

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Notions indispensables aux mécanismes d’isolation, mais plutôt méconnus du grand public, les namespaces sont devenus incontournables dans l’environnement Linux. Ils sont, le plus souvent, utilisés de manière implicite à travers les gestionnaires de conteneurs tels que LXC.
La notion de namespace [1] est apparue dans le système expérimental Plan 9 (voir encadré). Développé par Bell Labs sous la direction de R. Pike et K. Thompson à partir de 1987, ce projet était destiné à pallier les problèmes du système Unix [2].
Plan 9
Le nom « plan 9 » est inspiré du titre « Plan 9 from Outer Space”, film de science-fiction américain réalisé par Edward D. Wood et sorti sur les écrans en 1959 [3]. Classé dans la catégorie des nanars, il est devenu « collector ». Ce metteur en scène fantasque est d’ailleurs le personnage éponyme du biopic tourné par Tim Burton [4].

Bien que le concept existait avant son apparition en 1991, le système Linux s’est d’abord cantonné dans son statut de « Unix-like » en proposant un fonctionnement identique à son modèle. L’appel système chroot() ainsi que la mémoire virtuelle des processus était alors les seuls mécanismes d’isolation. Linux a proposé un premier namespace dans sa version 2.4.19 en 2002 : le « namespace mount » [5]. Il n’était pas prévu d’en proposer d’autres, mais afin de répondre aux besoins grandissants de la virtualisation des ressources informatiques, de nouveaux namespaces se sont avérés nécessaires et sont apparus à partir de 2006. Linux en compte sept actuellement. Et il est prévu d’en proposer de nouveaux dans les versions à venir.
Dans la série d’articles que je vous propose, il n’est pas question de paraphraser ce qui se trouve dans le manuel de Linux ou les différents articles disponibles ici et là sur le Web. Nous allons plutôt passer en revue tous les namespaces et ce qui s’y rattache de manière pratique (voire ludique) à travers les outils disponibles, des programmes écrits en shell et langage C et une petite plongée dans le code source du noyau. Ce sera l’occasion de combler quelques lacunes de la documentation, de comprendre certaines limitations, voire de pointer du doigt des faiblesses de l’implémentation. Nous nous accorderons aussi quelques digressions sur le gestionnaire de conteneurs LXC [6], qui ne pourrait pas exister sans les namespaces.
Le code de l'article est disponible sur http://www.rkoucha.fr/tech_corner/linux_namespaces/linux_namespaces.tgz.
1. Premier aperçu
1.1 Définition
À l’origine, Linux, « Unix-like » par excellence, définissait des espaces de noms uniques pour différentes ressources système. Dans le jargon informatique, ils sont nommés « singletons ». Par exemple, les processus se voient attribuer un identifiant unique et global au système (pid). Il en est de même pour les utilisateurs (uid) et les groupes d’utilisateurs (gid). Avec l’avènement des namespaces (c.-à-d. « espaces de noms » en français), il est désormais possible d’instancier ces ensembles. L’unicité des ressources est ainsi garantie au sein d’un espace donné, mais pas forcément d’un espace à l’autre. Linux propose actuellement sept types de namespaces [7] :
- Les points de montage du système de fichiers : « mount namespaces » (mount_ns) ;
- Les identifiants de processus : « pid namespaces »(pid_ns) ;
- Les noms de machine et de domaine : « uts namespaces » (uts_ns) ;
- Les ressources réseau (pile, protocoles, tables de routage, interfaces…) : « network namespaces » (net_ns) ;
- L’arborescence des cgroups : « cgroup namespaces » (cgroup_ns) ;
- Les identifiants de sécurité (identifiants d’utilisateur, identifiants de groupe…) : « user namespaces » (user_ns) ;
- Les IPC système V ainsi que les queues de message POSIX : « ipc namespaces » (ipc_ns).
Nous verrons par la suite que de nouveaux namespaces sont à l’étude ou apparaîtront dans les prochaines moutures de Linux.
Un processus est toujours associé à un namespace de chaque catégorie (cf. figure 1).
