

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Souvent méconnus ou oubliés, les en-têtes « saut par saut » font bel et bien partie du socle définissant le protocole HTTP/1.1. Ces derniers ont pu notamment retrouver une certaine notoriété depuis la mise en lumière de la CVE-2022-1388, exploitable notamment via ce type d'en-tête. Cette vulnérabilité critique (CVSS v3 9.8 [1]) parue en mai 2022 a affecté une solution largement utilisée par les entreprises : F5 BIG-IP. Cet article détaille le fonctionnement de ce type d'en-tête ainsi que les enjeux sécurité liés, notamment à travers l'étude de la vulnérabilité CVE-2022-1388.
1. Rappels sur le protocole HTTP/1.1
Avant de rentrer dans les détails concernant les en-têtes saut par saut et de comprendre au mieux la vulnérabilité CVE-2022-1388, il est important de (re)prendre connaissance des bases du protocole HTTP/1.1. Encore aujourd'hui largement utilisée, la version 1.1 est la première version standardisée de HTTP, en majorité inchangée malgré son âge et les multiples Request for Comments (RFC) parues à son égard depuis la RFC2068 [2] publiée en 1997.
1.1 Des requêtes méthodiques...
Les requêtes constituent la base de HTTP, protocole basé sur le modèle client-serveur : le serveur (web) transmet du contenu en réponse à une requête HTTP émise par le client.
Il convient également de noter que le protocole HTTP est dit « sans état » (stateless ). C'est-à-dire que lors de l'utilisation de ce dernier, le serveur ne conserve pas d'informations sur le client entre deux requêtes. Chaque requête est indépendante et n'est pas liée aux requêtes qui auraient été faites précédemment.
Dans l'utilisation quotidienne, l'utilisateur classique se servant de son navigateur (le client), va en formuler des milliers voire des dizaines de milliers, permettant ainsi l'accès et la transmission de ressources spécifiques hébergées sur des serveurs.
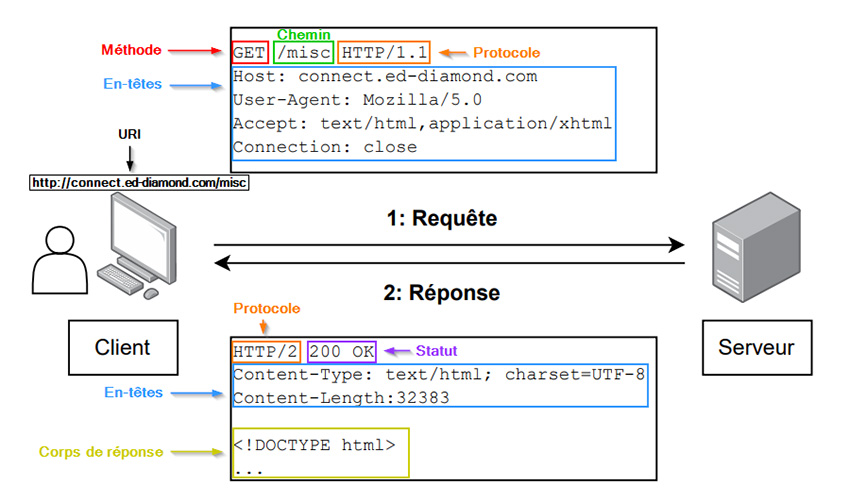
La première ligne d'une requête HTTP/1.1 va contenir plusieurs informations dans l'ordre précis suivant :
- [CIBLE] indique le chemin (path) vers la ressource requêtée. Sa valeur est définie suite à une URI (Uniform Resource Identifier) formulée par le client comme « http://connect.ed-diamond.com/misc » . (voir Figure 1).
