

 Ajouter à une liste de lecture
Ajouter à une liste de lecture
Cet article est un retour d'expérience. Il a pour but de vous présenter comment, dans un institut de recherche en biologie, nous avons entamé la migration de plusieurs centaines de téraoctets de données vers un seul et même serveur de fichiers. Cette migration a lieu dans le cadre d'un achat de nouveau matériel, destiné à remplacer plusieurs serveurs de stockage hétérogènes.
1. Contexte
La tâche peut paraître simple, mais malheureusement, les progrès technologiques aidant, les données que nous avons à gérer sont de plus en plus volumineuses ; ce prédicat est vrai pour les données professionnelles (nous avons ici des équipements capables de générer plusieurs Tio de données par jour), mais aussi, et pour l'instant dans une moindre mesure, pour nos données personnelles. À l'échelle de plusieurs centaines de Tio de données, les outils "classiques" tels que cp ou même rsync ne suffisent plus (nous verrons pourquoi).
Le contexte technologique est le suivant : notre infrastructure est constituée de serveurs hétérogènes (SunFire X4540, Netapp FAS980, HP X9000, IBM SONAS). Ils partagent environ 500 Tio de données pour 250 millions de fichiers à travers NFS v3 et CIFS et doivent être migrés vers une baie EMC/Isilon fraîchement acquise. Chaque serveur est relié au réseau via plusieurs liens gigabit agrégés (nos motifs d'accès à la donnée ne justifient pas - encore - le passage au 10 Gbps).
Les données hébergées sur ces systèmes ne possèdent pas d'attributs étendus ou d'ACL, juste des droits POSIX standards (ugo / rwx). Ce choix peut à première vue paraître étonnant, mais il s'agit à nos yeux du moyen le plus simple permettant un accès mixte (CIFS/NFS) à la donnée (postes de travail, machines de calcul). Cette problématique pourrait d'ailleurs faire l'objet d'un autre article.
Nous gérons environ 3000 comptes utilisateurs.
Voici, dans le détail, le chemin suivi pour aboutir à la solution qui vous sera dévoilée dans la suite de l'article.
2. Les besoins
Tout d'abord, commençons par définir les besoins.
Le premier est évidemment de transférer les données de manière sûre vers la nouvelle baie de stockage. Il faudra conserver les fichiers spéciaux ainsi que les métadonnées : utilisateurs et groupes propriétaires, droits associés, timestamps.
Cette solution doit permettre une interruption de service minimale pour les utilisateurs, idéalement qu'ils puissent continuer à travailler pendant le transfert des fichiers.
La solution doit également être assez souple pour transférer, au choix, de gros espaces de données ou bien des espaces plus petits afin de faciliter leur éventuelle réorganisation.
Elle doit être rejouable sans repartir de zéro : un plantage, une coupure électrique ou bien encore un défaut de climatisation sont vite arrivés.
Enfin elle ne doit bien évidemment pas coûter cher et réutiliser au maximum l'infrastructure dont nous disposons actuellement.
3. Choix de l'outil
Il n'est pas forcément évident de trouver de la littérature traitant de la migration de données avec un tel volume et un tel nombre de fichiers. Deux références récentes nous semblent cependant intéressantes. L'article de Jeff Layton "Moving Your Data - It's Not Always Pleasant"1 évalue différents outils (dont certains intègrent la préservation des attributs étendus et des ACL) et amorce une réflexion de fond sur la problématique. Il mentionne la présentation de Marc Stearman du Lawrence Livermore National Laboratory ayant eu lieu lors du Lustre User Group en 2013 : "Sequoia Data Migration Experiences"2. C'est un autre contexte et une architecture différente ainsi qu'un autre ordre de grandeur. Nous vous invitons vivement à parcourir ces deux références !
Notre choix s'est logiquement porté sur rsync3. Il est éprouvé et robuste. rsync a la possibilité de ne transférer que les blocs modifiés d'un fichier, économisant ainsi la bande passante (et donc le temps nécessaire à la copie des données). Il est capable de reprise : en cas de problème, il sera en mesure de poursuivre à partir du fichier dont le transfert a été interrompu ; un travail de copie est donc rejouable et sera très rapide si les fichiers source et destination sont identiques. Enfin, il dispose de nombreuses options avancées qui pourront nous être fort utiles.
Néanmoins, au-delà d'un certain nombre de fichiers, rsync montre certaines limites4. De plus, si on ne transfère pas uniquement des fichiers de tailles importantes, nous aurons du mal à maximiser l'utilisation de notre réseau, quelle que soit sa capacité. Ces limites peuvent être repoussées en adoptant une approche de type « diviser pour mieux régner », comme nous le verrons dans la suite de l'article. Auparavant, attardons-nous quelques instants sur les autres outils susceptibles d'être employés dans le cadre d'une migration de données.
Le premier qui vient à l'esprit est cp. Cet outil est simple, rapide et robuste, mais il présente évidemment un défaut majeur : il ne supporte pas la reprise. Une interruption de la copie et c'est toute une arborescence qu'il faut recopier ! C'est inenvisageable vue la quantité de données à traiter.
tar (tape archiver) pourrait sembler un bon candidat puisqu'il est initialement destiné à la sauvegarde/restauration de données. Il offre la possibilité de n'archiver que les fichiers nouvellement modifiés et celle de ne pas restaurer un fichier qui serait plus récent dans sa destination. C'est bien, mais non suffisant pour permettre la reprise, car tar restaurera tout de même l'intégralité du reste de l'archive (hors fichiers plus récents dans la destination). Par ailleurs ces fonctionnalités nécessitent de passer par un fichier d'archive (passer par un pipe - unidirectionnel - et faire transiter les données via netcat, par exemple, est par définition incompatible avec ce genre d'opérations), ce que nous ne pouvons nous permettre de faire car, en plus de nécessiter du temps, ceci nécessiterait beaucoup d'espace disque temporaire. Enfin, un dernier point est à noter : l'unité avec laquelle travaille tar est le fichier ; il n'est pas capable de transférer uniquement les blocs de données modifiées. La recopie d'un fichier volumineux nouvellement modifié prendrait donc beaucoup de temps, y compris pour seulement quelques octets de différence.
À l'institut, nous effectuons nos sauvegardes sur bandes via Netbackup. Nous pourrions donc être tentés d'utiliser ce logiciel et le protocole NDMP pour restaurer les données sur le serveur de destination. Malheureusement, Netbackup utilise une version modifiée de tar, ce qui nous ramène aux limitations exposées précédemment (avec la joie, en prime, de travailler avec des bandes et le plaisir de payer des licences logicielles et matérielles très onéreuses). Une solution mixte NDMP + rsync pourrait être envisagée, mais implique de disposer de suffisamment de bandes, de licences et ne répond pas à la question de la maximisation de l'utilisation du réseau.
