

Cet article aborde les problèmes spécifiques à l’architecture ARM qui se posent lorsqu’on désassemble un exécutable, c’est-à-dire lorsqu’on l’analyse statiquement pour en produire une représentation en langage assembleur. En effet, les particularités de l’architecture ARM peuvent rendre le désassemblage – déjà habituellement compliqué – particulièrement ardu.
Commençons par remarquer que par désassemblage nous entendons ici pas seulement la traduction des instructions machines en langage assembleur, mais bien une analyse globale du programme qui va le structurer en routines (l’équivalent de fonctions en langage haut niveau) et définir correctement les données utilisées.
Ainsi, nous présenterons des situations particulières à l’architecture ARM qui rendent cette analyse globale difficile. Pour chacun des problèmes abordés, nous présenterons en particulier la façon dont nous le gérons actuellement dans JEB [JEB], le décompilateur sur lequel nous travaillons et dont la partie désassemblage a occupé (et occupe encore) une bonne partie de notre temps.
1. Tour d’horizon du jeu d’instructions
1.1 Au commencement tout était (relativement) simple
Les processeurs ARM sont des processeurs RISC, donc avec un nombre d’instructions raisonnable (environ 300 dans le jeu d’instructions de base). Une première particularité de ces instructions est qu’elles sont de taille fixe : 32 bits dans le mode par défaut. L’architecture ARM emploie un modèle load store, ce qui signifie que les données de la mémoire doivent nécessairement être chargées dans des registres pour être manipulées, ces registres généraux étant au nombre de 16 (R0-R15).
La convention d’appel usuelle préconise d’utiliser les registres R0 à R3 pour passer les paramètres d’une routine (et la pile pour les paramètres supplémentaires), la valeur de retour étant retournée dans le registre R0. Trois autres registres sont réservés : R13 représente le Stack Pointer, R14 l’adresse de retour de la fonction (Link Register) et R15 le Program Counter (PC). Ainsi, le PC se retrouve accessible comme n’importe quel autre registre… mais une grande partie des instructions sera en fait unpredictable si PC y est utilisé. Dans la terminologie ARM, cela signifie qu’il n’y a pas de garantie sur le comportement de cette instruction : le processeur peut décider de lever une exception pour « instruction indéfinie », ou bien ignorer l’instruction, ou même faire l’opération demandée.
Les premiers processeurs ARM employaient un encodage en Big Endian (octets de poids fort en premier), qui est encore celui utilisé pour les spécifications, mais ils utilisent désormais largement du Little Endian en pratique. Le processeur peut opérer dans les deux encodages selon l’état d’un registre spécial. Finalement, en plus d’être de taille fixe les instructions sont alignées sur des adresses multiples de 4 (puisque ce sont des instructions 32 bits), ce qui est a priori une bonne nouvelle pour le désassemblage !
1.2 L’arrivée de Thumb
Pour des soucis de compression de code, un jeu d’instructions alternatif a été introduit : le mode Thumb. Celui-ci permet de créer des instructions sur 16 bits. Les instructions restent alignées, mais modulo 2 évidemment. Remarquons de suite que les deux modes peuvent tout à fait coexister dans un même programme. Cependant, pour éviter de changer de mode trop souvent (et pénaliser le pipeline), une grande partie des instructions disponibles en mode ARM a finalement été rajoutée au mode Thumb. Et comme la place d’encodage était limitée, ces nouvelles instructions (Thumb2) ont dû être codées sur 4 octets, mais toujours alignées sur 2…
Petit exemple : en Thumb, les 3 bits de plus haut niveau déterminent le type d’instruction et si le décodage doit se faire en Thumb2 (dans ce cas, ils valent 111) ou en Thumb1. Ainsi, 1C 40 se décode en ADD R0, #1 (les bits 13 à 15 valent 000), tandis que F1 00 00 01 représente ADD.W R0, #1 (les bits 13 à 15 valent 111).
Tout ceci en Big Endian. Et en Little Endian ? Impossible d’inverser entièrement l’instruction, puisque 01 00 00 F1 serait alors considérée comme 2 instructions Thumb1 (01 00 puis 00 F1). Donc l’encodage est fait par bloc de 16 bits, l’instruction devenant donc 00 F1 01 00.
