

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
L’autre jour, en passant dans le couloir, j’ai vu Peter apparemment très concentré sur son écran. Je me suis dit qu’il devait faire un truc intéressant, lui. En comparaison, moi j’avais épuisé les derniers travaux intéressants : il ne me restait plus qu’à écrire de la doc ou bien préparer mon entretien annuel. Clairement, la tentation était trop grande et je suis entré dans son bureau pour en savoir plus…
Il régnait dans le bureau de Peter un désordre typique des grands créatifs. Il passait d’ailleurs un peu trop souvent d’un sujet à l’autre, et pour pouvoir revenir rapidement au sujet précédent, il fallait à chaque fois laisser tout le setup bien en place...
Moi> Salut Peter ! Tu fais quoi ?
Peter> Ah, salut. J’essaie de mettre en place un VPN.
Moi> Ah, oui, avec Wireguard ou OpenVPN j’imagine ?
Peter> Non justement, j’essaie de trouver un setup alternatif pour le cas où les admin réseaux n’autorisent pas ces paquets réseaux UDP. C’est pour un logiciel que je distribue, donc je ne sais pas où et dans quels environnements ce module VPN sera installé.
Le plus simple pour créer un réseau virtuel, c’est d’utiliser des interfaces virtuelles. Pour un VPN entre une machine A et une machine B, on aura donc évidemment une interface virtuelle sur chacune des deux machines, et on fera transiter le trafic réseau entre ces 2 interfaces par un moyen sécurisé de son choix.
Moi> Quand tu dis « interface réseau virtuelle », tu penses à quelle techno ?
Peter> Je pensais utiliser des interfaces TUN. Tu connais ?
Moi> Je me souviens avoir vaguement exploré la chose. Mais ça m’a paru un peu obscur et assez compliqué. Déjà, pourquoi ce nom « TUN », et pas quelque chose de plus clair comme VPN-NET ?
Peter> Eh bien, parce que ça peut servir pour mettre en place autre chose qu’un VPN ! C’est par exemple un outil classique pour fournir le réseau à une machine virtuelle…
Peter se retourna vers moi, et en voyant mon air interrogateur, il s’arrêta quelques instants. Il est clair que je ne suis pas vraiment familier de ce genre de concept, et que fournir une explication qui me soit accessible devait lui demander un peu de réflexion. Mais il reprit :
Peter> En fait, du point de vue du noyau Linux, une interface physique et une interface virtuelle, c’est presque la même chose, et il va les gérer de la même façon. La différence majeure entre les deux, par contre, c’est ce qu’on va connecter dessus. Dans le cas de l’interface physique, on va connecter un vrai câble réseau et sans doute une machine ou un réseau de machines à l’autre bout. Dans le cas de l’interface virtuelle, ce qu’on connecte, c’est un programme informatique qui va simuler quelque chose. Par exemple, si ce programme est un gestionnaire de machine virtuelle, alors ce qu’on simule c’est un « câble virtuel » et une machine connectée de l’autre côté. Mais un programme encore plus complexe pourrait très bien simuler tout un réseau de plusieurs machines.
Moi> OK, intéressant... Mais pour un VPN, il n’y a rien de « simulé » ?
Peter> Euh… Si... En quelque sorte, le programme VPN simule « un réseau branché en direct sur l’interface », alors qu’en réalité le réseau en question est beaucoup plus loin.
Moi> Mouais. Bon. Il n’empêche que dans mes souvenirs, l’API est relativement obscure.
Peter> Tu te trompes ! Allez, je te prends au mot, essayons d’implémenter quelque chose de simple… Par exemple, on pourrait simuler une machine connectée de l’autre côté du câble virtuel et qui répond au ping ?
Moi> D’accord.
1. Une machine qui répond au ping
Peter commença à dérouler quelques lignes de commande.
Peter> On va faire du Python, c’est pas mal pour prototyper pas à pas. J’ai installé scapy dans mon « venv », c’est une librairie qui va nous aider à interpréter et générer les paquets réseau.
Pour avoir le droit de créer l’interface TUN, il faut des privilèges spéciaux. Pour ce premier test, j’utilise simplement sudo. On verra plus tard comme faire mieux à ce sujet.
Je commence par définir quelques constantes bas niveaux. En Python, elles ne sont pas connues, mais avec un grep dans /usr/include, on a vite fait de repérer leur valeur.
