

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Il existe deux principales méthodes pour trier rapidement des exécutables suspects : les lancer dans une sandbox (analyse dynamique) et l'analyse... statique. Lors de la première partie, nous avons énuméré et discuté de certaines caractéristiques du format Portable Executable (PE) pour déceler des anomalies parfois utilisées par les auteurs de malwares. Nous proposons dans cette deuxième partie de détailler la structure PE, tout en continuant à étudier comment elle est utilisée par le code malveillant.
1. Les prérequis d'un format « exécutable »
1.1 Fichier tu étais, processus tu deviendras !
Pour rappel, les fichiers au format PE décrivent un exécutable (.exe) pour la plateforme Windows, c'est-à-dire un format de fichier dont le contenu (découpé en sections) est destiné à devenir un processus. Il y a généralement une section contenant le code (nommée souvent « .text »), une section pour les données constantes (« .rdata »), une pour les ressources graphiques entre autres (« .rsrc »), etc. Les .dll utilisent aussi le format d'une manière très similaire.
Dans le fichier PE, les adresses sont dites « physiques » et en mémoire (celle du futur processus), elles sont « virtuelles » et relatives à une adresse de base : Relative Virtual Address. Les systèmes d'exploitation utilisent en effet un adressage virtuel : chaque processus croit disposer d'un adressage qui lui est propre.
Voici pour rappel le premier exemple de sections donné dans la 1re partie :
Les colonnes psize / paddr concernent les sections physiques sur disque, et vsize / vaddr leurs versions en mémoire. La colonne des caractéristiques liste les propriétés des sections en mémoire : « execute », « write » ou « read »...
1.2 Windows et ses bibliothèques partagées
Pour communiquer via le réseau, manipuler des fenêtres ou des fichiers, les fonctions nécessaires sont regroupées par le système d'exploitation sous forme de bibliothèques, le plus souvent chargées dynamiquement (.dll sous Windows, .so sous UNIX). Par exemple, la fonction FindFirstFileA, permettant de connaître le premier fichier dans un répertoire, est située dans la bibliothèque KERNEL32.DLL. Il faut donc charger cette DLL en mémoire afin que le code principal (.exe) puisse utiliser l'implémentation de cette fonction.
Par ailleurs, la partie « imports » du format PE liste les fonctions externes utilisées et où les trouver (dans quel fichier DLL). Au contraire, la partie « exports » liste des fonctions offertes (implémentées) par une DLL. Le système doit aussi vérifier que le fichier est compatible avec l'architecture (x86, x64, ARM), la version du système, etc.
Le format PE est donc conçu pour permettre au « loader » Windows de réaliser ces actions, voyons cela en détail.
2. Structure du format Windows PE
Le format se décompose en 3 parties principales : plusieurs entêtes, une table des sections et les sections elles-mêmes.
Ce poster de Ero Carrera Ventura [pe_pdf] donne les structures de données utilisées par le loader de Windows, dont les limites ont été âprement testées par Ange Albertini [corkami_pe]. Nous nous focaliserons sur l'essentiel.
Voici également la structure principale telle que donnée par l'outil PE Bear [pe_bear].
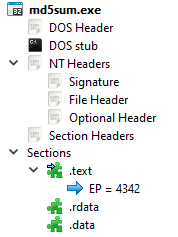
3. Entêtes
3.1 DOS (préhistoire)
L'entête MZ ou DOS ci-dessous est historique, d'une taille fixe de 64 octets et pointe vers l'entête PE, ici à l'offset 0xd0 (valable à la fin de cette partie, sur 32 bits Intel) :
Ensuite, on trouve du code Intel 16 bits affichant le texte ci-dessous, c'est le DOS stub, au cas où vous exécuteriez ce fichier dans une fenêtre DOS.
