

 Ajouter à une liste de lecture
Ajouter à une liste de lectureTester les manifestes Kubernetes pour se prévenir des erreurs de configuration avant de déployer sur un cluster de production est l’une des étapes cruciales après les tests applicatifs. Automatiser ces tests à travers un pipeline GitLab-CI et assurer un Continuous Delivery via Argo CD est le scénario parfait pour la mise en œuvre d’une démarche DevOps/GitOps. C’est ce que nous allons découvrir dans cet article.
Introduction
L’un des objectifs du DevOps est de limiter les possibilités d’erreurs humaines. Cependant, il s’avère que le développement logiciel est bien sujet à ce type d’erreurs. Les erreurs dans le cycle de vie des logiciels peuvent entraîner des défauts et des défaillances dans le système logiciel affecté.
L’assurance qualité est nécessaire pour éviter ces situations, réduire le nombre d’erreurs et améliorer la qualité d’un produit. Les tests logiciels constituent une technique d’assurance qualité essentielle qui exécute une série de validations et analyse les différents aspects du fonctionnement d’un logiciel.
Dans cet article, nous détaillerons en bref les différents tests à mettre en place dans un pipeline de CI/CD. Nous consacrons une grande partie aux tests des fichiers de configuration et de déploiement des ressources Kubernetes. L’outil que j’apprécie beaucoup en ce moment est datree. Un outil avec lequel on peut définir nos propres règles de contrôle de la qualité de nos fichiers de déploiement. La suite de l’article est également consacrée à l’automatisation de ces tests et au déploiement des ressources résultantes à travers l’outil de Continuous Delivery Argo CD. Toute la partie automatisation du CI/CD sera réalisée avec GitLab-CI. Bonne lecture !
1. Présentation des outils
Avant d’entrer dans le vif du sujet, passons en revue les différents outils qui seront exposés dans l’article.
1.1 GitLab-CI
GitLab-CI est une plateforme d’intégration et de déploiement continue, assurant la gestion complète d’un projet et le suivi du cycle de développement logiciel. Aujourd’hui, GitLab est considéré comme une plateforme de DevOps, car et à la différence d’autres outils et à l’instar de Jenkins, elle permet d’avoir une usine logicielle intégrée permettant de :
- gérer le versionning du code source ;
- mettre en place un workflow complet de gestion du projet ;
- une implémentation intégrée des pipelines d’intégration et de déploiement continu ;
- mettre à disposition des registry de gestion des livrables et des conteneurs ;
- une intégration avec les plateformes d’orchestration de conteneurs et particulièrement Kubernetes.
La plateforme est accessible soit on-promise (en version communautaire ou commerciale), soit en SAAS via l’offre gitlab.com.
1.2 Kubernetes
Kubernetes est un système open source permettant d’automatiser le déploiement, la mise à l’échelle et la gestion des applications conteneurisées. Aujourd’hui, Kubernetes est considéré comme la plateforme idéale pour la création des environnements cloud native et c’est la raison pour laquelle les différents fournisseurs cloud publics disposent d’une offre managée des clusters Kubernetes.
1.3 datree
Comme évoqué à l’introduction de cet article, l’outil de test datree permet d’appliquer des règles et d’en définir d’autres pour assurer le respect des bonnes pratiques de déploiement des manifestes Kubernetes, mais aussi d’instaurer des règles universelles qui seront implémentées au sein des projets. L’outil datree s’intègre avec les outils de CI/CD pour contrôler l’état des fichiers de déploiement avant leur mise en production.
1.4 Argo CD
Argo CD est un outil de livraison continue, il est considéré comme étant l’outil incontournable pour la mise en œuvre du concept GitOps à l’instar de FluxCD. Le principe d’un tel outil est de reposer sur les changements au niveau de Git en tant que source unique de vérité pour déclencher le processus de déploiement des applications dans Kubernetes.
2. Provisionnement automatisé d’un cluster Kubernetes
Notre première étape dans cet article est de provisionner l’infrastructure pour déployer notre application. Kubernetes sera bien évidemment notre environnement cible pour la mise en place de notre projet de CI/CD.
L’installation de Kubernetes a été détaillée dans plusieurs articles de Linux Pratique. Cette fois, l’idée est d’automatiser le provisionnement d’un cluster Kubernetes à travers des manifestes Terraform.
Un projet permettant d’automatiser ce déploiement dans DigitalOcean est disponible via ce lien GitHub : https://github.com/hivenetes/k8s-bootstrapper.
2.1 Mise à disposition du projet d’amorçage de cluster
Commençons par cloner le dépôt contenant les fichiers Terraform de déploiement de Kubernetes :
Ensuite, il faut initialiser notre projet Terraform :
Paramétrons notre fichier de variable comme suit :
Vérifions ensuite les ressources qui seront déployées par Terraform :
2.2 Provisionning du cluster Kubernetes
Une seule commande permet d’installer notre cluster :
Le provisionning reste une dizaine de minutes pour déployer le control plane et les workers du cluster.
Sur le tableau de bord de DigitalOcean, on aperçoit que le cluster est bel est bien là (Figure 1) !

