

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
L’hétérogénéité des modes opératoires adverses et des outils pour les détecter a conduit naturellement à penser un format de détection générique, facilement compréhensible, clé de voûte d’une stratégie de détection efficace.
La cybersécurité est un domaine où la collaboration et l'échange d'informations sont essentiels pour lutter contre les menaces informatiques. Ces informations concernent aussi bien les groupes d’attaquants que leurs modes opératoires ou Tactique Techniques et Procédures (TTP) ainsi que les outils utilisés et indicateurs associés. Dans ce cadre, les formats normés offrent de nombreux avantages parmi lesquels l’interopérabilité, l’automatisation des processus de traitement, le maintien de la cohérence des données et une meilleure compréhension de la menace.
Parmi ces formats, citons « Malware Attribute Enumeration and Characterization » (MAEC) (https://maecproject.github.io/) qui comme son nom l’indique, permet l’échange d'éléments relatifs aux malwares issus des analyses statiques, dynamiques ou des métadonnées. Le format YARA (https://virustotal.github.io/yara/) permet la recherche de pattern dans des binaires et présente également un intérêt tout indiqué dans l’analyse des malwares. Enfin, le format « Structured Threat Information Expression » (STIX) (https://oasis-open.github.io/cti-documentation/stix/intro.html) permet de représenter les informations sur les cybermenaces.
Le format qui va nous intéresser est le format Sigma. Principalement utilisé au sein des Centres de Réponse aux Incidents Cyber (CSIRT), des centres d'alerte et de réaction aux attaques informatiques (CERT) ainsi que des Centres des Opérations de Sécurité (SOC), il propose un écosystème permettant d’écrire, de gérer et de partager des règles de détection relatives aux menaces œuvrant aussi bien sur les réseaux que sur les postes informatiques.
1. Au départ
Les modes opératoires adverses sont une source de savoir importante pour les équipes de détection et sont généralement décrits au sein de rapports de Cyber Threat Intelligence (CTI), de graphes de connaissance et d’artefacts, ils indiquent comment l’attaque s’est déroulée et quels sont les éléments caractéristiques permettant aux analystes de détecter ces mêmes menaces.
Sigma a été introduit en 2017. Il s’agit d’un format générique de signature pour les systèmes de gestion des informations et des événements de sécurité (SIEM) permettant aux organisations de normaliser et de partager des règles de détection de menaces indépendamment de la technologie utilisée. Cette normalisation ouvre la voie à la recherche agnostique en termes de plateformes et permet aux équipes de sécurité de collaborer plus efficacement pour détecter et répondre aux cybermenaces.
Les analystes de sécurité peuvent ainsi rédiger des règles de détection de menaces une fois et les utiliser sur plusieurs SIEM ou via des outils compatibles, ce qui réduit la duplication des efforts et améliore la cohérence des règles de détection.
Aujourd’hui, Sigma est une spécification en langage structuré pour le format de règles génériques, deux outils pour convertir les règles Sigma en divers formats de requête et un référentiel de plus d'un millier de règles couvrant de nombreux modes opératoires [1].
1.1 Concepts
L’écriture de règles de détection avec un format générique comme Sigma nécessite une couverture à la mesure de l'hétérogénéité des solutions. En effet, il en existe énormément et chacune dispose de son propre lot de fonctionnalités, il est par conséquent pratiquement impossible de tout couvrir. Heureusement, la plupart de ces produits possèdent une part importante de fonctionnalités communes et c’est celles-ci que Sigma a vocation à couvrir. Les règles Sigma doivent être converties dans un format propre à la solution de détection choisie. Cette conversion s’appuie sur différents outils qui seront présentés en 1.2.
Pour illustrer cela, prenons la règle sigma « lnx_auditd_disable_system_firewall.yml » qui a vocation à détecter la désactivation d’un pare-feu sur un serveur Linux. La détection s’appuie sur les critères déclarés dans la section détection. Ici, nous recherchons l’arrêt des services (SERVICE_STOP) firewalld, iptables et ufw.
Dans le détail, les champs sont répartis en deux catégories : métadonnées et détection.
