

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
L’étude et la compréhension des buffer overflow datent de 1972, et leurs premiers usages documentés de 1988 [1]. Près de 50 ans plus tard, où en sommes-nous ? Il nous faut bien admettre que la situation est déprimante : Microsoft et Google reconnaissent chacun ([2], [3]) que près de 2/3 des attaques utilisent à un moment ou un autre une vulnérabilité mémoire. Le ver Morris, qui n’était au départ qu’une preuve de concept, avait quand même coûté la bagatelle de quelques millions de dollars à l’époque… Aujourd’hui, les coûts sont abyssaux : sur le plan financier bien sûr, mais aussi pour nos vies privées, voire nos vies tout court. Face à ce problème, de nombreuses approches sont possibles : analyse statique du code, instrumentation et vérification à l’exécution, langages « sûrs »… Je vous propose d’explorer dans cet article un vieux concept remis au goût du jour, les capabilities, et tout ce qu’elles pourraient nous permettre de faire.
La sûreté mémoire désigne la protection de la mémoire contre des accès erronés (les bogues logiciels) ou frauduleux (vulnérabilité de sécurité) et peut être vue suivant deux axes :
- la sûreté spatiale concerne les problèmes liés aux buffer overflows et autres accès hors bornes ;
- la sûreté temporelle concerne les problèmes liés à la temporalité : use-after-free…
On peut blâmer avec justesse le C ou le C++ d’être des langages sans sûreté mémoire, mais ce sont ceux qui étaient disponibles en production à l’époque où les lignes de code de nos environnements ont été écrites. Réécrire toutes ces lignes dans un langage plus policé, Rust par exemple, est tout simplement impossible. Qui peut se lancer aujourd’hui dans l’aventure de réécrire complètement toutes les couches logicielles qui tournent sur un de nos chers smartphones ? À ce titre, le post [4] de Daniel Stenberg, créateur et mainteneur de curl, est édifiant : il considère que même pour ce simple programme, ce serait une tâche extrêmement ardue de le réécrire en Rust en maintenant la compatibilité, et que même en cassant la compatibilité en introduisant un nouveau backend à curl, l’affaire n’est pas gagnée pour autant : les utilisateurs passeront-ils sur ce nouveau backend ? L’informatique, tel un château de cartes, s’est bâtie en empilant des couches et réutilisant des briques logicielles existantes : sa force devient son talon d’Achille. Pour pouvoir changer les choses, il faut un chemin de migration et surtout, revenir et intervenir à un niveau plus fondamental : l’accès mémoire. C’est là que les capabilities prennent leur sens.
1. Les capabilities
Les capabilities sont essentiellement des fat pointers, c’est-à-dire des pointeurs enrichis avec des métadonnées. Le concept est loin d’être nouveau : à vrai dire, il date des origines de l’informatique, et il a cohabité jusqu’au début des années 80 avec les architectures que nous utilisons aujourd’hui : par exemple, en 1970 le laboratoire d’informatique de l’université de Cambridge (CUCL) avait un CAP computer, et en 1978 IBM avait le system/38. Mais les systèmes à base de MMU et pagination ont gagné la course, car ils étaient beaucoup plus simples et moins coûteux à implémenter en silicium à l’époque. CUCL a néanmoins gardé le feu sacré, avec en particulier le projet CHERI (Capability Hardware Enhanced Risc Instructions) [5], projet qui a démarré il y a maintenant une dizaine d’années et a été financé par la DARPA avec l’aide de Google. ARM, avec sa forte implantation à Cambridge, gardait un œil sur ces recherches avant de les joindre il y a quelques années.
Les capabilities existent donc depuis longtemps, elles sont relativement simples à formaliser, ce qui permet d’analyser les programmes et de garantir des propriétés. Il faut saluer ici la recherche et le travail de l’université de Cambridge, qui a porté ces concepts aussi loin que possible dans FreeBSD et permis d’entrevoir par là une voie de déploiement industriel.
