

« Les data scientists sont partis et ont laissé un fichier au format HDF5. C'est magique, ça détecte les voitures. Tu crois qu'on peut en faire un outil ? Ça tournerait sur mon Raspberry Pi ? » Dans cet article, nous allons découvrir le format Open Neural Network eXchange (ONNX). Nous allons ensuite coder une petite application en Go dans le but d’exécuter un réseau de neurones sur Raspberry Pi, simplement.
Dans un précédent article, nous avons vu comment créer et entraîner un modèle de réseau de neurones pour faire de la détection d'objets.
Ce modèle renferme la connaissance qui permet de reconnaître une voiture. Mais sans outillage pour l'alimenter, ça reste très peu utilisable.
Je vous propose de partir de la version exportée en HDF5 (format utilisé par Keras) de ce modèle et de dérouler une recette pour construire une petite application simple en mode CLI. Le but de cette application est dire si oui ou non l'image en entrée est une voiture.
La principale contrainte que nous imposons est de faire que le code puisse tourner sans modification sur GNU/Linux et macOS, sur architecture AMD64 et sur ARM (pour l'exécuter sur un Raspberry Pi).
Les ingrédients :
- ONNX : c'est une représentation intermédiaire d'un réseau de neurones. Pas de panique si vous ne connaissez pas, nous allons découvrir ça ensemble.
- Go : ce langage présente pour nous deux avantages :
- Il est compilé statiquement, ce qui facilite les déploiements ;
- Il est Turing complet, et par conséquent, on peut cross-compiler nos programmes pour une autre plateforme que celle sur laquelle on développe.
1. Généralités sur les réseaux de neurones
Avant de nous lancer dans le développement de l'application, je vous propose de rappeler quelques notions sur les réseaux de neurones.
1.1 Les équations sont des graphes
Voyons comment représenter une formule mathématique sous forme de graphe. Prenons par exemple cette équation :
![]()
Réécrivons là dans une forme un peu plus fonctionnelle :
![]()
Une représentation sous forme de graphe devient plus évidente (voir figure 1).
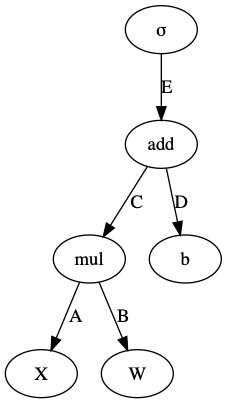
1.2 Un réseau de neurones est un graphe
Un réseau de neurones est une fonction qui prédit une valeur Y en fonction d'une entrée X.
X et Y sont des tableaux à 1, 2, 3… n dimensions ; nous appelons ça des tenseurs.
Un réseau de neurones, c'est donc la fonction f telle que f(X)=Y et comme les équations sont des graphes, nous pouvons décrire un réseau de neurones comme un graphe.
Les éléments du graphe sont soit des opérateurs, soit des tenseurs.
Les valeurs des tenseurs sont en général les paramètres qui vont évoluer au gré des apprentissages de la machine.
Reprenons le model.h5 généré lors de la phase de conception dans l'article précédent, « Keras, l'outil privilégié des data scientists » de S. Rochette et C. Bridon, et affichons son graphe d'exécution (voir figure 2) :
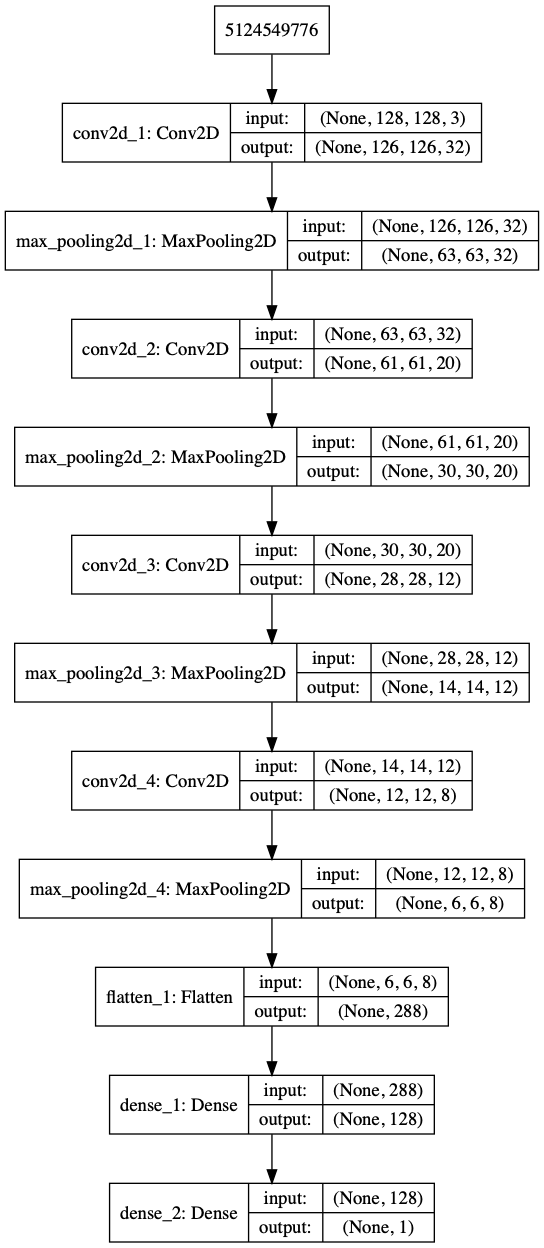
1.3 Un réseau de neurones est un logiciel
Nous venons de voir qu'un réseau de neurones était un graphe composé d'opérateurs et de tenseurs.