Une fois formulée, l'URI est décomposée de manière à ce que le chemin vers la ressource soit placé au sein de la première ligne de la requête HTTP/1.1 et que le nom de l'hôte cible soit placé au sein de l'en-tête Host (le fonctionnement des en-têtes est explicité dans la suite de l'article) ;
- [VERSION_HTTP] la version du protocole HTTP utilisée pour la requête ;
- [METHODE] qui correspond à la méthode de la requête utilisée et qui spécifie le type d'échange formulé entre le client et le serveur.
Ci-dessous, un rappel des méthodes de requêtes les plus connues qui composent le protocole HTTP ainsi que leur but :
- OPTIONS : Permet d'interroger le serveur hébergeant la ressource requêtée quant aux méthodes HTTP qui sont supportées par ce dernier ;
- GET : Méthode la plus populaire, dont le seul but est, dans la majorité des cas, de récupérer la ressource hébergée sur le serveur requêté, sans modifier l'état du serveur ;
- HEAD : Identique à la méthode « GET », cependant, celle-ci indique au serveur de ne pas retourner de corps de réponse, seulement les en-têtes qui seraient retournés si cette même requête avait été effectuée via la méthode « GET ». Par exemple : la taille de la réponse via l'en-tête « Content-Length » ;
- POST : Méthode utilisée pour envoyer des données au serveur. Le type du corps de la requête fourni au serveur peut être spécifié au sein de l'en-tête « Content-Type » ;
- PUT : Méthode utilisée pour créer une ressource sur le serveur ou la modifier. La différence majeure avec la méthode « POST » précédente est le fait qu'une requête « PUT » est idempotente, c'est-à-dire que, même après avoir effectué plusieurs requêtes « PUT » identiques, le résultat affecté à la ressource sera toujours le même. Ce qui n'est pas le cas avec une requête « POST » qui, si elle est envoyée de manière identique plusieurs fois, peut créer de multiples ressources. Exemple : Envoyer n fois le même formulaire, ce qui créera n même(s) réponse(s) ;
- DELETE : Méthode utilisée pour supprimer une ressource sur le serveur requêté ;
- CONNECT : Méthode utilisée afin de créer une communication bidirectionnelle avec le serveur hébergeant la ressource requêtée, notamment lors d'échanges d'informations via le protocole TLS (HTTPS). Par exemple, un client peut requêter une ressource hébergée sur un serveur web atteignable uniquement via un serveur relai (proxy). Le client va alors envoyer une requête en utilisant la méthode « CONNECT » au proxy, ce dernier va s'assurer que la ressource est disponible sur le serveur requêté puis en informera le client. Si la ressource est bien disponible, alors le proxy en informe le client et un tunnel se crée entre le serveur et le client avec la négociation TLS puis l'échange d'informations de manière chiffrée. En d’autres termes, cela permet de créer une connexion TCP encapsulée dans du HTTP(S).
L'ensemble des méthodes présentes au sein du protocole HTTP/1.1 sont renseignées au sein de la RFC2616 [3].
1.2 Des en-têtes, pour quoi faire ?
Comme énoncé précédemment, les requêtes sont nécessairement constituées d'une méthode précise permettant d'informer le serveur du type d'échange dont il est question, mais, à partir de HTTP/1.0, ce n'est pas la seule composante formant les requêtes HTTP.
Il est également possible de fournir certaines informations supplémentaires lors de l'échange entre le client et le serveur requêté. Ces informations concernent l'ensemble des spécificités qui peuvent être liées au contexte de l'échange afin que le serveur puisse fournir la ressource demandée par le client dans les meilleures conditions.
Ces informations sont fournies par le biais d'« en-têtes » (headers), valeurs faisant partie de la requête constituée d'une paire nom/valeur séparée de deux points.
