

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Vous avez succombé à l’esthétique soignée des tableaux de bord de Grafana, mais vous ne pouvez pas vous passer de l’écran d’alertes du vénérable Nagios ! Alors, est-il possible de faire cohabiter ces deux produits ? Avec un peu de code Python, cela devrait être possible !
Tous les administrateurs système et les responsables d’exploitation utilisent des outils de supervision. Parmi la panoplie des outils Open Source disponibles, celui qui est a été le plus déployé depuis vingt ans est sans conteste possible Nagios ! J’en ai moi-même installé des dizaines, que ce soit sa version native (Nagios et son interface web intégrée) ou bien l’un de ses clones ou de ses surcouches (EON, Centreon, Thruk, FAN...).
Si Nagios excelle pour la remontée des alertes, il n’offre pas de solution intrinsèque pour « grapher » des métriques. Certes, des Addons tels que PNP4Nagios comblent cette lacune, mais il faut bien avouer que le look-and-feel des graphes produits (en réalité par RRDTool) est un peu désuet et offre une interactivité limitée, comme le montre la figure 1.

Or, on constate depuis quelques années la montée en puissance d’une nouvelle génération d’outils de collecte et d’affichage de métriques : que votre infrastructure utilise des Containers ou non, il est très probable que vous ayez entendu parler ou que vous utilisiez déjà des solutions comme Prometheus et Grafana ?
Nous allons donc nous retrouver avec des outils complémentaires, proposant chacun leur interface web : d’un côté Nagios et ses alertes, d’un autre côté Grafana et ses graphes. Certes, vous avez plusieurs écrans à votre disposition, mais ne pourrait-on pas simplifier la console de supervision en intégrant les alertes de Nagios dans un Dashboard de Grafana ?

Le code Python présenté dans cet article a été testé avec Python 3.6+ et Grafana 7. Les sources sont disponibles sur GitHub [1].
1. Exposition des données de Nagios
Nagios effectue des tests périodiques sur des Hosts et des Services. En fonction du code retour des tests (qui sont en fait implémentés sous forme de commandes externes : les Plugins), il en déduit l’état du Host ou du Service.
Mais Nagios publie aussi l’état courant des Hosts et Services dans un fichier texte dont le nom est donné par le paramètre status_file défini dans son fichier de configuration (habituellement le fichier nagios.cfg). Par exemple :
Dans le fichier status_file, l’état d’un Host ressemble à ceci (nous n’avons conservé que les lignes utiles pour la suite) :
L’état d’un Service ressemble à ceci :
Voici donc les informations que nous aimerions voir s’afficher dans Grafana !
Les Plugins de Nagios doivent retourner les valeurs 0, 1, 2 ou 3 selon que le résultat du test est OK, WARNING, CRITICAL ou UNKNOWN. Ici, ce code retour est donné par la ligne current_state. Les Plugins peuvent en outre renvoyer une chaîne de caractères sur STDOUT. La valeur de cette chaîne est indiquée par le champ plugin_output. Elle est aussi affichée dans l’interface web, dans la colonne Status information.
Notez également que la ligne last_check, qui indique la date du dernier test, est exprimée classiquement en nombre de secondes écoulées depuis le 1er janvier 1970. Alors que les dates dans Grafana sont exprimées en millisecondes...
2. Grafana et ses Datasources
Grafana affiche les valeurs de métriques collectées à partir de Datasources multiples comme Prometheus, InfluxDB, Graphite, ElasticSearch, MySQL, PostgreSQL, CloudWatch...
