

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Spectre, et son pendant Meltdown, est une faille qui repose sur l’architecture moderne de nos processeurs. Dans cet article, nous verrons l’impact que cette vulnérabilité a eu sur le développement d’applications web.
Spectre, déjà trois ans [WIKI] ! La vulnérabilité a eu un important écho au moment de sa présentation. En effet, il était impossible de fournir un patch permettant de résoudre le problème qui se trouvait au cœur de nos systèmes : le processeur. Et depuis trois ans, que s’est-il passé ? Cet article vous propose de vous replonger dans cette vulnérabilité et de voir comment nous pouvons protéger nos sites web aujourd’hui contre ce type de menaces.
1. Bouh !
1.1 Au cœur de notre ordinateur
Avant de parler de Spectre en détail, nous allons tout d’abord présenter la manière dont fonctionnent nos processeurs. Nos processeurs ne sont pas uniquement des composants capables d’exécuter des instructions machine à un rythme élevé. Ils sont aussi le fruit d’une ingénierie très avancée prévue pour accélérer toujours plus le traitement des programmes.
Parmi les éléments constituant un processeur, on retrouve, par exemple, le cache. De base, le processeur possède des registres pour effectuer des opérations. L’accès aux registres est extrêmement rapide, mais la taille des registres est limitée. La mémoire vive, quant à elle, est plus large, mais moins rapide. On peut considérer qu’il faut au minimum 100 cycles d’horloges pour transférer des données entre la mémoire vive et un registre, voire plus. Je ne parle même pas des données stockées sur le disque. Pour accélérer les traitements, le processeur dispose de plusieurs niveaux de cache (L1, L2 …) connectés entre eux. Plus un cache est petit, plus il est rapide et s’il lui manque une donnée, il peut tenter de la récupérer dans le cache immédiatement supérieur qui est plus gros, mais plus lent. Lors de l’accès à une donnée, l’ordinateur met généralement en cache les données proches de celles qui viennent d’être accédées, ce qui semble logique. Ainsi, si on effectue un traitement sur un fichier ou un tableau, il y a de fortes chances qu’on souhaite lire la valeur suivante.
Le cache n’est qu’un exemple de composants présents dans un processeur. Les processeurs sont aussi pensés en prenant en compte le code qu’ils peuvent exécuter. Prenons le code suivant qui recherche l’index d’une valeur dans un tableau :
Généralement, il faut parcourir une grande partie du tableau avant de trouver la valeur que nous cherchons. Il y a donc peu de chance que le résultat de l’expression « array[i] === valeur » soit vrai. Regardons le code assembleur correspondant :
Il faut un certain temps pour obtenir le résultat de la comparaison. Si la valeur pointée par « array[i] » n’est pas en cache, il faut généralement quelques microsecondes voire plus pour la récupérer de la mémoire. Pour le processeur, que de temps de perdu ! Dans le cas présenté, en général, le résultat est faux (on ne trouve pas tout de suite la valeur recherchée) et le bloc du if est ignoré. En analysant la branche prise le plus fréquemment, le processeur peut « prédire » la branche qu’il devra prendre la prochaine fois.
Mais on peut aller un cran plus loin. Dans la mesure où la variable i ne sert que dans la fonction, le processeur pourrait commencer à incrémenter la valeur de i pour l’étape d’après. De plus, il pourrait aussi commencer à regarder si i est égal à la taille du tableau ou bien même commencer à récupérer la valeur array[i] suivante. En gros, il pourrait prendre de l’avance sur le reste du calcul plutôt que d’attendre à chaque fois le résultat de l’évaluation. Le processeur fait le pari que la condition ne sera pas forcément vraie (ce qui est le cas dans cet exemple). Si jamais il s’est trompé, il lui suffit de remettre à jour les anciennes valeurs de registre et d’exécuter le code de la bonne branche. Si le processeur ne l’avait pas fait, il aurait dû attendre de toute façon, donc autant s’occuper en s’avançant dans son travail ! Malin, n’est-ce pas ? Voilà le principe de l’« exécution spéculative » et de « prédiction de branchement ».
