

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Kubernetes est en train de devenir le système de gestion de référence pour les conteneurs. Comme tout gros système, il est complexe. Qui dit complexe dit opportunités pour un attaquant... une fois qu'il a réussi à se dépêtrer un peu dans cette complexité.
Quand un attaquant se lance dans k8s, l'approche est différente d'un noyau, d'un navigateur, d'un lecteur PDF ou multimédia, ou de n'importe quelle cible. Tout de suite, on s'imagine avoir à faire avec du Web et du réseau. Si ce n'est pas faux, c'est néanmoins une vue très étroite de ce qu'est réellement k8s, de ce qu'il permet, mais surtout de comment il fonctionne.
1. Comprendre Kubernetes : l'avènement de Cloud OS !
Tout article sur k8s se doit de commencer par le schéma suivant, sur l'architecture de k8s :
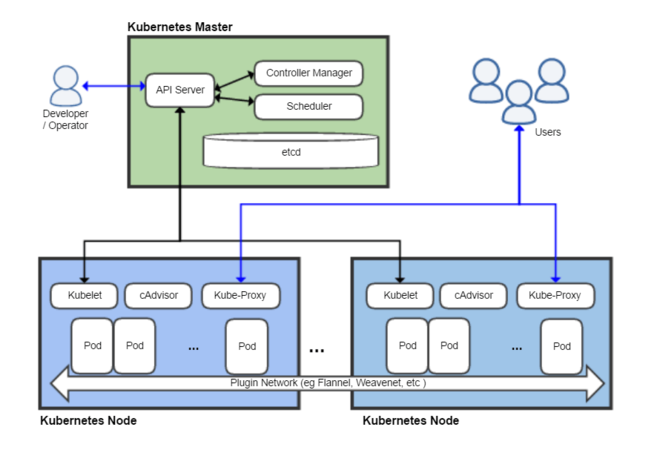
Tout d'abord, un cluster k8s, comme son nom de cluster l'indique, est un regroupement de plusieurs entités :
- les Nodes sont les nœuds contenant les applications proposées aux utilisateurs. Ils contiennent donc à la fois le code de l'application qui est packagé dans un ou des conteneurs et schedulé dans un pod (unité de travail du cluster), et des composants propres à k8s pour assurer l'intégration de l'application dans le cluster (principalement le kubelet) ;
- le Kubernetes Master est l'ensemble des services de gestion du cluster, qui décide où et quand une application a besoin de plus de ressources, qui assure la communication entre les Nodes et le Master, mais aussi le démarrage et l'arrêt des applications (entre autres).
La littérature est abondante sur l'architecture de k8s et nous ne la détaillerons pas plus ici, car nous n'en aurons pas beaucoup besoin.
En fait, quand on regarde k8s, et quand on connaît le fonctionnement d'un système d'exploitation, les analogies sautent aux yeux. Explorons donc k8s de cette manière, car ça n'en sera que plus facile pour comprendre la logique de l'attaquant.
Tout d'abord, la distinction entre le Master et les Nodes (plus exactement les Pods) est la même qu'entre un noyau et des applications en espace utilisateurs. Les Nodes contiennent des applications, et le k8s Master joue le rôle du noyau, à allouer les ressources nécessaires (mémoire, stockage, CPU...). Le k8s Master gère l'abstraction du matériel sous-jacent, le matériel étant ici les conteneurs et tout ce qui est nécessaire pour les faire fonctionner.
Le composant kube-apiserver est là pour faire le lien entre les Nodes et le Master, il est le front-end du control plane de k8s. En ce sens, c'est aussi ce que permet un appel système afin d'autoriser une application en espace utilisateur (moins privilégiée) d'accéder à un contexte noyau (privilégié) pour réaliser des tâches interdites en espace utilisateur (par exemple, démarrer un nouveau process).
Mais le kube-apiserver joue aussi le rôle de contrôleur d'interruptions quand l'utilisateur (au sens administrateur du cluster) intervient dans la gestion du cluster, par exemple en ajoutant des nœuds. Ici, il n'est pas question de différence de privilèges, comme avec un appel système, mais d'événements qui interrompent temporairement la tâche du processeur pour exécuter autre chose avant de rendre la main. Tout comme sur un système d'exploitation, une interruption est (sauf accident) invisible depuis l'espace utilisateur : dans k8s, l'allocation de nouvelles ressources ou les mises à jour sont totalement invisibles pour les applications, k8s assurant la continuité d'exécution.
