

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
À l’aide de différents services publics, il est possible de manipuler des données diversifiées en volumes conséquents, sans en assurer ni la collecte ni le rafraîchissement, et construire des services innovants
Bien que le concept nous apparaisse récent, le terme Big Data, ou Mégadonnées, aurait été utilisé pour la première fois en 1997. Dès les prémisses de la révolution Internet, on pressent déjà le foisonnement vertigineux des données qui rythmera le quotidien du XXIe siècle. Afin d’en appréhender les enjeux, un groupe de recherche du META Group, devenu ensuite Gartner, définit en 2001 les trois axes fondamentaux de ce que serait le Big Data : Volume, Variété, Vélocité ; ce que l’on appelle de façon mnémotechnique les fameux « 3V ». Plutôt qu’un véritable outil, les 3V dressent un constat. Premièrement, les ensembles de données dépassent largement en taille ceux que nous avions l’habitude de manipuler jusqu’alors. Par exemple, lorsque Google lance son moteur de recherche à la fin des années 90, l’entreprise fait face à un problème potentiellement infini : indexer l’ensemble des sites présents sur le réseau mondial. En effet, entre 1995 et 2000, le nombre de sites sur Internet a été multiplié par plus de sept cents, passant de 23500 à plus de 17 millions. En 2021, on recense plus de 1,88 milliard de sites (source : https://www.internetlivestats.com/total-number-of-websites/). De plus, au-delà du nombre de sites à la croissance exponentielle, il nous faut également mettre à jour cet index très régulièrement ; on estime le rythme de création de sites web à deux par seconde. C’est ce que souligne la nécessité de vélocité : les données sont créées, mises à jour, voire obsolètes à une fréquence largement supérieure à la capacité de traitement humain, voire d’un ordinateur standard. Enfin, quand bien même nous ne connaissons pas le fonctionnement de l’algorithme d’indexation des sites de Google, nous pouvons supposer qu’il utilise des données très différentes : les adresses IP des noms de domaine de chacun des sites, le contenu textuel, les références explicites d’un site à un autre, etc. Il s’agit d’une combinaison de données structurées, c'est-à-dire que l’on peut représenter dans un format tabulaire, et de données peu, voire pas structurées (du texte libre, des logs machines, etc.), ce qui illustre la notion de variété.
Avec cet exemple, on commence à comprendre le changement de paradigme qu’offre le Big Data. De prime abord, pour résoudre un problème comme la conception d’un algorithme d’indexation des sites web, on pourrait chercher à définir un modèle analytique s’appuyant sur des données richement descriptives, par exemple un score de pertinence en fonction d’un mot clé. La difficulté réside précisément dans la capacité à calculer ces valeurs, et à s’assurer de leur pertinence ! Une autre approche consiste à agréger de nombreux ensembles de données hétérogènes, qui ont unitairement un faible contenu informationnel, mais dont l’association répond au problème posé. Au fil du temps, et à la faveur des inspirations marketing, les 3V originaux se sont vus associés à 3 autres « V » : Véracité, Valeur et Visualisation. Que le lecteur se rassure, nous ne chercherons pas à singer l’introduction du personnage de « V pour Vendetta », et nous nous arrêterons à « 6V ». Il est toutefois intéressant de noter que ces 3 nouveaux « V », surtout les deux derniers, ne sont pas des verrous technologiques, mais plutôt des finalités. On comprend alors que pour générer de la valeur à partir des données, disposer d’un inventaire conséquent est une condition nécessaire. Il s’agit bien évidemment d’une tâche ardue qui nécessite une curation rigoureuse et bien souvent rébarbative, par rapport à des cas d’usage de modélisation ou de visualisation.
1. Les données ouvertes
Ce travail de curation, nombre d’administrations françaises sont contraintes de le faire pour mener à bien leurs missions. Pour unifier les pratiques au sein des administrations et faciliter la montée en compétences nécessaires, l'État a créé en 2011 Etalab. Il s’agit d’une administration publique française au double objectif d’amélioration du service public et de renforcement de l'action publique, et ce, grâce à la donnée. Il est apparu évident, notamment pour nourrir le second objectif, qu’il était nécessaire de mettre à disposition un maximum de données publiques sur une plateforme accessible à tous. C’est pourquoi, depuis le mois de décembre 2011, Etalab met en ligne et maintient la plateforme nationale des données ouvertes data.gouv.fr.
