

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Patrick McHardy est le chef du projet Netfilter depuis 2007. Il a eu la gentillesse de répondre à une interview par mail où il présente son travail et ses motivations.
Pouvez-vous vous présenter et nous dire comment vous avez découvert Linux et Netfilter ?

Patrick McHardy : J'ai 29 ans et je vis actuellement dans la jolie ville de Freiburg en Allemagne. Contrairement à ce que beaucoup de personnes pensent en regardant mon nom, je ne suis ni anglais, ni américain, mais je suis né à Frankfort et ma langue natale est l'allemand. J'ai étudié l'informatique à Freiburg, mais cela m'a vite ennuyé et j'ai arrêté mes études après quelques semestres.
Je gagne ma vie en tant que freelance sur des projets de consulting et de développement sur le noyau Linux. J'essaie cependant de passer le plus de temps possible sur des projets Linux pour lesquels j'ai un intérêt personnel. Astaro sponsorise mon travail depuis janvier 2006, ce qui me permet de passer beaucoup de temps sur Netfilter. Pendant mon temps libre, j'essaie de conserver une vie sociale en fréquentant des personnes au moins partiellement non geek, en prenant plaisir à traîner dans des bars sombres, en cuisinant un peu (Je suis un grand fan de la cuisine française) et en assistant aux cours de droit de l'université de Freiburg.
J'ai découvert Linux en 1996 ou 1997. Si l'on omet d'autres architectures moins connues ou plus obscures, j'avais principalement été un utilisateur d'Amiga jusque-là, mais il est devenu de plus en plus évident que cette architecture était désespérément en perte de vitesse. J'ai donc décidé de prendre un ordinateur x86. Utiliser windows était hors de question, la petite expérience que j'en avais m'avait suffit pour comprendre qu'il serait inutilisable pour moi en tant que développeur. En cherchant des alternatives, j'ai découvert Red Hat Linux, qui me paraissait bien plus attirant, spécialement du fait qu'il était livré avec le code source complet du noyau. À cette époque, tous les systèmes que j'avais utilisés étaient propriétaires et je n'avais donc jamais eu la chance de regarder le code d'un système d'exploitation. Comme j'avais joué avec des coupleurs acoustiques et des modems depuis l'âge de dix ans, j'étais intéressé depuis longtemps par découvrir comment une couche réseau fonctionnait vraiment et j'ai donc commandé une copie de RH Linux. L'installation était ardue et le gestionnaire de fenêtres était incroyablement laid, mais, une fois que tout fut paramétré et fonctionnel, la première chose que j'ai faite fut de regarder le code du noyau. Ça m'a vraiment dépassé de loin à l'époque. Je pense que c'était au-delà de mes capacités à ce moment. Je me concentrais donc sur les moyens d'améliorer le système, mais, pendant les années suivantes, je continuais de manière irrégulière à étudier le code quand j'en avais le temps.
Quand avez-vous décidé de participer à Netfilter ?
Patrick McHardy : J'ai écrit mon premier morceau de code conséquent lié à Netfilter aux alentours de 2000. Il s'agissait d'une implémentation de contrôle du débit TCP, une technique (malheureusement brevetée aux États-Unis) de contrôle du débit du trafic entrant par régulation du débit des TCP ACK et de la taille de fenêtre TCP.
NDLR
L'idée est de cet algorithme est de travailler sur deux paramètres qui influent sur la bande passante d'une connexion. Le premier est l'envoi des ACK qui accusent la réception des données. Si l'émetteur reçoit les ACK moins vite, il aura tendance à réduire son débit d'émission. Le deuxième paramètre est la taille de fenêtre TCP qui définit le volume de données que l'émetteur peut envoyer sans avoir reçu d'accusé de réception. L'action sur ses deux facteurs permet un contrôle du débit des données de l'émetteur, puisque l'on contrôle deux des facteurs de régulation du débit.
