

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
« Attention, nouveau virus ! » Nombreux sont les articles à nous alerter régulièrement, par cette métonymie, sur l’émergence d’un nouveau malware. Pourtant, le terme de virus a-t-il encore un sens aujourd’hui ? Wannacry était-il un ver, ou un ransomware ? NotPetya, un wiper, ou bien un ver ? Et plus encore, au-delà de l’utilisation de termes et expressions se pose la question de la nécessaire catégorisation des incidents de cybersécurité ; pourquoi, comment, à quelles fins ? Essai (critique) de réponse.
Dans les colonnes de votre magazine préféré, d’aucuns auront noté l’utilisation régulière de termes tels que « virus », « ver », ou encore « cheval de Troie », employés parfois comme s’ils représentaient chacun une réalité technique strictement cloisonnée des autres.
Ainsi, « un virus informatique » aura besoin d’être accolé à un autre programme pour se répliquer, au contraire du « ver », indépendant. Ces définitions, presque aussi vieilles que l’Internet, sont néanmoins perçues comme obsolètes par la plupart des acteurs actuels, bien conscients qu’un malware (maliciel, en bon français), aujourd’hui, a toutes les chances d’être modulaire, adaptable, et donc de revêtir les aspects les plus à même de servir les objectifs de l’acteur le manipulant. Cet exemple serait assez trivial s’il n’illustrait le décalage qui existe aujourd’hui, en matière de réponse à incidents de cybersécurité, entre la nécessité grandissante de prendre des décisions quant à la situation opérationnelle et les outils à disposition des métiers pour ce faire… Décalage que nous allons étudier dans le présent article.
1. Genèse d’une taxonomie de référence
Dans les années 1990 et 2000, ont émergé des structures opérationnelles dédiées à la réponse aux incidents de cybersécurité : les Computer Security Incident Response Teams (CSIRT). Ces dernières ont commencé à intervenir sur un périmètre défini, avec une ou plusieurs équipes dédiées, et selon tout un tas d’autres modalités traditionnellement consultables via la RFC2350 [1] du CSIRT en question.
À l’époque, les structures étaient à taille humaine, ce qui du point de vue du quotidien signifiait que les personnes amenées à caractériser techniquement un incident de cybersécurité, définir sa priorisation et décider des actions à prendre selon son évolution, faisaient souvent partie de la même équipe. C’est également à cette époque qu’une taxonomie relative incidents de cybersécurité simple et multi-emploi s’est imposée : la taxonomie eCSIRT [2].
|
Contenu abusif |
Spam |
|
Discours haineux |
|
|
Contenu (pédo)pornographique, violent |
|
|
Malware |
Virus |
|
Ver |
|
|
Cheval de Troie |
|
|
Dialler |
|
|
Rootkit |
|
|
Spyware |
|
|
Collecte d’informations |
Scan |
|
Sniffing |
|
|
Ingénierie sociale |
|
|
Tentative d’intrusion |
Exploitation de vulnérabilités connues |
|
Tentatives de connexion |
|
|
New attack signature |
|
|
Intrusion |
Compromission d’un compte à haut niveau de privilèges |
|
Compromission d’un compte à faible niveau de privilèges |
|
|
Compromission d’une application |
|
|
Bot |
|
|
Disponibilité |
DoS |
|
DDoS |
|
|
Sabotage |
|
|
Panne |
|
|
Sécurité de l’information |
Accès non-autorisé à de l’information |
|
Modification non-autorisée d’une information |
|
|
Fraude |
Accès non-autorisé à des ressources |
|
Copyright |
|
|
Masquerade |
|
|
Phishing |
|
|
Vulnérabilité |
Open for abuse |
|
Autre |
Tout ce qui n’entre pas dans les autres cases |
|
Test |
À utiliser en cas de test |
Cette taxonomie a depuis essaimé, de multiples forks en sont issus, le plus récent étant la taxonomie ENISA [3], du nom de l’agence européenne ayant piloté un groupe de travail dédié à ce sujet.
