

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Comprendre précisément le fonctionnement d’un système est important pour la réalisation d’une attaque, mais également pour le maintenir en conditions opérationnelles. Les développeurs et devops utilisent des outils spécifiques pour observer et comprendre leurs systèmes en temps réel - et même de façon proactive. Par exemple, pour comprendre la performance d’une application web, pour prédire le remplissage d’un disque dur ou pour détecter des erreurs dans les logs d’un fournisseur de cloud. Ces données peuvent aussi aider un attaquant à comprendre d’une part l’architecture du système ciblé, et d’autre part ses réactions à leurs stimuli.
1. Qu’est-ce que l’observabilité ?
L’observabilité permet aux créateurs et mainteneurs d’un système de surveiller son fonctionnement. On connaît tous les logs d’un serveur, qui permettent très simplement et intuitivement de comprendre ce qu’il s’y passe. Mais lorsque l’on parle d’un système plus complexe, et notamment distribué comme le sont souvent les architectures modernes, les logs ne suffisent plus. Un tel système peut contenir de nombreux services (applications web, API, bases de données…), répartis sur plusieurs serveurs, conteneurs, eux-mêmes répartis sur différents datacenters, dans différentes zones géographiques ou fournisseurs de cloud différents. La surveillance d’une telle profusion de systèmes requiert des outils spécifiques.
L’observabilité permet de donner une vision haut niveau du système, par exemple en agrégeant les données de tous les serveurs ou conteneurs, ou en représentant graphiquement les relations entre les différentes API.
L’observabilité utilise typiquement 3 catégories de données : logs, métriques, et traces.
|
|
Logs |
Métriques |
Traces |
|
Quoi ? |
Message généré à un moment précis pour décrire un évènement particulier |
Une valeur numérique à un moment donné |
Graphe d’appels représentant une requête traversant un système |
|
Exemples |
Log applicatif (l’utilisateur X vient de se connecter) ou système (le processus P a été tué) |
Évolution de l’occupation mémoire d’un conteneur Évolution de l’espace libre sur un volume |
Une requête HTTP passant via un load balancer pour contacter plusieurs microservices, ce qui résulte en un graphe d’appel |
|
Installation |
Simplement stdout ou un fichier, ensuite envoyé vers un collecteur (à la syslogd) |
Un agent local envoie les métriques du système, ou un système distant utilise les API du fournisseur cloud |
Librairie dans l’application (APM) |
2. Quels outils pour l’observabilité ?
Il existe une profusion d’outils d’observabilité, comme des plateformes commerciales ou des outils open source. Les outils commerciaux sont notamment AppDynamics, Datadog, Dynatrace, Elastic (le seul dont le backend est également disponible en open source). Ils couvrent les 3 catégories précédemment mentionnées.
Le standard Open Telemetry [OTEL] supporte les 3 catégories de données et la plupart des vendeurs commencent à le supporter. Il permet d’instrumenter ses applications indépendamment du vendeur.
La suite logicielle libre Prometheus est un backend pouvant récupérer les données d’Open Telemetry, et peut utiliser Grafana pour les afficher.
Du point de vue de la sécurité, le meilleur choix est en général d’adopter le logiciel que les équipes d'ingénieurs utilisent, car ce sont ces équipes qui doivent installer et maintenir les outils d’observabilité, s’assurer que les nouveaux services en bénéficient…
3. Zoom sur les traces
Les traces sont très proches du fonctionnement d’une application web / API et sont donc l'élément le plus intéressant pour un pentest. Ce paragraphe détaille ce qu’est une trace et comment elle est construite.

Voici une infrastructure d’exemple où une requête initiale (R0) contacte un premier service S0, qui lui-même va contacter d’autres services. S1 est peut-être une base de données, et S2 une autre API, qui dépend elle-même de S3 et S4 pour répondre à S0.
Pour générer ce graphe, chaque service nécessite de supporter les traces. C’est en général le rôle d’un composant nommé APM, pour Application Performance Management. Imaginons que l’APM soit installé sur chaque service. À chaque requête reçue par un service, l’APM tente d’y détecter un identifiant, et de le propager à tous les appels sous-jacents. Ainsi, tous les appels causés par cette requête y seront liés par cet identifiant.
Si aucun identifiant n’est présent, l’APM va en générer un.
Cet identifiant définit une trace, qui est elle-même composée de spans. Un span est une information atomique telle qu’une requête à une base de données, une erreur, une information métier tel qu’un log… Chaque span est lié hiérarchiquement à un autre span. L’ensemble des spans constitue donc la trace.
La complétude de ce graphe dépend de la quantité de composants logiciels instrumentés par l’APM. Si une technologie non supportée par l’APM est utilisée, alors elle sera invisible. Par exemple, si le lien entre S2 et S4 utilise une librairie gRPC non supportée par l’APM, alors le lien S2 -> S4 sera invisible, car S2 ne sera pas capable de détecter la requête vers S4, et ne pourra donc pas y injecter l’identifiant de trace. S4 générera ainsi un nouvel identifiant unique, qui générera une nouvelle trace, qui ne sera pas liée à la trace précédente.
