

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Comment créer un assistant vocal en JavaScript, en utilisant l’API Web Speech ? C’est ce que je vous propose d’étudier au travers d’un projet de lecteur MP3 pilotable intégralement à la voix.
Il y a quelques mois, j’ai appris qu’un de mes amis souffrait d’une grave infection oculaire. C’était pendant le second confinement, aussi je n’ai eu que la possibilité de le contacter par téléphone pour prendre de ses nouvelles. Il me confirma qu’il y voyait très mal, et que, faute de pouvoir regarder des écrans, le plus simple qu’il ait trouvé pour se changer les idées, c’était d’écouter les programmes de France Culture à la radio. Étant moi-même gros consommateur de podcasts produits par cette vénérable radio - j’en ai plein sur mon autoradio, chargés via une clé USB - je me suis demandé s’il serait possible de développer un lecteur de podcasts pilotable à la voix, que mon ami pourrait utiliser, ainsi que toute personne souffrant de problèmes de vue. Car il ne vous aura sans doute pas échappé que la plupart des lecteurs MP3, avec leurs écrans tactiles, sont très difficiles d’accès pour les personnes souffrant de handicap visuel.
N’ayant jamais développé de solution de ce genre, je m’aventurais en terre inconnue... mais je voyais très bien sur quoi je souhaiterais faire fonctionner ce lecteur de podcasts : un Rapsberry Pi 3. J’en avais un qui traînait dans un tiroir depuis pas mal de temps, ce serait génial de le transformer en un lecteur de fichiers audios, pilotable à la voix. Le Pi 3 ne coûtant pas cher, ce serait une solution économique qui pourrait rendre service à pas mal de monde. Et des Pi 3 dormant dans des tiroirs, il doit y en avoir plein... peut être même que vous en avez un vous aussi, non ?
En janvier 2021, j’ai eu enfin un peu de temps pour travailler sur ce sujet qui me tenait à cœur. Comme cet article est un retour d’expérience sur un projet encore en cours, j’arrête de parler au passé à partir de maintenant.
D’un point de vue logiciel, je le développe en quoi ce lecteur de podcasts ? Étant un développeur JavaScript (JS) aguerri, j’ai décidé de tenter l’aventure avec le JS. Okay, mais pour développer un assistant vocal, il me faut de la synthèse vocale et de la reconnaissance vocale. Comment je fais ça en JS ? Avec l’API Web Speech, dont j’ai découvert l’existence récemment, mais que je n’ai pas encore testée. Se pourrait-il qu’elle réponde à mes besoins ? C’est toute la question.
Je vais tout vous raconter : ce qui fonctionne à ce stade du projet, ce qui ne fonctionne pas, les points positifs et encourageants, et les autres…
1. Présentation de l’architecture
1.1 Architecture matérielle
Vous savez déjà que le matériel cible, c’est un Rapsberry Pi 3. Comme le système d’exploitation Rapsbian installé sur le mien est un peu ancien, et que sa carte micro-SD est rikiki, je l’ai remplacée par une carte micro-SD plus spacieuse (32 Gio), sur laquelle j’ai réinstallé un système Rapsbian complet et à jour. L’idée avec une carte de plus grande capacité, c’est d’avoir plus de confort pour y copier toutes les ressources sonores (podcasts et autres) que j’aurais envie d’y mettre.
À noter que le Pi 3 est équipé d’un bouton de démarrage placé directement sur le cordon d’alimentation. Cela semble d’un usage plutôt commode pour une personne souffrant de problèmes de vue.
Je me suis mis en quête d’un casque audio équipé d’un microphone. Mes critères ? Qu’il ait une bonne qualité d’écoute, qu’il soit agréable d’utilisation, pas trop cher, et qu’il puisse se brancher en USB sur le Pi 3, histoire de simplifier au maximum les branchements et les manipulations. Après quelques recherches, j’ai opté pour le modèle CH-321 de la marque Cooler Master. Il m’a coûté 40 euros sur Internet, et après plusieurs d’heures d’utilisation, je confirme qu’il répond bien à mon cahier des charges. À noter que le câble du casque fait dans les 2 mètres, et qu’il semble plutôt solide. Je n’avais pas prêté attention à ces détails en lisant le descriptif du produit, c’est plutôt une bonne surprise.
Si on considère qu’un Pi 3 coûte à l’heure actuelle dans les 50 euros (avec son boîtier de protection), en ajoutant le casque à 40 euros et une carte micro-SD de 32 Gio (aux alentours de 30 euros, voire moins) équipée du système Rapsbian, on a une configuration qui devrait avoisiner les 120 euros au maximum. En cherchant du côté du marché de l’occasion pour le Pi 3, on peut certainement gratter un peu et descendre à 100 euros.
Vous noterez que je ne mentionne ni clavier, ni souris, ni écran. Bien sûr, il serait utile d’en avoir, mais mon objectif, c’est que le Pi 3 soit dédié à une application unique complètement pilotable à la voix, sans l’aide d’aucun accessoire, hormis le casque-micro. Vais-je y arriver ? Ah ah, vous le saurez si vous lisez l’article jusqu’au bout ;).
1.2 Architecture logicielle
1.2.1 Web Speech, c’est deux API pour le prix d’une
L’API Web Speech n’existe pas en tant que telle. En fait, c’est un nom générique pour désigner deux API qui peuvent être utilisées ensemble ou séparément :
- l’API Speech Synthesis pour la synthèse vocale ;
- l’API Speech Recognition pour la reconnaissance vocale.
