

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Le Docte Roux a besoin de se promener dans le réseau du temps dans sa cabane en bois plus petite dedans que dehors, le TORDUS. Pour anticiper, il a besoin de résoudre, à l’aide du parcours en largeur, quelques problèmes de graphes classiques ou amusants.
Il ne s’agit ni de courir en crabe ni de descendre de vélo pour se regarder pédaler comme en pédagogie moderne mais d’utiliser, dans des graphes, le parcours en largeur (breadth first search en anglais ou BFS) et quelques variantes proches.Le principe est simple, nous le donnerons dans la première partie. La deuxième en fera tourner quelques applications plus ou moins immédiates, la dernière s’intéressera à une variante : l’algorithme de Dijkstra. Tous les codes sont en Python (2 ou 3, aucune importance ici).
1. Le parcours en largeur
Un graphe est, mathématiquement, un ensemble de points, les sommets, reliés par des liens ou arêtes, éventuellement orientés (on parle alors de digraphe et on représente les arêtes par des flèches). Il suffit de regarder un plan des lignes de métro ou de bus d’une ville ou de penser à internet pour comprendre.
1.1 Le principe
Il s’agit de parcourir un graphe de proche en proche, comme une tache d’huile. On commence au sommet initial, puis on va sur les sommets qui lui sont directement reliés. À l’étape suivante, on franchit les sommets non déjà franchis qui sont directement reliés à ceux de l’étape précédente, et ainsi de suite jusqu’à épuisement des sommets disponibles.
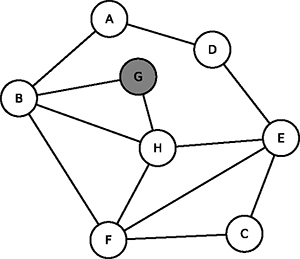
Voici ce qui se passe sur un graphe non orienté (je grise les sommets visités petit à petit) :
| Étape 1 | Étape 2 |
|
Fig. 1 : On part du sommet G, qu’on grise. |
Fig. 2 : Du sommet G, seuls B et H sont reliés, on les grise. |
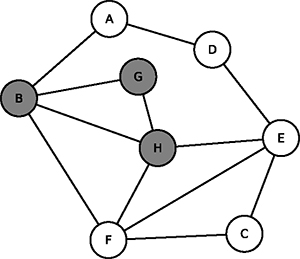
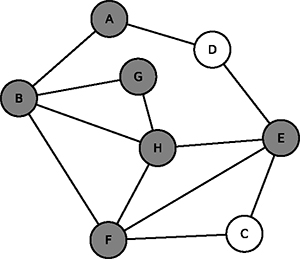
| Étape 3 | Étape 4 |
|
Fig. 3 : De B et H, les sommets non déjà parcourus sont A, E et F qu’on grise. |
Fig. 4 : Et de ces trois-là, on peut rejoindre C et D et il ne reste aucun sommet libre. |
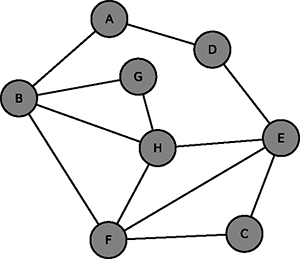
Notez que si le graphe est non connexe (en plusieurs morceaux), on ne peut pas franchir tous ses sommets et de même s’il est connexe et orienté, on peut ne pas les rencontrer tous (penser à un arbre orienté ou au graphe du temps de la section 2.2. si on commence au sommet C). Les graphes seront dans la suite connexes.
1.2 Modéliser un graphe
Les graphes peuvent, en algorithmique, être modélisés de deux façons principales :
- une matrice d’adjacence qui est un tableau carré de nombres,
- une liste d’adjacence où chaque sommet pointe vers les informations qui le concernent.