À présent, passons aux choses sérieuses. Pour créer une interface réseau virtuelle, il faut ouvrir le fichier spécial /dev/net/tun. Cet open() nous retourne un descripteur de fichiers que j’ai appelé tun_fd et qui permettra de manipuler la nouvelle interface réseau.
Ensuite, c’est la partie la moins triviale. Le truc, c’est que /dev/net/tun permet de créer 2 types d’interfaces virtuelles, au choix TUN ou TAP. Avec TUN, le programme va gérer des paquets IP. Avec TAP, il devrait gérer la couche Ethernet en plus, ce qui n’est pas utile dans notre cas. Pour configurer le mode TUN donc, on utilise un appel système ioctl() :
En C, cette partie serait plus explicite. En fait, le dernier argument de ioctl() est censé être une struct ifreq. Là, pour forcer Python a gérer un espace mémoire sous ce format, on bidouille un peu. Mais passons. On a donc choisi IFF_TUN plutôt que IFF_TAP, et avec IFF_NO_PI on désactive un header inutile1 devant chaque paquet.
Et voilà, via un autre terminal, on peut voir que notre nouvelle interface réseau est apparue !
Profitons de ce terminal pour lui donner une IP et la passer UP.
Moi> Du coup, 192.168.3.2 va devenir l’IP de la machine virtuelle qu’on simule ?
Peter> Non, ne mélange pas tout ! Là, on a juste configuré l’interface virtuelle, on ne simule rien pour l’instant ! Bon, je crois que tu as besoin d’un petit dessin (figure 1).
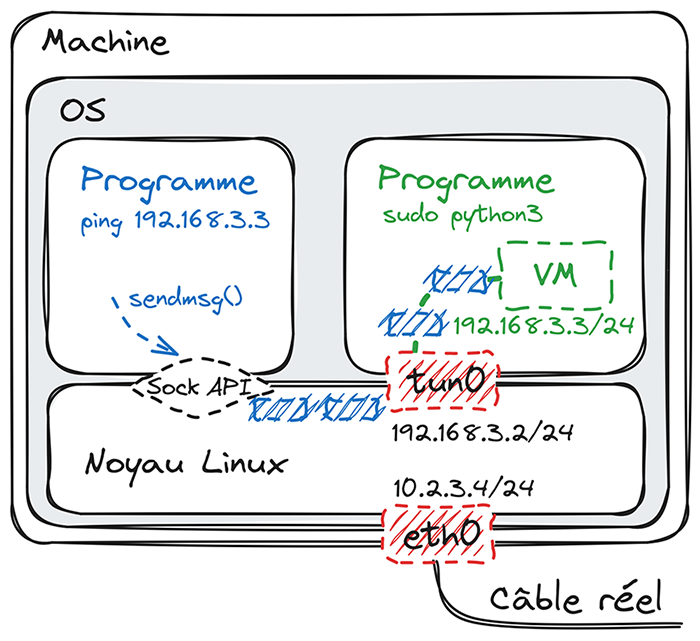
Regarde la partie « noyau Linux » en bas. Quand tu commences à t’embrouiller, le mieux est de revenir à l’analogie avec les interfaces réseau physiques. Là, on a configuré notre interface virtuelle tun0 de la même façon qu’on aurait configuré une vraie interface, par exemple eth0 sur mon dessin. Ce qui diffère, c’est que sur eth0 on a connecté un vrai câble réseau, pour communiquer avec de vraies machines ; alors que sur tun0, on a connecté un programme, qui devra simuler quelque chose. En l’occurrence, notre programme, c’est l’interpréteur Python. Et ce qu’on veut simuler, c’est une machine qui répond au ping. Maintenant, regarde à gauche. Tout à l’heure, on va lancer un ping vers l’IP de cette machine qu’on simule. J’ai choisi 192.168.3.3 pour cette IP. Comme tu le sais sûrement, la commande ping envoie des paquets réseau ICMP « echo request » et attend des paquets ICMP « echo reply » en retour. Ces paquets « echo request », dessinés en bleu, sont générés via l’API socket, puis routés par le noyau Linux. Ils auront pour destination 192.168.3.3, donc le noyau les enverra vers tun0, plutôt que eth0, puisque le sous-réseau 192.168.3.0/24 correspond. Du coup, plutôt que d’être transmis sur un vrai câble réseau, ils seront transmis à notre programme Python. À ce moment-là, notre programme aura juste à générer un paquet « echo reply » et à le renvoyer dans l’autre sens, pour faire croire qu’une machine a répondu.