1.1 Un portail de « mégadonnées »
Le site data.gouv.fr est un portail public où est recensé l’ensemble des données disponibles en accès libre. Il a d’ailleurs bénéficié d’une récente refonte graphique, et il est désormais possible d’accéder au catalogue par des vues thématiques : par exemple, les données relatives à la crise sanitaire, à l’emploi ou encore à l’urbanisme. De plus, la plateforme propose d’héberger des réutilisations des données, c'est-à-dire des cas d’utilisation précis de données, en publiant une page explicative, avec liens de référence. Les chiffres clés de son contenu sont résumés dans le tableau de la figure 1.
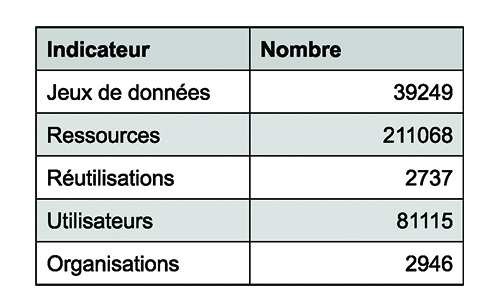
Sur la plateforme, un jeu de données est un cas d’usage, comme « baromètre des résultats de l’action publique ». Une ressource, toujours associée à un jeu de données, est une vue de ce cas d’usage : le baromètre des résultats de l’action publique a par exemple vingt-deux ressources, qui sont les différentes mailles d'observation des indicateurs : niveau national, niveau régional ou départemental, vue synthétique dans le temps ou détail complet, etc. Ainsi, une ressource est un fichier qui contient effectivement des données, et qui illustre un jeu de données dans une configuration particulière. Dans le cas d’un jeu de données où le rafraîchissement est annuel, il peut y avoir autant de ressources que d’années disponibles dans l’historique. Enfin, il se peut qu’une ressource permette d’avoir la même donnée, mais sous un format différent (tableur ou CSV). Avec près de quarante mille jeux de données, qui comportent chacun en moyenne plus de cinq ressources différentes, on peut dire que la plateforme propose un volume et une variété de données importants.
D’autre part, un utilisateur est en fait un compte créé sur la plateforme. Il est cependant possible de télécharger des données depuis l’interface web sans avoir à créer de compte ; il s’agit donc d’une sous-estimation du nombre de consommateurs potentiels, tout de même supérieur à quatre-vingt mille. Par ailleurs, il peut être pertinent de rassembler des utilisateurs entre eux, par exemple lorsqu’ils font partie de la même entité productrice de données, ou d’un collectif d’action publique ; c’est le rôle des organisations.
La plateforme traduit en outre une activité importante. Par exemple, une organisation très active sur la plateforme est celle du ministère de l’Intérieur. Elle comporte plus d’une trentaine de membres, et est productrice de plus de six cents jeux de données, parmi lesquels : le nombre de demandes d’asile, les accès à la nationalité française, la délivrance de visas, etc. On observe sur la figure 2 l’évolution temporelle des mises à jour de jeux de données que cette organisation produit.
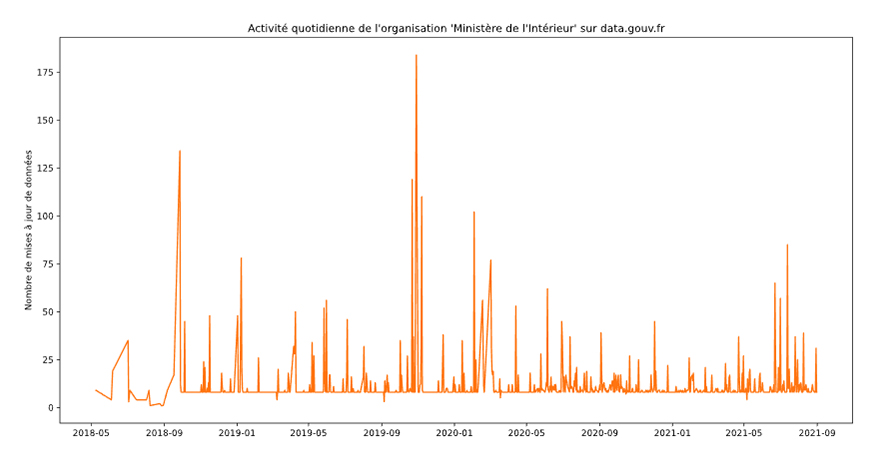
On constate une valeur minimale presque systématiquement de huit et une valeur moyenne de onze mises à jour quotidiennes : nul doute que le ministère de l’Intérieur a automatisé la publication de mises à jour pour les données pertinentes, et nous affranchit donc d’un travail de curation conséquent !