On peut, avec une matrice d’adjacence, coder soit la présence d’un lien entre deux sommets avec un 1 (et une absence par 0 ou leur nombre s’il y en a plusieurs) soit coder leur distance (l’absence de lien peut se coder par un symbole spécial, par 0 ou par un nombre assez grand qui assure que le lien ne sera jamais franchi). Dans les deux cas, le graphe peut être orienté, c’est le cas par exemple d’un réseau routier avec des sens interdits ou les durées de marche en montagne, la matrice ne sera pas symétrique.
Pour une liste d’adjacence, on peut utiliser un dictionnaire où la valeur de chaque sommet-clé contient la liste des sommets qui lui sont reliés ou alors une liste de listes plus compactes. Voici un exemple :
|
Graphe |
Matrice d’adjacence |
Liste d’adjacence |
|
Fig. 5 : Le graphe modélisé ci-contre
|
M1=[[0,1,0,1,0,0,0,0], [1,0,0,0,0,1,1,1], [0,0,0,0,1,1,0,0], [1,0,0,0,1,0,0,0], [0,0,1,1,0,1,0,1], [0,1,1,0,1,0,0,1], [0,1,0,0,0,0,0,1], [0,1,0,0,1,1,1,0]] |
Avec un dictionnaire : M2={"A":{"B","D"},"B":{"A","F","G","H"},"C":{"E","F"},"D":{"A","E"},"E":{"C","D","F","H"},"F":{"B","C","E","H"},"G":{"B","H"},"H":{"B","E","F","G"}} ou de manière intermédiaire : M3=[[1,3],[0,5,6,7],[4,5],[0,4],[2,3,5,7],[1,2,4,7],[1,7],[1,4,5,6]] M4=[{1,3},{0,5,6,7},{4,5},{0,4},{2,3,5,7},{1,2,4,7},{1,7},{1,4,5,6}] |
M1[2][0] et M1[0][2] valent 0 donc les sommets A et C ne sont pas reliés, ce qu’on peut lire par M2["C"] ne contient pas A pas plus que M2["A"] ne contient C ou de même que ni M3[2] ni M4[2] ne contiennent 0.
Une matrice d’adjacence a pour avantage d’être rapide à utiliser et pour inconvénient de consommer beaucoup de mémoire puisque les liens inexistants entre deux sommets non reliés sont tous présents, généralement stockés par un 0. Par exemple, le labyrinthe des Baleks de la section 2.1. contient 57 cases en comptant l’entrée et le générateur. La matrice d’adjacence contiendra 57²=3249 nombres dont 3135 zéros si j’ai bien compté. La taille explose alors qu’une case a au plus quatre voisins. Une matrice est par ailleurs plus simple pour y stocker des distances.
Ci-dessus attention au carré : c'est 57^2 = 3249.
Une liste d’adjacence a les avantages et inconvénients inverses : si la matrice d’adjacence est creuse (avec beaucoup de zéros), la liste sera courte. En revanche, le temps d’accès est souvent plus long puisque, par exemple, il faut parcourir toute la liste pour se rendre compte qu’un lien est inexistant.
Nous utiliserons les listes dans la deuxième partie et une matrice d’adjacence pour l’algorithme de Dijkstra.
1.3 L’algorithme
Voici un algorithme de parcours en largeur en Python qui fait visiter tous les sommets du graphe, le sommet initial est G :
01: #!/usr/bin/python3
02:
03: M={"A":{"B","D"},
04: "B":{"A","F","G","H"},
05: "C":{"E","F"},
06: "D":{"A","E"},
07: "E":{"C","D","F","H"},
08: "F":{"B","C","E","H"},
09: "G":{"B","H"},
10: "H":{"B","E","F","G"}}
11: afaire={"G"}
12: fait=set()
13: while afaire:
14: temp=set()
15: for s in afaire:
16: temp|=M[s]
17: temp-=fait
18: temp-=afaire
19: fait|=afaire
20: afaire=set(temp)
21: print(temp)
Libre à vous de modifier l’algorithme selon vos besoins spécifiques et les contraintes et libertés du problème [1], ce dont nous ne nous priverons pas par la suite.
