


À l'origine, à travers les sémaphores des outils de communication inter-processus (IPC), System V, Unix et par la suite Linux offraient des mécanismes de synchronisation assez lourds en termes de performance. Ces derniers ont peu à peu cédé la place à la notion de futex, issue des travaux de H. Franke, R. Russel et M. Kirkwood [1]. Linux propose ce mécanisme à partir de sa version 2.5.7.Déjà introduit en 2008 dans la rubrique « Kernel Corner » du numéro 106 de ce magazine, cette série d'articles propose un retour plus détaillé sur les futex, afin de comprendre leur efficacité, d'appréhender le code source du noyau Linux qui les implémente et des librairies open source qui les utilisent. De plus, depuis 2008, les futex proposent des opérations supplémentaires qui seront étudiées ici.
Véritables goulots d'étranglement à mesure de la généralisation de Linux sur des serveurs très sollicités, des processus multi-thread, des machines SMP et des environnements pseudo temps-réel, les sémaphores System V cèdent peu à peu la place aux futex.
Si un futex, contraction de l'expression anglo-saxonne « Fast User Space Mutex », était à l'origine destiné à l'implémentation de mutex efficaces, ils se sont généralisés comme des bases pour de nombreux mécanismes de synchronisation évolués (sémaphores, variables conditionnelles...). Le principe consiste à minimiser autant que possible le nombre d'appels système coûteux en termes de performance. À l'instigation des développeurs de la GLIBC, cette solution particulièrement adaptée au multi-threading a subi de nombreuses améliorations pour devenir la pierre angulaire des fonctions de synchronisation des threads POSIX.
L'utilisation des futex n'est pas aisée au premier abord. Il existe certes un manuel en ligne (i.e. man futex), mais il est succinct et n'est pas à jour du fait des évolutions constantes. L'utilisation par le programmeur moyen y est même déconseillée : « As these semantics involve writing non-portable assembly instructions, this in turn probably means that most users will in fact be library authors and not general application developers. » (sic).
Cet article se propose donc de démystifier les futex.
1. Des sémaphores System V aux futex
1.1 Exemple de mise en œuvre d'un sémaphore System V
Pour utiliser un sémaphore, il est d'abord nécessaire d'obtenir un identifiant via l'appel système semget(). Puis, les opérations sont effectuées à l'aide de l'appel système semop(), tandis que la destruction est réalisée par l'appel système semctl().
Le programme décrit dans le listing suivant (fichier ipc.c), consiste en deux threads. Le second met à jour la variable globale data avec le compteur de secondes traduit sous forme de chaîne de caractères, tandis que le premier affiche la valeur courante du compteur sur demande de l'opérateur. Les deux flux d'exécution se disputent la même ressource data pour la modifier ou la lire. Le conflit d'accès est résolu par le sémaphore semid, qui synchronise les deux threads en garantissant un accès exclusif à la variable dans les deux sections critiques où elle est modifiée ou lue (cf. les lignes de code rouge dans le listing). Ainsi, le thread principal lira toujours une valeur cohérente de la chaîne de caractères.
[...]
#define NB_SECONDS 20
static char *str_second[NB_SECONDS] =
{
"zero", "un", "deux", "trois", "quatre", "cinq",
"six", "sept", "huit", "neuf", "dix",
"onze", "douze", "treize", "quatorze", "quinze",
"seize", "dix sept", "dix huit", "dix neuf"
};
char data[100];
static int semid;
struct sembuf sembuf_for_P = {0, -1, SEM_UNDO};
struct sembuf sembuf_for_V = {0, +1, SEM_UNDO};
#define P(id) semop(id, &sembuf_for_P, 1)
#define V(id) semop(id, &sembuf_for_V, 1)
static void *thd_main(void *p)
{
unsigned int i = 0;
while(1)
{
// Mise à jour du compteur en ASCII
P(semid);
strcpy(data, str_second[i]);
V(semid);
// Attente d'une seconde
sleep(1);
// Incrémentation du compteur dans la plage [0, NB_SECONDS[
i = (i + 1) % NB_SECONDS;
}
return NULL;
}
int main(int ac, char *av[])
{
int rc;
pthread_t tid;
unsigned short val = 1;
// Création du sémaphore
semid = semget(IPC_PRIVATE, 1, IPC_CREAT|0777);
// Initialisation du sémaphore à la valeur 1
semctl(semid, 0, SETALL, &val);
// Création du thread
rc = pthread_create(&tid, NULL, thd_main, NULL);
// Interaction avec l’opérateur
while(fgetc(stdin) != EOF)
{
// Affichage de la valeur ASCII courante du compteur
P(semid);
printf("Compteur courant: %s\n", data);
V(semid);
}
Après compilation et exécution du programme, il suffit de taper sur la touche <ENTREE> pour que la fonction fgetc(), dans le thread principal, retourne et permette l'affichage de la valeur courante du compteur, mis à jour en parallèle par le thread secondaire toutes les secondes :
$ gcc ipc.c -o ipc -lpthread
$ ./ipc
Compteur courant: dix
Compteur courant: treize
<CTRL D>
$
L'utilitaire strace (avec l'option -f pour espionner tous les threads du processus) donne une très bonne idée des appels au système Linux pendant l'exécution de ce programme :
$ strace -f ./ipc
[...]
[pid 13265] semop(16678923, 0x8049ab0, 1) = 0
[pid 13265] semop(16678923, 0x8049ab6, 1) = 0
[pid 13265] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 13265] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 13265] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 13265] nanosleep({1, 0}, {1, 0}) = 0
[...]
[pid 13264] <... read resumed> "\n", 4096) = 1
[pid 13264] semop(16678923, 0x8049ab0, 1) = 0
[pid 13264] write(1, "Compteur courant: six\n", 22Compteur
courant: six
) = 22
[pid 13264] semop(16678923, 0x8049ab6, 1) = 0
[pid 13264] read(0, <unfinished ...>
[pid 13265] <... nanosleep resumed> {1, 0}) = 0
[pid 13265] semop(16678923, 0x8049ab0, 1) = 0
[pid 13265] semop(16678923, 0x8049ab6, 1) = 0
[pid 13265] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 13265] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 13265] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 13265] nanosleep({1, 0}, {1, 0}) = 0
[...]