Certains serveurs de fichiers propriétaires proposent des outils de migration permettant d'importer des données d'autres serveurs. C'est le cas d'Isilon, qui offre un outil de migration de données depuis des serveurs Netapp (isi_vol_copy). Malheureusement, cet outil ne couvre pas tous les types de serveurs dont nous disposons et ne permet pas de maximiser l'utilisation du réseau. D'une façon générale, les outils proposés par les constructeurs sont restreints à des technologies triées sur le volet et manquent cruellement de souplesse. Nous avons donc écarté ce type de solution.
Par curiosité, nous aurions également aimé évaluer des solutions dédiées de type ARX5. Ce sont des équipements qui se placent en coupure entre les données et les utilisateurs. Ils permettent un accès à la donnée quelle que soit sa source ainsi qu'une migration réellement transparente, sans aucun arrêt de service sauf lors de sa mise en place. Cette solution est par contre très onéreuse, mais elle est à mettre en regard avec le nombre de personnes impliquées dans une migration massive. Peut-être qu'au final il est financièrement plus intéressant de mettre en place ce type de solution plutôt que de dédier des ressources humaines pendant plusieurs mois à la migration. À noter que certains constructeurs intègrent ce type de fonctionnalités directement au sein de leurs baies.
Le logiciel n'est qu'une partie des outils à notre disposition. Il faut maintenant préciser que nous disposons également d'un cluster de calcul composé d'une soixantaine de machines physiques, fonctionnant sous GNU/Linux et disposant chacune d'une connexion gigabit. Ces machines sont connectées aux serveurs de fichiers via NFS v3. Idéalement, nous aimerions pouvoir bénéficier des connexions réseau de ces machines pour permettre de maximiser la bande passante utile vers le serveur de destination.
4. Notre approche
Notre réflexion fut la suivante : sur nos serveurs, pour de gros fichiers, les E/S (entrées/sorties) disques sont négligeables et le goulet d'étranglement sera le réseau ; effectuer la copie depuis une seule machine saturerait son lien gigabit et ne serait pas optimal. Pour des petits fichiers (par exemple pour les espaces hébergeant des boîtes aux lettres au format maildir), les E/S pourraient s'avérer limitantes, particulièrement au niveau des serveurs de fichiers sources (la destination étant un scale-out NAS, a priori capable d'encaisser une quantité d'E/S bien plus importante que nos baies de générations plus anciennes). Si nous pouvions paralléliser les copies, nous utiliserions au maximum la bande passante disponible et nous gagnerions du temps. Idéalement, cette parallélisation permettrait à une machine de recopier en même temps des données depuis des serveurs de fichiers sources différents afin de limiter les risques de ralentissement liés aux problèmes d'E/S évoqués : on maximise l'utilisation de la bande passante sans saturer une unique source.
Le problème est que l'outil sélectionné (rsync) ne permet pas nativement ces acrobaties. rsync n'est pas distribué : l'application considère une source et une destination, parcourt la source, compare les fichiers et envoie les modifications à répliquer à la destination, éventuellement à travers le réseau.
Cet outil présente également un autre défaut : son temps de parcours est long (construire la liste des fichiers à transférer prend par exemple 7 jours pour 50 millions de fichiers dans nos tests en production) et la liste de fichiers générée est située en mémoire. Elle est donc volatile : en cas de crash, il faudra reparcourir toute l'arborescence. rsync est bien capable de générer un fichier de travail (cf. mode batch), mais le fichier généré est binaire : nous aurions pu imaginer l'exploiter (par exemple le découper en plusieurs parties à traiter indépendamment), mais ce n'est pas possible nativement.
Un autre inconvénient est que rsync nécessite beaucoup de mémoire (environ 100 octets par fichier, cf. FAQ). Jusqu'à la version 3.0.0, il fallait attendre la fin du parcours complet de l'arborescence pour démarrer le transfert. Depuis, cette limitation a été levée6, diminuant fortement les besoins en mémoire et permettant de gagner du temps sur la synchronisation. Néanmoins, nous n'avons aucune idée du comportement qu'aura l'application sur plusieurs centaines de Tio de données si un nombre important de fichiers est à synchroniser. À cette échelle, la copie pourrait-elle simplement se terminer ?
Face à cette incertitude et dans l'idée de terminer le plus rapidement possible les synchronisations de données, il nous a paru évident qu'il était nécessaire de subdiviser notre arborescence afin d'effectuer les synchronisations en parallèle. Le problème est qu'il n'existe aucune méthode « clef en main » pour paralléliser rsync.
5. Subdiviser une arborescence de fichiers
Comment procéder pour subdiviser une arborescence de fichiers ? Par subdiviser, nous entendons diviser de manière équilibrée, c'est-à-dire en sous-arborescences contenant idéalement le même nombre de fichiers et faisant la même taille.
La première façon qui vient à l'esprit serait de descendre d'un ou plusieurs niveaux dans l'arborescence de fichiers et de fonctionner par sous-répertoires au lieu des répertoires parents. Cette manière de faire a l'avantage d'être simple et rapide, car elle ne nécessite pas de parcourir l'arborescence pour décider de la découpe à effectuer. Malheureusement, elle n'est pas équilibrée : nous ne pouvons présumer du nombre de fichiers ou de la taille de chaque répertoire ; cette méthode génère des paquets inégaux en taille et en nombre de fichiers.
Une autre façon de faire serait de créer des listes de fichiers, indépendamment de leur positionnement dans l'arborescence à synchroniser. Cette granularité permettrait, en théorie, d'équilibrer (presque) parfaitement les parties à synchroniser (aussi bien en nombre de fichiers qu'en taille). En outre, rsync propose une option --files-from qui permettrait d'exploiter ces listes et lui éviterait la longue période de parcours initial. Nous avons opté pour cette méthode.
Malheureusement, il n'existe pas d'outil standard pour effectuer cette tâche de création de paquets qui semble pourtant un besoin assez courant (votre moteur de recherche préféré vous le prouvera). Il serait bien entendu possible d'écrire un script shell (ou PERL ou autre) en utilisant par exemple find et en découpant la liste des fichiers affichés selon des critères de taille et de nombre, mais nous avons préféré un outil en C pour des raisons de performance et de portabilité accrues.
6. Fpart
L'outil que nous avons mis au point se nomme fpart7. Il est développé en C et est disponible sous licence BSD modifiée. Nous ne détaillerons pas la compilation et l'installation très classiques de fpart, mais sachez qu'il est d'ores et déjà disponible dans l'arbre officiel des ports FreeBSD (sysutils/fpart) et en cours d'intégration sous Debian.
