

Dans un précédent article [1], je vous avais montré comment scraper le contenu de pages HTML, grâce à NodeJS et à quelques packages complémentaires. La technique que j’avais utilisée fonctionnait très bien avec des pages statiques, mais elle se prêtait mal au scraping de pages générées dynamiquement. Pour régler ce problème, je vais vous présenter une alternative, reposant sur le projet Puppeteer, un package NPM très polyvalent.
Dans le hors-série GLMF 114 [1], je vous avais expliqué les bases du web scraping, et nous nous étions amusés à gratter le contenu d’une page de newsletter. Comme je l’indiquais dans l’introduction, la technique que j’avais présentée est parfaite avec des pages statiques (ou générées intégralement côté serveur), mais elle est inapplicable dans le cas de pages web générées dynamiquement, comme on en trouve notamment dans les architectures de types SPA (Single Page Application). En effet, dans ce type d’architecture, certaines portions de page sont générées suite à des actions de l’utilisateur, comme le clic de certaines options (boutons, cases à cocher, etc.). Pour gérer cette difficulté, nous avons besoin d’un outil de scraping capable d’émuler un navigateur, ou mieux encore, capable de faire fonctionner un navigateur dans un mode « bac à sable », de manière à prendre le contrôle de la navigation via du code. C’est précisément ce que permet de faire le projet Puppeteer (en anglais marionettiste).
1. Le tour du propriétaire
1.1 Présentation de Puppeteer
Au cas où vous n’auriez pas lu mon précédent article [1], je rappelle brièvement que faire du web scraping, cela consiste à télécharger des pages web et à en extraire de l’information.
Concrètement, le projet Puppeteer est un package Node.js qui permet de piloter une instance de Chromium dont nous allons prendre le contrôle via du code JavaScript. Le concept est très puissant, car il nous permet de faire beaucoup de choses, telles que :
- automatiser de nombreuses tâches, dont la soumission de formulaires et la surveillance de données en ligne ;
- parcourir les pages de tout type d’application web, soit en vue de les tester, soit en vue d’en extraire du contenu (donc de faire du web scraping, on y revient). On va le voir, Puppeteer s’adapte particulièrement bien au parcours d’application de type SPA (Single Page Application) ;
- générer du contenu prérendu, dans le cadre d’une architecture de type SSR (Server-Side Rendering) ;
- générer des captures d’écran et des PDF à partir de pages web ;
- capturer une trace chronologique d’un site pour aider à diagnostiquer des problèmes de performance ;
- tester des extensions Chrome ;
- etc.
On notera que le projet est développé et maintenu par Google.
Comme Puppeteer utilise Chromium sous le capot, il couvre l’essentiel des besoins en matière de tests d’interface utilisateur. Mais attention, Chromium c’est la partie open source de Chrome, donc Puppeteer n’a pas accès aux codecs propriétaires (pour le son et la vidéo). Puppeteer s’appuie sur le protocole DevTool de Chrome (et Chromium) pour accéder aux entrailles du navigateur et prendre le contrôle de la navigation. Mais je vous rassure, c’est transparent, car Puppeteer simplifie beaucoup de choses.
1.2 Installation de Puppeteer
L’installation se fait très simplement sous Node.js :
On notera qu’il est possible d’installer puppeteer-core, une alternative à Puppeteer, développée aussi par Google :
- l’installation de Puppeteer a pour effet de télécharger une version de Chromium, pilotée par des composants de puppeteer-core (qui fait partie des dépendances du package). Puppeteer implémente des variables d’environnement PUPPETEER_* qui sont très pratiques pour modifier son comportement ;
- puppeteer-core est une bibliothèque qui aide à piloter tout ce qui supporte le protocole DevTools. puppeteer-core ne télécharge pas Chromium une fois installé. En tant que bibliothèque bas niveau, puppeteer-core est entièrement piloté par son API et ignore toutes les variables d’environnement PUPPETEER_*.
En résumé, Puppeteer est livré « clé en main », prêt à répondre à vos différents besoins, tandis que puppeteer-core est plus complexe à mettre en œuvre, et sera réservé à des usages très spécifiques (si vous voulez l’utiliser directement). On va se focaliser sur Puppeteer dans la suite de l’article.
1.3 Premiers tests
Dans l’article que j’avais publié dans le hors-série n° 114 [1], je vous avais montré comment scraper la page d’une newsletter pour en extraire quelques paragraphes de texte et une image. Nous allons voir dans un instant comment faire la même chose avec Puppeteer.