Moi> OK, c’est beaucoup plus clair. Donc, si je comprends bien, notre programme Python qui a créé l’interface TUN, c’est lui qui doit aussi gérer les paquets ?
Peter> Oui, en tout cas, c’est le fonctionnement par défaut. Il y a moyen de déléguer cette gestion à un autre programme, mais on verra ça plus tard.
Moi> Autre question : comment notre programme va-t-il recevoir les paquets qu’il doit gérer ? Et renvoyer les réponses ?
Peter> Tu ne devines pas ? Regarde le code qu’on a écrit pour l’instant.
Moi> Euh... le seul moyen qu’on a pour communiquer avec le noyau, c’est tun_fd… donc... on ferait un read(tun_fd) pour recevoir les paquets à gérer et write(tun_fd) pour renvoyer les paquets-réponses ?
Peter> Tout à fait ! Tu vois, cette API TUN/TAP, tu aurais presque pu la concevoir toi-même !
Moi> Mouais. Bon, on continue ?
Peter> Oui. Donc là, toujours sur mon deuxième terminal shell, je lance le ping et je le laisse tourner :
Et revenons côté Python. En toute logique, ici on devrait recevoir les « echo request » générés par la commande ping.
Tu vois, on a bien reçu un 1er paquet ! Normalement, comme on fait du TUN et pas du TAP, on reçoit des paquets IP : les premiers octets sont ceux de la couche IPv4, puis ceux de la couche ICMP. Pour d’autres protocoles, on pourrait avoir davantage de couches réseau, par exemple IPv4 + TCP + HTTP (ou IPv6 + TCP + HTTP). Bref. Utilisons Scapy pour décoder.
Ah tiens, perdu ! Visiblement, c’est un paquet IPv6. Essayons de le décoder correctement.
C’est donc... un paquet émis par le mécanisme d’autoconfiguration IPv6. Il est clair que dès qu’une nouvelle interface apparaît, l’OS envoie aussitôt quelques paquets pour essayer d’obtenir une IP, via DHCP ou via ce mécanisme d’autoconfiguration IPv6, ou pour détecter les adresses IPv6 dupliquées, etc. Notre interface TUN ne fait pas exception à la règle.
Mais nous, on n’a rien implémenté pour répondre à des paquets de ce genre. Donc, faisons une boucle pour passer rapidement ce trafic initial :
Et voilà nos paquets « echo-request » qui arrivent toutes les secondes !
Moi> Sympa. Il ne nous reste plus qu’à renvoyer une réponse pour chacun de ces paquets…
Peter> Oui. Il va me falloir un autre import et trouver l’entier correspondant au type « echo-reply » :
En fait, notre paquet « echo reply » ressemblera beaucoup au paquet « echo request » reçu, sauf qu’on doit changer son type, inverser IP source et IP destination, et recalculer les checksums.
Pour le filtrage des paquets à traiter, je vais juste vérifier que ce sont des paquets ICMP. Normalement, il faudrait aussi vérifier le type « echo request » et l’IP de destination.
Voilà ce que ça donne :
Tu vois, simple et efficace. La seule subtilité, c’est la méthode pour forcer Scapy à recalculer les checksums : on supprime l’attribut correspondant du paquet.
Voilà, laissons tourner cette boucle, et revenons sur le terminal où on a lancé le ping :
Et voilà !!
Moi> Pas mal !! Même moi qui ai suivi la manip’ pas à pas, quand je vois cette commande ping, j’arrive presque à croire qu’une vraie machine nous répond !
2. Interfaces virtuelles et langage C
Peter> Bon, ensuite, on va s’arranger pour que ça fonctionne sans être root. En fait, le programme a juste besoin des droits d’administration réseau, pas de tous les droits root. On va donc utiliser les capabilities. Mais pour ça, on va devoir passer au langage C.
Moi> Ah bon, les capabilities, ça ne marche pas en Python ?
Peter> Si éventuellement, mais elles définissent les droits d’un exécutable. Et comme Python est un langage interprété, c’est sur l’interpréteur Python qu’il faudrait les définir...
Moi> Ah, je vois. Il est clair qu’en ajoutant des droits d’administration à un interpréteur Python, on diminuerait plus qu’on ne renforcerait la sécurité de notre OS…
Peter> C’est clair. Bon, en fait, j’ai déjà écrit un programme en C avant que tu n’arrives [1]. Le voici :
C’est un prototype, il faudra que je vérifie les codes de retour un peu partout.
