

Comment fonctionne StopCovid ? Quels sont les problèmes ? À quels risques s’expose-t-on ? Dans cet article, nous tentons d’éclaircir ces questions et de nourrir quelques réflexions sur l’usage du numérique.
L'application StopCovid a été annoncée le 14/04/2020, votée le 27/05/2020 et est disponible depuis le 02/06/2020 [1]. Elle est basée sur le protocole ROBERT, proposé par l'équipe de recherche PRIVATICS de l'Inria, puis développée et opérée par un consortium public/privé. Que ce soit au niveau médiatique, politique ou scientifique, ce chantier génère de nombreux débats et controverses, qui illustrent l'absence de consensus sur le sujet. Au niveau scientifique, des chercheurs sont en effet porteurs du projet initial ROBERT (et soutenus par des collègues), tout comme d'autres chercheurs sont très critiques sur cette approche (pétition Attention-StopCovid [2] signée par 155 académiques spécialistes du domaine et 317 informaticiens d'autres spécialités, analyse Risques-Traçage [3]). Dans cet article, nous dressons un panorama (personnel et incomplet, mais néanmoins le plus objectif possible) du fonctionnement et des critiques autour de ce projet. Par transparence, je précise que je n'ai aucune implication dans ROBERT/StopCovid et que je suis signataire de Attention-Stopcovid.
1. ROBERT
StopCovid est le nom de l'implémentation officielle du protocole ROBERT. ROBERT est un protocole, une spécification théorique de haut niveau d'abstraction décrite par l'équipe PRIVATICS de l'Inria ; StopCovid est ensuite une implémentation déployée, portée par un consortium public/privé. Son objectif est d'identifier les contacts longs (plus de 15 minutes) et proches (moins d'un mètre). Cette détection est basée sur l'émission en broadcast et l'écoute d'identifiants transmis en Bluetooth (BLE) entre smartphones. Dans cette section, nous décrivons de manière très synthétique le fonctionnement de ROBERT, illustré sur la figure 1. La spécification complète est disponible en ligne [4].
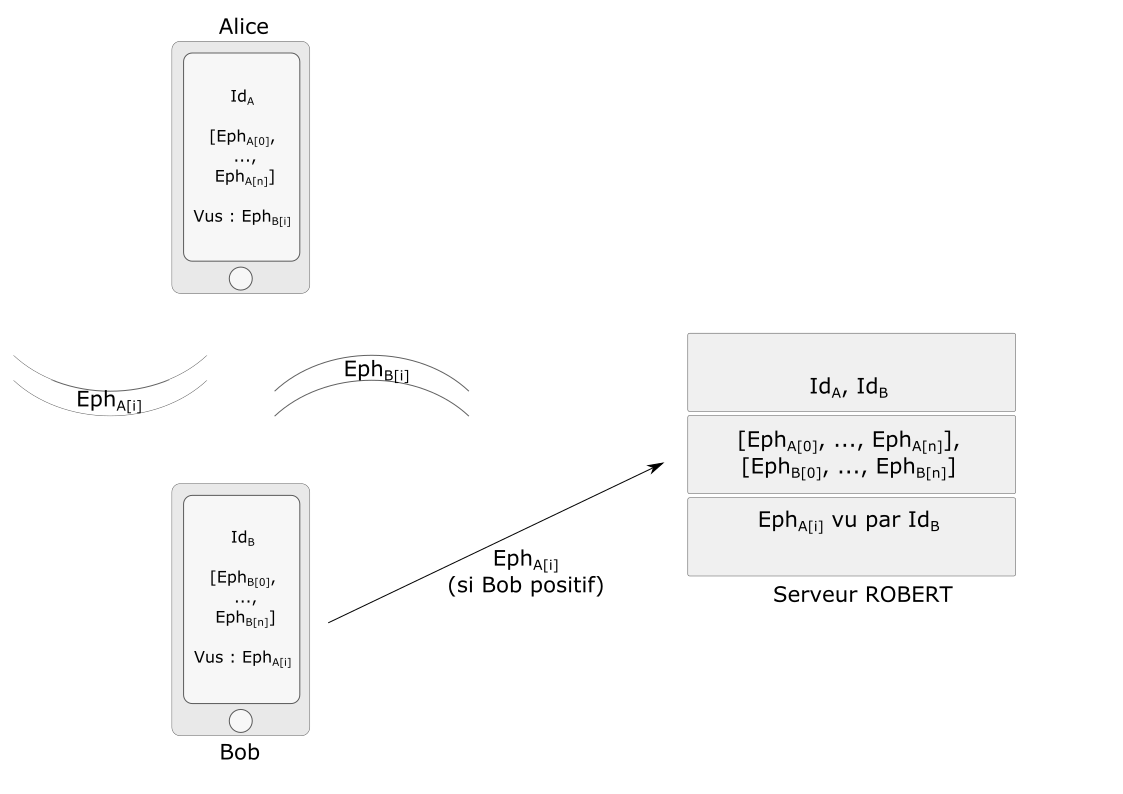
Cet exemple est composé de deux utilisateurs Alice et Bob et du serveur ROBERT. Le schéma décrit la connaissance de chacun des acteurs. Ainsi, Alice (A) connaît par exemple son identifiant long-terme (IdA), une liste d'identifiants éphémères personnels fournis par le serveur ([EphA[0], ..., EphA[n]]) qui seront émis successivement en BLE (lors de la période i, Alice émettra l'identifiant EphA[i]) et une liste d'identifiants tiers