Les principaux en-têtes utilisés sont récapitulés dans le tableau suivant accompagnés de leur signification et d'exemples de valeur :
|
En-tête |
Description |
Exemple de valeur |
|
Accept |
Les informations contenues (exprimées en types MIME) dans ce champ traitent du contenu que le client est en capacité de traiter. Une fois que le serveur sait ce que le client peut traiter comme contenu, le serveur informe le choix établi dans l'en-tête « Content-Type » contenu dans la réponse. |
|
|
Authorization |
Utilisé pour renseigner des informations relatives à l'authentification. |
Authorization: Bearer |
|
Cache-Control |
Utilisé afin de spécifier les directives concernant les mécanismes de cache. |
Cache-Control: no-cache, no-store |
|
Cookie |
Utilisé pour communiquer au serveur et/ou au client le « cookie » utilisé dans le contexte de l'utilisation d'une application web par exemple. La communication de cet en-tête permet notamment l'échange d'informations « avec état » (stateful). Ce qui permet au serveur de faire le lien avec un même client même si le protocole HTTP est dit « sans état » (stateless), comme présenté en introduction. Cet en-tête est souvent accompagné de l'utilisation d'un autre en-tête « Set-Cookie », permettant de définir le « cookie » communiqué par le serveur au client. |
Cookie: JSESSIONID=MiscMagazine |
|
Connection |
Utilisé afin de contrôler la façon dont la connexion TCP est gérée pour l'échange d'informations client/serveur. La valeur assignée « keep-alive » par exemple, annonce que la connexion sera persistante. C'est-à-dire que l'échange TCP créé avec le serveur sera également utilisé pour les futures requêtes, jusqu'à recevoir une nouvelle valeur « close ». L'utilisation de ce mécanisme permet in fine de réduire le temps de réponse du serveur pour obtenir les ressources demandées. |
|
|
Content-Length |
Indique la taille en octets du corps de réponse envoyé au client. |
Content-Length: 8593 |
|
Content-Type |
Comme indiqué dans la description de l'en-tête « Accept », l'en-tête « Content-Type » est renseigné dans la réponse envoyée par le serveur. Ce dernier permet d'indiquer le type de contenu réellement envoyé au client. |
Content-Type: text/html |
|
Host |
À partir du protocole HTTP/1.1 doit être inclus dans toutes les requêtes effectuées et spécifie le FQDN (Fully qualified domain name) du serveur contacté. Ce dernier peut être optionnellement accompagné du numéro de port associé. |
Host: connect.ed-diamond.com |
Parmi tous les en-têtes cités, le protocole HTTP/1.1 en comporte deux types distincts :
- Les en-têtes bout-en-bout (« End-to-end » en anglais) : en-têtes dont les valeurs sont mises en cache et transmises par les serveurs relais (proxys), sans modification, au serveur destinataire de la requête finale ;
- Les en-têtes saut par saut ou bond par bond (« Hop-by-hop » en anglais) : en-têtes dont les valeurs ne sont pas mises en cache et transmises par les serveurs relais (proxys). Ces derniers sont uniquement destinés aux proxys qui vont relayer la requête, et seront supprimés de la requête finale transmise au serveur destinataire.
Parmi l'ensemble des en-têtes mentionnés dans le tableau ci-dessus, seulement un est défini comme un en-tête saut par saut dans la RFC2616 [3].
Découvrons duquel il s'agit dans la section suivante.
2. Focus sur les en-têtes « saut par saut »
2.1 Les en-têtes concernés et leur but
La liste des en-têtes saut par saut définis au sein de la RFC2616 [3] (Section 13.5.1) est respectivement :
- Connection ;
- Keep-alive ;
- Proxy-Authenticate ;
- Proxy-Authorization ;
- TE ;
- Trailers ;
- Transfer-Encoding ;
- Upgrade.
Le reste des en-têtes HTTP est, par définition, considéré comme des en-têtes bout-en-bout.
Les en-têtes saut par saut ont été pensés afin d'agir dans un contexte précis : indiquer aux serveurs relais (proxys) les en-têtes qui n'ont pas d'utilité précise au serveur destinataire final, mais uniquement aux machines constituant la chaîne de transmission de l'information.
Une requête contenant un en-tête saut par saut sera donc transmise au serveur relais avec l'en-tête, mais ce dernier sera supprimé de la requête finale transmise au client par le proxy.