2.3 Accès au cluster Kubernetes
Pour pouvoir accéder au cluster Kubernetes et déployer des ressources, nous aurons besoin de deux étapes à mettre en place :
- Installer le client kubectl :
- Importer le kubeconfig contenant le certificat d’accès au cluster :
Puis, ajouter le contenu du kubeconfig dans le répertoire kube :
Vérifions l’accès au cluster en affichant la liste des nœuds Kubernetes :
3. Déploiement d’Argo CD
L’outil Argo CD est déployable en ressources Kubernetes au sein de notre cluster provisionné précédemment. Les étapes de déploiement se résument par les deux commandes suivantes :
La première commande ajoute le namespace argocd. La deuxième commande créera les ressources nécessaires dans le namespace argocd.
Sans entrer dans les détails de l’architecture Argo CD pour le moment, voici les pods créés par les manifestes de déploiement :
On est presque arrivés ! Il nous faut l’URL d’accès à l’IHM Argo CD, pour cela il faut trouver le port exposé par le service Argo CD :
Il faut changer le type de service de ClusterIP à NodePort.
Affichons maintenant le port exposé :
Le port est 30384.
Essayons de nous connecter : https://161.35.94.40:30384/ (Figure 2).

Pour s’authentifier et accéder à Argo CD (Figure 3), il faut récupérer le mot de passe depuis le secret Kubernetes, le nom d’utilisateur est admin :
On revient dans la suite de l’article à Argo CD pour ajouter une application.
4. GitLab et les dépôts du projet
Notre projet est divisé en deux dépôts, le premier contient le code source de notre application et le second contient les manifestes de déploiement des ressources Kubernetes. En effet, c’est dans le second dépôt que l’outil de test datree réalisera les checks nécessaires pour s’assurer du bon respect des règles de déploiement mises en place.
Le rapport de test est généré lors du lancement du pipeline, ce dernier nous permettra d’inspecter si les règles ont été bien respectées, dans le cas contraire il est possible de suspendre le déploiement vers le cluster Kubernetes.
Argo CD n’intervient que lorsque le dépôt Git qui héberge les manifestes Kubernetes est modifié. Un commit dans ce dépôt permet à Argo de déployer les ressources. Dans notre article, le changement sera soit une nouvelle mise à jour de version d’image de notre application, soit un changement du nombre de réplicas du déploiement Kubernetes.
Argo CD, étant donné que c’est un outil de GitOps, va s’assurer que l’état souhaité dans le cluster Kubernetes est celui qui est décrit dans les fichiers manifestes du dépôt Git.
Le premier dépôt contenant le code de notre application exemple (code source en Node.js) est : https://gitlab.com/gitops_project/node-js-application.git.
Le dépôt contenant les ressources Kubernetes : https://gitlab.com/imejri/shark-app-deploy.git.
5. Intégration de l’outil datree et implémentation des règles de test
datree est un outil simple d’utilisation, en effet il s’appuie sur des règles prédéfinies pour éviter les erreurs de configuration des ressources Kubernetes créées dans les fichiers manifestes (yaml).
Il assure :
- la compatibilité entre les manifestes créés et le schéma Kubernetes ;
- l’instauration des bonnes pratiques et des politiques de déploiement et de configuration des ressources Kubernetes.
En mettant en œuvre le test avec datree, un déploiement peut être bloqué si une violation des règles a été détectée lors de l’exécution des tests automatisés dans un pipeline de CI/CD.
5.1 Installation de datree
Deux modes d’installation peuvent être établis avec datree :
- Une installation indépendante du cluster Kubernetes, dans ce cas on installe datree comme binaire en local ou dans un runner GitLab (voir paragraphe 6) et qui sera invoqué lors du déroulement du pipeline.
- La deuxième possibilité est d’installer datree directement au sein du cluster Kubernetes, dans ce cas datree assure le scan des différentes violations des règles mises en place à travers sa politique.
Pour installer en ligne de commandes datree :
Une fois installé, une simple commande permet de tester notre fichier de déploiement. Voici notre manifeste Kubernetes à tester :
Lancement du test :
Le rapport de test est généré par datree, détectant des erreurs de configuration dans notre manifeste :
- pas de tag (version) pour notre image Docker, dans ce cas, il faut spécifier la version d’image à déployer ;
- le nombre de réplicas doit être supérieur à 1 pour assurer la disponibilité de l’application en cas d’erreurs ou de bugs du pod (conteneur) en exécution.
Le rapport affiche également le nombre des règles évaluées (14) ainsi que celles qui sont en échec (2).
5.2 Gestion des règles dans le tableau de bord datree
Pour l’activation ou la désactivation des règles datree dans le processus de tests, il faut créer un compte dur app.datree.io. Une fois le compte créé, il faut lier la commande datree à un token pour importer l’ensemble des règles déclarées dans le tableau de bord datree. Voici en figure 4 ce à quoi ressemble le tableau de bord datree.