Changeons maintenant de paradigme et imaginons maintenant le réseau de neurones comme étant un logiciel [1].
Le programme du logiciel est le modèle ainsi que la valeur des tenseurs qui le composent. Le logiciel est la version compilée de ce modèle, qui contient les instructions que l'ordinateur va exécuter (dans notre exemple, le fichier model.h5 que nous avons généré).
Pour exécuter ce programme, il faut une machine. Pour coder leur logiciel, les data scientists ont utilisé le logiciel Keras. Ensuite, ils ont utilisé TensorFlow, qui agit comme une machine virtuelle qui interprète et exécute le logiciel « réseau de neurones ».
Le problème est que le programme et l'environnement d'exécution sont fortement liés. Ainsi, pour utiliser un programme (réseau de neurones) dans un autre environnement que celui dans lequel il a été conçu, il faut le réécrire.
Pour pallier ce problème, une communauté soutenue par de grands noms tels que Microsoft ou encore Facebook s'est lancée dans un processus de standardisation. Ce standard, ouvert, vise à faciliter l'échange et l'utilisation des réseaux de neurones entre les frameworks.
Ainsi est né Open Neural Network eXchange (ONNX). ONNX n'est autre qu'une représentation intermédiaire [2] (en anglais IR), qui permet de décrire un graphe, ainsi que ses composants (tenseurs et opérateurs). Il permet donc d'écrire un réseau de neurones dans son langage préféré (Keras, Pytorch, etc.), et de le représenter dans une version binaire, exempte des spécificités du langage.
Cette représentation binaire peut être lue par un autre framework dans le but d'être compilée et exécutée.
1.4 ONNX et la dualité graphe logiciel
Nous venons de voir qu'ONNX ne compile pas réellement le graphe, il se contente de le convertir dans un format binaire.
Afin de répondre à la promesse d’ouverture, le mécanisme de sérialisation doit être indépendant de la plateforme, du langage et devait être suffisamment extensible pour décrire des types non standard en informatique, tels que des tenseurs.
Le choix du langage de description s'est porté sur protocol buffers [3] qui remplissait tous les prérequis.
Ainsi donc, ONNX n'est qu'un ensemble de définitions « protobufs » qui permettent de décrire un graphe, les tenseurs et les comportements des opérateurs qui le composent. Les outils natifs protobufs permettent ensuite de sérialiser et désérialiser ce graphe dans un format binaire.
Les spécifications d'ONNX sont disponibles ici : https://github.com/onnx/onnx/blob/master/docs/IR.md.
Transposons à présent le code model.h5 dans une version ONNX, en utilisant la bibliothèque keras2onnx :
Visualisons à présent le model.h5 ainsi que la version ONNX, grâce à l'outil netron [4] (les images de la figure 3 sont générées par la version web).
