

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
À une époque où Internet ne cesse d'évoluer, l'utilisation des mécanismes de cache HTTP est devenue incontournable pour optimiser les performances des sites web. Cependant, ils peuvent aussi être la source de nouvelles vulnérabilités. Cet article explore donc leur sécurité en présentant comment ces derniers peuvent être à l'origine de failles critiques représentant une menace pour l'intégrité des applications web et la confidentialité des données des utilisateurs.
Avec l'essor d'Internet, les sites web sont devenus de plus en plus complexes et les fichiers nécessaires à leur fonctionnement plus nombreux. Le chargement des sites web a donc nécessité la récupération d'un nombre plus important de ressources, ce qui a augmenté le temps de chargement de ces derniers.
Pour que la navigation sur les sites modernes reste fluide pour un maximum d'utilisateurs, des mécanismes de cache ont été mis en place afin d'optimiser le temps de récupération d'une même ressource lorsqu'elle est accédée plusieurs fois.
L'objectif de cet article est de présenter les différents types de cache existants et leur fonctionnement, puis de revenir sur des vulnérabilités rendues possibles par l'existence de tels mécanismes.
Deux types de failles connues seront détaillés à l'aide d'exemples : les vulnérabilités de type « web cache poisoning » et « web cache deception ».
1. Les mécanismes de cache
Il existe deux types de mécanismes de cache côté client, et côté serveur. Dans les deux cas, l'objectif est de faire en sorte que lorsqu'une ressource est chargée une première fois, elle soit mise en cache afin que les prochains chargements de cette ressource soient plus rapides pour les utilisateurs. Les parties suivantes visent à détailler le fonctionnement de ces deux mécanismes [1].
1.1 Mécanismes de cache côté client
Les mécanismes de cache côté client se basent sur le navigateur des utilisateurs. L’objectif de ce type de cache est de sauvegarder les différentes ressources chargées lors du premier accès à un site web directement sur le système de l’utilisateur.
Les ressources stockées localement par le navigateur peuvent ensuite être accédées par l’utilisateur sans avoir à émettre de requête vers le serveur hébergeant le site web. Cela permet d’augmenter grandement la vitesse de chargement des pages déjà visitées précédemment par l’utilisateur.
La Figure 1 illustre le fonctionnement de ce mécanisme de mise en cache.

Ce mécanisme de mise en cache est dit « privé », car les ressources mises en cache sont liées à un unique utilisateur et peuvent donc contenir des informations propres à ce dernier.
1.2 Mécanismes de cache côté serveur
Les mécanismes de cache côté serveur se basent sur des serveurs cache jouant le rôle de proxy et se trouvant en amont des serveurs hébergeant les sites web. L’objectif de ces serveurs est de sauvegarder une copie locale des ressources populaires afin de les retourner directement aux utilisateurs, sans avoir à transmettre la requête au serveur hébergeant les sites web. Ce mécanisme permet donc de réduire la charge sur les serveurs applicatifs tout en accélérant le chargement des sites web.
La Figure 2 illustre le fonctionnement de ce mécanisme de mise en cache.
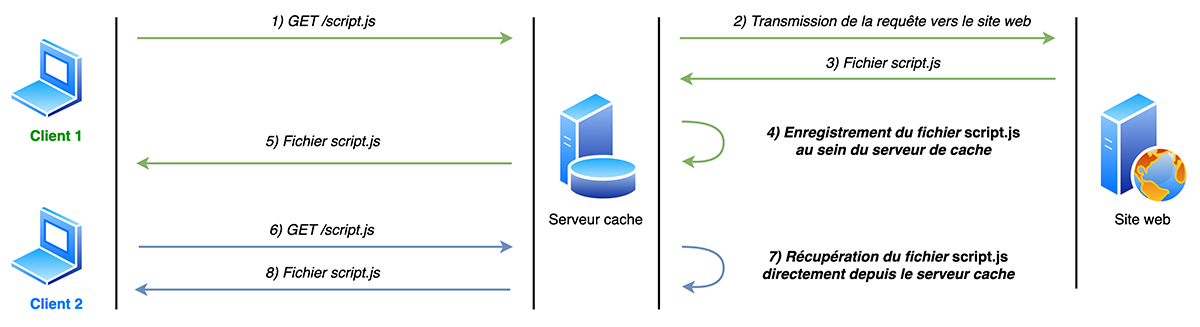
Ce mécanisme de mise en cache est dit « partagé », car les ressources mises en cache sont réutilisées par de nombreux utilisateurs et il est donc primordial qu’aucune information critique ne soit stockée par ces derniers.
