

Le namespace mount, premier d'une longue série de namespaces a été ajouté à Linux quelques années après chroot() pour offrir plus de possibilités et de sécurité dans l'isolation des systèmes de fichiers. Introduit peu après et indéniablement plus simple, le namespace uts permet d'instancier les noms de machine. Les conteneurs sont bien entendu les premiers clients de ces fonctionnalités.
Utilisé conjointement avec la notion de propagation des points de montage, le mount namespace (mount_ns) est une solution extrêmement flexible pour isoler tout ou partie du système de fichiers. Le namespace uts (uts_ns), d'une utilisation plus aisée, donne la possibilité de voir la machine sous différents noms afin d'en simuler plusieurs. Ces deux mécanismes sont bien entendu avant tout destinés aux conteneurs tels que LXC.
Le code de cet article est disponible sur http://www.rkoucha.fr/tech_corner/linux_namespaces/linux_namespaces.tgz.
1. Le namespace MOUNT
Premier namespace implémenté dans le noyau Linux, le namespace MOUNT isole les points de montage dans le système de fichiers. Une entrée est dédiée à ce namespace dans le manuel en ligne de Linux : man 7 mount_namespaces.
1.1 Création
À la création du namespace, la liste des points de montage est la copie de celles du mount_ns du processus appelant unshare() ou clone(). Ensuite, les processus associés à un mount_ns donné peuvent ajouter ou retirer des points de montage. Pour un processus d’identifiant pid, les points de montage vus de son mount_ns sont consultables dans le répertoire /proc/<pid> (cf. man 5 proc) via ces entrées :
- mounts : liste des systèmes de fichiers montés ;
- mountinfo : amélioration du précédent fichier avec prise en compte des types de propagation et des bind mounts ;
- mountstats : statistiques et informations de configuration sur les points de montage.
1.2 Types de propagation
Exécutons un sous-shell dans un nouveau mount_ns avec notre commande shns. Nous prenons soin de positionner la variable d’environnement PS1 de sorte à différencier le prompt de celui du shell initial, dans le but de faciliter la lecture des copies d’écran. Puis lançons la commande lsblk :
Insérons une clé USB et relançons la commande lsblk pour voir quel nouveau périphérique apparaît pour la contrôler. Ici, c’est /dev/sdd1 :
Comme c’est le cas ici sur /media, la clé peut être montée automatiquement dans les deux mount_ns. Si c’est le cas, démontons-la :
Le démontage dans l’un des mount_ns se répercute dans l’autre. En effet, dans un autre terminal (c.-à-d. le mount_ns initial), nous ne voyons plus le montage non plus :
Montons la clé sur un autre répertoire comme /mnt à partir du sous-shell :
La commande df montre que la clé est aussi montée dans le shell initial :
Un montage ou un démontage dans un nouveau mount_ns se propage donc sur le mount_ns initial.
C’est un fonctionnement qui peut avoir ses avantages comme ses inconvénients quand on parle d’isolation. En effet, on pourrait vouloir ce fonctionnement ou au contraire éviter qu’un montage dans un conteneur se voie côté hôte. Tout dépend des besoins.
Cela a été anticipé (ou plutôt rectifié, comme le dit le manuel) : les mount_ns qui offraient une trop grande isolation au départ ont été assouplis avec l’ajout de la notion de type de propagation des événements. Le fichier /proc/<pid>/mountinfo permet de voir cette valeur avec sa propre terminologie (cf. man 7 mount_namespaces à la rubrique « SHARED SUBTREES ») au niveau du septième champ des lignes affichées (situé juste avant le tiret, il peut être vide ou renseigné). Dans notre cas de figure, le contenu de ce fichier dans le sous-shell indique la valeur « shared » :
L’explication détaillée nécessiterait un article fastidieux. Pour cet exposé, nous nous contenterons de dire que le type de propagation détermine comment les montages/démontages sur les répertoires situés directement sous un point de montage donné sont propagés. Pour plus d’informations, il convient de se référer à la documentation du noyau [1] et [2]. Il s’agit d’un drapeau qui peut prendre l’une de ces valeurs :
- MS_SHARED : ce point de montage partage ses montages/démontages avec les autres membres de son groupe ;
- MS_PRIVATE : ce point de montage ne partage pas ses montages/démontages ;
- MS_SLAVE : les montages/démontages se propagent sous ce point de montage de la part d’un groupe maître. Par contre, ce point de montage ne partage pas les montages/démontages dans l’autre sens. C’est un compromis entre MS_SHARED et MS_PRIVATE ;
- MS_UNBINDABLE : en plus d’être MS_PRIVATE, ce point de montage ne peut pas être « bindé » (drapeau MS_BIND que nous verrons dans la suite).