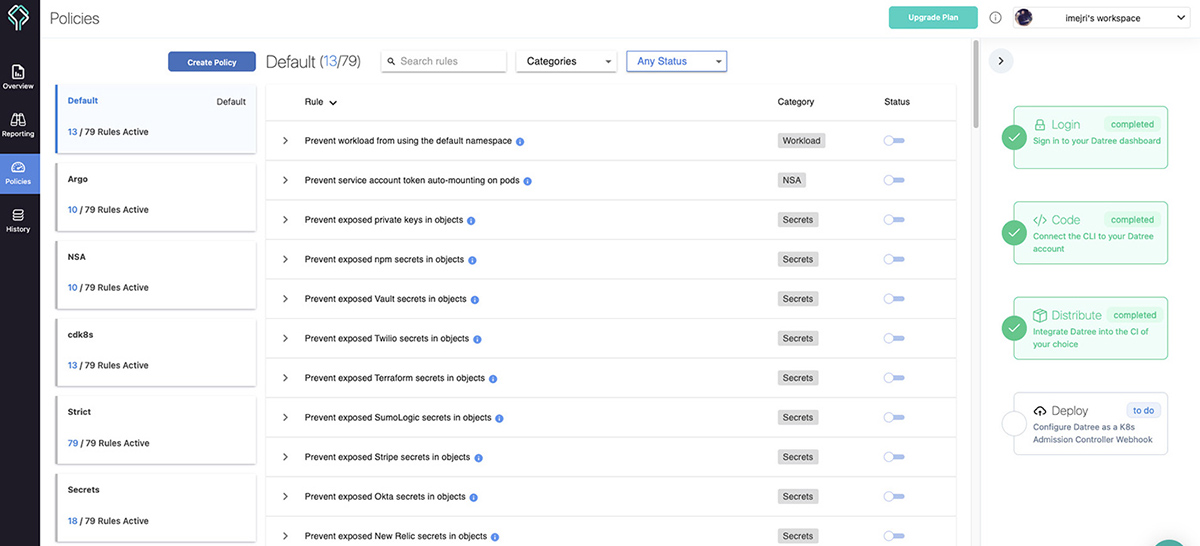
Les règles sont définies par catégorie (Deprecation, Container, Networking, Workload…) et par statut (active/inactive).
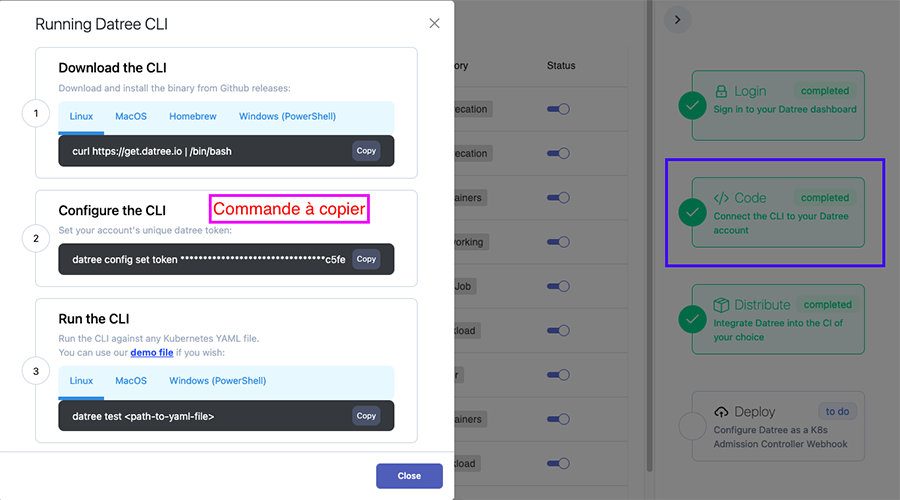
Pour relier la commande datree à notre compte, il faut passer en paramètre le token :
Pour récupérer le token, cliquez sur la barre latérale gauche sur Policies, puis sur le volet droit, cliquez sur le deuxième cadre en vert, indiquant la connexion de la CLI avec le compte datree.
6. Analyse du pipeline CI/CD
L’approche CI/CD définit l’automatisation comme l’un des concepts fondamentaux du DevOps. GitLab CI est un outil très prisé des utilisateurs qui permet d’automatiser la compilation, le test et le déploiement d’applications. Le pipeline est la mise en œuvre de cette automatisation. En effet, lorsqu’un changement est détecté dans un référentiel Git, Gitlab CI exécute une compilation automatisée pour vérifier que les nouvelles modifications sont correctes. Il s’agit d’une série de phases (stage) de vérifications qui forment ce que l’on appelle un pipeline d’intégration continue. Un pipeline CI se compose généralement des étapes suivantes :
- Extraction : GitLab CI détecte les changements dans le référentiel git et télécharge les nouvelles modifications (le dernier commit) ;
- Compilation : GitLab CI exécute les commandes nécessaires pour compiler et créer le paquetage de l’application ;
- Test : c’est la phase des tests d’application pour s’assurer que les dernières modifications sont correctes et ne présentent pas de bugs.