Les métadonnées ajoutent du contexte à la règle et sont composées des champs suivants :
- title : texte assez court pour décrire ce que la règle se propose de détecter ;
- id : c’est un UUIDs (version 4) pour permettre son suivi dans le temps ;
- description : brève description de la règle et de l'activité malveillante qui peut être détectée ;
- author : créateur de la règle sigma ;
- references : références de la source d'où provient la règle. Il peut s'agir d'articles de blog, de documents techniques, de présentations ou même de tweets ;
- date et modified : date de création de la règle et de la dernière modification ;
- tags : permet d’ajouter du contexte, ici avec le framework MITRE ATT&CK® .
Le champ status permet de connaître le degré de maturité de la règle pour son utilisation :
- deprecated et unsupported ne doivent pas être utilisés ;
- experimental est le niveau de départ pour toute nouvelle règle ;
- test : la règle tourne depuis un moment avec quelques rares faux positifs ;
- stable : seuls de vrais positifs sont attendus.
À noter qu’une règle possédant un status stable peut tout de même renvoyer des faux positifs après une mise à jour du système d’exploitation ou bien lors de l’ajout d’un nouveau programme. Elle restera tout de même stable. Le seul cas pour lequel la règle changera de statut sera pour deprecated.
Le champ level permet de connaître le degré de gravité de la règle :
- critical : la menace est identifiée et doit être très pertinente ;
- high : la menace est de grande importance et doit être examinée manuellement ;
- medium : c’est une activité suspecte pouvant être un faux positif ;
- low : violation de la politique ;
- informational : ce n’est pas une alerte, mais un message à caractère informatif.
On peut diviser en deux les niveaux (level) :
- règles ayant un caractère informatif et devant être affichées dans une liste ou un diagramme à barres (informational, low, medium) ;
- règles qui doivent déclencher une alerte spécifique (high, critical).
La catégorie detection contient le cœur de la détection. Deux champs sont importants :
Le champ logsource permet de connaître la source de l’information.
Par exemple, sur un serveur Apache, il y a deux sources de journaux d’évènements ou « logs » :
- les logs WEB au format W3C access.log ;
- les logs de fonctionnement du serveur error.log.
Le champ detection définit la recherche effectuée sur les logs.
Les listes (avec le -) sont traitées comme des « OR » tandis que les maps (sans le -) comme des « AND ».
Dans cet exemple, le code est composé de deux sections :
- selection_or contient une liste composée de monchampA égal à « azerty » OU « querty ».
- selection_and contient un map, ce qui donne monchampA est égal à « azerty » ET monchampB est égal à « azerty ».
1.2 Les outils
En 2017, la publication de Sigma était accompagnée d’un démonstrateur de conversion écrit en langage Python par Thomas Patzke sous le nom de « sigmac». Or, sa conception monolithique le rendant difficile à maintenir et à mettre à jour, son auteur décida d’écrire son successeur en 2020 sous le nom de pySigma (https://sigmahq.io/). En avril 2023, sigmac a été mis en suspens après la version 0.23.1 et déplacé sur le dépôt : https://github.com/SigmaHQ/legacy-sigmatools. À noter qu’il existe également un site internet s’appuyant sur pySigma - https://sigconverter.io/ - assurant ces conversions.
1.3 Exemple de conversion
1.3.1 sigmac
La commande suivante convertit la règle présentée ci-dessus au format SQLite à destination de l’outil Zircolite (https://github.com/wagga40/Zircolite). Cet outil est spécialisé dans le traitement des fichiers EVTX, Auditd et Sysmon pour Linux.
1.3.2 pySigma
pySigma repose sur l’utilisation de « pipelines » pour effectuer des modifications génériques (normalisation, gestion de casse…) et d’un « backend » pour la transformation des règles vers le langage de sortie.
La figure 1 est une représentation du processus de conversion. L’utilitaire Sigma-cli permet de charger les fichiers de règles dans le moteur pySigma. Elles seront ensuite transformées via les « pipelines » afin d’adapter les critères de la détection à l’outil assurant cette détection. La dernière étape réalisée par le « backend » concerne la conversion.
PySigma se veut compatible avec le plus d’outils possible, mais cela reste compliqué au regard du nombre de solutions existantes. Il est possible de s’appuyer sur les plugins internes à l’outil ou bien développer ses propres « backend » et « pipeline ».