Le drapeau est passé à l’appel système mount() dans le paramètre « mountflags » (cf. quatrième argument dans man 2 mount). Il est même possible d’appliquer les drapeaux précédents à toute une arborescence sous un point de montage en ajoutant le drapeau MS_REC (c.-à-d. récursif). L’article [3] présente quelques cas concrets.
Ces drapeaux sont aussi proposés par la commande mount du shell à travers des options sur sa ligne de commande décrites dans la rubrique « Shared subtree operations » de man 8 mount : --make-shared, --make-private, --make-slave et --make-unbindable. Pour l’aspect récursif, ces options se déclinent avec l’ajout d’un « r » dans le nom : --make-rshared, --make-rprivate, --make-rslave et --make-runbindable.
Dans l'exemple ci-dessus, où la clé USB montée dans le mount_ns du sous-shell est aussi vue dans le mount_ns initial, s’explique par le fait que le répertoire / dans le mount_ns initial a le drapeau MS_SHARED (c’est la signification de la valeur « shared:1 » retournée par l’affichage de mountinfo).
La liste des points de montage de tout nouveau mount_ns étant la copie de celle du mount_ns du processus qui le crée, nous avons les mêmes propriétés dans le sous-shell :
À partir du sous-shell, démontons la clé USB (l’action se propage aussi au namespace initial), puis changeons le type de propagation MS_SHARED de / en MS_SLAVE avec l’option idoine de la commande mount :
Nous vérifions que le type de propagation sur le mount_ns initial n’a pas changé (c.-à-d. shared) :
Avec l’opération mount précédente, nous avons indiqué que le point de montage / dans le mount_ns du sous-shell est l’esclave du point de montage / dans le mount_ns initial. Donc, un montage sur /mnt dans le sous-shell ne se propage plus dans le mount_ns initial :
On vérifie que dans le mount_ns initial, la clé USB n’est pas vue sur /mnt :
Démontons la clé USB dans le sous-shell :
Un montage/démontage dans le mount_ns initial sera propagé dans le mount_ns du sous-shell. Pour le vérifier, montons la clé dans le mount_ns initial :
Si nous lançons df dans le sous-shell, on voit aussi la clé USB :
Nous pouvons démonter la clé côté sous-shell, elle restera montée dans le namespace initial. Par contre, si nous la démontons côté mount_ns initial, elle sera aussi démontée côté sous-shell. Nous avons ainsi mis en pratique le cas d’un point de montage en mode esclave : les montages/démontages se propagent sur lui, par contre il ne les propagent pas dans le sens inverse.
Pour les exemples précédents, nous avons utilisé notre programme shns au lieu de la commande unshare, car l’option -m de cette dernière déclenche l’appel système mount() avec les drapeaux MS_REC|MS_PRIVATE sur / entre l’appel à unshare(CLONE_NEWNS) et l’exécution de la commande. Il suffit de lancer la commande sous le contrôle de strace pour s’en convaincre :
En d’autres termes, tous les points de montage de l’arborescence sont « privatisés » dans le nouveau mount_ns. Par conséquent, tout montage/démontage dans le sous-shell n’est pas propagé dans le mount_ns initial et inversement, les montages/démontage dans le mount_ns initial ne se propagent pas dans le sous-shell. Dans le fichier mountinfo, le septième champ des lignes (situé juste avant le tiret) est vide dans ce cas :
Il est en réalité possible de changer ce comportement par défaut de la commande unshare avec l’option --propagation, plus facile à comprendre maintenant que la notion de type de propagation a été présentée (cf. [3] pour les exemples d’utilisation).