3.2 Rich et File header (époque moderne)
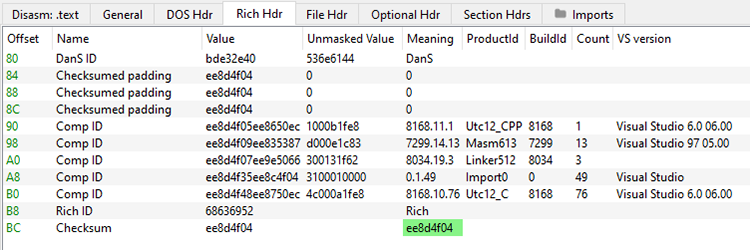
À la suite, on peut trouver l'entête « Rich » [rich], non documentée par Microsoft. Cette partie n'existe que si le binaire a été construit par Visual Studio et elle contient des détails sur les outils ayant servi à sa fabrication. Ces données se reconnaissent grâce au mot-clé « Rich » et sont codées avec une clé (xor) se situant juste après, ici 0x044f8dee. Ces données permettent de connaître la chaîne de compilation et donc reconnaître 2 malwares de la même origine, par exemple. Cela peut également servir à tromper l'analyste [devils].
Voici les données décodées par PE Bear :
Juste après, ci-dessous, l'entête File (aussi appelé NT header) commence par l'identifiant 50450000 (« PE ») sur 4 octets. Puis une première partie (image_file_header) de 20 octets, où l'on trouve notamment : l'architecture cible (x86 ou x64), le nombre de sections (ici 3), un horodatage (a7316436, 1er décembre 1998). On trouve l'adresse de cet entête (0xd0) à la fin de l'entête DOS.
Voici en clair :
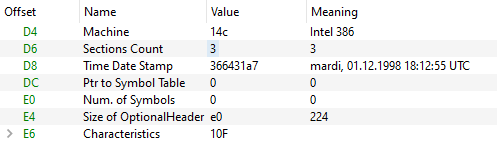
On peut vérifier en ligne que Visual Studio 6.0 date de 1998, ce qui est cohérent avec l'horodatage de l'entête PE ci-dessus. Ces informations ne semblent donc pas forgées par l'attaquant.
3.3 Optional header
Ensuite vient image_optional_header, qui diffère légèrement pour les PE 32 et 64 bits. Pour les .exe, cette partie est obligatoire et contient des informations très importantes : à commencer par EntryPoint et ImageBase. Pour rappel, la deuxième est l'adresse de base en mémoire du processus, et la première le déplacement (adresse virtuelle relative – RVA – à cette base) où le processeur exécutera la première instruction du PE.
On y trouve aussi toutes les valeurs nécessaires à l'initialisation des données du processus : pile, tas, taille du code et des données, vérification de la version de l'OS et de l'architecture, etc.
À la fin de l'optional_header, se trouve la table à 16 entrées dite DataDirectory, où l'interprétation des 2 valeurs (VirtualAddress, Size) dépend de l'indice dans cette table.
Ci-dessous, les 2 seules entrées décodées : en case 1 (VA=0x98d4, size=0x28), on trouve comment localiser la table des imports et en case 12 (0x9000, 0xc4), la table des adresses des imports, on y reviendra.
Voici la signification des entrées de 0 à 15 utilisées, et entre parenthèses, les sections associées le cas échéant :
- 0 = export_table (.edata) ;
- 1 = import_table (.idata) ;
- 2 = resources_table (.rsrc) ;
- 3 = exceptions_table (.pdata) ;
- 4 = certificate_table ;
- 5 = base_relocation_table (.reloc) ;
- 6 = debug_table (.debug) ;
- 8 = global_pointer ;
- 9 = threat_local_storage (.tls) ;
- 10 = load_configuration_dir ;
- 11 = bound_import_dir ;
- 12 = import_address_table ;
- 13 = delay_load_import_desc ;
- 14 = CLR_runtine_desc (.cormeta).
Nous allons nous contenter par la suite de détailler comment sont stockés les noms des DLL et les fonctions importées associées. Pour plus d'informations, voir la documentation officielle de Microsoft [pe].