Un bit spécifique dans le registre de statut du processeur (CPSR) indique au processeur dans quel mode décoder une instruction. Et pour changer le mode ? Lors d’un branchement (BX), le bit de poids faible (LSB) de l’adresse sert de drapeau : s’il vaut 0 le mode sera ARM, s’il vaut 1 le mode sera Thumb. Le LSB sera, dans tous les cas, remis à zéro pour que l’adresse de destination du saut soit bien alignée. Nous reviendrons par la suite sur d’autres indices qui peuvent aider à trouver le mode d’une adresse, en particulier lorsqu’il est difficile de suivre le flot de contrôle.
Pour la suite de cet article, nous noterons A32 pour le mode ARM, et T32 pour le mode Thumb incluant les instructions Thumb2. De plus, les instructions T32 sur 32 bits seront notées avec le suffixe .W (pour wide), afin de les différencier des instructions 16 bits (dites narrow).
1.3 Oui, mais à quelle condition ?
Une dernière particularité du jeu d’instructions ARM que nous voulons évoquer est la présence d’instructions conditionnelles. Ainsi en mode A32, les instructions sont divisées en deux familles :
- les instructions inconditionnelles : principalement les instructions SIMD (vecteurs, virgules flottantes). Ces instructions sont exécutées à chaque fois que le PC les référence ;
- les instructions conditionnelles, ce qui regroupe la majorité des opérations habituelles (MOV, ADD, branches…). Ces instructions ne seront exécutées que si la condition associée est vraie. Pour ce faire, les 4 bits de haut niveau représentent la condition, de 0000 à 1110 pour les différentes comparaisons possibles avec 1110 pour la condition spéciale « toujours vraie ». Par exemple, 0000 (EQ) signifie que l’instruction ne s’exécute que si deux valeurs ont été testées égales lors de la dernière comparaison. Ces comparaisons sont habituellement implémentées par l’instruction CMP, qui met à jour des drapeaux dans le registre CPSR (de façon similaire à EFLAGS en x86). Remarquons que le LSB d’une condition permet de l’inverser, par exemple 0001 encode la condition d’inégalité (NE).
En mode T32, il aurait été dommage de réserver autant de bits pour la condition. Il existe donc un autre mécanisme : une instruction dédiée IT indique la condition pour exécuter les prochaines instructions (dans la limite de 4). Dans la syntaxe assembleur de cette instruction, des T indiqueront que la condition devra être vraie, tandis qu’un E signifiera que la condition doit être fausse. Par exemple, ITTE EQ entraînera l’exécution des deux prochaines instructions si la condition d’égalité précédemment testée est vraie ou de la troisième instruction si elle est fausse.
L’existence d’instructions conditionnelles signifie que ce n’est pas parce que le registre PC pointe sur une instruction que celle-ci va être réellement exécutée : il faut que sa condition soit vraie. Pour le désassemblage, cela peut impliquer des contorsions : par exemple, un appel à une routine non retournante (typiquement exit()) signifie la fin de la routine courante si, et seulement si, la condition de l’instruction d’appel est assurée d’être toujours vraie. Si la condition peut être fausse, le désassembleur doit continuer à analyser la routine courante comme si l’appel à exit() pouvait ne pas être exécuté.
2. Mélange code et données
Une des questions fondamentales pour désassembler un programme exécutable est de distinguer le code des données. En effet, décoder des données comme du code est probablement la « pire » erreur qu’un désassembleur puisse faire, puisque ce mauvais décodage aura alors des conséquences imprévisibles (comme la création des branchements invalides au milieu d’autres routines, ou de fausses références vers d’autres parties du programme). Notons qu’il n’est habituellement pas possible de distinguer de façon fiable une donnée d’une instruction simplement en observant sa valeur, car les jeux d’instructions tels qu’ARM sont très denses : presque toutes les valeurs correspondent à une instruction valide.
On pourrait penser que dans un programme exécutable classique (i.e. non obfusqué) les zones de code sont distinctes des zones de données, et clairement identifiées comme telles, par exemple à l’aide des sections du fichier exécutable. Mais il existe en fait de nombreux cas où des données se retrouvent au milieu des instructions, et nous allons maintenant explorer deux d’entre eux, très communs dans les programmes ARM.
2.1 Piscines de données
Les literal pools sont des zones de données stockant des adresses, des constantes ou même des chaînes de caractères, et qui sont situées au milieu des zones de code. Elles servent notamment à résoudre le problème suivant : comment charger une constante de 32 bits dans un registre avec une instruction qui elle-même ne fait que 32 bits ? La solution est alors de mettre la constante dans un literal pool proche de l’instruction. Celle-ci pourra alors aller chercher la constante à partir de son adresse relative (en utilisant la valeur de PC comme base). Ainsi seule l’adresse relative de la constante (sur 12 bits) sera encodée dans l’instruction 32 bits.