Le fonctionnement de cet outil est simpl(issim)e : confronté à un incident de cybersécurité à qualifier, un analyste de CSIRT commencera par choisir une catégorie, puis un type (ou exemple) d’incidents ; cela peut donc donner :
- Malware > Cheval de Troie
ou
- Disponibilité > DDoS
Selon le CSIRT au sein duquel l’analyste évolue, ainsi que la bande passante disponible et les éventuelles priorisations opérationnelles définies, la réponse à l’incident de cybersécurité ainsi caractérisée pourra être ajustée.
Au fur et à mesure que le temps passe, une base de données sera constituée, base à partir de laquelle il sera possible de générer des indicateurs, tels que :
- En 2010, 45 % des incidents relatifs à un malware étaient dus à des chevaux de Troie
ou
- En 2009, 70 % des incidents affectant la disponibilité d’une infrastructure relevant de la responsabilité du CSIRT étaient des DDoS.
Petit point de définition : la méthodologie de classification eCSIRT est une taxonomie ; le sens de ce terme renvoie aux sciences naturelles, voire plus spécifiquement à la phylogénétique, et fait référence au fait de classer un être vivant (ou taxon) selon sa position au sein du monde du vivant. Cette action est rendue possible par la création de différents regroupements (ou clades) ; par exemple, l’être humain peut être classé selon les quelques embranchements suivants :
- Primate (ordre) → Hominidae (famille) → Homininae (sous-famille)
Une taxonomie est une méthodologie qui conduit à enregistrer l’élément qu’elle ambitionne de classifier dans une case finale unique, après avoir suivi un chemin spécifique. En ce sens, et pour revenir au sujet initial, la taxonomie eCSIRT est bien une taxonomie, et non une méthodologie de classification.
Il en existe bien d’autres, parfois plus complexes et/ou servant des objectifs différents : CTLE (Common Taxonomy for Law Enforcement), Longtsaff ; CIF, FICORA ; MAEC (pour les malwares), ou encore Stix ; etc.. Toutefois, l’analyse et surtout le mapping entre ces différentes taxonomies démontrent une logique de fonctionnement très similaire [4]. Vous noterez que ATT&CK n’a pas été mentionné, en ce qu’il est un framework permettant un mapping de tactiques et techniques et non une taxonomie ; nous y reviendrons plus loin dans l’article.
2. Évolution des métiers de la cybersécurité
Une vingtaine d’années plus tard, plusieurs phénomènes sont venus changer la donne. Tout d’abord, suivant le développement numérique croissant de nos sociétés ainsi que le rythme effréné des ingéniosités offensives (rendues publiques toujours plus rapidement), les métiers de la réponse à incidents de cybersécurité se sont développés et professionnalisés.
Qualitativement, une division de travail presque tayloriste a conduit à voir émerger de véritables nouveaux métiers opérationnels ; analystes de niveau N, experts système, experts réseau, chargés d’étude de la menace cyber (cyber threat intelligence), reversers, coordinateurs de la réponse à évènements de cybersécurité, chargés du suivi de la situation, etc. ; alors qu’auparavant beaucoup d’employés d’un CSIRT pouvaient assumer diverses casquettes selon les nécessités opérationnelles, une spécialisation progressive des métiers a rendu cela bien plus compliqué. Allons plus loin : aujourd’hui, la réponse à incidents de cybersécurité est loin d’être l’apanage des CSIRT. Les SOC (Security Operations Centers), qu’ils soient internes ou externes, sont très souvent chargés des premiers niveaux de réponse, dont l’essentielle phase de qualification.
Quantitativement, sur la même période, outre que nombre de CSIRT se sont donnés la peine de naître (en France, de 4 en 2007 [5], l’on est passé à 38 [6] en 2020), beaucoup des existants ont cru en taille, voire en responsabilité(s).
Si l’on ajoute à ceci l’émergence de nouveaux systèmes, matériels, et pratiques (la mobilité n’étant pas la moindre), force est de constater que le paysage de la réponse à incidents de cybersécurité de 2020 diffère de celui du début des années 2000. Les taxonomies ont-elles suivi le mouvement ?