reçus caractérisant les autres utilisateurs rencontrés (EphB[i] caractérisant le fait d'avoir rencontré Bob lors de la période i). Le serveur quant à lui connaît les identifiants longs-termes de tous les utilisateurs, les identifiants éphémères de tous les utilisateurs et, pour les utilisateurs qui se déclarent Covid+ dans l'application, les identifiants éphémères des autres utilisateurs rencontrés. Dans l'exemple, Bob a été testé positif et remonte ainsi au serveur qu'il a vu EphA[i], charge ensuite au serveur de possiblement prévenir Alice.
Durant ce processus, ROBERT vise notamment les objectifs de privacy suivants :
- Le serveur ne doit pas pouvoir associer les EphA[i] (et donc IdA) avec l'identité physique d'Alice, ce qui suppose des communications anonymes. S'il le pouvait, l'autorité gérant le serveur aurait la possibilité, en utilisant un scanner BLE même de manière ponctuelle (lors d'un événement, d'une manifestation, etc.), d'identifier nommément les personnes à proximité de manière non détectable.
- Le serveur ne doit pas pouvoir reconstruire la liste des utilisateurs rencontrés par Bob lorsqu'il remonte ses contacts, protection qui peut être obtenue par l'usage de mixnets (qui mélangeraient les remontées de différents utilisateurs positifs). S'il le pouvait, il pourrait reconstituer des parties du graphe social physique des citoyens.
- Un utilisateur qui se déclare positif ne doit pas pouvoir être reconnu par ceux qui l'ont croisé précédemment, autrement dit en cas d'alerte l'utilisateur alerté ne doit pas savoir de qui vient l'alerte. S'il le savait, cela pourrait mener à des discriminations au sein de la population.
- Pour limiter toute fuite de données potentielle (étatique, commerciale), le serveur doit collecter le minimum d'informations (minimisation). Toute fuite d'information donnerait de larges connaissances sur les interactions physiques entre les citoyens.
StopCovid [5], enfin, est une implémentation de ROBERT avec un serveur, un client iOS et un client Android. C'est bien StopCovid, avec ses limites, et non ROBERT qui importe puisque c'est le code qui est effectivement utilisé. Comme nous le voyons dans la suite, StopCovid est évidemment une implémentation imparfaite et incomplète de sa spécification ROBERT, que ce soit par manque de temps, par impossibilité pratique d'implémenter certaines attentes de ROBERT de manière satisfaisante ou par surplus de métadonnées dues au fonctionnement réel d'Internet.