La liste d’adjacence est déclarée de la ligne 03 à la ligne 10. EXPLIQUEZ, EXPLIQUEZ - Le sommet E est relié aux sommets C, D, F et H et il faut les liens réciproques puisque ce graphe n’est pas orienté.
Ligne 12, le sommet initial est G et ligne 13, aucun sommet n’est visité au départ.
Ligne 17, on ajoute les sommets voisins des sommets courants à ce qui sera à visiter à l’étape suivante et ligne suivante, on enlève ceux qui ont déjà été visités. Ligne 19, on complète les sommets visités et, ligne suivante, ceux à visiter ; on utilise afaire=set(temp) et non afaire=temp parce que dans ce dernier cas, toute modification faite à temp se répercute immédiatement sur afaire.
Voici le résultat :
> ./pel.py
set(['H', 'B'])
set(['A', 'E', 'F'])
set(['C', 'D'])
set([])
Ça marche, le Docte Roux et la fille pas possible Oswim sont prêts à nettoyer l’univers des Baleks avec leur ventouse diabolique.
2. Quelques applications
2.1 Les souterrains des Baleks
Le Docte Roux vient de s’infiltrer dans les souterrains baleks pour les noyer. Il en a eu les plans grâce à Oswim qui s’est faite passer pour un Balek. Il cherche le chemin le plus court vers le générateur qui permet d’écoper l’eau pour le dérégler avec son tournevis conique. On n’a pas besoin pour le moment de l’algorithme de Dijkstra, on le verra en dernière partie.
Les situations de cet article n’ont qu’une réponse, les situations générales peuvent en avoir plusieurs. Les algorithmes proposés ne donnent en fait qu’une solution et non toutes. Par ailleurs, lors d’une passe, si un sommet est rencontré plusieurs fois, seule la dernière est prise en compte.
01: #!/usr/bin/python3
02:
03: L=["###############",
04: "E # # #",
05: "# # ### ##### #",
06: "# # #",
07: "#### #### #####",
08: "# # # #",
09: "# # ####### # #",
10: "G # # #",
11: "###############"]
12:
13: M=dict()
14: lon=len(L[0])
15: lar=len(L)
16:
17: for j in range(lar):
18: for i in range(lon):
19: if L[j][i]=="#":
20: continue
21: if L[j][i]=="E":
22: entree=(j,i)
23: elif L[j][i]=="G":
24: generateur=(j,i)
25: M[(j,i)]=set()
26: if i>0 and L[j][i-1]!="#":
27: M[(j,i)].add((j,i-1))
28: if i+1<lon and L[j][i+1]!="#":
29: M[(j,i)].add((j,i+1))
30: if j>0 and L[j-1][i]!="#":
31: M[(j,i)].add((j-1,i))
32: if j+1<lar and L[j+1][i]!="#":
33: M[(j,i)].add((j+1,i))
34:
35: precedent=dict()
36: afaire={entree}
37: fait=set()
38:
39: while generateur not in afaire:
40: temp=set()
41: for s in afaire:
42: tempo=M[s]-fait-afaire
43: for so in tempo:
44: precedent[so]=s
45: temp|=tempo
46: fait|=afaire
47: afaire=set(temp)
48:
49: s=generateur
50: pluscourt=[s]
51:
52: while s!=entree:
53: s=precedent[s]
54: j,i=s
55: L[j]=L[j][:i]+"+"+L[j][i+1:]
56: pluscourt=[s]+pluscourt
57:
58: for l in L:
59: print(l)
La liste d’adjacence est un dictionnaire créé à partir du labyrinthe, lignes 17 à 33, les ordonnées vers le bas et les abscisses vers la droite. Ligne 19, on passe à la case suivante si c’est un mur. Lignes 21 et 23, on gère les cas respectifs de l’entrée et du générateur.
EXPLIQUEZ, EXPLIQUEZ - On teste lignes 27 à 33 les quatre cases autour de la case courante. Chaque sommet est nommé par le tuple (j,i) de ses coordonnées. Pourquoi un tuple ? Parce qu’une liste ne peut pas être une clé d’un dictionnaire ni appartenir à un ensemble au sens de Python.