Enfin, il est important de noter qu’il existe plusieurs façons d’accéder à la donnée présente sur la plateforme. Premièrement, directement via l’interface web, on peut télécharger la ressource qui nous intéresse, en cliquant sur le bouton idoine. Cela nous permet de naviguer dans le catalogue et de nous rendre compte de la mise en forme des jeux de données. En revanche, cette méthode est sous-optimale s’il nous faut télécharger quotidiennement un jeu de données. C’est pourquoi la plateforme expose une API, avec une documentation détaillée d’utilisation, et qui permet d'interagir de façon programmatique avec la donnée et d’automatiser les traitements d’information. La mise à disposition de ces outils favorise la réutilisation des ensembles de données, et permet l’émergence de belles initiatives.
1.2 Un exemple de réutilisation : EurosForDocs
Le site recense plus de deux mille sept cents réutilisations, qui permettent d’illustrer l’énorme potentiel des données mises à disposition. Par exemple, dans l’incarnation exemplaire de renforcement de l’action publique, l’association EurosForDocs développe et maintient des tableaux de bord recensant les liens d’intérêt financier entre industriels et acteurs de la santé (professionnels, académies, établissements de santé, etc.). En effet, depuis fin 2001, les industriels sont tenus de renseigner dans une base de données publique, la base Transparence - Santé, le type et le montant de compensations qu’ils versent à des acteurs du monde de la santé, dans le but principal de développer la confiance dans les décisions prises en matière sanitaire. Cependant, « transparence » ne veut pas forcément dire « accessibilité ». En effet, EurosForDocs est parti du constat que le site web exposant la base de données ne permet pas simplement d’extraire des déclarations des informations pertinentes : compensations totales reçues par un professionnel, compensations totales versées par un industriel, etc. Pire, ainsi présenté, il est difficile de déceler une anomalie ou une déclaration erronée. Afin de donner un maximum de visibilité sur ces sujets, dont l’importance se renouvelle avec le contexte sanitaire lié à la pandémie du coronavirus, l’association a mis en place https://www.eurosfordocs.fr/ qui expose des tableaux de bord lisibles, réactifs et riches. Les données sont issues d’une agrégation et d’un traitement de trois sources : la base Transparence - Santé, la base des professionnels de santé, et un tableur collaboratif qui permet d’associer en groupes des entreprises qui représentent le même industriel. Les deux premières sources de données sont bien entendu disponibles sur data.gouv.fr.
De plus, et dans la démarche de transparence, l’intégralité du code est disponible sur un dépôt GitLab : cela comprend le code nécessaire à la récupération des données, mais surtout les opérations de croisement et de nettoyage, ce qui permet à chacun d’auditer la génération de ces tableaux de bord. Cerise sur le gâteau, l’outil de visualisation utilisé, Metabase, est également un logiciel libre, et le dépôt GitLab comprend le code nécessaire pour lancer tous les services qui permettent au site d’exister : une contribution bénévole de grande qualité et ouverte à tous ! Si toutefois le lecteur ne souhaite pas rentrer dans les détails du code, il est possible de consulter facilement une vue d’ensemble de la base Transparence - Santé, illustrée sur la figure 3. Au mois d’août 2021 et depuis 2012, on constate que presque huit milliards d’euros ont été versés par les industriels aux acteurs de la santé, avec une forte probabilité pour que cette estimation soit en dessous de la réalité. Notons enfin que cette initiative prend de l’ampleur, avec un passage à l’échelle européenne, et ce, depuis le mois de juin 2021.

Dans ce cas de figure, il est intéressant de télécharger l’intégralité de la base de données à chaque fois qu’on souhaite mettre à jour les tableaux de bord. En effet, il se peut que la base Transparence - Santé soit corrigée a posteriori, et il nous faut pouvoir prendre en compte ces modifications, qui peuvent concerner l’entièreté de l’historique de la base. Pour autant, c’est un fonctionnement coûteux : l’ensemble des données compressé avoisine le gigaoctet, et presque six gigaoctets une fois décompressé. C’est un volume qui doit être téléchargé entièrement lors de chaque mise à jour. C’est toutefois une contrainte acceptable, dans la mesure où les données sont mises à jour au minimum chaque semestre. Si la fréquence de rafraîchissement était plus élevée, et le jeu de données plus important, il nous faudrait disposer d’un outil qui permette d’accéder à la fraction de données qui nous intéresse, par exemple, celle qui a été mise à jour ou les nouvelles entrées. C’est pour répondre à ce besoin que Etalab poursuit son effort pour pousser à une utilisation massive des données publiques.