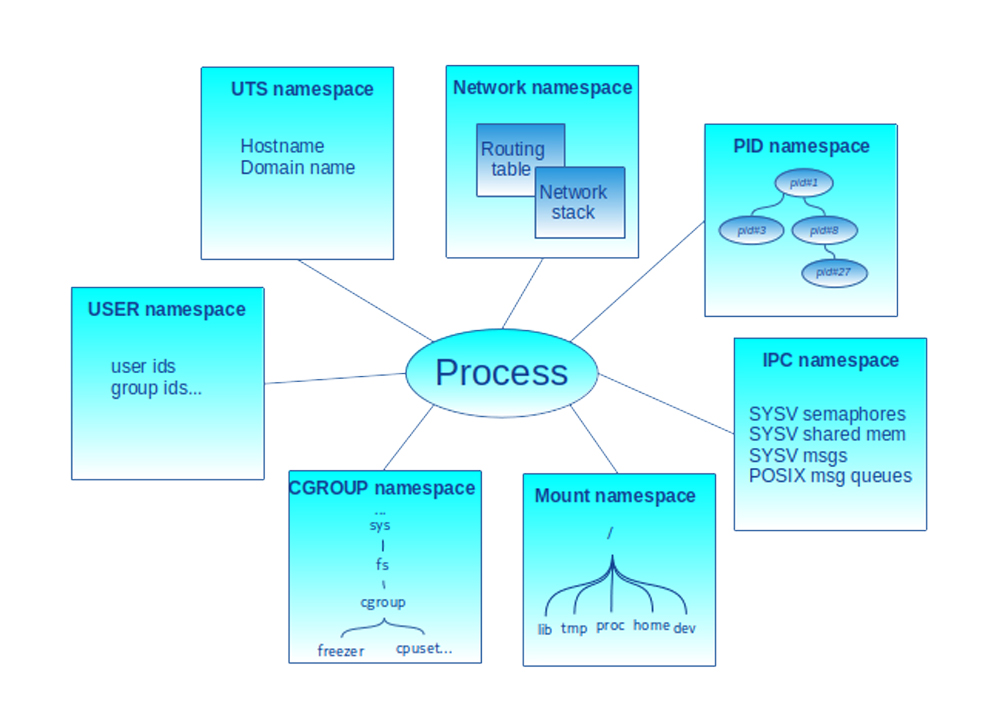
Un processus peut créer de nouveaux namespaces ou migrer d’un namespace à l’autre pour chaque catégorie.
Certains namespaces sont en plus hiérarchiques, dans le sens où il y a une relation père-fils (c’est le cas des user_ns et pid_ns).
Une même ressource peut être visible dans un seul namespace (p. ex. un sémaphore) ou plusieurs namespaces, mais pas avec le même identifiant (p. ex. un processus a un pid dans tous les pid_ns en remontant de son pid_ns courant au pid_ns racine de la hiérarchie). La figure 2 illustre le cas d’un processus associé à un pid_ns fils. Il est identifié avec le pid 3 dans le pid_ns fils et avec le pid 13 dans le namespace parent.
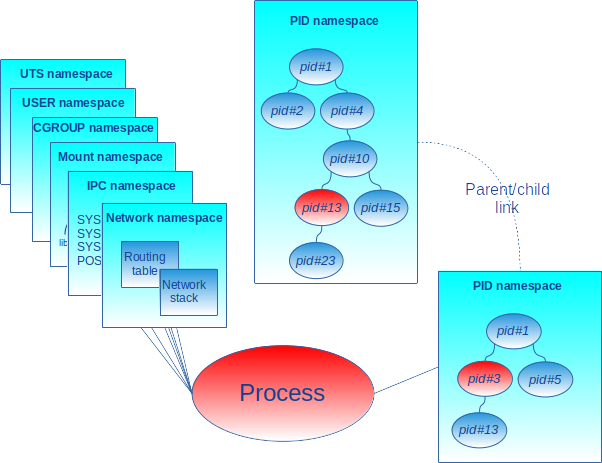
1.2 Besoin d’isolation
En guise de premier aperçu de l’utilité des namespaces, considérons un cas simple de développement et test d’un logiciel. Un système hôte est dédié aux tests unitaires. Parmi les ressources système dont le logiciel a besoin, il y a des sémaphores Système V. Le logiciel a une ampleur telle que différentes équipes de développeurs interviennent en même temps sur son code source pour la maintenance et les évolutions. Il faut le tester pour détecter les régressions et vérifier que les fonctionnalités ajoutées ont les comportements souhaités. Voici par exemple le programme sem qui crée un sémaphore avec la clé d’identification 0x12345 :
Un sémaphore étant identifié par une clé unique (cf. man 2 semget), il n’est pas possible de créer deux sémaphores avec une même clé sur une même machine. Si le programme précédent est lancé deux fois, une erreur est affichée lors de la seconde tentative d’exécution :
Les tests du logiciel par les testeurs ne peuvent donc pas se faire en parallèle, à moins d’utiliser des machines différentes. Pour des raisons de coûts notamment, il est difficile de multiplier le nombre de machines. Dans un tel contexte, les équipes sont condamnées à lancer les tests séquentiellement. Cela va à l’encontre des principes de l’intégration continue [8] (c.-à-d. CI) destinée à augmenter l’efficacité de la mise au point et la livraison des corrections et nouvelles fonctionnalités. Le fameux « time to market », cher aux commerciaux, s’en voit fortement impacté.