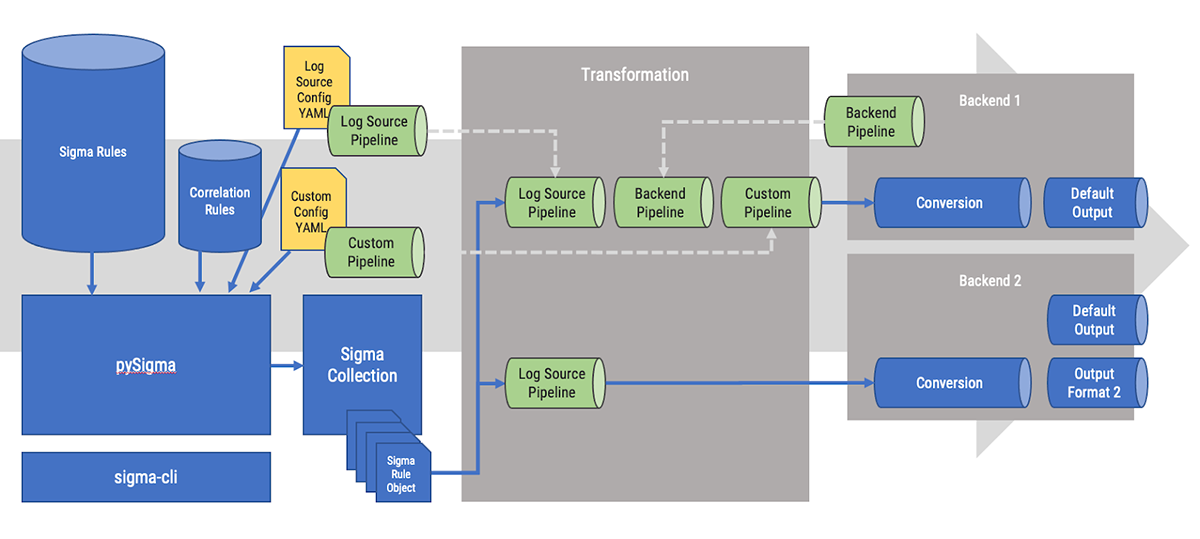
Nous allons illustrer ce concept en convertissant la règle Sigma pour Auditd présenté précédemment (lnx_auditd_disable_system_firewall.yml) à destination du moteur de détection Elastalert (https://elastalert2.readthedocs.io/en/latest/).
La première étape est de s’appuyer sur le « backend » Elasticsearch afin de convertir la règle Sigma en Lucene qui est le langage de requête natif à la suite Elastic. Au préalable, nous installons l’outil sigma-cli, via la commande pip install, afin de procéder à la conversion depuis le terminal. La seconde commande consiste à installer le plugin Elasticsearch qui intègre le « backend » et « pipeline ». La dernière commande est la conversion à proprement parler avec l’option convert. À noter que l’option --without-pipeline est ici obligatoire sinon l’outil émet une erreur, car la sortie Lucene exige d’avoir a minima un « pipeline ».
La suite Elastic s’appuyant sur le modèle de données unifié ECS, nous devons créer un « pipeline transformations » pour normaliser le nom des champs (https://sigmahq-pysigma.readthedocs.io/en/latest/Processing_Pipelines.html).
Fichier : auditd_ecs.yml
Le résultat de la commande confirme que nous avons les noms normalisés.
La dernière étape concerne la sortie, ici Elastalert. Nous utilisons pour cela un « pipeline postprocessing » avec un template jinja2. L’objectif de cette commande est que la requête soit mise dans une structure compatible avec Elastlalert.
Fichier : elastalert_any.yml
La règle est ainsi convertie dans le format voulu.
Cet exemple illustre l’adaptabilité du convertisseur et la philosophie sur laquelle repose pySigma. Dans bien des cas, il n’est pas nécessaire de réaliser toutes ces étapes. L’exemple ci-dessous converti une règle Windows vers Splunk plus simplement, car les « pipelines » et « backend » sont déjà présents.
2. Domaine d’emploi
2.1 Investigation numérique
L’investigation numérique est composée de nombreux processus permettant d’identifier, de prélever, d’examiner et d’analyser les preuves numériques tout en préservant l'intégrité des données et en maintenant une chaîne de contrôle des données complète [2].
Composée de 4 phases (identification, collecte, analyse et rapport) [2], la phase d’analyse a pour objectif d’identifier les éléments d'intérêt. Ces dernières années ont vu le développement d’outils s’appuyant sur les règles Sigma et offrant un gain de temps précieux aux analystes.