2. Faciliter l’accès programmatique aux données ouvertes
La plateforme data.gouv.fr couvre les aspects de volume et de variété de la donnée. Cependant, son fonctionnement impose le plus souvent de télécharger l’entièreté de la ressource pour ensuite manipuler la donnée. Il existe par exemple un jeu de données produit par le ministère de l’Économie, qui consolide les données de comptabilité générale de l’État, et ce, depuis 2012. Si nous souhaitons travailler sur ces données uniquement pour l’année 2020, il nous faut tout de même télécharger toute l’archive et appliquer un filtrage temporel ensuite. De plus, certaines données disposent de mises à jour quotidiennes. Selon l’utilisation de la plateforme, il faudrait soit écraser la ressource existante et la remplacer avec l’ajout de données, ce qui contraint le consommateur à télécharger tout l’historique, soit ajouter une ressource par jour, ce qui devient rapidement fastidieux. Pour s’adapter à ce besoin de vélocité, il nous faut disposer d’un service qui permette d’accéder à la donnée, en prenant en compte des paramètres, par exemple une fenêtre temporelle, voire de calculer des agrégations sur la donnée brute et de nous en fournir le résultat.
2.1 Les interfaces de programmation applicative
Ce fonctionnement est précisément celui d’une API (Application Programming Interface). Ces dernières répondent au besoin d’abstraction de représentation de la donnée lorsque deux applications communiquent. Par exemple, data.gouv.fr expose une API avec de multiples informations. Nous l’avons utilisée précédemment pour calculer le nombre quotidien de mises à jour de jeux de données faites par une organisation. Du côté de la plateforme, les données d’activité sont stockées dans un certain format, avec une certaine technologie, par exemple, une représentation tabulaire des données dans un serveur PostgresSQL. La plateforme peut également proposer d’exposer, via son API, l’ensemble des activités d’un même type, disons la mise un jour d’un dataset, pour une organisation donnée. Pour invoquer ce service, le consommateur doit fournir des paramètres dans un format attendu, et le producteur de données responsable de l’API s’engage à fournir un résultat sous un format connu : c’est une sorte de contrat entre services client (consommateur de la donnée) et serveur (responsable de la donnée). Dans notre exemple, ce sera probablement traduit en requête SQL et des clauses WHERE, mais c’est entièrement transparent pour le consommateur. C’est d’ailleurs tout l’intérêt ; si les technologies devaient changer du côté du serveur, mais que l’API ne change pas, le consommateur pourra toujours utiliser le service, sans avoir à faire évoluer ses traitements. C’est ce paradigme qui permet de faciliter la manipulation programmatique des données. Il existe par ailleurs des standards robustes pour les API web, le plus courant étant REST, qui aide à la conception de ce genre de services.
Il est donc logique qu’en plus d’exposer des jeux de données, Etalab cherche aussi à exposer des API, et ait motivé le lancement d’une nouvelle plateforme dédiée en 2016 : https://api.gouv.fr/. La plateforme étant plus récente, elle dispose de moins de cas d’usage que data.gouv.fr ; elle dénombre en août 2021 une centaine d’API disponibles. Toutefois, l’un des intérêts de ce type de service est qu’il permet un contrôle plus fin de l’accès à la donnée. Ainsi, il est possible d’exposer des API publiques, mais aussi des API restreintes à des entités particulières. Un deuxième avantage réside dans le fait qu’il est également possible d’exposer des traitements sur la donnée, par exemple des fonctionnalités de recherche.