Oui, mais voilà, c’est ce comportement, ou plus exactement une combinaison de ces comportements, qu’exploite la vulnérabilité Spectre.
1.2 Un (pas si) gentil fantôme
Spectre est une vulnérabilité affectant les processeurs hautes performances. Elle s’appuie sur plusieurs éléments des processeurs pour arriver à extraire des données via un canal secondaire. Dans cette partie, nous décrirons une des variantes de Spectre pour présenter cette vulnérabilité. Le lecteur est invité à lire le papier originel présentant la vulnérabilité.
![]()
Nous nous appuierons sur cet extrait de code issu du papier pour expliquer Spectre [SPECTRE].
Le but de l’attaquant est de lire des données dans la mémoire qui ne lui serait pas forcément accessible. Pour ce faire, il va fournir une valeur x qui est au-delà des limites du tableau. Grâce à l’exécution spéculative, le processeur va tenter de récupérer la valeur située à l’adresse du tableau array1 plus x, car il va commencer à exécuter la ligne suivante. Plusieurs points sont importants à noter. Tout d’abord, il faut qu’une des données pour la comparaison (x et array1_size) ne soit pas en cache. Sinon, le processeur aurait déjà les informations pour comprendre qu’il ne faut pas prendre la branche voulue. De plus, pour que l’exécution spéculative puisse avoir lieu, l’attaquant va devoir « tromper » la prédiction de branchement dans le processeur en exécutant plusieurs fois cette partie du programme avec une valeur valide pour x. Il y a donc une phase d’entraînement à effectuer avant.
Supposons que le processeur récupère la valeur désirée (array2[array1[x]]) et que celle-ci soit mise dans le cache. Entre temps, le processeur a évalué la condition du if et détermine qu’il faut arrêter l’exécution spéculative. Le processeur remet les registres dans un état correct. Mais, la valeur que l’attaquant souhaite lire est encore accessible... En effet, le processeur a laissé des traces. En effectuant les traitements, la donnée est potentiellement toujours dans le cache !
Si l’attaquant essaie d’accéder à la valeur suivante :
Il y a de fortes chances que ce code s’exécute plus vite si la valeur array2[k] est dans le cache. L’attaquant n’a alors plus qu’à mesurer le temps d’exécution pour différentes valeurs et garder celle qui s’est exécutée en un temps comparable au temps d’accès au cache. L’attaquant a donc besoin d’une horloge assez précise pour y arriver.
Le code est ici extrêmement simplifié. Par exemple, si la lecture était faite de manière trop ordonnée, le processeur mettrait en cache toutes les données que nous lisons. La figure 2 présente le déroulement de l’attaque.
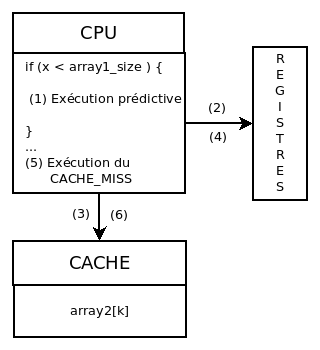
- (1) Exécution spéculative du code.
- (2) Les registres sont utilisés pour l’exécution.
- (3) Les données manquantes sont chargées en cache.
- (4) Lorsque le CPU se rend compte de son erreur, il réinitialise les registres et uniquement les registres.
- (5) L’attaquant exécute son test en tentant de récupérer la valeur.
- (6) Le cache est potentiellement accédé, confirmant la présence de la valeur en cache.
Si on résume, de quoi a besoin un attaquant pour réaliser le vol de données?
- Un processeur haute performance : les processeurs récents ont les fonctionnalités d’exécution spéculative et de prédiction de branchement.
- Un code s’exécutant sur la machine cible et plus précisément, dans le même espace mémoire (processus).