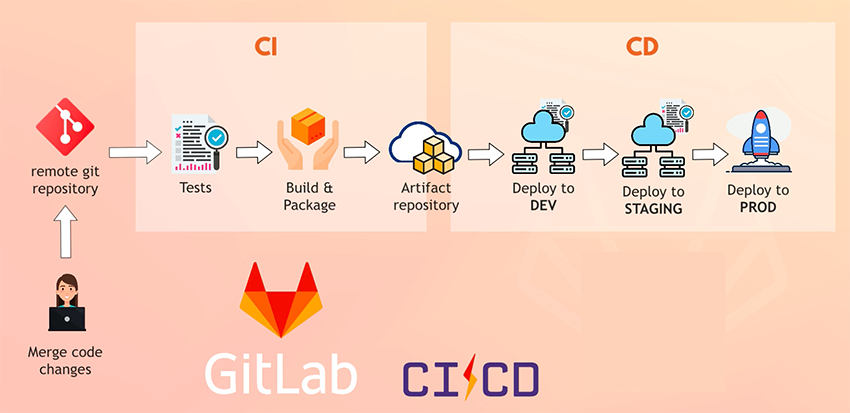
À toutes ces phases s’ajoute la partie pipeline CD (pipeline de livraison ou de déploiement), cette phase est fortement liée aux premières, car une fois que les précédentes phases s’exécutent sans échec, le pipeline pourra déployer l’application (artifact, image Docker...) dans les environnements cibles. La figure 6 résume le process de CI/CD dans GitLab CI.
Dans GitLab CI, les pipelines sont créées dans un fichier .gitlab-ci.yaml à la racine du projet. Voilà à quoi ressemble notre pipeline de CI/CD :
1
2
Datree-test:3
IMAGE_TAG: '$(cat version.txt)'Notre pipeline est composé de 3 stages :
- Permet de builder l’image de conteneur de l’application et de pousser vers le registry Quay.
- Réaliser les tests datree sur les manifestes kubernetes (situés dans un dépôt différent de celui où réside le code source de l’application) avant qu’Argo CD procède au déploiement des ressources au sein du cluster.
- Finalement, c’est la phase de mise à jour des manifestes avec la nouvelle version précédemment créée. L’étape de déploiement n’apparaît pas dans ce pipeline de façon explicite, car c’est Argo CD qui va déclencher la création des ressources quand il détecte un changement dans le référentiel Git. La configuration du workflow Argo CD (GitOps) sera réalisée dans le paragraphe qui suit.
6.1 Les Runners GitLab
Un GitLab Runner est une instance sur laquelle s’exécutent un ou plusieurs jobs. Un Runner peut être une machine virtuelle Linux, Windows, macOs déployée en local ou dans le cloud. Un job GitLab CI peut également s’exécuter dans un conteneur Docker.
Le runner doit éventuellement contenir tous les paquets et les binaires nécessaires pour réaliser les tâches qui lui sont confiées. Dans notre projet, il faut installer les outils : Git, Docker, datree, jq.
Une fois que ces outils sont installés, il faut installer le démon gitlab-runner et joindre le runner à l’instance GitLab (gitlab.com).
6.2 Installation du Runner GitLab
J’ai provisionné une VM CentOS 9 dans mon espace cloud comme Runner GitLab.
L’installation des différents outils a été réalisée. Maintenant, commençons l’installation de l’agent runner.
La première étape consiste à télécharger le binaire runner pour Linux :
Ajouter les permissions d’exécution :
Créer l’utilisateur gitLab-runner :
Installer et exécuter le service runner :
Finalement, enregistrer le runner :
La variable $REGISTRATION_TOKEN contient le token permettant de s’authentifier auprès de GitLab lors de la phase de l’enregistrement. Le token est disponible dans Settings > CI/CD > Runners.
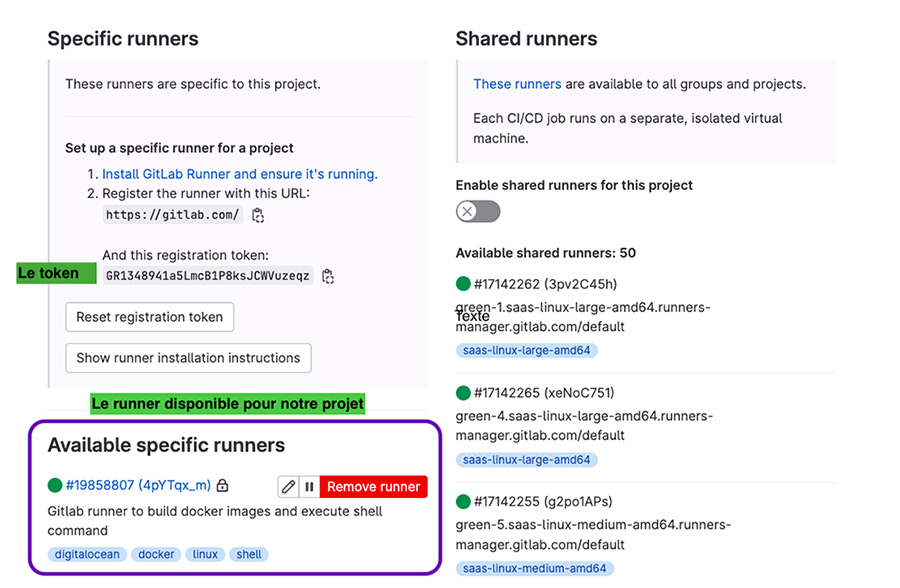
7. Création du projet dans Argo CD et mise en place du GitOps
La dernière brique à mettre en place dans notre projet est Argo CD. L’installation d’Argo CD a été abordée dans le paragraphe 3. Décrivons le mode de fonctionnement d’Argo CD.
Argo CD est un outil de GitOps, il permet d’assurer une réconciliation entre le contenu d’un dépôt Git et les ressources déployées dans Kubernetes, il valide ce qu’on appelle en anglais le desired state.