2. Les manques de l'implémentation, aka la dure réalité
Dès la publication de l'application, des manques sont apparus par rapport à la spécification. L'application est certes fonctionnelle, mais ces manques sont de nature à remettre en cause les objectifs de privacy précédemment décrits.
2.1 Risque de réidentification des utilisateurs
Une large part de l'effort du protocole ROBERT est d'utiliser des pseudonymes, c'est-à-dire que le serveur ne doit pas savoir à quelle personne physique correspond un identifiant, long-terme ou temporaire. L'usage de communications internet rend, en pratique, ce point difficile, chaque paquet reçu contenant les informations techniques adresse IP et port source. En effet, et cela est par exemple utilisé de manière automatique par l'HADOPI, une adresse IP et un port source correspondent, à un instant donné, à un abonné unique (et donc une personne). La collecte d'adresses IP est ainsi largement encadrée, car il s'agit de l'information à caractère personnel la plus classique dans les communications internet.
ROBERT passe ce point sous silence, l'implémentation du serveur a déclaré s'interdire de lire ce champ [6], ce qui pour les sceptiques illustre bien le risque reconnu de ces données. Cependant, dans le même temps, ces données sont classiquement journalisées par les équipes de sécurité, pour pouvoir investiguer en cas d'attaque : les opérateurs de StopCovid ont fini par admettre collecter ces données dans une réponse à un ticket [7], ce qui a ensuite été confirmé et pointé par la CNIL [8]. La CNIL a, depuis, levé cette mise en demeure, annonçant être satisfaite des réponses apportées, mais sans que cette collecte reconnue toujours présente ne soit documentée publiquement.
Ce point est assez révélateur, car il fait apparaître un manque de coordination et de cohérence entre les équipes. Comme pointé par la CNIL, l'étude d'impact et la transparence doivent porter sur l'ensemble du système, bien au-delà de la simple application serveur, en incluant tous les systèmes de sécurité, de répartition de charge, etc. Aujourd'hui, les parties périphériques sont hors du périmètre open source et donc totalement opaques. De manière positive, nous pouvons aussi constater que, une fois le problème clairement pointé, il a fini par être reconnu, plutôt que de mentir explicitement. Cela est donc rassurant sur l'honnêteté des personnes, aujourd'hui, aux commandes, mais perfectible par le manque de proactivité.
2.2 Absence de mixnets
Lorsqu'une personne est diagnostiquée positive, elle peut choisir de remonter la trace de ses rencontres. Pour des raisons de privacy, il est souhaitable que le serveur ne puisse pas relier l'ensemble des identifiants des rencontres : cela donnerait une trace des rencontres et ainsi une partie du graphe social physique. Ce problème est bien pris en compte dans la spécification ROBERT puisqu'il y est mentionné que la remontée doit avoir lieu via un mixnet. Schématiquement, un mixnet permet de mélanger les remontées de différents utilisateurs avant leur arrivée au serveur, ce qui empêche le serveur de savoir quels identifiants sont liés à une même alerte.
La notion de mixnet date de 1979 [9]. Ce problème a beau avoir 40 ans, il pose toujours de nombreuses difficultés pratiques. Au-delà de la complexité et charge de communication, de nombreux paramètres (combinaisons, délais, etc.) doivent être pris en compte pour satisfaire les attentes liées à une application particulière. Ainsi, même si les applications de routage en oignon comme Tor sont parfois vues comme les implémentations de mixnets les plus répandues, elles remplissent en fait un rôle d’anonymisation plus que de mélange et ne satisfont pas toutes les contraintes de ROBERT : Tor ne rajoutant pas de délai artificiel, le serveur saurait toujours quels identifiants remontés sont liés à une même alerte. Les mixnets font ainsi partie de ces constructions académiques intéressantes en théorie, mais implémentées tellement rarement qu'elles permettent souvent de cacher des difficultés fondamentales sous le tapis.