En jaune, le thread secondaire avec le pid 13265 est dans sa boucle infinie de mise à jour du compteur toutes les secondes : nous voyons les appels aux services semop() dans le noyau pour effectuer les opérations P() et V() sur le sémaphore, afin de protéger la mise à jour de l'emplacement mémoire data. Ensuite, le thread s'endort une seconde avec l'appel à la fonction sleep() de la librairie C, qui aboutit à l'appel système nanosleep().
En vert, le thread principal avec le pid 13264, est en attente sur l'entrée standard via la fonction fgetc() de la librairie C, qui se traduit par un appel bloquant au service read() du noyau. Quand l'opérateur appuie sur la touche <ENTREE>, read() rend la main et le thread fait appel aux services semop() dans le noyau pour effectuer les opérations P() et V() sur le sémaphore, afin de protéger la lecture de l'emplacement mémoire data et d'imprimer à l'écran son contenu via l'appel système write(), sous-jacent à la fonction printf() de la librairie C.
1.2 Les problèmes de performance
L'exemple précédent, et notamment les informations affichées par l'outil strace, montrent que le thread secondaire a recours au noyau via l'appel semop(), même s'il n'y a pas conflit d'accès sur data(tant que l'opérateur n'appuie pas sur la touche <ENTREE>, il n'y a pas conflit d'accès sur la ressource partagée). Ces appels systématiques au noyau par le thread secondaire sont consommateurs de temps CPU. Dans un contexte pseudo temps réel, ou des applications nécessitant une grande vitesse d'exécution comme par exemple les outils de gestion de bases de données, ce comportement est rédhibitoire.
Pour remédier à ce problème de performance, il faut éviter de solliciter le noyau quand le sémaphore est libre. Le document [1] propose une solution à travers la notion de futex introduite à partir de la version 2.5.7 de Linux. Diverses corrections et améliorations ont été apportées dans les moutures suivantes du système d'exploitation.
1.3 Principe des futex
Pour l'accès à la ressource partagée (la variable data dans notre exemple), on différencie les situations non conflictuelles (i.e. aucune tâche n'a pris le contrôle dessus) de celles où il y a conflit d'accès (i.e. une tâche a le contrôle dessus). Dans le premier cas, les traitements sont réalisés en espace utilisateur. Le recours aux services du noyau se limite au second cas. C'est là que réside la grande différence entre les sémaphores System V et les futex en termes de performance : les premiers font systématiquement appel au noyau en cas de conflit ou non sur la ressource partagée, tandis que les seconds ne sollicitent le noyau qu'en cas de conflit.
Plus précisément, un futex est une variable de type entier, partagée par les threads ou les processus qui se synchronisent. Par conséquent, il peut être tout simplement défini globalement s'il n'est partagé que par les threads d'un même processus, ou situé dans un segment de mémoire partagée s'il est partagé par des threads au sein de plusieurs processus.
La variable ainsi partagée contient un état modifié en espace utilisateur à l'aide d'opérations atomiques (cf. [2]). Quand l'état de la variable indique qu'il n'y a pas de conflit, aucun appel système n'est nécessaire. Dans le cas contraire, le noyau est sollicité à l'aide de l'appel système futex() pour mettre en sommeil la tâche appelante ou réveiller des tâches en attente. Ce mécanisme relativement simple est la base pour implémenter des services beaucoup plus évolués comme les mutex et les rwlocks entre autres. Par exemple, les fonctions POSIX de synchronisation des threads dans la GLIBC/NPTL (i.e. Native Posix Thread Library décrite dans [3]) sont basées sur les futex : pthread_mutex_lock(), pthread_cond_signal(),pthread_rwlock_rdlock()...
N'étant pas toujours disponibles dans les langages de programmation évolués comme le langage C, les opérations atomiques nécessitent le recours au langage assembleur. Cela pose des problèmes de portabilité d'une architecture à l'autre et c'est la raison pour laquelle le manuel en ligne indique que les futex sont plutôt réservés aux développeurs des librairies telles que la GLIBC, qui cachent les spécificités des différentes plateformes par des services standardisés de haut niveau. Mais certains compilateurs proposent des facilités pour éviter la programmation en assembleur. Par exemple, [4] décrit les « built-ins » disponibles pour certaines opérations atomiques avec le compilateur GCC.
1.4 Le programme ipc revu avec un futex
La figure 1 décrit le comportement du programme d'exemple ipc du programme de la section 1.1 quand il est basé sur un futex au lieu d'un IPC. Les opérations atomiques sont mises en valeur avec la couleur rouge. La séquence schématisée se situe au moment où l'opérateur a saisi la touche <ENTREE> pour débloquer la fonction fgetc() dans le thread principal. Le futex est représenté par la variable globale futex_var de type entier. Dans la boucle du thread principal, l'opération P() est remplacée par l'opération atomique qui consiste à positionner la variable futex_var à 1 si sa valeur courante est 0.
Pendant ce temps, le thread secondaire effectue la même opération, mais ne change pas le contenu de la variable futex_var, car elle a été modifiée par le thread principal et a donc la valeur 1 au lieu de 0. Il se met alors en sommeil en appelant le service futex() du noyau. Le thread principal continue dans sa lancée en affichant le contenu de la variable data, puis effectue l'opération V(), qui consiste à mettre la valeur 0 dans la variable futex_var de manière atomique. Puis, il appelle le service futex() du noyau pour réveiller le thread secondaire. Ce dernier teste de nouveau le contenu de la variable futex_var et le met à 1 atomiquement, afin de bloquer le thread principal si celui-ci veut consulter la variable data pendant sa mise à jour. Une fois la mise à jour terminée, le futex est de nouveau remis à 0 atomiquement et les éventuels threads en attente sont réveillés par l'appel futex() avant d'appeler de nouveau sleep()...