Pour la petite histoire, le développement de cet outil a débuté plusieurs mois plus tôt ; il n'était pas destiné initialement à la migration de données, mais juste à la création de "partitions" de fichiers à partir d'une liste de répertoires fournis sur la ligne de commandes. Ces "partitions" forment des sous-ensembles disjoints des répertoires fournis en argument et sont équilibrées (en taille et en nombre de fichiers) selon l'algorithme glouton8. Dans son mode par défaut, fpart parcourt une (ou plusieurs) arborescence(s) pour générer, à la fin du parcours, des partitions, selon les critères définis par l'utilisateur.
Voici un exemple d'utilisation basique, que nous détaillerons dans la prochaine section :
$ fpart -n 3 -o var-parts /data/src
267781 file(s) found.
Part #0: size = 2658718909, 89260 file(s)
Part #1: size = 2658718908, 89261 file(s)
Part #2: size = 2658718908, 89260 file(s)
fpart garantit que l'union de toutes les partitions générées permet de reconstruire l'ensemble des répertoires et fichiers examinés.
Le projet de migration de données a été l'occasion d'ajouter à fpart une fonctionnalité supplémentaire : la possibilité de générer en direct (mode live) les partitions et de déclencher une commande juste après la génération de chaque partition (post-hook), sans attendre la fin du parcours complet du système de fichiers. Cette fonctionnalité peut être utilisée pour déclencher immédiatement rsync sur le sous-ensemble de fichiers produits.
En mode standard, fpart permet de générer un nombre souhaité de partitions, ainsi que des partitions limitées par leur taille et leur nombre de fichiers. En mode live, générer un nombre n de partitions équilibrées n'est pas possible, car fpart ne peut présumer du nombre de fichiers qu'il est en train d'examiner (la répartition exacte ne peut se faire qu'une fois tout le système de fichiers parcouru). Il peut cependant générer des partitions de taille et de nombre de fichiers limités. Ceci, bien que non optimal, suffit largement à notre besoin.
Le mode live de fpart a un autre avantage : l'économie de mémoire. Dans ce mode, fpart peut parcourir plusieurs centaines de Tio avec une empreinte mémoire limitée (et quasi-constante, de quelques Mio seulement), car une seule partition est présente en mémoire à un instant t, à la différence du mode standard qui a une empreinte mémoire beaucoup plus importante pour trier les données de manière précise.
En utilisant fpart, nous limitons les risques évoqués précédemment en faisant travailler rsync sur de petits espaces de données. Cette méthode de travail nous permet également de répondre au besoin de parallélisation. Enfin, par le biais d'un parcours d'arborescence unique, nous limitons les E/S et nous sommes en mesure de démarrer les synchronisations pendant ce temps incompressible que représente un parcours de plusieurs centaines de Tio de fichiers.
7. Premiers exemples
Reprenons notre exemple d'utilisation de fpart cité précédemment :
$ fpart -n 3 -o var-parts /data/src
267781 file(s) found.
Part #0: size = 2658718909, 89260 file(s)
Part #1: size = 2658718908, 89261 file(s)
Part #2: size = 2658718908, 89260 file(s)
Cette commande parcourt intégralement /data/src et génère, en fin de parcours, 3 fichiers de partitions : var-parts.[0-2]. Ici, fpart est lancé en mode standard et il n'est pas question de hooks, mais juste de subdiviser notre arborescence en plusieurs partitions. Les fichiers générés contiennent la liste des fichiers parcourus ; les 3 listes sont équilibrées en nombre et en taille.
Voici un exemple plus avancé impliquant l'utilisation du mode live :
$ mkdir foo && touch foo/{bar,baz}
$ fpart -L -f 1 -o /tmp/part.out -W \
'echo == ${FPART_PARTFILENAME} == ; cat ${FPART_PARTFILENAME}' foo/
== /tmp/part.out.0 ==
foo/bar
== /tmp/part.out.1 ==
foo/baz
2 file(s) found.
Ici, nous générons deux fichiers vides : foo/bar et foo/baz puis exécutons fpart en mode live (option -L) pour générer des partitions de 1 fichier (option -f) et les écrire dans /tmp/part.out.<n> (option -o). Pour chaque partition générée, le hook (option -W) suivant est exécuté à la volée :
echo == ${FPART_PARTFILENAME} == ; cat ${FPART_PARTFILENAME}
La variable ${FPART_PARTFILENAME} est générée par fpart et fait partie de l'environnement du hook : elle représente le fichier de partition venant d'être produit. Ce hook affiche donc le nom du fichier de partition, ainsi que son contenu (dans notre cas, 1 fichier à chaque fois).
8. Un exemple avec rsync et GNU parallel
Ces exemples sont triviaux ; voyons désormais un exemple plus avancé, se rapprochant de notre problème initial. L'exemple suivant montre comment il est possible d'utiliser fpart pour lancer, depuis la même machine, 3 synchronisations en parallèle. Le mode live de fpart permet d'exécuter des hooks synchrones, c'est-à-dire que l'outil attend la fin du hook pour poursuivre le parcours du système de fichiers. En d'autres termes, il n'intègre pas de scheduler (ce n'est pas son rôle). Il faudra donc s'appuyer sur un scheduler externe. L'exemple donné ici utilise GNU Parallel9 et plus particulièrement la commande sem.
Nous allons ici synchroniser /data/src vers /data/dest.
Tout d'abord, placez-vous dans le répertoire source à examiner. Ceci est nécessaire, car l'option --files-from de rsync utilise par défaut une liste de fichiers relative au répertoire source :
$ cd /data/src
Ensuite, exécutez fpart depuis ce répertoire :
$ fpart -L -f 10000 -x '.snapshot' -x '.zfs' -Z -o /tmp/part.out -W \
'sem -j 3
"rsync -av --files-from=${FPART_PARTFILENAME}
/data/src/ /data/dest/"' .
Cette commande exécute fpart en mode live (option -L) en lui demandant de produire des partitions d'au plus 10 000 fichiers (option -f). fpart ne listera pas les fichiers ou répertoires nommés .snapshot ou .zfs (options -x), mais listera les répertoires vides ou non accessibles (option -Z, cette option est nécessaire lorsqu'on travaille avec rsync pour s'assurer de recréer à l'identique l'arborescence dans le répertoire cible). Enfin, chaque partition sera écrite dans /tmp/part.out.<n> (option -o) et utilisée dans le hook post-partition (option -W) suivant :
sem -j 3
"rsync -av --files-from=${FPART_PARTFILENAME} /data/src/ /data/dest/"
Ce hook utilise la commande sem de GNU parallel pour planifier au maximum 3 rsync concurrents. Ils sont exécutés de la manière suivante :
rsync -av --files-from=${FPART_PARTFILENAME} /data/src/ /data/dest/
La variable ${FPART_PARTFILENAME} est directement utilisée par rsync et lui indique la liste des noms de fichiers et répertoires à transférer.
