence, il a le mérite d'élargir le choix en la matière [7].
Les exemples d'implémentation de cet article doivent être plus robustes et configurables pour un usage dans des applications. Une version améliorée de la librairie TDW est disponible sous licence LGPL [8].
Références
[1] Le système Minix : https://fr.wikipedia.org/wiki/Minix
[2] Reinventing the timer wheel : https://lwn.net/Articles/646950/
[3] Attaque par déni de service : https://fr.wikipedia.org/wiki/Attaque_par_d%C3%A9ni_de_service
[4] R. KOUCHA, « Approche détaillée des futex », GNU/Linux Magazine n° 173, 175, 176 et 178 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-173/Approche-detaillee-des-futex-partie-1-4 pour le premier.
[5] An embedded Single Timer Wheel :
https://www.drdobbs.com/embedded-systems/an-embedded-single-timer-wheel/217800350
[6] G. VARGHESE et T. LAUCK, « Data Structures for the Efficient Implementation of a Timer Facility » : http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf
[7] A. COLYER, « Data structures for the efficient implementation of a timer facility » :
https://blog.acolyer.org/2015/11/23/hashed-and-hierarchical-timing-wheels/
[8] La librairie TDW : https://sourceforge.net/projects/tdwheel/