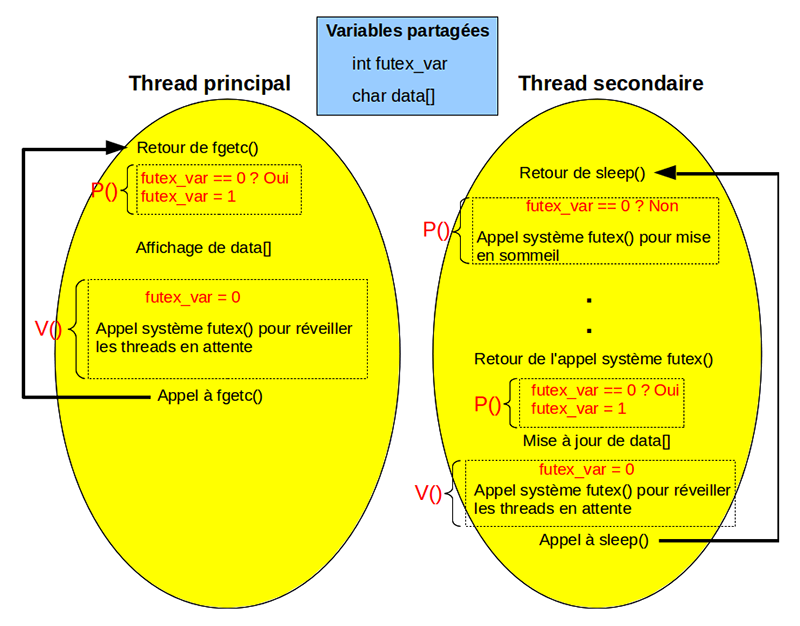
Dans cette séquence, l'opération P() ne nécessite pas d'appel système futex() quand il n'y a pas conflit, ce qui est une différence majeure par rapport aux sémaphores System V, où P() entraîne forcément un appel système qu'il y ait conflit ou non ! Par contre, l'opération V() se termine systématiquement par un appel à futex() pour réveiller les éventuels threads en attente. Dans la suite, il sera montré qu'il est possible d'être encore plus efficace sur l'opération V(), en appelant futex() seulement quand un thread est en sommeil.
2. L'appel système futex()
2.1 Le prototype
La section 7 du manuel en ligne donne une description générale, tandis que la section 2 décrit l'appel système futex() avec le prototype ci-après :
$ man futex
FUTEX(2) Linux Programmer’s Manual FUTEX(2)
NAME
futex - Fast Userspace Locking system call
SYNOPSIS
#include <linux/futex.h>
#include <sys/time.h>
int futex(int *uaddr, int op, int val, const struct timespec *timeout,
int *uaddr2, int val3);
[...]
Le paramètre op, dont les différentes valeurs possibles sont définies dans le fichier d'en-tête <linux/futex.h>, détermine le comportement de la fonction.
2.2 Invocation
Considérons le fichier futex.c, dont le listing est donné dans la suite et qui utilise l'appel système comme préconisé dans le manuel.
#include <linux/futex.h>
int main(int ac, char *av[])
{
int rc;
rc = futex((int *)0, 0, 0, (const struct timespec *)0, (int *)0, 0);
return 0;
}
La compilation se termine en erreur, car la fonction futex() n'existe pas dans la librairie C :
$ gcc futex.c
/tmp/ccGwg1Zs.o: In function `main’:
futex.c:(.text+0x41): undefined reference to `futex’
collect2: ld returned 1 exit status
Mais le service existe au sein de Linux, car il est répertorié dans le fichier d'en-tête standard <sys/syscall.h> :
$ cat /usr/include/bits/syscall.h | grep -i futex
#define SYS_futex __NR_futex
Il faut passer le code SYS_futex à la fonction syscall() pour déclencher le service dans le noyau, comme le montre le code de la version modifiée du fichier futex.c :
#include <sys/syscall.h>
#define futex(a, b, c, d, e, f) syscall(SYS_futex, a, b, c, d, e, f)
int main(int ac, char *av[])
{
int rc;
rc = futex((int *)0, 0, 0, (const struct timespec *)0, (int *)0, 0);
return 0;
}
2.3 Les paramètres
Le paramètre uaddr est l'adresse de la variable du futex. Le paramètre op est le code de l'opération à réaliser sur le futex. Les valeurs de ce dernier, définies dans le fichier d'en-tête <linux/futex.h>, déterminent la signification des paramètres qui suivent :
[...]
#define FUTEX_WAIT 0
#define FUTEX_WAKE 1
#define FUTEX_FD 2
#define FUTEX_REQUEUE 3
#define FUTEX_CMP_REQUEUE 4
#define FUTEX_WAKE_OP 5
#define FUTEX_LOCK_PI 6
[...]
Par exemple :
- Lorsque op vaut FUTEX_WAIT, l'appel système vérifie de manière atomique que l'emplacement mémoire à l'adresse uaddr contient bien la valeur stockée dans val. Si ce n'est pas le cas, futex() retourne immédiatement la valeur -1 et le code d'erreur dans errno à EAGAIN(synonyme de EWOULDBLOCK), sinon il met le thread appelant en attente. Cette attente dure jusqu'à ce qu'un autre thread appelle futex() avec l'opération FUTEX_WAKE, ou à échéance de la temporisation dont la valeur est stockée dans le paramètre timeout s'il n'est pas égal à NULL. Les paramètres suivants sont ignorés. Lorsque le retour résulte d'une opération FUTEX_WAKE exécutée par un autre thread, la valeur retournée est 0. S'il résulte de l'échéance de la temporisation, le code de retour est -1 et errno est positionné à ETIMEDOUT.
- Quand op vaut FUTEX_WAKE, le paramètre val indique le nombre maximum de threads à réveiller. Les arguments suivants sont ignorés. La valeur de retour est égale au nombre de threads réveillés.
2.4 Création et initialisation
S'il est partagé par plusieurs threads au sein d'un même processus, le futex est une simple variable globale ou un entier alloué dynamiquement par malloc().
S'il est partagé par des threads s'exécutant dans divers processus, l'entier sera localisé dans un segment de mémoire partagée créé via un IPC (i.e. appels système shmget() et shmat()), ou par appel au service POSIX shm_open() suivi de mmap()...
Nous verrons ces différentes méthodes de définition des futex à travers les programmes d'exemples qui suivent.