Bien entendu, exécuter plusieurs synchronisations d'un même espace de données (provenant d'un serveur source unique) sur la même machine présente a priori peu d'avantages (à moins que le client ou le serveur soit en mesure de paralléliser les E/S si l'emplacement physique des données le permet). Cet exemple donne simplement une idée de la manière dont peut être utilisé fpart.
Imaginez que l'on remplace le scheduler local (sem) par celui de notre cluster de calcul...
9. Utilisation avec notre cluster
C'est l'idée que nous avons déjà évoquée précédemment : utiliser notre cluster de calcul pour effectuer les transferts. Ainsi, nous mettons à contribution l'infrastructure existante et nous maximisons la bande passante disponible vers la baie de destination. Le cluster est composé d'une soixantaine de machines, toutes connectées via des liens gigabit à un commutateur central. Des liens agrégés partent également depuis ce commutateur vers les serveurs de stockage. Chaque nœud fonctionne sous GNU/Linux (CentOS) et monte les espaces de stockage via NFS v3 (tcp). L'orchestration de ces machines se fait via le logiciel OGS10 (Open Grid Scheduler), descendant direct de SGE (Sun Grid Engine).
Pour la migration, nous n'utiliserons en réalité qu'une sous-partie du cluster, dédiée temporairement à la copie des données. Nous associerons à ce pool de 5 machines réservées un nombre maximum de jobs exécutables en parallèle.
Le cluster dispose d'un nœud particulier capable de soumettre des jobs de calcul aux nœuds du cluster ; c'est cette "tête" que nous utiliserons pour soumettre les jobs rsync. Cette tête de soumission monte les mêmes espaces de stockage que les nœuds.
Les montages effectués sur chacune des machines sont les suivants :
- L'intégralité des espaces à synchroniser, provenant de nos serveurs de fichiers à migrer. Ceux-ci sont montés dans un répertoire dédié, accessible uniquement à root et en lecture seule. L'option no-root-squash a été positionnée sur les exports afin de pouvoir accéder à l'intégralité des données.
- L'espace de destination situé sur la baie Isilon. Celui-ci est monté dans ce même répertoire spécifique en lecture-écriture et exporté avec l'option no-root-squash.
Il convient ici de préciser que les utilisateurs « normaux » du cluster n'ont pas accès aux machines participant à la migration. Toutefois, il faut garder à l'esprit les risques potentiels d'un montage no-root-squash. Nous y reviendrons.
Voici le scénario imaginé : pour chaque espace à migrer (concrètement, pour chaque montage NFS, toutes machines sources confondues), nous exécuterons, depuis la tête de soumission du cluster, un script enrobant fpart, qsub (la commande pour soumettre un job à OGS, l'équivalent de sem dans notre exemple) et rsync. Ce script déterminera les partitions à synchroniser et soumettra à OGS les jobs rsync à effectuer. Le scheduler d'OGS, lorsqu'un nœud sera disponible, lui fera exécuter la copie des données.
Pour que ceci fonctionne il faut, comme nous l'avons précisé, que tous les espaces sources soient montés sur la tête de soumission afin de permettre à fpart de parcourir les fichiers. Sur les nœuds du cluster susceptibles de copier les données, il faut monter les espaces sources et l'espace de destination. Enfin, il a fallu dédier un espace NFS à fpart, monté sur toutes les machines, afin qu'il y stocke les fichiers des partitions générées. Cet espace servira d'espace d'échange des listes entre la machine de soumission (qui génère les listes) et les nœuds effectuant la copie des données (qui consomment ces listes).
Le script utilisé ressemble aux exemples étudiés précédemment à la différence du scheduler utilisé, qui est celui d'OGS. Voici les lignes clefs de ce script. Ne vous laissez pas impressionner, nous allons le décortiquer ensemble :
1) QSUB_COMMAND="sudo /bin/sh -c '${RSYNC_BIN} -av --numeric-ids --files-from=\\\"\${FPART_PARTFILENAME}\\\" \\\"${SRC_PATH}/\\\" \\\"${DST_PATH}/\\\"'"
2) FPART_POSTHOOK="sudo -i -u '${QSUB_RUNAS}' qsub -b y -N \"${QSUB_JOBNAME}-fpart-$$\" -o \"${FPART_LOGDIR}/$$-\${FPART_PARTNUMBER}.stdout\" -e \"${FPART_LOGDIR}/$$-\${FPART_PARTNUMBER}.stderr\" -q '${QSUB_QUEUE}' -l '${QSUB_RESOURCE}=1' \"${QSUB_COMMAND}\""
3) ${FPART_BIN} -f "${FPART_MAXPARTFILES}" -s "${FPART_MAXPARTSIZE}" -o "${OUTPART_TEMPLATE}" -x '.zfs' -x '.snapshot*' -Z -L -v -W "${FPART_POSTHOOK}" . 2>&1 | tee -a ${FPART_LOGDIR}/fpart.log
Les lignes sont présentées par « couches croissantes » : la ligne 3 encapsule la ligne 2 qui encapsule la ligne 1.
La première ligne est la commande qui sera exécutée sur les nœuds. Afin d'avoir accès aux données, elle utilise sudo pour passer root. Ce job devra évidemment être soumis par un utilisateur privilégié sur le cluster. On retrouve l'appel à rsync utilisant le nom du fichier de la partition venant d'être générée (${FPART_PARTFILENAME}). Cette variable sera renseignée par fpart au moment de l'exécution du hook. On retrouve aussi d'autres options de rsync, notamment le fait de copier les uid et gid sans passer par une résolution de nom intermédiaire (--numeric-ids).
