

Le monde du développement logiciel a évolué vers la fin des années 2000 en introduisant de l’automatisation et de la supervision partout où cela était possible (sous la bannière du DevOps). Les outils et principes permettant de livrer du code de meilleure qualité plus rapidement ont été réutilisés pour la gestion des infrastructures informatiques (Infrastructure as Code). En septembre 2020, Anton Chuvakin a proposé sur son blog l’expression « Detection as Code » [1] pour décrire la même transformation appliquée à la détection d’incident de sécurité des systèmes d’information. Nous allons voir ci-après quels avantages on peut tirer de la Detection as Code et comment la mettre en place avec pragmatisme.
1. Pourquoi cela va changer vos capacités de détection ?
1.1 Quel est le problème ?
Les systèmes de détection actuels reposent principalement sur un outil de supervision (un SIEM ou un EDR par exemple) et des règles de détection. Celles-ci sont des requêtes sur les journaux d’événements permettant de mettre en lumière des comportements supposés malveillants. Elles sont exprimées dans le langage de l’outil par des concepteurs, responsables de leur ingénierie et guidés par l’analyse de risque du système d’information à superviser : si on redoute une exfiltration de données, on va se concentrer sur les accès aux données et leur sortie du système d’information.
Pour identifier si les risques sont bien couverts, il est nécessaire de maintenir une synthèse de la couverture des risques assurée par les règles en place. Chaque règle permet de couvrir partiellement ou totalement un risque sur le périmètre supervisé ; quand une règle est ajoutée, modifiée ou supprimée, ma couverture évolue également. Maintenir manuellement une vision à jour de la couverture des risques est une opération fastidieuse et prône aux erreurs humaines.
Les règles déployées sur les systèmes de détection doivent suivre un processus qualité − après tout, une règle qui ne fonctionne pas ne sert à rien − appliqué par les concepteurs. Une inattention de la part de ces derniers et la semaine suivante, la société qui les emploie est la nouvelle victime du dernier rançongiciel en vogue.
Les fournisseurs de services managés de sécurité (MSSP) mutualisent les règles qui peuvent servir à plusieurs de leurs clients. Pour cela, ils utilisent une base centralisée des règles de détection. Un certain nombre d’opérations sont relativement coûteuses : le comparatif de ce qui est dans la base et ce qui est déployé sur le système de détection (pour voir les règles qui sont rapidement déployables, les mises à jour existantes, les règles qui n’auraient pas été capitalisées dans la base).
Un des fléaux actuels du domaine de la sécurité des systèmes d’information est le manque de ressources qualifiées. Les besoins sont de plus en plus nombreux et de plus en plus urgents à traiter, les enjeux grossissent, mais les ressources disponibles pas suffisamment. Les équipes sont surchargées, les projets prennent du retard, les coûts s’envolent : il est nécessaire de produire plus avec autant de personnes.
Si vous partagez certains de ces constats, vous trouverez dans cet article une approche très inspirée du DevOps permettant d’y répondre.
1.2 Le DevOps : principes de base
Le DevOps est un mouvement d’ingénierie informatique visant à améliorer les performances des équipes et la qualité des productions en rapprochant les équipes de développement logiciel (dev) et celles de gestion des infrastructures (ops). On obtient ces améliorations principalement grâce à un changement de culture qui apporte entre autres de l’automatisation aux processus de validation, d’intégration ou de déploiement.
Trois phases sont la plupart du temps présentes :
- l’intégration continue, abrégée CI pour Continuous Integration. On y retrouve généralement les tests de non-régression ;
- la livraison continue, abrégée CD pour Continuous Delivery. C’est la préparation du code pour qu’il soit prêt à être déployé (assainissement, compilation, empaquetage) ;
- le déploiement continu, abrégé CD également (oui, comme pour la livraison, c’est la vie) pour Continuous Deployment. C’est la phase de déploiement sur les différents environnements (notamment la fameuse production).
1.3 Quels gains pour un système de détection ?
On peut appliquer la même évolution à la conception de règles de détection. Nous avons l’avantage de pouvoir bénéficier des retours d’expérience du monde du développement logiciel et profiter des outils de qualité qui sont pour beaucoup disponibles gratuitement.