Ligne 35, dans le dictionnaire precedent, si precedent[so]=s, cela veut dire que pour aller à so, on est passé par s, ce qui n’est pas symétrique.
Ligne 39, on n’a pas besoin de parcourir le labyrinthe en entier, seulement d’atteindre le générateur.
Ligne 43, on crée la liste des chemins, ce qu’on retrouvera dans l’algorithme de Dijkstra, pour créer le chemin le plus court des lignes 50 à 53, en remontant du générateur. On en profite pour modifier le labyrinthe et changer chaque case parcourue en un +. On affiche le labyrinthe modifié à la fin.
Et la sortie :
> ./laby.py
###############
++# # #
#+# ### ##### #
#++++ # #
####+#### #####
#++++# # #
#+######## # #
G+# # #
###############
Pour savoir le temps nécessaire pour noyer complètement les souterrains si l’eau se déplace d’une case par seconde, il suffit de modifier légèrement le code précédent en remplaçant la gestion de la liste des chemins par un compteur.
35: compteur=0
36: afaire={generateur}
37: fait=set()
38:
39: while afaire:
40: temp=set()
41: for s in afaire:
42: temp|=M[s]
43: temp-=fait
44: temp-=afaire
45: fait|=afaire
46: afaire=set(temp)
47: compteur+=1
48:
49: print(compteur-1)
Ligne 37, cette fois, on part du générateur qui fuit (comment le rattraper ?).
Lignes 42 à 45, on reprend le code de la section 1.3, plus rapide que le précédent.
Ligne 48, l’eau a franchi une case supplémentaire.
Et ligne 50, en fait, le compteur tourne une fois de trop à l’étape où tout est noyé, c’est-à-dire quand temp est vide.
Le Docte Roux dispose de 30 secondes pour s’enfuir à bord du TORDUS :
> ./labyeau.py
30
Je vous laisse modifier le code pour trouver que le temps utile à bord du TORDUS pour toucher à tous les boutons est de 16 secondes.
Notez que ce code sans le compteur peut servir dans un jeu comme Frozen Bubble [2] pour rassembler un paquet de bulles de même couleur.
2.2 Le graphe du temps
Les Baleks sont furieux ; ils le sont tout le temps, mais là, encore plus. Le Docte Roux doit donc trouver la ligne du temps la plus longue, la plus éloignée des Baleks pour brouiller sa piste. Il n’est pas question de revenir en arrière, le graphe est donc orienté et n’a pas de cycle. S’il y en a un dans le graphe de la figure 6, par exemple, si on crée un lien de K vers D, le cycle D-G-K crée une boucle et le TORDUS ne s’arrêtera pas.
On doit donc supprimer la gestion des sommets visités de l’algorithme puisqu’on peut passer plusieurs fois par le même, le but étant de trouver le plus long chemin à partir du sommet A.

Fig. 6 : Le graphe du temps
Voici le code :
01: #!/usr/bin/python3
02:
03: M={"A":{"B","C"},
04: "B":{"F","G"},
05: "C":{"D","E"},
06: "D":{"F","G","I"},
07: "E":{"H"},
08: "F":{"J"},
09: "G":{"I","J","K","L"},
10: "H":{"G","K"},
11: "I":set(),
12: "J":{"I"},
13: "K":set(),
14: "L":set()}
15:
16: afaire={"A"}
17: precedent={c:(None,0) for c in M}
18: compteur=0
19:
20: while afaire:
21: compteur+=1
22: temp=set()
23: for s in afaire:
24: for so in M[s]:
25: precedent[so]=(s,compteur)
26: temp|=M[s]
27: afaire=set(temp)
28:
29: compteur-=1
30: for s in precedent:
31: if precedent[s][1]==compteur:
32: break
33: print(compteur,s)
34:
35: pluslong=[]
36: while s!=None:
37: pluslong=[s]+pluslong
38: s=precedent[s][0]
39: print("-".join(pluslong))
Observer ligne 04 — BFG EXTERMINEZ — Du calme Oswim, tu sais bien que le BFG n’est pas de notre monde et que je n’utilise pas d’arme. — que du sommet B part un lien vers F mais pas l’inverse. Certains sommets comme K sont des puits, sans sortie.