1.1 Concept
Une capability s’utilise comme un pointeur ou une référence. En plus de l’équivalent d’un pointeur vers la donnée, une capability contient la base et la taille de l’objet contenant la donnée, ainsi que des droits concernant la capability elle-même (est-elle modifiable ?), ou ceux de la zone mémoire référencée par la capability (lecture, écriture par exemple). Les instructions qui modifient les capabilities ne peuvent que réduire leurs tailles ou droits (propriété de monotonie). Les capabilities ne sont pas forgeables (propriété d’inforgeabilité) : elles ne peuvent être créées ex nihilo, elles ne peuvent qu’être dérivées d’une autre capability.
Les capabilities sont protégées, en mémoire ou en registre, par un bit de tag fragile qui est effacé par toute manipulation non légale. Les instructions prévues pour modifier les capabilities, un changement de droits par exemple, gèrent le tag : si la manipulation n’est pas correcte, gain de droits dans notre exemple, le bit de tag sera effacé. Toutes les autres instructions qui modifient tout ou partie d’une capability détruisent son tag. Dans l’exemple ci-dessous, l’écriture de l’un des octets de la capability l’invalidera (même s’il n’y avait pas de modification de la valeur) :
Seules les capabilities valides, c’est-à-dire avec le tag actif, peuvent être utilisées pour les accès mémoires (load et store). L’utilisation d’une capability non valide déclenche une faute d’accès.
1.2 Vision matérielle
À l’origine, dans les années 60-70, les capabilities contrôlaient aussi l’accès physique à la mémoire (d’où leur opposition aux systèmes à base de MMU). Avec CHERI, les capabilities sont orthogonales à ce que fournit la MMU : elles permettent un contrôle à grain fin des accès mémoires au sein d’un espace d’adressage virtuel, aussi bien pour le code que pour les données.
CHERI peut être intégré à tout jeu d’instructions 64 bits : MIPS, ARM, RISC-V, x86-64… Cette extension affecte bien évidemment les loads et les stores du jeu d’instructions hôte, et rajoute quelques instructions pour manipuler les capabilities.
1.3 Vision logicielle
Les mécanismes de CHERI permettent de garantir la sûreté spatiale d’un programme, en particulier pour des programmes écrits dans des langages de type C/C++, les accès étant vérifiés à grain fin par le matériel à la vitesse du matériel. Notons aussi en passant que les langages garantissant la sûreté mémoire « par design » peuvent aussi tirer parti de ce support matériel pour améliorer leurs performances, en termes de rapidité d’exécution bien sûr, mais aussi en termes de garanties : la foreign function interface et la partie unsafe de Rust viennent immédiatement à l’esprit.
Quid de la sûreté temporelle ? CHERI fournit une bonne opportunité d’améliorer la situation, pour un coût similaire à celui d’un garbage collector.
CHERI apporte aussi une forme simple d’intégrité de flot de contrôle avec la non-forgeabilité des capabilities et la fragilité de leur tag qui les rendent difficiles à hacker pour créer des adresses de saut valide.
Enfin, les caractéristiques de non-forgeabilité et de monotonie des capabilities permettent la formation de compartiments logiciels légers dans le même espace d’adressage (par rapport à une séparation basée sur des processus par exemple) : une portion de code ne peut qu’accéder à la fermeture transitive des racines mémoires qui lui ont été fournies. L’article Weird machines, exploitability, and provable unexploitability de Thomas Dullien [6] montre l’importance de la compartimentalisation pour empêcher la construction de ces machines bizarres, ou en tout cas en limiter les effets : un exploit ROP/JOP par exemple peut être vu comme la programmation d’une méta-machine.
2. Morello
À ce point, une petite pause culturelle et linguistique s’impose : en anglais, morello est une variété de cerise griotte, que nous connaissons en France sous le nom de cerise amarena (les gourmands parmi nous les dégustent dans la coupe de même nom). Le nom a été choisi en clin d’œil à CHERI (cherry, cerise en anglais) pour souligner la parenté des projets.