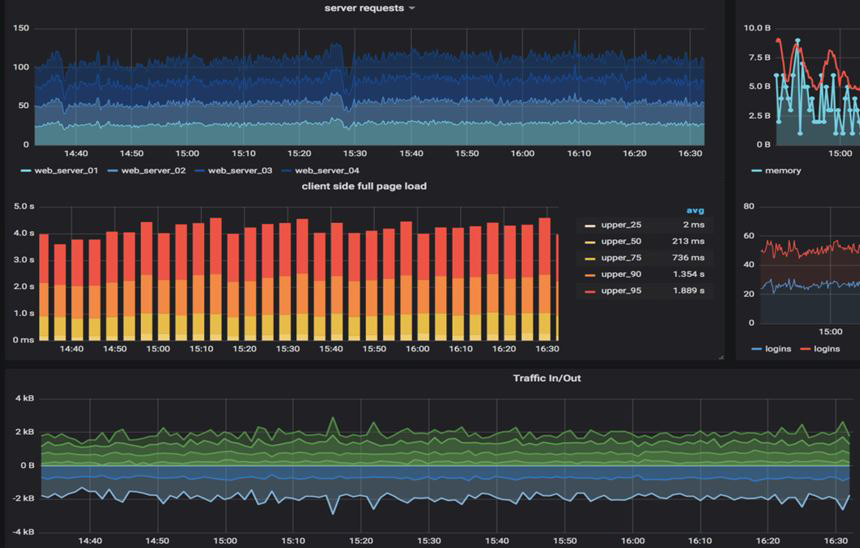
Une fois les données collectées, elles peuvent être visualisées sous différents formats dans les Panels qui constituent les Dashboards. La figure 4 montre la composition d’un Panel de type Graph ainsi que les différents types de visualisation disponibles (seul le visualiseur Worldmap Panel a été ajouté sur la distribution standard).
Notre problème serait immédiatement résolu si Grafana disposait d’une Datasource capable d’aller chercher les données dans le fichier status_file de Nagios, puis de les afficher dans une Table ou un Graph... mais ce n’est pas le cas !
3. Points de réflexion et solution
3.1 Notre première idée
Une première solution pourrait être alors de publier les données de Nagios dans une Datasource déjà connue de Grafana, par exemple ElasticSearch ou Prometheus.
Mais nous voyons deux écueils : cela imposerait d’une part la présence d’un de ces outils, et d’autre part, de traduire les données de Nagios sous la forme d’une Time-Serie. Mais qu’est-ce qu’une Time-Serie ?
Prenons le cas de Prometheus : celui-ci gère uniquement des Time-Series, c’est-à-dire des métriques ayant des valeurs qui fluctuent au cours du temps. Or, ces métriques sont caractérisées par un nom (metric name) et un ensemble de paires clés/valeurs. Par exemple, la charge CPU du serveur web s’exprimera ainsi :
On peut alors imaginer des noms de métriques comme nagios_host_status et nagios_service_status. Le nom complet des Time-Series serait alors similaire à ceci :
Les valeurs stockées dans ces Time-Series seraient alors la valeur du champ current_status exporté par Nagios. Le champ last_check servirait à dater les valeurs. Mais comment stocker avec cette notation la valeur du champ plugin_output ? La documentation de Prometheus est très claire : il faut éviter l’explosion du nombre de métriques en minimisant la cardinalité des valeurs associées aux labels définissant les Time-Series. Ainsi, ce type de nommage serait une hérésie :
En effet, à chaque consultation, la valeur du label plugin_output risque de changer, d’où l’explosion du nombre de métriques !
Nous excluons cette solution, alors comment faire ? … et si possible, simplement ?
3.2 Notre solution
Les concepteurs de Grafana ont eu la bonne idée de proposer un outil qui peut être enrichi via des Plugins. Il existe des Plugins de visualisation (par exemple, pour faire de la cartographie), mais aussi des Plugins qui ajoutent des Datasources ! Parmi ces Plugins, celui dénommé JSON-Datasource [2] va nous aider à répondre à notre besoin : ce Plugin permet de récupérer des données au format JSON en interrogeant un serveur web. La solution devient évidente : nous devons créer une interface entre Nagios et ce Plugin JSON pour exporter le statut des Hosts et Services de Nagios au format JSON !