1.3.1 Qualité
Les règles de détection peuvent être de meilleure qualité grâce à l’automatisation des tests et l’accès pour les concepteurs à des informations de fonctionnement rapidement. Imaginez que − dès la fin de la rédaction d’une règle − sa syntaxe et les métadonnées qui lui sont associées sont validées, on vous indique les alertes qu’elle générerait sur des événements témoin, et les impacts sur les ressources du SIEM, qu’elle s’exécute seule ou avec toutes les autres règles de la base.
Les capacités de travail collaboratif comme la validation des modifications par un collègue plus expérimenté ou la possibilité de commenter chaque ligne de « code » de vos règles fluidifient et structurent les échanges techniques. Chaque modification étant sauvegardée, on peut accéder à l’historique complet des modifications qui ont eu lieu sur une règle et aux commentaires associés (qui peuvent contenir les raisons de ces modifications avec un peu de rigueur).
Enfin, la normalisation des processus de création et modification des règles de détection permet d’avoir une consistance dans la forme de ces dernières et du niveau d’exigence de qualité du livrable.
1.3.2 Visibilité sur les capacités de détection
La centralisation et normalisation des éléments de configuration du système de collecte, des paramètres du SIEM, des règles de détection et des scénarios offensifs permettent de générer différentes visualisations très utiles pour la présentation des capacités de détection. Une fois l’automatisation mise en place, on peut instantanément répondre à des questions telles que « suis-je en capacité de détecter telle menace ? » ou « est-ce que les risques principaux identifiés pour mon SI sont couverts ? ».
1.3.3 Améliorer la productivité des services de détection
Les équipes de détection souffrent d’une rareté des profils ; adopter un mode de fonctionnement DevOps aide en facilitant la concentration des efforts sur le métier : plus besoin de faire des copier/coller, des inventaires ou des comparaisons entre d’anciennes versions d’une même règle. L’automatisation nous permet d’éviter la fatigue de l’opérateur aux équipes de conception en supprimant les tâches rébarbatives.
Un autre gain observable est la facilité pour réutiliser les règles ou moyens de déploiement créés pour un système sur un autre : il y a un investissement initial qui est largement compensé par l’efficacité à reproduire le travail fait pour un autre périmètre.
2. Comment mettre tout ça en place à moindre coût ?
2.1 Préparer le terrain
L’automatisation des processus nécessite une normalisation des données. En effet, si vous voulez générer automatiquement une matrice ATT&CK [2] de couverture des techniques offensives pour l’ensemble des règles de votre base, vous avez besoin d’accéder algorithmiquement à ces techniques pour chaque règle. Il vous faut donc normaliser comment une technique est représentée et définir comment on accède aux techniques couvertes pour une règle. Coup de bol, ça a déjà été fait dans le projet en source ouverte Sigma [3] et beaucoup d’autres − ATT&CK se plaçant dorénavant comme un référentiel incontournable.
Si Sigma ne répond pas à vos besoins, définissez votre propre modèle de données en gardant en tête les points suivants :
- il doit être représenté dans un format textuel comme yaml ou toml par exemple ;
- il doit avoir un schéma clairement défini, ce qui permet la validation des données. On y retrouve différentes métadonnées (un identifiant, un nom, des typologies, un état, des dépendances, des instructions de déploiement, etc.) ;
- définissez un champ permettant de le faire évoluer (une version pour votre modèle, vous vous remercierez plus tard).
Normalisez également les champs qui apparaissent dans vos alertes, ça vous permettra d’uniformiser les traitements que vous faites dessus.
La partie centrale de votre règle, la requête qui va s’exécuter dans le SIEM, peut être exprimée dans un métalangage (comme Sigma) ou directement dans le langage de votre SIEM.