4. Entêtes des sections
Après la table Data Directory, on trouve les entêtes des sections étudiées dans la première partie sur plusieurs exemples. Mais voici tout de même à quoi ressemblent les données brutes sur disque :
- Voici les entêtes pour les 3 premières sections :
- Voici la structure de chaque entête, une pour chaque section (ici 3) :
|
Offset |
Type |
Nom |
Contenu |
|
0 |
UTF-8 |
Name (zero terminated) |
.text par exemple |
|
8 |
ulong |
VirtualSize |
Taille en mémoire (vsize) |
|
12 |
ulong |
VirtualAddress |
Adresse en mémoire (vaddr) |
|
16 |
ulong |
SizeOfRawData |
Taille dans le fichier (psize) |
|
20 |
ulong |
PointerToRawData |
Adresse dans le fichier (paddr) |
|
... |
|
|
|
|
36 |
ulong |
Characteristics |
Propriétés de la section : code, r, w, x... |
Nous avons déjà expliqué la signification de ces valeurs sur l'exemple rappelé en début de cet article.
5. Import des fonctions
Voyons comment le loader importe les fonctions (situées dans différentes DLL Windows).
On utilise la table des imports, dont l'adresse virtuelle (VA) est à la case 1 de Data Directory. Essentiellement, les entrées de cette table comportent 3 champs qui nous intéressent :
- OriginalFirstThunk, une VA (16 bits LE, offset 0) vers la table ILT (import lookup table) ;
- Name, une VA vers le nom de la DLL, terminée par un 0 (16 bits, offset 6) ;
- FirstThunk, une VA (16 bits, offset 8) vers la table IAT (import address table) identique à ILT sur disque.
5.1 Trouver le nom des DLL...
Cherchons donc, pour notre exemple, le nom de la 1re DLL.
Ci-dessus, la table des imports est à l'adresse virtuelle 0x98d4. Dans la colonne vaddr, cette adresse est dans la section « .rdata », soit 0x8da à partir du début de cette section en mémoire. Donc pour trouver notre table sur disque, il faut ajouter cette valeur à l'adresse physique de la section, colonne paddr. La table des imports est dans le fichier PE, à l'offset 0x9000 (paddr) + 0x8da. La démarche est identique pour toutes les adresses virtuelles (VA). Ici, le fait que paddr et vaddr soient identiques est un cas particulier.
Ci-dessus, nous avons OriginalFirstThunk = 0x98fc, Name = 0x99e2 et FirstThunk = 0x9000. Voici ci-dessous le contenu à l'adresse 0x99e2 :
5.2 ... Et des fonctions importées
FirstThunk désigne IAT, comme à la case 12 dans Data Directory :
et OriginalFirstThunk désigne ILT. Elles sont bien identiques sur le disque.
Dans les tables ci-dessus, chaque entrée (32 bits pour x86, 64 bits pour x64) comme 0x9b36, 0x99d0 pointe un nom de la fonction dans la DLL pointée par Name. Cette liste se termine par une entrée à zéro. 0x9b36 contient le nom « WideCharToMultiByte », fonction disponible dans KERNEL32.DLL :
Dernière précision, si pour une entrée de la IAT ou ILT, le bit de poids fort est à 1 (31 ou 63e), alors la fonction est importée par ordinal (identifiant numérique unique pour la DLL) et non par nom.
Par expérience, un exécutable avec un très grand nombre de fonctions importées est sans doute un interpréteur, comme Delphi, AutoIt ou PyInstaller. Comme les imports d'un PE (ou d'un ELF) en disent beaucoup sur les fonctions internes d'un malware, beaucoup se débrouillent pour avoir une IAT ou ILT invalides et la reconstruisent dynamiquement à l'exécution.