D'après la RFC2616 [3], l'en-tête « Connection » a d'ailleurs la particularité de pouvoir indiquer aux proxys des en-têtes saut par saut supplémentaires ne faisant pas partie de ceux listés précédemment :
« Other hop-by-hop headers MUST be listed in a Connection header […] HTTP/1.1 proxies MUST parse the Connection header field before a message is forwarded and, for each connection-token in this field, remove any header field(s) from the message with the same name as the connection-token. ».
C'est d'ailleurs cette particularité de la spécification technique qui engendre des effets de bords impactant la sécurité des applications se basant sur la présence de certains en-têtes.
Voyons ensemble plusieurs manières d'exploiter cette particularité, au sein de la section suivante.
2.2 Plusieurs voies d'exploitation possibles
Le contexte où les en-têtes saut par saut peuvent être vecteurs d'erreurs ou d'attaques va concerner uniquement certains cas particuliers où les solutions de serveurs relais (proxys) ajoutent un en-tête au sein de la chaîne de transmission de la requête.
Imaginons que le back-end recevant la requête finale s'attende dans tous les cas à recevoir un en-tête qui est ajouté par le serveur relais sur l'origine de la requête par exemple. Comment réagirait alors le back-end si cet en-tête n'est finalement jamais délivré ?
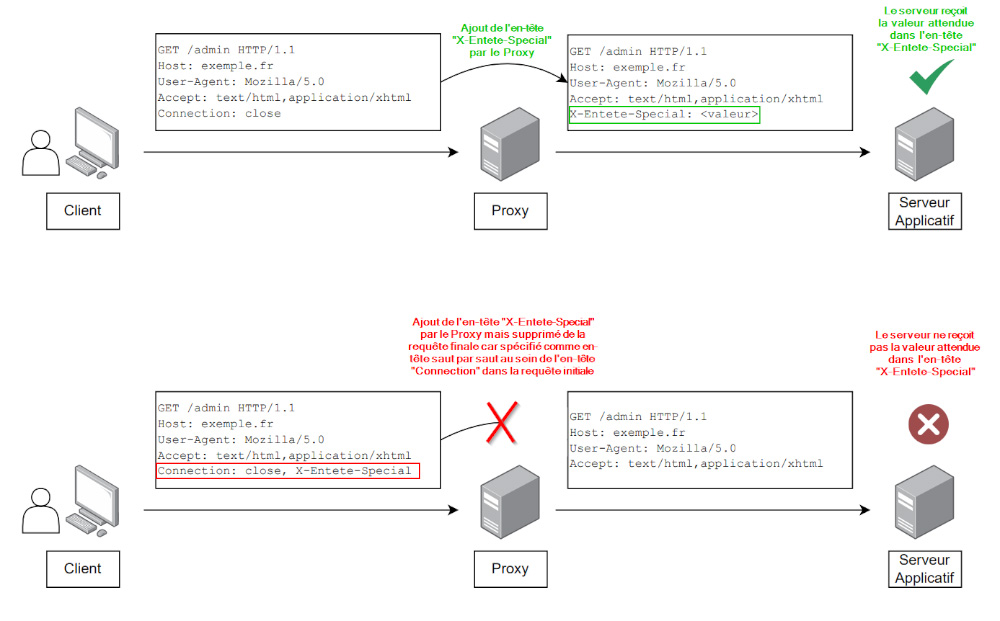
Comme le suggère le paragraphe précédent, un exemple de contournement de filtrage d'accès via les en-têtes saut par saut peut être notamment effectué si une application web ne contrôle pas rigoureusement une condition d'accès qui serait régie par la présence d'un en-tête « X-Forwarded-For » ajouté par un serveur relais.
En effet, dans le cas où un serveur relais (proxy) ne retournerait pas d'en-tête « X-Forwarded-For » au back-end, le filtrage d'accès serait contourné sans contrôle rigoureux de ce cas de figure. Ce qui permettrait à un attaquant d'accéder à des données restreintes de manière non légitime en émettant une requête avec l'en-tête « Connection : close, X-Forwarded-For » (voir Scénario 2 de la Figure n°2).