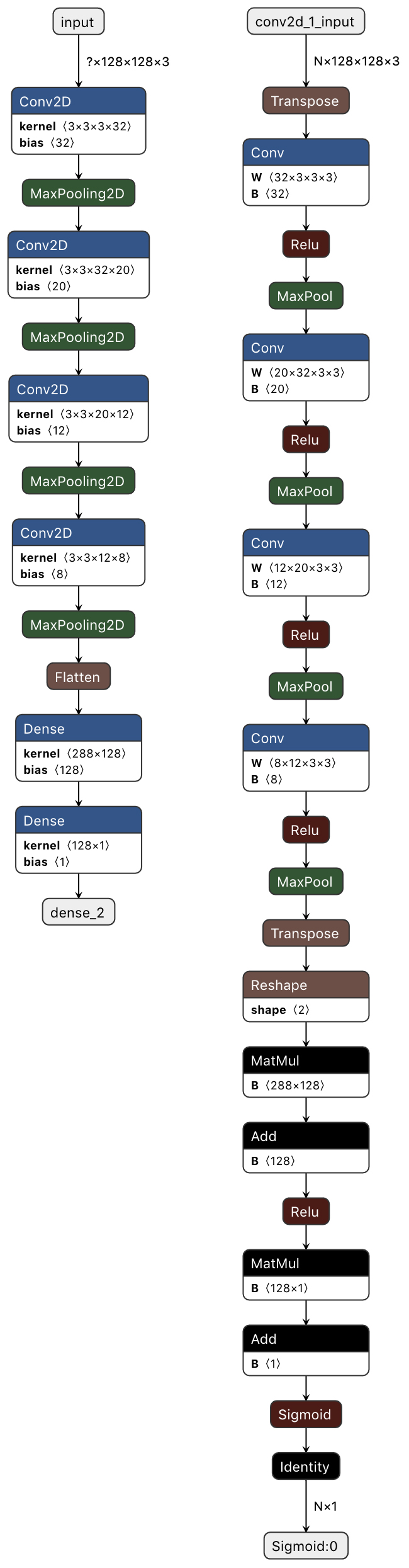
Nous pouvons remarquer que les graphes sont semblables, mais pas identiques. Ces différences n'ont pas d'incidence sur le fonctionnement ; ces différences sont dues à la définition des opérateurs, qui est différente entre Keras et ONNX.
2. Développement d’une CLI pour exécuter le réseau de neurones
Nous disposons à présent d'un réseau de neurones empaqueté en binaire. Ce réseau est le cœur de notre application ; il contient la logique métier. Nous allons désormais construire une application portable, dans le but d'utiliser ce réseau sur un Raspberry PI.
Pour accomplir cette tâche, Go est le parfait candidat. En effet, le langage Go est codé en Go. Par conséquent, il est possible de cross-compiler facilement un programme, pour passer d'une architecture à une autre.
D'autre part, le binaire généré est statique ; c'est-à-dire qu'il ne nécessite pas de dépendances externes à l'exécution ; le binaire embarque tout ce dont il a besoin.
2.1 Importer le fichier ONNX dans le langage Go
ONNX est écrit en protocol buffers (protobufs). Il existe un compilateur officiel protobufs pour Go. Cet outil permet de générer les fonctions de désérialisation, qui vont convertir le binaire ONNX en un objet Go.
Cependant, pour être utilisable, cet objet doit lui-même être transposé dans un système capable de comprendre et d’exécuter le contenu (le graphe). C'est le rôle du package onnx-go [5].
onnx-go est un wrapper autour de la définition protobuf. Il permet de décoder un tableau d’octets ([]byte) contenant un réseau de neurones au format ONNX et de l'instancier dans une structure Go particulière appelée Model.
Le Model est une coquille autour d'une autre structure d'exécution appelée backend. Ce backend est une interface Go.
En programmation orientée objet, une interface est une description des actions qu'un objet est capable de réaliser. Dans le langage Go, une interface est un contrat. Elle décrit les méthodes qu'un élément (par exemple, une structure) doit remplir.
Par conséquent, le backend est une simple description d'un ensemble de méthodes à implémenter par tout objet qui voudrait implémenter le réseau de neurones.
Cette interface décrit un graphe direct acyclique orienté et pondéré en utilisant l'interface DirectedWeightedGraphBuilder [6] du package gonum (cette bibliothèque est équivalente à Numpy dans l'écosystème Python).
Ainsi donc, le code du backend d'exécution est décorrélé de celui du désérialiseur.
onnx-go utilise le même procédé que Keras. Pour le montrer, voici une copie du premier paragraphe de la documentation de Keras, avec une simple substitution de Keras en onnx-go :
« [onnx-go] does not handle low-level operations such as tensor products, convolutions and so on itself. Instead, it relies on a specialized, well optimized tensor manipulation library to do so, serving as the "backend engine" of onnx-go. Rather than picking one single tensor library and making the implementation of onnx-go tied to that library, onnx-go handles the problem in a modular way, and several different backend engines can be plugged seamlessly into onnx-go. »
2.2 Backend d'exécution
Nous avons vu que pour instancier et exécuter le réseau de neurones via onnx-go, il est possible d'utiliser plusieurs backends.