Morello désigne :
- une extension du jeu d’instructions ARM A64 et de CHERI ;
- un ASIC (une puce) qui embarque plusieurs processeurs ARM supportant cette extension. Ce système supporte plusieurs configurations : serveur ou téléphone portable ;
- une carte de développement, avec tous les périphériques nécessaires pour démarrer Android ou une configuration serveur ;
- un projet financé par le gouvernement britannique dans le cadre de l’axe de recherche DSbD (Digital Security by Design) [7] de l’UKRI (équivalent de notre ANR) à hauteur de 70M£ et par des partenaires industriels à hauteur de 100M£. L’ampleur des sommes allouées donne la mesure de l’importance que les participants accordent à ce projet. Le but de ce projet est non seulement de concevoir la puce et la carte de développement, mais aussi d’évaluer les différentes options d’implémentation (tant au niveau matériel que logiciel), de déploiement et les priorités des différents partenaires industriels (Microsoft et Google par exemple). Sans encore parler de déploiement à l’échelle industrielle, cette étape a l’objectif avoué d’être un pas dans cette direction et de permettre de tenter un passage à l’échelle pour toute la chaîne.
Il est important de noter que Morello n’est pas l’implémentation d’une architecture finale : ce n’est qu’un prototype qui a vocation à disparaître, sans aucune garantie de compatibilité forward ou backward. Par contre tous les concepts qui auront montré leur utilité ou leur valeur seront intégrés à CHERI et/ou à une extension architecturale pour ARM. Il faut aussi noter que bien que Morello soit l’implémentation ARM de CHERI, les contributions d’autres architectures sont les bienvenues.
2.1 Implémentation
2.1.1 Format
L’implémentation originale des capabilities CHERI fait 256 bits : cela a du sens dans un cadre de recherche de ne pas trop s’encombrer de considérations sur la taille des « pointeurs », mais c’est clairement trop large pour un déploiement industriel. Les capabilities Morello ont donc un format compressé avec une taille de 128 bits. La compression permet de faire tenir dans ces 128 bits la base et la taille de la zone mémoire référencée, ainsi que le pointeur vers la donnée, et des bits de permission en utilisant un encodage conceptuellement similaire à celui des nombres flottants (mantisse et exposant IEEE754). Une complication qu’il a fallu prendre en compte est le pattern du past-the-end (le end() des itérateurs du C++). Par exemple, pour un tableau tab de taille N,i ∈ [0:N[ implique que &tab[i] est représentable et valide, alors que &tab[N] doit être représentable (afin d’être utilisé dans des comparaisons), mais invalide en cas de déréférencement. C’est aussi un idiome fondamental utilisé par le compilateur qui va souvent générer des adresses marquant le premier élément hors tableau, avant ou après suivant le sens dans lequel les optimiseurs auront choisi de parcourir le tableau.
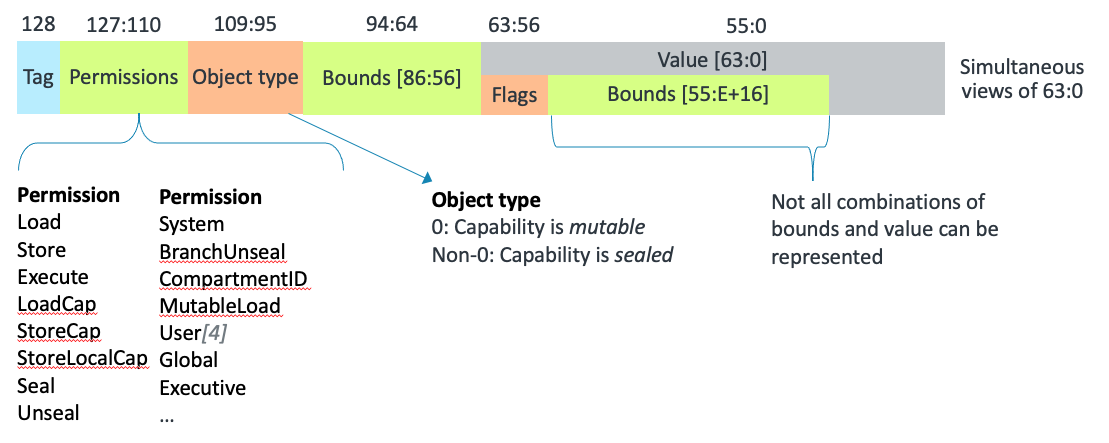
Les bus et le banc de registre passent donc à 129 bits (non, ce n’est pas une typo !) : 128 bits de capability + 1 bit de tag. Le registre de capability recouvre les registres W et X comme montré sur la figure 2.