3. État des lieux actuel et contradictions
Oui et non. Par définition, en cybersécurité, une taxonomie est un outil pouvant servir différents objectifs :
- caractériser techniquement ;
- qualifier/prioriser/trier ;
- aider à la décision ;
- générer des indicateurs.
La taxonomie eCSIRT a tendance à être utilisée aujourd’hui afin de tenter de servir tous ces objectifs à la fois… ce qui pose un certain nombre de problèmes.
Ainsi que vu dans l’introduction, produire des indicateurs sur la base d’une typologie hermétique entre des malwares pourtant capables de « changer » de type selon les objectifs d’un acteur adverse est non seulement inutile, mais potentiellement contre-productif ; en effet, en forçant l’utilisation de cette taxonomie, il sera toujours possible de classer les malwares dans des catégories, mais les indicateurs générés sur cette base seront au mieux décorrélés de la réalité opérationnelle, au pire serviront à guider des décisions structurantes.
Et cette taxonomie souffre d’autres contradictions ; si la première colonne semble assez universelle et intuitive, ce n’est pas le cas de la seconde colonne. La taxonomie en elle-même n’est pas essentiellement modulaire. Il est certes possible d’enlever des catégories inutiles selon le mandat d’un CSIRT, et d’en ajouter d’autres, mais opérer ainsi ne limite que peu le risque d’émergence de « zones quasi-vides », ou indicateurs structurellement proches de zéro, et obère l’un des intérêts d’user d’une taxonomie commune à différents CSIRT, à savoir la possibilité de partager facilement des informations en manipulant un vocabulaire commun.
S’il est certain que la taxonomie ENISA, par exemple, représente une mise à jour plus que louable de la taxonomie eCSIRT, la logique sous-jacente demeure inchangée. Toutes les deux sont des taxonomies ; toutes deux ont une fâcheuse tendance à mélanger des moyens (tels que « malicious code » ou « DDoS ») avec des objectifs (« sabotage », « information gathering »), ce qui fait naître une contradiction ; doit-on caractériser en priorité le medium utilisé, ou l’effet (que l’on pense être) recherché par l’acteur adverse ?
Bien d’autres faiblesses auraient pu être mises en exergue, mais le fait est qu’il est aujourd’hui difficile pour toute structure opérationnelle de s’éloigner de ces taxonomies. Déjà, car une telle structure est, par définition, tournée vers la réponse, donc l’urgence, et ne dispose par conséquent que rarement du temps nécessaire pour produire un travail de fond sur un sujet aussi large que celui de la classification ; ensuite, car les initiatives existantes et autres groupes de travail s’étant chargés de la question n’osent pas (suffisamment) remettre en question ce qui est devenu une brique fondamentale des structures opérationnelles.
Ainsi, chaque CSIRT utilise une version ou une autre de ces taxonomies, souvent selon sa méthodologie propre, et de laquelle il a d’autant plus de difficultés à se détacher qu’il utilise celle-ci depuis longtemps… et ce, bien que son utilité finale soit structurellement très faible ou nulle, voire contre-productive.
Est-ce à dire qu’il faut abandonner l’ambition de bénéficier de méthodologies de classification véritablement utiles à la réponse à incidents de cybersécurité ?
Certainement pas ! Si ces dernières années ont démontré quelque chose, eût égard à ces méthodologies, c’est bien que ces dernières avaient une utilité réelle dès lors qu’on leur assignait un objectif réaliste et en phase avec la réalité opérationnelle qu’elles sont censées servir. Ainsi, le framework ATT&CK est aujourd’hui utilisé afin de caractériser techniquement un évènement. Modulaire, adaptable et évolutif, ainsi que décliné sous divers formats, il est un outil extrêmement puissant pour participer de la caractérisation technique (encore qu’il doit être complété par nombre d’autres approches, en matière de cyber threat intelligence, notamment sur les problématiques de victimologie).