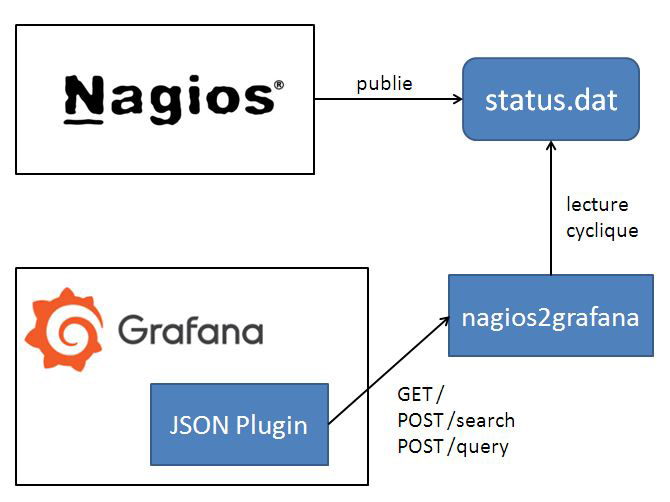
Notre application s’appellera... nagios2grafana et l’architecture globale est donnée par la figure 5.
3.3.Fonctionnement du Plugin JSON
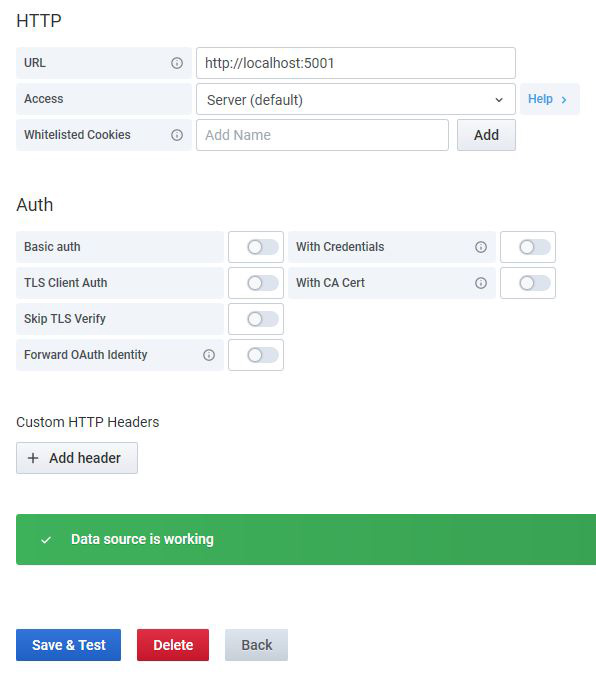
Lorsqu’une nouvelle Datasource utilisant le Plugin JSON est configurée dans Grafana, puis qu’on clique sur le bouton <Save & Test>, le Plugin invoque l’URL GET / et s’attend à recevoir un code 200, comme le montre la figure 6.
Quand on crée un nouveau Panel et qu’on sélectionne une Datasource qui utilise le Plugin JSON, une requête POST /search est réalisée et doit retourner la liste des métriques qui seront affichées dans la liste déroulante nommée Metric, que vous pouvez voir sur la figure 7.
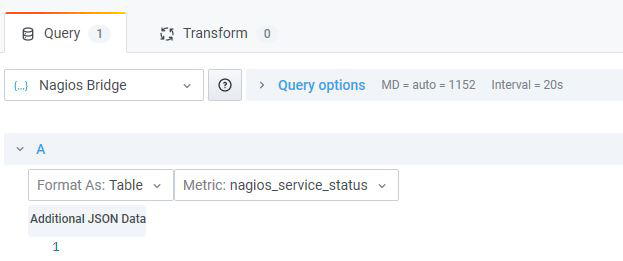
Enfin, une fois la métrique sélectionnée, une requête POST /query est envoyée au serveur avec un document JSON ressemblant à ceci (nous supposons que vous avez déjà sélectionné une visualisation de type Table) :
La structure de ce document nous aidera à comprendre le code de traitement de la requête. Le résultat attendu doit ressembler à ceci :
Les types supportés sont string, number et time.