2.5 Destruction
Détruire un futex signifie en premier lieu n'avoir aucun thread en attente dessus, afin que les structures de données qui lui sont associées dans le noyau soient désallouées. Ensuite, côté espace utilisateur, la destruction en elle-même est fonction de la méthode utilisée pour l'allouer. Si c'est une simple variable globale, le fait de ne plus avoir de thread en attente dessus fait que le futex n'existe plus, même si la variable est persistante pendant la durée de vie du programme. Si c'est une allocation dynamique via malloc(), un free() le désallouera. Si c'est un mmap(), on utilisera munmap()...
3. Exemples d'applications
3.1 Implémentation d'un mutex
Un mutex est un verrou à deux états : ouvert ou fermé. Il est typiquement utilisé pour protéger les portions de code qui nécessitent un accès exclusif à une ressource partagée entre threads concurrents. Ces portions de code sont appelées « sections critiques ». En général, deux opérations sont définies : LOCK() et UNLOCK() pour respectivement verrouiller et déverrouiller la section critique.
L'exemple du premier listing (section 1.1) est une application de ce principe : les sections critiques sont les portions de code encadrées par les opérations P() et V() (terminologie préférée à LOCK()/UNLOCK() quand il s'agit de sémaphores). Le listing suivant en présente une version non plus basée sur les sémaphores System V, mais sur un mutex construit à l'aide d'un futex. Les parties de code source communes entre ces deux programmes ont été volontairement élaguées.
[...]
int futex_var;
#define futex_wait(addr, val) \
syscall(SYS_futex, addr, FUTEX_WAIT, val, NULL)
#define futex_wakeup(addr, nb) \
syscall(SYS_futex, addr, FUTEX_WAKE, nb)
static void LOCK(int *f)
{
int old;
while (1)
{
old = __sync_val_compare_and_swap(f, 0, 1);
if (0 == old)
{
// Le futex était libre car il contenait la valeur 0
// et maintenant il contient la valeur 1
return;
}
else
{
// Le mutex contient la valeur 1 : l’autre thread l’a pris
// ==> Attente tant que le futex a la valeur 1
futex_wait(f, 1);
}
}
}
static void UNLOCK(int *f)
{
int old;
old = __sync_fetch_and_sub(f, 1);
futex_wakeup(f, 1);
}
static void *thd_main(void *p)
{
unsigned int i = 0;
while(1)
{
// Mise à jour du compteur en ASCII
LOCK(&futex_var);
strcpy(data, str_second[i]);
UNLOCK(&futex_var);
// Attente d’une seconde
sleep(1);
// Incrémentation du compteur dans la plage [0, NB_SECONDS[
i = (i + 1) % NB_SECONDS;
}
return NULL;
}
int main(int ac, char *av[])
{
int rc;
pthread_t tid;
unsigned short val = 1;
// Création du thread
rc = pthread_create(&tid, NULL, thd_main, NULL);
// Interaction avec l’opérateur
while(fgetc(stdin) != EOF)
{
// Affichage de la valeur ASCII courante du compteur
LOCK(&futex_var);
printf("Compteur courant: %s\n", data);
UNLOCK(&futex_var);
}
}
Le futex est représenté par la variable globale futex_var.
Les opérations FUTEX_WAIT et FUTEX_WAKE sont respectivement définies sous la forme des macro-instructions futex_wait() et futex_wakeup(). L'opération LOCK() est très intéressante. Elle doit effectuer une opération atomique en espace utilisateur et, en fonction du résultat, elle verrouille le mutex ou met le thread appelant en sommeil. L'opération en question est « compare and swap » (CAS), décrite dans Wikipédia [5], qui reçoit trois paramètres. Elle consiste à comparer le contenu du futex (premier paramètre) avec la valeur 0 (contenu du second paramètre). S'il y a égalité, alors le futex prend la valeur 1 (contenu du troisième paramètre). S'il n'y a pas égalité, le futex n'est pas modifié. Dans tous les cas, l'opération retourne la valeur du futex juste avant l'appel. Normalement, une telle opération nécessite d'être écrite en assembleur.
Par exemple, sur Intel, c'est l'instruction cmpxchg [5] qu'il faut préfixer par l'instruction lock pour les architectures SMP, afin de garantir l'usage exclusif de l'emplacement mémoire au processeur en cours d'exécution :
mov 0x8(%ebp),%eax ; EAX = @f
mov %eax,0xffffffe8(%ebp) ; old = EAX = @f
mov $0x0,%ecx ; ECX = 0
mov $0x1,%edx ; EDX = 1
mov 0xffffffe8(%ebp),%ebx ; EBX = old = @f
mov %ecx,%eax ; EAX = ECX = 0
lock cmpxchg %edx,(%ebx) ; Si *EBX (f) == EAX (0) alors *EBX (f) = EDX (1)
; Sinon EAX = *EBX (f)
mov %eax,%edx ; EDX = EAX
mov %edx,0xfffffff8(%ebp) ; old = EDX = résultat de cmpxchg
Et voici l'équivalent sur une plateforme PowerPC 32 bits qui se base sur la technique « load-link and store-conditional » (LL/SC) à l'aide des instructions lwarx et stwcx(voir explication dans Wikipédia [6]) :
stwu r1,-48(r1)
mflr r0
stw r0,52(r1)
stw r31,44(r1)
mr r31,r1
stw r3,24(r31)
lwz r9,24(r31)
li r11,1
sync
lwarx r0,0,r9
cmpwi r0,0
bne- 100005bc <LOCK+0x40>
mr r10,r11
stwcx. r10,0,r9
bne- 100005a0 <LOCK+0x24>
isync
stw r0,8(r31)
lwz r0,8(r31)
Heureusement, quand on utilise GCC, on peut compter sur les « built-ins » [4], qui permettent d'avoir un code relativement portable d'une architecture à l'autre, car on laisse au compilateur le soin de générer les instructions adaptées à la plateforme utilisée. Ainsi, nul besoin d'être un spécialiste de l'assembleur de toutes les machines auxquelles le projet est destiné : __sync_val_compare_and_swap() répond au besoin.