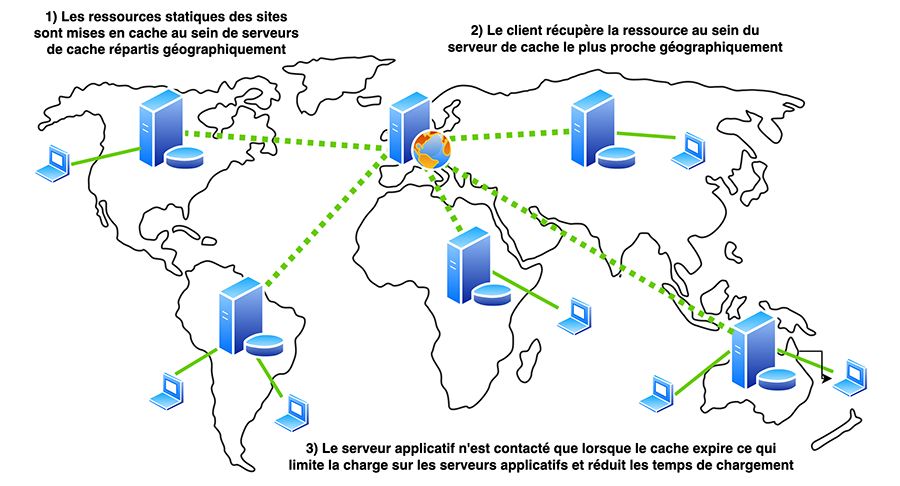
Pour optimiser les mécanismes de cache partagés, des réseaux de serveurs cache répartis géographiquement souvent nommés « Content Delivery Network (CDN) » ont été créés. Ces réseaux permettent de réduire encore plus le temps de chargement des ressources d’un site web en réduisant la distance physique que le contenu doit parcourir pour parvenir aux utilisateurs finaux. Ainsi des CDN tels que Akamai, Cloudfront et Cloudflare sont de plus en plus présents sur Internet et normalisent l’utilisation des mécanismes de cache partagé.
1.3 Configuration des mécanismes de cache
Pour mieux comprendre les différents mécanismes de cache, il est important de comprendre comment sont sélectionnées les ressources à « mémoriser », car toutes ne doivent pas l'être. Par exemple, certaines ressources comme les fichiers JavaScript, les images ou encore les vidéos sont légitimes à être mises en cache. Alors que les pages ou documents contenant des informations sensibles ne doivent pas être enregistrés au sein de caches partagés, sans quoi des informations sensibles pourraient être rendues accessibles au monde entier.
1.3.1 Entêtes HTTP utilisés par les mécanismes de cache
Pour simplifier le choix des documents à mettre en cache, des entêtes HTTP devant être spécifiés par les serveurs web existent. Ces entêtes visent à expliciter pour chaque ressource renvoyée par le serveur web, quelle est sa politique de stockage au sein des différents caches. Les navigateurs et les serveurs de cache se basent ensuite sur ces entêtes pour garder en mémoire ou non les différents fichiers d’un site web.
Les entêtes HTTP dédiés aux mécanismes de caches sont définis au sein de la RFC 9111 [2]. Ici, nous allons nous concentrer sur l’entête « Cache-Control » qui contient toutes les directives pour contrôler la mise en cache de fichiers, aussi bien au niveau des navigateurs que des caches partagés. Cet entête est primordial au fonctionnement des mécanismes de cache.
Voici les principales instructions utilisées au sein de cet entête :
- max-age : durée en secondes durant laquelle une réponse peut être conservée dans le cache ;
- public : autorise la mise en cache d’une réponse dans tous types de caches (ex. : privés et partagés) ;
- private : autorise la mise en cache d’une réponse au sein des caches privés (ex. : navigateur) uniquement ;
- no-cache : autorise la mise en cache d’une réponse sous couvert qu’elle soit revalidée avant chaque réutilisation ;
- no-store : interdit la mise en cache d’une réponse.
D’autres entêtes comme les entêtes « Pragma » et « Expires » utilisés avant l’apparition de l’entête « Cache-Control » ou encore des entêtes personnalisés utilisés par certains serveurs de cache existent, mais sont moins courants et ne seront donc pas détaillés au sein de cet article.
1.3.2 Configuration des serveurs de cache
Les entêtes HTTP ne sont pas les seuls mécanismes utilisés pour définir les documents devant être mis en cache. Les serveurs ont aussi leur propre configuration dans laquelle des règles personnalisées peuvent être configurées pour définir plus simplement les ressources à placer au sein de leur cache.
Il est donc courant de voir les serveurs de cache définir les règles suivantes :
- mise en cache de tous les fichiers se trouvant dans un certain dossier ;
- mise en cache des fichiers en fonction de leur extension ;
- mise en cache en fonction du nom des fichiers.
Par exemple, les serveurs de cache CloudFlare sont configurés pour placer automatiquement les fichiers avec certaines extensions (ex. : JS, CSS, CSV, GIF, PNG, ZIP, etc.) au sein de leur cache [3].