4. Comment s’interfacer lors d’un pentest ?
L’objectif de l’attaquant est de pouvoir consulter dans la plateforme d’observabilité l’effet des requêtes envoyées lors des tests. Une intégration avec un reverse proxy tel que Burp le permet très simplement : il suffit d’enrichir chaque requête sortante avec un identifiant de trace, générée par l’attaquant de façon aléatoire. Cet identifiant sera par définition propagé dans tout le système par les outils d’observabilité. L’attaquant pourra ensuite afficher cet identifiant dans la plateforme d’observabilité, et directement consulter toutes les opérations liées à cette requête particulière.
Il va de soi que le système attaqué doit utiliser une plateforme d’observabilité, et que cette méthodologie ne peut pas être appliquée lors d’un test en aveugle - à moins de compromettre en premier l’accès à la plateforme d’observabilité.
Dans le cas d’un système attaqué utilisant OpenTelemetry, l’identifiant généré doit être placé dans l’en-tête HTTP trace parent.
Une extension permettant d’interfacer Burp et la plateforme Datadog est disponible [APMToBurp]. Dans celle-ci, un simple clic droit sur une requête injectée permet d’ouvrir la trace correspondante dans le navigateur.
5. Quelles applications dans un pentest ?
Les applications dépendent des fonctionnalités de la plateforme d’observabilité utilisée. Voici les cas d’usage les plus répandus.
5.1 Comprendre la topologie du réseau et des applications
L'agrégation de traces permet de définir une topologie du réseau et les dépendances de chaque service. Représentée sous forme de carte, elle permet de mieux comprendre les types de services présents, les dépendances interservices, les sources de données, la surface d’attaque…
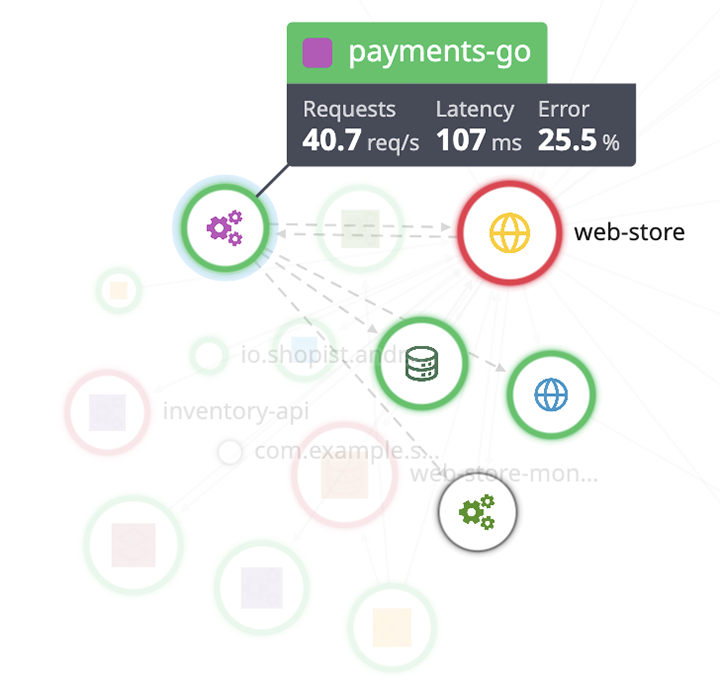
5.2 Détecter et comprendre des erreurs
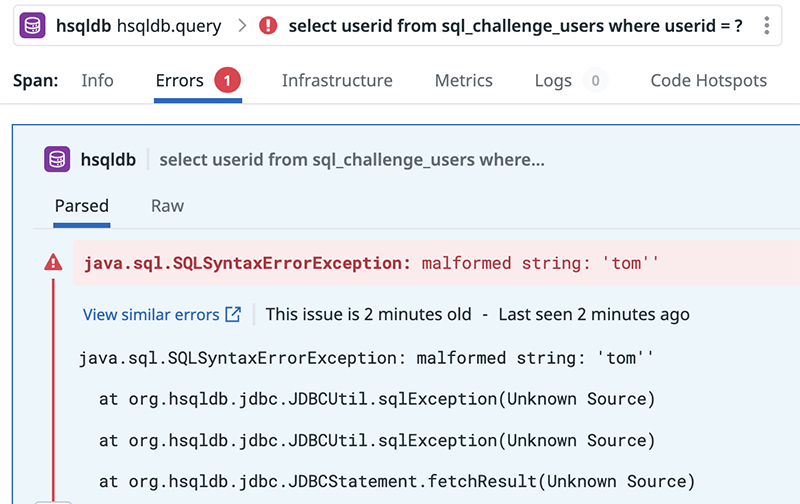
Les APM remontent quantité d’informations importantes pour les mainteneurs de services et en particulier les erreurs applicatives (par exemple, les exceptions ou les logs de type erreur). Pour un attaquant, être capable de comprendre pourquoi une requête particulière a généré une exception permet de détecter des bugs, certains pouvant mettre en avant des vulnérabilités.