En l’occurrence, ici, face à un vrai problème reconnu (le lien dans une trace de contacts), les auteurs de ROBERT proposent une solution pour le moins optimiste. Et concrètement, ces mixnets ne sont pas du tout implémentés dans StopCovid [10], rendant l'implémentation non sûre sur ce point.
2.3 L'attaque sybile
Afin d'éviter qu'un utilisateur alerté ne sache de qui vient l'alerte, les auteurs de ROBERT font l'hypothèse que chaque utilisateur n'a qu'un seul compte sur l'application. Très brièvement, si un utilisateur pouvait créer plusieurs comptes, alors il lui suffirait d'alterner entre ces comptes pour pouvoir déduire à quel moment il a croisé le contact positif, et donc qui était ce contact.
La spécification mentionne bien le besoin de limiter les inscriptions, mais laisse les détails à l'implémentation. Or cette création de comptes multiples dans un système ouvert tel qu'est censé l'être StopCovid est également un problème scientifique bien connu depuis 2002 : l'attaque sybile [11]. Nous sommes ici dans le même cas que précédemment : un problème scientifique assez ancien, mais aucune bonne solution depuis (et beaucoup s'y sont essayés, je plaide coupable !). C'est un problème qui, dans le cas d'un système ouvert, n'est scientifiquement pas résolu de manière satisfaisante. Laisser la gestion des détails à l'implémentation est la mise sous le tapis d'un problème trop compliqué.
Et concrètement, l'implémentation ne propose aucun mécanisme contre cette attaque [12,13]. Les captchas, qu'ils soient de Google ou d'Orange, ne protègent pas de cela : ce point est reconnu dans le ticket préalablement mentionné. Il est en effet facile, même manuellement (alors qu'il existe aussi des systèmes de mechanical turk très peu chers sur le sujet), de résoudre quelques dizaines de captchas, ce qui est suffisant ici. Une possible piste, fonctionnellement, serait de passer par le numéro de téléphone (proposé par les auteurs de ROBERT dans la proposition DESIRE) ou FranceConnect (proposé sur le GitHub de ROBERT), mais même si cela passait par un mécanisme cryptographique adapté, l'acceptabilité par les usagers pour une application présentée comme anonyme serait tellement amoindrie que ça ne semble pas envisagé pour l'implémentation.
Encore une fois, nous avons un vrai problème scientifique, non résolu, considéré comme hypothèse pour le cadre théorique qui a servi de support aux débats parlementaires, mais non implémentable.
2.4 Le sur-envoi d'informations
Enfin, passons rapidement sur un problème de la première version, depuis résolu, mais qui illustre les risques. La première version remontait, en fait, beaucoup plus d'informations de contacts qu'annoncé [14] : au lieu de ne transférer que les contacts de plus de 15 minutes, elle remontait en fait tous les contacts, quelle que soit leur durée, y compris donc les smartphones brièvement croisés. Ce problème a été résolu, ce qui encore une fois montre une certaine bonne volonté, mais il a fallu qu'un chercheur le constate et que la presse s'en empare. Ce problème illustre bien que l'architecture retenue, avec ce serveur de confiance, est très vulnérable à la moindre petite erreur, ici heureusement visible. Et ainsi, là où le principe de minimisation des données vise à améliorer la résilience en cas de bug ou compromission, nous constatons ici que nous sommes à un bug ou une compromission près d'un stockage de données beaucoup plus massif.
L'architecture est fondamentalement risquée, de nombreux efforts doivent ainsi venir se poser en contre-mesure de ces risques intrinsèques. Et comme on le sait en sécurité, mieux vaut une architecture fondamentalement saine que des contre-mesures qui seront trop souvent incomplètes...