Toutefois, le framework ATT&CK n’est que d’une utilité limitée pour la réponse à incidents de cybersécurité. Si l’on s’en réfère aux objectifs listés plus haut, l’on remarque que, s’il est excellent pour caractériser techniquement, il ne permet aucunement de participer à la priorisation des traitements, pas plus qu’il n’aide à la décision ni ne génère des indicateurs de situation. Avec ATT&CK, vous saurez mapper les techniques et tactiques qu’un attaquant aura utilisées, mais comment placer quelque chose de simple en son sein ? Un malware ? Un DDoS ? Très souvent, aux débuts d’une réponse à incidents, les informations sont parcellaires, et il importe bien moins de savoir quelle méthode d’injection un malware utilise que s’il en existe un, ou simplement d’évaluer l’étendue de la compromission.
4. Manifeste pour la construction de véritables indicateurs de décision et de situation opérationnels
De cette analyse critique, l’on en déduit qu’il manque aujourd’hui une brique à la réponse à incidents de cybersécurité : la caractérisation technique étant, aujourd’hui, très bien assurée par un ensemble de méthodologies existantes, le framework ATT&CK en étant l’une des initiatives les plus en vue, c’est d’un ensemble de solutions de classification, à même d’aider à la priorisation des évènements et de générer des indicateurs de situation, dont les structures opérationnelles ont aujourd’hui besoin. Peut-on dresser le portrait-robot de cet ensemble de solutions ?
4.1 L’impasse de l’objectif recherché
L’une des fausses pistes à éviter dans notre quête est celle de la téléologie de l’attaque. En effet, si la quête de l’objectif d’un acteur adverse fait parfaitement sens comme partie à une analyse de la menace, par exemple, elle ne sera que d’une utilité marginale aux métiers de la réponse à incidents de cybersécurité, ces derniers travaillant par définition dans une situation temporellement contrainte.
Une structure prenant connaissance d’une compromission d’un de ses bénéficiaires, accordera nécessairement moins d’importance à l’objectif supposément recherché par l’acteur à l’origine de la compromission (pré-positionnement ? Espionnage ? Sabotage ? etc.) qu’à l’analyse technique de ladite compromission (recherche du vecteur de compromission, évaluation du périmètre de la compromission et du niveau de privilèges atteint, activités de l’acteur adverse sur le système d’information, etc.)… quand bien même il serait possible d’affirmer que la compromission recherche un but unique et spécifique, ou que ce dernier n’est pas simulé !
Nombre de retours d’expériences démontrent qu’un acteur adverse pourra tout d’abord obéir à un objectif de connaissance de l’infrastructure, puis d’exfiltration de données d’intérêt, avant de finalement se laisser tenter par la perspective d’un gain financier. Seul un retour d’expérience ambitieux se basant sur une connaissance technique poussée de l’évènement de cybersécurité traité pourra ambitionner de comprendre l’imbrication des objectifs d’un acteur adverse ; mais au moment où l’incident doit être qualifié, la téléologie de l’acteur adverse n’est que (très) rarement d’une quelconque utilité.
4.2 Proposition de principes à respecter pour construire un schéma de classification utile à la réponse à évènements de cybersécurité
4.2.1 Utiliser un vocabulaire commun à la fois durable et flexible
Pour qu’un dialogue ait du sens, d’un point de vue dialectique, il faut déjà s’assurer que l’on parle de la même chose avec un vocabulaire commun. La cybersécurité ne fait pas exception à ce principe : échanger, analyser, argumenter, débattre et partager sont autant d’actions facilitées par l’utilisation de termes un tant soit peu définis qui, chez la myriade d’acteurs impliquée, recouvrent des réalités communément perçues.
4.2.2 Veiller à l’adaptabilité des solutions construites
La cybersécurité est un monde en mouvement ; les acteurs évoluent, les techniques naissent et meurent, les pratiques et les métiers changent, etc. ; les solutions construites doivent être capables de suivre ce rythme, si l’on souhaite éviter de se retrouver, dans quinze ans, à faire face aux mêmes problématiques qu’aujourd’hui. De plus, cette adaptabilité doit également permettre de refléter la diversité des mandats des structures opérationnelles.
