

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Le premier novembre 2021, les CVE-2021-42574 et CVE-2021-42694 étaient rendues publiques. Ces deux CVE rendent comptent des limitations de l’utilisation de caractères Unicode dans les identifiants, commentaires et/ou chaînes de caractères littérales de codes sources. Elles sont intéressantes par deux aspects : elles sont relativement agnostiques au langage de programmation sous-jacent, et elles utilisent comme cheval de Troie le rendu fait par certains outils, notamment les forges logicielles en ligne, de certains caractères Unicode.
Que penser à la lecture du code suivant :
Certes, le style de code est un peu disgracieux, mais fonctionnellement, cela ne fait aucun doute : la fonction logadmin affiche you are an admin à l’écran à condition que isAdmin soit positionné à true. Du moins, c’est ainsi que nous comprenons ce que le moteur de rendu de code a (éventuellement) choisi de nous présenter à l’écran. Or, pour faire ce travail de rendu, le moteur a pu avoir à interpréter des séquences Unicode, celles-ci étant autorisées en C11 pour les identifiants et les commentaires de code. Or, ce rendu Unicode se fait sans aucune connaissance du langage sous-jacent...
Car que voit le compilateur ? Juste une séquence d’octets qu’il interprète du premier au dernier, respectant ainsi le sens de lecture utilisé dans de nombreuses langues occidentales, de gauche à droite. Or, si la séquence d’octets ayant donné lieu au rendu observé pour la première ligne de la fonction logadmin est :
Il se trouve que la séquence suivante (caractères Unicode spéciaux identifiés par leurs codepoints) donne lieu au même rendu :
Bigre, la fonction de rendu n’est pas injective, ce qui implique que le code tel que présenté par le moteur de rendu peut ne pas représenter la séquence de code que l’on attend. Et dans le cas présenté plus haut, elles sont fonctionnellement bien différentes.
Cette attaque, nommée Trojan Source et présentée en détail dans un article de recherche de Nicolas Boucher et Ross Anderson est intéressante par le medium utilisé : en utilisant le rendu Unicode fait par, disons, un outil de revu de code tel que celui intégré à GitHub, on peut amener un relecteur de code à accepter un patch qui peut avoir un impact en termes de sécurité sur la base de code.
Depuis la parution de la faille, on peut d’ailleurs observer le rendu suivant dans certains cas :
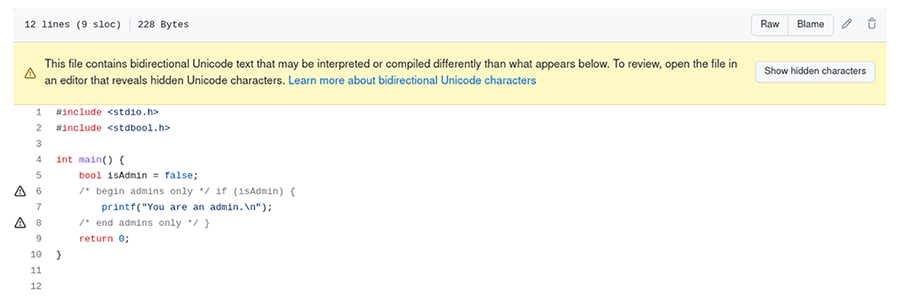
En cliquant sur le lien Show Hidden Characters, on voit à nouveau apparaître les codepoints U+202E, U+2066 et U+2069. Il est temps d’aller faire un tour dans le standard Unicode.
1. Support de code bidirectionnel dans Unicode
Le standard Unicode a pour vocation de pouvoir représenter tout type de texte. Cela est à la fois valable pour les langues occidentales, dont le sens de lecture va généralement de gauche à droite, noté par la suite LTR pour Left To Right, les langues orientales, dont le sens de lecture peut être de droite à gauche (p. ex. hébreux, arabe), noté RTL. L’écriture dite boustrophédon est également possible. Dans le cas de cette dernière, on écrit la première ligne de gauche à droite, la deuxième de droite à gauche, la troisième de gauche à droite, bref à la manière d’un bœuf creusant son sillon.
On peut également avoir besoin de citer un texte écrit en anglais depuis un texte écrit en arabe. Et cette citation peut elle-même contenir le nom d’un personnage hébraïque, ce qui nécessite l’imbrication de plusieurs sens de lectures.
Afin de gérer le cas commun du sens de lecture d’un texte, le standard Unicode associe un sens de lecture à chaque caractère. Ce dernier peut être, entre autres LTR, RTL ou Weak Neutral, ce dernier désignant des caractères comme le signe égal représenté par un = quel que soit le sens de lecture : ils n’ont pas de sens attribué. Dans ce cas, ils peuvent avoir la propriété mirrored qui fera qu’une parenthèse ouvrante sera représentée par un ( si le sens courant du texte est LTR, mais par un ) si le sens courant du texte est RTL.
Afin de supporter l’imbrication de différents sens de lecture, le standard prévoir également des caractères de contrôle, sans représentation visible, mais qui influent sur le sens de lecture. Ces caractères sont décrits dans l’annexe 9 du standard Unicode, nommée Unicode Bidirectional Algorithm, nous nous contenterons de la description des caractères utilisés dans l’exemple de début d’article.
