

Voici le dernier opus de cette longue série d’articles consacrée aux namespaces de Linux. Il nous reste à décrire le namespace cgroup, mais aussi les nouveaux namespaces en préparation pour les prochaines moutures de Linux. Nous finirons avec la gestion de la remontée des informations de plantage.
Le namespace cgroup (cgroup_ns) est certes le dernier-né, mais nous verrons que Linux nous réserve des namespaces additionnels dans ses prochaines moutures, tant les besoins en la matière sont importants pour la virtualisation. Nous achèverons cette série d’articles avec la gestion de la remontée des informations de plantage qui souffre de quelques manques, mais pour lesquels des palliatifs existent.
Le code de cet article est disponible sur https://github.com/Rachid-Koucha/linux_ns.git.
1. Le namespace cgroup
Le cgroup_ns limite la vue sur l’arborescence des cgroups [1] en faisant du niveau où le processus se trouve, suite à un appel à unshare() ou clone() avec le drapeau CLONE_NEWCGROUP, la racine des cgroups pour ce processus.
Une entrée est dédiée à ce namespace dans le manuel en ligne : man 7 cgroup_namespaces.
L’intérêt majeur de ce namespace est de limiter la vue à un sous-répertoire dans les hiérarchies des cgroups. Listons les hiérarchies des cgroups du shell courant dans un terminal :
La racine est dans le répertoire /sys/fs/cgroup. Créons un sous-répertoire nommé par exemple « sub » dans le contrôleur cpuset et redéfinissons l’ensemble des CPU qu’il autorise en le passant de 0-3 dans le cgroup racine (le PC utilisé ici a quatre cœurs) à 0-1 :
Migrons le shell d’un super utilisateur d’un autre terminal dans ce nouveau cgroup (p. ex. 13437). Et affichons les chemins de ses cgroups pour vérifier qu’il est bien dans le répertoire /sys/fs/cgroup/cpuset/sub :
Dans le terminal du shell 13437, exécutons (au sens littéral, car ici on écrase le shell courant avec la built-in exec !) la commande unshare avec l’option -C pour entrer dans un nouveau cgroup_ns. Cela a pour conséquence de remplacer le shell courant par le programme unshare. Ce dernier appelle unshare(CLONE_NEWCGROUP) afin d’entrer dans un nouveau cgroup_ns et se fait remplacer par un nouveau shell. Ainsi, l’identifiant de processus ne change jamais, comme indiqué dans la figure 1.
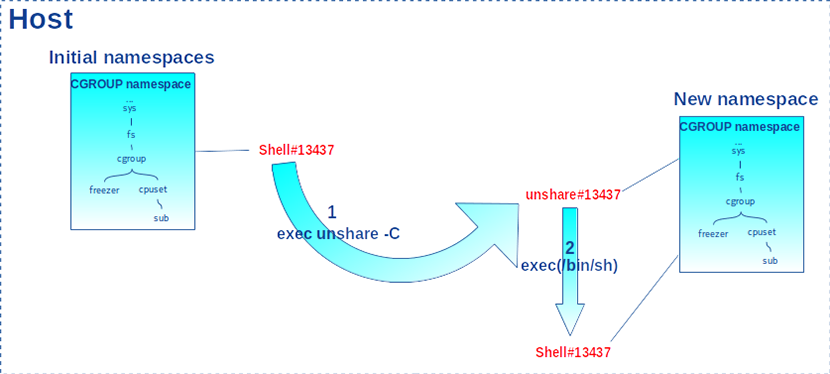
Affichons de nouveau les chemins de ses cgroups :
On constate que le shell 13437 considère /sys/fs/cgroup/cpuset/sub comme la racine du sous-système cpuset dans le nouveau cgroup_ns. Si nous affichons la liste des chemins des cgroups d’un processus qui n’est pas dans son cgroup_ns (ici, 13217) :
Le /.. affiché montre que le processus en question n’est pas dans le cgroup_ns courant, mais situé au-dessus de la racine du contrôleur cpuset du cgroup_ns courant.
