

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Après un premier article [1] sur la notion de namespace et de conteneur avec un passage en revue des appels système, ce second opus se concentre sur les commandes mises à disposition de l’utilisateur.
En plus des appels système destinés aux programmeurs, des utilitaires sont à la disposition de l’opérateur pour la mise en œuvre des namespaces. Ils recèlent des subtilités que nous allons découvrir et expliquer.
1. La commande unshare
Issu du paquet util-linux, cet utilitaire exécute un programme dans de nouveaux namespaces (cf. man 1 unshare) :
C’est un enrobage de l’appel système unshare(). Les options sur la ligne de commande permettent de choisir les namespaces à créer (p.ex., -p pour un nouveau pid_ns, -m pour un nouveau mount_ns...).
Utilisons cette commande avec les options -u, -p et -i pour lancer un shell associé respectivement à de nouveaux namespaces UTS, PID et IPC (les droits du super utilisateur sont nécessaires !) :
Tout semble s’exécuter à merveille. On est cependant confronté à un problème étrange déjà évoqué, mais non encore expliqué dans l’article précédent. Nous arrivons à lancer une première commande comme date ci-dessus, mais ensuite toute nouvelle commande se solde par une erreur de fork() :
Si on lance une built-in du shell comme echo qui ne provoque pas de fork()/exec(), cela fonctionne par contre :
Dans un autre terminal, listons les namespaces de ce nouveau shell :
Nous constatons que le shell est bien associé à un nouvel ipc_ns et un nouveau uts_ns (créés par le processus 8840) comme demandé, mais son pid_ns est toujours le namespace initial (créé par le processus numéro 1) ! En fait, lorsqu’un processus appelle unshare() pour créer et s’associer à un nouveau pid_ns ou setns() pour s’associer à un autre pid_ns, ce sont ses fils qui seront effectivement associés au nouveau pid_ns. Dans notre exemple, la commande unshare appelle le service unshare(CLONE_NEWUTS|CLONE_NEWPID|CLONE_NEWIPC), puis le service execve() pour exécuter /bin/sh (cf. figure 1).
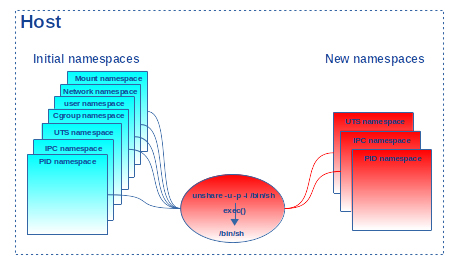
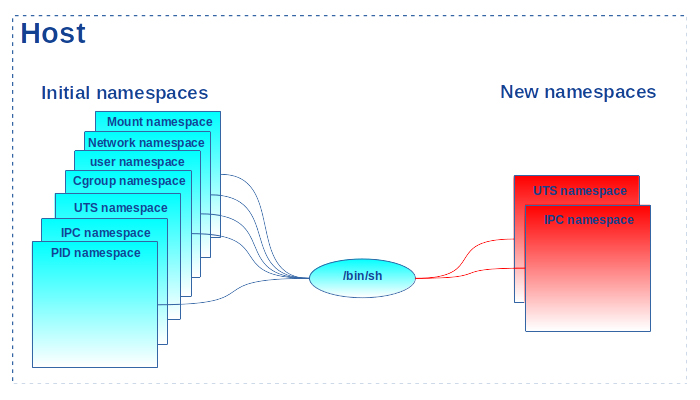
Comme on ne change pas de processus (c.-à-d. le programme unshare est « écrasé » par le programme /bin/sh), le shell ainsi lancé ne change pas de pid_ns. Seuls les nouveaux ipc_ns et uts_ns lui sont associés. Ce sont ses fils qui entreront dans le nouveau pid_ns. Lorsque la première commande date est lancée, un premier fork()/exec() est effectué pour l’exécuter. Le processus fils résultant hérite bien de tous les namespaces de son père, avec en plus l’association au nouveau pid_ns (cf. figure 2).