Mais tout d’abord, voici le squelette de base d’un script Puppeteer :
Le script ci-dessus instancie Chromium en mode headless, ce qui signifie que vous ne verrez pas la fenêtre du navigateur apparaître lors de l’exécution du script, même si elle est bien active dans les coulisses. Si vous voulez voir le navigateur apparaître, il vous suffit de dé-commenter la première ligne utilisant la commande puppeteer.launch, et de commenter la suivante :
Dans quel cas pourrait-on avoir besoin de faire apparaître le navigateur ? Cela peut être utile de tester votre script et de vous assurer visuellement que le navigateur suit bien la navigation que vous aviez prévue. Cela peut être utile également pour prendre la main sur certaines étapes de la navigation, si vous souhaitez interagir vous-même avec certains formulaires. Puppeteer vous permettra ainsi d’éviter certaines étapes répétitives et fastidieuses de la navigation, pour vous rendre plus rapidement sur la partie que vous souhaitez tester manuellement.
Nous avons vu un exemple de script très simple, dans lequel on se contente de récupérer le contenu HTML d’une page, et de l’envoyer dans la console. C’était intéressant pour débuter, mais voyons plutôt comment générer une copie d’écran et un fichier PDF à partir d’une même page :
Dans l’exemple ci-dessus, j’ai pris pour cible la newsletter de l’éditeur Manning qui, dans sa version du 21 janvier, présentait la machine analytique de Babbage. J’ai utilisé les fonctions page.screenshot et page.pdf pour générer une copie d’écran au format PNG et un fichier PDF. Tous deux sont générés dans un sous-répertoire output que vous prendrez soin de créer avant d’exécuter le script. Vous verrez après exécution que les sorties obtenues sont de très bonne qualité, et pour cause, c’est Chromium qui les a produites.
Vous noterez que dans l’instruction page.goto, j’ai utilisé l’option waitUntil, avec le paramètre domcontentloaded. Je reviendrai plus en détail, ultérieurement, sur les paramètres acceptés par page.goto.
Dans le hors-série n° 114 [1], je grattais le contenu d’une page de newsletter en récupérant plusieurs paragraphes de texte et le lien vers une image. Pour rappel, le contenu que je souhaitais récupérer se présentait tel que sur la figure 1.

Pour récupérer les éléments du DOM (Document Object Model) qui m’intéressaient, j’avais utilisé un petit package très pratique qui s’appelle jsdom. Je l’avais sélectionné, car il était proche dans son fonctionnement des API querySelector et querySelectorAll, que j’utilise généralement pour travailler avec le DOM du navigateur. Avec Puppeteer, nous n’avons pas besoin de package complémentaire (comme jsdom), car l’objet document est présent nativement, sachant que nous travaillons avec une instance de navigateur.
Pour utiliser les API querySelector et querySelectorAll, on doit passer par la fonction page.evaluate et par sa fonction de callback :
À l’intérieur de la fonction de callback, notre code s’exécute dans le contexte du navigateur, ce qui nous permet d’utiliser l’objet document et ses nombreuses propriétés et méthodes. On peut dès lors manipuler le DOM, comme on le ferait dans un navigateur classique, ce qui nous permet d’extraire les nœuds qui nous intéressent, comme dans l’exemple suivant :
Je dois souligner qu’à l’intérieur de la fonction de rappel, nous ne pouvons pas envoyer d’informations vers la console, car elles seraient transmises à la console du navigateur, et pas dans le terminal de Node.js. Si vous avez besoin de conserver des traces d’exécution, je vous invite à passer par un objet déclaré en amont de la fonction page.evaluate, que vous alimenterez selon vos besoins, pour pouvoir l’exploiter ultérieurement.
Voici le script complet me permettant de scraper le contenu de la newsletter :
En sortie, on obtient les données suivantes (j’ai tronqué le contenu de la propriété story, car il était un peu long) :
1.4 Approfondissement
Dans les exemples que je vous ai présentés, nous avons utilisé abondamment les méthodes async et await. Il aurait été possible d’écrire la même chose avec des Promises, ce qui donnerait ce genre de code :
Dans des cas simples comme ceux que nous venons de voir, cela pourrait aller, mais dans des cas nécessitant une navigation plus complexe, le code deviendrait vite confus et difficile à maintenir. C’est pourquoi la plupart des exemples relatifs à Puppeteer que vous trouverez sur le Web utilisent massivement async et await.