Zircolite offre des capacités de traitement des EVTX performantes. La différence principale réside dans le fait que cet outil s’appuie sur un « backend » Sigma plutôt qu’un moteur spécifique comme Chainsaw ou Hayabusa. Il présente également l’avantage de traiter d’autres formats d’entrée tels que le JSON, le XML et surtout les fichiers Auditd et Sysmon pour Linux. L’exemple ci-dessous illustre l’utilisation de Zircolite avec un fichier de logs Auditd couplé au set de règles de détection par défaut de Zircolite (rules_linux.json) composé de 168 règles. Le résultat met en avant deux règles medium qui mériteraient un approfondissement, les low n’étant qu’informatifs.
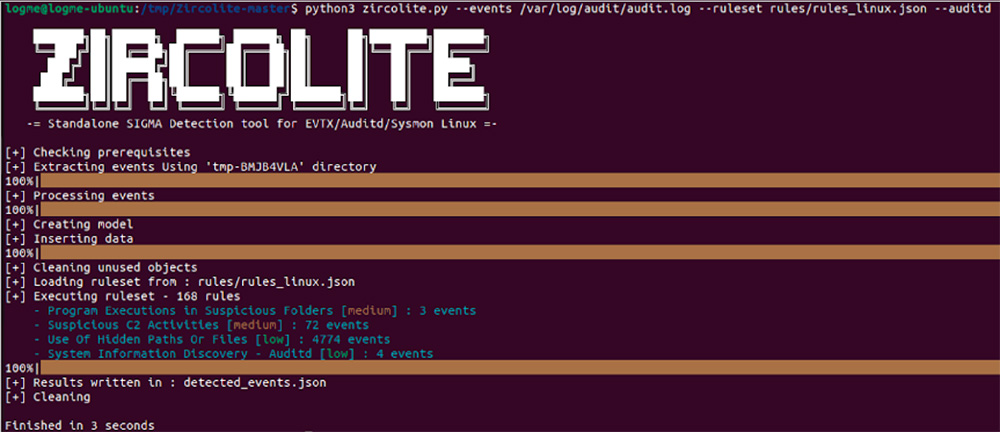
Pour compléter cette liste de solutions gratuites, notons que des solutions payantes telles que Drone, THOR ou bien Belkasoft X s’appuient également sur Sigma.
Ces outils apportent aux analystes une capacité de traitement rapide et efficace basée sur une meilleure compréhension de la menace. Les règles modifiées dans les deux premiers cas répondent à un besoin de précision dans les requêtes (vocabulaire adapté, expression régulière…).
2.2 SOC : stratégie de détection
Il s’agit ici d’un vaste sujet qui ne pourra être couvert en quelques lignes. De nombreux frameworks (Kill chain, UKC, MITRE ATT&CK…) et de nombreux ouvrages apportent déjà une vision exhaustive des moyens permettant de mettre en place une stratégie de détection efficace et en adéquation avec la menace. Nous allons aborder cela sous un prisme très restreint à savoir la manière dont Sigma peut être utilisé par un SOC.
L’objectif d’un SOC est de superviser un ensemble de systèmes d’information et de détecter, au travers de capteurs réseaux et de logs, des comportements malveillants. Sigma offre dans ce contexte, un cadre intéressant notamment, car il couvre de nombreuses menaces. L’erreur serait cependant de le considérer comme se suffisant à lui-même ; il faut comprendre par là que copier le contenu du dépôt SigmaHQ sur GitHub et déposer toutes les règles converties dans le langage de votre choix sans réflexion préalable conduirait à de nombreuses problématiques (faux positifs, nombreuses règles jamais utilisées, méconnaissance du système d’information supervisé...).
La stratégie proposée s’appuie sur une phase d’ajout de fonctionnalités (dans le cas présent des règles) dite build et une phase d’exploitation dite run ; elle concerne aussi bien les SOC matures que les SOC démarrant leur détection.