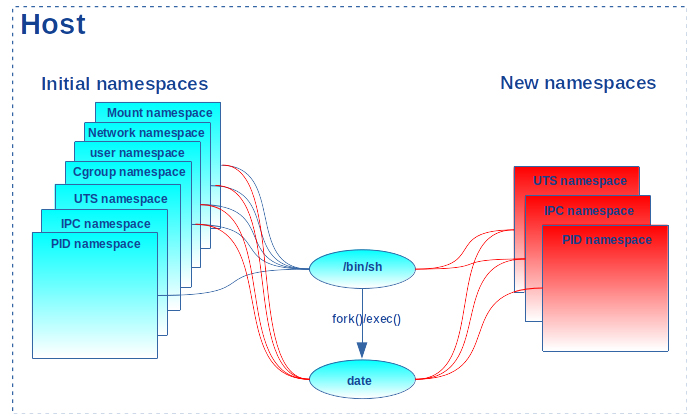
Cette commande s’exécute bien dans le nouveau pid_ns avec l’identifiant 1. Mais quand la commande se termine, le pid_ns disparaît avec le processus associé (cf. figure 3).
Cela rend impossible par la suite la création de tout nouveau processus. D’où l’erreur sur le fork(). Pour s’en convaincre, terminons le shell avec la built-in exit et utilisons un petit script shell alarm qui sommeille le nombre de secondes passé en paramètre et affiche le message « !!!!! ALARM !!!!! » lorsqu’il se termine à échéance de la temporisation. Lançons-le en background comme premier processus du shell. Comme il ne se termine qu’à échéance du délai passé en paramètre, des commandes peuvent s’exécuter pendant le laps de temps (p. ex., date, gcc...). Par contre, dès que le script alarm finit son exécution, en tant que premier processus du pid_ns, il entraîne avec lui la fermeture du pid_ns. C’est alors que l‘erreur de fork() est de retour au lancement de nouvelles commandes :
La commande unshare recèle cependant des fonctionnalités très utiles pour éviter cette chausse-trappe. L’option -f provoque un fork() et exécute le programme demandé dans un shell fils. C’est exactement ce dont nous avons besoin ici, car le shell est exécuté dans un processus fils qui hérite des namespaces de son père et sera donc non seulement associé aux nouveaux uts_ns et ipc_ns, mais aussi au nouveau pid_ns (avec l’identifiant 1) comme indiqué en figure 4.
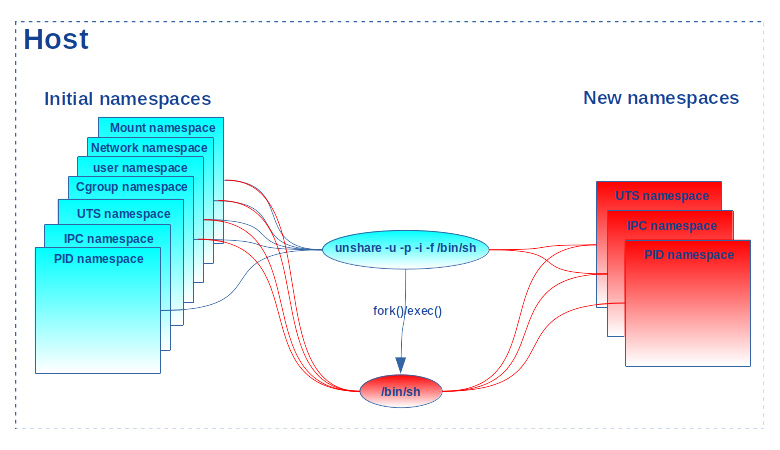
Le pid_ns reste actif tant que le shell n’est pas fini :
Nous vérifions bien que echo $$, résultat d’un getpid() dans le shell courant, affiche 1 comme identifiant, car le shell s’exécute en tant que premier processus dans le nouveau pid_ns.
Restons dans ce shell et lançons la commande ps :
Les identifiants de processus affichés ne correspondent pas à ce à quoi l’on pourrait s’attendre et notamment pour notre shell. En effet, il a le PID 3729 alors que echo $$ affiche 1. En fait, ps affiche le PID du shell vu du côté pid_ns initial, c’est-à-dire du pid_ns père dans la hiérarchie des namespaces. Alors que $$ est le PID vu du pid_ns du shell (le pid_ns fils).