La mise en cache dépend donc à la fois de la configuration du serveur web hébergeant les ressources et de la configuration des serveurs de cache. Une différence de configuration entre ces deux entités pourrait donc mener à des comportements potentiellement à risques.
L’objectif des parties suivantes est d’expliquer comment il est possible d’exploiter les mécanismes de cache partagés pour réaliser des actions malveillantes. Nous verrons que ces mécanismes peuvent principalement être exploités dans deux buts précis : la mise en cache de documents malveillants et la mise en cache de données confidentielles.
2. Vulnérabilités de type « web cache poisoning »
2.1 Description
Les vulnérabilités de type « web cache poisoning » visent à placer une page malveillante au sein d’un cache partagé afin que cette dernière soit renvoyée aux utilisateurs à la place d’une page légitime.
Pour exploiter ce type de vulnérabilité, il est nécessaire que l’application présente une première faille de sécurité permettant de générer une réponse malveillante. Il faut donc que l’application soit vulnérable, par exemple, une injection de code JavaScript (XSS) ou une redirection non contrôlée. Aussi, la réponse malveillante doit être mise en cache au sein d’un cache partagé.
Ainsi, l’attaquant peut attendre l’expiration du cache, exploiter la vulnérabilité initiale et placer la réponse malveillante dans le cache. Tous les utilisateurs suivants verront la réponse contenant la charge utile de l’attaquant leur être retournée par le serveur de cache [4].
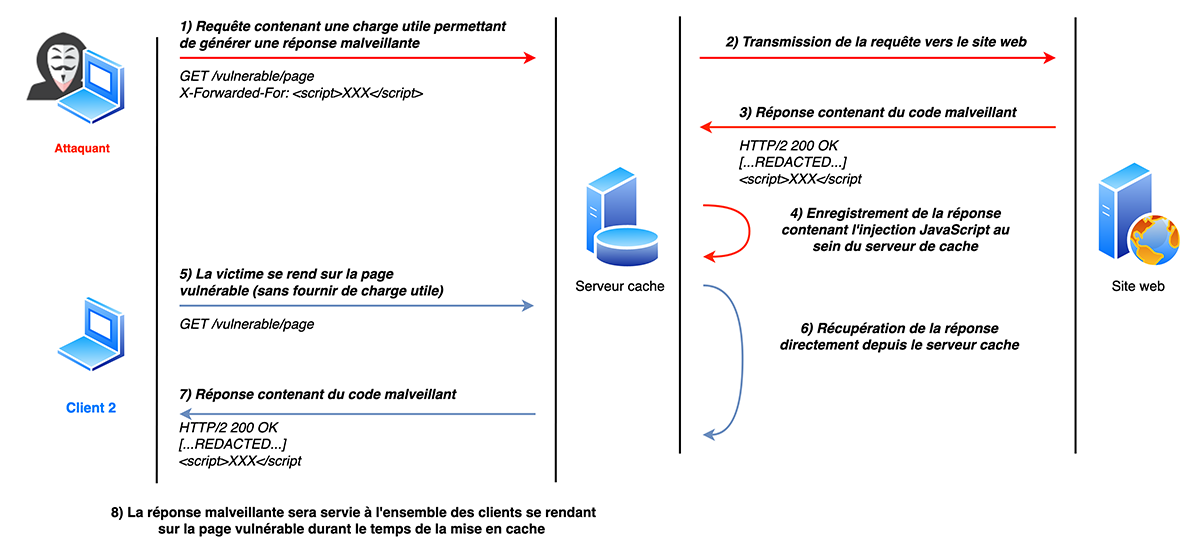
Ce type d’attaque n’est pas simple à mettre en œuvre, car il est difficile de contrôler la mise en cache sur des sites très fréquentés. En effet, au vu du nombre de requêtes reçues chaque seconde par de tels sites, le cache est rempli quasi instantanément après son expiration.
Mais l’exploitation de telles failles permet de créer un risque à partir de vulnérabilités qui ne seraient normalement pas exploitables. Par exemple, les injections de code JavaScript issues d’un entête ou encore d’un cookie deviennent exploitables lorsqu’elles touchent une page mise en cache.
2.2 Exemple d'exploitation
L’un des exercices de la plateforme Portswigger Academy [5] va désormais être utilisé afin d’illustrer le fonctionnement de ce type de vulnérabilité. Dans cet exemple, l’application vulnérable est une application de vente en ligne (Figure 6).