C’est typiquement l’un des contextes où la notion de namespace a sa place. Les tests peuvent s’exécuter en parallèle sur la même machine, à condition d’utiliser des namespaces différents. Dans cet exemple, chaque test aura au minimum son propre ipc_ns où seront créés les sémaphores. Il n’y aura plus d’interférences entre les tests. Pour s’en convaincre, utilisons la commande unshare (détaillée plus tard) pour relancer chaque instance du programme précédent dans un ipc_ns dédié (option -i pour IPC). La manipulation de la majorité des namespaces nécessite les droits du super utilisateur :
Nous constatons la création sans erreur des sémaphores, alors que les clés sont identiques. La commande lsns (détaillée plus tard) permet d’afficher la liste des namespaces auxquels un processus (option -p) est attaché. La première colonne est l’identifiant de namespace. Nous voyons que les deux processus évoluent dans les mêmes namespaces, sauf pour les ipc_ns :
De manière plus générale, nous isolons au sein de namespaces les ressources nécessaires aux logiciels à exécuter. La notion de conteneur est une application de ce principe.
1.3 Les conteneurs
Un conteneur est un ensemble de namespaces (un par catégorie) auxquels sont associés un ou plusieurs processus. Les ressources sont uniques dans un conteneur donné, car elles sont allouées dans un namespace, mais elles sont instanciées au niveau du système, car il peut y avoir plusieurs namespaces pour chaque catégorie de ressource. Le système d’exploitation est par contre commun à tous les namespaces, donc à tous les conteneurs. Au démarrage du système, tous les processus sont associés aux namespaces initiaux. Dans un environnement de conteneurs, ces derniers constituent ce qu’on appelle le système hôte. Ils ne sont donc jamais désalloués. La figure 3 schématise un premier processus associé à des namespaces initiaux (uts_ns et net_ns) et non initiaux. Le second processus s’exécute au sein d’un conteneur, car il est associé aux namespaces de ce dernier.

1.4 Identification d’un conteneur
Un conteneur LXC est identifié par un nom. Il est passé avec l’option -n sur la ligne de commande de la plupart de ses outils. D’ailleurs dans les manuels en ligne, l’option figure dans la partie « COMMON OPTIONS ». Par exemple, en consultant le manuel de lxc-destroy (destruction d’un conteneur) :
En interne, LXC référence un conteneur avec l’identifiant du premier processus lancé en son sein. Il est nommé init quand il s’agit d’un conteneur de type busybox [9] que nous utiliserons régulièrement pour étayer les propos de cette série d’articles. La mise en œuvre d’un tel conteneur est présentée dans l’encadré « Mini-guide LXC ».
Mini-guide LXC
Ces articles utilisent la version 2.1.1 de LXC.
Pour créer et démarrer un conteneur LXC simple nommé arbitrairement bbox et basé sur le template busybox (avec les droits du super utilisateur !) :
L’option -s est facultative, mais on l’utilise pour positionner la variable d’environnement PS1 qui spécifie le format du prompt afin de différencier les copies d’écran qui illustrent les articles. Le script lxc-start2 mis à disposition effectue ce travail :
Pour accéder à la console du conteneur afin d’y lancer des commandes comme ps pour voir les processus qui tournent :
On en a profité aussi pour lancer la commande hostname. Par défaut, un conteneur de type busybox prend le nom du conteneur (option -n de lxc-create) comme nom d’hôte (c.-à-d. bbox).
Comme indiqué dans la bannière d’accueil de la console, pour en sortir et revenir sur l’hôte, il faut taper la combinaison de touches <CTRL> + <a> + <q>.
Pour arrêter un conteneur, on a recours à la commande lxc-stop :
Une fois arrêté, un conteneur peut-être redémarré via lxc-start ou détruit définitivement avec lxc-destroy :
La figure 4, schématise un conteneur LXC :

Nous notons que le processus init a le pid 1 dans le conteneur, car il est le premier processus créé dans son pid_ns. Mais comme nous l’avons déjà dit et le reverrons plus en détail par la suite, un pid_ns (tout comme le user_ns) a la particularité d’être hiérarchique. Il y a une relation père-fils entre le namespace d’où est créé le namespace (le père) et le namespace nouvellement créé (le fils). Dans une telle hiérarchie, le père à la vision des ressources dans le fils, mais l’inverse n’est pas vrai. Dans le cas des pid_ns, lorsqu’un processus est créé dans un namespace fils, il est identifié dans ce dernier, mais il possède aussi un identifiant dans le namespace père. C’est la signification des liens en pointillé sur la figure 4. Le processus init de pid 1 dans le namespace fils est vu dans le namespace père avec le pid 51.