Nous avons une fois de plus à faire à une subtilité des namespaces. Tandis que echo $$ obtient le PID dans le descripteur de tâche au sein du noyau, la commande ps va glaner ses informations dans le système de fichiers /proc. Ce dernier exporte des informations du noyau qui correspondent au pid_ns du processus qui a effectué son montage (cf. paragraphe « /proc and PID namespaces » dans man 7 pid_namespaces). Comme /proc a été monté au démarrage du système par un processus associé au pid_ns initial, il exporte donc des informations vues de ce namespace. Il faudrait remonter /proc dans ce shell pour obtenir les bonnes informations. Mais pour ne pas perturber le mount_ns initial, il est conseillé de le monter dans un nouveau mount_ns. C’est justement ce que proposent les options -m (création d’un nouveau mount_ns) et --mount-proc (remontage de /proc) de la commande unshare ! Sortons donc du shell et relançons-le avec ces options en supplément :
On ne voit donc plus que les deux seuls processus du pid_ns fils : le shell (PID 1, car il est le premier processus du namespace) et ps (PID 2 lancé en second).
2. La commande nsenter
Issu du paquet util-linux, cet utilitaire exécute un programme dans les namespaces d’autres processus (cf. man 1 nsenter) :
C’est un enrobage de l’appel système setns(). L’option -t sur la ligne de commande permet de spécifier un processus cible avec lequel on veut partager les namespaces spécifiés par les mêmes options que la commande unshare (p. ex., -m pour mount_ns, -u pour uts_ns...).
Dans un terminal, affichons le nom de l'hôte (rachid-pc). Puis, relançons la commande d’illustration de la commande unshare vue en section précédente. L’invocation de hostname affiche le même nom d'hôte que celui de l’uts_ns initial, car il a été hérité. Dans ce nouvel uts_ns, on change le nom en new-pc :
Dans son pid_ns, le shell ainsi lancé a l’identifiant 1, car il est le premier processus dans son namespace. Mais il a un identifiant différent dans le pid_ns initial. Comme c’est le fils de la commande unshare, dans un autre terminal, la commande ps nous permet de l’obtenir :
Donc, le shell a l’identifiant 29207 dans le pid_ns initial. Dans ce même terminal, utilisons nsenter pour invoquer un autre shell dans les mêmes namespaces (pid_ns, uts_ns et mount_ns) :
Le nouveau shell a l’identifiant 5 dans le pid_ns cible. Cela confirme que la commande ps va chercher ses informations dans le système de fichiers /proc correspondant au pid_ns du processus qui l’a monté (le shell lancé par la commande unshare dans notre cas) et on vérifie bien qu’il est dans le même uts_ns en affichant le nom d'hôte (new-pc).
3. La commande lsns
Issu du paquet util-linux, cet utilitaire parcourt le répertoire /proc et pour tous les identifiants de processus relève et affiche les informations relatives aux namespaces (cf. man 8 lsns). Sans paramètres, il affiche par défaut le numéro d’inode (colonne NS), le type de namespace (colonne TYPE), le nombre de processus associés au namespace (colonne NPROCS), le plus petit identifiant de processus dans le namespace (colonne PID), le nom d’utilisateur du processus (colonne USER), et la ligne de commande du processus (colonne COMMAND) :
Cependant, le manuel précise bien que l’affichage par défaut de la commande est sujet à des changements dans les futures versions. Il ne faut par conséquent pas s’y fier dans le cas d’une utilisation dans des scripts qui filtrent sa sortie. Il est conseillé d’utiliser --output suivi de la liste des colonnes à afficher. L’option --help permet d’obtenir tous les noms de colonnes acceptés :
L’option -p est aussi très utile pour se focaliser sur les namespaces d’un processus donné. Reprenons notre exemple de shell lancé via la commande unshare. La commande lsns parcourant /proc. Vue du mount_ns du sous-shell, il n’y a que le shell (PID 1) et la commande lsns elle-même (d’où le 2 pour le nombre de processus dans la colonne NPROCS) :
Dans un autre terminal, lsns permet de récupérer le PID du sous-shell vu du pid_ns initial :
Nous vérifions ce que nous avons dit précédemment, à savoir que la commande unshare appelle certes le service système unshare() avec les options CLONE_NEWNS, CLONE_NEWUTS et CLONE_NEWPID pour respectivement créer un nouveau mount_ns, uts_ns et pid_ns, mais seul le processus fils et sa descendance sont associés au nouveau pid_ns. D’où l’identifiant 7451 (commande /bin/sh) pour le premier processus du pid_ns et 7450 (commande unshare) pour le premier processus du mount_ns et de l’uts_ns. On peut ainsi afficher les informations sur les namespaces du sous-shell :
La colonne NSFS est le point de montage du « namespace file system » (absolument rien à voir avec NFS, le « network File System » !). Les namespaces sont régis par un système de fichiers virtuels interne au noyau. Nous verrons cela plus en détail dans un prochain article de cette série qui détaillera les mount_ns et dans la présentation de la commande ip qui suit.