Le système de fichiers du conteneur LXC busybox est monté en mode esclave sur tous les points de montage de l’arborescence (c.-à-d. MS_REC|MS_SLAVE). Lançons le conteneur bbox comme indiqué dans l’encadré du premier article de notre série et affichons le contenu de mountinfo dans sa console :
Le système de fichiers du conteneur, préparé par le template busybox lors de l’appel à lxc-create, est créé dans /var/lib/lxc/bbox/rootfs. Si nous montons une clé USB sur le répertoire /var/lib/lxc/bbox/rootfs, du côté hôte :
Cette clé sera vue dans /mnt côté conteneur conformément à la propagation MS_SLAVE positionnée :
Démontons la clé USB côté conteneur :
Elle reste montée côté hôte :
Après la notion de type de propagation des événements de montage/démontage, un autre besoin se fait sentir au niveau des conteneurs : le partage partiel du système de fichiers avec l’hôte.
1.3 Bind mount
Un conteneur démarrant avec son propre mount_ns a au départ la copie de la liste des points de montage de l’hôte. En d’autres termes, le rootfs de l’hôte est partagé avec le celui du conteneur. Mais les conteneurs font le plus souvent un pivot_root(), variante plus sûre de chroot(), pour avoir leur propre rootfs dans un sous-arbre du système de fichiers de l’hôte. Par exemple, le conteneur busybox de LXC « localise » son rootfs dans le sous-arbre /var/lib/lxc/<nom_conteneur>/rootfs (créé au moment de l’appel à lxc-create). La figure 1 illustre cela pour bbox.

Affichons sur l’hôte le contenu de ce répertoire :
La configuration LXC pour ce conteneur spécifie ce chemin comme rootfs :
À l’appel de lxc-start, le conteneur bbox a sa racine située à cet endroit. Son contenu est donc le même, mais dans un nouveau mount_ns :
La commande lxc-create a renseigné le fichier de configuration et tous les répertoires. En particulier /bin avec l’exécutable busybox et les applets en liens symboliques :
Mais ce serait un gaspillage de place de copier les nombreuses librairies généralement situées dans /lib ou /usr/lib (libc, libc++...) dans les mêmes répertoires côté conteneur (c.-à-d. dans /var/lib/lxc/bbox/rootfs/lib et /var/lib/lxc/bbox/rootfs/usr/lib).
D’où l’utilisation du mécanisme de « bind mounting » [4] qui consiste à voir un répertoire ou un fichier donné à un autre endroit dans le système de fichiers. Il s’agit du drapeau MS_BIND (aperçu en section précédente) passé dans les options de l’appel système mount(). Pour un conteneur, il est possible de dire qu’on veut voir certains sous-arbres de l’hôte dans le rootfs à l’aide du mot-clé « bind » dans l’option de configuration lxc.mount.entry. C’est un mount() avec MS_BIND qui se cache derrière.
La configuration LXC pour le conteneur bbox spécifie que les répertoires sur hôte comme /lib et quelques autres sont « bind-montés » dans son rootfs :
D’où la vision côté conteneur des fichiers de l’hôte dans ces répertoires. Par exemple, le premier lxc.mount.entry dans la copie d’écran précédente indique que /lib sur hôte est « bind-monté » sur lib dans le répertoire racine côté conteneur. On a aussi pris soin de spécifier le mode « lecture seulement » (c.-à-d. ro) pour ne pas altérer les fichiers de l’hôte à partir du conteneur :
Cela implique bien sûr que toute modification des fichiers dans ces répertoires côté hôte (suite à une mise à jour système, par exemple) sera répercutée de manière transparente dans le conteneur, car le principe du « bind montage » fait que ce dernier a exactement la même vue sur le contenu de ces répertoires.
Dans lxc-start, les « bind-montages » ont lieu avant le pivot_root(), période pendant laquelle la commande a la vue sur le rootfs de l’hôte. Mais ces montages restent valides après, car le manuel de mount() précise bien qu’ils peuvent traverser les différents systèmes de fichiers (les points de montage) et les chroot() (cela comprend les pivot_root()) :
La figure 2 représente les « bind-mounts » dans le conteneur bbox.