Vu d’un autre terminal (c.-à-d. du cgroup_ns initial), la liste des chemins des cgroups continue bien entendu à indiquer que le processus 13437 est dans le sous-répertoire sub :
Cependant pour parfaire l’isolation du processus 13437, il ne faut pas que son fichier mountinfo montre qu’il n’est pas à la racine :
De plus, bien que son fichier /proc/$$/cgroup montre / pour le sous-système cpuset, rien ne l’empêche de migrer vers le cgroup père :
Il est donc conseillé de coupler un cgroup_ns à un mount_ns pour remonter les sous-systèmes au niveau de la racine. Remettons le processus 13437 dans son cgroup, puis faisons-le entrer dans un nouveau mount_ns (option -m de la commande unshare) dans lequel on va effectuer l’opération de remontage de l’arborescence cpuset :
L’isolation est maintenant complète, car le shell 13437 ne pourra plus se positionner dans les niveaux père du sous-système cpuset : il ne peut plus les voir.
Un gestionnaire de conteneur comme LXC réalise cette opération pour tous les sous-systèmes afin de faire croire à l’image qu’il fait tourner qu’elle se situe à la racine de l’arborescence des cgroups (cf. encadré « Les cgroups dans LXC »).
Les cgroups dans LXC
Le nom de la sous-arborescence LXC dans les cgroups est décidé par défaut à la configuration de la génération du package avec l’option --with-cgroup-pattern passée au script « configure » ou dans la configuration générale de LXC avec le paramètre lxc.cgroup.pattern. Dans LXC 2.1.1, la valeur par défaut est le schéma lxc/%n où %n désigne le nom du conteneur. Dans LXC 3.0.4, c’est lxc.payload/%n.
Par la suite, lxc-start utilise ce schéma afin de créer les répertoires /sys/fs/cgroup/<sous-système>/<schéma> dans l’arborescence des cgroups. Puis il crée le premier processus du conteneur (init) dans ses nouveaux namespaces (pid, network…) sauf pour le cgroup_ns qui reste celui de l’hôte. Puis lxc-start migre le processus dans les cgroups créés en écrivant son PID dans les fichiers /sys/fs/cgroup/<sous-système>/<schéma>/cgroup.procs. Enfin, avec une synchronisation père/fils, lxc-start indique au processus du conteneur d’appeler unshare(CLONE_NEWCGROUP). Cela a pour conséquence de faire de /sys/fs/cgroup/<sous-système>/<schéma>, la racine des cgroups pour le conteneur, car le processus init a été migré à cet emplacement par son père. Vu du côté hôte, le processus du conteneur est bien localisé dans le répertoire dédié dans les cgroups (ici, nous sommes avec LXC 2.1.1) :
2. Namespaces additionnels
Au cours des années, le nombre de namespaces s’est accru. Alors qu’on semble avoir fait le tour du sujet, de nouvelles demandes se font sentir pour pousser toujours plus loin l’isolation des ressources du système. Cependant, on arrive à certaines limites. Notamment, le nombre de bits disponibles dans l’entier 32-bits passé à la fonction clone() ou unshare() pour définir de nouveaux drapeaux de namespaces. Il suffit de regarder les macro-définitions dans <linux/sched.h> pour voir qu’ils sont tous utilisés :
Des solutions existent cependant : créer une nouvelle version de clone(), fusionner des namespaces, ajouter des ressources à isoler dans les namespaces existants, inventer des services dédiés à la création de chaque type de namespace...
2.1 Le namespace time
Le but est de permettre aux conteneurs d’avoir leur propre heure système afin par exemple de faciliter les migrations (« checkpoint/restore ») d’un système à l’autre. En septembre 2018, une première proposition de modification du noyau a été faite dans ce sens [2]. D’après [3], ce nouveau namespace apparaîtra dans la version 5.6 du noyau Linux. Il fonctionnera de manière similaire au pid_ns dans le sens où l’association au namespace sera faite par les processus fils du processus créateur.