Ligne 17, cette fois, le dictionnaire precedent contient, en plus du sommet précédent, le nombre de sommets parcourus, ainsi, precedent["C"]=("A",1). J’aurais pu utiliser deux listes et jongler avec chr et ord.
Remarquez lignes 26 et 27 qu’on a enlevé la gestion des sommets déjà visités à l’algorithme initial.
Les deux paquets finaux de cinq lignes de code recherchent et affichent respectivement la longueur du plus long chemin et ce plus long chemin.
Et la sortie est :
> ./fuite.py
(6, 'I')
A-C-E-H-G-J-I
Si M était une matrice d’adjacence et N=M⁶, le nombre Ni,j en notation matricielle ou N[i][j] en notation pythonique, est le nombre de chemins qui mènent du sommet i au sommet j en 6 étapes exactement. Or la matrice d’adjacence M du graphe est nilpotente d’indice 7, ce qui veut dire que M7 est la matrice nulle mais pas M6. On aurait pu alors calculer les puissancesde M jusqu’à obtenir la matrice nulle mais on n’aurait pas eu aussi facilement le chemin le plus long pour ce graphe.
2.3 Au poste d’observation
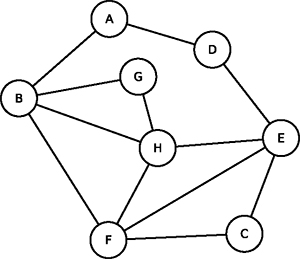
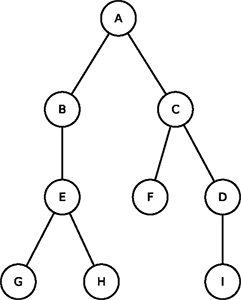
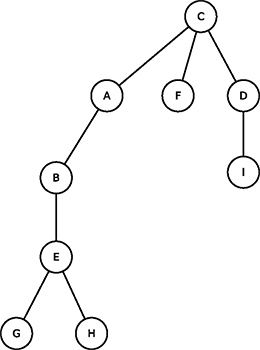
La structure du temps a changé, c’est une espèce de serpillière que le Docte Roux doit maintenant surveiller. Il doit pouvoir intervenir le plus rapidement possible et pour cela, il doit placer le TORDUS en son centre, au point le moins éloigné des extrémités. Il doit pincer la serpillière du temps pour qu’elle soit la plus courte possible quand elle pend : la figure 7 donne la solution, pas la figure 8.
|
Fig. 7 : Le Docte Roux se place en A car la distance maximale aux extrémités est de 3. |
Fig. 8 : Et non en C où la distance maximale est de 4. |
Voici le code :
01: #!/usr/bin/python3
02:
03: M={"A":{"B","C"},
04: "B":{"A","E"},
05: "C":{"A","D","F"},
06: "D":{"C","I"},
07: "E":{"B","G","H"},
08: "F":{"C"},
09: "G":{"E"},
10: "H":{"E"},
11: "I":{"D"}}
12:
13: mini=len(M)
14: for s in M:
15: compteur=-1
16: afaire={s}
17: fait=set()
18: while afaire:
19: temp=set()
20: for so in afaire:
21: temp|=M[so]
22: temp-=fait
23: temp-=afaire
24: fait|=afaire
25: afaire=set(temp)
26: compteur+=1
27: if mini>compteur:
28: smini=s
29: mini=compteur
30:
31: print(smini,mini)
— Ligne 15 EXPLIQUEZ EXPLIQUEZ — Au lieu de corriger à la fin comme précédemment, on commence à la place à −1.