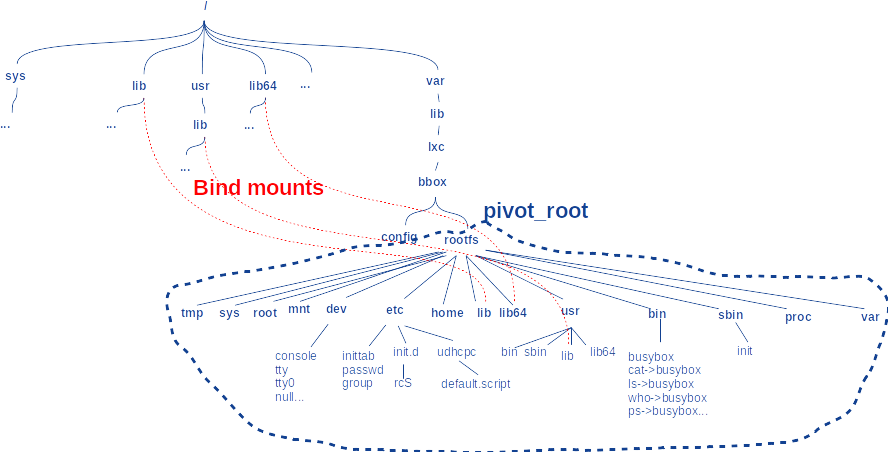
En résumé, le mécanisme de « bind-mount » donne la possibilité au système hôte de partager des parties de son système de fichiers avec les conteneurs.
1.4 Les namespaces de la commande ip
Lors de l’étude de la commande ip et notamment de son objet netns, nous avons vu qu’il est possible de créer de nouveau network namespace (net_ns) ou de s’attacher à des net_ns existants. Nous avons vaguement évoqué la notion de « bind montage » pour expliquer comment la commande s’est attachée au net_ns d’un conteneur LXC. Nous pouvons maintenant expliquer plus précisément le principe de la commande ip netns attach <name> <pid> utilisée. Le but de cette commande est d’attacher un nom <name> à un net_ns existant auquel un processus d’identifiant <pid> est associé (par exemple, le processus init d’un conteneur) :
1. Création du répertoire /run/netns où seront créés les noms des namespaces au sens de la commande ip : mkdir("/run/netns", S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH|S_IXOTH) ;
2. « Bind montage » du répertoire /run/netns sur lui-même afin d’en faire un point de montage : mount("/run/netns", "/run/netns", "none", MS_BIND | MS_REC, NULL) ;
3. Positionnement du type de propagation en MS_SHARED : mount("", "/run/netns", "none", MS_SHARED | MS_REC, NULL) ;
4. Création du fichier qui servira de nom au namespace au sens de la commande ip : open("/run/netns/<name>", O_RDONLY|O_CREAT|O_EXCL, 0) ;
5. « Bind montage » du lien symbolique du net_ns du processus cible sur le fichier précédent : mount("/proc/<pid>/ns/net", "/run/netns/<name>", "none", MS_BIND, NULL).
Pour la création d’un net_ns avec la commande ip netns add name, les étapes 1 à 4 sont les mêmes que précédemment, puis on ajoute l’appel à unshare() pour créer le namespace et un « bind montage » de /proc/self/ns/net sur /run/netns/<name>. À partir de l'étape 5, nous avons donc :
[...]
5. unshare(CLONE_NEWNET) ;
6. mount("/proc/self/ns/net", "/run/netns/<name>", "none", MS_BIND, NULL).
Ainsi, la liste des net_ns auxquels la commande ip a associé un nom est la liste des fichiers dans le répertoire /run/netns. La commande ip netns list affiche le contenu de ce répertoire :
Les fichiers de ce répertoire sont donc des « bind montages » des cibles (dans le système de fichiers NSFS vu dans [5]) des liens symboliques /proc/<pid>/ns/net associés aux net_ns. On les voit dans le fichier mountinfo, même si le noyau n’affiche pas explicitement le mot « bind » :
La figure 3 schématise le résultat des actions précédentes. La cible du fichier /proc/<conteneur_init_pid>/ns/net est « bind-monté » sur /run/netns/bbox_nsnet. Les deux autres namespaces (other et net2) ont été créés de toute pièce par des processus exécutant ip netns add. Ces deux processus ont disparu à la fin des commandes ip correspondantes, mais le « bind-montage » empêche les net_ns de disparaître. La commande ip netns del démontera les fichiers et provoquera implicitement la disparition des net_ns non liés à un processus.