Sur GitHub (par exemple https://github.com/torvalds/linux), on peut d’ores et déjà voir les modifications associées dans la configuration du noyau. Le paramètre CONFIG_TIME_NS a été ajouté dans init/Kconfig :
Le fichier d’en-tête include/uapi/linux/sched.h contient la définition du drapeau associé au time_ns :
On aura noté que le bit utilisé empiète sur la définition de CSIGNAL vue plus haut. Afin d’éviter les ambiguïtés, ce drapeau ne pourra être utilisé qu’avec le nouveau service clone3() présenté dans [4]. Ce dernier adopte une interface plus extensible que son aîné, car il reçoit en paramètres la structure clone_args et la taille de cette dernière. Si des champs sont ajoutés dans le futur (toujours à la fin !), le noyau saura s’adapter en fonction de la valeur du second paramètre. Voici cette structure dans le fichier d’en-tête include/uapi/linux/sched.h :
Dans les nouvelles moutures de la GLIBC, clone3() est défini comme suit :
Le namespace est décrit par la structure time_namespace définie dans le fichier d’en-tête include/linux/time_namespace.h :
Le champ offsets structure timens_offsets contient les offsets à additionner à l’heure système pour obtenir une heure vue du namespace :
Le champ vvar_page sert à optimiser les appels système (par exemple gettimeofday(), clock_gettime(), etc.) relatifs au temps, car ils sont fréquemment utilisés par les programmes en espace utilisateur [5].
La structure nsproxy, avec laquelle le descripteur de tâche task_struct garde des références sur les descripteurs des namespaces auxquelles une tâche est associée, se voit augmentée de deux pointeurs pour le nouveau namespace. Le pointeur time_ns référence le descripteur de namespace de la tâche, tandis que sur le même modèle de fonctionnement que les pid_ns, le pointeur time_ns_for_children référence le time_ns pour les processus fils :
La liste des numéros d’inodes des namespaces initiaux se voit augmentée d’une entrée dans include/linux/proc_ns.h :
Le paquet util-linux est aussi prêt pour gérer ce nouveau namespace. Par exemple, dans le code source de la commande lsns (https://github.com/karelzak/util-linux/blob/master/sys-utils/lsns.c), les modifications ont été apportées en début mars 2020 pour prendre en compte le nouveau namespace :
2.2 Le namespace syslog
Il ne s’agit pas ici du service syslog() de la librairie C (man 3 syslog) qui dialogue avec le daemon (r)syslogd, mais de l’appel système syslog() (man 2 syslog) qui accède au journal de bord du noyau accessible via /dev/kmsg. Pour éviter les confusions entre le service en librairie et l’appel système, la fonction klogctl() de la librairie C enrobe ce dernier. Il s’agit donc ici des messages affichés par la fameuse fonction printk() et stockés dans une mémoire tampon circulaire du noyau. L’utilitaire dmesg du shell affiche son contenu. La figure 2 résume tout cela.
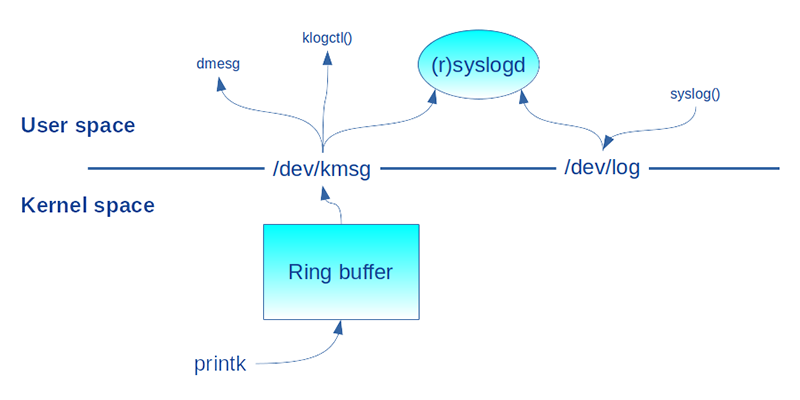
Jusqu’à maintenant, les affichages résultant des appels printk() du noyau sont visibles sur hôte et dans tous les conteneurs. Cela peut gêner l’administration des conteneurs pour lesquels les opérateurs n’ont pas forcément accès au système hôte. Cela peut aussi poser des problèmes de sécurité avec une fuite d’informations critiques de l’hôte vers les conteneurs ou d’un conteneur à l’autre.
