

Vous connaissez probablement déjà les outils classiques installés sur toutes les distributions GNU/Linux, et Python, langage populaire aujourd’hui. Découvrez Awk, un (vieux) langage qui pourrait vous servir lorsque les premiers sont trop limités et qu’un script Python vous semble surdimensionné.
Un script shell permet de réaliser des traitements basiques sur des lignes de texte grâce à un ensemble d'outils Unix (cut, grep, sort, wc, tr...). Cependant, lorsque les traitements deviennent plus complexes, un script shell avoue ses limites : faire des calculs est laborieux, le code est généralement peu structuré, etc. Dans ce cas, un script dans un langage plus évolué (comme Python) sera plus adapté. Cet article présente une solution intermédiaire : Awk, un langage créé par Alfred Aho, Peter Weinberger et Brian Kernighan. La version initiale date de 1977, révisée dans les années 80. Bien que toujours disponible, son heure de gloire semble passée. Il est spécialisé dans le traitement de lignes et leur transformation, ce qui le rapproche du comportement des enchaînements de filtres dans un terminal.
L'article présente Awk, en le comparant aux outils Unix classiques et à du code Python.
1. Disponibilité
En général, plusieurs interpréteurs Awk sont disponibles dans une distribution GNU/Linux (souvent gawk et mawk) et il est bien possible qu'il soit déjà installé. Tapez juste awk dans un terminal pour vérifier.
Par exemple, si mawk est installé, le début de la sortie sera :
Dans le cas contraire, vous pouvez en installer un depuis les paquets de votre distribution. Ils sont nommés mawk ou gawk sous Debian et Arch Linux (mawk est dans les dépôts AUR). D'autres interpréteurs plus récents existent (nawk, goawk).
2. Utilisation
Awk a été conçu pour l'écriture de one-liners, mais il est aussi possible d'écrire un programme Awk pour l'exécuter.
L'usage en tant que one-liner est :
L'usage avec un programme Awk écrit dans un fichier est :
Dans le cas où le programme est écrit sur la ligne de commande, il faut l'entourer de guillemets simples, car le programme va utiliser le caractère dollar (par exemple, la variable $0). Si ce sont des guillemets doubles qui sont utilisés, le programme ne fonctionnera pas correctement, car le shell va tenter d'interpréter les variables préfixées par le dollar comme des variables du shell avant d'exécuter le programme.
Ceci est un comportement classique du shell et n’est donc pas une spécificité liée à Awk.
Pour la suite de l’article, nous allons utiliser un fichier nommé distribs.txt contenant les données suivantes :
2.1 Imiter cat
Par exemple, pour faire l'équivalent de cat distribs.txt :
Comme le montre la figure 1, $0 représente l'enregistrement total (qu'on peut assimiler ici à la ligne). $1, le contenu du premier champ, $2 le contenu du deuxième champ, etc. Le contenu du dernier champ est $NF. NF signifie Number of Fields. On peut donc obtenir astucieusement le contenu de l'avant-dernier champ avec $(NF-1).
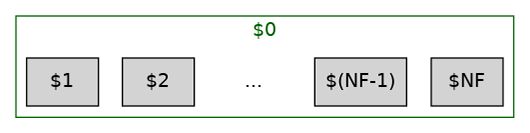
La plupart des langages de programmation démarrent les listes à partir de 0 (comme C, Java, Lisp, etc.) ; Python fait aussi partie de cette catégorie. Quelques langages, comme Awk, commencent à partir de 1. $0 représentant l'enregistrement complet, le premier élément ne peut pas lui aussi commencer à 0. Parmi les autres langages commençant aussi à 1, R ou Lua sont probablement les plus connus. Julia permet de choisir n'importe quel entier, mais utilise 1 comme index par défaut.
2.2 Imiter cut
Afficher le premier et le troisième champ avec cut avec les paramètres longs :
Avec les paramètres courts :
Avec Awk :
Alors que cut ne fait que filtrer des champs en gardant le même ordre, Awk permet de changer facilement l'ordre des champs ou d'insérer du texte dans la ligne qui sera affichée :
cut permet de choisir le délimiteur de champ. Par défaut, Awk considère les espaces blancs comme délimiteur. Les plus courants sont l'espace et la tabulation. Il est possible de changer la valeur par défaut avec la valeur FS (pour Field Separator). Le paramétrage de FS se fait dans un bloc BEGIN qui sera exécuté avant les traitements et donc pris en compte pour chacun d’eux. C'est pratique lors de traitement de CSV (ayant la virgule pour séparateur) ou le fichier /etc/passwd (ayant le caractère « : » pour séparateur).
Ainsi :
est équivalent à :
En python, csv.reader() permet d'avoir un résultat équivalent avec le code suivant :
2.3 Imiter wc -l
La commande wc -l permet d’afficher le nombre de lignes d’un fichier (ou de l’entrée standard). Comparons avec une version minimale écrite en Awk :
Mais quel est ce prodige ? Le bloc END est l’équivalent du bloc BEGIN : il permet de faire un traitement sur des informations que l'on aura qu'une fois le traitement terminé. Les blocs BEGIN et END sont toujours facultatifs. Une fois parcouru l’ensemble des lignes du fichier, le bloc END est exécuté. Il affiche la valeur NR (signifiant Number of Records). Par défaut, le séparateur d’enregistrement est le retour à la ligne. C’est pourquoi, dans la plupart des cas, un enregistrement est équivalent à une ligne.