Les composants d’Argo CD sont :
- l’API Server : semblable à Kubernetes, Argo CD dispose d'un serveur d'API qui expose des API avec lesquelles d'autres systèmes peuvent interagir, comme l'interface utilisateur web, la CLI, les événements Argo et les systèmes CI/CD. Le serveur API est responsable des éléments suivants :
- gestion des applications et rapports d'états ;
- appel d'opérations d'applications (par exemple, synchronisation, restauration, actions définies par l'utilisateur), gestion des informations d'identification du référentiel et du cluster (stockées sous forme de secrets Kubernetes) ;
- authentification et délégation d'authentification aux fournisseurs d'identité externes ;
- application des politiques RBAC.
- le Repository server : le serveur de référentiel est un service interne qui maintient un cache local du référentiel Git contenant les manifestes d'application. Ce service est appelé par d'autres services pour obtenir les manifestes Kubernetes. Il est chargé de générer et de renvoyer les manifestes Kubernetes à d'autres services lorsque les entrées suivantes sont définies :
- URL du référentiel ;
- révision (commit, tag, branche) ;
- chemin vers d'application ;
- paramètres spécifiques aux templates : parameters, environnements ksonnet, helm values.yaml ;
- application controller : le contrôleur d'application observe en permanence l'état en live de l'application et effectue une comparaison avec l'état souhaité dans le référentiel Git. Chaque fois qu'il y a une dérive et qu'ils ne sont pas synchronisés, il essaiera de les réparer et de les faire correspondre à l'état souhaité. Une dernière de ses responsabilités est d'exécuter tous les hooks définis par l'utilisateur pour les événements du cycle de vie de l'application.
La figure 8 résume les différents composants d’Argo CD.
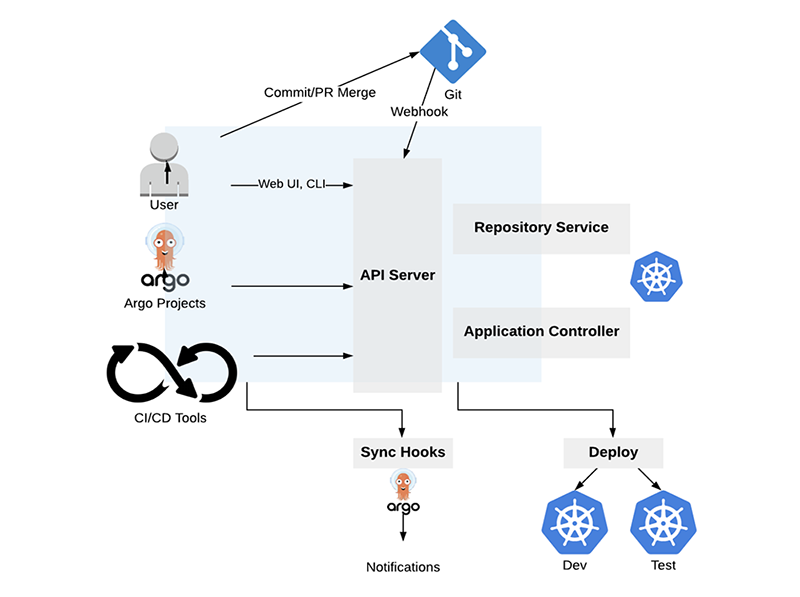
7.1 Création du projet dans Argo CD
Pour qu’Argo CD réalise la livraison continue de notre application dans Kubernetes, il a besoin d’une ressource permettant de référencer le dépôt Git de notre projet. Argo CD dispose d’une ressource personnalisée CRD (Custom Resource Record) nommée Application, c’est dans cette ressource que nous allons définir notre application qui fait référence au repository git et au cluster Kubernetes.
La création de cette ressource est réalisable soit en ligne de commandes, soit via l’IHM Argo CD.
7.1.1 Création d’application en ligne de commandes
Il faut tout d’abord installer la ligne de commandes Argo CD :
Puis, s’authentifier auprès d’Argo CD. Pour créer l’application, il faut se connecter à Argo CD en CLI :
Création de l’application :
L’application est apparue dans le tableau de bord d’Argo CD (Figure 9).
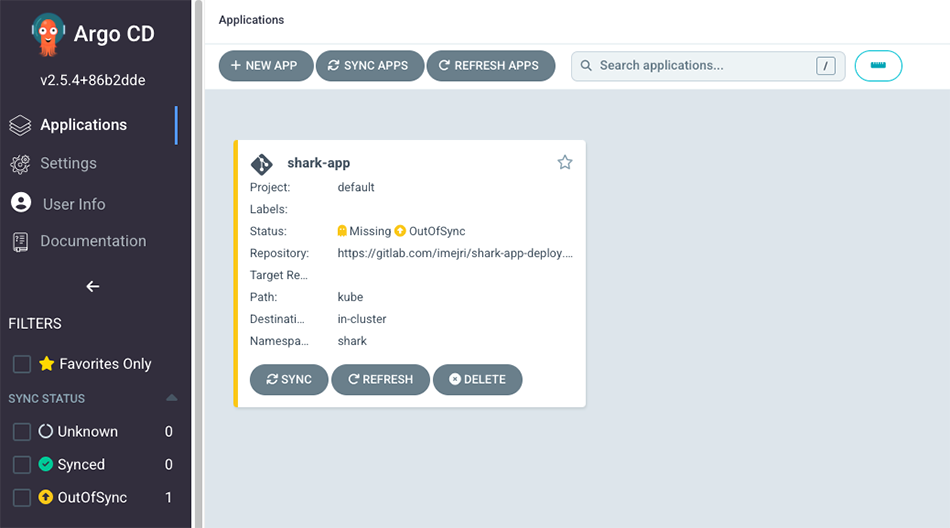
7.1.2 Création d’application par le tableau de bord
Une fois authentifié à Argo CD via l’IHM, cliquez sur l’onglet New app.