D'autres types d'exploitation sont possibles à travers la suppression d'un en-tête utile au fonctionnement d'un serveur relais comme la récupération d'informations sur les services utilisés.
La solution ProxySG de serveur relais éditée par Blue Coat par exemple, ajoute par défaut l'en-tête « X-BLUECOAT-VIA » au sein des requêtes transmises à des fins de performance pour détecter la présence de boucles réseaux. Pour détecter l'utilisation de cette solution, un attaquant pourrait émettre une requête avec l'en-tête « Connection : close, X-BLUECOT-VIA ». Cela supprimerait la présence de l'en-tête « X-BLUECOT-VIA » une fois transmis et provoquerait une erreur, confirmant ainsi l'utilisation du service dans la chaîne de transmission des requêtes.
Plus de détails et de voies d'exploitation théoriques à propos des en-têtes saut par saut sont disponibles sur le blog de Nathan Davison, chercheur en sécurité informatique [4].
Enfin, la CVE-2022-1388 impactant la solution F5 BIG-IP a, elle aussi, son contexte particulier lié à ce type d'en-tête. Dans le cadre de cette vulnérabilité, la formulation de requêtes spécifiquement formées permet le contournement de l'authentification menant à l'exécution de commandes arbitraires sur le serveur hébergeant le composant. Plus de détails sont fournis dans la suite de cet article.
2.3 Leur disparition dans les protocoles HTTP ultérieurs à HTTP/1.1
Les versions HTTP/1.0 et antérieures ne sont pas concernées par les en-têtes saut par saut dus à leur introduction dans la RFC2616 [3], une des spécifications ayant apporté de nouveaux changements au protocole HTTP/1.1.
Quant à HTTP/2 et HTTP/3, ces derniers introduisent des améliorations au niveau de la couche transport visant à pallier les limites du protocole TCP pour augmenter la performance des échanges HTTP. Notamment via l'introduction du multiplexage des requêtes au sein du protocole HTTP/2 qui permet l'émission de la requête et la réception des réponses sur une même connexion TCP.
Bien que HTTP/2 et HTTP/3 aient gardé en grande majorité les mêmes bases établies au sein du protocole HTTP/1.1 concernant la composition des requêtes, la plupart des en-têtes saut par saut ne sont plus supportés au sein de ces nouveaux protocoles. En particulier les en-têtes « Connection » et « Keep-Alive », spécifiant les modalités liées à la gestion des échanges TCP, qui deviennent obsolètes en raison de la refonte liée à la couche transport au sein des protocoles HTTP/2 et HTTP/3.
Pour plus d'informations sur cette refonte, je vous invite à aller consulter l'article MISC « HTTP/2 : Attention, peinture fraiche ! » [5] de Florian Maury.
3. CVE-2022-1388, le contexte idéal
3.1 Détails sur le fonctionnement de l'authentification au sein du composant vulnérable : iControl REST API
La vulnérabilité dont il est question ici réside au sein d'un composant de la solution BIG-IP de F5, appelé iControl.
La solution BIG-IP, bien connue des entreprises, comporte un grand nombre de fonctionnalités servant à la mise à disposition d'applications web, regroupant ainsi des fonctionnalités de pare-feu, WAF (Web Application Firewall) et répartiteur de charge.
iControl est, quant à elle, une API REST (Representational State Transfer Application Program Interface) qui permet un contrôle granulaire de la configuration et de la gestion de la solution BIG-IP. Les interfaces iControl vont permettre notamment de gérer toutes les politiques de configuration et de gestion de la plateforme BIG-IP qui permet le déploiement et l'approvisionnement d'applications, l'automatisation de tâches, l'établissement d'une surveillance du système et des performances, etc.