- Une horloge haute précision (de l’ordre de la nanoseconde). Il faut pouvoir mesurer le temps dû à l’échec de lecture de cache qui est très faible.
- Du code pouvant être détourné via l’exécution spéculative.
- Des données que l’on souhaite récupérer dans la mémoire du processeur.
Ah ! Mais dans un navigateur, tout est bien compartimenté, le code JavaScript est exécuté dans une « sandbox » et, de toute façon, c’est très lent, jamais on ne pourra détecter la branche prédite. Détrompez-vous ! Les applications web ont bien évolué depuis le dernier millénaire.
1.3 Plus de secrets dans le navigateur
Nos navigateurs ont en effet tout ce qu’il faut pour que la vulnérabilité associée à Spectre puisse être utilisée avec succès. Partons de l’hypothèse que votre ordinateur possède un processeur récent.
Pour le code JavaScript s’exécutant sur votre machine, on peut supposer que soit l’attaquant a réussi à vous attirer sur son site, soit un site sûr a chargé la page de l’attaquant, via une iframe. Mais, me direz-vous (enfin, je l’espère) que JavaScript est exécuté dans une « sandbox» ! Alors, oui, mais non ! La sandbox empêchera que le code accède à de la mémoire qui se trouve dans un espace d’adressage différent. Mais, l’iframe partage le même processus. À la fois pour des raisons d’économie de ressources, mais aussi, pour faciliter la communication entre iframes.
Quant à l’horloge, il est possible d’en « bricoler » une de haute précision en utilisant plusieurs API de JavaScript. Le principe est de partager une variable de type SharedArrayBuffer entre deux threads gérés via l’API worker. Un thread met à jour la valeur et un autre lit la valeur. On obtient ainsi une valeur avec une granularité suffisante pour faire office d’horloge.
Enfin, le code JavaScript peut être compilé à la volée. Notre navigateur peut, sous certaines conditions, transformer le code JavaScript en code machine grâce au compilateur JIT pour accélérer la vitesse de l’application web. Par exemple, asm.js est un sous-ensemble du code JavaScript qui est facilement transformé par le navigateur.
L’attaquant possède ainsi toutes les conditions requises pour pouvoir réussir à lire la mémoire de votre navigateur et ainsi, potentiellement récupérer des données intéressantes comme vos identifiants de session par exemple.
Face à cette situation, la réponse des éditeurs de navigateurs a, tout d’abord, été de désactiver SharedArrayBuffer. Mais, cette classe JavaScript est néanmoins utile. De plus, il est fort probable que ce type d’attaque puisse trouver d’autres manières de réussir l’exploitation de la vulnérabilité. Il a donc été nécessaire de trouver une parade durable à Spectre.
2. Impacts de Spectre sur l’architecture de nos navigateurs
La question que l’on peut se poser est comment faire face à une faille qui exploite une fonctionnalité matérielle, c’est-à-dire située au plus profond de nos ordinateurs. Bien que des micro-optimisations au niveau du code aient été apportées, il a été nécessaire de revoir en profondeur le modèle de sécurité des navigateurs. Les éditeurs de navigateurs web sont partis du postulat :
"We now assume any active code can read any data in the same address space. The plan going forward must be to keep sensitive cross-origin data out of address spaces that run untrustworthy code, rather than relying on in-process checks." [CHROMIUM]
En clair, il faut maintenant considérer que tout attaquant capable d’exécuter du code est aussi potentiellement capable d’accéder à toutes les données de cet espace mémoire.
2.1 Diviser pour mieux régner
Dans une approche sécurité par design, il a donc été décidé de donner la possibilité de séparer les sites entre eux. Chaque site peut ainsi s’exécuter dans un contexte de navigation particulier. Mais le navigateur a aussi plusieurs contraintes. Séparer les sites a d’abord un impact sur les performances du système. Plus de processus créés implique plus de mémoire utilisée, plus de latence dans les échanges, plus de temps au démarrage et dans certains cas, des communications entre sites impossibles (dans le cas des iframes par exemple). Il faut aussi assurer une compatibilité et éviter de casser Internet du jour au lendemain.