Globalement, ce programme se charge de configurer une interface TUN, puis il passe la main à un autre programme. Du coup, il fonctionne un peu comme sudo : on doit lui passer en argument l’autre programme à lancer (argv[2+]). L’autre programme, ça peut être du Python, du C, du shell, etc., ce qui est bien pratique pour prototyper.
Je commence donc par vérifier que l’invocation semble conforme à cet usage en ligne 17. Puis j’initialise une interface TUN, comme on a fait en Python. En ligne 27, je définis cette fois-ci explicitement le nom que je veux pour cette interface, mytun, afin de mieux m’y retrouver dans mes tests. Ensuite, lignes 29 à 43, je profite des droits d’administration réseau pour définir l’IP de l’interface (on l’indique via argv[1]), son netmask, et la passer UP, avec à nouveau des appels ioctl(). Tu te rappelles, tout à l’heure on avait fait la même chose, mais manuellement en utilisant la commande ip dans le 2e terminal. Et enfin, lignes 44 à 47, je définis quelques variables d’environnement et je passe la main au 2e programme, via execvp() : le processus en cours est alors remplacé par la commande passée en argument.
Moi> À quoi sert le assert(tun_fd == 3) en ligne 23 ?
Peter> assert(), c’est une fonction de la libc qui déclenche un abort() si la condition n’est pas vérifiée. Je l’utilise comme garde-fou vis-à-vis d’évolutions du code. Là, vu que c’est le début du programme, le premier entier disponible pour faire office de descripteur de fichiers devrait être 3, puisque 0, 1 et 2 seront déjà pris (stdin, stdout et stderr). Si le programme est lancé normalement, il n’y a pas de doute. Mais si dans le futur je rajoute du code avant cette ligne, il y a un risque de casser cette condition.
Moi> OK… Autre question. Le file descriptor numéro 3 a été ouvert par le 1er programme, mais le code semble laisser entendre qu’il sera encore disponible dans le 2e programme… C’est le cas ??
Peter> Tout à fait. C’est le comportement par défaut, en tout cas2.
Moi> Donc, dans ce 2e programme, on pourra recevoir les paquets à gérer en lisant ce file descriptor 3, et générer des paquets en retour en écrivant sur ce même file descriptor 3, comme on a fait en Python ?
Peter> Exactement. Je vois que tes cellules grises sont bien activées, à présent ! Bon, allons-y, compilons.
Voilà, on a un bel exécutable tun-do. Mais en l’état, il nécessite des privilèges.
3. Les capabilities
Peter> Rajoutons donc les capabilities sur ce fichier exécutable.
Les caractères « e » et « p » spécifient chacun un « capability set » dans lequel CAP_NET_ADMIN doit être ajouté : « effective » et « permitted ». Ce qu’on veut, c’est qu’à l’exécution du binaire, le programme soit immédiatement doté de cette autorisation, ce qui correspond au capability set effective. Mais tout ce qui est dans effective doit aussi être permis, donc être aussi dans permitted.
Une autre solution serait de mettre CAP_NET_ADMIN uniquement dans permitted, et pas dans effective, mais cela obligerait notre programme à rajouter lui-même la capability dans effective au démarrage, en utilisant prctl().
Intéressons-nous maintenant à la fin du programme. En fait, une fois que l’initialisation de l’interface réseau est faite, on n’a plus besoin de droits spéciaux : lire ou écrire sur un file descriptor ne requière aucun privilège. Donc, pas besoin de conserver ces capabilities quand on passe la main au 2e programme, au moment du execvp(). Ça tombe bien, CAP_NET_ADMIN sera automatiquement supprimé de nos 2 capability sets à ce moment-là ; cela fait partie du fonctionnement normal de execvp().
Pour ta culture, note aussi qu’il y a d’autres capability sets disponibles, justement utiles si on voulait conserver des capabilities au-delà du execvp().
4. Un shell pour vérifier
Peter> Grâce à tun-do, on peut maintenant fonctionner sans être root. Commençons par lancer un shell :
Tu vois, ça passe, pas besoin de sudo.
Tu te demandes peut-être pourquoi j’ai utilisé --norc... c’est un peu subtil. Tu sais qu’à la fin de tun-do.c, j’ai redéfini la variable d’environnement PS1, pour faire visuellement la différence entre le shell initial et celui qu’on a lancé avec tun-do : l’invite de commande est maintenant libellée « tun-shell ». Mais si on lançait Bash sans l’option --norc, il relirait ses fichiers de profil, il y trouverait à nouveau la définition par défaut de PS1, et il écraserait notre valeur !
