

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Nous proposons une méthode pour effectuer des requêtes SQL qui garantit l'invulnérabilité aux injections SQL, y compris lorsqu'elle est utilisée par un développeur pressé ou incompétent, contrairement aux requêtes paramétrées. Basée sur l'utilisation d'arbres de syntaxe abstraite, elle permet facilement de construire des requêtes dynamiques et est plus facile à mettre en œuvre qu'un ORM. Nous proposons une bibliothèque Java implémentant nos idées, mais la méthode peut s'appliquer à d'autres langages de programmation et d'autres types de requêtes.
La notion de vulnérabilité à des injections SQL est connue depuis plus de 20 ans [1]. La contre-mesure classiquement conseillée contre ce type de faille est également connue depuis longtemps : il suffit d'utiliser des requêtes paramétrées. Pourtant, les injections SQL sont toujours en tête des problèmes de sécurité applicative [2]. Pourquoi ?
Une réponse est le manque de formation des développeurs. Néanmoins, il nous semble que cette réponse mériterait réexamen. Considérons par exemple le code Java présenté dans le listing ci-dessous :
Bien que fictif, ce code est typique de ce que nous avons pu trouver lors d'audits : il est vulnérable à des injections SQL bien qu'il utilise des requêtes paramétrées.
Cela nous conduit aux critiques suivantes :
- L'utilisation de requêtes paramétrées permet d'écrire des requêtes non vulnérables, mais elle n'empêche pas d'écrire des requêtes vulnérables. Autrement dit, elle n'est pas, en soi, une garantie que le code est invulnérable aux injections SQL. C'est un problème réel pour les développeurs, mais aussi pour ceux qui auditent leur code, puisqu’il leur faut examiner toutes les requêtes pour s'assurer de l’absence de faille.
- Il est difficile de construire des requêtes paramétrées de façon dynamique. Par exemple, il peut être intéressant de calculer d'une part une requête et d'autre part un filtre à appliquer sur les résultats de cette requête et de vouloir combiner le tout en une seule requête SQL. Dans le code ci-dessus, la distinction entre les méthodes buildStatement et computeCriterion est relativement artificielle puisque le code ne fait que quelques lignes, mais dans un code réel, celle-ci serait justifiée.
Peut-on proposer une méthode qui ne soit pas sujette aux mêmes critiques ? Nous affirmons que oui et proposons les contributions suivantes à cet égard :
- Nous remettons en question l'utilisation de chaînes de caractères pour construire des requêtes SQL et proposons d'utiliser plutôt des arbres. Nous montrons comment l'exemple ci-dessus peut être très naturellement récrit en utilisant une bibliothèque représentant des requêtes SQL comme des arbres.
- Nous décrivons ensuite l'implémentation de notre bibliothèque. Disponible sous licence libre [3], elle permet à un développeur d'écrire des requêtes de façon sécurisée, mais a aussi pour effet de l'empêcher d'écrire des requêtes vulnérables aux injections. Notre bibliothèque ne prend pour l'instant en compte qu'un petit sous-ensemble de SQL, mais sa toute petite taille (moins de 250 lignes, dont moins de 200 non-vides, si l’on excepte la classe contenant 914 mots réservés en SQL) permet de l'adapter facilement à différents contextes.
Le plan de cet article est le suivant : les sections 1 et 2 décrivent ces contributions, section 3 nous présentons les travaux connexes, enfin nous concluons section 4 en présentant quelques extensions possibles.
1. Des chaînes aux arbres
Le code du listing précédent construit une requête SQL à partir d'un entier y, et de tableaux de chaînes de caractères fields et values représentant les noms des champs sur lesquels portent les contraintes additionnelles de la requête et les valeurs respectives qu'ils doivent avoir.
La méthode computeCriterion retourne un critère de recherche à prendre en compte dans buildStatement. Or une requête préparée est constituée d'une part d'une chaîne de caractères où les marques {} désignent des paramètres, et d'autre part des valeurs qu'on veut affecter à ces paramètres.
Donc, si on veut garder la séparation entre le calcul du critère dans la méthode computeCriterion d’une part et l'application de ce critère dans la méthode buildStatement d’autre part, la méthode computeCriterion ne peut renvoyer une simple chaîne de caractères : il faut utiliser une structure de données plus riche. Laquelle choisir ?