Une initiative est en cours avec TensorFlow, mais elle est hautement expérimentale d'une part et d'autre part, elle utilise la bibliothèque officielle Tensorflow et donc le système cgo. Ceci empêchera d'atteindre notre but de cross-compilation sur le Raspberry.
Nous utiliserons donc le backend qui se base sur Gorgonia, écrit en pure Go. Gorgonia est une bibliothèque qui permet de faire des calculs symboliques et de la différentiation automatique. C'est le TensorFlow du monde Go. D'ailleurs sur un CPU, les performances de ces deux bibliothèques sont semblables.
À noter que Gorgonia dispose de bindings pour utiliser d'autres bibliothèques, telles que CUDA ou Lapack. Cependant, ces bindings utilisent cgo, et comme le dit Dave Cheney : « cgo is not Go ».
Gorgonia n'est pas, pour l'instant [7], compatible directement avec onnx-go. Cependant, un package transitoire gorgonnx se charge d'implémenter l'interface backend d'onnx-go et de les transcrire en langage Gorgonia, pour permettre l'exécution du graphe.
Pour instancier le backend, nous importons donc le package gorgonnx :
Ce code suffit à décoder le format ONNX et à le « compiler » en format Gorgonia.
Le point d'entrée de Gorgonia est également un objet de type graphe nommé ExprGraph.
Il est d'ailleurs possible de visualiser ce graphe de Gorgonia en utilisant les packages d'encodage dot qui sont fournis avec la bibliothèque :
À présent, voyons comment exécuter ce graphe pour qu'il applique le réseau de neurones à notre image.
2.3 Exécution du code et entrées/sorties
Résumons : nous disposons dans notre code Go d'un objet Model. Ce Model contient toutes les informations du réseau de neurones. Par conséquent, il connaît quels sont les nœuds d'entrée et quels sont les nœuds de sortie.
onnx-go propose deux méthodes sur l'objet modèle pour interagir avec les entrées/sorties :
- func (m *Model) GetOutputTensors() ([]tensor.Tensor, error) ;
- func (m *Model) SetInput(i int, t tensor.Tensor) error.
Les éléments de communication de ces méthodes sont de type tensor.Tensor.
Le package tensor fait partie de l'écosystème Gorgonia, mais est indépendant de la bibliothèque de calcul.
Pour passer des données d'entrée à notre graphe, il faut positionner une valeur de tensor.Tensor à chacune de ses entrées référencées par l'entier i.
Notre réseau ne dispose que d'un seul point d'entrée. Par conséquent, il faudra appeler cette méthode de la sorte :
Avec ici inputT un objet de type tensor.Tensor.
2.4 Transformer une image en tensor.Tensor
Nous voulons analyser une image, il faut donc une fonction de conversion de l'image en tenseur.
Le tenseur attendu par notre réseau est de format BHWC (Batch, Height, Width, Channel) qui est un format beaucoup plus efficace que le BCHW quand la cible d'utilisation est un CPU plutôt qu'un GPU (cf. le livre « Go Machine Learning Projects » pour d'avantages d'explications [8]).
Nous allons utiliser une fonction dont la signature est la suivante :
Le contenu de cette fonction n'apportant rien à la présente explication, le code est omis. Il est disponible sur le GitHub du projet dont l'adresse est présente à la fin de l'article.
Cette fonction prend en entrée un io.Reader et attend que ce canal lui fasse parvenir une image au format JPEG ; cette fonction retourne un tenseur qui représente l’image au format adéquat. Nous pouvons à présent assigner une entrée à notre réseau de neurones :
2.5 Exécution du réseau
À présent que nous avons assigné une donnée à évaluer, nous allons pouvoir exécuter le réseau.
C'est le backend qui doit l'exécuter et nous appelons donc sa méthode Run() :
Il ne reste plus à présent qu'à récupérer la valeur de sortie du graphe grâce à la fonction décrite précédemment et à l'afficher :
3. Passage en production
3.1 Premier test sur notre machine de développement
L'ensemble du code est disponible sur le repository GitHub suivant : github.com/owulveryck/ironnx.
Les étapes importantes ont été listées ci-dessus, et les seuls ajouts concernent l'ajout de flags pour transformer le code en application CLI. En dehors des fonctions de traitement d'image, l'ensemble du code se trouve dans la fonction main pour rendre plus simple un éventuel hacking par le lecteur.
Voyons maintenant comment compiler et déployer cette application sur nos architectures cibles :
Nous pouvons alors lancer des prédictions sur les images des figures 4 à 7.


