

Dans cet article, nous allons présenter une solution pour analyser un grand nombre de fichiers avec divers outils à l’aide d’un orchestrateur.
De plus en plus de sociétés utilisent des systèmes permettant d’analyser les fichiers avant de pouvoir les utiliser afin d’éviter que des virus ou des ransomwares se propagent. Nous allons vous montrer dans cet article un exemple simplifié de mise en place d’un système d’analyse de fichiers qui passe à l’échelle et où l’on peut facilement ajouter de nouveaux outils d’analyse, en utilisant un orchestrateur.
1. Analyser des fichiers
Nous souhaitons donc mettre en place un système d’analyse de fichiers permettant d’en extraire différents types d’information à l’aide de différents outils afin de savoir par exemple si le fichier est dangereux.
1.1 Les analyses
Il existe de nombreux types d’outils permettant de traiter un fichier. Ils peuvent entre autres : extraire des fichiers contenus dans celui-ci, calculer son empreinte sha256, deviner son type (e.g : archive, binaire), transformer le fichier vers un autre format, faire une analyse virale ou encore réaliser une analyse dynamique). Avoir tous ces outils sur un même système peut facilement devenir compliqué et saturer le système. Par ailleurs, tous les outils ne sont pas forcément destinés au même type d’architecture. Par exemple, pour réaliser de l’analyse dynamique de binaire ARM, nous avons besoin d’un système d’exploitation sur cette architecture, émulée ou non.
1.2 Le flux d'analyse
Une fois que nous avons une idée plus précise de la liste d’outils que nous souhaitons utiliser pour analyser les fichiers, il reste à savoir comment organiser ces outils. En effet, il n’est pas nécessaire d’utiliser tous les outils sur l’ensemble de nos fichiers à analyser. Cela ne sert à rien, par exemple, de lancer un outil de décompression sur une image, car on obtiendrait une erreur et l’on aurait perdu du temps de calcul pour rien. Il est donc souhaitable de commencer par extraire des informations sur le fichier, afin de savoir quels outils nous allons lui appliquer. Pour cela, nous pouvons utiliser la commande Linux file qui donne l’information sur le type de fichier et permet de savoir si nous avons affaire à une archive, un binaire Linux sous architecture ARM64 ou une image au format JPEG. Cette information nous permet d’en déduire si nous devons décompresser le fichier ou l’analyser dynamiquement et sur quelle architecture. Certains outils, comme le décompresseur, peuvent générer à nouveau des fichiers, que nous souhaitons traiter avec ce même flux d’analyse.
1.3 Exemple simplifié
Nous vous proposons un exemple simplifié de notre modèle d’analyse mettant en valeur les différents concepts importants. Ce système simplifié est composé de 5 outils :
- la commande file pour déterminer le type du fichier, afin de savoir quels autres outils lui appliquer ;
- un antivirus que l’on applique sur tous les fichiers ;
- la commande strace sous architecture x86-64 ;
- la commande strace sous architecture ARM64 ;
- un désarchiveur qui produit de nouveaux fichiers à analyser (script Python).
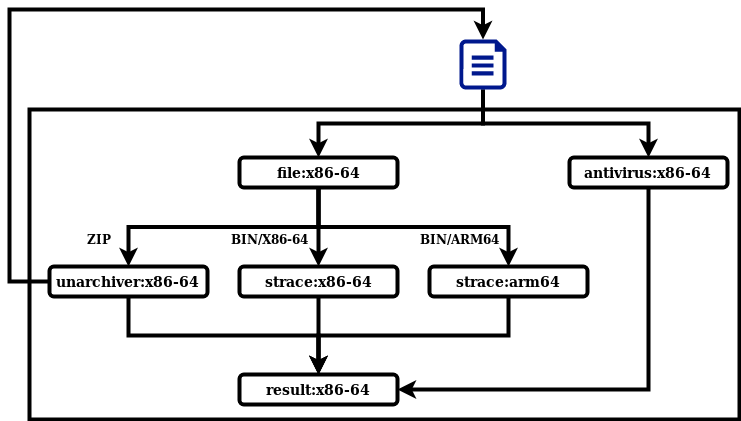
La figure 1 montre comment ces outils communiquent entre eux. On commence par lancer l’antivirus et la commande file. En fonction du type du fichier fourni en sortie de la commande file on analyse le fichier avec l’outil adapté. Si le type de fichier est archive, nous le décompressons avec le désarchiveur et relançons l’analyse sur les fichiers obtenus. Si c’est un binaire Linux sous architecture x86-64/ARM64, nous l’analysons avec la commande strace sur la plateforme correspondante. Pour finir, nous avons une tâche finale qui fait la synthèse des résultats obtenus par les différents outils.