Les requêtes préparées, en Java, se composent mal : rien ne semble permettre de représenter des morceaux de requêtes préparées et de les assembler pour obtenir une requête complète. On peut certes construire la chaîne de caractères par concaténation d'autres chaînes de caractères, mais c'est seulement une fois la chaîne de caractères globale construite qu'on peut fixer les valeurs des paramètres.
Or la génération de requête SQL est un cas particulier de génération de code, qui est une phase standard de la compilation, et un compilateur représente le code qu’il génère par des arbres qui ne sont traduits en chaînes de caractères qu’en toute fin de traitement. C'est donc la structure de données que nous utilisons dans la bibliothèque que nous avons développée [3].
Du point de vue utilisateur, cette bibliothèque consiste en deux classes, AST et SQLDSL :
- La classe AST permet de représenter des arbres de syntaxe abstraite (Abstract Syntax Tree) de requêtes SQL. Elle est opaque pour l'utilisateur : elle n'a aucun constructeur public et une unique méthode publique, execute(Connection con) permettant d'exécuter la requête correspondant à un arbre de syntaxe abstraite.
- Les méthodes publiques de la classe SQLDSL sont statiques et permettent de construire des objets de la classe AST. En ce sens, cette classe propose un langage dédié (Domain Specific Language), pour représenter les arbres de syntaxe en notation préfixe.
Considérons par exemple cette requête SQL :
Avec notre bibliothèque, elle peut être codée ainsi :
L'arbre ainsi construit est représenté en figure 1. On pourra noter que chaque nœud possède un label et zéro, un ou plusieurs fils. Les chaînes de caractères littérales sont figurées par des losanges pour les distinguer des identifiants. Enfin, nous distinguons avec des bords arrondis les nœuds correspondants à des opérateurs infixes (ici la conjonction et l'égalité).
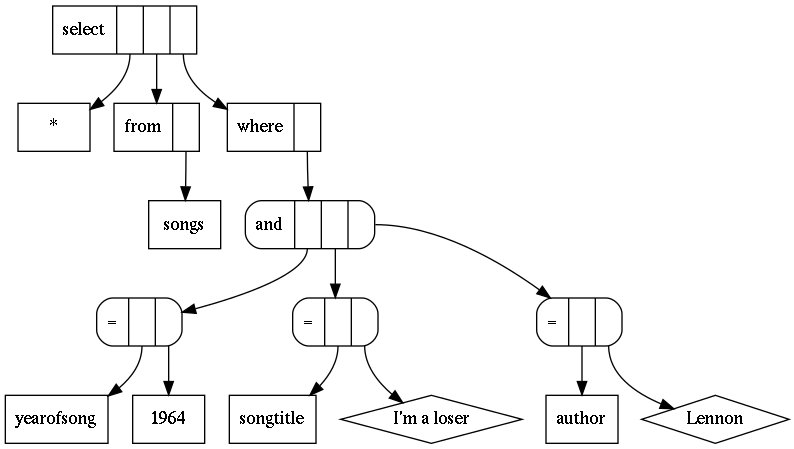
Nous présentons dans le listing ci-dessous notre exemple initial réécrit à l'aide de cette bibliothèque. Ce code est légèrement plus court que celui du premier listing. Il n'est pas vulnérable aux injections, car notre bibliothèque traduit correctement l'arbre donné. En outre, computeCriterion traite correctement le cas où les tableaux passés en argument sont vides.