L'implémentation était une discipline TC, mais elle utilisait le suivi de connexions Netfilter pour maintenir un état par connexion et le patch (intégré plus tard dans l'arborescence officielle) de suivi de la taille de fenêtres TCP pour valider les flux de contrôle TCP, la détection des retransmissions, etc. À cause du problème de brevet, il était clair que je ne pourrais pas faire intégrer le code dans le noyau officiel. J'ai donc demandé au propriétaire du brevet sa permission de l'utiliser, mais, sans surprise, il a décliné ma proposition et j'ai abandonné le projet.
Mes premières contributions actives remonte à 2002 ou 2003. J'avais un travail d’étudiant comme développeur chez Pyramid Computer, une société de Freiburg qui, à cette époque, produisait des appliances basées sur Linux. Je développais là-bas le composant pare-feu de leur nouvelle appliance. Il utilisait une bonne partie des fonctionnalités les plus avancées de routage et de filtrage de Linux et j'ai trouvé pas mal de bogues, fonctionnalités manquantes ou incohérences. J'ai donc commencé à les corriger et à envoyer les patches. Pendant l'ère de Linux 2.4, les choses évoluaient très lentement et même les corrections de bogues atterrissaient souvent dans le patch-o-matic pendant des mois.
NDLR
Le patch-o-matic était un ensemble de patches et de fonctionnalités ajoutés à Netfilter (donc au noyau) ou iptables qui n'était pas disponible dans le noyau officiel mais qui était distribué par le projet Netfilter.
Mais l'impression que mes contributions étaient appréciées, le fait que l'on pouvait poser des questions et avoir des réponses des auteurs et en particulier l'arrivée plus ou moins rapide de mon travail dans le noyau officiel me motivaient fortement. En devenant plus familier avec le code, je découvrais des bogues, des incohérences et des choses qui méritaient d'être corrigées. Porté par tout cela, je continuais le travail.
Quelle question vous énerve-t-elle le plus sur une liste de diffusion ?
Patrick McHardy : Je suis persuadé d'être une personne au caractère tempérée (ndlr : je confirme) et je ne m'énerve pas facilement. Je n'aime pas quand les gens font trop de bruit sur une liste de diffusion, mais c'est tout. On apprend à ignorer ces choses-là rapidement. Cependant, j'aime toujours observer une bonne joute par emails et anticiper sur son apparition :)
Quel est le meilleur retour que vous ayez eu jusqu'ici ?
Patrick McHardy : Parfois, des utilisateurs envoient des courriels pour exprimer leur gratitude pour notre travail ce qui est à mon avis un geste sympathique. Le meilleur... je pense que c'est quand un type dans un club est venu vers moi, m'a demandé si mon nom était Patrick McHardy (ce qui a dû me perdre, c'est que je portais un T-shirt de Nerd) et a commencé à m'offrir des verres :)
En ce qui concerne les retours des développeurs, il y en a malheureusement peu ; la plupart de mes patches sont mergés à leur première soumission sans beaucoup de retour. Il est toujours difficile de juger si c'est parce que personne ne les a regardés en détail ou si c'est parce qu'ils étaient simplement parfaits. Pour moi, le meilleur retour non technique de la part de développeurs est quand quelqu'un reconnaît la beauté derrière quelque chose de particulièrement intelligent ou élégant dans le code (ndlr : cela s'est notamment produit à l'issue de la présentation de nftables lors du workshop 2008 à Paris).
Comment considérez-vous vos responsabilités en tant que leader du projet Netfilter ?
Patrick McHardy : Il ne s'agit pas réellement d'un ensemble bien défini de responsabilités, il s'agit plutôt de s'occuper des choses que personne d'autre ne fait et bien sûr de relire et intégrer des patches. Théoriquement, je suis aussi supposé prendre la décision finale si la coreteam n'arrive pas à se décider sur quelque chose, mais je ne me rappelle pas que cela soit déjà arrivé.