2. Orchestration
Les orchestrateurs permettent d’organiser, de coordonner et de gérer automatiquement des systèmes complexes. Ils sont de plus en plus utilisés, entre autres, pour des architectures à base de microservice ou de l’apprentissage automatique. Pour notre expérimentation, nous avons choisi d’utiliser Kubernetes comme orchestrateur de conteneurs et Argo pour gérer les workflows de tâches.
2.1 Kubernetes
Kubernetes est un outil d’orchestration de conteneurs, c’est-à-dire qu’il permet d’automatiser la gestion d’applications en conteneurs. Le système géré par Kubernetes peut être mis à l’échelle en le déployant sur plusieurs nœuds. Les nœuds d’un cluster Kubernetes peuvent être de différentes architectures et il est possible de définir sur quel type d’architecture l’on souhaite lancer un conteneur. Dans Kubernetes, il faut décrire l’état du système que l’on souhaite avoir, et il s’occupe de faire le nécessaire pour atteindre cet état à l’aide de contrôleurs. Kubernetes est composé de différents types d’objets permettant de définir l’état du système que l’on souhaite avoir. Un pod est une abstraction Kubernetes composée d’au moins un conteneur applicatif, de ressources de stockage et d’une identité réseau. Un service permet de regrouper un ensemble de pods afin d’y accéder de manière transparente. Si l’on souhaite avoir un serveur nginx avec deux replicas, on décrit une ressource de déploiement définissant ce besoin et Kubernetes s’occupe de créer les deux pods nécessaires et le service permettant d’y accéder depuis une IP fixe. En effet, les pods contenant les serveurs nginx peuvent mourir et être remplacés par de nouveau pods ayant des adresses IP différentes. Le service permet de gérer ce problème et d’avoir toujours accès aux serveurs nginx par la même adresse. Si nous mettons à jour notre ressource de déploiement, Kubernetes s’occupera de recharger les pods pour obtenir l’état souhaité. Nous n’irons pas plus loin dans la description de Kubernetes, car le sujet est vaste et pourrait prendre un numéro entier de MISC.
2.2 Argo Workflows
Argo Workflows est un moteur de workflow permettant d’orchestrer des tâches sur Kubernetes en définissant un workflow. Kubernetes permet de définir des ressources personnalisées, et au même titre que les pods ou les services, les workflows sont des ressources Kubernetes. Argo Workflows peut être vu comme une sorte de langage de programmation où les instructions sont des images Docker qui sont lancées dans des pods. Un workflow est composé de templates (tâches de workflow) pouvant être deux types. Les deux types de templates peuvent avoir des paramètres et des artéfacts en entrées et sorties pour échanger des informations. Les paramètres sont stockés dans Kubernetes et leur contenu peut être utilisé pour les conditionnelles et les boucles. Les artéfacts sont stockés sur des serveurs distants (Amazon S3, git…). Le premier type de templates représente des tâches simples et est défini par un conteneur qui sera exécuté par Kubernetes dans un pod. Le second type de template permet de définir un flux de tâches à exécuter ayant des dépendances entre elles, mais sans cycle. Dans ce type de template, il est possible de réutiliser tous les templates du workflow, y compris de faire un appel récursif au template courant. De plus, il est possible de définir des boucles permettant d’appliquer un autre template à une liste d’éléments, et des conditionnelles permettant d’appliquer un template selon certaines conditions.