Si on souhaite simuler exactement la sortie de wc, il faut utiliser la valeur FILENAME qui est initialisée automatiquement par Awk :
Un programme équivalent en Python serait :
2.4 Imiter head
Par défaut, head affiche les dix premières lignes d'un fichier.
Awk dispose de conditions, ce qui permet de réaliser un équivalent facilement :
À chaque ligne du fichier, si la condition ‘NR <= 10’ est vraie, alors la ligne sera affichée.
Une solution possible en Python serait :
Les tests en début de bloc (comme le NR <= 10 précédent) permettent de vérifier facilement des égalités (ou inégalités) sur des nombres, des chaînes de caractères, etc., avec Awk. La syntaxe est celle que l'on retrouve dans la plupart des langages. Il n'y a pas de surprises de ce côté-là.
2.5 Imiter grep
La commande grep affiche les lignes correspondant à un motif passé en paramètre. Awk est conçu pour filtrer les enregistrements avec des conditions et exécuter les blocs de traitement lorsque la condition est remplie, donc réaliser un équivalent à grep est facile. La condition peut être une chaîne exacte :
Avec la commande précédente, trois lignes seront affichées : celles qui ont « linux » dans la deuxième colonne.
La condition peut aussi être une expression rationnelle. Dans ce cas, le motif à rechercher doit être encadré par le caractère /.
La syntaxe des expressions rationnelles Awk est celle qui est communément utilisée et qu’on retrouve en Perl, Python, etc. L’article ne peut s’attarder à expliquer les expressions rationnelles, car elles sont un sujet à part entière. Pour le besoin de l’article, on considérera uniquement le caractère $ qui signifie une fin de ligne.
Si on souhaite connaître tous les utilisateurs ayant Zsh comme shell par défaut, il faut afficher toutes les lignes du fichier /etc/password contenant zsh en fin de ligne : en effet, le shell utilisé est le dernier champ de ce fichier. grep utilise le paramètre -E pour activer les expressions rationnelles étendues, ce qui donne :
L’équivalent avec Awk peut être obtenu avec :
Un équivalent Python serait :
Awk permet aussi un filtrage sur des champs spécifiques alors que grep filtre sur la ligne entière. grep va donc nécessiter une expression rationnelle plus compliquée pour obtenir un comportement équivalent. Le filtrage de Awk sur un champ s’obtient en préfixant l'expression rationnelle du numéro du champ souhaité. Par exemple, afficher uniquement le premier et le deuxième champ uniquement si le premier champ termine par « linux » :
Dans ce cas, seule la ligne concernant « Archlinux » sera affichée puisque c’est la seule avec le motif linux contenu dans la première colonne. Contrairement à l'exemple précédent, le terme « linux » présent dans le deuxième champ n’est pas pris en compte.
Un équivalent Python serait :
2.6 Imiter grep --invert-match
L’option --invert-match (ou son équivalent court -v) permet d'afficher uniquement les lignes qui ne correspondent pas à l'expression rationnelle passée en paramètre. Le caractère ! permet de faire la même chose avec Awk.
Sur une ligne complète (donc seuls les systèmes BSD seront affichés) :
Uniquement sur le premier champ (donc toutes les lignes seront affichées sauf celle contenant « FreeBSD ») :
3. Transformer les données
3.1 Sur des chaînes
Il est possible de mettre en majuscule avec toupper() et en minuscule avec tolower().
C'est équivalent aux méthodes upper() et lower() disponibles en Python.
Il est possible de séparer des données à l'intérieur d'un champ avec split(), connaître la longueur d'un champ avec length(), trouver la première occurrence avec match(), etc.
3.2 Sur des nombres
Il est possible de faire des calculs sur des champs directement :
Cela affichera le premier champ et le résultat de la soustraction entre l’année actuelle et le troisième champ (c’est-à-dire l’âge de la première publication).
Awk embarque aussi des fonctions mathématiques comme int(), exp(), cos(), etc. Ce sont des fonctions équivalentes de celles présentes dans le module math de Python. Awk dispose aussi une fonction rand(). Son équivalent Python est random.random(), donc hors du module math, mais on ne va pas chipoter.
4. Boucle et condition
Nous avons vu précédemment comment Awk permet d’avoir une condition pour entrer dans un bloc. Il est aussi possible d’écrire des conditions à l’intérieur d’un bloc. Dans ce cas, la syntaxe de Awk est directement inspirée de celle du C. C’est aussi le cas pour les boucles for et while.
Exemple :
Elle utilise donc des accolades pour définir des blocs, comme les scripts shell et le C (contrairement à Python qui utilise l'indentation).