En résumé, le résultat de la « built-in » de GCC permet de savoir si le futex est à 0 ou à 1. Dans le premier cas, cela veut dire que le mutex est libre et qu'on peut le verrouiller (i.e. __sync_val_compare_and_swap()met le futex à la valeur 1). Dans le second cas, le mutex est verrouillé (i.e. le futex a déjà la valeur 1) et donc, le thread appelant se met en sommeil via l'opération FUTEX_WAIT de l'appel système futex(), jusqu'à ce que le mutex soit déverrouillé via la fonction UNLOCK().
L'opération UNLOCK() est beaucoup plus simple que LOCK() : le futex est repassé à la valeur 0 grâce à la « built-in » __sync_fetch_and_sub() de GCC, qui le décrémente atomiquement. Son principe consiste à retourner ce qui est stocké à l'adresse passée en premier paramètre (opération fetch dans le nom), avant de lui soustraire la valeur passée en deuxième paramètre (opération sub dans le nom). Il faut voir ce service comme la version atomique de la post-soustraction « (*f)-- » du langage C. Puis, les éventuels threads en attente sont réveillés via l'opération FUTEX_WAKE de l'appel système futex().
Le reste du programme reste identique à celui du premier listing de la section 1.1, sauf qu'il n'y a plus d'IPC à initialiser, car la variable globale futex_var s'est substituée et que les appels P() et V() sont respectivement remplacés par LOCK() et UNLOCK().
3.1.1 Exécution du programme d'exemple
Le fichier source du code précédent peut être compilé comme suit sur plateforme Intel 32 bits :
$ gcc mutex.c -o mutex -lpthread
Pour certaines architectures de PC, on notera le recours à l'option -march du compilateur, afin qu'il ne génère pas du code i386 qui ne supporte pas les opérations générées par les « built-ins » __sync_val_compare_and_swap() et __sync_fetch_and_sub() :
$ gcc mutex.c -o mutex -lpthread
/tmp/ccOfVXw3.o: In function `LOCK’:
mutex.c:(.text+0x1d): undefined reference to `__sync_val_compare_and_swap_4’
/tmp/ccOfVXw3.o: In function `UNLOCK’:
mutex.c:(.text+0x6e): undefined reference to `__sync_fetch_and_sub_4’
collect2: ld returned 1 exit status
$ gcc mutex.c -o mutex -lpthread -march=i486
L'exécution du programme mutex avec l'outil strace met tout de suite en avant la grande différence avec le programme ipc basé sur les IPC : il y a moins d'appels système. Comme précédemment, les traces relatives au thread principal sont en vert, tandis que celles du thread secondaire sont en jaune :
$ strace -f ./mutex
[...]
[pid 15956] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 15956] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 15956] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 15956] nanosleep({1, 0}, {1, 0}) = 0
[pid 15956] futex(0x8049a20, FUTEX_WAKE, 1) = 0
[pid 15956] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 15956] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 15956] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 15956] nanosleep({1, 0}, <unfinished ...>
[pid 15955] <... read resumed> "\n", 4096) = 1
[pid 15955] fstat64(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 3), ...}) = 0
[pid 15955] mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS,
-1, 0) = 0xb7f3d000
[pid 15955] write(1, "Compteur courant: six\n", 22Compteur courant: six
) = 22
[pid 15955] futex(0x8049a20, FUTEX_WAKE, 1) = 0
[pid 15955] read(0, <unfinished ...>
[pid 15956] <... nanosleep resumed> {1, 0}) = 0
[pid 15956] futex(0x8049a20, FUTEX_WAKE, 1) = 0
[pid 15956] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 15956] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 15956] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 15956] nanosleep({1, 0}, {1, 0}) = 0
[...]
Sur l'opération LOCK(), le thread vérifie en espace utilisateur (donc sans appel système !) si le futex est nul, et le met à 1 de manière atomique pour le verrouiller. Cette opération n'engendre un appel système futex() avec l'opération FUTEX_WAIT que si le futex vaut 1 (i.e. verrouillé par l'autre thread). Dans la fonction P() équivalente, le programme du premier code exécute systématiquement l'appel système semop(). Par contre, les deux threads appellent toujours le système avec l'opération FUTEX_WAKE via UNLOCK() une fois le futex remis atomiquement à 0, afin de réveiller l'éventuel autre thread en attente. On n'a donc économisé les appels système que sur l'opération de verrouillage. Nous allons voir comment on peut aussi optimiser le nombre d'appels au noyau lors du déverrouillage.
3.1.2 Amélioration des performances
Il est possible d'aller plus loin dans la minimisation des appels au système. En effet, le traçage du programme mutex montre qu'on a un appel systématique au service système FUTEX_WAKE lors de l'appel à la fonction UNLOCK(), alors que la plupart du temps, il n'y a pas de thread en attente sur le futex. Dans son article [7], Ulrich Drepper propose une solution à ce problème en ajoutant un état supplémentaire au futex. En d'autres termes, il peut prendre les valeurs 0, 1 et 2, qui signifient respectivement :
- Déverrouillé (0) ;
- Verrouillé sans threads en attente (1) ;
- Verrouillé avec des threads en attente (2).
L'appel au système pour exécuter l'opération FUTEX_WAKE ne se fera donc qu'à la condition où le futex est dans l'état 2 (i.e. des threads sont en attente). Les fonctions LOCK() et UNLOCK() sont revues comme indiqué dans le listing suivant. Elles sont légèrement plus complexes que leur version d'origine dans le code précédent (section 3.1). Le reste du programme restant identique à ce listing précédent n'est pas reproduit.