Remplir les champs nécessaires à la création de la ressource application (Figures 10 et 11) et à la fin, cliquez sur le bouton Create.
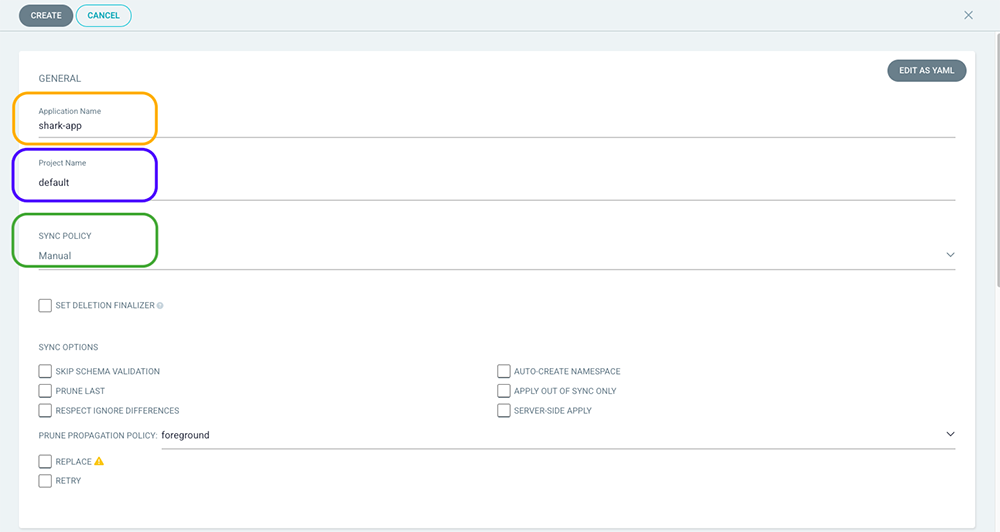
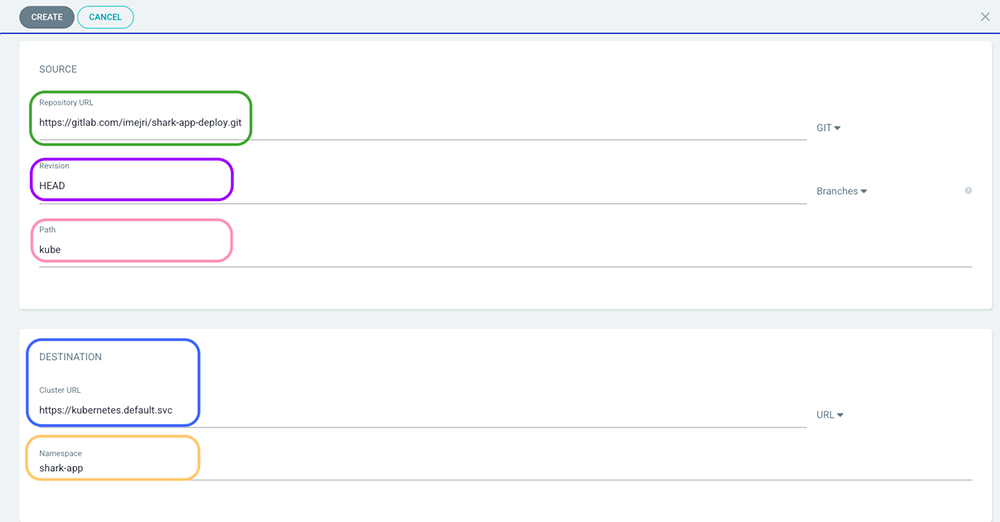
Bien sûr, le résultat final est le même que celui en ligne de commandes.
7.2 Synchronisation et mise place du GitOps
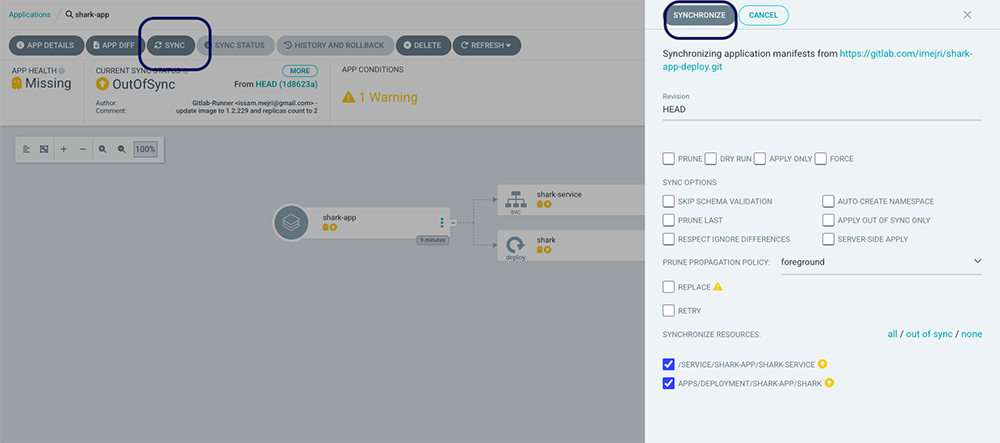
Maintenant qu’Argo CD réalisera le suivi des changements dans Git pour rapatrier les éventuelles modifications au niveau du cluster Kubernetes (c’est le principe même du GitOps), il est temps de lancer la synchronisation. Il faut savoir que lors de la création de notre application nous avons laissé le type de synchronisation à « manuel ». Cliquons sur l’onglet Sync en haut à gauche de la fenêtre (Figure 12), sur la fenêtre qui s’affiche, cliquez sur Synchronize.