Ce qui intéresse particulièrement les internes de LXC est l’identifiant dans le pid_ns père du processus init. En d’autres termes, le pid du processus vu du côté système hôte. Dans le cas de la figure 4, il s’agit de l’identifiant 51. Nous allons aussi beaucoup utiliser cet identifiant dans la suite de cet écrit pour « pénétrer » à l’intérieur des conteneurs. Il convient donc de savoir l’obtenir.
Comme chaque conteneur lancé via lxc-start est supervisé par un daemon nommé [lxc monitor] chemin_lxc nom_conteneur côté hôte. Le premier processus du conteneur (init) étant son fils, on peut déduire son pid en cherchant le fils du daemon :
Ce n’est rien d’autre que l’identifiant PID affiché par la commande lxc-info :
Comme on va avoir régulièrement besoin de cette information tout au long de cette série d’articles, nous nous facilitons la tâche avec notre script shell lxc-pid. Il reçoit en paramètre le nom d’un conteneur et affiche son identifiant en filtrant la valeur dans le résultat condensé (options -H et -p) de la commande lxc-info :
À l’exécution, cela donne :
1.5 Les namespaces d’un processus
Tout processus est lié à un seul namespace par type. Le répertoire /proc/<pid>/ns contient la liste des namespaces auxquels le processus d’identifiant pid est associé. Par exemple, les namespaces du processus 3542 sont :
Le contenu de ce répertoire est un ensemble de liens symboliques pointant sur le nom du namespace séparé par un « : » d’un numéro d’inode entre crochets. Le lien pid_for_children est une spécificité du pid_ns qui sera décrite plus tard. Le numéro d’inode sert à identifier les namespaces. Il est unique dans le système.
Pour obtenir un descripteur de fichier sur un namespace nécessaire à certains appels système vus plus bas, il suffira d’appeler open() sur la cible de ces liens symboliques. C’est un choix d’implémentation qui a été préféré à l’introduction d’un nouvel appel système qui prendrait en argument un identifiant de namespace et retournerait un descripteur de fichier [10].
Nous verrons dans un article suivant que les cibles des liens symboliques sont des fichiers gérés par un système de fichiers interne au noyau dédié aux namespaces (NSFS).
1.6 Identification des namespaces
Un namespace est identifié de manière unique par deux entités : un numéro de périphérique et un numéro d’inode. Comparer les namespaces de deux processus revient par conséquent à comparer les champs st_dev et st_ino de la structure renvoyée par un appel système comme stat() sur la cible du lien symbolique correspondant. Notre programme cmpns compare les namespaces de deux processus, dont les identifiants sont passés en paramètres :
Si on le lance avec deux identifiants de processus associés aux mêmes namespaces, nous obtenons (à lancer avec les droits du super utilisateur !) :
Par contre, si on le lance avec deux identifiants de processus associés à des namespaces différents (par exemple, le processus courant et le processus init d’un conteneur), on voit que tous les namespaces sont différents, sauf le user_ns :
Nous avons dit plus haut qu’un conteneur est un ensemble de namespaces dédiés. Or, l’affichage précédent montre que tous ses namespaces sont différents du système hôte, sauf l’user_ns. En fait, un conteneur privilégié utilise le user_ns initial contrairement à un conteneur non privilégié qui a son propre user_ns. Nous reviendrons sur cet aspect lors de l‘étude des user_ns.
On notera que nous avons utilisé l’appel système stat() et non pas lstat() qui nous donnerait les informations sur le lien symbolique lui-même et non pas sa cible.
2. Les appels système
Les appels système manipulant les namespaces sont les suivants :
- clone() : création d’un processus en l’associant à de nouveaux namespaces ;
- setns() : association du processus appelant à un namespace existant ;
- unshare() : association du processus appelant à de nouveaux namespaces ;
- stat() : obtention de l’identifiant d’un namespace ;
- ioctl() : opérations diverses spécifiques aux namespaces ;
2.1 clone()
clone() est l’appel système de Linux permettant de créer une tâche. Souvent méconnu du grand public, il est au cœur des bien plus célèbres services fork() et pthread_create(). Le prototype est le suivant (cf. man 2 clone) :
En bref, cette fonction crée une nouvelle tâche avec pour point d’entrée la fonction fn (premier paramètre) qui recevra l’argument arg (quatrième paramètre) et la zone mémoire child_stack qui servira de pile d’exécution (second paramètre). Le troisième paramètre flags détermine le nombre et la nature des arguments qui suivent, ainsi que ce qui est partagé entre la tâche appelante et la nouvelle tâche (information sur le système de fichiers, espace mémoire, contexte d’entrées/sorties...). Parmi les drapeaux supportés, il y a ceux dédiés aux namespaces. Ils sont définis à raison d’un par namespace dans le fichier d’en-tête <sched.h> pour associer la tâche créée à un nouveau :
- cgroup_ns (CLONE_NEWCGROUP) ;
- ipc_ns (CLONE_NEWIPC) ;
- net_ns (CLONE_NEWNET) ;
- pid_ns (CLONE_NEWPID) ;
- user_ns (CLONE_NEWUSER) ;
- uts_ns (CLONE_NEWUTS) ;
- mount_ns (CLONE_NEWNS).