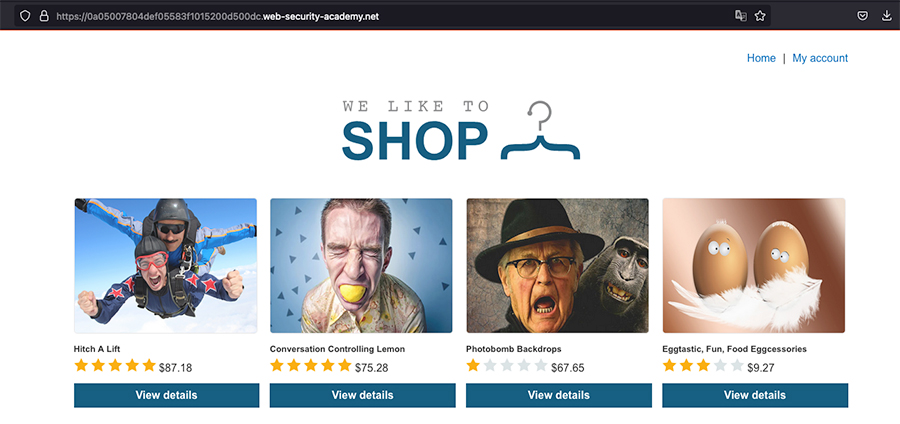
Lors du premier accès au site, il est possible d’observer que des entêtes propres à ces mécanismes sont retournés par le serveur :
Les entêtes présents dans la réponse ci-dessus sont les suivants :
- Cache-Control : indique la politique de mise en cache de la page ;
- Age : indique le nombre de secondes depuis lequel un objet se trouve dans le cache ;
- X-Cache : indique si la réponse est issue du cache.
La présence de ces entêtes permet d’identifier que l’application utilise un mécanisme de mise en cache.
Cependant, comme cela a été expliqué précédemment, afin d’exploiter ce mécanisme dans le cadre d’une attaque de type « web cache poisoning » il est nécessaire d’identifier une faille de sécurité permettant de générer une réponse malveillante. Ici, en analysant le fonctionnement de l’application, il est possible d’observer que la valeur de l’un des cookies de session est réfléchie sans vérifications au sein de la réponse retournée par le serveur. En modifiant la valeur du cookie, il devient donc possible d’injecter du code JavaScript (XSS) au sein de la réponse fournie par le serveur :
Par défaut, ce type d’injection JavaScript ne représente aucun risque pour les utilisateurs de l’application. En effet, la valeur injectée n’est pas stockée par le serveur, ce qui signifie que seuls les utilisateurs utilisant le cookie spécifiquement conçu verront le code JavaScript s’exécuter sur leur navigateur.
Le cookie étant propre à chaque utilisateur, il n’est pas possible d’exploiter cette vulnérabilité autrement qu’en convainquant un utilisateur d’injecter lui-même du code JavaScript au sein de son cookie (self-XSS). Ce scénario n’étant pas réaliste, ce genre d’injection n’est pas considéré comme une vulnérabilité dans la majorité des cas.
Cependant, dans le cas présent, étant donné qu’un mécanisme de mise en cache est configuré, cette injection devient exploitable. En effet, si un attaquant parvient à placer la page contenant la charge utile malveillante au sein du cache, durant toute la durée de mise en cache de cette dernière, les utilisateurs se rendant sur la page vulnérable verront le code JavaScript malveillant être exécuté au sein de leur navigateur, quelle que soit la valeur de leur cookie.
Un attaquant peut donc exploiter cette faille pour contrôler le contenu de la page placée dans le cache. En modifiant la charge utile, l’attaquant pourrait par exemple remplacer la page d’accueil du site par une page de phishing. Dans cet exemple, le « web cache poisoning » est utilisé pour transformer une self-XSS n’étant pas exploitable en une XSS stockée pouvant avoir un impact critique sur l’application cible.

3. Vulnérabilités de type « web cache deception »
3.1 Description
Les vulnérabilités de type « web cache deception » cherchent à réaliser l’inverse des vulnérabilités de type « web cache poisoning ». L’attaquant ne cherche plus à placer une page malveillante dans le cache afin de piéger sa victime, mais plutôt à faire en sorte que la victime place une page contenant des informations personnelles dans le cache afin de pouvoir récupérer ces informations [6].
Pour exploiter ces vulnérabilités, il est donc nécessaire d’identifier un défaut de configuration permettant de créer une confusion entre le serveur web hébergeant l’application et le serveur de cache afin qu’une ressource n’étant pas destinée à être mise en cache le soit tout de même. Ce type de défaut de configuration se nomme « path confusion » et désigne une configuration dans laquelle un même chemin d’URL est interprété différemment par deux serveurs.