En ce qui concerne les tâches individuelles, être responsable en dernier lieu de l'évaluation et de l'incorporation des patches est positif sur de nombreux aspects. Le plus important est que c'est probablement le levier qui me permet de pouvoir orienter au moins partiellement les développements dans la direction qui me semble la bonne. Cela me force aussi à identifier les erreurs au plus tôt au lieu d'avoir à les corriger une fois qu'elles ont atteint le noyau officiel. Il y a beaucoup plus de travail dans ce cas puisqu'il faut gérer les problèmes de compatibilité, le backport des corrections, etc. Je pense que j'ai fait un bon travail d'amélioration de la qualité du code. D'un autre côté, cela fait de moi un point d'échec central (SPOF), ce qui peut être frustrant et créer du travail supplémentaire pour les contributeurs quand je n'ai pas le temps d'évaluer et d'incorporer leurs patches. J'essaie donc d'alléger la dépendance, mais il n'y a pas de moyens de faire ça simplement, et cela est aggravé par le fait que je sois le seul membre de la coreteam à être actuellement payé pour travailler sur Netfilter.
Une autre facette d'être le point d'entrée du flux de patches est que les plaintes qui descendent en sens inverse atterrissent d'abord dans votre boite mail. Le type de plainte le plus urgent est celui où l'ordinateur de l'utilisateur ne boote pas après que vous avez une fois encore cassé quelque chose :)
La publication de nouvelles versions des outils en espace utilisateur est une des tâches que je n'aime pas beaucoup, principalement parce que c'est répétitif et que le mise à jour du site web est pénible.
Ensuite, viennent les corrections de bogues et les réponses aux rapports de bogues. J'aime réellement fixer des bogues, mais les rapports de bogues peuvent être vraiment désorganisants : il faut répondre rapidement, sinon on court le risque que le rapporteur du bogue disparaisse, ou que l'on réagisse lentement sur un bogue sérieux.
Malheureusement, peu de gens, y compris parmi les développeurs les plus actifs, participent aux rapports de bogues. En particulier les rapports de bogues reçus depuis le bugzilla de kernel.org sont pratiquement tous exclusivement traités par moi-même. Là encore, je suis le point de passage obligé, mais c'est un peu plus un problème pour les utilisateurs que pour les développeurs.
Et enfin, il y a l'organisation de la conférence des développeurs, à laquelle j'ai participé (pour ce qui est la partie non locale) ces deux dernières années. Cela prend toujours beaucoup de temps et la collecte de l'argent des sponsors m'expose personnellement à certains risques légaux et financiers. Le concept global de sponsoring semble troubler les conseillers fiscaux et j'en ai rencontré un seul capable de me donner des conseils légaux sur comment gérer cela proprement. Cela fait donc partie des activités que j'apprécie le moins.
De combien de temps disposez-vous pour implémenter vos propres idées ?
Patrick McHardy : Je dispose de beaucoup de temps pour travailler sur Netfilter et sur le noyau. Le temps que je peux allouer à mes propres idées dépend de facteurs externes, comme ce que les autres développeurs font et combien de temps est utilisé pour analyser et incorporer les patches, participer aux discussions, gérer les rapports de bogues, etc. Comme je suis aussi actif dans d'autres parties du noyau, il serait facile d'utiliser tout mon temps sur des revues de patches et des discussions, mais cela ne passe pas à l'échelle, donc parfois il faut juste laisser passer les choses et faire confiance aux autres personnes qui feront les bons choix.
Un problème sérieux est que même, quand il est possible d'avoir du temps, la communication avec les autres développeurs qui se fait exclusivement par e-mail peut être désorganisatrice pour le travail en cours, car l'activité est toujours multitâche ; à un certain moment le coût du changement de contexte devient tel qu'il n'est plus possible d'effectuer un travail réel. La seule manière pour moi de travailler efficacement sur des gros projets est d'ignorer complètement les e-mails pendant quelque temps.
Vous travaillez actuellement sur Nftables. Quel est le but de ce projet ?
Patrick McHardy : Le but premier est de créer un successeur pour iptables, ip6tables, arptables et ebtables. Cela sera, je pense, la quatrième génération de pare-feu pour Linux. Il y a bien sûr un sérieux syndrome du second système. Il essaye d'adresser de nombreux buts et souhaits.
Commençons par les deux buts premiers, qui expliquent aussi pourquoi j'ai commencé une nouvelle implémentation depuis le début au lieu d'améliorer l'existant.