2.2 Les adresses
Une des API publiques particulièrement intéressantes est celle des adresses. Elle permet de fournir la correspondance entre une adresse postale et ses coordonnées GPS. Par exemple, si je souhaite connaître les coordonnées spatiales de l’adresse des Éditions Diamond, alors, en me référant à la documentation de l’API, il me suffit d’exécuter la commande suivante dans un terminal :
Nous parlions de contrat précédemment : dans ce cas précis, il nous faut respecter l’URL de l’API, en l’occurrence https://api-adresse.data.gouv.fr, suivi du traitement que l’on souhaite, c.-à-d. la conversion d’une adresse en coordonnées qui s’appelle ici search et enfin le format de la requête, un préfixe ?q= suivi de la chaîne de caractère, qui constitue ma requête où les espaces sont remplacés par le signe +. Cela peut paraître contraignant, mais c’est le protocole de fonctionnement de l’API. En revanche, si le client respecte ce protocole, il se voit assuré de recevoir une réponse de la part du serveur avec un format défini. En l’occurrence, il s’agit du format GeoJSON qui est une adaptation du format JSON aux données géographiques. Il ressemble au texte suivant (par souci de concision, l’entrée properties a été réduite, et nous laissons le soin au lecteur d’en découvrir la teneur) :
Nous savons donc que le ou les résultats de la requête se trouvent dans l’entrée features, qui contient une liste d’objets, et que ceux-ci disposent chacun de l’entrée geometry (propre au standard GeoJSON) qui elle-même contient une entrée coordinates qui donne un itérable de deux valeurs flottantes, respectivement la longitude et la latitude du point dans le système de coordonnées EPSG:4326. Cela semble fastidieux à expliquer littéralement, mais la rigidité de ce format d’échange est précisément ce qui permet d’automatiser ce traitement pour un grand nombre d'adresses. D’ailleurs, l’API expose le service /search/csv/ qui permet le traitement d’adresses présentes dans un fichier CSV, avec un fichier d'exemple.
L’API expose un service supplémentaire : la correspondance entre des coordonnées et une adresse postale. Pour l’utiliser, rien de plus simple :
Notez les différences avec le service search : les deux paramètres sont nommés et se suivent avec le caractère &. Comme le précise la documentation, le format de retour est exactement le même que pour le search, et l’information que l’on cherche se trouve non pas dans l’entrée geometry, mais dans l’entrée properties.
Ainsi grâce à cette API, on peut facilement jongler entre adresse postale et coordonnées GPS, sans jamais avoir à télécharger l’intégralité des données de la base sous-jacente ni à se soucier de l’algorithme nécessaire à la correspondance. Nous pouvons donc intégrer ce service dans un produit, sans avoir à maintenir son fonctionnement.
Tâchons désormais de construire un service à partir des données disponibles via une de ces API.
3. Représentation de disponibilité de vélos
Afin d’illustrer la facilité de réutilisation des données disponibles, nous allons détailler la mise en place d’un service relativement simple : l’exposition d’une carte interactive qui donne la disponibilité des vélos aux stations de vélopartage à Toulouse. La mise en place de cette solution sera sans coût et reposera sur des logiciels libres, avec un code ouvert.
3.1 Données brutes et mise en forme
Parmi l’ensemble des données publiques disponibles en ligne, les données relatives au transport en commun sont de premier intérêt. Elles sont indispensables au développement de la mobilité urbaine, dont le fonctionnement tend à agréger plusieurs modes de transport. On peut trouver bon nombre de ces données sur une autre plateforme dédiée, transport.data.gouv.fr. Celle-ci expose tout à la fois des jeux de données et des API, et il est fort probable que ces dernières seront un jour fusionnées aux solutions vues précédemment.
Ce qui est particulièrement intéressant avec ce type de données, c’est que leur exploitation se fait en quasi temps réel. En effet, lorsque l’on cherche la disponibilité de vélos en libre-service, c’est souvent lorsque l’on souhaite en utiliser un dans l’instant. De plus, pour faciliter l’exposition et la consommation de ces informations, les acteurs de la mobilité ont décidé d’utiliser un standard propre. Dans le cas des vélos en libre-service, on parle de GBFS (General Bikeshare Feed Specification). Ce standard est relativement simple à comprendre, car lisible, et repose également sur une structure en JSON.
Sur la page du service exposé, disponible ici https://transport.data.gouv.fr/datasets/velos-libre-service-velotoulouse-disponibilite-en-temps-reel/, on constate que l’information est proposée dans deux sources ; une sur le statut de la station, c.-à-d. le nombre de vélos dont elle dispose, et une sur les informations de la station, c’est-à-dire sa position géographique, son nom, etc. Le lien entre les deux se fait via un identifiant unique. Il est relativement simple de récupérer ces informations en Python, via la librairie Requests, utilisée pour interagir avec des API web, et de les combiner, par exemple en utilisant la librairie Pandas en joignant les dataframes.
Pour représenter ces informations sur une carte, on propose d’utiliser la librairie Folium, sorte de surcouche à Leaflet.js pour Python, qui permet très simplement de représenter un fond de carte, et de lui ajouter des informations, le tout dans un fichier HTML interactif !