La colonne NETNSID affiche l’identifiant de net_ns NETLINK [2] vu du net_ns du processus appelant. Si aucun identifiant n’a été assigné, la commande affiche unassigned. Nous reverrons cette notion dans la présentation de la commande ip qui suit.
4. La commande ip
L’utilitaire ip est le couteau suisse de la configuration réseau sous GNU/Linux. Il a rendu obsolète la fameuse commande ifconfig. Il est issu du paquet iproute2. Parmi ses nombreuses fonctionnalités, il ajoute un niveau d’abstraction sur les net_ns afin d’en faciliter la manipulation. Cela consiste à leur donner un nom (plus facile à mémoriser qu’un numéro d’inode ou un identifiant de processus !). Le manuel principal est dans man 8 ip. La partie concernant les options relatives aux namespaces a une description dédiée dans man 8 ip-netns.
4.1 Création d’un net_ns
La commande ip peut créer un nouveau net_ns tout en lui associant un nom. Ici, nous créons le net_ns newnet avec la requête add :
La commande n’est pas très loquace. Pour connaître la liste des net_ns nommées par la commande ip :
En interne, un net_ns est créé avec l’appel système unshare(CLONE_NEWNS). Cependant, comme un namespace disparaît lorsqu’il n’y a plus de processus qui lui est associé, ce nouveau net_ns ne ferait pas long feu s’il disparaît lorsque la commande ip se termine. L’astuce est de créer un fichier dans /var/run/netns/<nom_namespace>, puis d’appeler unshare() pour créer et s’associer à un nouveau mount_ns, puis enfin de monter le lien symbolique /proc/<pid>/ns/net qui caractérise le nouveau namespace sur le fichier créé dans /var/run/netns (on donnera plus de détails sur ce montage dans l’article concernant les mount_ns). Ce montage étant persistant à la fin de la commande ip, le net_ns reste actif, bien qu’aucun processus n’y soit associé :
Quand le montage évoqué ci-dessus est réalisé, le fichier mountinfo dans /proc montre que le système de fichiers virtuel NSFS interne au noyau est mis en œuvre :
Nous avions cité ce système de fichiers lors de la présentation de la commande lsns. Nous avions même vu que cette dernière affiche les points de montage NSFS lorsqu’ils sont mis en œuvre, mais à condition d’exécuter lsns dans un contexte où un processus associé au net_ns considéré est visible. Dans notre cas de figure, il n’y a pas de processus associé à newnet. On peut utiliser l’option exec de ip pour lancer un processus en arrière-plan associé à ce net_ns :
Ainsi, la commande lsns sera à même de voir et d’afficher le point de montage NSFS correspondant au net_ns newnet :
L’intérêt de créer un net_ns est d’isoler des interfaces réseau afin d’exécuter des commandes. Par défaut, un net_ns nouvellement créé n’a qu’une interface loopback :
C’est d’un intérêt limité. Mais certaines interfaces réseau ont la possibilité de migrer d’un net_ns à l’autre. Comme chaque namespace a sa propre pile réseau, sa propre table de routage et ses propres règles de pare-feux, il est possible de mettre en place de multiples combinaisons de configurations réseau sur une même machine.
4.2 Attachement à un net_ns
La commande ip permet aussi de s’attacher à des net_ns existants. Par exemple, un net_ns mis en place pour un conteneur. Pour nous familiariser avec ce mécanisme, nous allons configurer une interface Ethernet dans un conteneur LXC. Le conteneur nommé bbox est créé et démarré comme indiqué dans l’encadré « Mini-guide LXC » du premier article [1]. Par défaut, pour l’accès au réseau, le conteneur contient :
- une interface loopback lo : interface par défaut dans tout nouveau net_ns ;
- une interface Ethernet virtuelle [3] eth0 : choisie par le template busybox et configuré par la commande lxc-start pour accéder au réseau Internet.
L’interface Ethernet virtuelle est déterminée par le paramètre lxc.net suivant dans la configuration du conteneur :
L’interface virtuelle Ethernet est une sorte de tunnel. Dans le cadre de LXC, elle sert de lien entre le système hôte et le conteneur. Un client UDHCPC est aussi lancé pour configurer l’adresse IP sur cette interface (à l’autre extrémité, côté hôte, un serveur dnsmasq s’occupe des requêtes DHCP [4]).