1) Une interface utilisateur moderne, basée sur Netlink et travaillant de manière incrémentale
L'interface d'iptables souffre d'un certain nombre de sérieux problèmes de conception qui ne peuvent être corrigés sans briser la compatibilité binaire (ABI). Le premier problème majeur est que le jeu de règles est représenté par un énorme blob qui ne peut être remplacé qu'atomiquement, ce qui entraîne une complexité quadratique pour les changements de jeu règles incrémentaux et, si les développeurs n'y prennent garde, cela peut entraîner la perte par le noyau de l'état interne des règles lorsque des changements dissociés de règles dissociés sont effectués. Le second problème majeur est directement relié à cela. La représentation interne dans le noyau est exactement celle du blob qui est utilisé dans l'ABI de l'espace utilisateur. Cela réduit sérieusement le degré de liberté disponible pour améliorer l'implémentation interne du noyau, puisque tout changement sur les structures de données brisera la compatibilité applicative.
2) Un système de classification générique, indépendant d'une famille de protocoles spécifique :
Un autre choix malheureux dans l'ABI utilisateur a été d'embarquer des informations spécifiques au protocole comme des adresses IPv4 dans le cœur des structures de données. Cela a rendu impossible l'utilisation de la même ABI pour des protocoles différents comme IPv6, ARP ou le bridge et la réutilisation des parties du cœur du code de classification, si bien que les gens ont créé trois « ports » couper-coller (NDLR : IPv6, arp et bridge), quadruplant le coût de maintenance et de développement.
buts secondaires
Support des règles de synchronisation à état
Certains filtres maintiennent un état interne, l'exemple le plus évident est le filtre limit. Afin de supporter la synchronisation de jeux de règles à état entre des systèmes différents l'espace utilisateur doit être capable d'accéder à ces états. (NDLR : Par exemple pour la réplication d'état entre deux pare-feu actif/actif),
Cibles multiples par règle
Une plainte courante est que si l'on veut, par exemple, journaliser et accepter un paquet, il est nécessaire de dupliquer la règle ou créer une chaîne utilisateur dédiée, qui contient les deux actions. Nftables, ne fait plus la distinction entre filtre et cible et permet l'utilisation d'un nombre arbitraire des deux dans une simple règle.
Support natif des évaluations de jeux de règles (et des ensembles) non linéaires
L'évaluation linéaire des règles telle que faite par iptables est lente, les ensembles permettent une classification plus rapide et des expressions plus naturelles pour certains types de règles. Pour iptables, nous avons le module non officiel ipset de Jozsef Kadlecsik, qui rend possible l'utilisation d'ensembles pour certains types de données comme les adresses ou les numéros de ports. nftables pousse cela un pas plus loin et supporte des ensembles pour tous les types de données. Il supporte aussi les recherches par intervalles dans des ensembles et utilise des ensembles comme des dictionnaires qui permettent de représenter des algorithmes de classification plus intéressants.
Cibles paramétrables dynamiquement
Les ensembles sont utiles dans le cas où il y a de nombreux filtres similaires, mais quand le paramètre de la cible change, il est tout de même nécessaire d'avoir des règles séparées. Une cible paramétrable dynamiquement permet de déterminer ces paramètres au moment de l'exécution, par exemple en réalisant une recherche dans un dictionnaire. Il est ainsi possible d'exprimer quelque chose comme :
"marque les packets de l'adresse IP x1 avec la valeur m1, x2 avec la valeur m2, ..."
dans une règle unique. Cela offre aussi la possibilité d'exprimer des choses un peu plus folles comme
"DNAT la connexion vers l'adresse source du paquet"
Limitation du code dupliqué pour des tâches similaires
De nombreuses tâches peuvent être généralisées assez facilement, par exemple le filtre TCP, le filtre UDP, le filtre adresse IP, etc. Tous chargent des données depuis le contenu du paquet et les comparent à une constante. La seule différence est l'offset et la longueur des données. Par conséquent, nftables utilise un seul module « payload », l'espace utilisateur est responsable de la traduction des filtres spécifiés par l'utilisateur en des paramètres appropriés. La même chose s'applique à d'autres types de filtres.