En mémoire, les capabilities sont alignées sur 16 bytes et le bit de tag est stocké séparément, par exemple en utilisant l’ECC dans une configuration type serveur.
2.1.2 L’état CPU
Un processeur supportant Morello peut être dans 2 états :
- A64 – l’ancien monde, les pointeurs sont des entiers :
- accès au jeu d’instructions aarch64 + minimum pour opérer sur des capabilities ;
- les accès mémoires utilisent des adresses par défaut ;
- C64 – le nouveau monde, les pointeurs sont des capabilities :
- accès au jeu d’instructions aarch64 + minimum pour opérer sur des adresses ;
- les accès mémoires utilisent des capabilities par défaut. Les accès utilisant une adresse sont interprétés relativement à un registre de capability global DDC (Default Data Capability) qui permet de restreindre la portée de l’adresse.
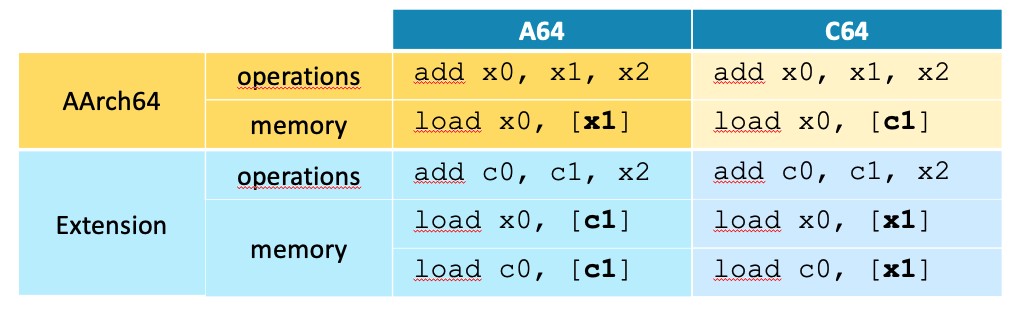
Cette approche est tout d’abord une pirouette d’encodage : être « modal », permet d’économiser de l’espace d’encodage pour toutes les instructions qui existent dans les deux modes (comme les loads et les stores). L’encodage des instructions ne change pas, seule leur interprétation dépend du mode.
Cette approche permet de gérer la migration des bases de code qui ne vont pas basculer toutes ensemble d’un seul coup au C64. La cohabitation et l’interopérabilité de ces programmes en modes A64 et C64 sont permises par quelques instructions ajoutées à chacun de ces modes. Le changement de mode quant à lui se fera sur des changements de niveau d’exécution, EL0 / EL1 par exemple.
2.1.3 Quelques exemples d’instructions
2.2 Gestion mémoire à grain fin
Les langages de programmation fournissent déjà un certain nombre d’abstractions et d’informations : structures, tableaux, classes, visibilités, modules. Les formats de fichiers tels que l’ELF fournissent aussi des informations, qui sont aujourd’hui rarement utilisées. Les compilateurs, éditeurs de liens, loaders et autres comme ceux proposés en section 6 « Et pour expérimenter ? » sont déjà capables d’en tirer parti et d’apporter un premier niveau de sécurisation inséré de façon automagique. Une simple recompilation suffit pour déjà bénéficier d’une amélioration – les low hanging fruits de nos voisins anglais.
Que les outils puissent propager la taille automatiquement quand c’est possible est une avancée significative, mais ce n’est malheureusement pas toujours possible ou désirable. Regardons cela sur 2 petits exemples.