RLO, pour Right to Left Override, force donc le sens de lecture à RTL. Cette modification est valable jusqu’à la fin du paragraphe (au sens Unicode, c.-à-d. jusqu’à la rencontre d’un caractère équivalent à une nouvelle ligne) ou la rencontre d’un caractère de terminaison d’override particulier comme PDF (Pop Directional Formatting, U+202C).
LRI, pour Left to Right isolated, a le comportement inverse à RLO, avec la spécificité d’être isolated. La différence entre isolated et override va au-delà des besoins de l’article.
Enfin, PDI, pour Pop Directional Isolate, agit comme un marqueur de fin commun aux marqueurs de début LRI, RLI et FSI. Il ferme également l’ensemble des marqueurs LRE, RLE, LRO, ou RLO précédemment rencontrés.
L’application de l’algorithme de rendu de texte bidirectionnel sur la séquence d’origine :
donne donc le comportement suivant :
1. Afficher deux caractères neutres dans le sens par défaut, LTR :
2. Changer le sens de lecture à RTL, afficher une accolade fermante qui a la propriété mirrored :
3. Passer au nouveau sens de lecture LTR pour afficher if (isAdmin). On clôt alors le dernier LRI et on repasse donc en RTL.
4. Repasser au sens de lecture LTR pour afficher begin admins only */. La fin de ligne termine l’algorithme.
On note l’astuce d’avoir deux blocs LRI à l’intérieur d’un bloc RLO : cela permet d’avoir deux blocs qui se lisent chacun dans le sens latin, mais se suivent dans le sens arabe !
2. Détection par le compilateur
À la vue de la subtilité du standard Unicode, on peut se demander si autoriser les caractères Unicode dans les caractères est une bonne idée, ou si cela constitue une faiblesse dans le standard. Les compilateurs Clang et GCC proposent, à travers des options différentes, un mécanisme de détection relativement fin qui permet de détecter des commentaires Unicode mal formés.
Pour déterminer si un commentaire est bien formé, on applique l’algorithme Unicode de rendu de texte bidirectionnel en commençant au premier caractère suivant le /* et on l’arrête au caractère précédant le */. S’il reste des caractères d’ouverture de changement de contexte non fermés à ce point, on considère le commentaire comme mal formé, dans le cas contraire il est bien formé, car les caractères de terminaison s’afficheront dans le sens de lecture par défaut et ne pourront pas perturber la lecture. Cela est valable, car les caractères de contrôle du sens de lecture ne sont pas autorisés hors des commentaires et des chaînes de caractère.
Cette approche nécessite le traitement de tous les commentaires rencontrés par le compilateur, ce qui a un impact sur le temps de compilation : ces derniers sont généralement traités par un algorithme rapide qui recherche juste la fin du commentaire. La communauté derrière GCC a choisi d’intégrer ce test comme un avertissement activé par le drapeau -Wbidi-chars. La communauté derrière Clang a quant à elle décidé d’intégrer le test à l’outil d’analyse statique clang-tidy à travers la passe misc-misleading-bidirectional.
Le bandeau d’avertissement qui apparaît dans le rendu GitHub proposé à la Figure 1 s’affiche dès lors qu’un caractère de contrôle BiDi est rencontré, sans traitement spécifique au langage.
3. Bonus : attaques basées sur les identifiants Unicode
Il a été mentionné dans la section 2 que chaque caractère avait un sens de lecture propre, LTR, RTL ou Neutral. Il est possible d’utiliser cette propriété pour construire un code dont le rendu ne représente pas l’intuition que l’on peut avoir du code d’origine. Prenons la séquence formée par les trois caractères suivants :
U+05D0 : א
U+003D : =
U+05D2 : ג
Pour le compilateur, cela désignera l’affectation de U+05D2 dans U+05D0. Or, des deux caractères ont un sens de lecture RTL, et le signe égal est Weak. Le rendu de cette séquence sera donc :
Ce qui, pour un lecteur habitué au sens de lecture LTR, est le contraire du sens espéré.
L’outil clang-tidy est capable de détecter cette catégorie d’identifiant pouvant donner lieu à des représentations déroutantes à travers la passe misc-misleading-identifier.
Impossible de terminer cette section sans mentionner un classique de nos boites mail : les identifiants foo et 𝐟oo sont bien évidemment différents de par leur première lettre, mais clang-tidy vous avertira de la ressemblance entre les glyphes qui les constituent à travers la passe misc-homoglyph. GCC en fera de même avec le drapeau -Whomoglyph.
Conclusion
En combinant Unicode et langages de programmation, on combine la richesse des représentations écrites crées par l’humanité avec la rigueur d’un langage informatique. La représentation visuelle d’un tel mélange peut donner lieu à plusieurs situations déroutantes pour l’œil humain, mais tout à fait valides d’un point de vue informatique !
Références
[0] « Trojan Source: invisible vulnerabilities » : https://trojansource.codes/trojan-source.pdf
[1] « Unicode Bidirectional Algorithm » : http://www.unicode.org/reports/tr9