Vérifions qu’on a bien obtenu ce qui était prévu :
Tu vois, l’interface mytun existe bien, elle est UP et elle a bien l’IP spécifiée.
Et on a bien le file descriptor 3 qui a été conservé. Je ne vais pas te refaire toute la boucle de réponse au ping, mais vérifions au moins qu’on peut toujours lire des paquets sur ce file descriptor, à ce stade.
Tu vois, on reçoit les paquets sans soucis. C’est comme tout à l’heure, l’OS a dû générer quelques paquets pour essayer d’initialiser l’interface, et c’est le premier de ces paquets que l’on vient de lire. Pour l’écriture, ça marche aussi, et je te demande juste de me croire sur parole.
5. SSH, un tunnel bidirectionnel générique
Peter> On se rapproche doucement de notre implémentation de VPN… En gros, j’envisage de le monter via un tunnel SSH entre deux interfaces TUN, chacune sur une machine. En choisissant SSH, je suis à peu près sûr qu’aucun admin réseau ne va interdire le trafic réseau nécessaire.
Tu sais, la commande ssh peut être utilisée comme un tunnel bidirectionnel… Regarde ceci, par exemple3:
Le mot « test », qu’on a envoyé sur le stdin de ssh, est transmis à travers le tunnel SSH vers la machine vpn-server, puis se retrouve sur le stdin de la commande cat qui tourne là-bas. Cette commande recopie le mot lu sur stdin sur son stdout, et ça repart dans le tunnel SSH en sens inverse, pour apparaître au final sur le stdout de la commande ssh, donc sur notre terminal.
Moi> Oui, ça je maîtrise. Pour transférer de gros répertoires, j’ai parfois combiné ssh avec tar et zstd.
Peter> OK. Bon, eh bien maintenant, dans un tunnel SSH, on va transférer des paquets réseau.
6. Client VPN
Peter copia tun-do.c sur vpn@vpn-server, le compila sur cette machine et ajusta les capabilities. Logique, puisque là-bas aussi il faudrait créer une interface TUN. Puis il reprit :
Peter> Je te propose d’intégrer la partie client VPN dans un script client.sh. Le voici :
On crée juste l’interface TUN locale, et le gros du boulot est délégué à un 2e script client‑2.sh que voici :
Voilà. Cette simple commande SSH suffit, je pense. On verra juste après l’implémentation de endpoint.sh côté serveur.
Moi> OK… Tu utilises cette notation avec l’esperluette pour référencer le file descriptor 3... Si j’ai bien suivi, ce file descriptor est ouvert par tun-do au moment où il crée l’interface TUN locale, stdin, stderr et stdout occupant déjà les entiers 0, 1 et 2. Ensuite, tu rediriges le stdin et le stdout de la commande ssh vers ce file descriptor… Donc si je comprends bien, la commande ssh aura le même rôle que notre interpréteur Python tout à l’heure. En particulier, elle recevra sur son stdin les paquets que le noyau lui donne à gérer. Comme tu l’as montré avec le petit test du paragraphe précédent, ces paquets sur stdin seront injectés dans le tunnel SSH et reçus de l’autre côté sur le stdin de endpoint.sh.
Peter> Oui, c’est ça. Et comme tu peux t’en douter, quand endpoint.sh devra renvoyer des paquets dans l’autre sens, il les écrira sur stdout. Le petit test précédent montre alors que ces paquets traverseront le tunnel SSH dans l’autre sens, puis seront émis sur le stdout de notre commande ssh locale, c’est-à-dire sur le file descriptor 3, et donc injectés dans l’interface TUN locale.
Moi> OK, ça me paraît cohérent.
7. Endpoint VPN côté serveur
Peter> Alors c’est parti pour le côté serveur, avec endpoint.sh :
Voilà, j’imagine que tu n’es pas trop surpris pour l’instant… Mais la suite est plus inattendue, voici le contenu de endpoint‑2.sh :
Moi> Ah, oui… Bon, en fait, je ne savais pas trop à quoi m’attendre. Mais je crois que je devine ce que ça fait. On a vu que ce qui arrive sur le stdin de endpoint.sh, qui est aussi le stdin de endpoint‑2.sh, ce sont les paquets transmis depuis le côté client. Ces paquets-là, il est logique de les injecter dans notre interface TUN locale, ici côté serveur, et c’est ce que fait le 2e cat. Quant au 1er cat, celui en background, il a pour stdin le file descriptor 3, donc il est là pour capturer les paquets émis par le noyau de ce côté-ci, côté serveur, et il les copie sur son stdout. Son stdout n’est pas redirigé, donc c’est le même que celui de endpoint.sh, et comme on a vu tout à l’heure, ces paquets traversent alors le tunnel SSH dans l’autre sens pour au final être injectés dans l’interface TUN côté client.