[...]
static void LOCK(int *f)
{
int old;
old = __sync_val_compare_and_swap(f, 0, 1);
switch(old)
{
case 0:
{
// Le futex était libre car il contenait la valeur 0
// et maintenant il contient la valeur 1 car au moment
// de l’opération atomique il n’y avait pas de thread
// en attente
return;
}
break;
default:
{
// Le mutex contient la valeur 1 ou 2 : il est occupé car
// un autre thread l’a pris
// On positionne le futex à la valeur 2 pour indiquer qu’il
// y a des threads en attente
old = __sync_lock_test_and_set(f, 2);
while (old != 0)
{
// Attente tant que le futex a la valeur 2
futex_wait(f, 2);
// Le futex a soit la valeur 0 (libre) ou 1 ou 2
old = __sync_lock_test_and_set(f, 2);
}
}
break;
}
}
static void UNLOCK(int *f)
{
int old;
old = __sync_fetch_and_sub(f, 1);
switch(old)
{
case 1:
{
// Il n’y avait pas de thread en attente
// ==> Personne à réveiller
}
break;
case 2:
{
// Il y avait des threads en attente
// Le futex a la valeur 1, on le force à 0
old = __sync_lock_test_and_set(f, 0);
// Réveil des threads en attente
futex_wakeup(f, 1);
}
break;
default:
{
// Impossible
}
}
}
[...]
En cas de conflit, la fonction LOCK() force le futex à la valeur 2 pour indiquer qu'il y a un thread en attente. Pour cette opération qui doit être atomique, GCC propose la « built-in » __sync_lock_test_and_set(). Désassemblée sur plateforme Intel, cette « built-in » n'est autre que l'instruction xchg (le préfixe Intel lock n'est pas utile pour cette dernière, car le manuel [8] indique que cette instruction effectue implicitement l'opération lock quand un des opérandes est une adresse en mémoire). Désassemblée sur architecture Intel 32 bits, l'instruction en langage C « old = __sync_lock_test_and_set(f, 2) » se traduit par :
mov 0x8(%ebp),%eax ; EAX = f
mov $0x2,%edx ; EDX = 2
xchg %edx,(%eax) ; *f = 2 et EDX = ancienne valeur de *f
mov %edx,0xfffffff8(%ebp) ; old = ancienne valeur de *f
La fonction UNLOCK(), quant à elle, ne va faire l'appel système futex() qu'à la condition où le futex est dans l'état 2 indiquant un thread en attente. Dans ce cas, il faut bien entendu au préalable forcer atomiquement le futex à la valeur 0 pour que le thread réveillé le voie libre.
Après compilation de cette nouvelle mouture du programme mutex, l'outil strace montre qu'il n'y a plus d'appel systématique à futex() dans la fonction UNLOCK() :
$ gcc mutex_1.c -o mutex_1 -lpthread
$ strace -f ./mutex_1
[...]
[pid 24759] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 24759] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 24759] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 24759] nanosleep({1, 0}, {1, 0}) = 0
[pid 24759] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 24759] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 24759] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 24759] nanosleep({1, 0},
<unfinished ...>
[pid 24758] <... read resumed> "\n", 4096) = 1
[pid 24758] fstat64(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 3), ...}) = 0
[pid 24758] mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS,
-1, 0) = 0xb7f39000
[pid 24758] write(1, "Compteur courant: trois\n", 24Compteur courant: trois
) = 24
[pid 24758] read(0, <unfinished ...>
[pid 24759] <... nanosleep resumed> {1, 0}) = 0
[pid 24759] rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0
[pid 24759] rt_sigaction(SIGCHLD, NULL, {SIG_DFL, [], 0}, 8) = 0
[pid 24759] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 24759] nanosleep({1, 0}, {1, 0}) = 0
[...]
Pour le lecteur qui voudrait aller plus loin sur le sujet de l'optimisation, la page [9] propose un algorithme qui serait encore plus efficace en ajoutant un quatrième état aux trois précédemment définis pour le futex :
- Déverrouillé (0) ;
- Verrouillé sans threads en attente (1) ;
- Verrouillé avec des threads en attente (2) ;
- Déverrouillé avec des threads en attente (3).
3.2 Synchronisation sur fin de thread
Ici, nous voyons un cas de synchronisation entre un service du noyau de création d'un thread et l'espace utilisateur. Le programme clone du code suivant est un exemple de création d'un thread. Le thread créé par le service pthread_create() affiche le message « Bonjour de la part du thread secondaire » avant de se terminer et le thread principal, après avoir attendu la fin du thread secondaire via le service pthread_join(), affiche le message « Fin du programme ».
[...]
#define STR_BONJOUR "Bonjour de la part du thread secondaire\n"
#define STR_FIN "Fin du programme\n"
void *thd_main(void *p)
{
write(1, STR_BONJOUR, sizeof(STR_BONJOUR) - 1);
return NULL;
} // thd_main
int main(int ac, char *av[])
{
pthread_t tid;
// Création du thread
pthread_create(&tid, NULL, thd_main, NULL);
// Attente de la fin du thread
pthread_join(tid, NULL);
write(1, STR_FIN, sizeof(STR_FIN) - 1);
return 0;
} // main
L'intérêt de cet exemple réside dans la manière dont les threads se synchronisent de sorte à ne pas terminer le thread principal, donc le processus dans son ensemble, avant que le thread secondaire n'ait eu le temps de s'exprimer :
$ gcc clone.c -o clone
$ ./clone
Bonjour de la part du thread secondaire
Fin du programme
En utilisant l'utilitaire strace, on voit ce qui est réalisé par le système. Tout d'abord, pthread_create() alloue la pile, le TCB (de l'anglo-saxon Task Control Block, ou descripteur de tâche en français) et la page de garde (ou zone rouge) de protection contre les débordements de la pile. Pour cela, l'appel système getrlimit() permet de connaître la taille par défaut de la pile (8192 x 1024 soit 8 MB). Ensuite, mmap() permet d'allouer l'espace en mémoire virtuelle (à l'adresse 0x7fc556389000) pour contenir à la fois la zone rouge, la pile et le TCB d'une taille totale de 8392704 octets. Puis, mprotect() sert à créer la page de garde en interdisant la lecture, l'écriture et l'exécution (i.e. PROT_NONE) sur les 4096 premiers octets de cet espace (vu que la pile croît des adresses hautes vers les adresses basses) :
$ strace -f ./clone
[...]
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM_INFINITY}) = 0
mmap(NULL, 8392704, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_
STACK, -1, 0) = 0x7fc556389000
brk(0) = 0x23aa000
brk(0x23cb000) = 0x23cb000
mprotect(0x7fc556389000, 4096, PROT_NONE) = 0
[...]