Avec un tel prototype, un développeur sain d’esprit et qui a en plus pris la peine de rajouter la qualification const rêverait que l’objet pointé par p devienne réellement non modifiable. Les capabilities le permettent, et le matériel vérifiera que c’est bien le cas… Ce qui révélera souvent des problèmes à l’exécution. En effet, le compilateur n’effectue que des vérifications assez superficielles sur l’usage de l’objet et un const, ça se cast-away si facilement ! L’activation du const matériel est donc à faire avec précaution, elle ressemblera assez fortement à l’exercice de const-ification d’une base de code C++ : c’est pénible, même si au final le code en ressort plus propre.
Dans cet exemple, malloc va nous retourner une capability limitant correctement la taille de tab à 10 objets S. Mais que faut-il faire pour l’appel f(&tab[i])? Faut-il passer une capability dérivée de tab et restreinte au i-ème élément ? Le compilateur pourrait le faire, mais cela cassera quelques bases de code qui aiment bien regarder l’élément i-1 ou i+1. Donc là encore, la réponse n’est pas simple.
Cela nous oriente sur un chemin de migration progressive des bases de code, avec le déploiement incrémental d’options de compilation de plus en plus contraignantes.
2.3 Compartimentalisation
Dans l’absolu, on aimerait pouvoir tout garantir partout, mais l’expérience montre que cela n’est pas toujours simple, ni forcément nécessaire. Les méthodes yaka et sa variante yakafokon ne passent pas à l’échelle. Les équipes avec des exigences fortes et bien définies de sécurité le savent : elles n’ont d’autre choix que de réduire la taille du problème – en termes de base de code et/ou de matériel – à quelque chose de gérable et d’analysable.
Tous les modules logiciels d’un système n’ont pas le même pédigrée. Certains sont même assez peu recommandables – mais restent largement utilisés ! Par exemple, est-il vraiment souhaitable d’effectuer l’appel suivant en utilisant une donnée de source inconnue téléchargée sur Internet :
J’ai choisi ici la libjpeg, mais ce n’est qu’un exemple parmi une trop longue liste des fournisseurs officiels de CVE. Pour leur décharge, l’écriture de parseurs n’est pas si simple qu’il y parait – la présentation Journey to a RTE-free X.509 parser [8] d’Arnaud Ebalard, Patricia Mouy et Ryad Benadjila est une bonne illustration.
L’utilisation de composants de plus haute confiance peut aussi être requise, par exemple :
Les routines d’Evercrypt sont formellement prouvées… si et seulement si les préconditions sur lesquelles elles reposent sont garanties, ce qui peut être compliqué quand l’appelant est une base de code complexe (comme un navigateur web).
La compartimentalisation peut aussi être désirable dans le cas des systèmes d’exploitation : les drivers de périphériques sont souvent de qualité moindre que le reste du système qui pourrait être protégé du comportement erroné d’un driver.
Le terme module, sans aucune définition et sans faire référence à un langage précis, a été employé ici à dessein. Des discussions que nous avons pu avoir avec les différents acteurs intéressés par les capabilities, il apparaît clairement que chacun a sa propre notion de ce qu’est un compartiment et de comment la transition entre compartiments doit s’effectuer — CHERI / Morello supporte donc différents modèles (appel direct ou passage par un gestionnaire de compartiment par exemple) qui vont être explorés en pratique dans les mois à venir.
La compartimentalisation automatique n’est pas encore une réalité, mais un chemin se dessine ! Il reste néanmoins que les langages, ainsi que les bibliothèques partagées permettent d’exprimer des notions de module, que les compilateurs et éditeurs de lien dynamiques pourraient déjà mettre à profit pour effectuer de la compartimentalisation automatique.
2.4 Garbage collection
En prenant un peu de distance, le bit de tag permet au final un typage au niveau matériel, qui peut donc faire la différence entre des octets bruts – qu’il interprétera dans le sens que le développeur (ou l’attaquant !) lui indiquera – et une adresse. Il devient maintenant possible de scanner la mémoire pour trouver où sont les références mémoires et les objets. Il est aussi possible d’invalider les tags. Tout cela donne des perspectives intéressantes pour revisiter voire améliorer les performances des langages utilisant le garbage collection.