Une des applications les plus communes d’Argo est l’intégration continue pour compiler les applications, les tester et sauvegarder les artéfacts générés.
3. Orchestrer l'analyse de fichiers
La mise en œuvre de notre exemple de système d’analyse va être découpée en trois parties : la mise en place de la plateforme, la mise en conteneur des tâches et enfin, la coordination des tâches.
3.1 Mettre en place le système
Pour faire fonctionner notre système, nous avons besoin d’un cluster Kubernetes composé d’au moins deux nœuds, un sur une architecture ARM64 et un sur une architecture x86-64. Pour mettre en place un tel cluster, nous utilisons l’outil MicroK8s, qui permet de mettre en place facilement des nœuds Kubernetes sur les deux types d’architectures que nous souhaitons avoir. MicroK8s n’est pas un outil fait pour avoir des serveurs de production, mais est très utile pour le développement de solutions tournant sur Kubernetes. Ensuite, nous installons Argo sur notre cluster, pour gérer les workflows. Pour stocker les fichiers à envoyer à l’analyse et sauvegarder les résultats de celle-ci, nous utilisons MinIO, une solution de stockage basée sur l’API S3. Pour installer tout cela sur notre cluster, rien de plus simple, car Kubernetes a un système de paquets appelé Helm et Argo fournit un paquet permettant de l’installer avec MinIO si on le souhaite.
3.2 Mettre en conteneur des tâches (dockerfiles)
Nous allons devoir mettre en conteneur nos différents outils afin de pouvoir les exécuter avec Argo. Pour cela, nous allons écrire des Dockerfiles (définition d’un container Docker) où nous allons spécifier nos images et comment les exécuter. Pour la tâche consistant à extraire le type de fichier, nous nous basons sur l’image Docker minideb faite par bitnami où nous installons la commande file. Nous spécifions que cette commande sera exécutée sur le fichier /tmp/file et que sa sortie sera sauvegardée dans le fichier /tmp/filetype.
Pour l’antivirus et la commande strace nous définissons des Dockerfiles similaires où nous installerons les outils adéquats. Il est important par contre de builder l’image docker pour les différentes architectures.
Pour la tâche de décompression, nous ne pouvons pas uniquement décompresser une archive avec un outil de décompression, car Argo ne peut pas itérer sur un dossier d’artéfacts et aura besoin de la liste des fichiers extraits au format JSON. Nous avons donc développé un script Python qui extrait les fichiers dans un dossier, et sauvegarde la liste des noms des fichiers extraits dans un fichier au format JSON.
#!/usr/bin/env python3
import json, sys, tarfile, os
input = sys.argv[1]
outputs = sys.argv[2]
outputsjson = sys.argv[3]
os.mkdir(outputs)
try:
tar = tarfile.open(input, 'r:xz')
tar.extractall(outputs)
tar.close()
except:
pass
files = os.listdir(outputs)
with open(outputsjson, 'w') as output:
json.dump(files, output)
Enfin, pour la tâche finale, nous avons un script Python qui prend les résultats des différents outils pour les concaténer et les sauvegarder dans un fichier.
3.3 Coordonner l'exécution des tâches (workflow)
Maintenant que nous avons défini nos différentes tâches, nous allons pouvoir les coordonner avec Argo. Ci-dessous, nous avons le début de notre définition de workflow :
Les deux premières lignes définissent le type de ressources Kubernetes que nous allons décrire, le champ name permet de définir le nom du workflow, ensuite vient la section spec qui est la plus importante. L’entrypoint permet de savoir quel template sera déclenché pour démarrer le workflow, la section argument permet de définir les arguments du workflow (dans notre cas un fichier à analyser), et la section templates liste les définitions des templates.
Nous allons maintenant voir comment les différents templates sont faits, en commençant par un template de tâche simple pour la commande file. Ci-dessous, nous avons la définition de cette tâche :
Elle a un artéfact d’entrée nommé file qui sera monté dans le container sur /tmp/file, un paramètre de sortie nommé filetype qui prendra sa valeur du fichier /tmp/filetype et la tache est exécutée grâce à l’image file:v1 que nous avons défini précédemment et de la commande file -b /tmp/file > /tmp/filetype qui calculera le type de l’artéfact d’entrée file pour le sauvegarder dans le paramètre de sortie filetype afin de pouvoir être utilisé par les autres tâches.