Sémantique et intelligence en espace utilisateur
Les retours d'erreurs d'iptables sont plutôt pauvres parce que la plupart (sinon toutes) des vérifications sémantiques sont faites par le noyau à qui il manque un bon mécanisme de retours d'erreurs. Généralement, l'espace utilisateur est plutôt stupide et se limite à construire des structures de données et à les passer au noyau. Pour être capable de réaliser toute sorte de transformation, nous avons besoin en espace utilisateur d'une meilleure compréhension des jeux de règles. Le noyau de l'autre coté n'a pas besoin d'une compréhension totale, il a seulement besoin d'être sûr que le jeu de règles ne contient pas de choses qui peuvent crasher ou blesser le noyau lors de l'exécution. Ainsi, avec nftables, le noyau fournit principalement un langage de classification léger et tout ce qui est nécessaire à la compréhension de la sémantique est fait en espace utilisateur.
Planifiez-vous de merger nftables dans le noyau officiel ?
Patrick McHardy : Absolument. Je n'ai pas actuellement d'estimation du moment, mais j'espère l'avoir en bon état aux alentours de la deuxième moitié de cette année. Une première version alpha sera disponible dans le mois (NDLR : janvier 2009).
Y a-t-il d'autres nouvelles choses de prévu pour Netfilter ?
Patrick McHardy : Je n'ai actuellement rien de particulièrement intéressant en vue, mais laissez-moi répondre à la question avec une petite anecdote.
Au début de 2006, Astaro m'a demandé de finir le module de suivi de connexions pour H.323. Je travaillais dessus avec une priorité basse depuis l'année précédente. H.323 est un ensemble de protocoles bien compliqué et mon module de suivi de connexions nécessitait encore un bonne quantité de travail. J'ai libéré du temps pour m'en occuper de manière plus urgente ; le jour où j'ai voulu commencer à travailler dessus, je me suis levé, j'ai ouvert mon mail et j'ai trouvé une soumission de patch de Jing Min Zhao, contenant un module de suivi de connexions complet pour H.323, qui, à part quelques points mineurs, était tout simplement parfait et sans doute meilleur que le mien.
Cela montre que même les choses imposantes et compliquées peuvent en fait surgir du néant, sans qu'on n'en sache rien à l'avance. Nous avons un bon nombre de contributeurs actifs travaillant dans leur propre domaine d'intérêt. Je suis donc persuadé que nous continuerons à voir arriver de nouvelles choses intéressantes.
Cela dit, nous avons réalisé ces dernières années un ensemble d'inclusion de fonctionnalités utiles dans le noyau officiel, si bien que les demandes pour de nouvelles fonctionnalités sont en déclin constant et l'attention se porte de plus en plus sur la maintenabilité et l'amélioration de la qualité du code. Les domaines les plus actifs sont actuellement ctnetlink et, par extension, les améliorations de la gestion du failover et de la synchronisation des tables d'états, la journalisation en espace utilisateur, l'unification des codes de arptables, ebtables, iptables et ip6tables ainsi que la fin du travail sur le support des espaces de noms réseau.
La figure 1 montre le travail de la coreteam netfilter deuis 2.6.12. Avez-vous des remarques sur ce graphe ?