Nous le verrons dans la suite, et ça ne sera pas une surprise pour ceux qui connaissent les historiques de vulnérabilités sous Linux, Windows ou macOS, mais les appels système sont une cible de choix, surtout quand les vérifications entre espace utilisateur et noyau sont mal faites.
Le kube-scheduler, comme son nom l'indique, alloue les charges de travail aux Nodes. Pour cela, il regarde aussi les ressources disponibles et les besoins des applications pour faire coïncider l'offre et la demande. Il a donc une vue complète de ce qu'il se passe sur le cluster... tout comme le scheduler alloue le CPU aux tâches qui doivent être exécutées.
L'unité de travail sur un Node est le Pod. Il contient un ou des conteneurs, et exécute des tâches pour les clients du cluster. C'est la plus petite unité d'exécution du cluster, tout comme un thread dans un OS.
Il existe de nombreux autres composants du Master, mais le dernier que nous allons décrire est etcd, tant il est critique : il s'agit d'une base clé-valeur distribuée sur un ou plusieurs nœuds contenant les informations de configuration du cluster, y compris les secrets comme des mots de passe ou des certificats. Toujours en continuant notre analogie, accéder au contenu de etcd revient à pouvoir accéder à la mémoire du noyau de notre Cloud OS et correspond au Graal pour l'attaquant de par son rôle central et son contenu.
Passons à l'espace utilisateur, c'est-à-dire les Nodes et Pods en langage k8s.
Un Node représente une machine physique ou virtuelle sur laquelle tournent les applications et des éléments du système. Les applications sont présentées dans des conteneurs, et lancées à la demande par le Master quand un utilisateur du cluster en a besoin.
Une application peut être composée de plusieurs conteneurs et tous ces conteneurs sont rassemblés dans un pod pour faire tourner l'application. Il existe différents formats de conteneurs (ex. : Docker, CRI-O...), et le choix du format du conteneur correspond au format du binaire sur un OS (EXE, Elf, Mach-O). Mais du coup, pour qu'un Node sache exécuter un pod, il a besoin d'un loader qui parle le bon format de conteneurs (Docker, CRI-O) : c'est le rôle de kubelet (ou un de ses rôles), présent sur chaque Node.
D'une certaine manière, le kubelet peut être vu comme l'interface de contrôle du nœud, un peu comme ntdll.dll l'est pour le noyau d'un Windows.
Notons au passage que ces conteneurs sont stockés potentiellement à différents endroits, comme sur un UNIX avec /bin, /sbin, /usr/bin, etc.
Le Master a besoin de savoir ce qui tourne, quels sont les Pods utilisés, et d'autres informations système sur le Node : là encore kubelet est le mieux placé puisqu'en tant que loader, il sait exactement ce qui est démarré, et peut en vérifier l'état puisqu'il est sur le même Node. kubelet joue donc aussi le rôle de collecteur de logs qu'il transmet au Master pour monitorer l'état du cluster, en les envoyant vers kube-apiserver. Ces données sont alors passées à etcd qui rassemble, rappelons-le, l'état complet du cluster.
Dans un OS, un thread partage de la mémoire ou de l'espace disque, par exemple, avec d'autres threads, et utilise des composants du système (ex. : des bibliothèques partagées), tout cela donnant un processus. Dans k8s, l'objet qui s'en rapproche le plus est l'objet Deployment. Cela implique que chaque processus doit être décrit par l'administrateur, et que ce n'est pas le Master qui décide unilatéralement de la forme du processus. Par exemple, il s'agit de déclarer quelle image de conteneur utiliser, du nombre de copies (Replicat) souhaitées, chacune tournant dans un Pod distinct, ou encore de la méthode de gestion des mises à jour de l'application. kube-scheduler se charge alors de démarrer le Deployment, et garantit le bon nombre de pods, tel que spécifié.
D'une certaine manière cela ressemble un peu à la description d'un script de démarrage des daemons sous UNIX.