2.2 Base centralisée de règles
Maintenant que nous avons défini des contraintes sur nos règles de détection, nous avons besoin d’un support pour les capitaliser. Pour cela, il nous faut une base de données gardant un historique, la possibilité d’avoir des métadonnées et permettre d’y associer un suivi des évolutions (l’attacher à un système de tickets). GitLab [4] est une plateforme s’appuyant sur Git (l’outil de référence pour la gestion des versions de code) et de la conteneurisation pour supporter les opérations d’intégration et de déploiement continu. Elle peut être hébergée par vos soins et la version gratuite est amplement suffisante pour répondre à nos besoins.
Les opérations courantes de Git nous permettent de couvrir un grand nombre de nos cas d’usage. Le développement d’une nouvelle règle de détection se fait dans une branche dédiée, que l’on intègre à la branche principale une fois celle-ci satisfaisante (par exemple après la relecture d’un pair et la validation d’un senior).
2.3 Organiser votre base
Si ça n’est pas déjà fait, définissez un processus décrivant le cycle de vie de vos règles. Quels états existent pour vos règles ? Sigma utilise experimental, testing et stable par exemple. Comment est-ce que ces états évoluent, sous quelles conditions ? Tout n’étant pas forcément automatisable − on ne peut pas encore se passer de l’humain, Skynet c’est pour plus tard − pour assurer de la qualité n’oubliez pas d’inclure une étape de relecture. Ce processus va également alimenter le modèle de donnée défini dans la section 2.1.
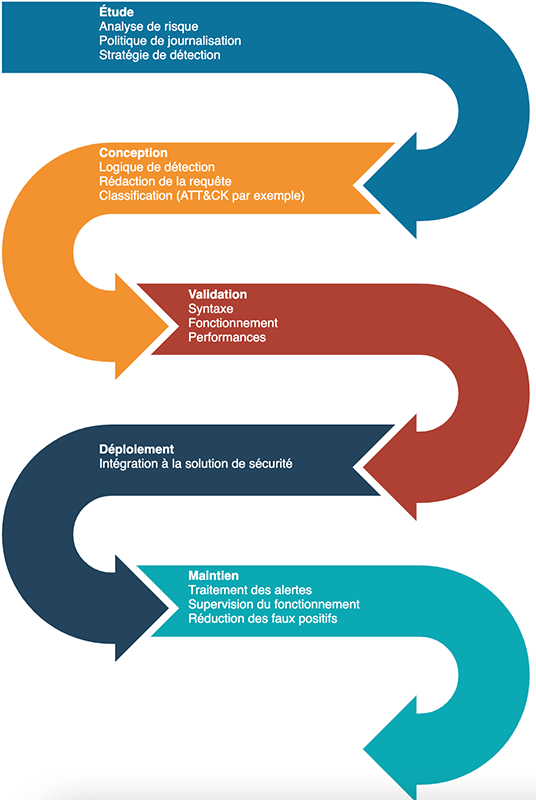
Déclinez ensuite votre processus dans des issue template de GitLab : pour créer une nouvelle règle, en modifier une existante ou changer son état, on utilise des modèles spécifiques qui accompagnent les équipes à suivre le processus. Une modification du processus s’accompagne d’une mise à jour de ces modèles.
Utiliser des issues pour les évolutions assure une traçabilité et des explications des modifications. Quand dans trois ans vous vous demanderez pourquoi un paramètre a changé dans une règle, GitLab vous indiquera tout le contexte de l’époque, qui a travaillé sur le sujet, qui a validé les modifications et toutes ces informations à la seconde près !
2.4 Exploitez la donnée
Le gain au niveau de l’historique des modifications et du contexte est déjà précieux, mais ça n’est que la partie émergée de l’iceberg. Les efforts de rigueur dans les processus et de normalisation de la donnée sont largement compensés par l’intégration continue et le déploiement continu. Dans GitLab, à travers les fonctionnalités de CI/CD on peut automatiser trois phases inspirées du monde du développement logiciel : les tests, la préparation et le déploiement.
Durant la phase de test, vous pouvez valider le bon remplissage des données en accord avec le modèle de données que vous avez défini précédemment. Si vous avez dans les métadonnées un champ listant les dépendances nécessaires au bon fonctionnement d’une règle par exemple, vous pouvez valider l’existence des dépendances en question.