La seconde ligne enrobe la première et constitue le post-hook en tant que tel ; il s'agit de l'appel à qsub (la commande de soumission de jobs d'OGS) qui soumettra la commande sudo étudiée précédemment. Elle est effectuée sous l'identité de l'utilisateur privilégié dont nous parlions à la première ligne (${QSUB_RUNAS}). Nous donnons un nom à ce job : ${QSUB_JOBNAME}-fpart-$$ (la variable ${QSUB_JOBNAME} est renseignée interactivement au démarrage du script) et nous traçons les sorties standard et d'erreur du job dans des fichiers de log dédiés (${FPART_LOGDIR}/$$-\${FPART_PARTNUMBER}.stdout et ${FPART_LOGDIR}/$$-\${FPART_PARTNUMBER}.stderr). Les noms de ces fichiers sont générés par le biais de variables fpart et ceux-ci sont créés sur le même espace NFS que celui permettant de stocker les listes de fichiers à synchroniser (puisque tous les nœuds, ainsi que la tête, y ont accès). Enfin, nous précisons la queue (${QSUB_QUEUE}) et la ressource (${QSUB_RESOURCE}) utilisées par le job.
La dernière ligne enrobe les deux premières et constitue cette fois l'appel principal à fpart. On retrouve nos paramètres, initialisés plus haut dans le script (${FPART_MAXPARTFILES, ${FPART_MAXPARTSIZE}), ainsi que le template des noms de fichiers de partitions générées (${OUTPART_TEMPLATE}). Ici aussi, tout est tracé, dans un fichier de log général dédié aux scans fpart (${FPART_LOGDIR}/fpart.log), via tee.
Voilà l'idée globale du script que nous avons utilisé. Nous n'avons détaillé ici que les options principales ; vous pourrez creuser un peu si le cœur vous en dit. La partie la plus difficile dans l'écriture de ce script est de savoir à quel moment les variables doivent être évaluées et de les protéger en conséquence.
Voici un schéma récapitulant cette architecture :
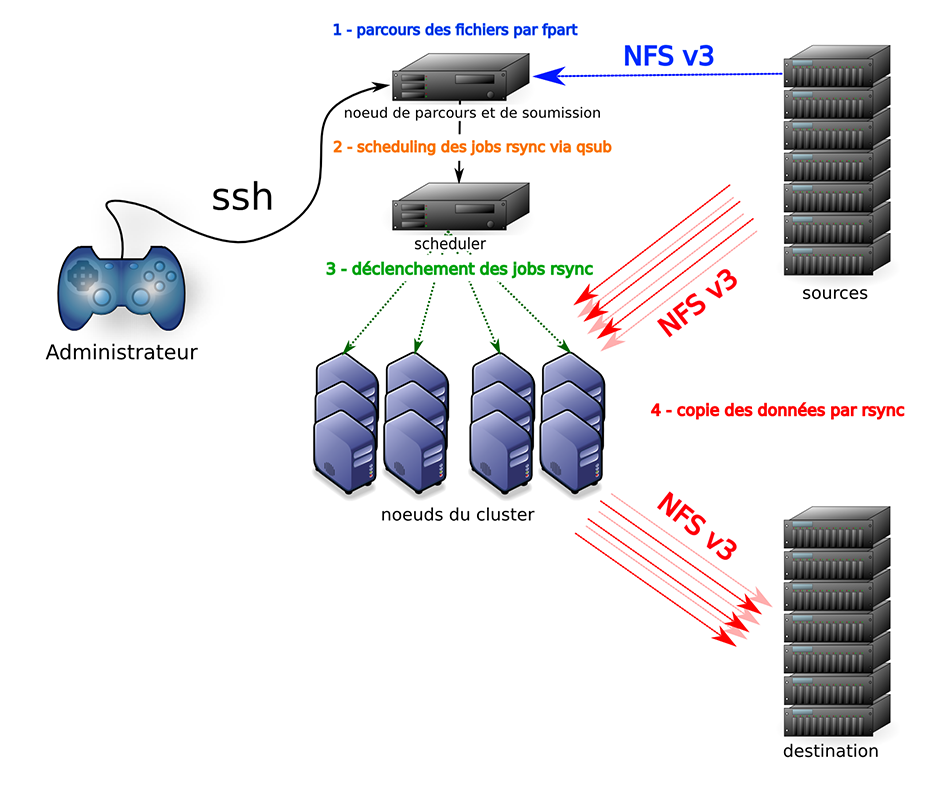
10. Les étapes de la migration
10.1 Une migration en 3 étapes
Pour chaque espace de données à migrer, la synchronisation se déroulera en 3 étapes :
- une pré-migration, qui se déroule en ligne ; ceci signifie que les utilisateurs peuvent continuer à travailler pendant ce temps. Cette étape comprend un passage de fpart, ainsi que la soumission et l'exécution des jobs de synchronisation en résultant.
- une ou plusieurs migrations intermédiaires, en ligne également, afin d'éviter de laisser la destination déjà synchronisée dériver des données originales si trop de temps s'écoule avant l'étape finale.
- l'étape finale, qui correspond à la bascule définitive de l'espace de données vers la nouvelle baie de stockage. Cette étape doit être la plus courte possible, car elle se fait hors ligne, c'est-à-dire que l'accès est bloqué pour les utilisateurs, afin d'éviter qu'ils ne modifient leurs données pendant la migration. Pour que cette étape soit courte, elle doit se situer dans le temps le plus tôt possible après une migration intermédiaire.
Ce plan de synchronisation nous garantit un maximum d'efficacité et de sécurité avec un minimum d'interruption de service.
10.2 L'étape finale
Détaillons cette dernière étape, car elle est un peu particulière : elle consiste en un rsync unique, non exécuté depuis fpart.
La raison de cette dernière synchronisation est simple : jusqu'ici, nous n'avons fait que synchroniser les fichiers ajoutés et modifiés, mais nous n'avons jamais supprimé les fichiers ayant disparu de la source. Les fichiers se sont donc accumulés dans la cible au fil des « migrations préparatoires ». Cette dernière synchronisation doit permettre d'obtenir un miroir exact de l'espace d'origine en supprimant les fichiers surnuméraires de la cible. Sans cette dernière passe, l'utilisateur qui a supprimé des fichiers après les premières synchronisations les verrait "réapparaître" dans la destination après la migration, ce qui n'est pas souhaitable.
Pourquoi avoir fait le choix d'un rsync final unique et non distribué via fpart ? Il y a deux raisons.
La première est que l'utilisation de fpart ne ferait probablement pas gagner de temps ici : les données à transférer sont minimales, donc le temps nécessaire pour cette étape tend vers le temps de parcours du système de fichiers.
La seconde raison est la plus importante et elle est technique : l'option à utiliser pour supprimer les fichiers de la cible est --delete ; malheureusement, elle est incompatible avec l'option --files-from si la liste fournie contient des fichiers (ce qui est notre cas).