Peter> Eh oui, tu as tout bon. Note juste une subtilité : si tu inverses les 2 commandes cat, alors celle qui lit stdin se retrouvera en background, et ça ne marchera plus ! Je te laisse méditer là-dessus...
8. Premiers tests
Peter> Bon, il n’y a plus qu’à tester si ça marche vraiment. Comme tu as vu, client.sh déclenche toute la mécanique, y compris côté serveur. Donc, allons-y :
Maintenant, lançons un ping dans l’autre terminal. Pour l’instant, on va juste essayer de joindre l’IP à l’autre bout du tunnel.
Ça fonctionne, on dirait !
Pour faire passer davantage de trafic dans le tunnel, il faut quelques confs supplémentaires. Il faudra bien sûr automatiser ces choses-là dans la version finale.
Ici côté client, je vais remplacer ma default gateway, 192.168.172.1, par 192.168.3.3, pour envoyer le trafic vers le tunnel. Par contre, pour que le tunnel SSH puisse continuer à fonctionner, il faut que je garde une route pour savoir comment joindre le serveur SSH par le réseau physique :
Côté serveur, il faut relayer les paquets qui arrivent depuis le tunnel pour les envoyer à leur destination finale, via l’interface de sortie, qui s’appelle ens2 sur ce serveur. Pour ce test, je vais me contenter d’une configuration grossière avec l’ancien outil iptables :
Maintenant, depuis le client, on devrait pouvoir aller plus loin :
Ça marche toujours !
9. Des perfs au ras des pâquerettes ?
Peter> Voyons ce que ça donne côté débit. Côté serveur, je lance iperf en mode serveur :
Et je lance la mesure de débit TCP depuis le client :
Quoi ?? 1,67 Mbit/s ?? On est reparti dans les années 70, ou quoi ?
Moi> Ça ne pourrait pas être dû à ton implémentation, qui n’est pas très rapide, tout simplement ?
Peter> Écoute, je ne vois pas pourquoi elle ne serait pas rapide… Le gros du boulot, c’est le chiffrement, qu’on fait faire par ssh, qui est tout de même un soft éprouvé. D’ailleurs, il utilise par défaut le même algo’ de chiffrement que Wireguard, « chacha20-poly1305 » ! Le programme tun-do passe la main très rapidement, donc il ne peut pas être en cause non plus. Il y a les commandes cat, qui font un travail hyper simple, donc a priori pas de souci de ce côté non plus... Et le reste, les scripts shell, ils sont juste là pour l’orchestration, ils ne traitent pas les flux de données...
Nous passâmes quelques minutes à vérifier le setup. Mais tout semblait fonctionnel. D’ailleurs, le ping fonctionnait toujours aussi bien. Mais finalement, une idée apparut dans mon esprit.
Moi> J’ai peut-être une idée. Quand tu lis les paquets sur tun_fd, le noyau t’envoie un paquet réseau et un seul pour chaque read(), n’est-ce pas ?
Peter> Oui, et alors ?
Moi> Eh bien, j’imagine que pour les write() c’est pareil, il faut écrire un paquet et un seul par write(). Or là, on concatène les paquets dans le canal SSH, et donc, suivant le débit, la taille du payload SSH et des buffers réseau, de l’autre côté on peut sans doute recevoir en une seule lecture un buffer contenant plusieurs paquets concaténés. Et la fin du buffer ne sera pas forcément une frontière entre 2 paquets. Du coup, si ce buffer côté récepteur n’est pas un paquet et qu’on essaie de l’écrire sur tun_fd, il est ignoré par le noyau.
Malgré tout, ton tunnel reste fonctionnel en cas de débit très bas, car un débit très bas implique que les paquets sont espacés dans le temps. S’ils le sont suffisamment, alors ils seront bien reçus un par un de l’autre côté, et ça fonctionne. À mon avis, c’est donc le contrôle de congestion TCP lié à iperf qui converge vers ce débit de 1,67 Mbit/s. Grosso modo, ça doit être le débit maximal au-delà duquel les paquets se retrouvent concaténés à la réception et donc perdus. Même si cette valeur de 1,67 Mbit/s est faible, c’est le meilleur débit que TCP arrive à trouver !