Il est également possible d’effectuer des tests fonctionnels. Vous pouvez exécuter la règle sur un SIEM de test et remonter les erreurs éventuelles d’exécution et les impacts sur les performances. Attention, pour la mise en place de ces tests, vous aurez besoin d’infrastructures réutilisables, ça peut représenter une forte charge de travail si vos infrastructures ne sont pas capitalisées as code. Le projet CALDERA [5] de MITRE permet d’automatiser des comportements offensifs sur un système d’information.
La phase de préparation consiste à transformer vos règles disponibles dans votre base en un format utilisable par votre SIEM : ne conserver que les règles activées, dans le cas de Sigma, utiliser sigmac pour formater la requête, générer des paramètres spécifiques au SIEM, etc.
Enfin, lors de la phase de déploiement, vous poussez les règles vers le SIEM et autres systèmes. N’essayez pas de mettre en place un système de mise à jour des règles en place à moins d’avoir une bonne raison de le faire. Envoyez toutes les règles en réécrivant ce qui est déjà en place pour rester synchrone avec la base. Ce point est primordial, c’est ce qui assure la cohérence entre la base et ce que vous avez sur vos systèmes en production. Dans les autres systèmes, on peut trouver votre Business Intelligence, un rapport synthétique, une matrice ATT&CK de couverture des capacités, etc. Tout élément exploitant vos règles ou leurs métadonnées doit être mis à jour à ce moment.
Ces différentes phases doivent être intégralement automatiques. À chaque modification de la base (que ça soit dans la branche principale ou des branches secondaires, temporaires ou non), vous êtes libres d’exécuter ce que vous voulez. Typiquement, on exécute les tests qui s’exécutent rapidement (validation du formatage, de la syntaxe, des valeurs valides) dans tous les cas, ce qui offre à la personne qui effectue des changements un retour rapide sur ce qu’elle a modifié, lui permettant de corriger ou adapter immédiatement, tant qu’elle est concentrée sur le sujet. La phase de déploiement s’effectue en général sur la branche principale, là où les modifications ont été validées.
2.5 Boucle d’amélioration continue
Nul système n’est fonctionnel dès sa conception, il faut pouvoir l’améliorer dès la découverte de faiblesses. Pour notre système de détection, les défauts remarqués par différents acteurs (analystes, concepteurs, bénéficiaires ou décideurs) peuvent être tracés dans des tickets de suivi au sein de GitLab. Les issue template [6] de GitLab vous permettent de guider les utilisateurs dans le remplissage de ces tickets, notifier les personnes concernées, mettre une échéance de correction et des labels pour aider au tri des tickets.
Il est également possible de détecter automatiquement les cas où une révision de la règle de détection est nécessaire, par exemple suite aux détections et métriques sur les alertes levées − par exemple le taux de faux positifs − vous pouvez créer un ticket qui va pointer les règles à revoir. Une autre possibilité est de mesurer les impacts des règles sur les performances du SIEM pour demander l’amélioration de certaines qui consomment beaucoup de ressources.
3. Testez vous-même
3.1 Objectif
Dans cette partie, vous allez pouvoir mettre en place l’automatisation de la génération d’une matrice de couverture ATT&CK [7] à partir d’un dépôt de règles Sigma [3]. Tout est en source ouverte et hébergé en ligne, pour suivre ce tutoriel vous n’avez besoin que d’un accès à Internet et des connaissances de base du format JSON et du fonctionnement de Docker. Si vous voulez valider l’affichage de la matrice, alors vous aurez besoin de la capacité d’exécuter des conteneurs Docker.
Les étapes décrites dans les sections suivantes vous permettront de mettre en place une preuve de concept ; un certain nombre de points d’attention à avoir pour de la production sont volontairement ignorés ici pour simplifier le processus.
Vous aurez besoin de 30 minutes pour compléter ce tutoriel.
3.2 Centraliser l’information
Nous allons utiliser GitLab comme plateforme DevOps ; c’est une solution complète qui peut être auto hébergée et dont les fonctionnalités gratuites sont amplement suffisantes pour nos besoins. GitHub offre des fonctionnalités similaires, mais certaines sont encore en version bêta et seule une version en ligne existe.