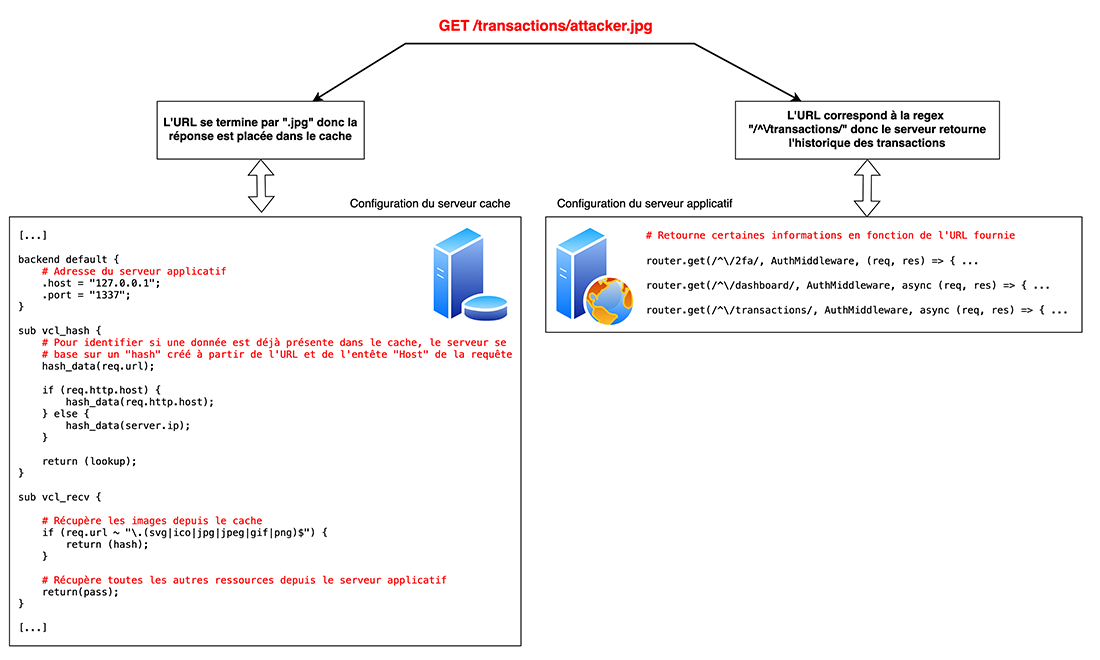
L’idée est donc d’utiliser ce type de défaut de configuration afin de faire passer une requête d’API légitime vers le serveur applicatif pour une requête vers un fichier statique devant être mis en cache aux yeux du serveur de cache. Une fois qu’une telle requête a été identifiée par un attaquant, l’objectif est de réaliser un phishing (ou d’exploiter une autre vulnérabilité telle qu’une XSS) afin de forcer la victime à émettre cette dernière de sorte que ses informations soient stockées dans le cache. Dès lors que les informations de la victime sont stockées dans le cache, l’attaquant n’a plus qu’à rejouer la même requête pour récupérer les informations.
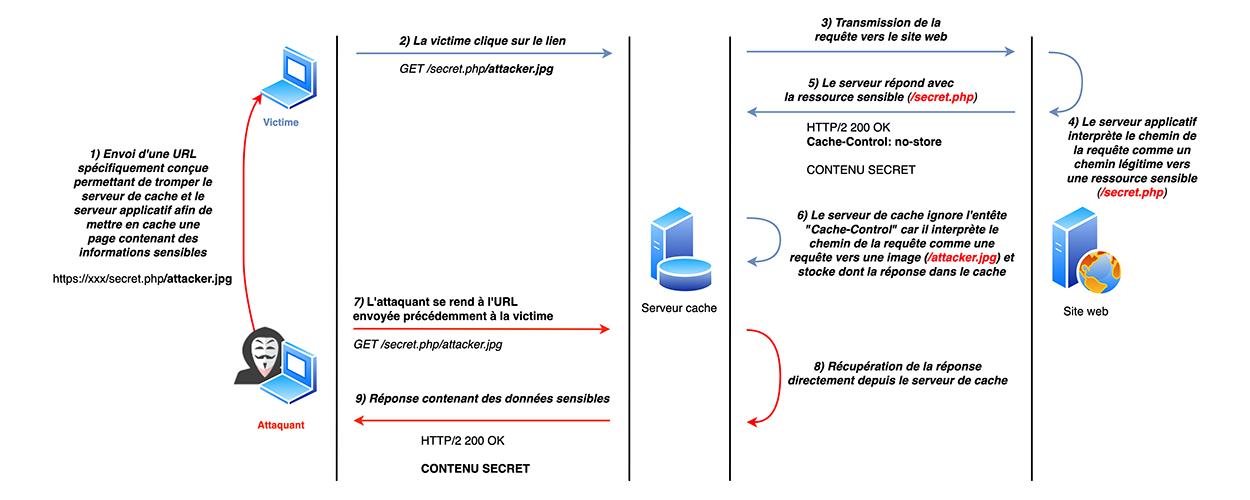
3.2 Exemple d'exploitation
Pour illustrer le fonctionnement des vulnérabilités de type « web cache deception », l’un des challenges de la machine « Forgot » issue de la plateforme Hack The Box [7] va être utilisé dans la suite de cette partie.
Dans cet exemple, le site web vulnérable est une application de ticketing. Cette application permet aux utilisateurs de générer des tickets qui seront ensuite traités par un service de support.