2. Implémentation
2.1 Organisation
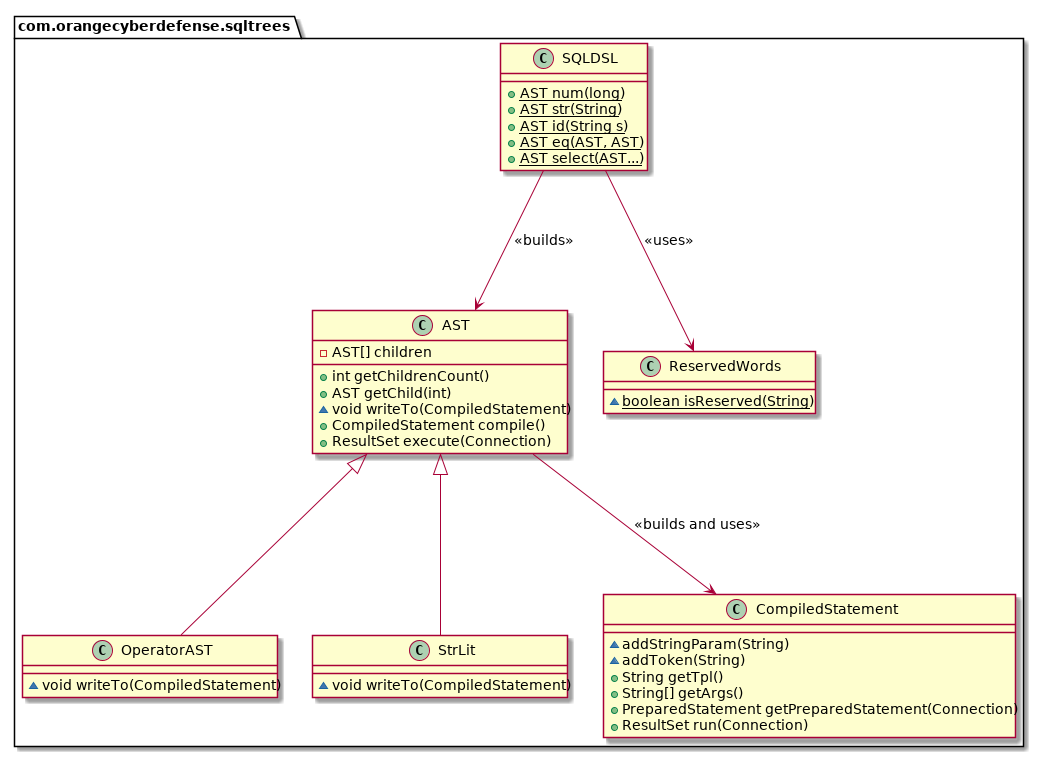
Le diagramme de classe en figure 2 montre l'organisation de notre implémentation, délibérément minimaliste. Pour simplifier, nous n'avons pas présenté toutes les méthodes, mais toutes les classes sont bien là : il n'y en a que six. La classe AST est la classe centrale. Elle permet de représenter l'arbre de syntaxe abstraite d'une requête et de l'exécuter, grâce à son unique méthode publique execute. Les méthodes statiques de SQLDSL sont les seuls points d'entrée de notre bibliothèque, aucune classe n'ayant en effet de constructeur public (la visibilité des constructeurs est restreinte au paquetage).
Pour vérifier qu’un identificateur est valide, il est facile de filtrer par liste blanche pour n’accepter qu’un jeu de caractères bien précis, mais il faut aussi interdire les mots réservés de SQL… et de ses dialectes ! C’est le rôle de la classe ReservedWords qui contient une liste noire de plus de 900 mots réservés. Le filtrage par liste noire est insatisfaisant en matière de sécurité, mais il semble difficile de procéder autrement ici.
On peut considérer que notre implémentation suit le patron de conception Interpréteur. Comme le remarque [4], ce patron est en effet applicable aussi pour écrire un compilateur. La classe CompiledStatement joue ici le rôle de la classe appelée contexte et la méthode writeTo joue le rôle de la méthode d'interprétation.
L'exécution d'une requête représentée par un AST est effectuée par la méthode execute donnée dans le listing ci-dessous, et dont l'exécution est détaillée dans le diagramme de séquence figure 3.

2.2 Prévention des injections
Pour éviter d'avoir à réécrire la gestion de la connexion aux bases de données, nous avons utilisé le paquetage java.sql.
Pour que les requêtes que nous effectuons à travers cette bibliothèque soient insensibles à d'éventuelles tentatives d'injections, il est essentiel de traduire correctement les chaînes de caractères littérales.
Pour cela, nous aurions pu construire une requête sous forme de chaîne de caractères, que nous aurions exécutée avec la méthode executeQuery(String sql) d'un Statement retourné par la méthode Connection.createStatement.