Nous avons vu que Puppeteer s’exécute en mode headless par défaut, et que l’on peut facilement désactiver ce mode pour faire apparaître le navigateur. Dans ce cas, on peut jouer sur certains paramètres pour redéfinir la taille de la fenêtre. Pratique quand on souhaite prendre la main sur certaines étapes de la navigation :
On notera qu’il est possible de redimensionner le viewport en cours de route, avec le code suivant :
On peut transmettre d’autres paramètres à la fonction puppeteer.launch. On peut par exemple demander à ce que le navigateur ouvre automatique la fenêtre relative aux outils de développement (l’équivalent d’un <F12> automatique). Cela se fait via le paramètre devtools. On peut aussi activer le paramètre dumpio, ce qui nous permet d’utiliser le mode débogage. On peut aussi forcer le chemin d’accès au navigateur avec le paramètre executablePath, et lui transmettre des paramètres optionnels avec le paramètre args. Je vous fais un prix de gros avec l’exemple (fictif) suivant :
Autre astuce très pratique : on peut ralentir la navigation avec la propriété slowMo (valeur exprimée en millisecondes). Cela évite de déclencher des timeouts intempestifs, notamment quand certaines requêtes Fetch sont trop lentes. Cela m’a rendu service dans un cas que je vous présenterai dans la suite de l’article :
Avant de poursuivre, sachez qu’une documentation très détaillée des API fournies par Puppeteer existe [2]. Elle est un peu ardue à lire, mais elle contient pas mal d’exemples intéressants.
1.5 De l’art de se simplifier la vie
Dans les outils de développement de Chrome, il y a une fonction un peu cachée qui s’appelle Recorder. Elle est dédiée à la génération de scripts Puppeteer. Pour activer cette fonctionnalité, il faut cocher la case correspondante dans les options du navigateur (figure 2).
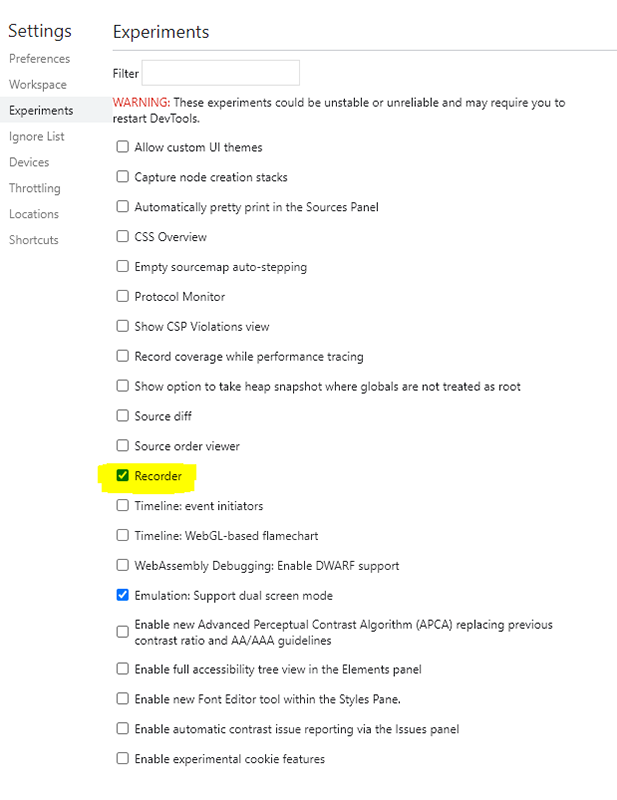
Avertissement : Je crois me souvenir que l’option Recordings n’apparaît dans les menus qu’après redémarrage du navigateur. Donc si vous ne la retrouvez pas dans ce qui suit, ne cherchez pas plus loin, relancez le navigateur, cela devrait régler le problème.
Rendez-vous maintenant sur votre page cible. Placez-vous dans les outils de développements (touche <F12>), allez dans l’onglet Sources, et pour finir, dans l’onglet Recordings (figure 3).
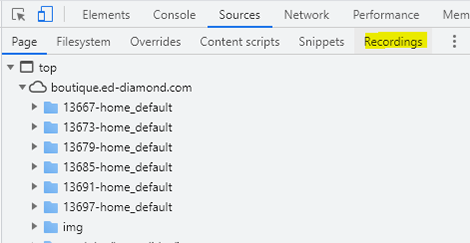
Dans la fenêtre Recordings, vous allez pouvoir créer de nouveaux enregistrements (figure 4). Cliquez d’abord sur l’option Add recording, puis sur le bouton Record un peu plus bas à droite (ou faites <Ctrl> + <E>).

Le bouton Record est maintenant de couleur rouge, l’enregistrement est en cours...