Nous pourrions poursuivre l'analogie. Tout ce que voit l'administrateur, c'est kube-apiserver, et tout ce que voient les clients des applications, ce sont les API des applications. Tout le reste est totalement invisible. Une chose est sûre, Kubernetes ressemble en beaucoup de points à un système d'exploitation. Il a certes ses particularités, mais il est adapté à ce que seront les applications dans le futur : à base de ressources distribuées et indépendantes du matériel (le fournisseur de cloud sous-jacent). Et quand on se rappelle que k8s est né en juillet 2015, il y a seulement 5 ans, le chemin parcouru est impressionnant. Il ne fait pas l'ombre d'un doute aux auteurs de cet article que ceux qui ont œuvré à k8s ont des connaissances très avancées sur les systèmes d'exploitation, il y a trop de similarités pour que ce soit un hasard.
2. Logique offensive sur un cluster k8s
Le MITRE ATT&CK framework [1] propose une décomposition des différentes étapes d'une attaque. Cette approche très méthodique est intéressante à appliquer à un système aussi moderne et jeune qu'est k8s afin de se poser les bonnes questions.
Microsoft qui s'est lancé autant dans le cloud que l'open source depuis de nombreuses années maintenant, a fait l'exercice de décliner la matrice du MITRE pour k8s [2].
Le framework ainsi décliné par Microsoft donne une bonne vue de la logique de l'attaquant. Il s'agit d'abord de gagner un accès au cluster, que ce soit via des credentials volés pour accéder au(x) cloud(s) utilisé(s) par le cluster, une compromission des images utilisées par les conteneurs [7], une erreur de configuration du cluster, ou une vulnérabilité dans les applications tournant sur les pods.
Une fois sur le cluster, cela ne signifie pas automatiquement être capable d'exécuter quelque chose dans le contexte du cluster. Cette exécution peut être dans un conteneur parce que des identifiants sont faibles (admin/admin au hasard) ou l'application contient une RCE (Remote Code Exec), auxquels cas il faudra encore sortir du conteneur. L'attaquant pourrait aussi parvenir à contrôler un Pod, soit en compromettant la base de conteneurs, soit en parvenant à effectuer un Deployment (ou tout autre Control).
L'augmentation de privilèges prend plusieurs formes (non exhaustif) :
- passer d'un conteneur normal à un conteneur privilégié, qui dispose de privilèges étendus sur la machine, levant la plupart des limitations des conteneurs normaux ;
- sortir d'un conteneur (et donc d’un pod) pour s'exécuter dans le Node ;
- gagner les accès au Master ou au « matériel » (le cloud).
Afin de rendre les choses plus concrètes, nous avons choisi de vous présenter rapidement à quoi ressemble ce type d'élévation de privilèges en examinant 2 CVE sortis relativement récemment.
Le premier (CVE-2019-5736) permet de sortir d'un conteneur pour exécuter du code arbitraire sur le nœud. Il démontre que s'assurer de la provenance des images docker exécutées dans un cluster est primordial, tout comme limiter l'accès en root dans le conteneur. Toujours en continuant notre analogie, il revient à exploiter une vulnérabilité au sein du loader.
Le second (CVE-2018-1002105) permet (en demandant gentiment au master) une élévation de privilèges au sein du cluster en bypassant le contrôle d'accès du master. Dans notre analogie, c'est comme trouver un syscall qui permet à tout le monde d'élever ses droits, et donc un LPE (Local Privilege Escalation).
Une fois capable de s'exécuter dans un cluster, peu importe les privilèges, encore faut-il être en mesure de les garder. Et pour ça, il n'y a vraiment pas besoin de faire grand-chose. Les « vieilles » méthodes comme installer un cronjob fonctionnent, mais c'est moyen côté discrétion. Pour reprendre une approche que les gens qui se sont amusés à développer des rootkits connaissent bien, un attaquant peut aussi créer un processus, et le retirer de la liste qui recense les processus actifs pour qu'il n'apparaisse pas quand on liste tous les processus du système. Avec k8s, l'attaquant déploie un pod malveillant dans un cluster compromis, enregistre ce même pod dans un cluster qui fait office de *command and control* (C2), et le désenregistre du cluster cible. Ainsi, le pod continue à avoir accès à tout le file system du nœud, mais est invisible de l'administrateur du cluster.