Un coup d’œil au site Caniuse.com [1] m’apprend qu’elles ne sont pas au même niveau en termes de support par les navigateurs. Si la synthèse vocale est implémentée sur un large panel de navigateurs (dont Chrome et Firefox), la situation est plus contrastée en ce qui concerne la reconnaissance vocale. A priori, Chrome la supporte presque complètement, tandis que Firefox l’implémente partiellement.
Un coup d’œil à la spécification [2] m’apprend aussi qu’elle est encore au stade de brouillon (draft) au 18 août 2020. Cela explique certaines des difficultés que je vais rencontrer tout au long du projet.
Pour pouvoir activer les deux API sur Firefox, il faut entrer la commande about:config, puis activer les deux paramètres suivants : media.webspeech.recognition.enable et media.webspeech.synth.enable.
Pour information, la version de Firefox qui est installée sur ma machine de développement est la 85.0.2, et la version de Chrome est la 88.0.4x. Je préfère le préciser, car les choses bougent vite dans le monde des navigateurs, et certains problèmes que j’ai rencontrés sur ce projet (développé entre janvier et février 2021) auront peut-être disparu dans quelques mois.
Je vous avoue que, au démarrage du projet, j’ai eu une inquiétude par rapport à Chrome. Car sur Rapsbian, c’est le navigateur Chromium (la version open-source de Chrome) qui est fourni. Est-ce que Chromium est au même niveau que Chrome en ce qui concerne la synthèse et la reconnaissance vocale ? C’est un point que je vais devoir vérifier. Ce doute va d’ailleurs orienter mon choix d’architecture logicielle. Car j’ai aussi envisagé, au tout début du projet, de le développer sur Electron (un projet basé sur Node.js). Mais Electron embarque nativement Chromium. Si jamais Chromium me pose des difficultés, je vais être bien embêté avec mon projet Electron. Comme il y a beaucoup d’inconnues dans cette équation, et que je ne veux me fermer aucune porte, je vais faire très vite le choix de développer mon projet de lecteur audio sur une base de Node.js couplée au framework Express. Ceci afin d’avoir une base de travail simple et de pouvoir « pivoter » plus facilement, si je rencontre des difficultés.
Et des difficultés, il va y en avoir, et pas vraiment là où je m’y attendais.
1.2.2 Tester la reconnaissance vocale
Vous vous demandez peut-être pourquoi je commence par la reconnaissance vocale ? Eh bien, parce que contre toute attente, c’est la fonctionnalité qui m’a posé le moins de problèmes.
Mais, car il y a bien sûr un mais, j’ai découvert qu’elle ne peut fonctionner sans une connexion à Internet. Pour faire court, si votre ordinateur n’est pas connecté à Internet (que ce soit en filaire ou en Wi-Fi), eh bien la reconnaissance vocale ne fonctionnera pas.
Je vais découvrir dans la spécification [2] l’explication du problème :
"network"
Some network communication that was required to complete the recognition failed.
Et effectivement, je vais constater durant mes tests que, sans connexion à Internet, j’obtiens bien une erreur de type network. Il faudra donc que le Pi soit connecté à Internet via sa connexion Ethernet (prise RJ45) ou via sa liaison Wi-Fi intégrée.
Moi qui espérais faire de mon Raspberry Pi un lecteur audio autonome... on dirait bien que mon scénario a du plomb dans l’aile. N’ayant pas trouvé de solution de contournement, je vais poursuivre l’expérience avec l’API Web Speech, faute de mieux, en espérant ne pas rencontrer de problèmes plus bloquants.
Pour me faire la main sur cette fonction de reconnaissance vocale, je me suis appuyé sur un dépôt GitHub mis à disposition par Mozilla, et en particulier sur l’exemple qui s’intitule « phrase matcher » [5]. L’exemple fourni par Mozilla sélectionne une phrase au hasard dans une liste de phrases en anglais, vous demande de cliquer sur un bouton, de prononcer la phrase affichée, et vous indique s’il a reconnu la phrase ou pas. J’ai testé cet exemple sur Chrome et sur Firefox, il fonctionnait très correctement sur les deux navigateurs. Donc je partais confiant. Mais au fur et à mesure de l’avancement de mon projet, je me suis rendu compte que la reconnaissance vocale fonctionnait bizarrement sur Firefox, sans que j’en comprenne la raison.
Pour comprendre ce qui « débloquait », j’ai retravaillé l’exemple « phrase matcher » de Mozilla à ma sauce. Comme il ne fonctionnait qu’en anglais, j’ai ajouté la possibilité de choisir une langue dans une liste déroulante, et de saisir sa propre phrase. Si cela vous tente, vous pouvez tester la version que j’ai mise en ligne sur Codepen : https://codepen.io/gregja/live/WNoxVNr.
À noter que dans ma version de développement en local, j’avais structuré le code sous forme de modules ES6 pour pouvoir l’intégrer comme un module de test dans mon projet final (dans lequel j’ai utilisé massivement des modules ES6, car cela permet d’écrire un code plus modulaire et plus robuste).
Sur Chrome, aucun problème, ma version avec modules ES6 fonctionnait très bien, mais sur Firefox, les ennuis ont commencé. Au début je ne voulais pas y croire, mais j’ai dû me rendre à l’évidence, dès qu’on inclut dans la page un module ES6, la reconnaissance vocale part en vrille. J’en ai eu la confirmation en modifiant le mode d’inclusion de mon script JS dans la page HTML principale :
- dans cette version tout va bien :
- mais en ajoutant le type module (spécifique aux modules ES6) les ennuis commencent :
… et les ennuis commencent même très vite, car dans mon script testspeech2.js, j’ai une erreur dès la 3e ligne de code :
L’erreur en question est la suivante : Uncaught ReferenceError: webkitSpeechRecognitionEvent is not defined.