Voici un exemple de code assembleur Thumb1 dont la première instruction charge une constante de 4 octets (0xAABBCCDD) dans le registre R3. Cette constante se trouve alors à l’adresse PC + 8 (sachant que PC est lui-même positionné deux instructions plus loin) :
Les literal pools peuvent a priori sembler être un gros problème pour le désassemblage, puisque le code ARM se retrouve alors parsemé de zones de données. Ce qui rend la situation moins difficile qu’il n’y paraît c’est que celles-ci sont habituellement placées après le code qui les utilise. Ainsi, une zone de code à désassembler ne commence pas par un literal pool, mais bien par du code dont l’analyse permettra de définir les literal pools. Cette analyse n’est pas toujours triviale, par exemple lorsqu’une instruction charge une donnée dans un registre SIMD de 128 bits (ce qui permet de connaître la taille de la donnée), mais que l’adresse de cette donnée a été chargée dans un autre registre, il faut une analyse de flux de données entre les registres pour faire le lien entre l’adresse de la donnée et sa taille.
2.2 Tables de saut
Les jumptables sont des tables d’adresses utilisées notamment pour l’implémentation des instructions de type switch/case, chaque adresse de la table pointant sur les instructions d’un case. Le branchement se fera alors de façon indirecte en utilisant un registre qui fera office d’index dans la table d’adresses pour rediriger vers le case correspondant. Cette construction est produite par les compilateurs notamment lorsque les valeurs testées par les cases sont proches les unes des autres (il n’y aura alors pas d’entrées inutilisées dans la table).
En ARM, pour les raisons de limitation d’adressage précédemment mentionnées, les compilateurs placent habituellement ces tables d’adresses juste après l’instruction de branchement indirecte, c’est-à-dire au milieu d’une zone de code. Là encore, il suffit a priori d’analyser les instructions référençant la table pour trouver sa taille et celle de ses entrées, et ainsi éviter de la désassembler par après. Cela se révèle en fait particulièrement ardu sur ARM, car les compilateurs utilisent de multiples variantes, notamment en mode T32 afin de limiter la taille. Explorons quelques exemples de code désassemblé utilisant des jumptables (en Thumb, car c’est là qu’on rencontre les cas les plus intéressants).
2.2.1 Exemple 1 : le classique
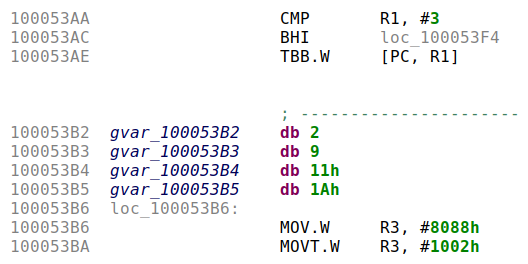
C’est le cas d’école d’un branchement par table d’adresses en Thumb :
- on compare la valeur de la variable testée dans R1 avec le nombre maximal de cases (#3), puis BHI redirige vers le cas par défaut si on est strictement supérieur ;
- sinon, on se base sur R1 pour charger la prochaine adresse à partir de la jumptable. L’instruction TBB (Table Branch Byte) branche à l’adresse obtenue en multipliant par 2 la valeur récupérée dans une table d’octets (la fameuse jumptable) et en ajoutant le résultat au PC. La table d’octets est référencée par un registre de base (ici PC, dont la valeur est adresse_courante + 4, puisque nous sommes en Thumb), et on sélectionne la valeur dans la table avec un registre d’index (ici R1).
Par exemple, si la variable testée vaut 0, alors [PC, R1] vaut [adresse_courante + 4 + 0] = [0x100053B2] = 2 (la première entrée de la table). Finalement, TBB branche à l’adresse obtenue en multipliant la valeur récupérée dans la table par 2, et en l’ajoutant à la valeur de PC : 2*2 + (adresse_courante + 4) = 4 + 0x10053B2 = 0x100053B6 (c’est-à-dire qu’on branche sur le code situé juste après la jumptable).