5. Formater la sortie
Il est possible de changer le séparateur de sortie avec la constante OFS (pour Output File Separator) :
Un formatage plus fin est réalisable grâce à la fonction printf(). Son usage est calqué sur la fonction éponyme en C. L'intérêt était probablement plus évident lorsque Awk servait à générer des rapports, mais je doute qu'il soit encore utilisé pour cela aujourd'hui. printf est aussi disponible comme commande shell, avec des capacités de formatage équivalentes en C ou Awk. L'équivalent en Python est print() (comme déjà vu dans les exemples précédents). Cependant, en Python, l'utilisation de f-strings est maintenant privilégiée au formatage façon C. Les f-strings ont l’avantage d’être bien plus lisibles.
6. Utilisation et limites du langage
Le mode de fonctionnement est très orienté filtre, comme un remplaçant puissant des outils Unix chaînés par des pipes. Chaque bloc de traitement peut avoir un filtre, chacun différent. On peut avoir une succession de traitements possibles et une ligne peut correspondre à plusieurs blocs (cf. figure 2).
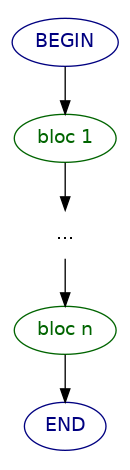
Vouloir l'utiliser différemment oblige à tordre l'outil. Par exemple, il n'est pas fait pour trier les lignes puisque Awk les traite une par une. Dans ce cas, repasser par des commandes shell peut être une meilleure stratégie (typiquement avec la commande sort).
Selon Brian Kernighan [1], l'idée était d'avoir un outil pour faire des appels simples :
« Our model was that an invocation would be one or two lines long, typed in and used immediately. [...] choices that made it possible to write one-liners. »
Cela a poussé à certains choix comme la conversion implicite de types. Assez logiquement, cela se passe aussi mal que dans d'autres langages avec un typage faible :
Cas | Opération | Résultat | Commentaire |
1 | "hello" 2 | hello2 | concaténation de chaîne de caractères |
2 | "1" + "2" | 3 | addition (uniquement sur les éléments pouvant être convertis en nombre) |
3 | "hello" + "1" + 2 | 3 | pas d'erreur |
Ce genre de comportement n'arrivera pas en Python, puisqu'il lèvera une exception en cas de tentative de concaténation de chaînes et de nombres :
Les variables d'environnement de localisation (LANG, LC_...) modifient aussi le comportement de Awk.
Ainsi, dans le cas de l'addition, la variable d'environnement LANG modifie l'interprétation des données. Par exemple, avec LANG=C, le séparateur pour les nombres à virgule est le point et non la virgule.
Cas | Variable d'env. | Opération | Résultat | Commentaire |
4 | LANG=C | "1.3" + 2 | 3.3 | avec séparateur "." |
5 | LANG=C | "1,3" + 2 | 3 | avec séparateur "," |
6 | LANG=fr_FR.utf-8 | "1,3" + 2 | 3,3 | avec séparateur "," |
Cette sensibilité aux variables d'environnement peut rendre le comportement d'un script non reproductible d'une machine à l'autre ou d'un utilisateur à l'autre.
Les conversions implicites de type sont un comportement général de Awk et se retrouvent donc aussi lors de comparaisons. Par exemple, toutes les conditions suivantes sont vraies, car converties en chaînes de caractères avant la comparaison :
Cas | Test | Commentaire |
7 | 1 == "1" |
|
8 | "10" < 2 | comparaison lexicographique entre "10" et "2" |
9 | "abc" > 1 | idem, "a" précède "1" |
En Python, le cas 7 serait évalué à « faux », car les types de données sont différents. Dans les cas 8 et 9, une exception serait levée en Python lors de l'exécution d'une comparaison de ce type :
Enfin, le découpage des champs fait par Awk peut être problématique : par exemple, si le séparateur est l'espace et qu'il existe aussi des espaces dans les données, alors le découpage sera erroné. Par défaut, entourer la donnée de guillemets ne résoudra pas le problème. Les contournements possibles sont peu fiables ou lisibles. En 2023, Brian Kernighan a décidé d'ajouter une gestion spécifique du format CSV. Des implémentations comme gawk ou goawk disposent d'un paramètre --csv pour avoir un comportement équivalent.
Sur ce point, l'utilisation du module csv de Python permet d'avoir un découpage correct automatiquement (comme montré dans l'exemple donné dans la section 2.2).
Conclusion
De mon point de vue, Awk n'est pas réellement un concurrent des outils Unix ou de Python, mais bien un outil complémentaire lorsque les utilitaires Unix ne répondent pas directement au besoin et que le code ne sera pas intégré dans un ensemble plus grand, auquel cas Python permettrait d'avoir un code plus maintenable dans le futur. Quelqu'un connaissant Perl ne ressentirait pas le besoin d'utiliser Awk, étant donné que Perl permet aussi de faire des one-liners facilement.
Référence
[1] Alfred Aho, Brian Kernighan, Peter Weinberger, The AWK Programming Language, page 181.