La perfection n’existant pas en tant que telle, il faut moins chercher à l’atteindre qu’à rechercher la perfectabilité (on salue Karl Popper). À ce titre, il convient de cesser d’utiliser les taxonomies existantes comme des taxonomies, et de privilégier les méthodologies modulaires et suivant rapidement les évolutions du terrain.
4.2.3 S’assurer que notre ensemble de solutions de classification facilite les échanges entre pairs
Un CSIRT est une structure qui échange des informations ; il n’y a pas de compétition dans la défense, et, à ce titre, tout comme l’ambitionnait (feu) la taxonomie eCSIRT, notre ensemble de solutions de classification doit toujours avoir en tête la question de la facilitation du partage.
4.2.4 Appuyer la rationalisation de l’engagement opérationnel
Travailler dans une structure opérationnelle implique de devoir, parfois, faire face à Jean-Michel C’est-moi-le-boss, et à ses décisions d’engagement de ressources aussi inconstantes que décorrélées de la réalité du terrain ; plus encore, force est de reconnaître que réagir dans l’urgence complique nécessairement la prise de décision. Des solutions utiles au terrain se doivent par conséquent d’aider à tendre vers une utilisation efficiente des ressources opérationnelles engagées pour répondre aux incidents de cybersécurité.
5. Quelques idées de solutions
Une première orientation de solutions peut passer par la définition et la centralisation de typologies. Comme toujours, il faut se méfier de la complexification à outrance et des volontés d’exhaustivité ; ces typologies doivent répondre aux principes énoncés plus haut, c’est pourquoi je déconseillerais d’en construire autour des objectifs poursuivis par les acteurs adverses, ou selon des éléments de caractérisation technique.
Une proposition concrète serait de développer une bibliothèque de typologies au sein de laquelle une structure opérationnelle (SOC, CERT, CSIRT, Fusion Center, etc.) pourrait piocher différents modules à même de faciliter la production d’indicateurs utiles à cette structure opérationnelle spécifique. Un répertoire GitHub ferait, pour ce faire, parfaitement l’affaire, et pourrait inclure des guides d’implémentation et d’utilisation, ainsi que des bonnes pratiques et conseils de partage.
5.1 Niveau 1 : quelques essais de typologies (voire d’échelles)
5.1.1 Échelle de criticité de l’effet de l’incident de cybersécurité
Cela peut paraître évident, mais une compromission à haut niveau de privilèges, sera sûrement plus critique que la compromission d’un poste utilisateur sans aucun droit particulier. De même, avant une compromission, des effets moins critiques peuvent toutefois être détectés (tentatives de spearphishing, campagnes de scan, recherches de vulnérabilités, etc.). En se basant sur tout cela, il est aisé de construire une échelle de criticité assez basique allant d’un niveau faible (actions préalables à une compromission), à un niveau haut (compromission à haut niveau de privilèges) en passant par un niveau intermédiaire (compromission d’un poste utilisateur). Bien sûr, cette échelle est adaptable selon la taille et le nombre de systèmes d’information concernés.
5.1.2 Typologie (simplifiée) des incidents de cybersécurité
La taxonomie ENISA peut être particulièrement utile, notamment si l’on commence par cesser de l’utiliser comme une taxonomie, et que l’on ne garde que sa première colonne dont on expurgerait les éléments orientés objectifs de l’attaque et à laquelle on ajouterait quelques blocs, en se laissant la possibilité de lier cette typologie avec d’autres, complémentaires.