L'espace mémoire étant alloué et initialisé, pthread_create() démarre le thread à l'aide de l'appel système clone(). Le thread ainsi créé a l'identifiant 7057 :
[...]
clone(Process 7057 attached
child_stack=0x7fc556b88fb0, flags=CLONE_VM|CLONE_FS|CLONE_
FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_
PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7fc556b899d0,
tls=0x7fc556b89700, child_tidptr=0x7fc556b899d0) = 7057
[...]
La figure 2 décrit l'espace mémoire du thread secondaire au moment de son exécution.

Dans le thread principal,pthread_join() effectue l'opération FUTEX_WAIT sur le futex à l'adresse 0x7fc556b899d0 dans le TCB afin d'attendre la fin du thread secondaire tant que la variable du futex est égale à l'identifiant du thread secondaire (i.e. 7057) :
[...]
[pid 7056] futex(0x7fc556b899d0, FUTEX_WAIT, 7057, NULL <unfinished ...>
[...]
La synchronisation entre les deux threads est réalisée par le truchement des drapeaux CLONE_PARENT_SETTID et CLONE_CHILD_CLEARTID de l'appel système clone(). Il est ainsi demandé au noyau de stocker le numéro du thread créé à l'adresse parent_tidptr (i.e. 0x7fc556b899d0, qui est donc l'adresse du futex sur lequel le thread principal attend), puis de stocker 0 dans le futex child_tidptr(i.e. la même adresse 0x7fc556b899d0 que parent_tidptr) et d'y réaliser l'opération FUTEX_WAKE lorsque le thread est terminé. Cela a donc pour conséquence de réveiller le thread principal et ainsi, la pile du thread terminé peut être désallouée ou réutilisée pour un nouveau thread.
3.3 Implémentation d'une barrière
Une barrière au sens POSIX du terme [10] est un endroit dans le programme où N threads décident de suspendre leur exécution avant de la reprendre dès qu'ils sont tous arrêtés. Cela permet par exemple de s'assurer que des threads aient exécuté un ensemble d'actions avant de reprendre leur exécution. Le listing suivant est une application où tous les threads du programme stockent leur identifiant au sens noyau Linux du terme (i.e. résultat de l'appel système gettid()) dans les entrées de tab[] avant de se mettre en attente sur la barrière, jusqu'à ce que tous les threads aient renseigné la table.
Une fois les entrées actualisées, tous les threads sont réveillés dont le thread principal, qui affiche le contenu de tab[] à l'écran. Sans la barrière, on n'aurait aucune garantie sur le niveau de remplissage de la table au moment de l'affichage, car le thread principal peut prendre la main à tout moment et en particulier avant que certains threads secondaires n'aient eu le temps de mettre à jour le tableau !
[...]
int futex_var;
int nb_barrier;
pid_t *tab;
#define futex_wait(addr, val) \
syscall(SYS_futex, addr, FUTEX_WAIT, val, NULL)
#define futex_wakeup(addr, nb) \
syscall(SYS_futex, addr, FUTEX_WAKE, nb)
#define gettid() syscall(__NR_gettid)
void barrier_wait(void)
{
int old;
old = __sync_fetch_and_sub(&futex_var, 1);
if (1 == old)
{
futex_wakeup(&futex_var, nb_barrier - 1);
return;
}
// On se met en attente tant que le futex ne vaut pas 0
old = old - 1;
do
{
futex_wait(&futex_var, old);
old = __sync_fetch_and_sub(&futex_var, 0);
if (0 == old)
{
break;
}
} while(1);
}
void *thd_main(void *p)
{
int *idx = (int *)p;
tab[*idx] = gettid();
barrier_wait();
return NULL;
}
int main(int ac, char *av[])
{
pthread_t *tid;
int i;
int *idx;
nb_barrier = 4;
futex_var = nb_barrier;
tab = (pid_t *)malloc(nb_barrier * sizeof(pid_t));
idx = (int *)malloc(nb_barrier * sizeof(int));
tid = (pthread_t *)malloc(nb_barrier * sizeof(pthread_t));
tab[0] = gettid();
for (i = 1; i < nb_barrier; i ++)
{
idx[i] = i;
pthread_create(&(tid[i]), NULL, thd_main, (void *)&(idx[i]));
}
barrier_wait();
free(idx);
for (i = 0; i < nb_barrier; i ++)
{
printf("tab[%d] = %d\n", i, tab[i]);
}
free(tab);
for (i = 1; i < nb_barrier; i ++)
{
pthread_join(tid[i], NULL);
}
free(tid);
return 0;
}
La compilation et l'exécution de ce programme donnent le résultat suivant :
$ gcc barrier.c -o barrier -lpthread
$ ./barrier
tab[0] = 3656
tab[1] = 3657
tab[2] = 3658
tab[3] = 3659
Pour réaliser une barrière à partir d'un futex, il suffit de l'initialiser avec le nombre de threads à mettre en attente. Puis, chaque thread effectue une décrémentation atomique de ce dernier et se suspend tant que le futex n'a pas atteint la valeur 0. Le thread pour lequel la décrémentation donne 0 réveille les autres.
Encore une fois, lorsqu'on utilise GCC, nul besoin de produire du code assembleur pour la décrémentation atomique : on utilise la built-in __sync_fetch_and_sub() vue plus haut en section 4.1. Dans le programme, la fonction barrier_wait() utilise cette facilité.
La variable globale futex_var est préalablement initialisée avec le nombre de threads à synchroniser en début de fonction main(). Quand la valeur 1 est retournée, cela signifie que la nouvelle valeur du futex est à 0 et par conséquent, on peut réveiller les (nb_barrier - 1) threads en attente via l'opération FUTEX_WAKE de futex(). Tant que __sync_fetch_and_sub()retourne une valeur supérieure à 1, cela veut dire que le futex n'est pas encore à 0 et qu'il faut se mettre en attente en invoquant l'appel système futex() avec l'opération FUTEX_WAIT. L'attente est dans une boucle afin de gérer les cas de croisements, où N threads décrémentent le futex juste après qu'un thread l'ait décrémenté, mais avant qu'il ne se soit mis en attente. La valeur « old - 1 » sur laquelle ce dernier thread se met en attente n'est plus « old - 1 », mais « old - 1 - N » et par conséquent, l'opération FUTEX_WAIT retourne immédiatement le compte-rendu -1 avec l'erreur EAGAIN.