J’ai tenté d’éliminer cette troisième ligne, partant du principe que Firefox s’appuierait de toute façon sur l’objet SpeechRecognitionEvent. Cela a semblé fonctionner jusqu’à ce que je m’aperçoive que la gestion des événements était devenue incohérente, ce qui corroborait les bizarreries que j’avais rencontrées au démarrage du projet.
Donc manifestement, la reconnaissance vocale sur Firefox, ça fonctionne bien tant qu’on ne l’utilise pas dans des modules ES6. Comme j’avais décidé de m’appuyer sur les modules ES6 pour structurer mon code, Firefox se retrouvait hors jeu. Voilà pour les mauvaises nouvelles.
Sinon pour les bonnes nouvelles, eh bien la reconnaissance vocale, ce n’est pas bien sorcier :
- ça, c’est la phase d’initialisation :
Vous noterez que j’ai défini une phrase de test « en dur » que l’on va demander à la reconnaissance vocale de reconnaître. J’inclus cette chaîne dans une variable normalisée que, par commodité, j’ai appelée grammar, et je passe cette « grammaire » à un objet de type SpeechGrammarList. J’ai également défini un code langue en dur, celui du français de métropole (fr-FR). C’est un code IETF, le même que ceux qu’on utilisera dans la synthèse vocale.
Au final, on a instancié un objet de type SpeechRecognition, stocké dans la variable recognition. Pour déclencher la reconnaissance, on va utiliser l’instruction suivante :
À partir du moment où la reconnaissance est déclenchée, on va pouvoir suivre les différentes étapes au moyen d’une série d’écouteurs d’événements. On a une belle liste d’écouteurs que l’on peut suivre au fil de l’eau : onresult, onspeechend, onerror, onaudiostart, onaudioend, onend, onnomatch, onsoundstart, onsoundend, onspeechstart, onstart.
L’exemple fourni par Mozilla les passe tous en revue, et ils se définissent tous sur le même moule. En voici un exemple avec l’événement onresult :
Les plus intéressants à surveiller, à mon avis, ce sont les trois premiers (onresult, onspeechend, onerror). Je ne dis pas que les autres événements ne sont pas intéressants, mais dans mon contexte, ils ne m’ont pas semblé très utiles.
Pour l’écouteur d’événement onerror, je vous propose ici une implémentation très basique (à adapter selon la manière dont vous voulez gérer les erreurs dans votre application) :
Pour l’écouteur onspeechend, cela peut être intéressant de stopper la reconnaissance – si on veut la redémarrer plus tard via un clic de bouton - comme dans cet exemple :
Le plus intéressant, c’est onresult, car on peut faire beaucoup de choses avec lui :
Je vous ai proposé un exemple simplifié qui envoie dans la console du navigateur ce que la reconnaissance vocale a « compris » de votre message vocal, à savoir :
- la transcription du texte tel que la reconnaissance vocale l’a « compris », récupérée à partir de l’objet event.results[0][0].transcript ;
- un taux de confiance, récupéré à partir de l’objet event.results[0][0].confidence.
J’ai un peu surveillé le contenu de l’objet event.results, histoire de voir si je pourrais récupérer d’autres informations intéressantes, mais je n’ai rien vu de significatif jusqu’ici. Je suppose que le contenu de cet objet pourra évoluer dans les futures versions de la spécification.
Un point important à souligner, c’est qu’on se moque pas mal de ce que vous mettez comme « phrase de test » dans la variable « phrase » que vous transmettez à la reconnaissance vocale. À la limite, si vous envoyez une chaîne vide, ce n’est pas un problème. Car j’ai constaté que le taux de confiance était indicatif, et pas d’une grande fiabilité ni d’une grande utilité.
Ce qui est important, c’est que la reconnaissance vocale vous renvoie une transcription exploitable dans le contexte de votre application. Par exemple, si vous avez prévu dans votre interface que l’utilisateur puisse prononcer une phrase du genre « écouter podcast sur Platon »… il faut que la reconnaissance vocale soit en mesure de vous restituer cette phrase de manière fidèle, pour que vous puissiez l’utiliser pour déclencher les bonnes actions.
J’ai testé pour vous, et je confirme que la reconnaissance vocale a été en mesure de retranscrire cette phrase sans trop d’erreurs, et cela sans que je lui aie transmis au préalable de phrase de comparaison (pour sa grammaire). La reconnaissance vocale m’a même envoyé un taux de confiance de 94 %, ce qui montre bien que ce taux n’est pas d’une grande utilité.
Elle en fait quand même des erreurs, cette reconnaissance vocale, car dans le cas de « Platon », elle a compris plusieurs fois « plateau ». Moi et ma manie de bouffer les mots, aussi… Bon, en insistant bien sur le son « on » de Platon, en général ça passe. Il y a d’autres mots qui passent mal. Par exemple, le mot « moins » est souvent confondu avec « moi », et quand je dis « choix 2 », de temps en temps la reconnaissance vocale comprend « choix de », ce qui fait un peu désordre.
Malgré tout, la reconnaissance vocale fonctionne plutôt bien, avec une retranscription des phrases assez fidèle (malgré quelques bémols), pour peu qu’elles ne soient pas trop complexes.