Ce composant repose sur une application en Java hébergée localement sur un serveur Jetty sur le port 8100 et exposée via un serveur Apache en frontend sur le port 443 qui agit comme un proxy inverse (reverse proxy). Pour joindre l'API REST, le chemin de la requête doit commencer par /mgmt qui signalera ainsi au serveur Apache de rediriger la requête vers le serveur Jetty.
Quant à l'authentification, il existe deux façons de procéder pour s'identifier sur le composant iControl [6] :
- Via un jeton d'authentification (token) résidant au sein de l'en-tête « X-F5-Auth-Token » d'une requête HTTP. La requête est alors redirigée au serveur Jetty pour vérification du jeton ;
- Via une authentification de type HTTP Basic réservée à des utilisateurs détenant des droits administrateurs sur le serveur : les informations d'authentification fournies au sein de l'en-tête « Authorization » sont alors vérifiées via le module mod_auth_pam d'Apache pour pouvoir interagir avec le serveur Jetty.
Cependant, il existe une particularité concernant la façon dont Jetty traite certaines requêtes pour l'authentification, cette dernière est détaillée dans la section suivante.
3.2 L'exploitation par les en-têtes « saut par saut »
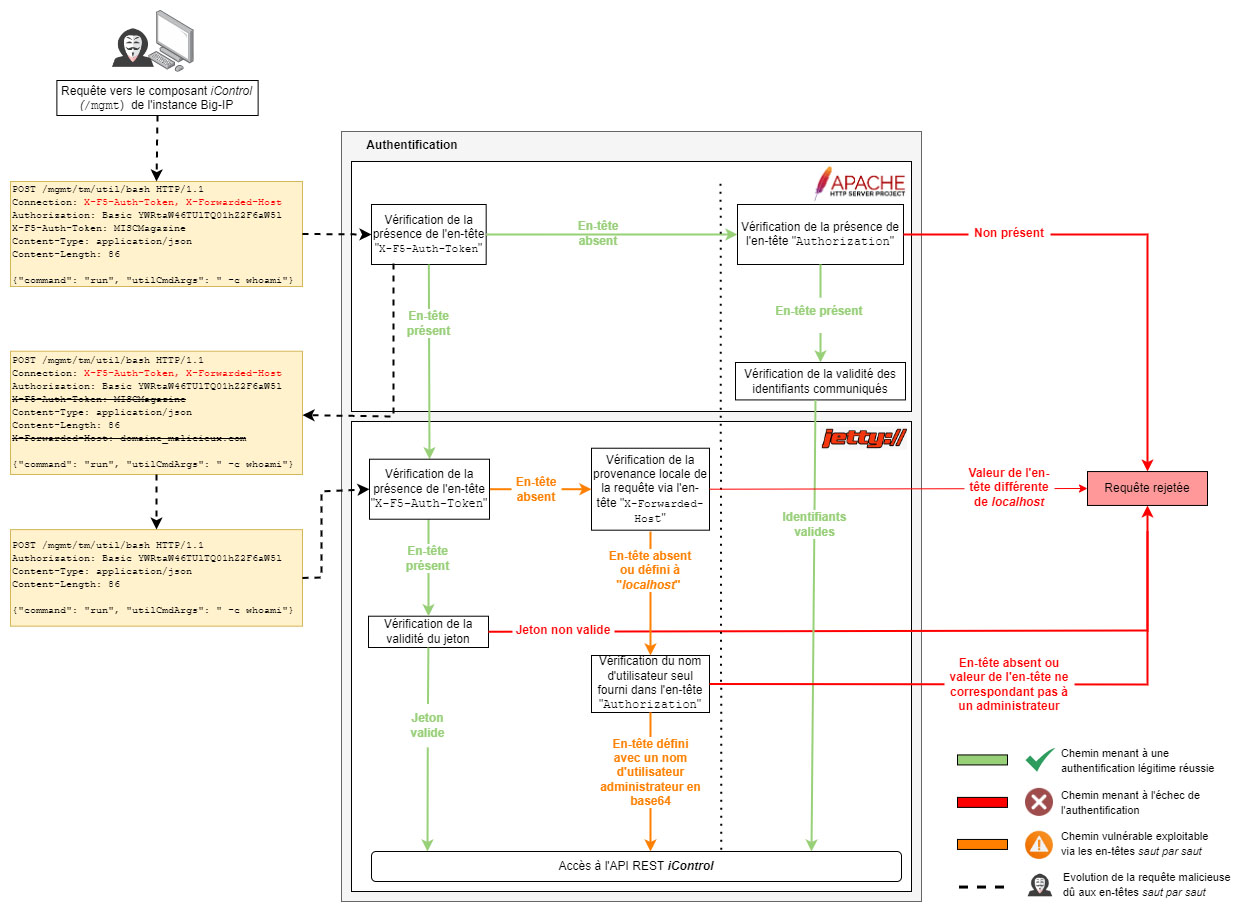
L'authentification se déroule donc en deux temps. D'abord la requête est reçue par le serveur Apache placé en frontend afin de vérifier la présence d'informations relatives à l'authentification, puis cette dernière est transmise au serveur Jetty pour authentification et traitement de la demande formulée au sein de la requête. Nous sommes donc dans un scénario où un serveur relais (proxy) transmet les requêtes au service visé.
À noter ici que le serveur Jetty considère une requête comme locale si :
- L'en-tête « X-Forwarded-Host » a sa valeur définie à « localhost » ou que ce dernier est absent. Cet en-tête est ajouté par le serveur Apache afin d'indiquer la valeur précédemment stipulée par l'en-tête « Host » indiqué dans la requête originale ;
- L'en-tête « X-F5-Auth-Token » est absent.