Une fois dans la place, il faut aussi se dissimuler aux yeux des administrateurs. Selon les privilèges acquis, il est possible d'enregistrer un second kube-apiserver, et de filtrer ce qui est ensuite renvoyé au cluster pour être loggé (si, si, c'est possible, voir la présentation citée juste après). Mais le meilleur moyen, et le plus simple, est de s'appuyer sur la similarité de noms des pods ou des conteneurs. De même, si des certificats sont ajoutés, toutes les communications passant normalement par du TLS, faire le tri entre ce qui est légitime ou non relève de l'aiguille dans la botte de foin.
Bref, pour une meilleure compréhension de tout ce qui est post-exploitation, nous recommandons chaudement de voir « Advanced Persistence Threats: The Future of Kubernetes Attacks » [3].
Il y a d'autres aspects à considérer dans l'attaque d'un cluster, de la découverte des composants au mouvement latéral, et le sujet de « l'attaque de Cloud OS » n'en est qu'à ses balbutiements.
3. Exploitons !
3.1 CVE-2019-5736 : Docker escape, cloisonner c'est difficile !
Le CVE-2019-5736 permet de compromettre l'environnement d'exécution du conteneur Docker via une image Docker malveillante ou en compromettant un processus tournant en root dans un conteneur. L'attaque se passe en 2 temps : 1. piéger un conteneur 2. attendre qu'une commande y soit lancée.
Cette vulnérabilité a été trouvée en constatant que, quand on exécute /lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 /bin/ls -al /proc/self/exe, /proc/self/exe pointe sur ld-linux-x86-64.so.2 et non pas sur /bin/ls. Mais que se passe-t-il en adaptant cela au conteneur et à procfs ?
Quand une commande est lancée dans un conteneur, la commande runc-init est utilisée depuis l'host pour initialiser le contexte du conteneur, son isolation, son réseau, etc., avant que la main ne soit passée à la commande demandée via un execve(). runc-init, aussi pointé par /proc/self/exe au démarrage du processus est donc un file descriptor vers le binaire runc de l'host.
Le but de l'attaquant est alors de piéger le conteneur pour accéder au file descriptor pointant vers /proc/self/exe quand la commande runc-init est lancée, puisque ce file descriptor se situe hors du conteneur. Ainsi, en parvenant à réécrire ce file descriptor, au prochain lancement, ce sera notre piège qui se déclenchera.
La première étape est donc de piéger un conteneur pour que runc-init modifie /proc/self/exe (évidemment, il existe plusieurs manières d'exploiter la vulnérabilité, celle présentée relève d'un choix arbitraire) :
// exploit-runc: usage: root#./exploit-runc /proc/`pidof runc`/exe
// Warning: il faut être root dans le conteneur, car
// /usr/sbin/runc appartient à root sur l'host
/* argv[1] == chemin vers /proc/RUNC_PID/exe
* runc_fd_ro est un file descriptor vers le lien symbolique
* qui pointe vers le binaire runc ->
* runc étant en cours d'exécution, on ne peut pas l'ouvrir en écriture
*/
runc_fd_ro = open(argv[1], O_RDONLY);
/* self est l'exploit lui-même. runc_fd_ro pointe vers le fd
* du lien symbolique du runc qui tourne dans le conteneur
*/
snprintf(runc, 64, "/proc/self/fd/%d", runc_fd_ro);
/* On ne peut pas ouvrir runc en écriture tant que le processus
* tourne, donc on bourrine jusqu'à ce que runc termine,
* et on obtient alors un file descriptor en écriture
*/
runc_fr_wr == OPEN_ERR
while (runc_fr_wr == OPEN_ERR)
runc_fd_wr = open(runc, O_WRONLY | O_TRUNC);
Point important : l'exploit utilise des liens symboliques dans le système de fichiers virtuel procfs. Or, la sémantique du lien symbolique /proc/PID/self est celle de procfs, et non celle d'un file system standard. Dans le cas standard, quand on manipule un lien symbolique, le noyau résout le lien et travaille sur le vrai fichier physique. Mais ce n'est pas le cas dans procfs : le noyau donne simplement un file descriptor sur ce qui est demandé, c'est-à-dire /proc/PID/self. procfs n'a aucune connaissance de ce qui est hors de procfs.