3. Et la compilation dans tout ça ?
Les capabilities introduisent un nouveau type, donc cela affecte l’ABI. Afin de pouvoir gérer la cohabitation pendant la phase de migration, il y a maintenant 2 ABI :
- -mabi=aapcs : c’est l’ABI aarch64 legacy, telle qu’on la connaît. Les program counter, link register, stack et frame pointers sont toujours des entiers.
- -mabi=purecap : tous les pointeurs sont des capabilities, ainsi que les program counter, link register, stack et frame pointers.
Un programme se compile dans l’une des 3 configurations suivantes :
- aarch64 (-target <aarch64-target>) : c’est le legacy. Les pointeurs sont des entiers, rien ne change par rapport à ce qu’on connaît déjà, l’ABI est aapcs ;
- A64 (-target <arch64-target> -march=morello) : aarch64 avec l’extension morello. Au niveau source, les pointeurs de data et de fonctions restent des pointeurs entiers, à moins d’être annotés individuellement avec __capability. L’ABI est une aapcs hybride, avec le minimum pour pouvoir supporter les capabilities, mais qui doit garder une compatibilité avec les binaires non recompilés ;
- C64 (-target <arch64-target> -march=morello+c64) : tous les pointeurs sont des capabilities, l’ABI utilisée est purecap.
Les manipulations de capabilities (réduction de taille, de droits…) se font via des intrinsèques fournis par le compilateur.
4. Retour d’expérience
Au cours du développement de Morello, nous avons recompilé de nombreuses bases de code, et même si nous sommes bien conscients que cela ne représente même pas la partie émergée de l’iceberg, quelques grandes tendances se dégagent.
On aurait pu croire que les développeurs ont profité du passage aux pointeurs 64 bits pour gérer correctement la taille des pointeurs, c’est-à-dire s’abstraire de l’hypothèse pointeur = long int, rendant le passage aux pointeurs 128 bits indolore…. Sans surprise, il n’en est rien !
La grande majorité des bases de code ont des accès hors bornes que CHERI et Morello ont attrapés. Les bibliothèques standards n’y échappent pas, en particulier avec les fonctions optimisées pour manipuler des chaînes de caractères. Le bon point, c’est que cela démontre l’utilité de CHERI / Morello ! Par contre, la recompilation n’est qu’une étape, il faut tester les programmes, qui suivant les bonnes pratiques établies depuis des lustres dans le développement logiciel ont bien évidemment des tests de non-régression avec une couverture décente de la base de code…
Il est surprenant de voir combien de bases de code ont réimplémenté les fonctions type memcpy / memmove à leur sauce.
Malheureusement, ces fonctions effectuent une recopie brute de la mémoire, et vont effacer les tags des capabilities recopiées. Dans certains cas, les développeurs ont écrit ces fonctions de façon triviale (faut-il vraiment s’en réjouir ?), et le compilateur est capable de reconnaître l’idiome et d’utiliser à la place une version correcte qui gérera correctement les tags. Hélas, certaines versions ont été écrites de façon particulièrement obfusquées.
Beaucoup de choses plus ou moins horribles sont faites avec les pointeurs, et CHERI / Morello ont permis d’en élaborer un véritable musée. Dans la partie propre du spectre, on a des hacks qui relèvent de l’optimisation, telle que l’utilisation des bits de poids faible d’un pointeur d’une zone alignée en mémoire pour gagner quelques octets – il est vrai que dans certains cas, les gains sont substantiels. On peut noter que le format des capabilities inclut quelques bits non utilisés par le hardware et qu’ils pourraient être utilisés dans ce cadre. À l’autre bout du spectre, on trouve des problèmes de type pointer provenance que j’illustre dans une version simplifiée ci-dessous :
Malheureusement, certaines bases de code dépendent de ce comportement pour fonctionner correctement. CUCL a profité de l’occasion pour écrire 2 articles que je recommande vivement à la lecture : Exploring C semantics and pointer provenance [8] et Into the depths of C : elaborating the de facto standard [9]. Ce dernier article explore le standard C tel qu’officiellement écrit, ce que les différents compilateurs ont implémenté, et ce qu’ont compris les développeurs. Heureusement, l’intersection n’est pas nulle, mais les résultats sont parfois surprenants…
5. Questions ouvertes
Il apparaît clairement que l’amélioration de la sûreté mémoire passera par une réécriture du code… Quitte à réécrire ce code, ne vaudrait-il pas mieux utiliser un meilleur langage, comme Rust ? Les rustacés abonderont dans ce sens bien évidemment, mais en pratique, la réponse n’est pas si simple. À moins d’être un programme isolé, il y a beaucoup de contraintes à prendre en compte : interopérabilité, le support de plateformes multiples...