4. Et maintenant, le code !
Les spécifications sont claires. Notre code, écrit en Python, doit donc lire le contenu du fichier status_file de Nagios et être capable de répondre aux requêtes émanant du Plugin JSON de Grafana.
4.1 Lecture du fichier status_file
En section 1, nous avons donné un extrait du fichier status_file. Son analyse consiste à trouver les lignes hoststatus { et servicestatus {, puis à récupérer les valeurs des champs « intéressants » jusqu’à trouver la ligne constituée d’une accolade fermante (}) qui termine le bloc. Cet algorithme est implémenté par la méthode read_status() de la classe NagiosFileReader du fichier nagios_file_reader.py dont voici la trame principale :
4.2 Implémentation du serveur web intégré
Notre programme doit proposer un service pour le Plugin JSON de Grafana. Nous allons utiliser Flask pour implémenter ce serveur web. Le fichier nagios2grafana.py se compose de 3 parties :
1. La prise en compte des arguments de la ligne de commande, pour permettre de spécifier la localisation du fichier status_file, le port d’écoute et la période d’analyse du fichier. Suivent l’initialisation des variables globales et la lecture immédiate du fichier status_file :
2. Un thread est dédié à la relecture périodique du fichier status_file :
3. Pour finir, l’application Flask qui répond aux 3 requêtes possibles :
- GET / qui répond par un simple code 200 ;
- POST /search qui retourne la liste des 2 métriques possibles : nagios_host_status et nagios_service_status ;
- POST /query qui retourne l’état des Hosts ou Services lus à partir du fichier status_file, puis mis au format attendu par le Plugin JSON de Grafana. Le format des données postées est décrit en section 3.3 :
Pour finir, la mise en forme des données est assurée par les fonctions du fichier status_exporter.py :
Il y a une remarque à faire à propos des deux fonctions précédentes : lors des tests, nous avons noté que même si le type d’une colonne était indiqué comme étant de type chaîne (string), la valeur était convertie en nombre si la chaîne débutait par un nombre ! C’est pour éviter cela que nous ajoutons systématiquement un préfixe au début de la valeur de plugin_output (ici, nous ajoutons la chaîne '> ').
5. Intégration dans Grafana
5.1 Configuration de Grafana
Tout d’abord, nous devons exécuter notre application Python en lui passant quelques paramètres, dont la localisation du fichier de statut de Nagios. Nous indiquons aussi que le service sera à l’écoute sur le port 5001/tcp :
L’installation du Plugin JSON Datasource de Grafana se fait en mode ligne de commande ainsi :
5.2 Création d’un Dashboard
À partir de l’interface d’administration web de Grafana, on crée la nouvelle Datasource depuis le menu Configuration > Data Sources. Vous pouvez cliquer ensuite sur le bouton <Add data source>, puis remplir le formulaire comme indiqué sur la figure 6. Donnez un nom à cette Datasource (par exemple Nagios Bridge), puis cliquez sur le bouton <Save & Test> en bas du formulaire pour le valider et vérifiez que la source est valide.
Maintenant, nous pouvons créer un nouveau Dashboard à partir du menu Dashboards > Manage, puis en cliquant sur le bouton <New Dashboard>. Un écran similaire à celui de la figure 8 s’affiche.