Pour permettre aux sites d’améliorer la sécurité, l’en-tête « Cross-Origin Opener Policy » a été créé. Cet en-tête permet au site de plus haut niveau d’indiquer s’il souhaite partager le même contexte d’exécution que les sites qu’il peut inclure. En ajoutant l’en-tête suivant dans la réponse du document chargé :
Si les autres sites inclus ont la même origine (au sens de la « Same Origin Policy »), alors ils s’exécuteront dans le même contexte, les autres sites ayant un contexte dédié. Il existe de nombreux cas pour lesquels un site a besoin de communiquer avec un autre (par exemple, avec un site faisant office de SSO). L’en-tête suivant autorise alors les autres sites à partager le même contexte s’ils sont ouverts dans un nouvel onglet ou pop-up :
Grâce à ça, un site incluant l’iframe d’un site malveillant ne partagerait pas le même espace mémoire. Les données sensibles du site ne seraient alors pas accessibles par le site de l’attaquant.
Vous trouverez sur l’excellent site « Mozilla Developer Network » de nombreuses informations sur cet en-tête [COOP].
2.2 Celui qui lit ça...
La deuxième étape dans l’amélioration de la sécurité des sites est d’empêcher le chargement de données en mémoire par le navigateur. Deux moyens sont fournis pour y arriver : CORB et CORP/COEP.
Imaginons qu’un attaquant, via une campagne de phising emmène une cible à accéder à un site qui contient le code HTML suivant :
Que va-t-il se passer ? Le navigateur va récupérer le fichier json, analyser le contenu et refuser d’afficher puisqu’il ne s’agit pas d’une image. Fin de l’histoire ? Et non, car, grâce à Spectre, un attaquant pourrait lire les données en mémoire même si elles ne sont pas accessibles normalement. Pour s’en prémunir, Chrome propose un mécanisme appelé CORB pour Cross-Origin Resource Blocker, actif par défaut. Il permet de bloquer le chargement de ressources chargées de manière illégitime. Si le type du fichier n’est pas spécifié dans un en-tête, le navigateur va télécharger le fichier et tenter de le « deviner ». Le fichier, potentiellement sensible, va se retrouver en mémoire et sera donc vulnérable à Spectre. Il est nécessaire de spécifier le type du fichier avec l’en-tête « Content-Type » et d’indiquer que le navigateur ne doit pas tenter de déterminer le type en incluant « X-Content-Type-Options : nosniff ». CORB ne bloquera plus le chargement de la ressource. Mais, si on reprend notre exemple, comme ce n’est pas une image, le navigateur interdira son chargement. Pour un rappel de tous ces en-têtes, je vous renvoie à [101].
Le deuxième mécanisme pour contrôler le chargement des données est deux nouveaux en-têtes. Tout d’abord, l’en-tête « Cross-Origin-Resource-Policy » permet à un site d’indiquer au navigateur qui peut accéder à ces ressources. L’en-tête « Cross-Origin-Embedder-Policy » sert à indiquer que seuls les sites spécifiant un mécanisme d’autorisation type CORP ou CORS peuvent être accédés.
Pour activer COEP, rien de plus simple, il suffit d’ajouter l’en-tête suivant au document chargé par le navigateur :
De même, pour mettre en œuvre CORP, il faut ajouter lors du chargement de toutes les ressources l’en-tête suivant :
Avec les différents en-têtes vus précédemment, vos sites résisteront à la classe de vulnérabilités à laquelle appartient Spectre. Nous avons ainsi vu qu’il existait de nombreuses évolutions qui vont être nécessaires d’ajouter pour protéger aux mieux nos applications web. Comment faire pour s’assurer que la configuration est correcte ?