Sur tous ces points, il y a en fait peu de réponses, peu de transparence de l'équipe de développement, alors que le projet est promu comme open source.
3. Le blanc-seing de l'open source ?
Une importante part de l'argumentation a été basée sur la transparence de l'open source : puisque c'est transparent, c'est donc que tout va bien. Or cet argument est au minimum exagéré.
Tout d'abord, nombre de critiques ont été émises contre ROBERT. Ces critiques visent l'architecture centralisée, qui à la fois génère un risque de surveillance étatique et devient une cible de choix. Ces critiques visent également le principe même du suivi de contacts par smartphone, en nous rendant toujours plus prêts à une surveillance numérique généralisée, allant de la vidéosurveillance aux contrôles biométriques. Et donc une implémentation transparente d'un protocole critiqué ne devient pas meilleure que le protocole original.
Ensuite, une large part de l'applicatif exécuté, le plus critique, celui exécuté côté serveur, n'en est pas plus surveillable et contrôlable parce qu'il est open source. En effet, les citoyens n'ont aucune visibilité sur ce qui est exécuté côté serveur, ce qui est collecté (des éléments techniques IP/ports ?), à quelle granularité, combien de temps. Ces éléments sont, potentiellement, accessibles à la CNIL, mais ne sont pas liés à l'open source. Sur l'exemple de la collecte d'IP/ports à des fins de protection anti-DDoS, cet élément était par exemple manifestement inconnu de la CNIL : il a été relevé et discuté sur le GitLab du projet, avec insistance, puis la CNIL s'en est du coup emparée. Sur cette partie, nous naviguons à l'aveugle : il a été dit depuis le début que si le code serait open source, l'infrastructure et les éléments de sécurité resteraient eux secrets.
Enfin, l'open source sous-entend, implicitement, un certain nombre de valeurs et de modalités de développement, au-delà de la licence. En l’occurrence, StopCovid est très proche d'AOSP (Android Open Source Project) : le projet est développé dans un silo étanche puis publié ponctuellement, release par release. Les commentaires sont ouverts, mais sans volonté manifeste d'interactions. Les aspects organisationnels restent par ailleurs très opaques. De nombreux acteurs sont impliqués dans le consortium, mais aucune information ne permet par exemple de savoir comment sont cloisonnées les informations critiques, qui a accès à quoi, quelles parties critiques distinctes sont en fait réalisées par deux personnes assises côte à côte ou comment est agencé le workflow entre ces acteurs qui ont démarré la collaboration très rapidement. Dans un monde de DevOps et d'attaques sur la chaîne logistique tout autant que sur les chaînes d'intégration et de déploiement, la connaissance du code uniquement donne un trop maigre aperçu du résultat final.
Au final, les citoyens ne savent en réalité pas grand-chose de ce qu'il se passe côté serveur, il faut faire confiance, avec peu de garanties organisationnelles ou by-design. Ce terme d'open source, connoté de manière très positive, participe ainsi à l’embellissement de l'opération et devient donc, presque, un faux-ami.
4. Des risques intrinsèques au suivi de contacts
StopCovid n'est évidemment pas la seule application de ce type et de nombreuses alternatives sont déployées à travers le monde. La plus proche est le suivi de contacts décentralisé par Bluetooth également (essentiellement le protocole DP3T, implémenté aujourd'hui par l'immense majorité des applications dans les pays démocratiques). La principale critique contre cette alternative décentralisée est que les utilisateurs pourraient déduire lequel de leurs contacts s'est déclaré positif, mais comme nous l'avons vu, StopCovid n'est pas non plus exempt de ce risque avec l'attaque sybile. En revanche, en décentralisé, le rôle du serveur est beaucoup plus faible et la confiance nécessaire à lui accorder est ainsi bien inférieure. Notons d'ailleurs que, tout comme de nombreuses critiques contre StopCovid ont ciblé le captcha Google (problématique certes, mais corrigeable et à mon sens pas le pire risque), le décentralisé est critiqué pour son implémentation dans l'API Exposure Notification fournie par Apple et Google : l'usage de cette API pose évidemment des questions légitimes de souveraineté (tout comme l'utilisation des OS de ces éditeurs pour StopCovid...), mais cette API ne fait que faciliter le développement d'applications distribuées, il est possible de proposer du distribué en dehors de cette API spécifique. D'autres alternatives plus lointaines sont, aussi, clairement plus invasives, en Chine ou en Corée du Sud par exemple (usage du GPS, du bornage téléphonique, des paiements par carte bancaire, etc.)