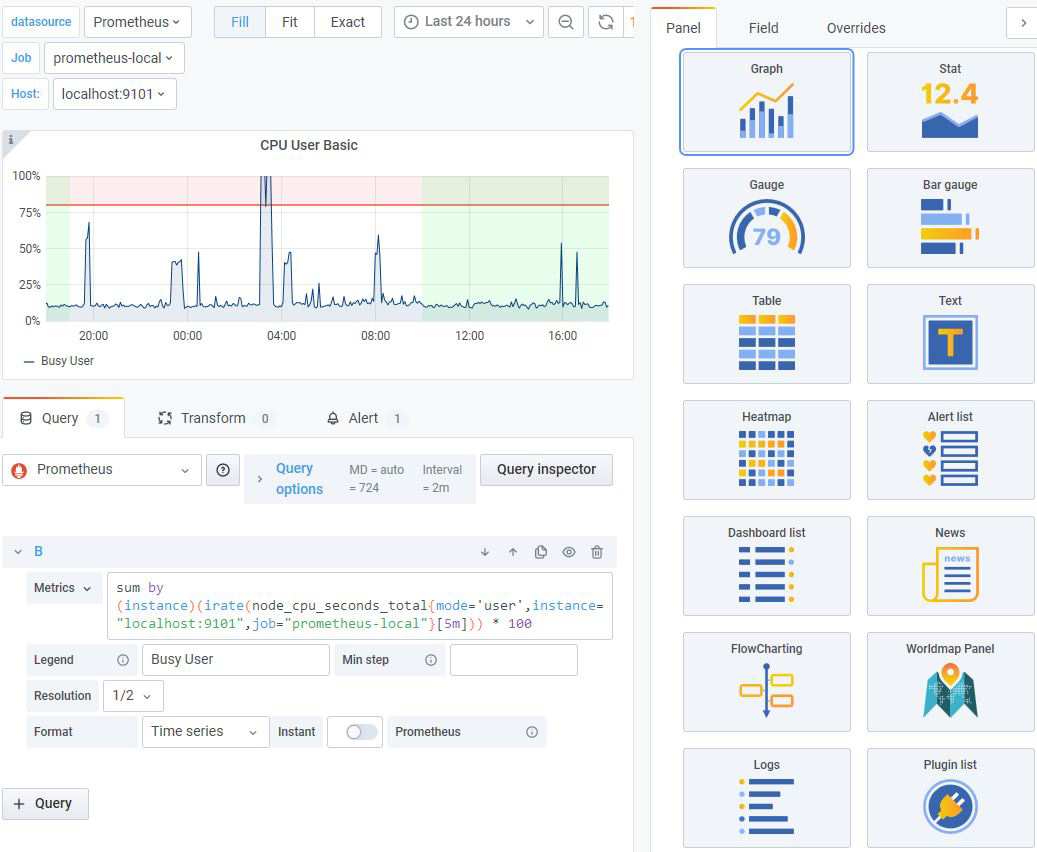
Ajoutons un nouveau Panel à ce Dashboard en cliquant sur le bouton <+ Add new panel>. Un Panel avec la Datasource par défaut est affiché et le mode de visualisation est de type Graph. La figure 9 vous montre comment configurer le Panel pour qu’il affiche dans une table l’état des serveurs, tel que Nagios le remonte.