Maintenant qu’on a vu le principe, je vous explique rapidement comment j’ai géré la reconnaissance vocale dans l’application.
J’ai tout d’abord défini une douzaine de mots clés, je vous en mets un échantillon ci-dessous, pour vous montrer le principe :
Les mots clés « stop » et « play » sont utilisés sur la page spécifique au lecteur audio (contexte « reader »), pour déclencher ou stopper la lecture d’un podcast. Le mot clé « reload » est lui disponible sur toutes les pages (contexte « all »), de même que le mot clé « menu ». Le mot clé « search » est lui utilisé sur la page permettant de faire des recherches de podcasts (contexte « searching »).
L’action « stop », en version détaillée, se présente comme ceci :
La propriété words contient un tableau définissant les mots clés que l’utilisateur peut prononcer pour stopper la lecture du podcast. Ici, l’utilisateur peut stopper la lecture en utilisant les mots « stop » ou « arrêt », selon sa convenance. La propriété « action » indique quelle action sera déclenchée au sein de l’algorithme (ici, la fonction « stop »).
Donc quand l’utilisateur prononce une phrase, l’algorithme découpe cette phrase en plusieurs mots, le premier étant l’action principale, qu’il recherche dans la propriété words de mon tableau d’actions. S’il ne trouve aucun mot clé exploitable, l’algorithme envoie un message vocal indiquant qu’il n’a pas compris, et attend la demande suivante.
Certains mots clés se suffisent à eux même, comme « stop » et « play », mais d’autres nécessitent d’analyser la demande de l’utilisateur plus finement. À ce titre, le cas de « goto » est intéressant :
L’action « goto » permet à l’utilisateur de se positionner à un endroit de son choix dans le podcast, ce qui peut être très utile, car les podcasts sont souvent assez longs et on peut avoir envie de sauter certains passages. Par exemple, l’utilisateur peut demander « aller à 20 minutes », ou encore « aller à 30 secondes », histoire de sauter une intro ennuyeuse. Je n’ai pas prévu le cas où l’utilisateur demanderait un positionnement en minutes et secondes. Donc, dans le cas du « goto », j’ai prévu une propriété « exception », fixée à la valeur true, ce qui permet à mon algorithme de savoir qu’il doit analyser l’ensemble de la phrase et pas seulement le premier mot.
L’action « searching », utilisée sur la page permettant des recherches de podcasts, fonctionne sur le même principe que « goto ». Dans le cas de la recherche, l’utilisateur va par exemple demander « chercher Platon » ou « chercher Alan Turing ». L’algorithme va reconnaître le mot clé « chercher », va analyser le reste de la phrase et s’en servir pour lancer une recherche dans la base des podcasts. C’est aussi simple que ça.
J’ajoute simplement que j’ai prévu une table des actions pour le français et une pour l’anglais. Les deux sont quasi identiques, si ce n’est que les propriétés desc et words contiennent des valeurs correspondant à chacune des langues. Il ne sera pas trop compliqué d’ajouter d’autres langues par la suite, si besoin.
1.2.3 Jouer avec la synthèse vocale
Alors, elle fonctionne comment cette API Speech Synthesis ?
À première vue, cela semble très simple. A priori avec un bout de code comme celui-ci, vous pouvez faire parler votre navigateur :
Le mot anglais « utterance » désigne l’énonciation, la parole.
Donc, on instancie un objet SpeechSynthesisUtterance associé à l’API de synthèse vocale, en lui passant le texte à prononcer. On complète l’objet avec quelques paramètres optionnels sur lesquels je reviendrai, et on termine par un appel de l’API de synthèse vocale (via cette fois l’objet speechSynthesis, à qui on demande de parler via la méthode speak). Voilà, ce n’est pas bien compliqué… enfin, sur le papier.
Car le code précédent a fonctionné du premier coup sur Firefox, mais pas sur Chrome. Ce dernier m’a renvoyé le message de la figure 1 :
![]()
Le message est relativement clair : Chome exige une interaction de l’utilisateur - par exemple un clic de souris – pour activer l’API de synthèse vocale. Voilà qui est fâcheux. Car je rappelle que je souhaite développer une application entièrement pilotée à la voix. Mon objectif prioritaire, c’est que les utilisateurs puissent se passer complètement de souris et de clavier.
D’après mes recherches dans les forums, il semblerait que les concepteurs de Chrome aient pris la décision d’imposer cette interaction utilisateur, parce que certains développeurs auraient fait un usage abusif de la synthèse vocale. Je ne m’étendrai pas sur le bien-fondé (ou le ridicule) de cette décision… en tout cas, cela ne m’arrange pas.
Par curiosité, mais à vrai dire, sans trop y croire, j’ai tenté de contourner le problème en simulant un clic de souris sur un bouton ajouté à ma page :
Okay, j’ai tenté, ça n’a pas fonctionné, comme ça je n’ai pas de regret.
Heureusement, je finis par découvrir dans une documentation (dont j’ai égaré le lien) que les concepteurs de Chrome ont prévu une porte de sortie, sans doute pour calmer les grincheux dans mon genre. Donc pour contourner cette restriction qui empêche la synthèse vocale de démarrer immédiatement, il faut ajouter le paramètre suivant dans la commande de démarrage de Chrome : --autoplay-policy=no-user-gesture-required.
Je crée donc un raccourci vers Chrome en ajoutant ce paramètre, et je reteste mon code précédent… Cela fonctionne, YES !!!