Ceci étant dit, au-delà des choix architecturaux de ROBERT et des spécificités de l'implémentation, un certain nombre de risques semblent intrinsèques au principe même du suivi de contacts. Ils ont par exemple été étudiés par l'équipe de Risques-Traçage [3]. Cette surveillance fait ainsi systématiquement apparaître des risques, par exemple :
- au niveau privé (traque entre voisins) ;
- au niveau professionnel (discrimination à l'embauche) ;
- au niveau sociétal (si l'État sait reconnaître ses citoyens présents à une manifestation).
Se pose ainsi la question de l'usage futur de ces technologies. De clairement temporaires et bornées dans le temps au début, Apple et Google sont déjà en train de les intégrer plus profondément au sein de leurs OS mobiles. La discussion a énormément changé en quelques mois et l'acceptabilité a largement grandi (à tort ou à raison). Mais ensuite, de ces risques qui aujourd'hui paraissent loin, quelles déviations d'usages seront possibles ? Au-delà de ce que des utilisateurs accepteraient volontairement, quels nouveaux usages peuvent être faits sans changer l'interface, sans changer l'application côté client, juste en modifiant le traitement côté serveur ? En dehors d'un cadre structurellement protecteur (autorité indépendante et financée, a minima), qui devrait être un préalable à tout travail, comment éviter une dérive si un exécutif devenait plus autoritaire ?
Peut-être, en fait, que tout cela devrait être vu comme un résultat d'impossibilité : on a essayé, on s'est interdit le GPS, la collecte trop large, etc. Des spécialistes de la privacy ont fait leur maximum. Mais le résultat n'est pas satisfaisant. Cela ne retire rien à personne, c'est un résultat. Peut-être qu'on ne peut pas garantir des risques acceptables, que l'application soit centralisée ou décentralisée, en l'état actuel des technologies et des connaissances. DESIRE, proposé par l'équipe de ROBERT, résout par exemple certains problèmes (pas tous), mais n'a pas d’implémentation publique à ce jour. Basé sur des échanges plus élaborés, de nouveaux écueils apparaissent avec par exemple les limites de la norme BLE ou la consommation d’énergie.
5. Au-delà de la technologie
5.1 Le rapport risque/bénéfice
Les risques, ainsi, sont à peu près déterminés ; les bénéfices, eux, ne sont toujours pas établis scientifiquement. Le gouvernement a expliqué que « ça sauve des vies dès la première utilisation » et a cité une étude d'Oxford : la seule sur le sujet, citée par le monde entier, mais ne donnant qu'un regard sur une réalité en fait beaucoup plus complexe et interprétée de nombreuses façons différentes. Une étude scientifique est un pas, une brique, qui doit être analysée, critiquée, reproduite par d'autres, pour potentiellement arriver à un consensus scientifique, comme on peut l'avoir aujourd'hui avec le GIEC sur le dérèglement climatique. Il n'y a aujourd'hui, à ma connaissance, pas de consensus scientifique sur le sujet. Or, c'est bien l'émergence d'un consensus qui crée la vérité scientifique, pas la publication d'une unique étude : sans les renvoyer dos à dos, si une étude créait la vérité scientifique, l'hydroxychloroquine serait la solution à nombre de nos problèmes actuels... Le propre de la science serait plutôt d’étudier largement les bénéfices attendus hors terrain ou sur une zone spécifique, puis étendre de manière progressive, comme c’est le cas pour les vaccins par exemple. Le gouvernement en a aussi, dans le même temps, fait un cheval de bataille pour la souveraineté numérique, à un moment qui peut paraître sous-optimal et contradictoire avec les objectifs d'urgence.