Naviguez sur la page de votre choix, cliquez sur quelques boutons et/ou saisissez quelques valeurs dans un formulaire si vous en avez un, puis stoppez l’enregistrement en recliquant sur le bouton Record, qui va repasser en noir (ou faites <Ctrl> + <E>).
Votre code source Puppeteer est généré, vous n’avez plus qu’à le copier-coller vers votre éditeur de code préféré, pour le réutiliser ultérieurement.
1.6 De l’art de bien naviguer
Nous avons vu pas mal de commandes Puppeteer, mais il nous manque quelques fonctions essentielles, à savoir celles qui permettent de simuler la navigation d’un utilisateur.
Je vous propose un tour d’horizon, en commençant par les fonctions les plus fréquemment utilisées.
Nous avions vu brièvement la fonction goto avec l’exemple suivant :
L’option waitUntil peut recevoir les paramètres suivants :
- load : considère que la navigation est terminée quand l'événement load est déclenché ;
- domcontentloaded : considère que la navigation est terminée quand l'événement DOMContentLoaded est déclenché ;
- networkidle0 : considère que la navigation est terminée lorsqu’il n’y a pas plus de 0 connexion réseau pendant au moins 500 ms ;
- networkidle2 : considère que la navigation est terminée lorsqu’il n’y a pas plus de 2 connexions réseau pendant au moins 500 ms.
On peut aussi transmettre un tableau contenant plusieurs des paramètres ci-dessus, comme ceci :
La fonction type permet d’injecter une valeur dans un champ de formulaire :
Il est possible de définir un délai optionnel, pour simuler la vitesse de saisie d’un utilisateur humain. Le délai appliqué entre la saisie de chaque caractère est exprimé en millisecondes :
La fonction click est sans ambiguïté :
Cette fonction accepte elle aussi des paramètres optionnels :
- button : peut être défini à left (valeur par défaut), right ou middle ;
- clickCount : définit le nombre de fois qu’un élément doit être cliqué (la valeur par défaut est 1) ;
- delay : définit le nombre de millisecondes entre chaque clic (la valeur par défaut est 0).
La fonction focus permet, comme son nom l’indique, de mettre le focus sur un élément du DOM, comme par exemple un champ de formulaire :
Les fonctions goBack et goForward permettent respectivement de reculer et d’avancer dans l’historique de navigation :
La fonction hover permet de déclencher un événement de type mouseover sur un élément du DOM :
Puppeteer met à disposition un jeu de fonctions d’attente, adaptées à différents contextes. Ces fonctions commencent toutes par waitFor :
- waitForSelector ;
- waitForNavigation ;
- waitForFunction ;
- waitForRequest ;
- waitForResponse ;
- waitForXPath.
Jusqu’ici, je me suis surtout servi des deux premières fonctions (waitForSelector et waitForNavigation).
On utilise waitForSelector pour isoler un élément du DOM sur lequel on souhaite par exemple déclencher un clic de souris :
Dans le cas de waitForNavigation, je me suis aperçu qu’en la plaçant après un clic, elle me permettait dans certains cas d’empêcher l’apparition de l’erreur suivante : « Execution context was destroyed, most likely because of a navigation ».
Mais ce n’est pas systématique, à apprécier au cas par cas :
Nous avions vu que la fonction goto accepte un certain nombre de paramètres complémentaires, via l’option waitUntil. Eh bien, les fonctions waitFor acceptent aussi cette même série de paramètres :
En cas de doute sur l’utilisation de l’option waitUntil, je vous encourage à fouiller dans la documentation officielle [2]. En effectuant une recherche dans cette documentation, vous trouverez facilement toutes les fonctions acceptant l’option waitUntil (et beaucoup d’autres choses encore).
On notera aussi que la fonction waitForSelector accepte un paramètre optionnel visible, ce qui est intéressant quand un élément du DOM est généré dynamiquement :
Sans surprise, la fonction reload permet de déclencher un rechargement de page :
Nous avions déjà vu dans un exemple la fonction evaluate, qui permet de renvoyer une valeur extraite d’un élément du DOM :
... ou une série de valeurs :
La fonction evaluateHandle est une variante qui renvoie un nœud du DOM en sortie (plutôt que des valeurs) :
La fonction setContent permet de forcer un contenu HTML spécifique, on peut l’utiliser ensuite pour produire une image PNG ou un document PDF, comme dans l’exemple suivant :
On peut utiliser aussi cette technique pour forcer un contenu HTML avec des valeurs erronées, en vue de contrôler si la gestion d’erreurs que l’on a implémentée fonctionne correctement.