Deux types de profils différents existent sur cet environnement :
- Administrateur dispose d’un accès en lecture aux détails de l’ensemble des tickets ;
- Utilisateur dispose uniquement des privilèges nécessaires à la création de tickets.
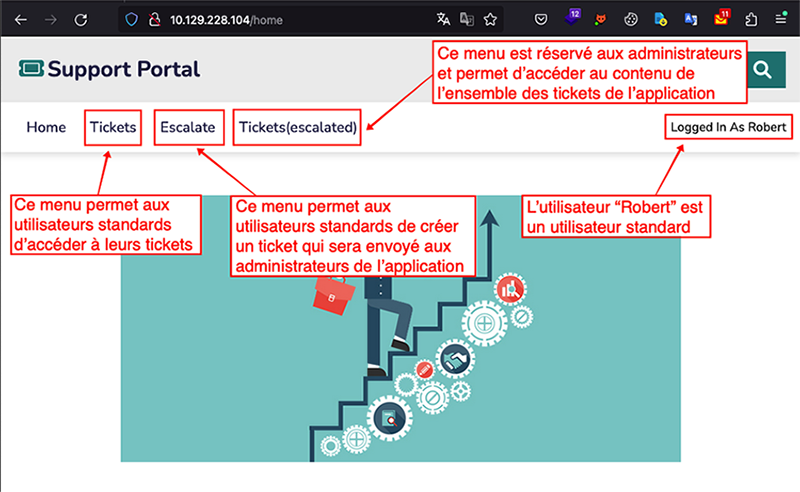
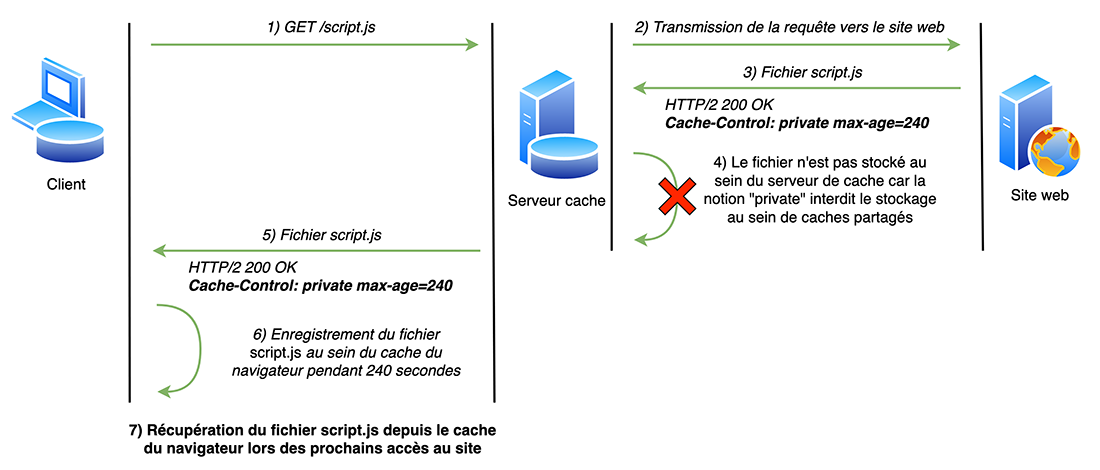
Ici, l’objectif va être d’utiliser un défaut de configuration au sein des mécanismes de cache afin d’accéder aux fonctionnalités d’administration depuis un compte utilisateur standard. Pour cela, il est tout d’abord possible d’observer qu’un mécanisme de cache est configuré pour les ressources statiques (JavaScript, CSS, images, etc.) du site web. Comme dans l’exemple précédent, la présence de ce mécanisme peut être observée à l’aide des entêtes retournés par le serveur :
Les entêtes ci-dessus indiquent que l’image peut être placée dans le cache durant 240 secondes. Aussi, l’utilisation du serveur de cache « Varnish » est mise en avant par les entêtes X-Varnish et Via. Toutes les ressources se trouvant au sein du dossier /static de l’application sont concernées par la mise en cache. Cependant, les autres pages de l’application ne sont pas mises en cache :
Cette observation permet de déduire que le mécanisme de mise en cache est configuré de manière à placer uniquement les fichiers issus du dossier /static au sein du cache. Ce dossier ne contenant que des images ou fichiers publics, il est légitime d’autoriser la mise en cache de ces ressources. Cette règle de mise en cache permet donc d’éviter la mise en cache de pages contenant des informations sensibles.