La dénomination CLONE_NEWNS relative au mount_ns déroge à la règle de nommage utilisée pour les autres namespaces (c.-à-d. CLONE_NEW<nom de namespace abrégé>). Au lieu de « NS » pour « NameSpace », on aurait pu s’attendre à quelque chose comme « MOUNT ». En fait, le mount_ns étant le premier namespace proposé par Linux, les développeurs de l’époque ne pensaient pas que d’autres suivraient.
La figure 5 schématise le fonctionnement de clone() auquel on a passé les drapeaux CLONE_NEWUTS et CLONE_NEWIPC. Le processus fils est associé à de nouveaux ipc_ns et uts_ns et hérite les autres de son père.
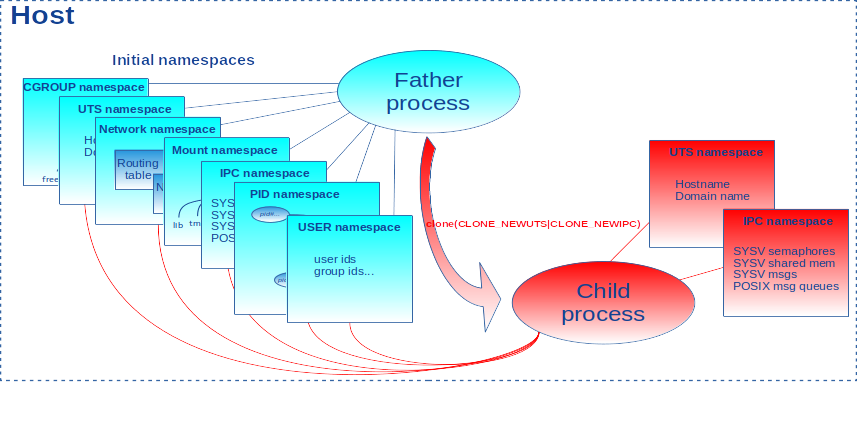
Notre programme clonens utilise cet appel système pour engendrer et associer un processus à de nouveaux namespaces dont les noms sont passés en argument :
Les noms de namespaces passés sur la ligne de commande sont convertis en drapeaux CLONE_NEW* via la fonction ns_name2type() pour être passés à l’appel système clone() qui crée un processus fils. Ce dernier exécute la fonction child() qui se met en attente avec l’appel système pause() tandis que le processus père attend sa terminaison via l’appel à waitpid().
Lançons ce programme pour créer un processus associé à de nouveaux pid_ns et uts_ns :
Dans un autre terminal, utilisons notre programme cmpns pour comparer ses namespaces à celui du shell courant :
Les pid_ns et uts_ns sont différents, comme attendu. Ce qui est aussi vérifiable en listant le contenu du répertoire /proc/<pid>/ns pour les deux processus.
Le service lxc-start, qui démarre un conteneur, s’appuie entre autres sur cet appel système pour créer le premier processus du conteneur et l’associer aux namespaces qui le caractérisent.
2.2 setns()
setns() permet au processus appelant de s’associer à un namespace existant. Le prototype est le suivant (cf. man 2 setns) :
Le premier paramètre fd est le descripteur du lien symbolique du namespace cible et le second paramètre nstype, qui a plus une fonction de mise au point qu’une réelle utilité, est le drapeau correspondant au type de namespace cible. Par type, on entend une valeur parmi les drapeaux CLONE_NEW* vus lors de la description de clone(). Ce paramètre peut être mis à 0 ou sinon doit avoir obligatoirement la valeur du drapeau correspondant au namespace associé au premier paramètre, sous peine de retour erreur !
Le service lxc-attach qui exécute un programme dans un conteneur s’appuie sur cet appel système. Il crée un processus fils sur l’hôte. Le fils s’associe à tous les namespaces qui caractérisent le conteneur cible avant d’exécuter le programme demandé.
Sur la même idée, notre programme execns prend en paramètres le pid d’un processus cible, les noms de namespaces du processus cible auxquels les associer (tous par défaut ou avec l’option all) et une commande à exécuter dans ces namespaces (par défaut /bin/sh). Le principe consiste à ouvrir une à une les cibles des liens symboliques dans le répertoire /proc/<pid_cible>/ns et à passer le descripteur de fichier associé à setns() afin d’associer le processus aux namespaces correspondants. Ensuite, un processus fils est créé via fork() (il hérite des namespaces de son père) pour exécuter le programme demandé. L’étape de création d’un processus fils peut paraître inutile, étant donné qu’une fois migré dans les namespaces cibles, le processus père pourrait exécuter le programme lui-même plutôt que de le sous-traiter à un fils. Mais une particularité des pid_ns empêche de faire cela : lorsqu’un processus change de pid_ns, seuls ses fils sont effectivement associés à ce nouveau namespace.