Nous avons vu que la fonction evaluate permet d’accéder à des éléments du DOM via l’objet document. Mais il y a des situations dans lesquelles on souhaite connaître la valeur de certains éléments, sans nécessairement passer par la fonction evaluate. On peut dès lors utiliser les fonctions page.$eval et page.$$eval.
La fonction page.$eval accepte deux paramètres ou plus. Le premier paramètre est un sélecteur (qui utilise en interne la méthode querySelector), le second une fonction de rappel (callback). S’il y a des paramètres complémentaires (trois ou plus), ils sont utilisés comme paramètres d’entrée de la fonction de rappel.
La fonction page.$$eval fonctionne sur le même principe que sa cousine, mais elle utilise querySelectorAll en interne. Elle permet donc d’extraire et de manipuler des séries de valeurs :
À noter que j’ai emprunté les deux exemples précédents au site internet Tabnine [3], qui propose pas mal de snippets intéressants autour de Puppeteer, entre autres.
Dans cette rapide présentation, je me suis efforcé de parcourir les fonctions les plus courantes, celles que vous avez toutes les chances d’utiliser pour du web scraping. Ce n’était pas une présentation exhaustive, loin de là, car Puppeteer est un outil très puissant qui peut répondre à des problématiques variées. Aussi, je vous encourage vivement à parcourir la documentation officielle [2], si ce que je vous ai présenté ici ne répond pas parfaitement à votre besoin.
2. Mini-étude de cas
Pour illustrer certains des points que nous venons d’aborder, j’ai choisi pour cible un site internet fonctionnant selon une architecture de type SPA. C’est le site officiel du framework P5.js [4], framework qui, comme chacun sait, est le petit frère du projet Processing.
Sachant que la page Reference du site regroupe l’essentiel de la documentation de P5, et sachant que cette page met la plupart du temps 1 à 2 secondes pour s’afficher, je me suis dit que cette page constituait un bon terrain de jeu.
J’ai commencé par utiliser l’outil Recorder embarqué dans Chrome. Avec cet outil, j’ai simulé une navigation dans laquelle je clique sur l’option de menu correspondant à la page Reference, de manière à faire apparaître son contenu. Mon objectif est de récupérer le contenu HTML spécifique à cette page, contenu dont je rappelle qu’il est généré dynamiquement.
J’ai récupéré le code JavaScript généré par l’outil Recorder et j’ai tenté de le faire fonctionner dans mon environnement de développement. J’ai constaté que le script n’était pas en mesure de fonctionner en l’état, et j’ai été obligé de procéder à de légères modifications. Je me suis heurté à un problème épineux, mais intéressant : quoi que je fasse, l’affichage du contenu de la page Reference s’affichait toujours trop tard, et je ne parvenais jamais à récupérer le contenu de la page souhaitée. Après de nombreuses tentatives, je me suis aperçu que je pouvais régler le problème grâce au paramètre slowMo qui est déclaré dans la fonction puppeteer.launch :
En effet, c’est seulement en ralentissant la navigation que j’ai pu faire fonctionner correctement mon script de scraping. Je vous avoue que c’est la première fois que je suis confronté à ce problème, qui est peut-être très spécifique à ce site.
En tout cas, je vous donne ci-dessous le code source complet du script de scraping. Vous verrez que j’utilise deux manières différentes pour extraire le contenu de la page Reference :
Conclusion
Dans cet article, j’ai essayé de vous présenter un tour d’horizon des possibilités de Puppeteer dans le contexte du web scraping. L’outil est relativement simple à prendre en main, mais il est très puissant et peut vous accompagner dans de nombreux usages. Vous pouvez par exemple l’utiliser pour développer des tests. Si cet autre sujet vous intéresse, je vous invite à lire également l’article de Gabriel Zerbib publié dans GNU/Linux Magazine n°232 [5].
Références
[1] G. JARRIGE, « Web scraping avec Node.js », GNU/Linux Magazine n°114, mai 2021 :
https://connect.ed-diamond.com/GNU-Linux-Magazine/glmfhs-114/web-scraping-avec-node.js
[2] Documentation de l’API : https://github.com/puppeteer/puppeteer/blob/main/docs/api.md
[3] Tabnine : https://www.tabnine.com/code/javascript/functions/puppeteer
[4] P5.js : https://p5js.org/
[5] G. ZERBIB, « Automatiser les tests end-to-end en PHP », GNU/Linux Magazine n° 232, décembre 2019 :
https://connect.ed-diamond.com/GNU-Linux-Magazine/glmf-232/automatiser-les-tests-end-to-end-en-php