Cependant, la configuration du serveur de cache n’est pas assez précise. En effet, il semble que le serveur cherche uniquement le mot clé /static au sein des URL afin de déterminer si une ressource doit être mise en cache. Il est donc possible de créer des URL contenant ce mot-clé tout en étant en réalité à des pages n’étant pas destinées à être mises en cache :
Chemin | Résultat |
/static/../tickets/poc | Erreur 404 |
/tickets?a=static | Pas de mise en cache |
/tickets?a=/static/poc | Mise en cache de la page « /tickets » |
/tickets/static/poc | Mise en cache de la page « /tickets » |
Par exemple, la requête suivante permet de mettre en cache une réponse à une requête authentifiée vers la route contenant la liste des tickets accessibles par un utilisateur standard :
Une fois mise en cache, cette page normalement accessible uniquement par les utilisateurs authentifiés devient accessible sans authentification à l’aide de l’URL utilisée précédemment (Figure 11).
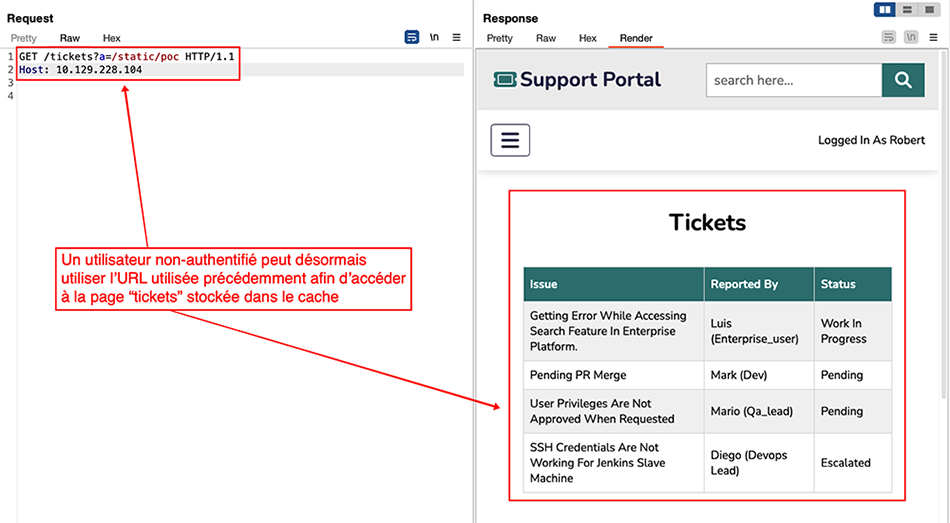
Cela signifie donc qu’un utilisateur non authentifié qui parvient à convaincre un utilisateur authentifié de cliquer sur un lien spécifiquement conçu peut faire en sorte de placer une page sensible dans le cache. Une fois que l’utilisateur authentifié a cliqué sur ce lien, l’attaquant pourra lui aussi consulter la page en utilisant ce dernier, car la page placée dans le cache précédemment par la victime sera retournée.
Il est donc possible d’utiliser ce comportement afin d’accéder au contenu de la page « Ticket (escalated) » de l’application. L’analyse du code HTML de l’application permet d’identifier que cette page est accessible à l’URL /admin_tickets. L’objectif est donc de réaliser un phishing menant l’administrateur à cliquer sur un lien spécifiquement conçu afin de placer cette page au sein du cache puis d’aller récupérer son contenu par la suite (Figure 12).
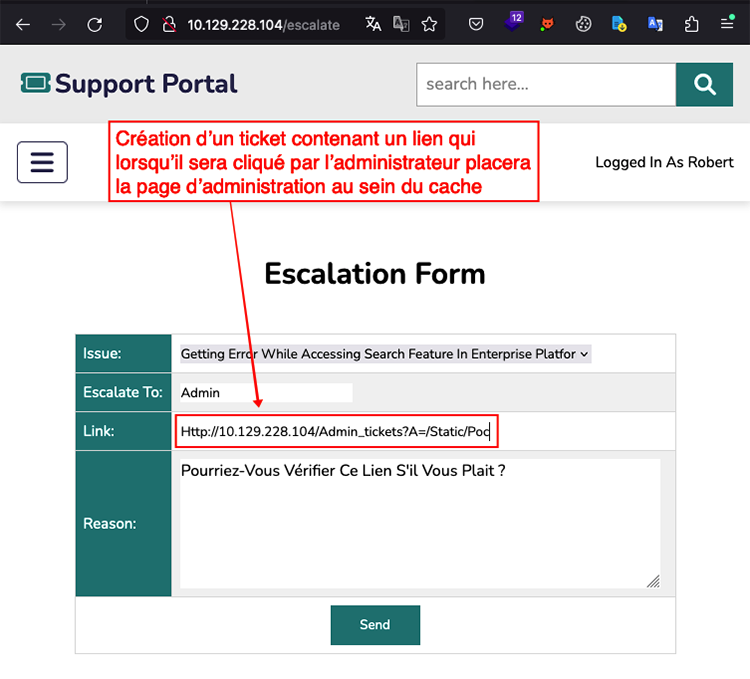
Une fois que l’administrateur a cliqué sur le lien, il est possible d’accéder à la page d’administration placée dans le cache en utilisant le même lien que celui envoyé précédemment (Figure 13).