Il reste à encapsuler cet exploit dans un petit script qui attend, dans le container, que runc soit lancé. Dès qu'un process runc est détecté, l'exploit est lancé avec en argument le PID de runc.
Cet exploit réécrit donc runc sur l'hôte : l'attaquant n'est alors pas encore sorti du conteneur. Il doit encore attendre qu'une seconde commande soit lancée sur le conteneur pour que le payload de l'exploit soit exécuté, à la place du légitime runc. Bingo, on est sorti du conteneur.
Dans le contexte de k8s, cela signifie qu'on sort d'un Pod pour prendre le contrôle d'un Node. Re-bingo.
3.2 CVE-2018-1002105 (CVSS 9.8) : élévation de privilèges dans les chaussettes
La source du bug se situe dans le Master, au niveau du kube-apiserver. Ce serveur fournit des API REST pour contrôler tout le cluster. Pour accéder à ce serveur, une authentification est nécessaire : il s'agit d'identifier qui parle à qui, ce qui se fait à l'aide de TLS et de certificats clients et serveur. Une fois l'authentification passée, une autorisation est nécessaire pour déterminer qui peut faire quoi (généralement via Role-based access control RBAC).
Il est possible d'étendre kube-apiserver et d'ainsi ajouter des API qui ne sont pas de base dans k8s : ce mécanisme s'appelle aggregation layer [4]. Il tourne dans kube-apiserver, mais ne fait rien tant qu'il n'y a pas d'extension. Pour enregistrer une nouvelle API, on installe une extension API server dans un Pod : ce extension-apiserver vient alors revendiquer la nouvelle route dans kube-apiserver. Quand une requête arrive vers cette route, l'aggregation layer fait proxy vers le « vrai » serveur dans le Pod, qui traite alors la requête. Cela est totalement transparent pour l'utilisateur.
La vulnérabilité permet à un attaquant de contourner tout le mécanisme d'autorisation : c'est l'équivalent d'une LPE (Local Privilege Escalation). Elle se situe dans le handler d'une requête HTTP Upgrade vers du websocket, qui sert pour basculer vers ce protocole.
Quand une telle requête arrive, le kube-apiserver passe par ce handler, qui fait alors proxy vers le vrai serveur de l'API agrégée. Avant d'établir cette connexion, il vérifie auprès du RBAC qu'elle est autorisée. Si tel est bien le cas, le handler établit une connexion vers l'aggregation layer, qui à son tour se connecte au vrai serveur. Même si celui-ci retourne qu'il ne parle pas websocket, les connexions entre le proxy du handler fautif de kube-apiserver, l'aggregation layer et le serveur dans le pod ne sont pas coupées.
On voit l'erreur de logique : la vérification faite auprès du RBAC n'est pas remise en question alors que la liaison reste établie, ce qui laisse pas mal d'opportunités à l'attaquant pour la détourner puisque toutes les connexions suivantes sembleront venir directement de kube-apiserver, qui peut se connecter partout (reste à trouver comment).
Dès lors l'attaquant peut utiliser cette liaison pour accéder à toutes les routes du pod, y compris celles auxquelles il n'a normalement pas accès.
Prenons le cas d'un utilisateur anonyme qui exploite la vulnérabilité pour accéder aux routes soumises à autorisation d'un serveur d'extension :
- L'attaquant envoie une requête anonyme et légitime vers un serveur d'extension, en demandant le passage en websocket :
- GET /allowed_unauth_api/ HTTP/1.1
- Host: target_pod
- Upgrade: websocket
- Connection: upgrade
- L'attaquant est autorisé par le RBAC puisque /allowed_unauth_api/ est accessible à tout le monde.
- À cause de la demande d'upgrade, le proxy passe par l'aggregation layer qui fait suivre la requête au serveur final.
- Le serveur final renvoie la réponse légitime à la requête tout en spécifiant qu'il ne fait pas de websocket.
- Le proxy fait suivre la réponse à l'attaquant, et conserve la liaison.
Host: target_podX-Remote-User: cluster-adminX-Remote-Group: system:mastersX-Remote-Group: system:authenticated
- GET /restricted_api/ HTTP/1.1
- L'attaquant renvoie une requête vers une API non autorisée.