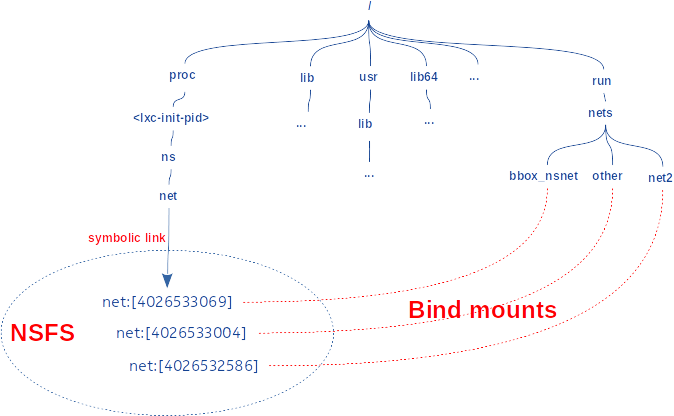
Ainsi, pour effectuer des actions dans un net_ns auquel est associé un nom, la commande ip n’aura plus qu’à ouvrir le fichier associé dans /run/netns. Ce dernier étant un point de « bind montage » de la cible du lien symbolique du namespace, le descripteur de fichier qui en résulte peut être passé à l’appel système setns() pour entrer dans le namespace correspondant.
1.5 Émulation de terminal dans LXC
Lorsqu’un conteneur émule un système GNU/Linux minimum sans interface graphique, il peut mettre en œuvre des terminaux physiques (tty) sur lesquels tournent des processus getty pour gérer les connexions des utilisateurs. Lorsqu’un utilisateur saisit son nom d’utilisateur, getty exécute le programme login pour gérer la saisie du mot de passe et exécuter le shell associé à l’utilisateur dans le fichier /etc/passwd.
Dans un conteneur LXC, le nombre de terminaux est configurable avec le paramètre lxc.tty.max. Par exemple, le conteneur busybox a un terminal :
Le fichier /etc/inittab est configuré pour demander au processus init de lancer un getty sur ce terminal :
Pour se connecter au terminal, il suffit de spécifier son numéro sur la ligne de commande de lxc-console (dans la copie d’écran précédente, on s’est connecté sur la console de numéro 0) et utiliser root comme nom d’utilisateur (défini par défaut par le template passé à lxc-create). Mais comme son mot de passe n’est pas défini, il faut lui en attribuer un via la console :
Ensuite, on peut se connecter via le terminal numéro 1 :
Dans les faits, un conteneur n’a pas de périphérique terminal, car ces derniers sont attribués au système hôte. Pour pallier ce manque, LXC monte un système de fichiers devpts dans le conteneur (dimensionné avec un nombre de pty spécifié par le paramètre de configuration lxc.pty.max) et effectue un « bind montage » des pseudo-terminaux /dev/pts/<x> (pty) sur le fichier /dev/tty<x+1>. Par exemple :
Pour la console du conteneur, c’est aussi un « bind montage », mais c’est fait avant le pivot_root() et avec le premier pseudo-terminal libre sur l’hôte au moment du démarrage du conteneur. Par exemple, si le premier pty libre est le numéro 6 lors de l’appel à lxc-start, LXC va effectuer le montage suivant sur l’hôte :
Comme on l'a dit plus haut, ce montage est persistant après le pivot_root().
Le fichier mountinfo dans le conteneur se présente comme suit pour les terminaux :
Le fichier /dev/console est « bind monté » sur /dev/pts/6 (côté hôte !), le fichier /dev/tty1 est « bind monté » sur /dev/pts/0 (côté conteneur !) dans le système de fichier devpts monté à cet effet (dimensionné par le paramètre de configuration lxc.pty.max).