Ligne 27, si on trouve un meilleur sommet, on le remplace et on met à jour la plus courte distance.
code
On obtient :
> ./serpillère.py
('A', 3)
3. L’algorithme de Dijkstra
Ça y est, les Baleks sont sortis, le Docte Roux sait où et quand. Il peut intervenir en temps et en heure grâce à l’algorithme précédent et avec son ami Staik, le Konkarien au cou court, il lui reste à trouver le plus court chemin dans l’espace. Pour cela, il va utiliser l’algorithme de Dijkstra (prononcer [dɛɪkstra] et non [diʒkstra]), au programme de spécialité mathématique de la série ES du baccalauréat. On veut trouver le chemin le plus court de A à H dans le graphe de la figure 9.

Fig. 9 : Le graphe du sujet de bac ES de métropole de juin 2015 qui servira pour la suite.
L’algorithme est simple :
- On choisit le sommet disponible le plus proche du départ, qui devient dorénavant indisponible.
- En partant de ce sommet, on calcule les distances au départ des sommets disponibles qui lui sont connectés, en choisissant la plus courte si nécessaire et on garde une trace du sommet choisi.
- Tant qu’il reste des sommets, on recommence.
Remarques :
- On ne visite pas tous les sommets disponibles à la fois à chaque passe, seulement un par un : le plus proche du départ ou un seul d’entre eux s’ils sont plusieurs.
- L’algorithme fonctionne aussi si le graphe est orienté.
L’algorithme donne, dans la liste distances, les distances de tous les sommets au sommet initial et dans la liste precedent, l’arbre des plus courts chemins, comme d’habitude.
Cette fois, le code présentera la sortie sous la forme du tableau utilisé par les élèves :
01: #!/usr/bin/python3
02:
03: def form(d,i,fait,inf):
04: if d=="@":
05: return " - |"
06: elif d==inf:
07: return " ∞ |"
08: c=str(d)
09: if i not in fait:
10: if len(c)==1:
11: return " "+c+" |"
12: return " "*(3-len(c))+c+"|"
13: return " * |"
14:
15: M=[[0,12,0,14,0,0,0,0],
16: [12,0,0,0,0,9,16,21],
17: [0,0,0,0,13,10,0,0],
18: [14,0,0,0,10,0,0,0],
19: [0,0,13,10,0,16,0,10],
20: [0,9,10,0,16,0,0,11],
21: [0,16,0,0,0,0,0,11],
22: [0,21,0,0,10,11,11,0]]
23:
24: inf=len(M)*(max(max(l) for l in M)+1)
25: precedent=[-1 for s in range(len(M))]
26: distances=[inf for s in range(len(M))]
27: depart=ord("A")-65
28: arrivee=ord("H")-65
29: distances[depart]=0
30: fait=set()
31: afaire=set(range(len(M)))
32:
33: print(" "+" | ".join(chr(i+65) for i in range(len(M)))+" | choix")
34:
35: while afaire:
36: dmin=inf
37: for s in afaire:
38: if dmin>distances[s]:
39: dmin=distances[s]
40: smin=s
41: print("-"*(4*len(M)+7))
42: print("".join(form(distances[i],i,fait,inf) for i in range(len(M)))+" "*3+chr(smin+65))
43: print("".join(form(chr(precedent[i]+65),i,fait,inf) for i in range(len(M)))+" préc.")
44: fait.add(smin)
45: afaire.remove(smin)
46: for s in afaire:
47: if distances[smin]+M[s][smin]<distances[s] and M[s][smin]:
48: distances[s]=distances[smin]+M[s][smin]
49: precedent[s]=smin
50:
51: s=arrivee
52: pluscourt=[s]
53: while s!=depart:
54: s=precedent[s]
55: pluscourt=[s]+pluscourt
56:
57: print(distances[arrivee])
58: print("-".join([chr(i+65) for i in pluscourt]))
La fonction form, ligne 03, retourne une cellule du tableau.
La ligne 04 traite le cas où le sommet n’a pas été visité (le @ a pour valeur ASCII 64=65−1 et A 65), la ligne 06 aussi quand on demande d’afficher une distance infinie.