Quid de la composition de composants prouvés sûrs ? Si on prenait par exemple SeL4 et qu’on le portait avec quelques applications sécurisées sur CHERI / Morello, le système complet est-il toujours sûr ? Comment le prouve-t-on ? Il y a besoin de méthodes et d’outils pour répondre à ces questions, et surtout qu’ils puissent passer à l’échelle sur des bases de code réelles. Nous espérons que Morello, en particulier avec la mise à disposition de plateformes d’évaluation matérielles, sera l’occasion de faire éclore de tels outils : le monde en a besoin.
6. Et pour expérimenter ?
L’hiver n’a que trop duré… et si l’on mettait un peu de CHERI pour bien démarrer l’année ? Afin de permettre aux académiques, industriels et hobbyistes d’expérimenter, de nombreuses ressources avec un support Morello initial sont mises à disposition au niveau source sur https://www.morello-project.org/ :
- différentes versions des compilateurs, supportant le baremetal et Android ;
- différents firmwares : Trusted Firmware TF-A, UEFI EDK2…
- noyau Linux ACK (Android Common Kernel) ;
- nano Android, incluant une version modifiée de la librairie standard C bionic et un port d’applications en pure-capability ;
- CheriBSD, le port BSD de CUCL pour CHERI supporte aussi Morello, et illustre une implémentation possible en kernel et user space de l’utilisation des capabilities ;
- un simulateur Morello Platform Model, qui permet les développements logiciels avec Morello avant d’avoir accès à des cartes de développement début 2022.
Conclusion
Quand Émilien m’a contacté pour écrire un article à propos D’ARM, j’ai immédiatement proposé ce sujet. CHERI / Morello sont des initiatives ambitieuses et intéressantes, qui pourraient permettre d’améliorer significativement la sécurité et les performances de nos systèmes informatiques. Il me semble important que cet effort apparaisse sur le radar de la communauté française de la sécurité et ne se limite pas au monde anglo-saxon : la France a une expertise et un savoir-faire en sécurité reconnu dans le monde, faisons entendre notre voix ! Et il y a tellement de possibilités non encore explorées : analyses pour de la compartimentalisation automatique ou refactorisation de code par exemple que l’on peut certainement apporter nos pierres à l’édifice — qui je le souligne encore ne se limitent pas à l’écosystème ARM.
Les fêtes de fin d’années s’éloignent déjà à grands pas, j’espère que chacun aura eu son content de rêverie et de féérie, nous en avons tellement besoin. Mais en informatique, il n’y a ni baguette magique, ni père Noël : toutes les solutions réclameront un effort. Les capabilities nous semblent être la voie la plus prometteuse, et surtout offrent un chemin de migration plausible vers un monde plus sûr.
Références
[1] https://en.wikipedia.org/wiki/Buffer_overflow#History
[3] https://www.zdnet.com/article/chrome-70-of-all-security-bugs-are-memory-safety-issues/
[4] https://daniel.haxx.se/blog/2020/10/09/rust-in-curl-with-hyper/
[5] https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-927.pdf
[6] http://www.dullien.net/thomas/weird-machines-exploitability.pdf
[7] https://gtr.ukri.org/projects?ref=105694
[8] https://www.sstic.org/2019/presentation/journey-to-a-rte-free-x509-parser/
[9] https://www.cl.cam.ac.uk/research/security/ctsrd/pdfs/201901-popl-cerberus.pdf
[10] https://www.cl.cam.ac.uk/research/security/ctsrd/pdfs/201606-pldi2016-clanguage.pdf