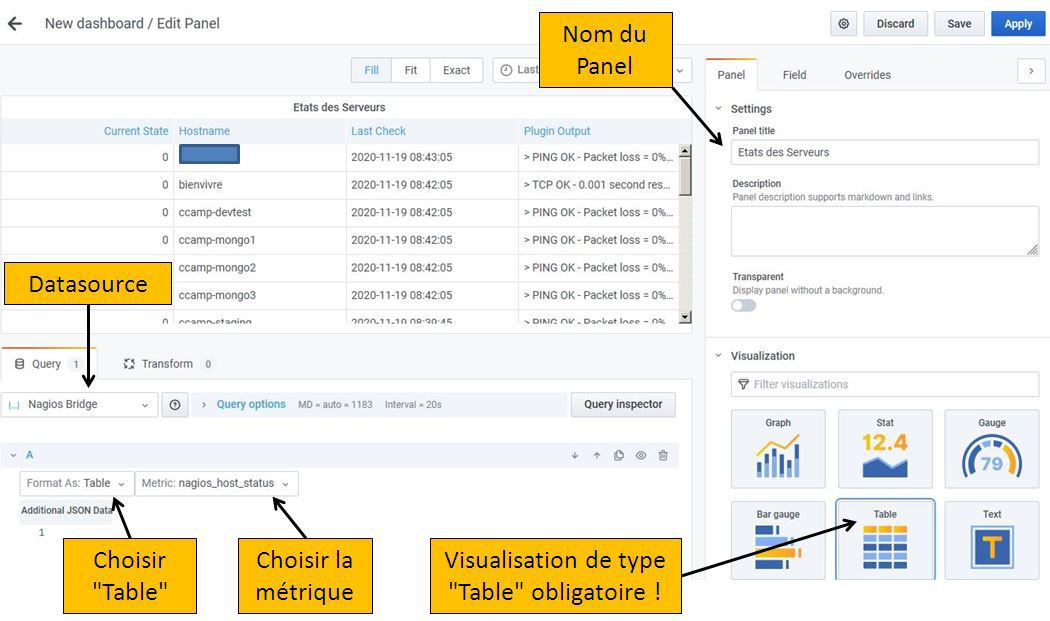
Les caractéristiques de ce Panel sont les suivantes :
- la Datasource s’appelle Nagios Bridge : à ce moment-là, la liste des métriques disponibles se met à jour, car la requête POST /search a été envoyée. Nous sélectionnons par exemple la métrique nagios_host_status ;
- le type de visualisation est Table ;
- le format d’affichage des résultats est aussi Table.
Si tout est correct, les états des Hosts surveillés par Nagios apparaissent dans la Table !
Vous pouvez sauver ce Panel, en créer un autre pour la métrique nagios_service_status et ainsi composer votre Dashboard !
5.3 Amélioration des effets visuels
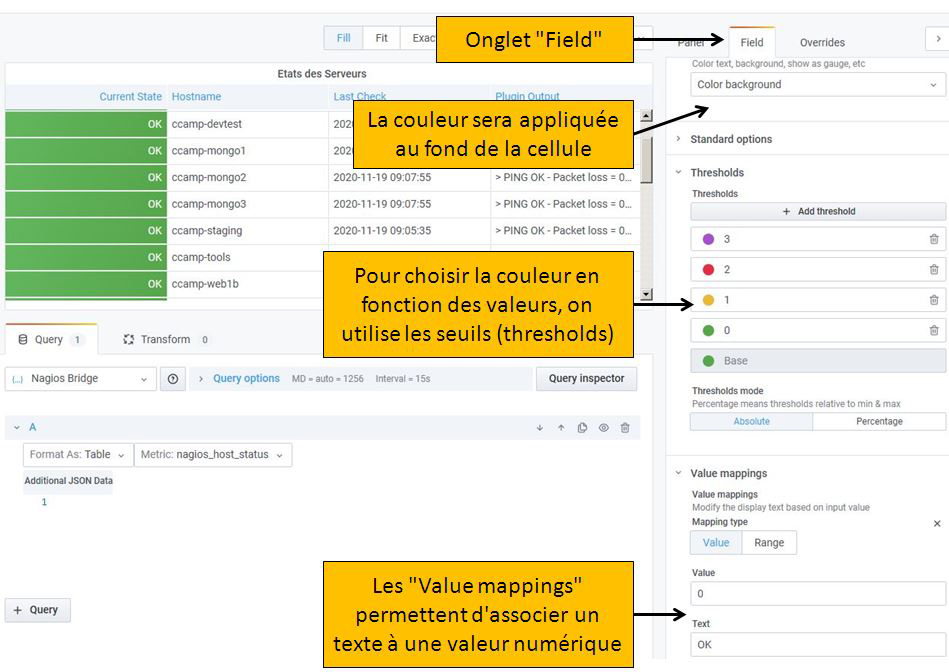
Comme vous l’avez remarqué sur la figure 9, la colonne Current State affiche le code retourné par le Plugin de Nagios qui a vérifié l’état du Host. Ce code est un nombre entier qui peut valoir 0, 1, 2 ou 3, comme nous l’avons expliqué dans une note en section 1.