Par exemple, un appel à dmesg dans un conteneur LXC busybox affiche le contenu du journal système commun au système hôte et à tous les conteneurs :
L’idée d’un syslog_ns est d’isoler les affichages de printk() de chaque conteneur. L’article [6] explique les problèmes liés à l’implémentation et explore notamment certaines solutions pour résoudre le cas des appels printk() hors contexte de tâche (p. ex. contexte d’interruption), alors que les namespaces normalement liés aux tâches sont retrouvés par le descripteur de la tâche en cours (c.-à-d. current→nsproxy comme indiqué dans nos articles [7] et [8] dédiés à l’implémentation dans le noyau). Jusqu’à aujourd’hui, aucune solution n’a été mise dans la branche principale de Linux.
Faute de mieux, la valeur 1 dans le fichier /proc/sys/kernel/dmesg_restrict est un pis-aller afin de limiter la vision du journal du noyau aux utilisateurs privilégiés. Si nous faisons l’essai sur hôte :
Un utilisateur non privilégié ne pourra plus voir le contenu du journal système :
Ce fichier étant commun au système hôte et aux conteneurs, rien ne change dans un conteneur LXC busybox privilégié, car il s’exécute dans le user_ns initial. Son utilisateur root est par conséquent le super utilisateur du système hôte :
Mais dans un conteneur non privilégié (c.-à-d. avec son propre user_ns !) comme notre session shns3 maintes fois utilisée jusqu’à maintenant, même l’utilisateur privilégié sera restreint, car root est mappé sur un utilisateur non privilégié du système hôte (c.-à-d. UID/GID égaux à 1000) :
2.3 Le namespace device
Les périphériques sont liés au user_ns initial. Et pour les interfaces réseau, ils sont même liés au net_ns initial [9]. Même si certaines interfaces peuvent migrer d’un net_ns à l’autre. Lors de l’étude des net_ns, nous avons vu le concept de SR-IOV qui permet de partager un même périphérique entre plusieurs namespaces. Le champ d’application reste cependant limité à certains types de périphériques répondant à la norme PCI Express.
Des solutions ont été proposées afin de créer un namespace device [10] ou de virtualiser devtmpfs, le pseudo système de fichiers qui gère les périphériques, de sorte à pouvoir le monter dans différents user_ns [11]. Mais cela n’a visiblement pas été retenu.
C. Brauner (l’un des développeurs de LXC) propose une autre direction avec la virtualisation des périphériques [12] en utilisant le protocole netlink (cf. man 7 netlink) utilisé pour le dialogue entre l’espace noyau et l’espace utilisateur.
3. Durée de vie des namespaces
Le manuel man 7 namespaces indique qu’un namespace disparaît lorsqu’il n’a plus de processus associé, sauf sous certaines conditions :
- le namespace est un namespace initial ;
- la cible d’un lien symbolique est ouverte sur le namespace dans /proc/<pid>/ns ;
- le namespace est hiérarchique (c.-à-d. pid_ns ou user_ns) et il a des namespaces fils actifs ;
- le namespace est un user_ns et il est propriétaire de namespaces actifs ;
- le namespace est un pid_ns et un processus référence le namespace via le lien symbolique /proc/<pid>/ns/pid_for_children ;
- le namespace est un ipc_ns et un système de fichiers pour ses queues de message POSIX est monté ;
- le namespace est un pid_ns et un système de fichiers de type proc le référence.