Pour utiliser l'option --delete de manière distribuée, il faudrait faire en sorte de passer une liste de répertoires (uniquement) à l'option --files-from. L'option -d de fpart, qui demande d'inclure les noms des répertoires à partir d'une certaine profondeur de chemin, aurait pu être une piste. Dans tous les cas, et comme évoqué précédemment, un découpage par répertoire ne produit que rarement des listes équilibrées. Ainsi, vu le peu d'avantages de cette méthode et la complexité supplémentaire qu'elle induirait, nous avons fait le choix d'un rsync final unique.
Note : pour ceux qui seraient tentés d'utiliser l'option --delete avec l'option --files-from et une liste de répertoires, il faut dans ce cas utiliser également l'option -r pour que le contenu de chaque répertoire soit synchronisé en plus de l'entrée du répertoire lui-même.
Ce choix peut paraître étonnant, car nous émettions des doutes quant au passage à l'échelle de rsync sur un grand nombre de fichiers. Pour cette dernière étape, nous en avons fait le pari, les actions à effectuer étant minimales (suppressions de fichiers) et les fichiers concernés a priori peu nombreux.
11. Résultats
Afin d'illustrer les performances de la solution, nous vous proposons les résultats obtenus à partir de deux jeux de données de 100 Gio :
- un répertoire « home » caractéristique contenant des PDF, des sources, des dépôts de sources, de la musique, de la vidéo, des mails, dupliqué 3 fois pour un total de 100 Gio.
- un espace de données « artificielles » ne contenant que des fichiers de 70 Mio. Il s'agit de 1500 archives du noyau Linux au format xz réparties dans 15 répertoires pour un total de 100 Gio.
Les tests reposent sur l'architecture exposée dans le schéma précédant. Cinq nœuds du cluster sont ici dédiés à nos tests. Le serveur de fichiers source n'était pas en production à l'inverse du serveur destination (plusieurs milliers d'utilisateurs, accès CIFS et NFS, données scientifiques accessibles sur le cluster, messagerie...). Les tests ont été lancés à plusieurs reprises et nous n'avons pas relevé de divergences notables dans l'allure des courbes de trafic. Dans ces conditions imparfaites, mais néanmoins raisonnables, nous nous intéresserons donc plus aux tendances qu'aux résultats bruts. Entre chaque test, nous avons pris soins de vider les caches disques (echo 3 > /proc/sys/vm/drop_caches).
Voici tout d'abord les résultats d'un simple rsync sur le jeu de données « home » (obtenus à l'aide de l'interface web de ganglia) :
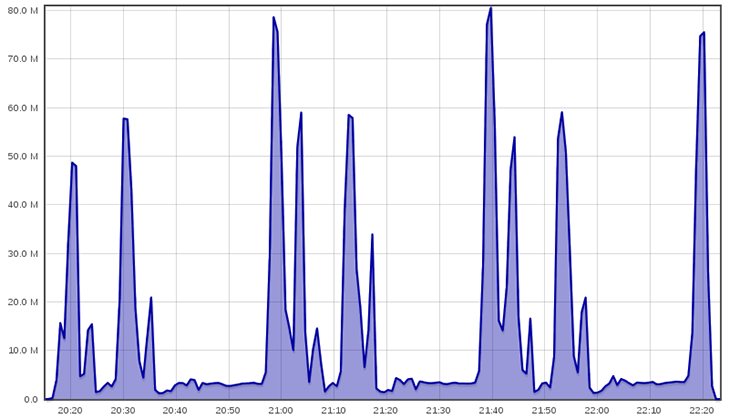
100 Gio en environ 2h10, soit 13 Mio / seconde en moyenne. Le motif d'utilisation très irrégulier de la bande passante nous confirme que nous avons affaire à des tailles de fichiers bien différentes dont certaines auraient bien du mal à saturer un lien réseau à seulement 100 Mbits/s.
Nous lançons maintenant le même transfert avec fpart qui soumet des rsync à notre gestionnaire de tâches sur le cluster. fpart a été lancé afin de générer des paquets de moins de 20 000 fichiers et d'au plus 5 Gio au total, ce qui représente ici 53 « paquets » à transférer (certains paquets sont limités par le nombre de fichiers, d'autres par la taille). Le temps incompressible nécessaire au parcours de l'arborescence est de 25 minutes environ. Durant ces 25 minutes, dès qu'un paquet est créé, fpart soumet le transfert au gestionnaire de tâches. Nous autorisons deux rsync à tourner en même temps. Voici une illustration de l'état du gestionnaire de tâches en cours de transfert :
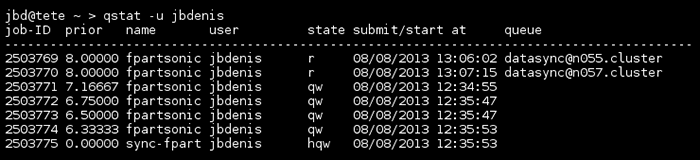
Il y a deux tâches en cours (« state » r) et des tâches en attente (« state » qw pour « queue wait »). La dernière tâche en « hold queue wait » dépend des tâches précédentes : il s'agit d'un job final destiné à nous envoyer un message lorsque toutes les tâches sont terminées.
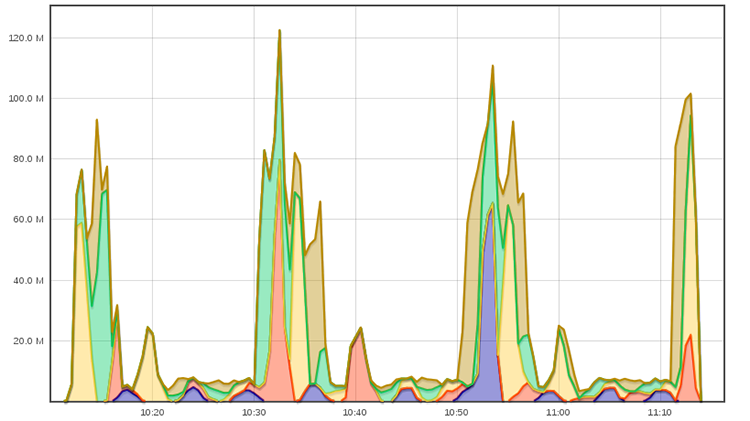
100 Gio en environ 1h01, soit 28 Mio / seconde en moyenne. Chaque couleur du graphique représente une machine différente. Le gestionnaire de tâches choisit une machine sur les cinq de notre architecture pour lancer chaque tâche se trouvant dans sa file d'attente. Le mécanisme d'élection se base ici sur la charge processeur de chaque machine (une métrique de charge réseau aurait été plus pertinente dans notre cas). À un instant donné, il ne peut y avoir que deux machines qui interviennent dans le transfert. Cela n'est pas le cas sur certaines zones du graphiques à cause du délai entre chaque prise de performances de ganglia (toutes les 15 secondes par défaut). Le graphique présente les performances empilées (« stacked » dans la terminologie ganglia). Par exemple, vers 10h32, le débit cumulé était de 120 Mio/s sur l'ensemble des cinq machines (même si il n'y en a que deux qui participent au transfert)
Même test, avec fpart et 4 rsync en parallèle :