Cependant, il faudrait échapper correctement toutes les chaînes de caractères littérales de la requête. Or la façon d'échapper les caractères dépend en partie de la base de données utilisée. Nous aurions pu utiliser les bibliothèques du projet ESAPI de l'OWASP [5], mais cela aurait requis une dépendance sur une bibliothèque non standard.
Nous avons donc préféré contourner la difficulté, en utilisant des requêtes préparées (PreparedStatement) plutôt que de simples requêtes. Nous générons donc une chaîne de caractères qui contient le texte de notre requête, à l'exception des chaînes de caractères littérales, que nous passons en argument de la requête paramétrée.
En termes d'implémentation, c'est la classe CompiledStatement, dont le code est présenté dans le listing ci-dessous, qui permet la construction de ces requêtes. Elle n'a que deux attributs : args, la liste des arguments à passer à la requête préparée, et tpl, le corps de la requête préparée. Elle offre deux méthodes pour ajouter des unités lexicales à la requête en cours de construction : addToken, destinée à l'ajout d'une unité lexicale usuelle et addStringParam, destinée à l'ajout d'une chaîne de caractères littérale.
Ces méthodes sont appelées par la méthode writeTo de la classe AST. Plus précisément, alors que la méthode writeTo de la classe AST n'ajoute que des unités lexicales usuelles, nous avons introduit une sous-classe StrLit pour représenter les chaînes de caractères littérales, dans laquelle nous redéfinissons la méthode writeTo pour ajouter les chaînes littérales.
2.3 Auditabilité
Nous souhaitons faciliter les audits de sécurité des applications en garantissant que les requêtes effectuées par notre bibliothèque sont invulnérables aux injections (sous réserve que la bibliothèque ne soit pas modifiée, c'est-à-dire que les classes constituant notre paquetage Java ne soient pas modifiées et qu'aucune autre classe ne soit ajoutée).
Comme on l'a vu, la compilation vers des requêtes préparées garantit qu'un usage « normal » de la bibliothèque ne conduira pas à des injections SQL. Il convient aussi de garantir que d'autres usages ne permettront pas d’injections non plus. Les usages pour lesquels nous nous sommes prémunis sont les suivants :
- création d'objets de notre bibliothèque de façon non prévue ;
- modification des objets après leur création ;
- création de classes héritant des classes de notre bibliothèque.
Pour cela, nous avons pris les mesures suivantes :
- Seules trois classes sont accessibles depuis l'extérieur de notre paquetage :
- la classe AST des arbres de syntaxe abstraite ;
- la classe SQLDSL qui fournit le langage dédié pour construire ces arbres ;
- la classe CompiledStatement qui peut être utile à des fins de mise au point (pour vérifier qu'une requête est bien compilée comme on le pensait).
- La classe SQLDSL est déclarée final pour éviter toute extension non prévue. Elle ne possède que des méthodes statiques, n'a aucun état (aucun attribut statique) et ne peut avoir aucune instance, son constructeur étant privé et n'étant nulle part appelé dans la classe.
- Nous n'avons pas pu déclarer final la classe AST, car nous voulions pouvoir en hériter dans le reste du paquetage. En revanche, son constructeur n'est pas public (sa visibilité est restreinte au paquetage), ce qui rend impossible l'écriture d'une classe héritant de celle-ci hors du paquetage.
- La classe AST et ses sous-classes possèdent pour seules méthodes publiques les méthodes getChildrenCount et getChild permettant d'obtenir les fils d'un arbre, ainsi que les méthodes compile et execute, la première compilant la requête représentée par l'arbre en un objet de classe CompiledStatement et la seconde faisant appel à la première avant d'exécuter la requête compilée.
- À l'exception de la classe CompiledStatement, les classes de notre bibliothèque s'instancient en des objets non modifiables : lorsque les attributs ne sont pas déclarés final, ils sont protected ou private et ne sont pas modifiés après l'initialisation.
- La classe CompiledStatement est déclarée final. Un objet de cette classe possède des méthodes permettant de modifier son état (pour ajouter de nouvelles unités lexicales), mais la visibilité de celles-ci est restreinte au paquetage.
Ainsi, il suffit de vérifier qu'une application passe par notre bibliothèque plutôt que par les classes Statement ou PreparedStatement Java classiques pour s'assurer de sa sécurité vis-à-vis des injections SQL. Si la bibliothèque est modifiée, il suffira d'auditer le code de celle-ci.