Nous n’allons pas entrer plus que cela dans les détails de la gestion des terminaux dans LXC, sous peine de nous égarer. Nous nous contentons de dire que lxc-console se connecte aux terminaux ainsi configurés via le superviseur du conteneur (processus [lxc monitor]) qui garde en interne des descripteurs de fichiers ouverts sur les terminaux du conteneur. L’option -t permet de choisir le terminal sur lequel on se connecte (0 pour la console, 1 pour le tty1 et ainsi de suite). La figure 4 schématise la configuration du conteneur bbox :

1.6 Montage hors namespace initial
Comme nous l’avons vu, un namespace est la propriété d’un namespace user (user_ns). Pour des raisons de sécurité, si le user_ns n’est pas initial, il y a des restrictions sur certaines opérations et en particulier les montages de systèmes de fichiers [6], même si l’utilisateur est privilégié dans le namespace.
Dans le noyau Linux (version 5.3.0 ici), un drapeau a été introduit dans le fichier include/linux/fs.h afin d’indiquer si un système de fichiers peut être monté ou pas dans un user_ns non initial :
L’appel système mount() défini dans fs/namespace.c aboutit à l’appel d’une fonction de service interne mount_capable() localisée dans fs/super.c :
La fonction est chargée de déterminer si l’utilisateur appelant a la capacité CAP_SYS_ADMIN pour effectuer l’opération de montage :
- si le système de fichiers à monter n’a pas le drapeau FS_USERNS_MOUNT, la fonction vérifie la capacité dans le user_ns initial. Autrement dit, si l’appelant n’est pas le super utilisateur au démarrage du système, il n’aura en général pas le droit de faire le montage ;
- si le système de fichiers à monter a le drapeau FS_USERNS_MOUNT, la fonction vérifie la capacité dans le user_ns courant de l’utilisateur. Dans ce cas, il suffira à l’appelant d’être super utilisateur dans cet user_ns pour avoir le droit d’effectuer le montage (et même s’il correspond à un utilisateur ordinaire dans le user_ns supérieur, via la fonction de mapping vue dans l’étude des user_ns !).
Au départ assez restreinte, une recherche rapide dans les sources du noyau montre que la liste des systèmes de fichiers autorisés à être montés dans les user_ns non initiaux s’est étoffée. Nous pouvons citer entre autres : cgroup, cgroup2, cpuset, proc, ramfs, devpts, ext2, ext3, ext4, fuse, aufs, sysfs, shiftfs, overlay, mqueue, binder et tmpfs.
2. Le namespace UTS
Ce namespace isole deux identifiants : le nom de nœud et le nom de domaine. Ce sont respectivement les champs nodename et domainname de la structure utsname renseignée par l’appel système uname(). Ces informations peuvent être modifiées par les services sethostname() et setdomainname(). Le nom « uts » n’est pas très explicite, voire trompeur, car il est l’acronyme de « Unix Time Sharing ». C’est une réminiscence du système UNIX reconduite dans Linux. Dans le code source du noyau, nous la retrouvons pour tout ce qui touche à l’identification du système : UTS_RELEASE, UTS_VERSION, UTS_MACHINE...
Le nom de domaine trouvait son utilité dans le service NIS (auparavant Yellow pages) de la société Sun Microsystem [7], mais ce service a été supplanté par LDAP et DNS. Il n’est plus très utile de nos jours. Par contre, le nom de nœud (ou machine) est encore très usité. Il sert d’alias pour l’adresse internet de la machine.