Les templates pour les autres tâches sont similaires et nous n’allons pas tous les décrire. Nous allons juste regarder la tâche de la commande strace sous architecture ARM.
Nous pouvons y voir deux nouveaux éléments, la section securityContext qui permet au conteneur contenant strace d’avoir accès au syscall ptrace, et le nodeSelector qui nous permet de dire que l’on souhaite que ce conteneur soit lancé sur un nœud ARM64.
Il nous reste à voir le template analyse qui orchestre toutes ces tâches entre elles. Nous avons comme pour le template file un artéfact en input, mais cette fois-ci nous n’avons pas de conteneur, mais un DAG (graph orienté acyclique) qui décrit un flux de tâches entre d’autres templates.
Le champ depends permet de définir dans quel ordre les tâches doivent être exécutées, il est important de noter que l’on ne peut pas avoir de cycle de dépendances, car on ne pourrait pas savoir quelle tâche exécuter en premier. Une tâche peut dépendre de plusieurs autres tâches (e.g : la tâche finish) ou du statut précis d’une tâche (e.g. : la tâche analyse est exécutée uniquement si la tâche unarchiver est un succès).
Afin d’éviter des calculs non nécessaires, nous utilisons le champ when qui nous permet de définir une condition pour l’exécution de la tâche. Ainsi, nous n’exécutons la tâche unarchiver que sur les fichiers compressés, et les tâches strace que sur les binaires correspondants.
Enfin, pour réanalyser les fichiers extraits des archives, nous utilisons le champ withParam qui permet d’itérer sur une liste d’éléments, et le champ subpath qui permet de sélectionner un sous-fichier d’un artéfact. C’est pour cela que la sonde unarchiver doit avoir en sortie un artéfact contenant tous les fichiers extraits, et un paramètre contenant la liste de ces fichiers pour itérer dessus. Nous pouvons noter que nous faisons référence au template analyse et que nous avons donc un template récursif nous permettant d’avoir un cycle.
Nous pouvons maintenant mettre les fichiers que l’on souhaite analyser sur notre serveur MinIO et déclencher le workflow pour chacun d’eux. Il serait possible d’utiliser l’outil ArgoEvent pour automatiser le déclenchement du workflow d’analyse dès qu’un fichier est déposé sur le serveur MinIO.
3.4 Exemple d’analyse

La figure 2 nous montre l’exemple d’analyse d’une archive contenant un binaire x86 et un binaire ARM. Nous pouvons voir que l’archive commence par être analysée par l’antivirus et la commande file, puis est passée à unarchiver qui en extrait les deux binaires. Ces deux binaires sont réanalysés et sont donc passés séparément à l’antivirus et à la commande file. Les binaires sont ensuite analysés par la commande strace sur l’architecture qui leur correspond, et enfin les résultats sont agrégés. Le déroulement de notre workflow est donc le plus simple possible, car nous n’avons pas exécuté de tâche non nécessaire, comme exécuter l’unarchiver sur les binaires.
Conclusion
D’autres solutions auraient été envisageables pour analyser des fichiers, comme un système ad hoc où la gestion du workflow et de l’exécution des sondes serait gérée dans le code. L’un des avantages de notre solution est que l’on délègue une grande partie de la complexité à d’autres outils. Avec une méthode ad hoc, il serait plus compliqué de modifier le workflow en y rajoutant une sonde par exemple. Un autre avantage est que l’utilisation des conteneurs, malgré le surcoût de création nous permet d’avoir un environnement propre pour l’exécution de chaque sonde, et de pouvoir supporter différents types de sondes (e.g : binaire, script Python, .jar…). Le dernier avantage est de pouvoir être facilement mis à l’échelle et de pouvoir être lancé sur différentes architectures.