3. Travaux connexes
Les travaux liés à la question des injections sont nombreux. On peut classer essentiellement ces travaux en deux grandes catégories :
- ceux qui permettent de réduire l'écart entre le langage de programmation source et le langage de requêtes en facilitant l'écriture de requêtes ;
- ceux qui permettent de détecter des vulnérabilités.
3.1 Travaux facilitant l'écriture de requêtes
3.1.1 Échappement des caractères dangereux
Les fonctionnalités permettant de nettoyer les caractères dangereux d'une chaîne de caractères dont le contenu n'a pas été validé, comme celles proposées par l'Enterprise Security API de l'OWASP [5] sont efficaces, mais il faut penser à les utiliser sur chaque entrée pouvant être contrôlée par l'utilisateur. Un oubli n’est détecté ni à la compilation, ni à l'exécution et peut rendre l’application vulnérable. En conséquence, cette méthode est plutôt lourde et risquée. À la différence de la méthode que nous proposons, l’audit de code requiert alors de regarder toutes les requêtes dans l'ensemble du code.
Pour cette raison, PHP a proposé des mécanismes permettant l'échappement automatique des entrées utilisateurs (guillemets magiques). Mais cet échappement se faisait de façon indiscriminée pour toutes les entrées utilisateurs et de la même façon, quelle que soit la base de données. De plus, il dépendait du bon vouloir de l'administrateur du système sur lequel tournait l'application. Ce mécanisme a finalement posé plus de problèmes qu'il n'en résolvait, au point qu'il a été supprimé [6].
3.1.2 Extension de langages de programmation
SQLJ [7] et Embedded SQL [8] permettent d'écrire des requêtes SQL dans un langage généraliste. Un préprocesseur permet de vérifier les requêtes SQL et les traduit dans le langage considéré. Il est relativement naturel pour le développeur.
Cependant, même si les arguments peuvent être fournis dynamiquement, la structure des requêtes doit être connue à la compilation : notre exemple initial échappe typiquement à ce qu'il est possible de faire avec un tel outil.
En outre, sur le plan pratique, cette approche pose des problèmes d'intégration avec les outils existants : les éditeurs ne savent pas nécessairement traiter ce code Java étendu et les outils de compilation doivent prendre en compte cette phase de compilation supplémentaire.
3.1.3 ORM
Les systèmes de mapping objet-relationnel (ORM) permettent de générer et d'exécuter automatiquement des requêtes SQL. Des outils comme SQL DOM [9], Querydsl [10] ou jOOQ [11] offrent des garanties fortes en matière d'exécution, au sens du « well-typed programs cannot go wrong » de Milner [12] : si le code Java compile, alors les requêtes générées ne comportent pas d'erreur de syntaxe ni de typage. Par contraste, notre bibliothèque n'offre aucune de ces deux garanties : tout ce que nous garantissons est que, si l'arbre de syntaxe abstraite est correct, la requête générée est une représentation fidèle de cet arbre.
Ces outils permettent d'écrire des requêtes de façon plus dynamique que les outils de SQL embarqué, mais rendent assez lourde l'écriture de notre exemple initial, car il n'est pas possible de construire directement un critère à partir du nom d'un champ. Cette limitation peut être vue comme bénéfique, car elle impose d'associer un objet d'une classe différente à chaque nom de champ, ce qui constitue un mécanisme de validation par liste blanche du nom du champ. Malheureusement, certains ORM, pour faciliter l'écriture de requêtes plus dynamiques, permettent d'écrire directement des requêtes SQL sous forme de chaînes de caractères, ce qui les expose au risque d'injection. C'est notamment le cas d'Hibernate [13].
Cela dit, l'adoption d'un ORM pour réduire le risque de vulnérabilités SQL est souvent une bonne décision. Mais elle ne peut généralement être prise qu'en début d'un projet : en effet, mélanger des accès directs à la base de données et des accès via l'ORM n'est pas nécessairement prévu et en outre, il s'agit d'un investissement important en temps et en formation. Or, lorsqu'une équipe hérite d'un projet ancien mal documenté, il arrive parfois que les développeurs ne comprennent pas à quoi correspond le schéma de la base de données (voire même qu'ils n'y aient pas accès). Dans ce cas, basculer sur l'utilisation d'un ORM est très difficile. Par contraste, l'approche que nous proposons demande assez peu d'investissement (il suffit de comprendre le lien entre la syntaxe concrète de SQL et la syntaxe abstraite que nous proposons) et peut être mise en œuvre de façon graduelle dans un projet : il suffit de remplacer chaque construction de requête sous forme de chaînes de caractères par la construction d'un arbre.