De plus, lorsque la requête est considérée comme faite localement, le serveur Jetty ne contrôle pas le mot de passe communiqué au sein des informations HTTP Basic, mais uniquement le nom d'utilisateur correspondant à un administrateur. Exemple : Les administrateurs par défaut « admin » ou « root ».
Mis bout à bout, l'absence des en-têtes « X-F5-Auth-Token » et « X-Forwarded-Host » permet ainsi de tromper le serveur Jetty en lui faisant croire que la requête est faite de manière locale. Ce qui permet in fine de contourner l'authentification via HTTP Basic, car le mot de passe n'est pas contrôlé lorsque la requête est considérée comme locale.
Mais si le serveur Apache, contrôle la présence de l'en-tête « X-F5-Auth-Token » et ajoute l'en-tête « X-Forwarded-Host » dans un deuxième temps, comment s'arranger pour les faire disparaître de la requête finale ? La réponse est : avec l'aide des en-têtes saut par saut et des spécificités de la RFC2616 [3] mentionnées plus haut.
En effet, une requête émise par un client distant sur Internet contenant les en-têtes ci-dessous contournera l'ensemble des mécanismes d'authentification du composant iControl :
- Connection: X-F5-Auth-Token, X-Forwarded-Host→Indique au serveur relais Apache les en-têtes qui seront à supprimer avant de transmettre la requête finale visant à tromper le serveur Jetty quant à la provenance de la requête ;
- Authorization: Basic YWRtaW46TUlTQ01hZ2F6aW5l →Fournit les informations d'authentification suivantes « admin:MISCMagazine » encodées en base64. Le mot de passe ne sera pas traité par Jetty puisque la requête sera considérée comme locale dû à l'absence des en-têtes « X-F5-Auth-Token » et « X-Forwarded-Host » ;
- X-F5-Auth-Token: MISCMagazine →En-tête qui doit être présent pour forcer la redirection de la requête vers le serveur Jetty et ainsi contourner l'authentification via mod_auth_pam d'Apache malgré la présence de l'en-tête « Authorization ». À noter que la valeur définie au sein de l'en-tête « X-F5-Auth-Token » est ignorée par le serveur Apache.