Avec ce programme, on peut ainsi exécuter une commande dans un conteneur comme on le ferait avec la commande lxc-attach. Dans l’exemple suivant, le process init d’un conteneur a l’identifiant 14010. On passe cet identifiant et le programme /bin/sh en paramètre à execns. On en profite pour positionner la variable d’environnement PS1 afin d’afficher le nom de l'host dans le prompt du shell (la variable est héritée par le shell créé). La mécanique mise en œuvre est schématisée en figure 6.
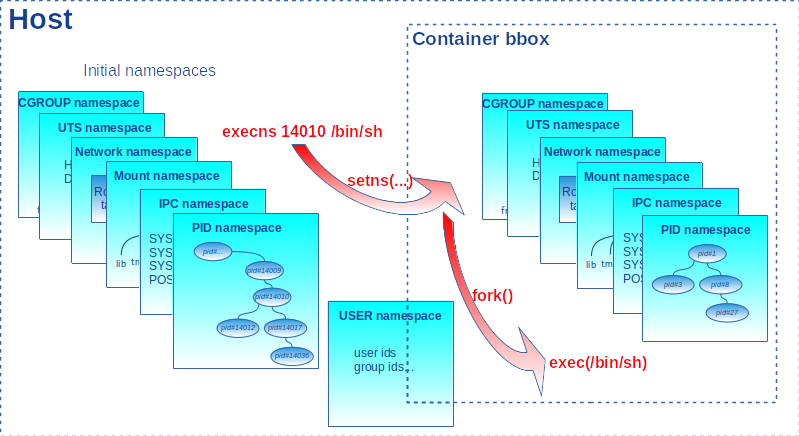
Dans le shell ainsi créé, la commande ps montre bien la liste des processus du conteneur et non pas celle du système hôte. On appelle exit pour sortir du shell et donc rendre la main au processus père qui affiche le statut de retour de la commande.
Le service setns() est aussi utilisé par la commande lxc-start à travers les trois options --share-net, --share-ipc et --share-uts pour respectivement partager le net_ns, l’ipc_ns et l’uts_ns d’un autre processus ou conteneur. L’option est accompagnée d’un pid ou d’un nom de conteneur. Dans le second cas, le pid du processus init du conteneur est récupéré à partir du nom. Puis, LXC ouvre le fichier /proc/<pid>/ns/[net|ipc|uts] et utilise l’appel système setns() pour migrer le conteneur dans le namespace correspondant.
2.3 unshare()
L’appel système unshare() permet au processus appelant de se désassocier d’une ou plusieurs parties du contexte d’exécution. Le prototype est le suivant (cf. man 2 unshare) :
Dans le cadre des namespaces, la fonction reçoit en paramètre le masque des drapeaux associés (c.-à-d. les constantes CLONE_NEW* vues dans la description de clone()) afin de créer de nouveau namespaces et les associer à l’appelant.
C’est par exemple utilisé avec le drapeau CLONE_NEWNS dans la commande lxc-create afin de créer le système de fichiers du conteneur dans un mount_ns séparé, de manière à éviter la pollution du mount_ns initial (le système de fichiers de l’hôte).
La figure 7 illustre le comportement de l’appel système lorsqu’il est appelé avec les drapeaux CLONE_NEWUTS et CLONE_NEWIPC. Un nouvel uts_ns ainsi qu’un nouvel ipc_ns sont créés. Le processus appelant se détache des namespaces d’origine correspondants pour être attaché à ces derniers. Mais rien ne change pour les autres namespaces.
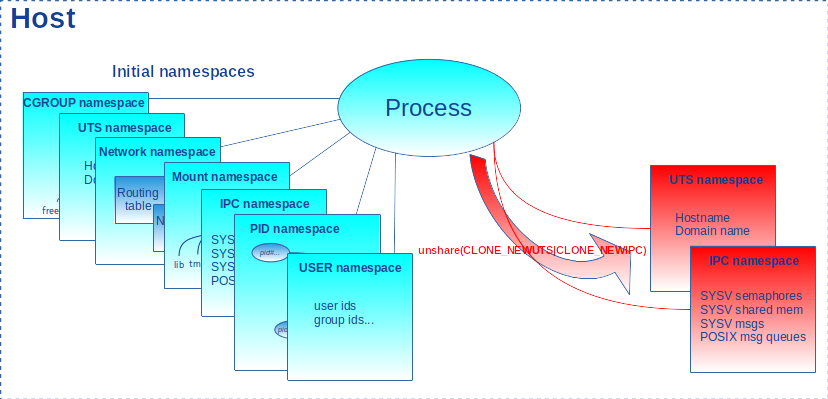
Notre programme shns donne la possibilité de créer un shell dans de nouveaux namespaces dont les noms sont passés en arguments (tous par défaut ou avec l’option all). Pour tous les namespaces demandés, le programme construit le masque de drapeaux associés et le passe à la fonction unshare(). Puis, un processus fils est créé (il hérite des nouveaux namespaces) via fork() pour exécuter le shell avec execv().