J’avais déjà prévu que mon application Node.js démarre Chrome automatiquement, du coup l’ajout du paramètre ci-dessus dans le code de démarrage de Chrome suivant est une formalité :
Plus tard, il faudra que je vérifie que cela fonctionne aussi sur Rapsbian avec Chromium. Mais ne brûlons pas les étapes.
Donc je récapitule, pour faire parler notre navigateur, on a besoin d’instancier un objet parleur (« utterance » en anglais), et de lui passer quelques paramètres. J’ai appelé la fonction console.log en lui passant cet objet, pour voir à quoi il ressemble (figure 2).
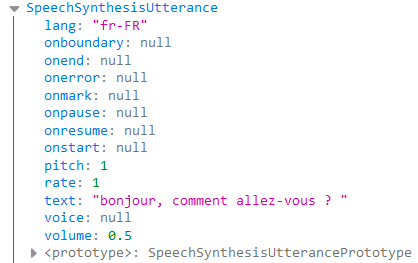
Les paramètres sur lesquels on a la main directement sont les suivants :
- la langue (propriété lang) : il s’agit ici des codes IETF tels qu’on en utilise dans de nombreux logiciels, mais la liste est limitée à quelques langues seulement, j’y reviendrai plus loin ;
- le pitch : définit la hauteur de la voix, peut prendre toute valeur entre 0 et 2 (testez 1 pour commencer et vous ajustez selon vos goûts) ;
- le rate : définit la vitesse d’élocution, peut prendre toute valeur entre 0 et 2, la valeur 1 est un bon début ;
- le volume : peut prendre toute valeur entre 0 et 1, je recommande de démarrer à 0.5 ;
- la voix (propriété voice) : il s’agit d’un paramètre optionnel que l’on utilisera dans le cas de langues pour lesquelles on a le choix entre plusieurs voix (par exemple, une voix féminine et une voix masculine).
La gestion de la voix va m’apporter son lot de problèmes, en particulier sur Chrome.
En effet, en testant certains exemples fournis par le site MDN [3], je m’aperçois que le chargement de la liste des voix ne fonctionne pas avec Chrome, en tout cas pas directement, il faut biaiser un peu pour que cela fonctionne.
Normalement, le chargement de la liste des voix devrait se faire très simplement via la fonction suivante :
Cela fonctionne bien sur Firefox, mais sur Chrome, l’appel de la méthode getVoices ne fonctionne pas directement.
Voici en figure 3 la jolie liste que me renvoie la méthode getVoices sur un Firefox tournant sur Windows.
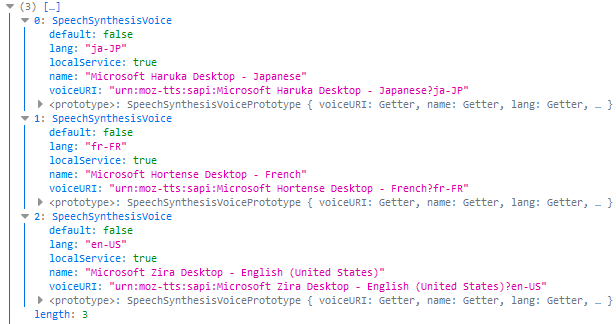
On voit que le système Windows fournit à notre API de synthèse vocale 3 voix (dont le français), voix qui sont définies dans des objets SpeechSynthesisVoice. On pourrait s’attendre à ce que Chrome renvoie au moins cette liste-là par défaut, mais non, il ne renvoie rien du tout, car sur Chrome la fonction getVoices fonctionne de manière asynchrone. Et pour qu’elle renvoie la liste des langues, il faut l’appeler à l’intérieur de l’écouteur d’événement onvoiceschanged, comme ceci :
On s’aperçoit de ce problème avec l’un des exemples fournis par MDN [3] quand, sur Chrome, la liste déroulante censée fournir la liste des voix reste désespérément vide.
A priori, ce problème ne devrait pas en être un pour moi, car dans la première version de mon lecteur de podcasts, je n’utilise que la voix standard associée à la langue ayant pour code fr-FR. Mais je vais m’apercevoir assez rapidement que, sur certains systèmes (notamment certains GNU/Linux), Chrome est désespérément muet, tant qu’il n’a pas chargé sa liste de voix. Donc, je dois trouver une solution à ce nouveau problème.
Heureusement, pour ce problème précis, j’étais déjà prévenu, car j’avais suivi le JSBootcamp organisé par Flavio Copes durant l’été 2020 [4]. Flavio avait consacré un chapitre à la synthèse vocale (mais pas à la reconnaissance), et il avait proposé un patch pour le problème de chargement de la liste des voix, patch que voici dans une version très légèrement remaniée par moi. Cette solution se compose de deux fonctions, la première renvoyant une promesse à la seconde :
Comment utiliser cela ? Supposons que j'aie une fonction startModule qui reçoit en entrée un tableau contenant la liste des voix, et qui s'en sert pour générer la liste des options d'un champ de saisie (balise <select>), ainsi que d’autres choses intéressantes (mise en place d’écouteurs d’événements, initialisation de variables, etc.). Il me suffit de transmettre cette fonction startModule à la fonction prepareVoicesList comme une callback, et le tour est joué :
Vous pouvez trouver des variantes de la solution proposée par Flavio Copes dans les forums, il y a plusieurs manières de procéder, mais elles sont finalement assez proches.
Au fait, elle ressemble à quoi la liste des langues une fois le problème corrigé sur Chrome ?