Le code utilise des arguments qui permettent de lire une image et de charger un modèle ONNX différent du modèle par défaut. D’autre part, rien dans le code que nous avons écrit n'est spécifique à ce réseau particulier (en dehors de la taille des images d'entrées). Il est donc possible d'utiliser ce même code pour exécuter une autre version de modèle permettant de détecter par exemple d'autres objets.
3.2 Le but ultime : faire tourner l'utilitaire sur ARM (Raspberry Pi)
Il est à présent possible de cross-compiler ce projet pour qu'il fonctionne sur plateforme ARM. En Go, la cross-compilation se réalise simplement en ajoutant quelques variables d'environnement. Go supporte les architectures cibles ARM suivantes :
|
Architecture |
Status |
GOARM value |
GOARCH value |
|
ARMv4 and below |
not supported |
n/a |
n/a |
|
ARMv5 |
supported |
GOARM=5 |
GOARCH=arm |
|
ARMv6 |
supported |
GOARM=6 |
GOARCH=arm |
|
ARMv7 |
supported |
GOARM=7 |
GOARCH=arm |
|
ARMv8 |
supported |
n/a |
GOARCH=arm64 |
La compilation suivante se réalise sur votre machine de développement (GNU/Linux, Windows ou macOS) :
Ensuite, nous utilisons l'émulateur qemu pour valider notre version en cible ARMv6 (compatible avec la plupart des Raspberry récents) :
Après avoir activé le SSH et transféré le binaire dans la VM, nous pouvons enfin tester :
Victoire ! Le temps de traitement du réseau est de 8 secondes, ce qui n'est pas surprenant du fait du nombre important de calculs à réaliser.
Il est également possible de compiler l'outil pour qu'il fonctionne sur ARMv7 et ARM64, pour tenter d'avoir des versions plus performantes et bénéficier de certaines optimisations :
Nous sommes en mesure d'utiliser notre code, simplement, sur toutes les plateformes ARM récentes et de désormais mettre facilement en production ce réseau de neurones (en uploadant simplement un nouveau fichier model.onnx).
CQFD!
Conclusion
Si nous faisons le parallèle avec le monde Java, nous venons de créer un runtime environment pour exécuter du bytecode. Ce bytecode représente au final un logiciel : le fameux « software 2.0 ».
De plus, cet article a montré une séparation entre la logique métier (le code qui détecte les voitures), le code applicatif (celui qui lit l'image et affiche le résultat) et l'infrastructure d'exécution (le système qui exécute le réseau de neurones). Ce modèle d'architecture s'apparente à de l'architecture hexagonale.
Par conséquent, il est envisageable de transformer l'interface logicielle pour passer d'une application CLI à un web service par exemple, sans modifier la logique fonctionnelle ; nous pouvons créer de nouveaux outils en nous concentrant sur le développement logiciel et non, sur la data science ou le déploiement.
Enfin, un tel web service, faiblement dépendant, pourrait facilement se transformer en une application cloud native (ou knative) pour être hébergée sur les technologies les plus hypes du moment.La promesse « write once, run anywhere » de SUN Microsystem pourrait donc bien revenir à la mode…
Références
[1] A. KARPATHY, « Software 2.0 », novembre 2017 : https://medium.com/@karpathy/software-2-0-a64152b37c35
[2] Wikipedia, « Les représentations intermédiaires en informatique » : https://fr.wikipedia.org/wiki/Langage_interm%C3%A9diaire\#Repr%C3%A9sentation_interm%C3%A9diaire
[3] Documentation officielle de protocol buffers : https://developers.google.com/protocol-buffers
[4] Repository du projet Netron « Visualizer for neural network » qui héberge la version web de l’outil : https://github.com/lutzroeder/netron
[5] Repository GitHub du projet onnx-go : https://github.com/owulveryck/onnx-go
[6] Documentation de l’interface Go Directed Weighted Builder du projet gonum : https://godoc.org/gonum.org/v1/gonum/graph\#DirectedWeightedBuilder
[7] Roadmap de Gorgonia v0.10.0 : bit.ly/2P7pKvq
[8] X. CHEW, « Go Machine Learning Projects », Packt, 2018 : http://bit.ly/2J8xYjp
Pour aller plus loin
Les projets onnx-go et Gorgonia sont en développement actif et sont ouverts aux contributions ; ils sont accessibles aux adresses suivantes :
Vous pouvez dialoguer avec les auteurs des bibliothèques Gonum, Gorgonia et onnx-go sur les channels #deeplearning #data-science et #gorgonia du slack gophers.slack.com.