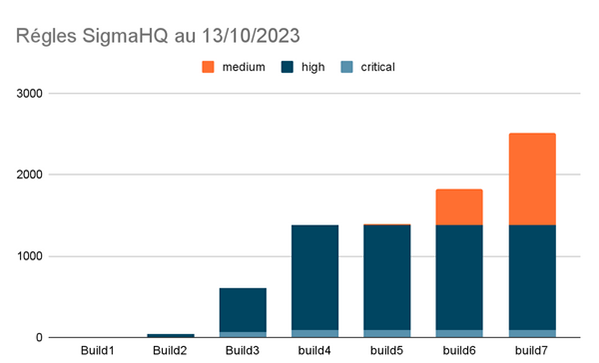
Les champs level et status peuvent servir de critères à une stratégie de déploiement des règles. La figure 3 présente des builds (combinaison de champs level et status) et le nombre de règles correspondant à cette combinaison. Nous observons par exemple que les 2 premiers builds sont beaucoup trop restrictifs, il est donc conseillé d’ajouter dès le début les 3 premiers builds afin d’arriver à une couverture suffisante en termes de règles. Les builds 4 et 6 sont des paliers importants qui nécessitent une certaine maturité du SOC. Les procédures de traitement des alertes doivent être maîtrisées ainsi que la mise à jour des règles. Chaque phase de build peut être l'occasion de faire modifier la politique de journalisation pour répondre au besoin.
Au-delà des critères level et status, il faut sélectionner les règles en fonction des sources de logs disponibles et des menaces. L’exemple le plus courant est le Script block Logging. Il s’agit d’un service qui, une fois activé, permet d’enregistrer le block de script Powershell exécuté. Il n’est pas activé par défaut sous Microsoft Windows, il est donc important de s’assurer de son activation afin que les règles reposant dessus fonctionnent.
La mise sous supervision d’un système d’information est plurifactorielle. Que voulons-nous protéger ? Quelles sont les menaces associées au contexte donné ? De ceci découle une politique de sécurité adaptée, une formation du personnel. Toutes ces questions amèneront inévitablement vers de nombreux outils selon ce qui sera considéré comme nécessaire à surveiller. Quelques exemples d’outils prenant nativement Sigma :
- Graylog v5 (Collecteur de log / SIEM) : https://graylog.org/ ;
- Aurora Agent (EDR) : https://www.nextron-systems.com/aurora/ ;
- HarfangLab (EDR) : https://harfanglab.io/.
2.3 Évolution
L’une des évolutions majeures du format Sigma est la corrélation. Elle s’appuie sur des meta-rules (https://github.com/SigmaHQ/sigma-specification/blob/version_2/appendix_meta_rules.md) et se compose de 2 catégories :
- corrélation ;
- filtre global.
Le filtre global consiste à pouvoir écrire le même filtre d'exclusion pour plusieurs règles. Cela revient à écrire l’exclusion à un endroit commun, unique et à ensuite l’appliquer à plusieurs règles.
La corrélation se compose de 3 possibilités :
- nombre d’évènements : pour exemple dans le cas de 100 tentatives de connexion échouées sur un hôte en une heure ;
- nombre de valeurs : tentatives de connexion échouées avec plus de 100 comptes d'utilisateurs différents par source et par destination au cours d'une même journée. L’idée est de compter sur un champ unique, mais en groupant 2 autres champs. Il faut donc avoir 100 fois le même triptyque utilisateur-source-destination ;
- temporelle : des commandes de reconnaissance définies dans trois règles Sigma sont invoquées dans un ordre arbitraire dans un délai de 5 minutes sur un système par le même utilisateur.
La refonte de la spécification est en cours de finalisation au moment de la rédaction de cet article, aussi certains éléments sont susceptibles d’évoluer.
Conclusion
Sigma est un format ouvert qui permet de créer des règles de détection de sécurité normées et portables. Simple à écrire et fort d’une communauté active, il propose un cadre intéressant pour la mise en place d’une stratégie de détection et pour identifier des modes opératoires adverses. Il existe de nombreux dépôts de règles sur Internet tel que le dépôt officiel SigmaHQ qui propose à ce jour plus de 3140 règles.
Que ce soient les projets ouverts ou les éditeurs logiciels, la tendance observée est la prise en compte de façon native, soit directement via un moteur dédié, soit indirectement en automatisant l’étape de conversion, ce qui décharge l’utilisateur de la phase de conversion manuelle.
Remerciements
Nous tenons à remercier toute la communauté derrière Sigma pour le travail réalisé et également Baptiste pour la relecture de cet article et la pertinence de ses remarques.
Références
[1] https://sigmahq.io/docs/guide/about.html
[2] Guide to Integrating Forensic Techniques into Incident Response NIST 800-86