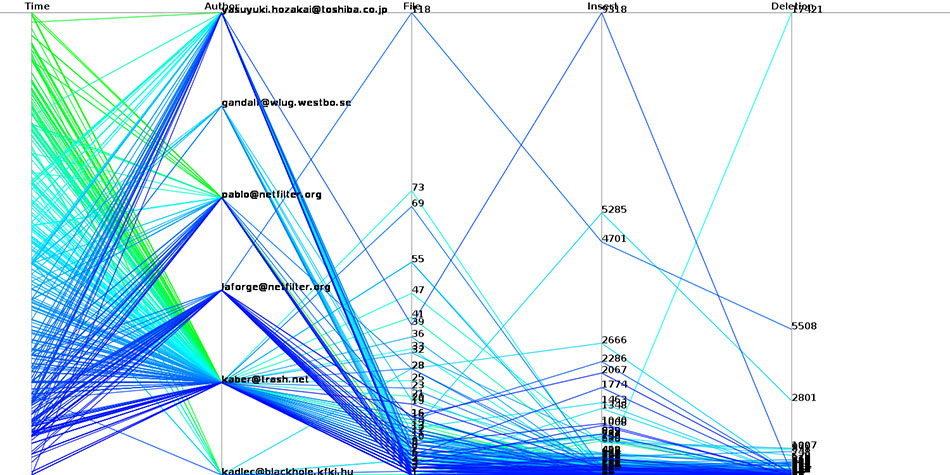
Le graphique de la figure 1 utilise les coordonnées parallèles pour représenter le travail sur Netfilter des membres de la coreteam depuis 2.6.12. Chaque ligne brisée représente un commit. Pour tracer un commit, on place la date à laquelle il a été effectuée sur le premier axe en partant de la gauche (les plus anciens en bas les plus récents en haut), sur le deuxième axe, on place l'auteur, sur le troisième le nombre de fichiers modifiés, sur le quatrième le nombre de lignes effacées et, enfin, sur le cinquième, on place le nombre de lignes ajoutées. On relie ensuite les points entre eux pour former une ligne brisée. Dans le cas de ce graphe, la couleur de cette ligne est choisie en utilisant un dégradé sur la date de commit. On voit ainsi que le travail récent en vert à principalement était effectué par Patrick McHardy (kaber). On voit aussi que les commits récents, pris individuellement ne sont pas très volumineux. Il y a en effet plus de bleu ciel dans les commits avec beaucoup de choses modifiées que de vert. (NDRL) Merci à Sébastien Tricaud et son excellent outil Picviz utilisé pour la génération de ce graphe.
Je suis heureux d'avoir effacé autant de lignes de code de Netfilter. J'espère que cela continuera encore.
De manière plus générale, je ne considère pas les métriques basées sur la taille et le nombre de patches comme un indicateur très significatif puisqu’elles mesurent uniquement la quantité et ne disent rien sur l'importance et la qualité des contributions et du temps de travail qui a été nécessaire. Elles montrent principalement les niveaux généraux d'activité, ce qui est dans mon cas une petite surprise.
Votre travail sur Netfilter est impressionnant, mais, en fait, vous travaillez aussi sur d'autres parties du noyau. Pouvez-vous nous en dire plus ?
Patrick McHardy : Merci. Je travaille uniquement dans des domaines relatifs au réseau. À côté de Netfilter, je maintiens les pilotes VLAN et MACVLAN, je suis listé comme co-mainteneur de IPv4/IPv6 et je travaille occasionnellement sur le cœur de l'infrastructure réseau, IPsec, etc. L'ordonnancement de trafic est un autre de mes centres d'intérêt, j'y ai implémenté les ordonnanceurs HFSC et DRR, le classifier de flux et fait beaucoup de travail sur l'infrastructure et de corrections de bogues. Un autre sujet qui m'intéresse est le protocole netlink et les interfaces avec l'espace utilisateur. Il y a historiquement beaucoup d'interfaces mal conçues. Les corriger, ajouter de nouvelles interfaces correctes et prévenir l'ajout de nouvelles interfaces mal conçues est à mon avis très important, car lorsque une interface est dans le noyau officiel, on est bloqué avec elle pour des années. Malheureusement, les auteurs de pilotes en particulier ne semblent pas avoir de vision d'ensemble lorsqu'ils implémentent une nouvelle interface, et une attention constante est donc nécessaire.
Lors des mois précédents, j'ai dû cependant réduire mes activités dans ces domaines, car mes projets actuels demandent beaucoup de temps. En plus de travailler sur nftables, j'ai récemment démarré une implémentation de la couche de protocoles DECT (oui, le truc pour téléphone sans fil :)). C'est un projet en basse priorité, que je réserve pour le temps où j'ai besoin d'une pause sur nftables, mais c'est un projet compliqué et il demandera probablement une grande quantité de travail.