4. Gestion du plantage de processus
4.1 Nommage du fichier core
Par défaut, les informations générées lors du plantage d’un processus sont stockées dans un fichier nommé core. Il est possible de définir un autre nom respectant un schéma de nommage stocké dans /proc/sys/kernel/core_pattern (cf. man 5 core). Ce fichier est global au noyau : son contenu concerne tous les namespaces. En d'autres termes, il n’est pas virtualisé. Les spécificateurs suivants sont des raccourcis (placeholders) remplacés par les valeurs associées au moment du crash :
Le code source de Linux 5.3.0 qui gère la substitution des spécificateurs se trouve dans fs/coredump.c. C’est géré par une instruction switch dans la fonction interne format_corename() :
Les spécificateurs qui nous intéressent dans le contexte des namespaces sont :
- %p et %P : identifiants du thread principal du processus respectivement dans le pid_ns courant et le pid_ns initial. On notera l’utilisation respective des « helpers » task_tgid_vnr() et task_tid_nr() vus lors de l’étude des sources du noyau [8] ;
- %i et %I : identifiants du thread courant respectivement dans le pid_ns courant et le pid_ns initial. Si le processus est monothreadé, ce sont respectivement les mêmes valeurs que %p et %P. On notera l’utilisation respective des « helpers » task_pid_vnr() et task_pid_nr() vus lors de l’étude des sources du noyau [8] ;
- %u et %g : identifiants d’utilisateur et groupe du processus dans le user_ns initial. D’où la référence à la structure init_user_ns vue lors de l’étude des structures de données dans le noyau [7] ;
- %h : le manuel donne la définition laconique « hostname (same as nodename returned by uname(2)) ». Est-ce le nom de l'hôte dans l’uts_ns initial ou celui de l’uts_ns courant ? Le fait qu’il soit en minuscule, on subodore que c’est le second choix conformément à la méthodologie de nommage utilisée pour les identifiants de processus et thread. Voyons cela de plus près...
Le code source précédent montre que le spécificateur est substitué par utsname()->nodename. La fonction utsname() est définie dans include/linux/utsname.h comme suit :
C’est le résultat du déréférencement du champ nsproxy à partir du pointeur current. Ce dernier est le pointeur sur la tâche en cours d’exécution dans le noyau. Autrement dit, c’est la tâche en cours de plantage. Cela fait de current->nsproxy->uts_ns->name, donc du spécificateur %h, le nom d’hôte dans l’uts_ns de cette tâche, donc l’uts_ns courant.
Mettons en pratique un schéma de nommage du fichier core :
Introduisons le programme multi-th qui lance autant de threads que le nombre passé en argument. Le thread principal (main) ainsi que les secondaires (th_main) se mettent ensuite en attente sur pause() :
Lançons le programme shns3. Par défaut, il lance un shell dans de nouveaux namespaces pour chaque type. Configurons la taille des fichiers core si nécessaire ainsi que le système de fichiers /proc (pour avoir des identifiants de processus cohérents avec le pid_ns dans le résultat de la commande ps) et le nom de l’hôte.