L'authentification étant maintenant contournée, une requête de type POST avec un corps de requête en format json effectuée sur le chemin correspondant au module de l'API REST qui permet d'exécuter des commandes (/mgmt/tm/util/bash) mène à la capacité pour un attaquant d'exécuter du code de manière arbitraire sur le système cible (serveur Jetty). De plus, les commandes seront exécutées avec l'utilisateur root, car le service Jetty est lancé avec cet utilisateur sur l'instance BIG-IP.
Donnant ainsi la requête offensive finale suivante :
Un récapitulatif de l'attaque en Figure 3.
3.3 La remédiation indiquée par F5
Pour remédier à cette vulnérabilité, F5 indique sur son site internet [8] de procéder à la mise à jour du module BIG-IP ou de modifier la configuration httpd du serveur Apache en ajoutant une condition concernant la fameuse en-tête « Connection ».
Cette modification limite la présence de valeurs différentes de close ou keep-alive au sein de l'en-tête, empêchant ainsi le contournement lié à l'authentification.
Ci-dessous, la condition indiquée par F5 :
À la suite de la publication de cette note de remédiation, des chercheurs en sécurité informatique ont rapidement fait le lien entre le module d’authentification vulnérable et la faiblesse de l'en-tête « Connection » liée à son type saut par saut. Plusieurs PoC (« Proof of Concept ») et codes d'exploitation ont été publiés et sont encore consultables sur le Web.
Les équipements n'ayant pas appliqué cette note de remédiation et qui sont exposés sur Internet sont donc toujours à risque et nécessitent une correction en ce sens. D’après les données du moteur de recherche ONYPHE [7], environ 720 000 équipements seraient exposés, dont 3 200 exposant également l’interface iControl REST API.
Les versions vulnérables de la solution BIG-IP concernées et mentionnées sur le site Internet de F5 [8] sont respectivement :
- 11.X : 11.6.1 – 11.6.5 → Correctif non proposé
- 12.X : 12.1.0 – 12.1.6 → Correctif non proposé
- 13.X : 13.1.0 – 13.1.4 → Correctif apporté dans la version 13.1.5
- 14.X : 14.1.0 – 14.1.4 → Correction apporté dans la version 14.1.4.6
- 15.X : 15.1.0 – 15.1.5 → Correctif apporté dans la version 15.1.5.1
- 16.X : 16.1.0 – 16.1.2 → Correctif apporté dans la version 16.1.2.2
- 17.X : Non vulnérable
Conclusion
Les spécificités liées à des protocoles établis il y a maintenant plusieurs décennies peuvent mener à des comportements inhabituels lorsqu'ils ne sont pas pris en compte par les éditeurs de solution. C'est ce que nous avons pu voir à travers les scénarios d'exploitation mentionnés au sein de cet article et l'exploitation de la vulnérabilité CVE-2022-1388 via l'utilisation des requêtes saut par saut dans un contexte particulier. À l'ère du Cloud informatique qui contribue à agrandir la chaîne de transmission de l'information, les cadres d'application et les possibilités qui concernent ce type d'en-têtes sont multiples et restent à être explorées.
Remerciements
Je remercie chaleureusement mes relecteurs Patrice Auffret, Nicolas Bonnand et Sébastien Dellac pour leur contribution, leurs conseils et le temps consacré.
Références
[1] https://nvd.nist.gov/vuln/detail/CVE-2022-1388
[2] https://www.ietf.org/rfc/rfc2068.txt
[3] https://www.ietf.org/rfc/rfc2616.txt
[4] https://nathandavison.com/blog/abusing-http-hop-by-hop-request-headers
[5] F. Maury, « HTTP/2 : attention, peinture fraîche ! », MISC n°88, novembre - décembre 2016 :
https://connect.ed-diamond.com/MISC/misc-088/http-2-attention-peinture-fraiche
[6] https://cdn.f5.com/websites/devcentral.f5.com/downloads/icontrol-rest-api-user-guide-14-1-0.pdf