Eh bien, sur Chrome en environnement Windows, on obtient 19 langues fournies par Google, plus dans mon cas les 3 langues fournies par Microsoft. Cela nous fait un tableau de 22 éléments contenant des objets de type SpeechSynthesisVoice, tableau dont voici un aperçu en figure 4.

En regardant de près, on voit que le code fr-FR est en doublon entre les langues fournies par Microsoft et celles fournies par Google. On voit aussi que certaines langues ont plusieurs voix, c’est le cas notamment de l’anglais (code en-GB) qui a une voix féminine et une voix masculine.
Si vous êtes sur un système Fedora, sur Chrome vous retrouverez ces 19 voix (et seulement celles-là), tandis que sur Firefox vous allez trouver un nombre beaucoup plus impressionnant de voix (je suppose que ce sont des voix fournies par IBM). J’ai fait le test rapidement sur Firefox, sur la machine d’un ami, aussi je n’ai pas pris le temps de dénombrer précisément les voix disponibles, mais je pense qu’il y en avait vraiment beaucoup, avec très souvent plusieurs voix pour une même langue. Les quelques tests que j’ai faits, assez rapidement, m’ont donné l’impression que ces voix étaient de moins bonne qualité que celles fournies par Microsoft et Google (mais il faudrait que je le revérifie).
Bon, sachant que le système cible pour mon projet, c’est Rapsbian, je dispose de combien de voix sur cet environnement ?
Zéro ! Oui, vous avez bien lu, zéro ! Aussi bien sur Firefox que sur Chromium.
Je ne l’avais pas vu venir ce coup-là. C’est la douche froide.
Après quelques minutes d’abattement, je me suis dit que la solution passerait peut-être par l’utilisation d’un OS alternatif à Rapsbian. J’ai testé notamment Fedora sur mon Rapsberry Pi 3, le résultat a été désastreux (lenteurs atroces et plantages répétés du système). J’ai testé aussi Ubuntu Mate, pour un résultat tout aussi désastreux.
Intéressons-nous brièvement à d’autres aspects de l’application, qui je le rappelle est un lecteur de podcasts en devenir (un « devenir » qui semble s’assombrir).
1.2.4 Construire le socle de l’application
Je rappelle que l’architecture de mon lecteur de podcasts est basée sur le framework Express de Node.js.
Pour construire le squelette de l’application, j’ai utilisé un assistant fourni par l’IDE Webstorm (de la société Jetbrains), car je le trouve très pratique. Cet assistant offre le choix du moteur de templating, aussi j’ai opté pour Handlebars (parce que je l’aime bien).
À noter que l’interface utilisateur du lecteur de podcasts va être minimaliste, aussi j’ai opté pour une architecture simple, avec Handlebars pour la construction des pages de base et un CSS basique pour le rendu, en essayant de choisir de gros caractères, et des rendus simples, avec peu de couleurs. J’ai en effet privilégié le noir et le blanc (et quelques gris très légers), pour faciliter la vie des personnes souffrant de daltonisme en plus d’une vision faible. Et encore, je ne suis pas sûr que cela soit suffisant, il faudrait que j’en discute avec des personnes souffrant de ces handicaps pour valider ces choix. Si mon application doit pouvoir être pilotée intégralement à la voix (c’est l’objectif), je trouve intéressant que des personnes ayant une vision faible puissent s’aider d’un écran si c’est possible, ou qu’elles puissent se faire aider par une personne voyante qui pourra les assister dans la prise en main de l’application.
Voici en figure 5 l’arborescence de départ d’une application Express, telle qu’elle est générée par l’assistant de Webstorm.
Le fichier bin/www est un script Node.js lancé automatiquement quand on exécute la commande npm run start. C’est paramétré dans le fichier package.json (cf. extrait suivant) :
C’est dans le script bin/www que j’ai placé le code permettant de démarrer automatiquement Chrome (sous Windows) ou Chromium (sous GNU/Linux).
On peut dire pour simplifier que bin/www met en place les composants « bas niveau » de l’application, tandis que le script app.js met en place la couche intermédiaire (le middleware) avec l’initialisation du composant Handlebars (pour le templating) et surtout l’initialisation des différentes routes de l’application. Dans le code généré par Webstorm, nous avons par défaut les routes index et users, j’ai gardé uniquement index et j’ai construit mes propres routes.
J’avoue que j’ai hésité sur la manière de structurer la gestion des pages. J’aurais pu partir sur une architecture de type SPA (Single Page Application), mais j’ai préféré rester sur une architecture Express relativement standard, basée sur la notion de routes, avec les trois pages suivantes :
- page « index » : page d’accueil permettant d’orienter l’utilisateur vers différents choix (ces choix seront dans un premier temps très restreints puisqu’ils se limiteront au seul accès à la page de recherche des podcasts) ;
- page « searching » : page permettant de rechercher des podcasts dans une liste et d’en sélectionner un pour écoute (ce qui aura pour effet de débrancher vers la page qui suit) ;
- page « audioreader » : page affichant le lecteur de podcasts, qui s’appuie sur la balise <audio> pilotée vocalement, via des commandes comme « écouter » (ou « play » en anglais), « stop », etc.
Les trois pages que je viens de lister sont construites de manière classique, mais elles sont toutes pilotables à la voix. J’ai choisi d’afficher toutes les informations (menus, listes, etc.), même si elles sont accessibles via l’interface vocale, car il existe différentes gravités dans les handicaps visuels, et certaines personnes souffrant d’un handicap plus léger que d’autres pourraient trouver intéressant de prendre des raccourcis à la souris.