5.1.2 Échelle/typologie de bénéficiaires
Les structures opérationnelles se différencient tout d’abord par leurs bénéficiaires, c’est-à-dire les structures pour lesquelles ils assurent un service de réponse à incidents de cybersécurité. Selon son mandat, un CSIRT pourra être responsable de la réponse sur un certain périmètre prioritaire, de la coordination de la réponse sur un autre, et de notifier un autre CSIRT sur un troisième. Là encore, la construction d’une typologie (voire d’une échelle, si la réponse doit être prioritaire selon certains bénéficiaires) est assez aisée. On peut commencer par créer deux catégories : « bénéficiaires dans le mandat du CSIRT (scope) », et « bénéficiaires hors du mandat du CSIRT (hors scope) » ; ensuite, libre à nous de subdiviser ces catégories selon les bénéficiaires (quitte à les nommer ; exemple : client 1, client 2, client 3), voire à les classer selon leur sensibilité.
5.1.3 Échelle de sensibilité des systèmes d’information
Selon le mandat du CSIRT et les architectures des systèmes d’information d’un bénéficiaire, l’on peut créer une échelle reflétant une sensibilité croissante, par exemple : systèmes d’information support, système d’information bureautique principal, système d’information sensible, système industriel, système d’information d’importance vitale, etc.
5.1.4 Échelle/typologie d’engagement opérationnel
Pour les CSIRT ayant développé une doctrine interne d’engagement opérationnel, selon la gouvernance des ressources engagées et/ou leur quantité, il est là encore possible de les classer par ordre croissant d’importance : engagement mineur, engagement intermédiaire, engagement majeur, engagement prioritaire/crise. Un bon exemple de ceci a été conduit par le NCSC (National Cyber Security Center) britannique [7].
5.2 Niveau 2 : la combinaison de typologies
Combiner certaines des typologies/échelles créées plus haut est une solution très efficace pour faciliter la production d’indicateurs, notamment utiles à la prise de décision. Illustration avec quelques schémas (voir figures 1, 2 et 3) simplifiés en guise de « preuve de concept ».
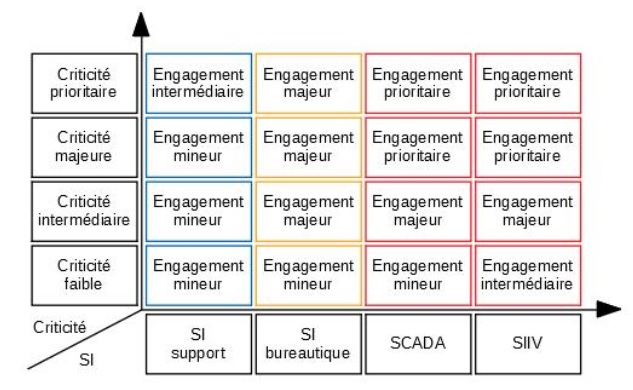
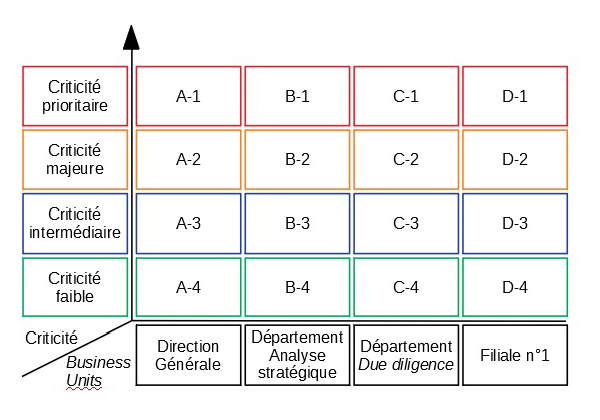
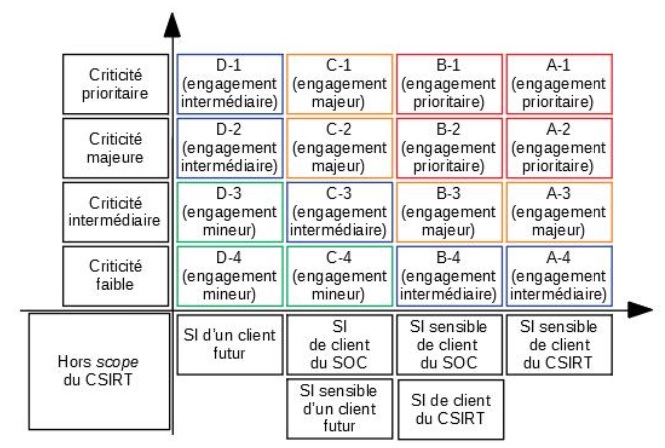
Sur l’ensemble de ces schémas, l’on voit que la rencontre de différentes typologies fait émerger des « cases », qu’il est alors aisé de suivre dans le temps ; outre qu’elles facilitent évidemment la priorisation des actions de réponse, analyser le nombre d’occurrences d’incidents derrière chacune des cases est également une excellente méthode permettant de dégager des tendances, d’enrichir des retours d’expérience, et d’identifier des actions à mener, telles que :
- sensibilisation/audit de certains bénéficiaires ;
- renforcement de certaines équipes ;
- définition de processus de traitement (ou mises à jour des existants) ;
- amélioration des méthodologies de détection de certains évènements ;
- création de plans de formation ou de cyber-entraînements spécifiques ;
- etc..