Dans l’exemple ci-dessous (issu de l’application vulnérable [WebGoat]), là où un attaquant aveugle verrait simplement une erreur HTTP 500, la plateforme d’observabilité fournit l’exception générée par l’application et permet donc de détecter la présence d’une vulnérabilité de type injection SQL, grâce à la requête SQL automatiquement remontée par l’APM. Les requêtes SQL sont en effet très utiles aux administrateurs, car souvent critiques dans la performance des applications.
Si la plateforme permet de lier une application à son code source, l’attaquant peut même parcourir le code source lié à cette erreur.
5.3 Exploiter une vulnérabilité
L’exemple précédent permet de déceler la présence d’une injection SQL et de l’exploiter beaucoup plus simplement qu’en aveugle, en particulier par la compréhension de l’erreur, mais également de la présence de la requête SQL.
De nombreuses autres fonctions instrumentées par les APM permettent des approches similaires pour confirmer (ou infirmer) des vulnérabilités. Dans cet exemple, l’un des spans représente une requête HTTP à un autre système, sur le path /SSRF/task1. L’APM va présenter les détails de cet appel tels que l’URL complète appelée, permettant à l’attaquant de comprendre où son paramètre est injecté et comment modifier cet appel.

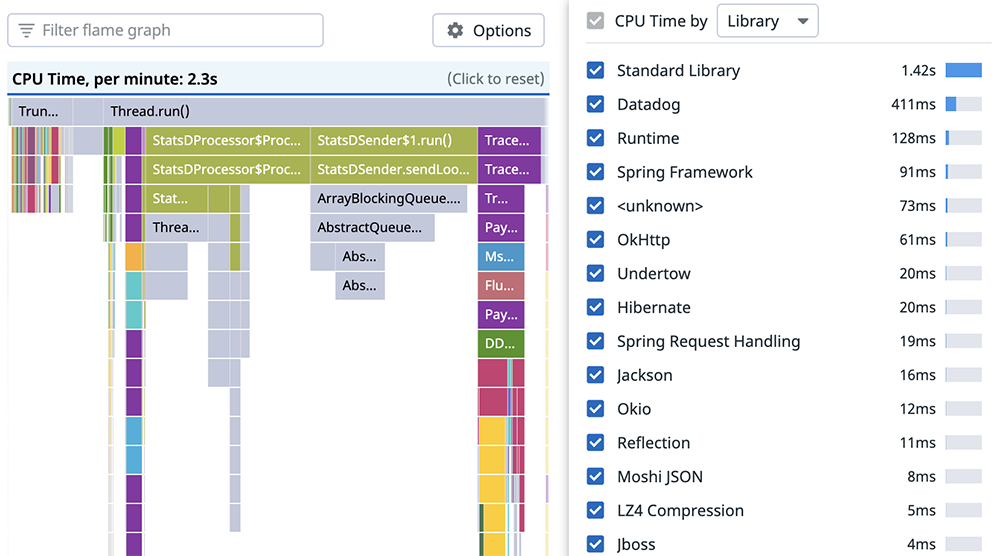
5.4 Comprendre le code en fonctionnement
Certains APM supportent des fonctionnalités de profiling, permettant d’obtenir des détails sur l’intégralité de l’exécution de l’application (et non seulement les parties instrumentées). Le profiling utilise un mécanisme de sampling (typiquement, la stack du processus est capturée à intervalles réguliers, puis résolue et enregistrée). Cela permet à l’APM de détecter les librairies tierces parties utilisées par l’application, et notamment celles appelées lors d’une requête particulière.
Cette approche statistique ne permet pas de facilement comprendre si un code path particulier est utilisé pour une requête spécifique, mais aide à comprendre si un endpoint spécifique utilise une certaine librairie.
6. Pour qui ?
Les red teamers dont l’employeur utilise une plateforme d’observabilité sont probablement les plus concernés. Par exemple, la red team de Datadog utilise ces techniques intensivement lors des tests internes. De la même façon, lors d’un pentest réalisé par une entité extérieure, leur proposer un compte sur le ou les outils d’observabilité utilisés permet d’accélérer la compréhension du système tout comme la qualité des tests.
Enfin, les systèmes d’observabilité sont une cible très intéressante pour un attaquant qui peut en tirer des informations très importantes.
Conclusion
Les outils d’observabilité fournissent un nouvel éclairage sur le fonctionnement interne d’un système. Nous n’avons fait qu’effleurer la surface de ce que permettent ces outils, et ils ont d’ailleurs un spectre différent d’une organisation à l’autre où leur adoption et leur usage diffèrent.
Liens
[OTEL] https://opentelemetry.io/
[APMToBurp] https://github.com/aviat/APMToBurp
[WebGoat] https://github.com/WebGoat/WebGoat