Faisons une digression sur une faiblesse de Bash. Au démarrage, ce dernier obtient le nom de l’hôte avec un appel à gethostname() et mémorise le résultat une fois pour toutes dans ses contextes. Si par la suite nous changeons le nom de l’hôte, il n’est pas pris en compte, car Bash continue à utiliser la valeur stockée dans ses contextes. Le spécificateur \h dans la variable PS1 ne change donc pas de valeur de nom d’hôte. Pour contourner ce problème, on réexécute Bash pour qu’il relance son initialisation (sans relire le fichier .bashrc avec l’option --norc au cas où ce dernier change PS1) afin que le nouveau nom de l’hôte soit pris en compte dans le prompt (variable PS1) :
Puis lançons le programme multi-th en arrière-plan :
Simulons un plantage de l’un des threads de multi-th en lui envoyant le signal SIGSEGV :
Nous constatons l’apparition du fichier core nommé conformément au schéma stocké dans core_pattern :
Les spécificateurs %e, %h, %g, %u, %p, %P, %i et %I ont respectivement été substitués par le nom de l’exécutable (multi-th), le nom de l'hôte (new-pc) dans l’uts_ns auquel le thread était associé, les identifiants d’utilisateur et de groupe du processus dans le user_ns initial (1000), l’identifiant de processus dans le pid_ns du processus (28), l’identifiant de processus dans le pid_ns initial (18647), l’identifiant de thread dans le pid_ns du processus (30) et l’identifiant de thread dans le pid_ns initial (18649).
4.2 Redirection du fichier core
Linux supporte une syntaxe alternative dans /proc/sys/kernel/core_pattern : si le premier caractère est « | » (le fameux tube du shell), alors le reste de la ligne est interprété comme un exécutable suivi de ses paramètres à déclencher lors du plantage d’un processus. Les informations liées au plantage (le fichier core) sont injectées sur son entrée standard. Les spécificateurs vus plus haut sont aussi utilisables sur la ligne de commande. Il est important de noter que le chemin du programme à exécuter est situé dans le mount_ns initial et c’est d’ailleurs toujours dans les namespaces initiaux qu’il est exécuté. Dans un contexte où des conteneurs sont en action, cela signifie que tout plantage de processus à l’intérieur ou à l’extérieur des conteneurs sera pris en charge par ce programme qui s’exécute dans le contexte de l’hôte ! D’où l’intérêt de la possibilité de passer les spécificateurs en paramètres du programme afin qu’il puisse identifier les namespaces, voire même le conteneur où le plantage a eu lieu.
Notre script shell getcore s’appuie tout simplement sur la commande dd pour stocker dans /tmp le contenu du core reçu sur son entrée standard. Le fichier de sortie est nommé de la même manière que dans notre exemple précédent avec les informations passées en paramètres :
Modifions core_pattern de sorte à invoquer ce script (avec un chemin absolu !). Ici, on transfère l’outil dans /tmp pour les besoins de l’article, mais dans un environnement professionnel, il devra de préférence se trouver dans un répertoire comme /sbin :
Relançons shns3 comme précédemment avec la configuration de la taille des fichiers core et le montage du système de fichiers /proc, le lancement de multi-th en arrière-plan et la terminaison de l’un de ses threads par le signal SIGSEGV. Le script est invoqué pour produire en sortie le fichier core conformément à nos attentes :
On peut même lancer une session gdb afin de vérifier que le fichier généré est bien au format correct :
4.3 Les fichiers core dans LXC
Le système de fichiers /proc et notamment sa sous-arborescence /proc/sys ainsi que /sys contiennent des informations sensibles ainsi que des paramètres de configuration du système hôte. Il faut donc éviter la fuite d’information et les risques de corruption par le truchement des conteneurs. La configuration de LXC prévoit différentes manières de monter /proc et /sys :
Les conteneurs LXC busybox choisissent par défaut la valeur proc:mixed de sorte à monter /proc en lecture/écriture, mais avec /proc/sys en lecture seule :
Si on lance un conteneur, son fichier core_pattern a la valeur que nous avons positionnée côté hôte plus haut, car il est global au système et l’on ne peut pas le modifier :
Configurons la taille du fichier core dans le conteneur et vérifions que getcore n’est pas dans le répertoire /tmp du rootfs du conteneur (nous rappelons que le conteneur a son propre système de fichiers situé dans /var/lib/lxc/<nom de conteneur>/rootfs dans lequel il fait un pivot_root()) :
En simulant un plantage dans le processus syslogd du conteneur, nous constatons qu’il n’y a pas de fichier core dans son répertoire /tmp :
Par contre, côté hôte, le fichier core associé au plantage est bien dans /tmp :
Nous avons donc bien vérifié que, quel que soit l’endroit du plantage d’un exécutable (en conteneur ou hors conteneur), le script mentionné dans core_pattern est lancé dans les namespaces initiaux (c.-à-d. côté hôte). Donc de ce point de vue, le script getcore va écrire dans le répertoire du mount_ns de l’hôte. Les spécificateurs, et notamment %h, sont d’un grand secours pour identifier le conteneur où le plantage a eu lieu.