C’est magique ! La synchronisation a créé les ressources Kubernetes comme prévu (mon service et mon déploiement qui définit deux réplicas de mon application et donc deux Pods) (Figure 13).
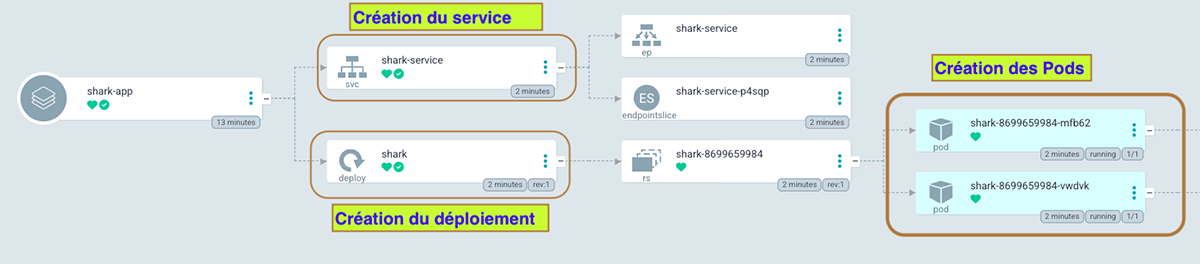
Vérifions la création de ces ressources dans Kubernetes :
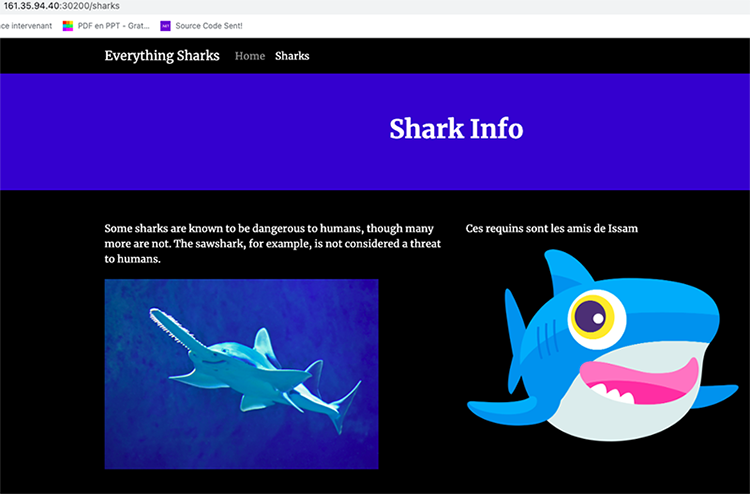
En se connectant avec l’une des IP des nœuds du cluster (en production, il est recommandé de créer un service de type LoadBalancer ou de passer par un Ingress Controler) et en spécifiant le port 30200 (c’est le port exposé par le service), on pourra accéder à notre application et rencontrer notre requin (Figure 14) !
8. Exécution du workflow complet
Le workflow complet se présente comme suit.
Un commit au sein du code source génère le lancement du pipeline CI/CD dans GitLab. Le pipeline exécute les jobs qui sont présents dans le fichier gitlab-ci.yaml comme indiqué dans le paragraphe 6. Le job Build-and-push-image-to-Quay permet de créer la nouvelle version d’image et de la pousser dans le registry Quay (Figure 15).
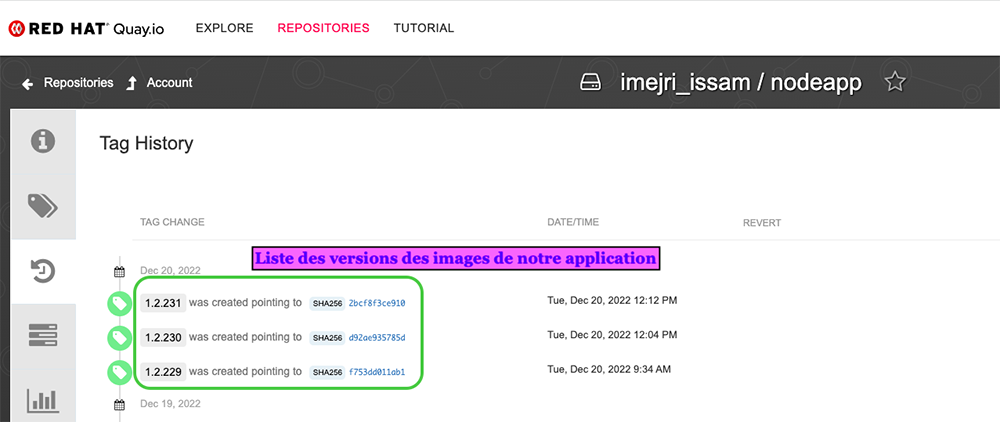
À la suite de ce job, on réalise les tests datree et on exécute les mises à jour des manifestes yaml dans le dépôt référencé dans Argo CD. À partir de ce moment, Argo CD détectera les nouvelles modifications et synchronisera l’état du dépôt git avec l’état des ressources dans le cluster Kubernetes.