L'absence de mesure du bénéfice influence, évidemment, énormément l'adoption de l'application. Un consensus scientifique est un argument à l'installation, à accepter le risque ; cet argument scientifique, encore absent, est ici remplacé par la répétition d'éléments de langage, avec un effet beaucoup moins convaincant. C'est un peu comme en sécurité numérique : si une contrainte n'est pas expliquée et comprise (ce qui nécessite une argumentation cohérente), elle sera toujours contournée. La pédagogie n'est pas une affaire d'éléments de langage, mais de transmission d'un raisonnement cartésien.
5.2 Le solutionnisme technologique
StopCovid apparaît enfin comme la recherche d'une solution numérique à un problème sanitaire. Le numérique peut évidemment aider, et il l'a fait par le maintien de certaines activités pendant le confinement et encore aujourd'hui en limitant les contacts. Mais peut-être qu'il ne peut pas autant qu'on le souhaiterait. Il faut accepter de ne pas tout pouvoir résoudre avec du numérique.
Pendant qu'il occupe le débat médiatique, le gouvernement montre son activité, donne l'impression d'avancer, peu importe l'utilité. Pendant que StopCovid était voté, souvenons-nous que nous manquions de masques et de tests, et que l'agitation politique avait donc un intérêt... politique. Des brigades de traceurs humains en Autriche, un moment après le déploiement (plus réussi) d'une application du même type, expliquaient ainsi qu'elle n'était pas utile, que les enjeux pour eux étaient l'accroissement humain des équipes et l'outillage numérique qu'ils utilisent pour le traçage manuel, sujet moins abordé en France.
Ceci cache aussi tous les autres axes d'ajustement qui pourraient être choisis, ce qui générerait une réflexion sur le risque des transports en commun, des bars, des cinémas ou d’autres façons d’adapter nos activités dans cette période. Le choix StopCovid, c'est aussi le choix politique de faire repartir l'activité au plus proche du classique face à cette crise sanitaire. D'autres choix peuvent être possibles, peuvent se débattre, mais évidemment remettent en cause certains éléments de notre société. Comme le dit Félix Tréguer, « Le solutionnisme technologique restreint complètement nos imaginaires politiques » [15], et le vrai danger est probablement dans cette rigidification des cadres. En cela, ce solutionnisme exacerbe les rapports de domination et l'actualité nous montre que, justement, c'est surtout Apple, Google ou d'autres vendeurs de surveillance qui risquent de sortir encore plus dominants de cet épisode. Ainsi, à l'heure où j'écris ces lignes, Apple annonce qu'il va intégrer le système de suivi de contacts plus profondément dans son OS, Alphabet, la maison mère de Google, se lance dans l'assurance santé et des solutions de vidéosurveillance arrivent à se repositionner comme outils pour la lutte contre le Covid...
Conclusion
La spécification ROBERT me paraît très optimiste, à la fois sur l'hypothèse de confiance dans le serveur et les mécanismes technologiques supposés côté privacy. L'implémentation StopCovid a été une course contre la montre, avec un timing peut-être impossible. La coordination dans l’ensemble sanitaire est aussi un large problème. Et le défi de faire du traçage sans envahir la vie privée, mais avec les mesures de sécurité nécessaires paraît contradictoire.