Nous allons configurer le Panel pour remplacer ce code par un texte plus explicite (0 => OK, 1 => WARNING, etc.) et lui adjoindre une couleur (0 => vert, 1 => orange, etc.). La capture d’écran de la figure 10 vous montre les zones à remplir pour arriver à ce résultat. L’effet de vos modifications doit se voir immédiatement dans la table des résultats.
5.4 Filtrage des données
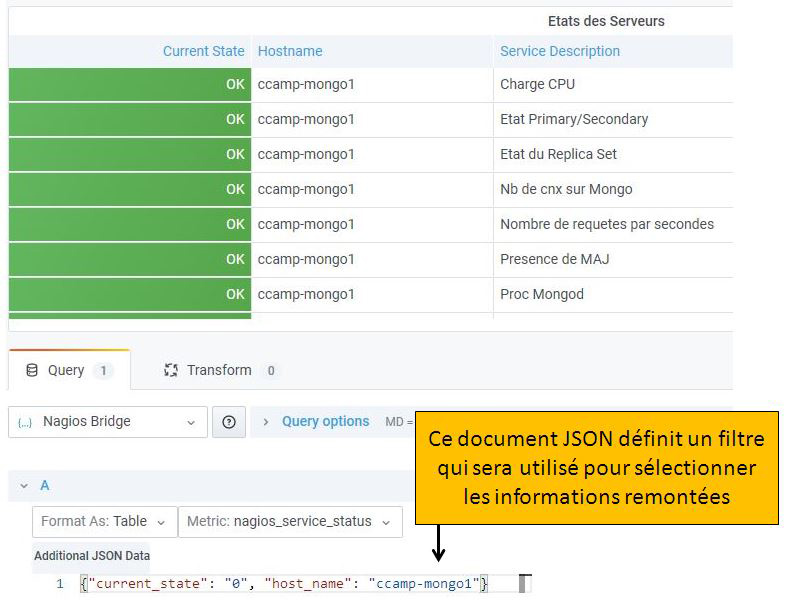
Comme vous le constatez, notre Panel affiche l’état de TOUS les Hosts ou TOUS les Services, selon la métrique choisie. La figure 11 montre qu’il est possible de limiter l’affichage des données en définissant un filtre sous forme de document JSON. Les filtres sont composés d’une ou plusieurs paires clés/valeurs.
Les clés possibles sont host_name, service_description, current_state, last_check et plugin_output. Les valeurs sont forcément des chaînes de caractères. Au moment d’écrire cet article, seuls des tests d’égalité sont implémentés, ainsi, l’exemple donné dans la figure 11 n’affiche que les Status des Services dont la valeur de current_state est 0 (OK) ET le host_name est ccamp-mongo1.
Conclusion
Et voilà, grâce au Plugin JSON-Datasource de Grafana, notre but est atteint : nous avons réussi à intégrer facilement l’affichage de Nagios dans l’interface de Grafana ! Bien sûr, le code complet se doit d’être un peu plus complexe : en particulier, l’application devrait être lancée via un serveur taillé pour la production comme gunicorn, quelques try...except... mériteraient d’être ajoutés et surtout, la syntaxe des filtres pourrait être enrichie pour permettre au minimum de faire du pattern-matching à l’aide d’expressions régulières... Qui sait, ces améliorations seront peut-être proposées dans le dépôt GitHub au moment où vous lirez cet article ?
Références
[1] Dépôt GitHub du projet : https://github.com/majeinfo/nagios2grafana
[2] Site du Plugin JSON – Datasource pour Grafana :
https://grafana.com/grafana/plugins/simpod-json-datasource