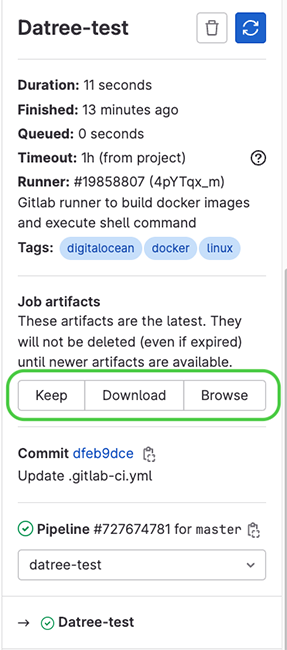
Sans oublier que le job de test datree génère un artifact contenant le rapport de test, il est téléchargeable en cliquant sur le nom du job dans le pipeline, puis dans le volet droit on choisit soit Download, soit Browse pour accéder au rapport de test (Figure 16).
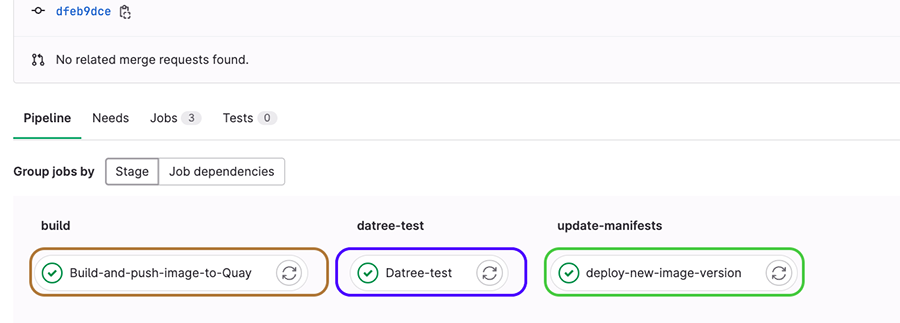
Les différents jobs dans le pipeline de GitLab sont représentés en Figure 17.
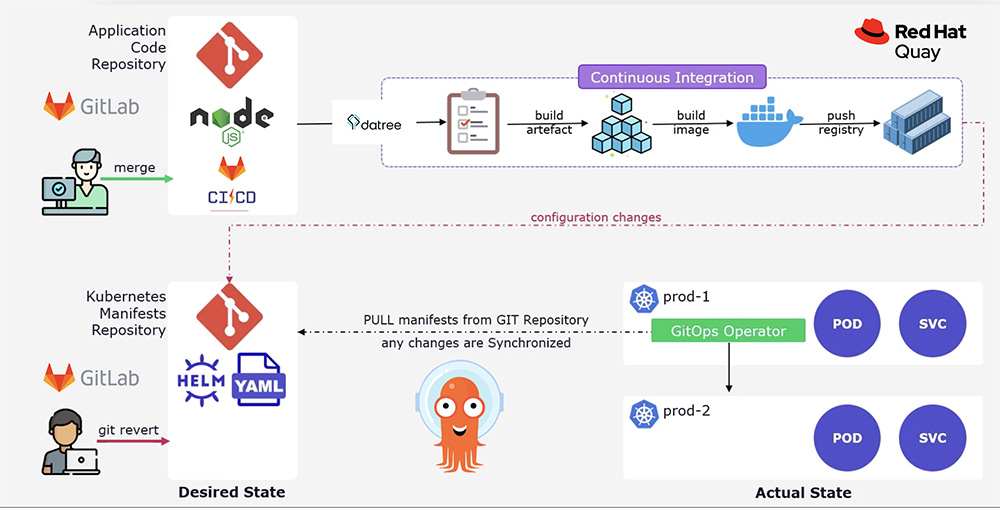
On finalise l’article avec une illustration d’un workflow complet en Figure 18.
Conclusion
Implémenter des outils de tests et des outils de livraison continue dans le cadre d’un projet assure la fiabilité dans le cycle de développement logiciel et permet de bénéficier d’une accélération lors des étapes de déploiement en production. Des outils comme Argo CD ou datree, qui ont été détaillés dans cet article ont leur valeur ajoutée lorsqu’on peut les intégrer dans des pipelines de CI/CD et standardiser leur utilisation sur différents projets.
Références
- Installation Argo CD : https://argo-cd.readthedocs.io/en/stable/getting_started/#2-download-argo-cd-cli
- Ligne de commandes Argo CD : https://argo-cd.readthedocs.io/en/stable/cli_installation/
- GitLab-CI : https://docs.gitlab.com/ee/ci/yaml#stages
- Datree : https://hub.datree.io/