Ligne 09, on tente un affichage centré sur trois caractères… oui, j’aurais pu utiliser la méthode center de la classe str.
La longueur « infinie » de la ligne 24, inf, est supérieure à la longueur maximum d’un chemin hamiltonien (qui passe par tous les sommets et il en existe ici.)
Ligne 33, on affiche l’en-tête du tableau.
Ligne 37, on recherche le sommet disponible le plus proche de A.
Ligne 41 à 43, on affiche une ligne du tableau qui affiche le meilleur sommet et sa distance à A.
Lignes 46 à 49, on calcule la plus courte distance à A des sommets disponibles. Si M[s][smin]==0, le lien n’existe pas, ce n’est pas une distance nulle.
Il faudra bien sûr adapter le code précédent si le graphe contient plus de vingt-six sommets ou si les distances sont plus grandes.
Et le beau tableau de sortie :
A | B | C | D | E | F | G | H | choix
---------------------------------------
0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | A
- | - | - | - | - | - | - | - | préc.
---------------------------------------
* | 12| ∞ | 14| ∞ | ∞ | ∞ | ∞ | B
- | A | - | A | - | - | - | - | préc.
---------------------------------------
* | * | ∞ | 14| ∞ | 21| 28| 33| D
- | * | - | A | - | B | B | B | préc.
---------------------------------------
* | * | ∞ | * | 24| 21| 28| 33| F
- | * | - | * | D | B | B | B | préc.
---------------------------------------
* | * | 31| * | 24| * | 28| 32| E
- | * | F | * | D | * | B | F | préc.
---------------------------------------
* | * | 31| * | * | * | 28| 32| G
- | * | F | * | * | * | B | F | préc.
---------------------------------------
* | * | 31| * | * | * | * | 32| C
- | * | F | * | * | * | * | F | préc.
---------------------------------------
* | * | * | * | * | * | * | 32| H
- | * | * | * | * | * | * | F | préc.
32
A-B-F-H
Il permet de reconstruire facilement le chemin le plus court :
- De H, on vient de F.
- De la ligne où F a été choisi, on regarde pourquoi, c’est parce qu’on vient de B à la colonne F, parce que le plus court chemin vers F vient de B, de longueur 21.
- Et de B, on vient de A.
D’où le meilleur chemin A-B-F-H de longueur 32.
J’ai codé cet algorithme (sans le sucre syntaxique pythonique ni le tableau) sur ma calculette de poche Ti86 en simili-BASIC [3]. Il faudra adapter le code pour d’autres modèles ou d’autres marques.
Conclusion
Les graphes sont une source inépuisable de problèmes, comme trouver une chaîne hamiltonienne (qui passe par tous les sommets une seule fois chacun) ou eulérienne (qui passe par toutes les arêtes une seule fois chacune), trouver une chaîne hamiltonienne qui maximise une grandeur (problème du voyageur de commerce), déterminer si un graphe possède des cycles ou ses composantes connexes et leur nombre… Certains de ces problèmes se résolvent à l’aide du parcours en largeur, d’autres avec le parcours en profondeur [4] (comme l’ordre de succession au trône britannique). Amusez-vous bien !
Références
[1] Certains problèmes sont inspirés par le site https://www.codingame.com/, je vous laisse trouver lesquels. Ne rêvez pas, les solutions ne sont pas optimales : vous n’aurez pas 100% en recopiant mes codes, il faudra travailler encore un peu.
[2] http://www.frozen-bubble.org/ si vous n’avez pas lu le GLMF de l’été.
[3] Code sur ideone.com http://ideone.com/Iz8cal (i capitale au début et L minuscule à la fin). Il faut supprimer les commentaires, le langage ne sait pas ce que c’est. Par ailleurs, les indices des listes et des matrices commencent à 1.
[4] Colombo T., « De Königsberg à Kalingrad, une petite histoire de graphes », GNU/Linux Magazine n°173, juillet/août 2014, p. 24 à 37.