Le code décrit ici est disponible dans le dépôt GitLab : https://gitlab.com/constant.bridon1/carte_velos, dans le fichier generate_map.py :
L’exécution de ce fichier produit une carte au format HTML, dont une représentation est disponible en figure 4.

Comme on le voit, dès que ce fichier Python sera exécuté, il récupérera les informations disponibles à ce moment-là et créera une carte. On se propose de générer cette carte régulièrement, et de l’exposer sur Internet.
3.2 Automatisation et mise en forme du déploiement
Il nous reste deux fonctionnalités à produire pour notre cas d’usage : l’automatisation du traitement et l’exposition du résultat sur Internet. Nous allons tirer profit de deux fonctionnalités clés de GitLab : les pages et les schedules.
Pages permet d’exposer un site web statique hébergé par GitLab, sous le domaine de l’utilisateur. Le site statique est généré par la librairie Python mkdocs. Cette dernière permet aisément de créer des pages, notamment à partir de fichiers Markdown, qui sont ensuite utilisés pour construire un dossier contenant les fichiers HTML à exposer ensuite. Dans le dépôt de code précédemment cité, regardez le contenu du dossier docs : il n’y a qu’un fichier index.md, avec une référence en iframe à la carte. Notez bien cependant que la carte n’est pas dans le dépôt de code ; elle sera générée uniquement pour la construction des fichiers HTML composant le site statique.
En effet, tout se joue dans le fichier .gitlab-ci.yml. Ce fichier permet de déclencher des instructions du côté des serveurs GitLab lorsque certains événements ont lieu sur le dépôt de code. Par exemple, on peut utiliser ce fichier pour dire à GitLab qu’à chaque commit sur le dépôt, il faut exécuter une chaîne de tests, construire des artefacts (distribution Python), et les pousser sur un serveur PyPi. C’est précisément ce fichier de configuration que l’on utilise pour des tâches de Continuous Integration et Continuous Deployment (CI/CD), et qui va nous permettre de générer à la fois notre carte et notre site. Regardons son contenu plus en détail :
La première ligne précise à GitLab l’image Docker dans laquelle doit s’exécuter : ici, on demande une image docker Linux qui contient un exécuteur Python en version 3.7.
La ligne 2 précise le nom de l’action que GitLab doit faire, on parle de job. Les entrées before_script et script sont quant à elle assez compréhensibles : on installe tout d’abord les dépendances nécessaires au traitement, qui sont contenues dans le fichier requirements.txt et l’on exécute deux actions, la génération de la carte avec le script Python que nous avons vu précédemment, et la génération du site statique avec la librairie mkdocs. Comme la génération du site se fait dans un environnement où la carte est présente dans le système de fichiers, puisque créée précédemment, elle l’ingère sans avoir à la persister.
La ligne 8 est celle qui permet de dire à GitLab ce qu’on souhaite exposer : en précisant l’artefact que l’on souhaite sauvegarder dans le chemin public, et parce que le dépôt de code est également publique sur GitLab, le résultat du traitement, l’artefact, sera exposé par la fonctionnalité pages sous une URL, en l'occurrence : https://constant.bridon.gitlab.io/carte_velos/.
En l’état, le job ne se lance que lorsqu’il y a un commit ou un push sur le dépôt de code. Pour l'exécuter de manière régulière sans avoir à effectuer ces actions, c’est vers la fonctionnalité schedules de la rubrique CI/CD qu’il faut se tourner. Elle permet très simplement de paramétrer l'exécution régulière de notre pipeline, par l’intermédiaire d’une règle cron. Ici, la fréquence la plus élevée qui nous est autorisée est la fréquence horaire, aussi nous paramétrons le schedule pour qu’il s’exécute à chaque changement d’heure.
Ainsi, chaque heure, GitLab lancera le job qui récupérera les données les plus actuelles de la disponibilité des vélos, créera la carte, le site statique contenant la carte, et mettra à jour l’information exposée par l’URL. Il est à noter que cette fonction de planification d’exécution ne sera pas maintenue dans le temps, afin de ne pas consommer inutilement des ressources de calcul.
Conclusion
En conclusion, il n’est pas nécessaire d’être producteur de données pour créer des services utiles. L’État français, par l’intermédiaire de Etalab, met à disposition gratuitement des jeux de données riches et régulièrement mis à jour. Avec des services robustes et à l’état de l’art technologique, comme des API web, c’est une multitude de cas d’usage qui s’offrent à tous, sans avoir à être responsable des tâches contraignantes de maintien en qualité des données. Alors, qui sera le prochain EurosForDocs ?