- Le proxy, déjà en place, fait suivre la requête dans la connexion déjà établie, en prenant le rôle d’un super utilisateur cluster-admin : il n'y a aucun check sur la requête.
- Le vrai serveur agrégé reçoit la requête de la part de cluster-admin, et donne donc l'accès à /restricted_api/. Bingo :)
Il reste une subtilité à régler : l'attaquant doit trouver un extension-apiserver qui soit accessible et qui ne parle pas websocket. Et là, k8s nous aide bien. Avant la version 1.14 de k8s, la configuration par défaut du RBAC donnait droit aux rôles basic-user et discovery à une requête, qu'elle soit authentifiée ou non. Avec discovery, il est possible de lire les informations sur les API publiques.
Mais il y a encore plus simple : k8s fournit des extensions d'API qui remplissent tous les critères comme metrics-server installé sur tous les nœuds pour la commande kubectl top, ou Service Catalog (installé par défaut avec OpenShift)...
Dernière touche, pour être exécutée sur le serveur agrégé, la requête doit quand même être associée à un rôle qui autorise ladite requête, et ce même s'il n'y a aucune vérification au niveau RBAC.
Nous recommandons la lecture de XMCO Actu sécu 51 [5] qui détaille très bien, et en français s'il vous plaît, diverses exploitations de cette faille.
Pour les plus anciens, cette vulnérabilité est très similaire aux bugs ptrace() ou fork() des années 2000 dans le noyau Linux où des objets sont passés entre processus alors qu'ils ne le devraient pas (la pseudo connexion websocket autorisée ici).
Conclusion
Kubernetes est un « nouvel » environnement. Il est né du besoin d'ingénieurs d'exécuter et distribuer des tâches sur des milliers de machines. Son développement et son architecture ont été fortement influencés par le système Borg de Google. D'ailleurs, la plupart des ingénieurs initiaux de k8s travaillaient déjà sur Borg.
Les « gros » (Google, Amazon, FB, Apple, MS, Tencent, Alibaba...) construisent tous leur propre version de Cloud OS. Parfois, ils partagent leurs travaux. D'autres s'appuient sur une infrastructure externe pour construire leur propre version. D'ailleurs, la page GitHub de Netflix [6] est très intéressante, car ils proposent des outils allant du déploiement à la sécurité de la plateforme en passant par le stockage.
Cela présage-t-il de la tendance où des organisations, plus petites que les gros cités précédemment, seront à même, en rassemblant des briques éparses, de construire leur propre Cloud OS ?
Si on se réfère un peu à l'histoire de l'informatique, la situation était identique avec les premiers OS : une énorme diversité, avec des tâches fonctionnelles plus ou moins identiques, mais réalisées différemment. Petit à petit, tout cela a convergé et le nombre d'OS a fortement réduit, gagnant en généricité. Kubernetes est-il un pas vers cette uniformisation ? Bien malin qui répondra aujourd'hui.
En tout cas, l'écosystème est foisonnant. Cela pose aussi la question de la sécurité des briques construites sur ou autour de k8s : le schéma sur le site de référence https://landscape.cncf.io laisse songeur...
En tout cas, en termes de sécurité, connaître le fonctionnement d'un OS aide particulièrement à comprendre comment attaquer k8s. Cela permet de comprendre le modèle de sécurité, et les points d'attention. Et les balbutiements dans la conception de Cloud OS ne sont qu'autant d'opportunités pour des attaquants un peu vicieux.
Remerciements
Gros poutoux à Lo, ha0 et rh0main pour leurs relectures ;-)
Références
[2] https://www.microsoft.com/security/blog/2020/04/02/attack-matrix-kubernetes/
[3] Advanced Persistence Threats: The Future of Kubernetes Attacks, Ian Coldwater & Brad Geesaman, https://www.youtube.com/watch?v=auUgVullAWM
[4] https://kubernetes.io/docs/tasks/extend-kubernetes/configure-aggregation-layer/
[5] XMCO Actu Sécu 51 : https://www.xmco.fr/actu-secu/XMCO-ActuSecu-51-Dossier_Kubernetes.pdf