Pour finir, voici 2 exécutables compressés avec 7-zip SFX, j'ai ajouté une colonne avec le md5 pour chaque section :
Que remarquez-vous ? Eh oui, le contenu des 5 sections est identique, car leurs hachés sont identiques aussi, seul l'overlay diffère. Pour conclure que 2 zones contiennent les mêmes données, seul un hash (SHA-256 de préférence) doit être utilisé, pas uniquement la taille.
Si vous souhaitez manipuler les PE, la bibliothèque [LIEF] est indispensable. Elle permet même de modifier les exécutables d'autres systèmes comme GNU/Linux ou macOS.
6. Au-delà du format PE
6.1 Interprétation du code
D'autres outils utilisent une analyse du graphe de contrôle pour déduire les fonctionnalités internes ou des similarités entre malwares, de la réutilisation de code. On peut citer [intezer] et [capa], ce dernier permettant à la communauté d'écrire elle-même des signatures détectant les portions de code probablement malveillantes.
6.2 Lire le code
Enfin, on peut bien sûr lire le code avec un désassembleur ou un décompilateur selon le langage original : avec IDA Free ou Ghidra pour l'assembleur, le C/C++, [dnSpy] pour le .NET. Certains exécutables embarquent un interpréteur, comme Delphi, AutoIt ou Python, il faut alors utiliser les outils appropriés comme [idr] pour le 1er, [autoit-ripper] pour le 2e et [uncompyle6] [pyinstxtractor] pour le 3e, avant de pouvoir analyser le code original. Les binaires issus des langages Rust et Go sont plus difficiles à analyser, mais IDA depuis la 7.6 a marqué un réel progrès dans leur analyse.
Conclusion
L'analyse statique rapide ou triage des exécutables PE peut se limiter à répondre à la question : « ce fichier est-il malveillant ou non ? », simplement en décelant l'usage de protections retardant l'analyse ou de fonctionnalités destinées à cacher. Pour cela, l'approche proposée se résume ainsi : utiliser les hachés, pour le fichier et les sections, l'entropie, les DLL et fonctions importées. Les différents horodatages sont-ils cohérents ? Le nombre et les propriétés des sections sont-ils hors normes, existe-t-il un overlay ? Que nous apprend la recherche de signatures ? Le fichier est-il signé et par qui l'est-il ?
Remerciements
Merci à Laurent Cheylus et au rédacteur en chef pour leurs conseils.
Références
[pe_pdf] Portable Executable Format, Ero Carrera Ventura, déc. 2005,
http://www.openrce.org/reference_library/files/reference/PE%20Format.pdf
[corkami_pe] https://github.com/corkami/pocs/tree/master/PE?s=09
[pe_bear] PE Bear, par Hasherezade, https://hshrzd.wordpress.com/pe-bear/
[rich] Rich Headers, https://www.virusbulletin.com/virusbulletin/2020/01/vb2019-paper-rich-headers-leveraging-mysterious-artifact-pe-format/
[devils] https://securelist.com/the-devils-in-the-rich-header/84348/?s=09
[pe] PE format, Microsoft, https://docs.microsoft.com/en-us/windows/win32/debug/pe-format
[LIEF] Library to Instrument Executable Formats, QuarksLab, https://lief-project.github.io/
[inside_pe] Matt Pietrek, Microsoft, 2002,
https://docs.microsoft.com/en-us/archive/msdn-magazine/2002/february/inside-windows-win32-portable-executable-file-format-in-detail et
https://docs.microsoft.com/en-us/archive/msdn-magazine/2002/march/inside-windows-an-in-depth-look-into-the-win32-portable-executable-file-format-part-2
[intezer] brevet https://patents.justia.com/patent/10824722
[capa] https://github.com/mandiant/capa
[dnSpy] https://github.com/dnSpy/dnSpy
[idr] https://github.com/crypto2011/IDR
[autoit-ripper] https://github.com/nazywam/AutoIt-Ripper
[uncompyle6] https://pypi.org/project/uncompyle6/
[pyinstxtractor] https://github.com/extremecoders-re/pyinstxtractor