3.2 Détection des injections
Les techniques d'analyse statique (notamment celles de type taint analysis) permettent, dans une certaine mesure, de détecter les injections potentielles à la compilation en étudiant le flux de données dans un code source. Cependant, il semble que la mise en place d'outils d'analyse statique soit difficile sur des projets existants, en raison du nombre de faux positifs qui vont être initialement levés et de l'expertise nécessaire pour comprendre et traiter correctement les alertes.
Un certain nombre de travaux [14, 15, 16] proposent de détecter dynamiquement les tentatives d'injection par des méthodes qui vont au-delà des vérifications de motifs des WAF classiques. Comme nous, les auteurs de ces travaux s'intéressent à la représentation des requêtes sous forme arborescente.
Par exemple, [15] et [16] proposent des constructions permettant au développeur d'insérer des marques délimitant les données entrées par l'utilisateur. Celles-ci permettent de construire deux arbres de syntaxe : d'une part un modèle de la requête que le développeur souhaitait construire et d'autre part celui de la requête effectivement construite. Si ces deux arbres ne coïncident pas, il y a tentative d'injection. Cette façon de faire permet de gérer des requêtes arbitrairement complexes et générées dynamiquement. Cependant, la sécurité de cette solution repose sur le fait que le développeur pense à bien mettre systématiquement les marques. En termes d'usage pratique (notamment pour les audits), on retrouve donc les mêmes problèmes qu’avec l’échappement manuel des entrées utilisateur.
Les travaux présentés dans [14] n'ont pas cette limitation : le développeur écrit sous forme d'arbre le texte qu'il souhaite construire, il n'y a donc rien à faire pour extraire l'arbre modèle du texte qui sera construit. De plus, les auteurs montrent que leur approche est correcte sur le plan sémantique. Sur le plan conceptuel, ces travaux sont proches des nôtres, même s'ils portent sur la prévention des failles XSS lors de la génération de code HTML plutôt que sur la prévention des injections SQL. Cependant, là où nous préconisons la mise en place d'un générateur de code qui respecte la structure de l'arbre en échappant les caractères dangereux ou en détectant les problèmes lors de la génération du texte de la requête SQL, les auteurs ont choisi une approche qui nous semble plus lourde à mettre en œuvre : ils génèrent complètement le code HTML sans chercher à gérer les caractères dangereux puis effectuent l'analyse syntaxique du résultat pour détecter une éventuelle tentative d'injection.
Conclusion
Le succès (relatif) des requêtes préparées pour lutter contre les injections SQL semble principalement dû au fait qu'il s'agit d'un mécanisme déjà présent dans les bases de données : en un sens, leur existence a dispensé de chercher à mieux comprendre l'origine du problème. Pourtant, elles ne sont pas adaptées à la construction de requêtes SQL dynamiques, ce qui conduit souvent les développeurs à écrire du code vulnérable.
Manipuler des arbres en Java ne présente pas de réelle difficulté et permet, à peu de frais, de construire des requêtes dynamiques non vulnérables aux injections. Nous conjecturons que si la manipulation de cette structure de données pour construire des requêtes ne semble pas avoir été considérée jusqu'ici, c'est en raison de son caractère non naturel dans les langages orientés objets (on peut y voir un argument en faveur de l'hypothèse de Sapir-Whorf).
En outre, les structures d'arbres se prêtent naturellement à des implémentations non modifiables, ce qui permet, en encapsulant correctement leur construction, de garantir des invariants sur ces structures. En programmation fonctionnelle, il est bien connu que cela aide à garantir des propriétés de sûreté de fonctionnement des programmes. Ici, cela permet de garantir des propriétés de sécurité : on peut garantir que le programmeur ne risquera pas de construire des requêtes vulnérables.