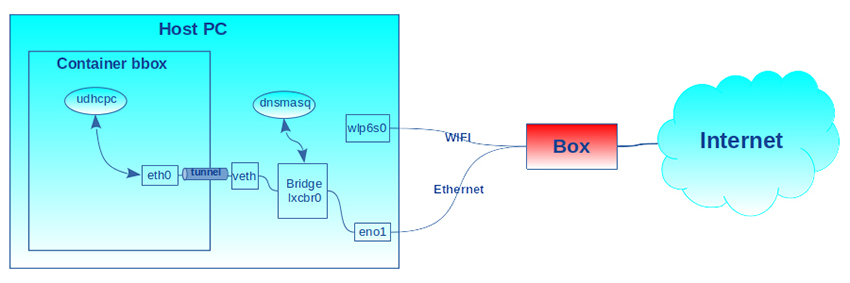
Côté hôte, nous avons :
- lo : l’interface loopback associée au net_ns initial par défaut ;
- eno1 : l’interface du port Ethernet connectée à la box domestique ;
- wlp6s0 : l’interface Wi-Fi connectée à la box domestique ;
- lxcbr0 : le pont (bridge en anglais [5]) qui permet de connecter le lien Ethernet virtuel hôte/conteneur au réseau. Les conteneurs connectés à ce bridge sont dans un sous-réseau. Un serveur dnsmasq [6] en écoute sur cette interface attribue les adresses IP (protocole DHCP) dans ce sous-réseau. Pour la communication avec l’extérieur via eno1, la distribution GNU/Linux se charge de la configuration de l’« IP forwarding » et des filtres réseau à partir du script lxc-net typiquement installé dans /usr/libexec/lxc ;
- veth : l’autre extrémité du tunnel Ethernet virtuel reliant l’hôte au conteneur.
La configuration est schématisée en figure 5.
Avant de nous lancer, permettons-nous une nouvelle digression pour revenir sur la commande lsns et la colonne netnsid. Nous avons dit qu’il s’agit d’un identifiant utilisé via le protocole netlink. En fait, un net_ns a la possibilité de mémoriser un identifiant par net_ns avec lequel il est en interaction. Lorsqu’on démarre un conteneur LXC avec une interface Ethernet virtuelle, un identifiant de namespace (NSID) est attribué au net_ns du conteneur dans le net_ns courant. Ici, il s’agit de l’identifiant 0 :
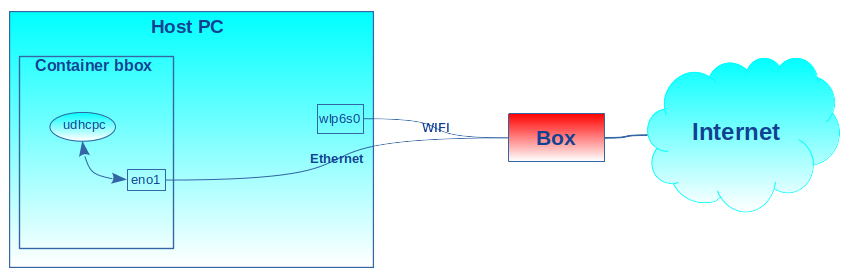
Pour en revenir à notre sujet, le but de la manipulation va consister à faire en sorte que le conteneur se connecte directement à l’extérieur, sans passer par « le sous-réseau Ethernet virtuel » mis en place par le template busybox de LXC. Cela implique de migrer l’interface Ethernet eno1 du net_ns de l’hôte vers celui du conteneur, comme indiqué en figure 6. Une interface réseau ne peut appartenir qu’à un seul net_ns. Comme nous le verrons plus tard, certaines interfaces comme Ethernet peuvent migrer d’un namespace à l’autre, tandis que d’autres comme celles gérant le Wi-Fi ne le peuvent pa.
Côté hôte, notons l’adresse IP sur l’interface eno1 :
Désactivons l’interface Ethernet virtuelle côté conteneur et vérifions que le trafic réseau ne passe plus à l’aide d’un ping vers le système hôte :
Côté hôte, nous associons un nom (p. ex., bbox_nsnet) au net_ns du conteneur, en utilisant l’identifiant du processus init de ce dernier. La commande ip permet en effet d’attacher un nom à un net_ns existant à partir de l’identifiant d’un processus associé au net_ns cible, grâce à la requête attach :
Dans ce cas, nous pouvons aussi voir le NSID du net_ns du conteneur via la requête list de ip :
Le net_ns newnet créé au paragraphe précédent n’a quant à lui pas de NSID.