Vous pouvez créer un compte gratuit à l’adresse https://gitlab.com/users/sign_up puis vous authentifier. Dans un premier temps, nous allons récupérer les deux projets en source ouverte nécessaire pour la génération de la matrice :
- ATT&CK Navigator qui regroupe le code nécessaire à afficher la matrice ATT&CK sur une page web dynamique ;
- Sigma qui contient une base de règles avec métadonnées et un script pour alimenter le Navigator ATT&CK.
Depuis la page d’accueil, cliquez sur Create a Project, puis Import Project. Sélectionnez Repo by URL pour choisir de récupérer le code depuis une source externe.
Dans le champ Git repository URL entrez l’adresse du dépôt de Sigma : https://github.com/SigmaHQ/sigma.git, sélectionnez la visibilité à Public sans toucher aux autres champs. Choisir de mettre le projet en public nous évite d’avoir à configurer la gestion des droits dans ce tutoriel, cependant les modifications que vous allez apporter seront accessibles à tout le monde.
Validez avec le bouton Create project. Vous vous retrouvez alors avec votre copie personnelle du dépôt Sigma à jour.
Nous allons de la même façon importer le projet ATT&CK Navigator. Pour cela, retournez à la page d’accueil en cliquant sur le menu Projects en haut à gauche de la page, puis sélectionner Import project.
Suivez alors les mêmes étapes que précédemment en précisant cette fois-ci l’adresse https://github.com/mitre-attack/attack-navigator.git.
Vous avez alors importé dans GitLab les deux projets que vous pouvez voir en allant dans le menu Projects en haut puis Your projects.
3.3 Ajouter de l’automatisation
Maintenant que nous avons regroupé tout le code, nous allons configurer ces dépôts pour effectuer plusieurs opérations :
- nous allons générer un conteneur hébergeant l’application web du Navigator ATT&CK. Ce conteneur n’aura pas connaissance de nos règles, mais contiendra le moteur pour afficher la matrice ATT&CK ;
- nous allons créer un calque, dans un format compréhensible par le Navigator, représentant les règles du dépôt Sigma ;
- enfin nous allons, à partir du conteneur et du calque, créer un second conteneur permettant de visualiser les règles sur la matrice ATT&CK.
Depuis le projet Attack Navigator, accédez au fichier nav-app/src/assets/config.json et modifiez-le en cliquant sur le bouton bleu Edit.
Trouvez dans le fichier la clé default_layers et substituez son contenu par le code ci-dessous, ce qui permet de préparer le conteneur à recevoir les règles Sigma.
Validez la modification du fichier en cliquant sur Commit Changes.
À la racine du projet, cliquez sur le bouton + au-dessus de la liste des fichiers et sélectionnez New File pour créer un fichier.
Donnez-lui le nom .gitlab-ci.yml, c’est par convention le fichier qui héberge la configuration de l’intégration continue du projet. Pour le contenu, reproduisez les lignes ci-dessous (attention, les espaces en début de ligne sont importants).
Le conteneur est créé au niveau de la ligne mise en emphase. La ligne suivante permet de conserver ce conteneur dans la librairie interne du projet.
Validez la création du fichier en cliquant sur Commit Changes. La construction du conteneur commence alors en tâche de fond. Vous pouvez voir son avancée en cliquant sur CI/CD dans le menu latéral, la création va durer environ 7 minutes, mais vous pouvez avancer sur les étapes suivantes en parallèle.
Nous allons maintenant mettre en place l’automatisation sur le projet Sigma, allez dans le menu Projects en haut puis Your projects et accédez à Sigma.
Créez un nouveau fichier à la racine (bouton +) que l’on va nommer Dockerfile. Ce fichier décrit les étapes pour construire le conteneur avec le calque des règles Sigma. Mettez-y le contenu suivant (en remplaçant _utilisateur_ par votre nom d’utilisateur, visible dans l’URL) puis validez sa création en cliquant sur Commit Changes.
Nous avons dans ce fichier une recette simple pour créer le nouveau conteneur : l’ajout du fichier sigma_layer.json (passé en paramètre) au conteneur du projet Attack Navigator permet de créer ce nouveau conteneur. Il ne nous manque plus que le robot qui va s’occuper de cuisiner.