Conclusion
Cet article s’est voulu une mise en évidence d’une problématique propre à toutes les structures opérationnelles ; il y a matière à pousser bien plus loin l’étude de celle-ci, en ce que l’on aurait pu évoquer d’autres dimensions (le cycle de vie d’un incident, par exemple ; à cet égard, le travail RE&CT [8] est particulièrement utile ; la sécurité et manipulation d’une information ; etc.), ainsi que nombre d’autres initiatives. Ainsi, d’aucuns seront peut-être, à juste titre, quelque peu frustrés du peu de place accordé aux solutions proposées.
Un rhétoricien pourrait répondre à cela que pour bien traiter un problème, il faut déjà l’avoir correctement défini et délimité ; la rédaction de MISC, elle, répondrait plutôt que l’article est suffisamment long et dense pour ne pas regretter qu’il ne le soit encore plus ! La vérité est pourtant toute autre. Si j’ai esquissé ici quelques pistes, et bien qu’ayant encore nombre d’autres en réserve (dont beaucoup sont très certainement parfaitement loufoques), je suis convaincu que répondre utilement à la problématique ici abordée ne saurait être autre chose qu’un travail collectif. Ainsi, si vous avez connaissance de volontés similaires ou souhaitez participer/échanger/critiquer/commenter, n’hésitez pas à me contacter ! Plus on est de fous…
Remerciements
Merci au NCSC-UK, qui a inspiré une grande partie des solutions suggérées dans cet article, ainsi qu’à l’ANSSI, et plus spécifiquement à la sous-direction Opérations, pour être un espace d’échange privilégié peuplé d’agents à l’esprit critique constructif et toujours prêts à jouer avec de nouvelles idées.
Références
[1] RFC2350, https://tools.ietf.org/html/rfc2350
[2] Taxonomie eCSIRT mkVI, https://www.trusted-introducer.org/Incident-Classification-Taxonomy.pdf
[3] Taxonomie ENISA, page GitHub, https://github.com/enisaeu/Reference-Security-Incident-Taxonomy-Task-Force/blob/master/working_copy/humanv1.md
[4] Rapport de l’ENISA, Reference Incident Classification Taxonomy, https://www.enisa.europa.eu/publications/reference-incident-classification-taxonomy, janvier 2018
[5] Article du Journal du Net, daté de 2007, http://www.journaldunet.com/solutions/securite/decryptages/0822-qr-les-certs.shtml#:~:text=Qui%20sont%20les%20Certs%20fran%C3%A7ais,Computer%20Security%20Incident%20Response%20Teams)
[6] CERT en France, https://fr.wikipedia.org/wiki/Computer_emergency_response_team#France
[7] NCSC, Categorisation system, https://www.ncsc.gov.uk/news/new-cyber-attack-categorisation-system-improve-uk-response-incidents, 11 avril 2018
[8] ATC RE&CT, response stages, https://atc-project.github.io/atc-react/responsestages/