Sur les trois pages, on va retrouver un menu très basique, dont il sera possible de lister vocalement les options via la commande vocale « aide menu ». Ou « help menu », si l’application est configurée en anglais, car j’ai oublié de préciser que j’ai prévu que l’application soit bilingue (il sera possible d’ajouter d’autres langues ultérieurement). Sur les trois pages également, il sera possible de lancer la commande vocale « commande » pour obtenir un rappel, sous forme de liste vocale, des commandes disponibles sur la page. Cette liste diffère selon la page laquelle on se trouve.
Je vous propose de jeter un coup d’œil au lecteur audio.
1.2.5 Le lecteur de fichier audio
L’interface du lecteur audio est présentée en figure 6.

Le lecteur est construit sur la balise HTML <audio>, dont il reprend la plupart des fonctionnalités (écouter, stop, pause), plus quelques bonus spécifiques tels que :
- arrière : revient en arrière de 5 secondes ;
- avant : avance dans le titre de 5 secondes ;
- monter : pour monter le volume ;
- baisser : pour baisser le volume ;
- aller à : permet de se déplacer plus précisément dans le titre, en minutes ou secondes, par exemple « aller à 2 minutes » ou encore « aller à 50 secondes » ;
- info : donne des précisions sur le titre en cours d’écoute (avec en bonus la durée totale du titre et la durée d’écoute effective) ;
- commande : pour obtenir une piqûre de rappel sur les différentes commandes disponibles ;
- retour : pour revenir à la page de recherche ;
- index : pour revenir à la page d’accueil.
Je dirais que cette partie du développement a été la plus facile, et peut être la plus plaisante à réaliser.
Dans la suite, nous allons voir comment construire et consulter la base de données des podcasts.
1.2.6 Construire la base des podcasts et la fonction de recherche
Il me fallait une solution permettant d’extraire les tags MP3 des podcasts pour pouvoir constituer une petite base de données. J’ai trouvé un package NPM très pratique pour ça : node-id3 [6]. Il est bien documenté, d’un usage facile, et il a bien répondu à mon besoin.
J’ai créé un petit script dont la fonction principale consistait à parcourir un répertoire et ses sous-répertoires (de manière récursive) pour en extraire la liste de tous les fichiers MP3 présents, et surtout leurs tags MP3.
En observant les tags MP3 récupérés, je me suis rendu compte de deux problèmes mineurs :
- certains tags ne m’intéressaient pas, alors pour les éliminer, j’ai créé un tableau précisant la liste des tags que je souhaitais conserver, tableau que j’ai utilisé comme argument de filtrage : ["album", "title", "artist", "copyright", "fileUrl", "encodedBy", "date", "comment", "length"].
- certains tags contenaient des caractères erronés, comme des points d’interrogation à la place de guillemets par exemple, c’était notamment le cas des tags "album" et "title", alors j’ai créé une petite fonction de nettoyage (histoire que la synthèse vocale ne raconte pas n’importe quoi).
En faisant « lire » des titres par la synthèse vocale, je me suis aperçu d’un problème gênant, avec les titres de certaines séries de podcasts. Par exemple, sur des séries de 5 épisodes, on a souvent dans le titre des infos telles que 1/5, 2/5, 3/5... Cela fait bizarre quand la synthèse vocale vous dit « 1 cinquième » plutôt que « 1 sur 5 ». Du coup, j’ai ajouté à mon algorithme de nettoyage le remplacement des barres obliques (slashs) par le mot « sur », histoire d’avoir une lecture plus… humaine ?
À l’arrivée, j’ai obtenu un fichier JSON contenant un tableau d’objets, chaque objet correspondant à un podcast. Voici un exemple de podcast :
On voit que le nettoyage n’est pas parfait (cf. propriété album), mais dans l’ensemble ça fait l’affaire.
En plus des tags standards, j’ai ajouté les tags last_reading et nb_readings, en me disant que ce serait sympa de savoir combien de fois l’auditeur a écouté le podcast, et à quand remonte la dernière écoute (histoire de pouvoir l’alerter s’il sélectionne involontairement un titre déjà écouté). Mais je vous avoue que je n’ai pas implémenté cette fonctionnalité dans la version actuelle de l’application.
Un autre tag que j’ai ajouté, c’est category. Dans ce tag, j’ai prévu des valeurs telles que : philosophie, science, musique, etc. Car les tags de podcast ne contiennent pas d’informations permettant de faire un véritable classement thématique, alors j’ai essayé d’ajouter un début de classement, en me basant sur des mots clés prélevés dans les tags titre, album et artist. Cette partie du projet implique un nettoyage manuel des données pour obtenir un classement à peu près correct, mais c’est mieux que rien.
Okay, j’ai ma base de podcasts dans un fichier JSON, pour faciliter sa consultation et les recherches à l’intérieur de cette base, j’ai utilisé le package NPM json-server [7]. C’est un package très pratique, bien documenté, qui se comporte comme un serveur d’API REST. Techniquement, il monte en mémoire le fichier JSON qu’on lui donne à digérer, et il se comporte comme un serveur de base de données, que l’on pourra interroger via des requêtes HTTP (de type GET, POST, PUT et même DELETE). C’est très pratique pour prototyper rapidement un serveur d’API quand vous n’êtes pas sûr de l’architecture finale, ou quand elle n’est pas encore opérationnelle et que vous avez besoin d’avancer dans vos développements. Et c’est très pratique dans mon cas, car ma base de podcasts n’est pas très volumineuse, et ce package me semble idéal pour développer une application légère et facilement déployable.