Pour cette étape finale, on doit attendre que le conteneur du projet Attack Navigator soit créé ; vous pouvez vérifier sa présence en allant dans le projet et dans son menu latéral sélectionner Packages & Registries puis Container Registry.
Sur le projet Sigma, ajoutez la configuration de la CI de GitLab (créez un fichier nommé .gitlab-ci.yml à la racine du projet) suivante pour générer automatiquement le fichier de calque puis le conteneur du Navigator ATT&CK à partir des règles du dépôt de sigma. Prenez soin de bien reproduire les espaces.
La construction du conteneur dure cette fois-ci environ 3 minutes. Il y a ici deux étapes principales mises en emphase dans la configuration :
- création du calque sigma_layer.json en utilisant le code disponible dans le dépôt de Sigma ;
- création du conteneur à partir du calque et de la configuration Dockerfile mise en place à l’étape précédente.
Une fois le conteneur créé, vous y avez accès dans le menu latéral Packages & Registries puis Container Registry.
3.4 PROFIT
Si vous avez Docker, vous pouvez lancer votre conteneur avec la commande suivante, en substituant _utilisateur_ avec votre nom d’utilisateur GitLab.
Une fois le conteneur démarré, vous avez accès à la matrice à l’adresse http://localhost:4200/.
Ce que vous avez mis en place n’est pas juste la création du conteneur, mais la mise à jour à chaque modification de la base. Si vous modifiez les techniques associées à une règle, ou ajoutez une règle, alors le conteneur sera mis à jour immédiatement. Sur un système en production, dans la CI de Sigma, on ajouterait une étape de déploiement qui pousse le conteneur vers un hôte qui se charge d’héberger les sites web internes.
4. Pour aller plus loin
4.1 Système multipérimètres
Dans un service gérant plusieurs périmètres (c’est le cas des prestataires de service notamment), on utilise une base centralisée et on y choisit des règles pour les appliquer sur différents périmètres. Ces règles doivent alors être adaptées sur chaque périmètre : les seuils de déclenchement peuvent varier et si les données ne sont pas normalisées sur les SIEM, il se peut que ces dernières soient accédées différemment. Pour conserver des modifications pour un périmètre tout en faisant évoluer la base centrale, on utilise des branches différentes de Git. Une opération de rebase permet d’injecter les modifications faites en central sur la branche d’un périmètre. Pour gérer indépendamment les différents périmètres et leur contrôle d’accès, utilisez des forks de votre base centrale. Dans GitLab, vous garderez vos périmètres à jour grâce à la fonctionnalité de repository mirroring.
4.2 Au-delà de la détection
Je vous ai présenté dans cet article des méthodes et outils pour adapter au DevOps la conception des systèmes de détection, cependant le lecteur averti notera que les conseils peuvent s’appliquer à d’autres métiers de la sécurité opérationnelle.
Au sein d’un CSIRT, au lieu de travailler sur les événements dans le SIEM, vous travaillez sur les traces forensiques collectées sur les systèmes. À la place de règles de détection, vous trouverez des requêtes d’analyse, par exemple la liste des comptes à privilèges créés autour de la date de compromission du patient zéro.
Pour une équipe d’audit, des scénarios d’attaque et exploits peuvent être capitalisés au sein d’une base en suivant ces principes. Que ça soit pour des scripts nmap ou des modules metasploit, la même méthodologie peut être appliquée.
Si vous avez une approche SOAR des opérations (Security Orchestration Automation & Response), adaptez vos outils pour prendre en compte les points ci-dessus : ajoutez à vos playbooks une tâche de création d’un ticket pour la révision d’une règle, évaluez régulièrement la pertinence des règles de détection à partir de métriques simples, etc. La seule limite est votre imagination.
Références
[1] https://medium.com/anton-on-security/can-we-have-detection-as-code-96f869cfdc79
[3] https://github.com/Neo23x0/sigma
[5] https://github.com/mitre/caldera
[6] https://docs.gitlab.com/ce/user/project/description_templates.html