La boucle récupère donc la valeur courante du futex (astuce de la soustraction atomique avec la valeur 0) et ne remet en attente le thread courant sur cette valeur qu'à la condition où elle diffère de 0. L'outil strace permet d'observer ce fonctionnement :
$ strace -f ./barrier
[...]
[pid 3656] futex(0x8049950, FUTEX_WAIT, 3, NULL <unfinished ...>
[...]
[pid 3657] gettid( <unfinished ...>
[pid 3658] gettid( <unfinished ...>
[pid 3659] gettid( <unfinished ...>
[pid 3657] <... gettid resumed> ) = 3657
[pid 3658] <... gettid resumed> ) = 3658
[pid 3659] <... gettid resumed> ) = 3659
[pid 3657] futex(0x8049950, FUTEX_WAIT, 2, NULL <unfinished ...>
[pid 3658] futex(0x8049950, FUTEX_WAIT, 1, NULL <unfinished ...>
[pid 3659] futex(0x8049950, FUTEX_WAKE, 3 <unfinished ...>
[pid 3657] <... futex resumed> ) = -1 EAGAIN (Resource
temporarily unavailable)
[pid 3658] <... futex resumed> ) = -1 EAGAIN (Resource
temporarily unavailable)
[pid 3659] <... futex resumed> ) = 1
[pid 3656] <... futex resumed> ) = 0
[...]
[pid 3656] write(1, "tab[0] = 3656\n", 14tab[0] = 3656) = 14
[pid 3656] write(1, "tab[1] = 3657\n", 14tab[1] = 3657) = 14
[pid 3656] write(1, "tab[2] = 3658\n", 14tab[2] = 3658) = 14
[pid 3656] write(1, "tab[3] = 3659\n", 14tab[3] = 3659) = 14
[...]
Dans cette exécution, le premier thread à appeler futex() avec l'opération FUTEX_WAIT est le thread principal d'identifiant 3656. La valeur du futex est « 4 - 1 » soit 3. Ensuite, les threads secondaires d'identifiants 3657, 3658 et 3659 prennent la main pour appeler gettid(), puis futex(). Le futex prend successivement les valeurs 2, puis 1, comme on peut le voir en troisième paramètre de futex(). Lors de ce dernier appel par les threads 3657 et 3658, la valeur du futex change du fait de la décrémentation concurrente et par conséquent, l'appel système retourne -1 avec le code d'erreur EAGAIN. C'est le thread 3659 qui décrémente le futex pour la dernière fois et réveille tous les autres avec l'opération FUTEX_WAKE de l'appel système futex(). Le troisième paramètre est 3, car sur les 4 threads qui se synchronisent, seuls 3 sont en attente, vu que le dernier est celui qui réveille les autres.
Dans la GLIBC/NPTL, les barrières sont gérées par les services tels que pthread_barrier_init() ou pthread_barrier_wait(). Les développeurs ont fait le choix d'une implémentation légèrement plus lourde, en utilisant un mutex basé sur un futex (comme étudié précédemment) pour protéger le compteur de threads en attente. De plus, la fonction pthread_barrier_wait()retourne 0 pour tous les threads éveillés et PTHREAD_BARRIER_SERIAL_THREAD pour le thread qui provoque le réveil des autres (i.e. le dernier à atteindre la barrière !).
Dans notre exemple, il suffit de changer la fonction barrier_wait(), comme indiqué en rouge dans le listing suivant, pour avoir un comportement analogue : le thread qui appelle futex() avec l'opération FUTEX_WAKE est celui qui reçoit le compte-rendu BARRIER_SERIAL_THREAD.
[...]
#define BARRIER_SERIAL_THREAD 1
int barrier_wait(void)
{
int old;
old = __sync_fetch_and_sub(&futex_var, 1);
if (1 == old)
{
futex_wakeup(&futex_var, nb_barrier - 1);
return BARRIER_SERIAL_THREAD;
}
// On se met en attente tant que le futex
// ne vaut pas 0
old = old - 1;
do
{
futex_wait(&futex_var, old);
old = __sync_fetch_and_sub(&futex_var, 0);
if (0 == old)
{
break;
}
} while(1);
return 0;
}
[...]
Conclusion
Illustré par des exemples simples, ce premier article a permis de comprendre l'avantage des futex par rapport aux anciens services de synchronisation de Linux. Dans le prochain article, une étude plus en profondeur sera proposée en abordant l'implémentation des futex dans le noyau de Linux afin d'en exploiter toutes les possibilités.
Références
[1] Franke H. et Russel R., « Fuss, Futexes and Furwocks: Fast Userlevel Locking in Linux » :
http://www.kernel.org/doc/ols/2002/ols2002-pages-479-495.pdf
[2] Les opérations atomiques :
http://fr.wikipedia.org/wiki/Atomicité_(informatique)
[3] Native Posix Thread Library :
http://en.wikipedia.org/wiki/Native_POSIX_Thread_Library
[4] « Built-in functions for atomic memory access » extrait du manuel du compilateur GCC :
http://gcc.gnu.org/onlinedocs/gcc-4.1.1/gcc/Atomic-Builtins.html
[5] L'opération atomique « Compare And Swap » :
http://en.wikipedia.org/wiki/Compare-and-swap
[6] Load-link/store-conditional :
http://en.wikipedia.org/wiki/Load-link/store-conditional
[7] Drepper U., « Futex are tricky » :
http://people.redhat.com/drepper/futex.pdf
[8] Intel 64 and IA-32 Architectures, Software Developer’s Manual, Volume 2 (2A, 2B & 2C) : Instruction Set Reference, A-Z
[9] Mutexes and Condition Variables using Futexes :
http://locklessinc.com/articles/mutex_cv_futex/
[10] Barrière de synchronisation :
http://fr.wikipedia.org/wiki/Barrière_de_synchronisation