L’exécution de shns sans paramètre lance un shell dans de nouveaux namespaces. L’affichage de l’identifiant de process du shell courant donne la valeur 1, car le premier processus créé dans un nouveau pid_ns a pour identifiant 1 :
Dans un autre shell, nous cherchons le pid du processus shell fils de shns et pouvons vérifier que de nouveaux namespaces ont été créés en les comparant aux namespaces initiaux à l’aide de notre programme cmpns :
2.4 stat()
Déjà évoqué plus haut et de manière pratique dans les programmes cmpns et execns, l’appel système stat() permet entre autres de récupérer le couple « numéro de périphérique, numéro d’inode » de la cible du lien symbolique d’un namespace. Ce duo constitue l’identifiant unique d’un namespace. Muni de cette information, il est par exemple possible de comparer les namespaces.
Notre programme idns prend en paramètres le pid d’un processus et les noms de namespaces (tous par défaut ou avec le mot-clé all) afin d’afficher les identifiants correspondants :
Pour les namespaces initiaux et un conteneur, idns retourne par exemple ceci :
Le conteneur étant privilégié, il est associé au même user_ns que celui de l’hôte.
2.5 ioctl()
Quelques opérations relatives aux namespaces sont disponibles via l’appel système ioctl(). Toutes les opérations, sauf SIOCGSKNS, sont documentées dans man 2 ioctl_ns.
Dans sa version 2.1.1, LXC n’a pas du tout recours à ces opérations. Le champ d’application peut donc paraître assez limité.
2.5.1 NS_GET_USERNS
Cette opération retourne le descripteur de fichier référençant le user_ns auquel appartient un namespace (c.-à-d. le user_ns à partir duquel il a été créé). La fonction reçoit le descripteur de fichier fd du namespace et retourne le descripteur new_fd du user_ns auquel il appartient. Le prototype est le suivant :
La notion d’appartenance à un user_ns est importante pour des raisons de sécurité. Tout ce qui est fait dans un namespace donné est conditionné par le degré de privilèges configuré dans le user_ns auquel le namespace appartient.
Notre programme ownerns utilise cet ioctl pour déterminer le user_ns auxquels appartiennent les namespaces d’un processus donné (identifiant passé en premier paramètre). Les namespaces sont énumérés par leur nom sur le reste de la ligne de commande (tous par défaut ou avec le mot-clé all) :
Appelé sur hôte avec l’identifiant du shell courant, le programme affiche bien l’identifiant du user_ns initial :
L’erreur affichée pour le user_ns est conforme au manuel qui précise que EPERM est retourné si on tente d’obtenir le parent du user_ns initial.
Avec la même commande pour le processus init d’un conteneur, nous obtenons la même erreur pour le user_ns, car le conteneur étant privilégié, il est associé à celui de l’hôte (c.-à-d. initial) :
Si nous lançons un shell dans un nouveau pid_ns, net_ns, uts_ns et user_ns avec les options respectives -p, -n, -u et -U de l’utilitaire unshare (que nous verrons dans le prochain article) :
Dans un autre terminal, la commande owner_ns indique que le net_ns et l’uts_ns appartiennent au nouvel user_ns (c.-à-d. [4,4026532935]), par contre le pid_ns et le user_ns continuent à appartenir au user_ns initial (c.-à-d. [4,4026531837]) :
Tout cela s’explique par les raisons suivantes :
- Le nouvel user_ns appartient au user_ns à partir duquel il est créé. Ici, c’est le user_ns initial ;
- Le manuel des user_ns spécifie que clone() ou unshare() (appel système appelé par la commande unshare) avec entre autres le drapeau CLONE_NEWUSER, garantissent que le user_ns est créé en premier. Par conséquent, les namespaces créés dans la foulée appartiendront à ce nouveau user_ns. D’où le fait que les nouveaux net_ns et uts_ns de notre exemple appartiennent au user_ns nouvellement créé. Mais quid du pid_ns ? Devrait-il suivre la même règle ?