2.2.2 Exemple 2 : le compliqué

La logique de cet exemple est la suivante :
- comme précédemment, on compare avec le nombre maximal de cas (#5), puis BHI redirige vers le cas par défaut si on est strictement supérieur ;
- sinon, le saut est effectué en ajoutant la valeur extraite de la jumptable au PC. Là encore, on a une table d’octets référencée par un registre de base (ici R3) et un registre d’index (ici R2). Un octet de cette table est chargé dans R3 par l’instruction LDRSB (Load Register Signed Byte), puis ajouté à la valeur de PC par l’instruction ADD pour brancher sur l’adresse finale.
Par exemple, si la variable testée vaut 0, alors LDRSB charge dans R3 la valeur de [R3, R2], c’est-à-dire [0x10002E2C + 0] = 4. Finalement, ADD PC, R3 branche à (adresse_courante + 4) + 4 = 0x10002E2E + 4 = 0x10002E32.
À noter qu’il existe de nombreuses variantes : avec LDR au lieu de ADR, avec LSL pour faire du décalage manuel sur les valeurs des offsets…
2.2.3 Exemple 3 : le compact
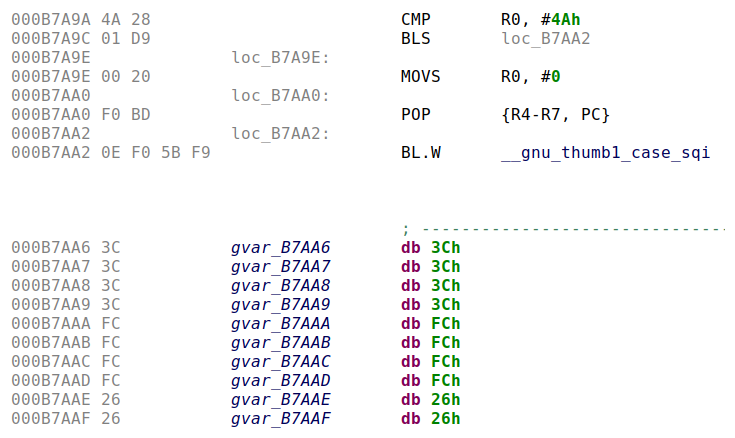
La particularité de cette construction est que le branchement est délégué à la routine __gnu_thumb1_case_sqi (après le traditionnel test avec la valeur maximale #4A). Cette routine est appelée par plusieurs des branchements par table d’appels dans le programme, évitant ainsi de dupliquer les instructions de branchement pour chacun d’entre eux. La routine reçoit une référence vers la table d’adresses dans le registre LR, comme « adresse de retour » qui suit l’instruction BL, et se charge de rediriger vers le case correspondant.
2.3 Comment distinguer les données du code
Pour résoudre les problèmes comme les literal pools ou les jumptables, JEB utilise une combinaison de plusieurs analyses pour suivre au mieux le code et déterminer où sont les données référencées. Ainsi, nous avons sur le code assembleur des heuristiques spécifiques à chaque compilateur (et donc nous collectons des indices pour déterminer quel compilateur a pu produire le programme), jusqu’à des analyses plus génériques basées sur une « représentation intermédiaire » (un langage abstrait dans lequel les instructions ARM sont traduites), ce qui nous permet d’identifier des variantes des mêmes constructions (au prix du coût en performance de la traduction en langage intermédiaire).
3. Victime de la mode
Tel qu’expliqué précédemment, les processeurs ARM peuvent évoluer dans deux modes distincts, A32 et T32, qui ont chacun un encodage propre, et qui peuvent coexister dans un même programme. Autrement dit, pour désassembler un programme ARM, il ne suffit pas de savoir qu’une zone mémoire contient du code (et pas des données), mais encore faut-il savoir dans quel mode ce code doit être désassemblé.
Tel qu’expliqué précédemment, la façon dont le processeur détermine le mode d’une instruction repose sur l’état d’un bit du registre CPSR, et le changement de mode se fait au moment des branchements. Pour reproduire cela au moment du désassemblage, il faudrait être capable de suivre de façon fiable le flot de contrôle, de façon à connaître la valeur du bit de mode à chaque instruction. Même si cela fonctionne dans des cas simples, du fait de nombreuses inconnues propres à l’analyse statique le désassembleur se retrouvera immanquablement devant des zones de code dont il ne connaît pas le mode. Il existe néanmoins d’autres indices qui peuvent aider à le déterminer, par exemple :
- L’alignement des instructions : typiquement, un alignement sur 2 (et pas sur 4) indique une adresse en mode Thumb ;
- La table des symboles : les symboles Thumb doivent (normalement) avoir leur bit de poids faible à 1. Notons aussi que les fichiers ELF peuvent contenir des symboles spécifiques pour indiquer le début des zones de code ARM ($a), de code Thumb ($t) et de données ($d) (mais ces symboles ne sont bien sûr pas toujours présents) ;
- La forme du code : il existe par exemple des instructions de prologue de routine en mode ARM dont l’encodage ne correspond pas à des instructions habituellement en début de routine en Thumb. Autre exemple, la présence d’une série de 4 bytes dont le quatrième (en Little Endian) commence toujours par 0xE peut correspondre à une succession d’instructions ARM dont la condition est « toujours vraie » (voir l’encodage des instructions décrit précédemment).