Conclusion
Les namespaces sont une réponse au célèbre aphorisme de D. Wheeler [13] : « tous les problèmes dans le domaine de l’informatique peuvent être résolus par un nouveau niveau d’indirection » (ou d’abstraction).
Cette série d’articles agrémentée de nombreux exemples est une approche essentiellement pratique des namespaces. Le but n’était pas d’être exhaustif, mais de constituer un complément à la documentation disparate et parfois incomplète sur certains aspects. Nous avons apporté une vision sous des angles différents et notamment un aperçu de l’implémentation dans les utilitaires, le noyau et LXC. Nous pouvons même nous targuer d’avoir révélé des secrets d’implémentation jusqu’ici jalousement gardés par la communauté des développeurs du noyau Linux. Nous avons ainsi levé le voile sur ce qui constitue les fondations de la conteneurisation sous Linux.
Le concept de namespace va dans le sens d’une nouvelle approche de la construction des applications dans un monde qui demande de plus en plus aux machines en termes de puissance et de fonctionnalités. Nous passons d’un modèle monolithique à un modèle modulaire. Le maître mot en la matière est une interprétation au sens figuré de l’adage « diviser pour mieux régner » : diviser pour mieux partager les ressources matérielles, diviser pour découper les applications en microservices [14] afin de réduire les temps de développement, de faciliter la maintenance, d’améliorer la robustesse et la sécurité, de favoriser l’évolutivité pour une juste adaptation aux besoins et enfin, de faciliter la portabilité et le déploiement.
Alors que les namespaces permettent d’instancier les ressources du noyau, le lecteur pourra aussi se pencher sur les cgroups, l’autre pilier des conteneurs, dont l’objectif est de contrôler l’utilisation des ressources.
Références
[1] Les cgroups : https://fr.wikipedia.org/wiki/Cgroups
[2] Le namespace time : https://lwn.net/Articles/766089/
[3] Le namespace time dans le noyau :
https://www.phoronix.com/scan.php?page=news_item&px=Linux-Time-Namespace-Coming
[4] L’appel système clone3() : https://lwn.net/Articles/792628/
[5] Implementing virtual system calls : https://lwn.net/Articles/615809/
[6] Le namespace syslog : https://lwn.net/Articles/527342/
[7] R. KOUCHA, « Les structures de données des namespaces dans le noyau », GNU/Linux magazine n°243, décembre 2020 : https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-243/les-structures-de-donnees-des-namespaces-dans-le-noyau
[8] R. KOUCHA, « Le fonctionnement des namespaces dans le noyau », GNU/Linux magazine n°245, février 2021 :
https://connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-245/Le-fonctionnement-des-namespaces-dans-le-noyau
[9] R. KOUCHA, « Les namespaces network et pid », GNU/Linux magazine n°256, mars - avril 2022 :
https://connect.ed-diamond.com/gnu-linux-magazine/glmf-256/les-namespaces-network-et-pid
[10] Device namespaces : https://lwn.net/Articles/564854/
[11] Add support for devtmpfs in user namespaces : https://lwn.net/Articles/598782/
[12] Making the Kernel and Udev Namespace Aware : https://www.youtube.com/watch?v=ondREXbSa5E
[13] David Wheeler (computer scientist) : https://en.wikipedia.org/wiki/David_Wheeler_(computer_scientist)
[14] Les microservices : https://en.wikipedia.org/wiki/Microservices