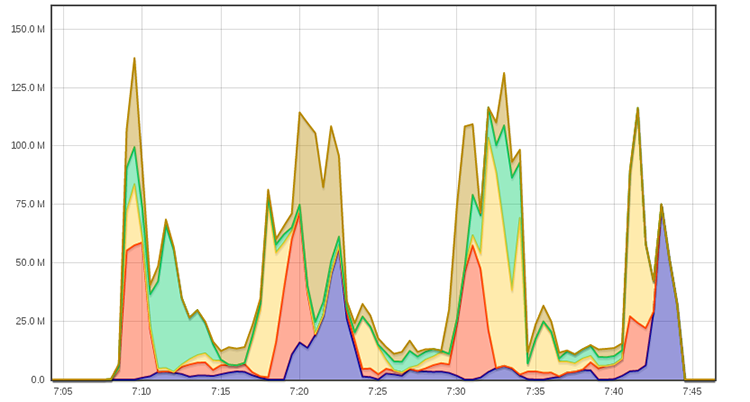
100 Gio en environ 36 minutes, soit 46 Mio / seconde en moyenne.
Enfin, avec 8 rsync en parallèle. Comme nous n'avons que 5 machines à notre disposition, il faut garder à l'esprit que plusieurs rsync s'exécuteront sur la même machine.
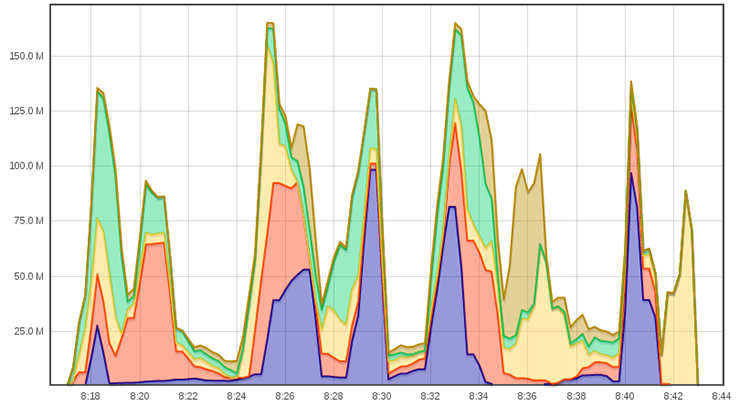
Il n'y a pas d'amélioration par rapport à l'utilisation de 4 rsync. Nous arrivons très certainement aux limites en entrées/sorties du serveur source en lecture et/ou du serveur destination en écriture.
Nous avons relancé ces tests sur notre jeu de données « artificielles » : 1500 noyaux linux compressés au format xz, soit 100 Gio de données. Voici les résultats avec 2, 4, et 8 rsync en parallèle, sur le même graphique :
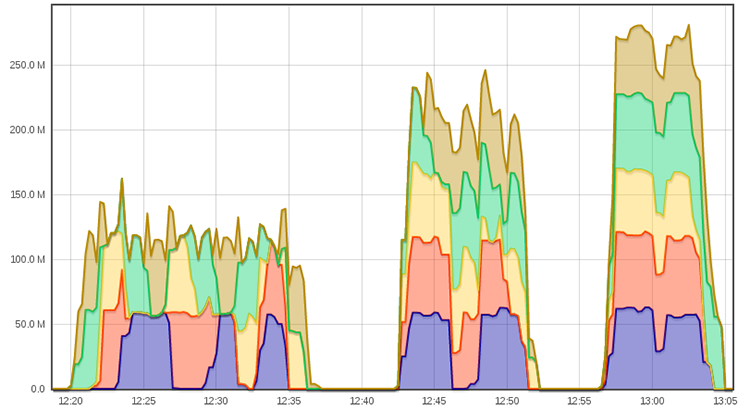
17 minutes avec 2 rsync (98 Mio/s), 10 minutes avec 4 rsync (166 Mio/s), 7 minutes avec 8 rsync (238 Mio/s), cela fonctionne plutôt bien. Dommage que nous n'ayons eu que 5 machines à notre disposition, peut-être que la version avec 8 rsync aurait donné de meilleurs résultats.
Si l'on ne regarde que les débits sur les données « réelles » de type répertoire personnel, on peut penser qu'ils sont décevants : 46 Mio/s cumulés sur 5 liens gigabit, c'est 10 % du débit théorique. Le type, la taille et le nombre de fichiers à transférer ont une importance capitale. Par exemple, il est illusoire d'espérer saturer un lien gigabit avec une arborescence de boîtes au format maildir de plusieurs Tio. C'est ce qui se passe ici, à une moindre échelle. Il est beaucoup plus rapide de transférer de gros fichiers qu'un ensemble de fichiers plus petits. C'est une évidence bien souvent oubliée par les personnes établissant les plannings de migration avec des conséquences que tout le monde peut imaginer.
Le gain est par contre très appréciable, surtout lorsqu'on parle de plusieurs dizaines de Tio de données et de plusieurs semaines de transfert. Nous sommes parvenus à effectuer des transferts de données utilisateurs en une semaine au lieu d'un mois tout en pouvant ajuster, en direct, le nombre de rsync en parallèle en fonction des impacts sur la production.
12. Limites
Si la méthode de migration présentée ici a plusieurs avantages, elle a aussi quelques limites et inconvénients. Les voici.
La plus importante des limites de cette méthode est sans doute qu'elle nécessite un accès POSIX (à travers la couche VFS) au système de fichiers source. Cette limite peut sembler anodine mais, en pratique, elle peut s'avérer très ennuyeuse. Nous l'avons constaté avec les serveurs Sunfire. Ces serveurs hébergent des espaces projets (ils sont nombreux) demandés par nos utilisateurs. Dans l'idée d'en simplifier l'administration, nous avons pris l'habitude de créer un système de fichiers (ZFS) par espace. Ces systèmes de fichiers sont tous imbriqués au sein d'un système de fichiers parent. Si cette pratique nous a satisfait tout au long de la vie des serveurs, la migration de ces machines a été rendue très compliquée par la présence de ces nombreux systèmes de fichiers. Nous avions initialement pensé exporter le système de fichiers racine pour migrer les données depuis celui-ci ; malheureusement, ceci n'est pas possible avec NFSv3. En effet, NFS dans sa version 3 exporte un système de fichiers à la fois : le serveur NFS ne traverse pas les frontières du système de fichiers exporté. Ainsi, l'export initial ne contenait que des répertoires vides, ceux-ci correspondant aux points de montages des systèmes de fichiers enfants sur le serveur ! Il nous a finalement fallu exporter un par un les systèmes de fichiers de la machine, en prenant soin de ne pas en oublier. Ici, la mise en place d'un serveur rsync (qui, lui, aurait pu gérer au sein d'un seul export la totalité des systèmes de fichiers) aurait pu nous éviter ce travail d'export fastidieux, mais ceci aurait été au détriment de l'utilisation de fpart et nous aurait obligé à repasser à une synchronisation unique.