Dans le cas de JEB, nous essayons d’abord de suivre le flot de contrôle depuis les points d’entrées du programme (symboles, point d’entrée du fichier exécutable) afin de suivre les changements de mode au moment des branchements. Lorsque nous nous retrouvons devant une zone de code inconnue, nous utilisons une panoplie d’heuristiques telles que celles décrites précédemment pour essayer de déterminer le mode le plus probable. Mais bien conscient des limites de ces heuristiques, si le désassemblage dans ce mode ne permet pas de construire une routine correcte (par exemple, son graphe de flot de contrôle contient des aberrations, telles qu’une branche au milieu d’une routine existante, ou sur du code dans l’autre mode), alors nous recommençons le désassemblage dans le second mode.
4. Ceci n’est pas une routine
Le but d’un désassembleur comme JEB n’est pas seulement de décoder des instructions, mais aussi de reconstruire la structure du programme. Cela passe par une abstraction de base : la routine. Une routine représente une unité de code au même sens que les fonctions dans un langage de haut niveau. Mais contrairement à des fonctions, les routines assembleurs n’ont pas de définitions syntaxiques claires : ce qui détermine leur présence (en l’absence de symboles) c’est habituellement la façon dont le reste du code les référence. Typiquement en ARM la présence de l’instruction BL (Branch with Link) - qui se charge de brancher et de mettre à jour le registre LR avec l’adresse suivante - est habituellement le signe que la cible est le point d’entrée d’une routine (de façon similaire à l’instruction CALL en x86).
Mais il existe une construction assez commune en mode Thumb (encore lui) qui met à mal cette vision du problème. En effet, l’instruction B (Branch), qui sert pour les simples branchements, a une portée limitée en T32. Cela force les compilateurs à utiliser des BL - dont la portée est supérieure - lorsque la cible est inatteignable par un simple B. Nous retrouvons alors des instructions d’appels de routines qui sont en fait des branches intra-routines.
La figure 4 présente un extrait du code désassemblé de la routine de demangling de la bibliothèque Libiberty, qui est incluse dans de nombreuses bibliothèques natives Android. On peut observer un appel traditionnel à une routine nommée d_find_pack, suivi de trois « faux » appels, qui correspondent à de simples branches. A priori rien ne distingue ces deux utilisations de l’instruction BL, et un désassemblage traditionnel découpera alors cette routine en de nombreuses petites routines incorrectes, rendant la décompilation du code difficile.
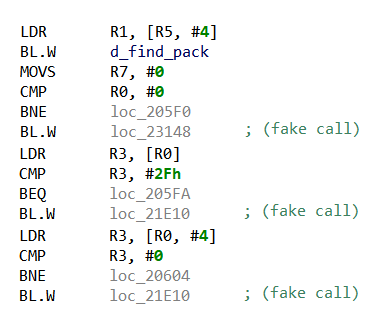
Pour essayer d’identifier ces « faux » appels de routines, JEB repère les branchements par BL dont la cible est trop loin pour être atteinte par un B, et qui est également ciblée par des B. Cela pourrait indiquer que les deux branches B et BL et la cible appartiennent en fait à la même routine. On essaye alors de désassembler ces différentes zones mémoires comme une seule et même routine ; en cas d’échec le découpage initial est considéré correct.
Conclusion
Nous avons survolé dans cet article quelques-unes des difficultés qui se posent lors du désassemblage d’un exécutable ARM. Au-delà des problèmes spécifiques à cette architecture, il faut aussi gérer les problèmes communs à toutes les architectures, comme la détection des tail calls (appels de routines optimisés en simples branchements), l’identification des routines non-retournantes ou la reconnaissance des fonctions de bibliothèques classiques. Nous avons également omis de parler d’ARM64, qui amène son propre lot de difficultés.
Référence
[JEB] Décompilateur JEB : https://www.pnfsoftware.com/