Peter> Ça se tient, ton analyse... Et dans le cas du ping, on ne voyait pas le problème, puisqu’on a un temps d’attente d’une seconde entre chaque paquet, donc effectivement des paquets très espacés dans le temps…
Moi> Oui, c’est ça. Il faut donc qu’on délimite correctement les paquets dans le canal SSH, pour pouvoir les écrire un par un sur tun_fd de l’autre côté. Par exemple, en les préfixant d’un champ indiquant leur longueur.
Peter> OK. Eh bien, allons-y. Il va nous falloir 2 programmes complémentaires.
Après 15 minutes, ces deux programmes étaient prêts. Le premier, tun‑read.c [1], lisait en boucle les paquets sur tun_fd=3 et les copiait sur son stdout, mais en préfixant la longueur à chaque fois sur deux octets. C’est simple, car la longueur d’un paquet, c’est tout simplement la valeur de retour du read() sur tun_fd. Le deuxième, tun‑write.c [1], lisait un flux délimité de cette façon sur son stdin, et s’assurait d’écrire chaque paquet correctement sur tun_fd=3. Peter reprit alors la parole.
Peter> Il reste à modifier nos scripts shell. Commençons par client‑2.sh :
Voilà. Il suffisait de remplacer les redirections vers le file descriptor 3 par des appels à tun‑read et tun‑write, et faire le lien avec des pipes.
Et pour endpoint-2.sh :
Encore plus simple. Il n’y a plus qu’à retester...
Ah, voilà des résultats4 qui me conviennent mieux !!
10. Sécurisation du serveur
Moi> Bon, je vais devoir y aller. À part refaire une version « production », qu’est-ce qu’il te reste à faire ?
Peter> Je vais améliorer la sécurité côté serveur. C’est là qu’on a notre porte d’entrée SSH accessible depuis Internet, donc là qu’il y a le plus de risques.
Bien évidemment, je vais utiliser le fichier .ssh/authorized_keys pour autoriser les clients. Mais plutôt que d’utiliser une simple paire de clés pour chaque client, ce qui m’obligerait à éditer ce fichier à chaque nouveau client, je vais utiliser des certificats. Il n’y aura donc qu’une seule ligne, qui référencera le certificat que j’aurai généré pour l’autorité de certification. Si ça t’intéresse, recherche l’option cert-authority dans man authorized_keys. Par ailleurs, dans la même ligne de .ssh/authorized_keys, j’utiliserai l’option command pour forcer l’utilisation de la commande endpoint5, et l’option restrict pour interdire les fonctionnalités annexes (redirections de ports, etc.).
Et enfin, je crois que je vais aussi revoir l’architecture du soft côté serveur, toujours dans cette optique de renforcer la sécurité. Car le fait de donner des droits d’administration réseau sur un exécutable de cet utilisateur vpn, auquel on se connecte par SSH depuis Internet, ce n’est quand même pas idéal. L’alternative, bien plus sûre, est de laisser tourner un service VPN doté de CAP_NET_ADMIN et qui se chargera de créer et configurer lui-même les interfaces TUN pour chaque nouveau client. Notre programme endpoint n’aura donc plus besoin de CAP_NET_ADMIN. À la place, il enverra un message sur un socket UNIX, sur lequel le service VPN écoute, pour demander une interface TUN. En retour, le service VPN créera l’interface, et lui transmettra le file descriptor correspondant comme donnée auxiliaire de son message de réponse.
Moi> Comment ça ?? On peut transmettre un file descriptor d’un processus à un autre à travers un socket UNIX ??
Peter> Bien sûr. Regarde la doc Python de sendmsg() [2] et recvmsg() [3], tu as un bel exemple de code pour le faire. C’est grosso modo la même chose en C.
Moi> OK, très intéressant… Mais donc, en quoi est-ce plus sécurisé de déléguer ces opérations ?
Peter> Disons que CAP_NET_ADMIN donne au final beaucoup de droits. Un pirate qui trouverait une brèche pourrait s’en servir pour se connecter à un VLAN d’administration, par exemple, peut-être reconfigurer des switchs, etc. En comparaison, le service VPN nous livre une interface déjà configurée. Dans le cas de mon logiciel par exemple, l’interface obtenue sera connectée à un réseau d’expérimentation, pour la recherche, et le user vpn auquel on se connecte depuis Internet n’aura pas les droits pour en faire autre chose.