Attention, il faut installer ce package comme un package global :
Comme il s’agit d’un package à installer en global, sur certains systèmes vous devrez préfixer la commande ci-dessus avec un sudo.
Le démarrage de json-server se fera dans le script bin/www que j’avais évoqué précédemment. Comme mon serveur Express utilise le port 3000, je paramétrerai le serveur JSON sur le port 3001 pour éviter tout conflit, cela donne ceci :
À partir de là, il devient possible de lancer des requêtes HTTP de type GET. Par exemple, pour trouver des podcasts dont le titre contient le mot clé « Platon » (http://localhost:3001/podcast?title_like=platon) ou pour chercher les podcasts appartenant à la catégorie « philosophie » (http://localhost:3001/podcast?category_like=philosophie).
Je n’ai utilisé ce package qu’à 10 % de ses capacités, mais il m’a permis d’avancer très vite sur cette partie « recherche de titre ». Mais je vais devoir consacrer plus de temps à la fonctionnalité de recherche côté navigateur, pour la rendre plus conviviale, plus pratique, car pour l’instant on se contente de lancer des recherches vocales du type « chercher Platon » ou encore « chercher Alan Turing ». Cela fonctionne, mais ce n’est pas très convivial. Car se pose maintenant la question cruciale de l’ergonomie, particulièrement dans le cas où le serveur JSON renvoie plusieurs titres pour une même recherche. Des questions se posent, telles que :
- faut-il énumérer chacun des titres trouvés ? S’il y en a beaucoup, cela risque d’être prodigieusement ennuyeux ;
- faut-il limiter la sélection à une dizaine de titres, ou moins ? Mais quid des titres suivants, qui risquent de n’être jamais écoutés (sauf peut-être si l’on exclut les titres déjà écoutés de la sélection) ;
- faut-il prévoir une fonction de recherche permettant de distinguer explicitement les titres non écoutés et les titres déjà écoutés ? Sans doute, car l’utilisateur aura probablement envie de réécouter certains titres.
Des questions comme celles-là, en cherchant bien, on peut en trouver d’autres.
À ce stade du projet, je commence à envisager l’utilisation d’une solution de type NLP (Natural Language Processing) pour offrir un mécanisme de recherche réellement plus convivial. Le package NPM natural est sans doute un bon candidat pour prendre cette orientation.
Dans le cas où je m’orienterais vers une solution de type NLP, il faut que le serveur de base de données réponde de manière pertinente et efficace aux recherches réalisées selon ce mode. Du coup, je serai peut être amené à remplacer json-server par une base de données de type SQL, par exemple.
Conclusion
Je dois souligner qu’entre le moment où mon ami m’a parlé de son handicap visuel, et le moment où je me suis lancé sur ce projet, quelques mois se sont écoulés, et que sa vue s’est un peu améliorée entre temps. Heureusement, car mon application n’est pas satisfaisante en l’état.
Ma fonction de recherche fonctionne assez bien, mais elle est peu conviviale et mériterait d’être complétée par une solution de type NLP.
Le système Rapsbian étant visiblement dépourvu de synthèse vocale, ma solution destinée à transformer un Rapsberry Pi 3 en lecteur de podcasts est dans les choux (pour l’instant). Par acquit de conscience, j’ai tenté d’installer un système Fedora sur le Pi 3, puis un Ubuntu Mate, mais dans les deux cas, les performances se sont révélées désastreuses (lenteurs désespérantes, et plantages répétés). Donc, ma solution est peut-être viable avec un Pi 4 équipé de l’un des systèmes que je viens de citer, mais pour le Pi 3, c’est mal parti...
Le fait que l’API Web Speech ne puisse fonctionner sans connexion à Internet est à mon sens un problème vraiment gênant. Cela réduit beaucoup l’intérêt de stocker les MP3 sur le Rapsberry Pi, puisqu’il n’est pas autonome. Compte tenu de cette contrainte, j’entrevois une piste plus prometteuse, qui consisterait à exploiter les flux RSS relatifs aux podcasts de France Culture, de manière à proposer une interface vocale permettant de naviguer dans ces flux, et de sélectionner et écouter des podcasts à la volée.
Malgré les difficultés rencontrées, j’ai bien kiffé cette expérience. Elle m’a permis d’apprendre beaucoup de choses, et de toucher du doigt les problématiques liées au développement d’interface vocale. J’espère que je trouverai le temps d’améliorer ce projet de façon significative, en tout cas vous pouvez le récupérer sur ce dépôt GitHub et vous amuser avec : https://github.com/gregja/ar-vocal-project.
N’hésitez pas à m’envoyer des messages via l’option Issues de GitHub, pour me signaler des bugs ou me proposer des améliorations.
Références
[1] Que dit Caniuse sur WebSpeech : https://caniuse.com/?search=web%20speech
[2] La spécification de WebSpeech : https://wicg.github.io/speech-api/
[3] Documentation de MDN : https://mdn.github.io/web-speech-api/speak-easy-synthesis/
[4] Le JSBootcamp de Flavio Copes : https://thejsbootcamp.com/
[5] Dépôt GitHub d’exemples fournis par Mozilla : https://github.com/mdn/web-speech-api/
[6] Le package node-id3 : https://www.npmjs.com/package/node-id3
[7] Le package json-server : https://www.npmjs.com/package/json-server
[8] Le package natural : https://www.npmjs.com/package/natural