Nous avons par exemple vu dans [8] que le script template lxc-busybox utilise le nom du conteneur (option -n des commandes) comme nom de machine (paramètre de configuration lxc.uts.name). Le fichier de configuration est en général visible dans /var/lib/lxc/<nom_de_conteneur>/config :
Le programme d’exemple setnshost reçoit en paramètres l’identifiant et un nom de machine à positionner dans l’uts_ns d’un processus cible. L’outil migre dans le namespace en invoquant setns() avec le descripteur de la cible du lien symbolique correspondant (c.-à-d. /proc/<pid_processus_cible/ns/uts), puis appelle sethostname() avec le nom demandé :
On peut ainsi modifier le nom de machine d’un conteneur en passant l’identifiant de son processus init à setnshost. Vérifions tout d’abord le nom de machine courant dans le conteneur bbox :
Dans un autre terminal, renommons le nom de l’hôte du conteneur en foo (à ne pas confondre avec le nom du conteneur qui restera bbox !) en prenant soin de vérifier avant et après que le nom côté hôte (ici, c’est rachid-pc) ne change pas :
Dans le conteneur, affichons le nom de l’hôte pour vérifier la modification (un appui sur <Return> convient aussi vu que le nom de l'hôte est affiché dans le prompt) :
Toutes les informations de la structure new_utsname, vue lors de l'étude des namespaces dans le noyau [9], sont exportées en espace utilisateur via /proc/sys/kernel :
L’implémentation est dans le fichier kernel/utsname_sysctl.c :
Tous les champs sont accessibles en lecture (mode égal à 0444) et deux (hostname et domainname) sont en plus modifiables par le super utilisateur (mode égal à 0644). L’accès à ces fichiers déclenche la fonction proc_do_uts_string(). Cette dernière obtient l’adresse du champ désiré de la structure new_utsname de l’uts_ns de la tâche courante en appelant la fonction get_uts() :
Il est par conséquent possible de consulter le fichier /proc/sys/kernel/hostname du côté hôte pour avoir la valeur dans le namespace initial :
Tandis que côté conteneur, l’affichage correspond à ce qui a été modifié par notre programme :
Les valeurs de domainname et hostname sont ainsi consultables et modifiables dans /proc au lieu de passer par les appels système.
Le bémol de cette seconde méthode tient au fait que /proc/sys est un répertoire sensible du point de vue des données qu’il exporte (nous le soulignerons aussi lors de l’étude des namespaces ipc). Dans le contexte d’un conteneur, /proc/sys est souvent monté en lecture seule pour raisons de sécurité. La modification directe des fichiers /proc/sys/kernel/{hostname,domainname} est donc en général impossible. D’où l’intérêt de passer par les appels système sethostname() et setdomainname() qui modifient les champs nodename et domainname dans la structure new_utsname pointée par le nsproxy de la tâche appelante, sans avoir à passer par le système de fichiers. Le code source de sethostname() se présente en effet comme suit dans le fichier kernel/sys.c du noyau :
La fonction interne utsname(), définie dans include/linux/utsname.h, retourne un pointeur sur la structure new_utsname référencée par le nsproxy de la tâche courante :
En résumé, sethostname() et setdomainname(), bâtis sur le même algorithme, modifient respectivement les champs current->nsproxy->uts_ns->name.nodename et current->nsproxy->uts_ns->name.domainname après avoir vérifié que l’utilisateur a la capacité CAP_SYS_ADMIN (apanage du super utilisateur, en général).
Conclusion
En donnant la possibilité de voir et d’isoler certaines parties de l’arborescence des fichiers du système grâce aux différents types de propagation et le mécanisme de « bind montage », les mount_ns permettent d’optimiser au mieux l’empreinte et la sécurité du système de fichiers des conteneurs. En plus des conteneurs, des commandes comme ip bénéficient de ces fonctionnalités.
L’uts_ns, le plus simple des namespaces, permet de nommer les conteneurs de sorte à différencier les machines émulées sur le système.
Références
[1] Les sous-arbres partagés : https://www.kernel.org/doc/Documentation/filesystems/sharedsubtree.txt
[2] Mount namespaces and shared subtrees : https://lwn.net/Articles/689856/
[3] Mount namespaces, mount propagation, and unbindable mounts : https://lwn.net/Articles/690679/
[4] Mount namespaces and shared subtrees : https://lwn.net/Articles/689856/
[5] R. KOUCHA, « Le fonctionnement des namespaces dans le noyau », GNU/Linux Magazine no245, février 2021 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-245/Le-fonctionnement-des-namespaces-dans-le-noyau
[6] Filesystem mounts in user namespaces : https://lwn.net/Articles/652468/
[7] Network Information Service : https://en.wikipedia.org/wiki/Network_Information_Service
[8] R. KOUCHA, « Les namespaces ou l'art de se démultiplier », GNU/Linux Magazine no239, juillet/août 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-239/Les-namespaces-ou-l-art-de-se-demultiplier
[9] R. KOUCHA, « Les structures de données des namespaces dans le noyau », GNU/Linux Magazine no243, décembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-243/Les-structures-de-donnees-des-namespaces-dans-le-noyau