- Lorsqu’un processus appelle unshare() ou setns() avec le drapeau CLONE_NEWPID, ce sont ses fils qui entrent dans le nouveau pid_ns. Le père, donc l’appelant de ces appels système, est cantonné à son pid_ns courant qui appartient au user_ns initial. Comme l’utilitaire unshare n’invoque pas fork(), mais juste execv() pour lancer le shell, ce dernier reste dans le pid_ns initial. Par contre, les fils créés par le processus lancé par unshare (ici, la commande /bin/sh) entreront dans le nouveau pid_ns qui par conséquent appartiendra au nouvel user_ns.
Par la suite, la présentation de l’utilitaire unshare et ensuite du pid_ns permettront d’éclaircir ce propos, car le shell lancé comme précédemment ne peut lancer qu’une première commande, puis il affiche une erreur de fork() pour les suivantes :
2.5.2 NS_GET_PARENT
Cette opération retourne le descripteur de fichier (new_fd) référençant le namespace parent du namespace dont le descripteur de fichier est passé en paramètre (fd). Le prototype est le suivant :
Cela ne s’applique qu’aux namespaces hiérarchiques. Seuls deux namespaces le sont : le user_ns et le pid_ns. Pour tout autre namespace, l’erreur EINVAL est retournée.
Notre programme parentns est une copie de ownerns où l’opération NS_GET_USERNS a été remplacée par NS_GET_PARENT. Appelée avec un namespace non hiérarchique en paramètre, l’opération retourne l’erreur EINVAL conformément au manuel :
Avec un namespace hiérarchique, mais initial, l’opération retourne l’erreur EPERM conformément au manuel :
Si on l’appelle pour les namespaces pid et user situé dans un conteneur, on obtient l’identifiant du namespace père uniquement pour le pid_ns, car, le conteneur étant privilégié, il évolue dans le user_ns initial pour lequel l’opération retourne EPERM :
2.5.3 NS_GET_NSTYPE
Cette opération retourne le type de namespace (c.-à-d. le drapeau CLONE_XXX vu avec les appels système précédents) dont le descripteur de fichier est passé en paramètre (fd). Le prototype est le suivant :
2.5.4 NS_GET_OWNER_UID
Cette opération retourne l’identifiant d’utilisateur (troisième paramètre uid) du processus qui a créé un user_ns dont le descripteur de fichier est passé en paramètre (fd). Le prototype est le suivant :
Nous parlons ici de l’identifiant effectif de l’utilisateur du processus qui a créé le namespace. À ne pas confondre avec l’opération NS_GET_USERNS qui retourne le descripteur de fichier du user_ns auquel appartient un namespace donné.
Notre programme userns reçoit en paramètre le pid d’un processus et affiche le nom et l’identifiant de l’utilisateur de son user_ns :
Avec l’identifiant du shell courant, le programme affiche par exemple :
C’est effectivement sous l’identité du super-utilisateur que Linux démarre et crée ses namespaces initiaux.
2.5.5 SIOCGSKNS
Cette opération est à part, car elle n’est pas documentée. Elle a, semble-t-il, été introduite pour les opérations de « dump/restore » [11] des conteneurs OpenVZ [12] afin d’obtenir un descripteur de fichier fd sur le net_ns auquel un descripteur de socket sd est associé. Le prototype est le suivant :
Conclusion
La mise en œuvre des appels système à travers les programmes d’exemple qui ont jalonné cet article a d’ores et déjà révélé des subtilités sur les namespaces. Certaines ont été expliquées, mais d’autres juste mentionnées, pour ne pas alourdir le propos. Nous ne manquerons pas d’y revenir en détail dans les articles suivants ! Le second opus sera consacré aux utilitaires basés sur ces appels système.
Références
[1] The Use of Name Spaces in Plan 9 : http://doc.cat-v.org/plan_9/4th_edition/papers/names
[2] Le système Plan 9 : https://fr.wikipedia.org/wiki/Plan_9_from_Bell_Labs
[3] Plan 9 from Outer Space : https://fr.wikipedia.org/wiki/Plan_9_from_Outer_Space
[4] Le film « Ed Wood » de Tim Burton : https://fr.wikipedia.org/wiki/Ed_Wood_(film)
[5] Mount namespaces and shared subtrees : https://lwn.net/Articles/689856/
[6] Linux containers (LXC) : https://linuxcontainers.org/lxc/
[7] Les namespaces de Linux : https://en.wikipedia.org/wiki/Linux_namespaces
[8] L’intégration continue : https://fr.wikipedia.org/wiki/Int%C3%A9gration_continue
[9] BusyBox, le couteau suisse de Linux embarqué : https://busybox.net/
[10] Namespace file descriptors : https://lwn.net/Articles/407495/
[11] Add an ioctl to get a socket network namespace : https://lore.kernel.org/patchwork/patch/728774/
[12] OpenVZ : https://fr.wikipedia.org/wiki/OpenVZ