Nous aurions certainement pu mettre au point une solution hybride : parcours initial des fichiers via NFS puis synchronisation depuis les nœuds via le protocole rsync, mais cette solution nous a semblé inutilement complexe et risquée : en multipliant les types d'accès, nous augmentons d'autant les risques d'erreurs d'accès aux données (par exemple à cause de noms de fichiers gérés avec des encodages différents entre NFS et rsync). De plus, ceci nous aurait juste évité d'effectuer les montages NFS sur les nœuds du cluster : il aurait tout de même fallu mettre au point les exports et les monter sur la tête de soumission.
Pour permettre la migration, les exports sont faits en no-root-squash. Attention aux idées reçues : ce qui est risqué ici n'est pas de positionner cette option, car un utilisateur malveillant pourra, dans tous les cas et s'il a accès au compte root, prendre l'identité de sa victime pour accéder à ses données ; non, le vrai risque réside dans la mise à disposition elle-même des données sur le cluster. Nous avons limité les risques en dédiant des machines du cluster à la migration (elles ne sont plus accessibles aux autres utilisateurs). Il convient également de s'assurer qu'elles sont bien à jour et de maîtriser la liste des personnes disposant du droit de passer root.
fpart fait de son mieux pour générer des partitions correspondant aux critères fournis par l'utilisateur. En mode live, l'algorithme est simpliste : fpart parcourt le système de fichiers et clôt la partition une fois le seuil fixé par l'utilisateur atteint. Par « atteint », nous entendons en fait « dépassé », car fpart doit être en mesure de placer tout fichier dans une partition, y compris ceux qui dépassent allègrement les critères spécifiés. Si fpart est exécuté avec une taille limite par partition de 100 Mo et qu'un fichier d'1 Go est trouvé, ce fichier va clore la partition en cours (ou même en constituer une à lui tout seul si par hasard ce fichier était le premier d'une nouvelle partition). On voit bien dans ce cas que les tailles des partitions peuvent être très variables. En mode live les partitions sont donc "à peu près égales" et certains cas dégénérés peuvent déclencher des synchronisations beaucoup plus longues que la moyenne.
Un point à noter est que nous perdons dans notre synchronisation les attributs étendus et les ACL. Nous n'avions pas besoin de les migrer, mais il doit être assez aisé d'adapter la méthode pour les prendre en compte ou bien même les répliquer a posteriori.
Une des pistes d'amélioration de fpart serait de rendre multithread le parcours du système de fichiers. Actuellement, celui-ci est linéaire et repose sur fts(3). Il doit probablement y avoir moyen de gagner du temps à cette étape en s'inspirant d'un projet comme robinhood11 et de résultats comme ceux exposés dans l'article « On Distributed File Tree Walk of Parallel File Systems »12 de Jharrod Lafon du LANL.
À nos yeux, la puissance de fpart réside dans son mécanisme de hooks. C'est lui qui nous a permis d'exploiter de façon transparente l'infrastructure du cluster de calcul. Vous n'aurez sans doute pas trop de mal à les adapter à la vôtre. Néanmoins, dans le cadre très spécifique de la migration de données, un compagnon générique à fpart (GUI, wrapper...) pourrait trouver un plus large public, par exemple afin d'être plus évident à utiliser si l'on n'a pas déjà un gestionnaire de tâches qui pilote un cluster de machines. Pour l'instant, chacun doit écrire une glue spécifique. Rien de complexe, mais c'est plutôt fastidieux comme vous avez pu vous en rendre compte avec l'extrait de script shell exposé plus haut. Pourquoi ne pas aller dans le sens de dcp13 (dont les limites sont évoquées dans l'article de Jeff Layton) qui implémente une file d'attente distribuée via la libcircle14 ? Si l'on souhaite rendre la migration de données aussi simple qu'un cp, cela semble être un axe de développement des plus intéressants.
Conclusion
La méthode présentée dans cet article nous satisfait pleinement. En pratique, nous pouvons lancer notre migration sur une arborescence arbitrairement grande en pleine confiance. L'impact sur les utilisateurs est minimal. Toutefois, il faut garder à l'esprit que la migration des données n'est pas la seule tâche à accomplir pour migrer des serveurs de fichiers. Le transfert des données elles-mêmes est une grande partie du travail, mais il faut également répliquer toutes les méta-données relatives aux espaces migrés, notamment :
- les quotas,
- les politiques de snapshots et de sauvegarde,
- les partages NFS,
- les partages CIFS (en revoyant éventuellement les noms des partages pour éviter les collisions car on passe de plusieurs espaces de noms - plusieurs serveurs - à un seul),
- la configuration des clients (adapter les chemins des partages à monter).
Enfin, selon les cas, il se peut qu'il faille convertir les noms des fichiers eux-mêmes (si les encodages source et destination sont différents). convmv15peut s'avérer très utile dans ce cas.
Malheureusement, ces tâches sont fastidieuses et difficilement automatisables ; nous les avons traitées à la main et au coup par coup, selon les espaces.
Merci aux différents relecteurs qui se reconnaîtront et bonne migration à tous !
1 http://www.admin-magazine.com/HPC/Articles/Moving-Your-Data-It-s-Not-Always-Pleasant
2 http://www.youtube.com/watch?v=FamWy_c95Wo
4 http://rsync.samba.org/FAQ.html#4
5 http://www.f5.com/products/data-solutions/arx/overview/
6 http://rsync.samba.org/ftp/rsync/src/rsync-3.0.0-NEWS
7 http://contribs.martymac.org, http://sourceforge.net/projects/fpart
8 http://fr.wikipedia.org/wiki/Algorithme_glouton
9 http://www.gnu.org/software/parallel
10 http://gridscheduler.sourceforge.net
12 http://www.cs.nmsu.edu/~misra/papers/sc12paper.pdf
14 https://github.com/hpc/libcircle
15 https://www.j3e.de/linux/convmv/man