3. Des outils !
Il existe plusieurs outils pour vous aider à mettre en œuvre les bonnes configurations de sécurité.
3.1 ZAP pour vous servir
OWASP ZAP est un scanner de sécurité pour les applications web. Il s’agit d’une application open source maintenue par de nombreux développeurs à travers le monde. Parmi les nombreuses fonctionnalités qu’il propose, ZAP analyse le site selon un ensemble de règles de sécurité. Et parmi ces règles ont été ajoutées la détection et l’aide à la configuration des en-têtes vues précédemment.
ZAP permet d’accéder à un site de plusieurs façons :
- en scannant un site de manière autonome (« scraping ») ;
- en configurant le navigateur pour qu’il accède au site en utilisant ZAP comme proxy web ;
- en utilisant une version instrumentée par ZAP du navigateur.
Une fois le site chargé, ZAP analyse les requêtes et les réponses à la recherche d’erreurs de configuration.

Pour faciliter les développements et la détection d’erreurs en amont, ZAP s’intègre de façon très simple dans une chaîne d’intégration continue :
Face aux évolutions constantes des menaces et des bonnes pratiques, vous aurez ainsi un outil capable de détecter les problèmes au plus tôt.
3.2 Chrome
Pour ne rien vous cacher, l’origine de mon intérêt pour ce sujet vient de l’apparition de fonctionnalités de debuggage qui sont apparues dans Chrome 83 en mars dernier [DEVTOOLS].

Par exemple, si vous activez l’en-tête COEP et que vous tentez d’accéder à un site qui ne met pas en œuvre CORP, vous obtiendrez le message d’erreur affiché en figure 5 dans l’onglet Network.

Enfin, pour conclure, en configurant correctement les différents en-têtes, Chrome autorise à nouveau l’usage de SharedArrayBuffer.
Conclusion
Comme nous l’avons vu, Spectre est une faille très subtile qui est toujours présente. Le problème se situant au cœur de nos systèmes, il n’est pas possible de la faire disparaître facilement. Malgré tout, en intégrant ce type de failles dans nos modèles de sécurité, nous avons la possibilité de concevoir des applications qui sont capables d’être résistantes à ce type d’attaque.
En termes de développement, cela ajoute une complexité supplémentaire qu’il est important de prendre en compte. Cela ne fait que renforcer l’importance d’instrumenter correctement nos processus de développement en y incluant des outils efficaces pour aider les équipes à sécuriser correctement les applications qu’elles construisent.
Rapidement après la présentation de la faille, les fondeurs de puces ont commencé à intégrer des protections matérielles et logicielles. Toutes les variations de l’attaque ne sont ainsi pas contrées au niveau matériel, mais il est cependant possible de la défaire au prix d’une dégradation des performances. Spectre a ainsi encore de beaux jours devant lui.
Remerciements
Je tiens à remercier tout particulièrement Didier BERNAUDEAU, Kevin H et Ronan pour leurs relectures et leurs remarques constructives.
Références
[WIKI] https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
[SPECTRE] Kocher, Paul ; Genkin, Daniel ; Gruss, Daniel ; Haas, Werner ; Hamburg, Mike ; Lipp, Moritz ; Mangard, Stefan ; Prescher, Thomas ; Schwarz, Michael ; Yarom, Yuval (2018). "Spectre Attacks: Exploiting Speculative Execution"
[CHROMIUM] https://chromium.googlesource.com/chromium/src/+/master/docs/security/side-channel-threat-model.md
[COOP] https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Opener-Policy
[COEP] https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Embedder-Policy
[CORP] https://developer.mozilla.org/en-US/docs/Web/HTTP/Cross-Origin_Resource_Policy_(CORP)
[101] https://connect.ed-diamond.com/MISC/MISC-101/Vos-entetes-HTTPS-avec-HELMET
[DEVTOOLS] https://developers.google.com/web/updates/2020/03/devtools