L’attachement du net_ns du conteneur par la commande ip provoque aussi un montage du système de fichiers interne nsfs :
Nous désactivons l’interface Ethernet de l'hôte, puis nous la transférons dans le net_ns du conteneur (dans la couche d’abstraction de la commande ip, c’est bbox_nsnet configuré plus haut) :
Nous constatons bien la migration de l’interface Ethernet eno1 dans le conteneur :
Arrêtons le client udhcpc lancé au démarrage du conteneur et qui, par défaut (c.-à-d. sans paramètre), lance ses requêtes sur l’interface eth0. Puis relançons-le pour qu’il adresse ses requêtes via l’interface Ethernet eno1 (option -i) tout juste transférée dans le conteneur et que nous prenons soin d’activer au préalable :
L’affichage du client DHCP montre qu’il a obtenu l’adresse 192.168.0.19 de la part du serveur DHCP tournant dans la box domestique. La table de routage est mise à jour automatiquement et le client DHCP devient un daemon :
Nous vérifions que le conteneur a bien accès à l’Internet mondial avec un ping sur le serveur des Éditions Diamond, par exemple :
Tout se passe donc comme si deux machines indépendantes étaient connectées au réseau Internet : le PC hôte via le Wi-Fi wlp6s0 et le conteneur bbox via l’interface Ethernet eno1 (comme schématisé en figure 6).
Arrêtons le conteneur :
Si on liste les interfaces réseau disponibles dans le net_ns initial, on ne voit toujours pas l’interface eno1 alors qu’une interface réseau doit être réaffectée au net_ns initial, lorsque son net_ns disparaît :
En fait, bien que stoppé, le net_ns du conteneur existe toujours, car nous avons vu que bbox_nsnet est un point de montage du lien symbolique du net_ns du conteneur. Tant que ce montage est actif, le net_ns du conteneur continue à exister. Effectuons le « démontage » de bbox_nsnet à l’aide de la requête del de ip :
Maintenant, le net_ns du conteneur a disparu et l’interface Ethernet eno1 se retrouve de nouveau associée au net_ns initial :
Avant de conclure cet article, on notera que pour avoir un conteneur LXC avec juste une interface loopback dans son net_ns, il suffit de modifier le paramètre de configuration lxc.net comme suit dans /var/lib/lxc/bbox/config :
Stoppons et relançons le conteneur :
Enfin, il est aussi possible de démarrer un conteneur LXC avec une interface Ethernet en modifiant la configuration /var/lib/lxc/bbox/config comme suit :
Sortons de la console du conteneur, stoppons-le et redémarrons-le pour qu’il prenne en compte cette nouvelle configuration :
Pour obtenir une adresse IP, il faut réactiver l’interface (on aurait aussi pu décommenter lxc.net.0.flags=up) et redémarrer le client DHCP comme on l’a fait précédemment :
Nous avons donc refait avec la configuration de LXC ce que nous avons fait manuellement en début de paragraphe.
Conclusion
Ce second article, à travers l’étude des utilitaires qui les mettent en œuvre, a révélé et expliqué des subtilités inhérentes aux namespaces et les options qui permettent de les exploiter. Cela nous a aussi permis d’avoir un premier aperçu de la gestion des interfaces réseau dans les conteneurs LXC. Nous ne sommes pas au bout de nos surprises ! Dans le prochain article, nous présenterons la vue des namespaces côté noyau.
Références
[1] R. KOUCHA, « Les namespaces ou l'art de se démultiplier », GNU/Linux Magazine n°239, juillet/août 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-239/Les-namespaces-ou-l-art-de-se-demultiplier
[2] Netlink : https://en.wikipedia.org/wiki/Netlink
[3] Paire Ethernet virtuelle : http://man7.org/linux/man-pages/man4/veth.4.html
[4] Le protocole DHCP : https://fr.wikipedia.org/wiki/Dynamic_Host_Configuration_Protocol
[5] Les ponts réseau : https://en.wikipedia.org/wiki/Bridging_(networking)
[6] Le serveur dnsmasq : https://fr.wikipedia.org/wiki/Dnsmasq