En conclusion, tout cela n'a pas convaincu. D’après l’avis du 15 septembre 2020 du Comité de contrôle et de liaison Covid-19 [16], il y a peu d'installations, à peine 2,4 millions de téléchargements auxquels il faut soustraire au moins 700 000 désinstallations : le gouvernement ne communique pas le nombre d'utilisateurs quotidiens réels, le seul réellement utile. Tout cela pour moins de 200 notifications. Les citoyens ont manifestement manqué de confiance en l'État pour installer une application de ce type : le contexte social actuel, pour le moins tendu depuis presque deux ans, n'y est peut-être pas étranger. Selon que l'on soit optimiste ou pessimiste, et que l'on soit favorable ou défavorable à cette voie, on pourra soit y voir un échec qui compliquera toute tentative future d'un système de ce type, soit y voir un premier pas vers une meilleure acceptation d'une future autre application...
Avec l’impact qu’a maintenant le numérique sur le monde physique, nous ne pouvons plus nous contenter d’évaluer une technologie par rapport à son usage prévu, initial. Nous devons faire l’effort, systématiquement, d’évaluer le potentiel d’un service numérique, en se projetant dans ses impacts futurs.
Remerciements
Je remercie Léo Perrin pour ses commentaires sur une version préliminaire de cet article.
Références
[1] Suivi StopCovid : http://perso.citi-lab.fr/flesueur/suivi-stopcovid/
[2] Mise en garde contre les applications de traçage : https://attention-stopcovid.fr
[3] Le traçage anonyme, dangereux oxymore : https://risques-tracage.fr
[4] ROBust and privacy-presERving proximity Tracing protocol : https://github.com/ROBERT-proximity-tracing/documents
[5] StopCovid sources : https://gitlab.inria.fr/stopcovid19
[6] ROBERT Server, Issue 38 « REST server is leaking monitoring data » : https://gitlab.inria.fr/stopcovid19/robert-server/-/issues/38
[7] ROBERT Server, Issue 30 « Data collection surrounding the server application » : https://gitlab.inria.fr/stopcovid19/robert-server/-/issues/30
[8] Application « StopCovid » : la CNIL tire les conséquences de ses contrôles : https://www.cnil.fr/fr/application-stopcovid-la-cnil-tire-les-consequences-de-ses-controles
[9] Untraceable electronic mail, return addresses, and digital pseudonyms, David Chaum, 1979 : https://www.worldcat.org/title/untraceable-electronic-mail-return-addresses-and-digital-pseudonyms/oclc/22448941
[10] ROBERT Server, Issue 31 « Mixnet missing (specification and implementation) » : https://gitlab.inria.fr/stopcovid19/robert-server/-/issues/31
[11] The Sybil Attack, John R. Douceur, 2002 : https://www.microsoft.com/en-us/research/wp-content/uploads/2002/01/IPTPS2002.pdf
[12] ROBERT Server, Issue 29 « Sybil attack - Multiple accounts to identify infected people » : https://gitlab.inria.fr/stopcovid19/robert-server/-/issues/29
[13] StopCovid Android, Issue 25 « Sybil attack implementation is almost trivial. » : https://gitlab.inria.fr/stopcovid19/stopcovid-android/-/issues/25
[14] L’application StopCovid collecte plus de données qu’annoncé : https://www.lemonde.fr/pixels/article/2020/06/16/l-application-stopcovid-collecte-plus-de-donnees-qu-annonce_6043038_4408996.html
[15] Le solutionnisme technologique restreint complètement nos imaginaires politiques (interview de Félix Tréguer) : https://lundi.am/Le-solutionnisme-technologique-restreint-completement-nos-imaginaires
[16] Avis du 15 septembre 2020 du Comité de contrôle et de liaison Covid-19 :
https://solidarites-sante.gouv.fr/IMG/pdf/avis_du_ccl-covid_du_15_09_20._pour_un_systeme_d_information_au_service_d_une_politique_coherente_de_lutte_contre_l_epidemie.pdf