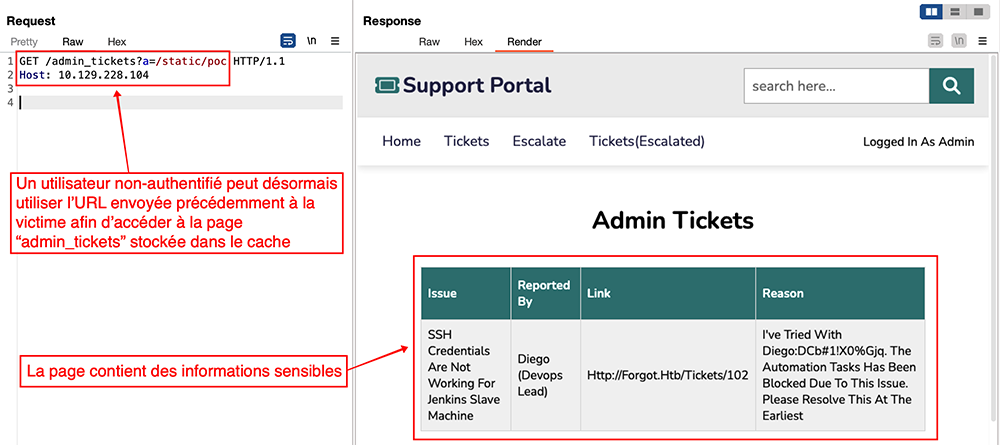
Un attaquant peut donc utiliser cette vulnérabilité de type « web cache deception » afin d’accéder à des informations sensibles. L’impact de telles failles peut être critique en fonction des informations qu’elles permettent de compromettre. Ici, les identifiants dérobés peuvent être utilisés afin d’obtenir un accès SSH au serveur de l’application.
Conclusion
Les mécanismes de cache font partie intégrante de l’Internet moderne. Ces derniers permettent d’accélérer le temps de chargement des ressources tout en réduisant la charge des serveurs applicatifs.
Cependant, ces mécanismes peuvent être à l’origine de nouvelles vulnérabilités telles que le « web cache deception » et le « web cache poisoning ». L’impact de ces failles dépend fortement des fonctionnalités offertes par le site vulnérable. Mais dans certains cas, l’impact peut être critique sur l’application et ses utilisateurs en permettant, par exemple, le défacement de sites web ou encore le vol d’informations sensibles.
Il est donc important de prendre les précautions suivantes lors de la mise en place d’un mécanisme de cache :
- corriger les vulnérabilités côté client (XSS, redirection non contrôlée, etc.) même si elles semblent inexploitables ;
- mettre en cache uniquement les fichiers explicitement autorisés à l’être (via l’entête Cache-Control) ;
- préférer l’utilisation de règles de mise en cache basées sur l’entête Content-Type (plutôt que via l’extension ou le chemin d’un fichier) ;
- limiter l’envoi d’entêtes non essentiels (Via, X-cache, etc.) révélant l’existence de mécanismes de cache.
Pour finir, il est intéressant de noter que les vulnérabilités concernant les mécanismes de mise en cache sont dues à des défauts de configuration au niveau de l’infrastructure et qu’elles peuvent donc impacter des applications dont le code respecte toutes les meilleures pratiques de sécurité. Cela permet de rappeler que la sécurité est un ensemble et qu’elle est autant de la responsabilité des développeurs que des équipes en charge de l’infrastructure.
Remerciements
Je remercie chaleureusement Florian Duthu, Stéphane Avi et Adrien Guinault pour leurs conseils précieux qui ont grandement aidé à la rédaction et la publication de cet article.
Références
[1] Présentation des mécanismes de cache HTTP :
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching
- https://www.cloudflare.com/en-gb/learning/cdn/what-is-caching/
[2] Entêtes HTTP dédiés aux mécanismes de cache : https://datatracker.ietf.org/doc/rfc9111/
[3] Configuration par défaut des serveurs de cache Cloudfare :
https://developers.cloudflare.com/cache/about/default-cache-behavior
[4] Vulnérabilités de type « web cache poisoning » :
https://developers.cloudflare.com/cache/about/default-cache-behavior
[5] Exemples d'environnements vulnérables aux failles de type « web cache poisoning » :
https://portswigger.net/web-security/all-labs#web-cache-poisoning
[6] Vulnérabilités de type « web cache deception » :
- https://www.blackhat.com/docs/us-17/wednesday/us-17-Gil-Web-Cache-Deception-Attack.pdf
- https://portswigger.net/daily-swig/path-confusion-web-cache-deception-threatens-user-information-online
[7] Plateforme « HackTheBox » : https://www.hackthebox.com/