Nous aimerions prolonger ce travail dans les directions suivantes :
- Sur le plan théorique, il serait intéressant de comparer notre approche à celle de [16] : peut-on adapter la définition formelle d'injection SQL donnée par les auteurs à l'approche que nous proposons et montrer formellement que notre approche est sécurisée ?
- Donner aux développeurs des bibliothèques pour construire des arbres de syntaxe SQL peut évidemment se faire dans d'autres langages que Java. Néanmoins, il serait intéressant de voir si, dans des langages ayant des fonctionnalités d'encapsulation moins fortes, il reste possible d'empêcher les développeurs de construire des requêtes vulnérables.
- Il serait intéressant de fournir des bibliothèques pour résoudre les problèmes d'injections similaires : XSS, injections LDAP, injections de commandes, etc.
- Notre bibliothèque ne gère pour l'instant qu'un minuscule sous-ensemble de SQL. Il conviendrait de l'étoffer. Toute contribution est à cet égard bienvenue !
Références
[1] Rain Forest Puppy. « NT Web Technology Vulnerabilities ». In Phrack Magazine, 8.54, déc. 1998. http://phrack.org/issues/54/8.html
[2] Andrew van der Stock, Brian Glass, Neil Smithline, and Torsten Gigler. « OWASP top 10 - 2017 ». https://owasp.org/www-pdf-archive/OWASP_Top_10-2017_%28en%29.pdf.pdf
[3] Judicaël Courant. « sqltrees: A secure, developper-proof, Java library for querying SQL databases », 2020. https://github.com/Orange-Cyberdefense/sqltrees
[4] E. Gamma, R. Helm, R. Johnson, and J. Vlissides. « Design Patterns: Elements of Reusable Object-Oriented Software ». Addison-Wesley Professional Computing Series. Pearson Education, 1994.
ISBN : 978-0-201-63361-0
[5] Kevin Wall and Matt Seil. « The OWASP Enterprise Security API ».
https://owasp.org/www-project-enterprise-security-api/
[6] Sebastian Bergmann, Arne Blankerts, and Stefan Priebsch. « Why magic quotes are gone in php 7 ». Août 2017. https://thephp.cc/news/2017/08/why-magic-quotes-are-gone-in-php7
[7] « SQLJ », Wikipedia, The Free Encyclopedia. Mars 2020.
https://en.wikipedia.org/w/index.php?title=SQLJ&oldid=945238109
[8] « Embedded SQL », Wikipedia, The Free Encyclopedia. Mars 2020.
https://en.wikipedia.org/w/index.php?title=Embedded_SQL&oldid=948412805
[9] R. A. McClure and I. H. Kruger. « SQL DOM: compile time checking of dynamic SQL statements ». In : Proceedings. 27th International Conference on Software Engineering, 2005. ICSE 2005. p. 88-96.
[10] Querydsl. http://www.querydsl.com/
[11] jOOQ. https://www.jooq.org/
[12] Robin Milner. « A theory of type polymorphism in programming ». Journal of Computer and System Sciences, 17 (1978), p. 348-375.
[13] Hibernate project. https://hibernate.org/
[14] Zhengqin Luo, Tamara Rezk, and Manuel Serrano. « Automated code injection prevention for web applications ». In : Theory of Security and Applications - Joint Workshop, TOSCA 2011, Saarbrücken, Germany, March 31 - April 1, 2011, Revised Selected Papers.Sous la dir. De Sebastian Mödersheim et Catuscia Palamidessi. T. 6993. Lecture Notes in Computer Science. Springer, 2011, p. 186-204. https://doi.org/10.1007/978-3-642-27375-9_11
[15] Gregory T. Buehrer, Bruce W. Weide, and Paolo A. G. Sivilotti. « Using parse tree validation to prevent sql injection attacks ». In : Proceedings of the International Workshop on Software Engineering and Middleware (SEM) at Joint FSE and ESEC. 2005, p. 106-113.
[16] Zhendong Su and Gary Wassermann. « The essence of command injection attacks in web applications ». In : Proceedings of the 33rd ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2006. Sous la dir. de J. Gregory Morrisett et Simon L. Peyton Jones. ACM, 2006. https://doi.org/10.1145/1111037.1111070