Moi> Je vois. Bon, je dois te laisser, et me remettre à des choses inintéressantes.
Peter> D’accord, bon courage ! Et merci pour le coup de pouce sur le problème de délimitation des paquets !
Conclusion
J’aime bien l’approche de Peter qui combine des briques simples pour obtenir une fonctionnalité complexe. Ça fait très « philosophie UNIX ». Le principal avantage, c’est sans doute que quand on rajoute une brique, cela a peu d’incidence sur la complexité globale. D’ailleurs, quand je suis parti de son bureau il venait d’ouvrir la page de manuel de zstd, et je le soupçonnais donc de vouloir intercaler des briques de compression et décompression supplémentaires dans ses scripts ! Et j’avais raison, il me l’a confirmé le lendemain au café, mais c’était plus compliqué que prévu. Dans la même veine, puisque la bande passante du tunnel est limitée par la commande SSH qui sature un cœur CPU, il voulait aussi tester l’établissement de plusieurs tunnels entre les deux machines, pour ensuite les combiner via une technique d’agrégation de liens [4].
Cela faisait un moment que je n’avais pas discuté « technique » avec Peter [5] [6], et je crois que ça me manquait un peu. Je remercie H-J. Audéoud, K. Ngongang, A. Tchana et O. Alphand pour les relectures !!
Pour aller plus loin
L’originalité principale de ce VPN est de transporter des paquets sur un lien TCP (sous-jacent au lien SSH) et non UDP comme les VPN classiques (Wireguard, par exemple). Comme en général la plupart du trafic transporté est lui aussi basé sur TCP, on obtient du TCP sur TCP. Et si on n’y prend pas garde, l’interférence dans la gestion de congestion des 2 couches TCP peut sûrement causer des problèmes de performance. En fait, il faut que le VPN simule un lien avec pertes, parce que le trafic TCP à l’intérieur du tunnel se base sur ces paquets perdus pour adapter son débit. Si on cherche au contraire à transmettre tous les paquets, alors que le débit plus loin dans le réseau est trop faible, on va faire artificiellement monter la latence au lieu de diminuer le débit… Il faut donc détecter la congestion6, et se résoudre à abandonner certains paquets !
Malgré ces imperfections, nos premiers tests sur des Raspberry Pi semblent montrer que ce type de VPN peut être au final plus efficace que Wireguard. Pourquoi ? Je n’en suis pas sûr. Mais j’ai ma petite idée…
Références
[1] Dépôt de code lié à cet article : https://github.com/eduble/glmf-peter-reseaux-virtuels
[2] Doc Python de sendmsg() : https://docs.python.org/3/library/socket.html#socket.socket.sendmsg
[3] Doc Python de recvmsg() : https://docs.python.org/3/library/socket.html#socket.socket.recvmsg
[4] Page Wikipédia sur l’agrégation de liens réseau : https://fr.wikipedia.org/wiki/Agr%C3%A9gation_de_liens
[5] DUBLE E., « Le Test de Peter », GNU/Linux Magazine n°206, juillet-août 2017, p. 52 et gratuit en ligne : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-206/le-test-de-peter
[6] DUBLE E., « Le Cerveau de Peter », GNU/Linux Magazine n°219, octobre 2018, p. 8 et gratuit en ligne : https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-219/le-cerveau-de-peter
1 Ce header optionnel encode le type de paquet et deux octets de flags dont je n’ai pas trouvé la définition.
2 Si on veut au contraire qu’un file descriptor soit automatiquement fermé en cas d’appel exec*(), il faut activer son flag FD_CLOEXEC.
3 On voit que Peter peut se connecter à vpn@vpn-server sans mot de passe, il a sans doute ajouté une clé publique dans .ssh/authorized_keys pour cela.
4 Ce test a été fait avec des nœuds virtuels sur la même machine, la bande passante obtenue est uniquement limitée par la commande ssh qui sature un cœur CPU.
5 Jusque-là dans nos tests, en écrivant ssh vpn@vpn-server endpoint.sh, c’est côté client qu’on se décidait pour la commande à lancer côté serveur... Un expert sécurité ferait clairement une attaque, en voyant ça !
6 En détectant un buffer de sortie plein via select() ou implicitement (write() partiel), ça se fait...


